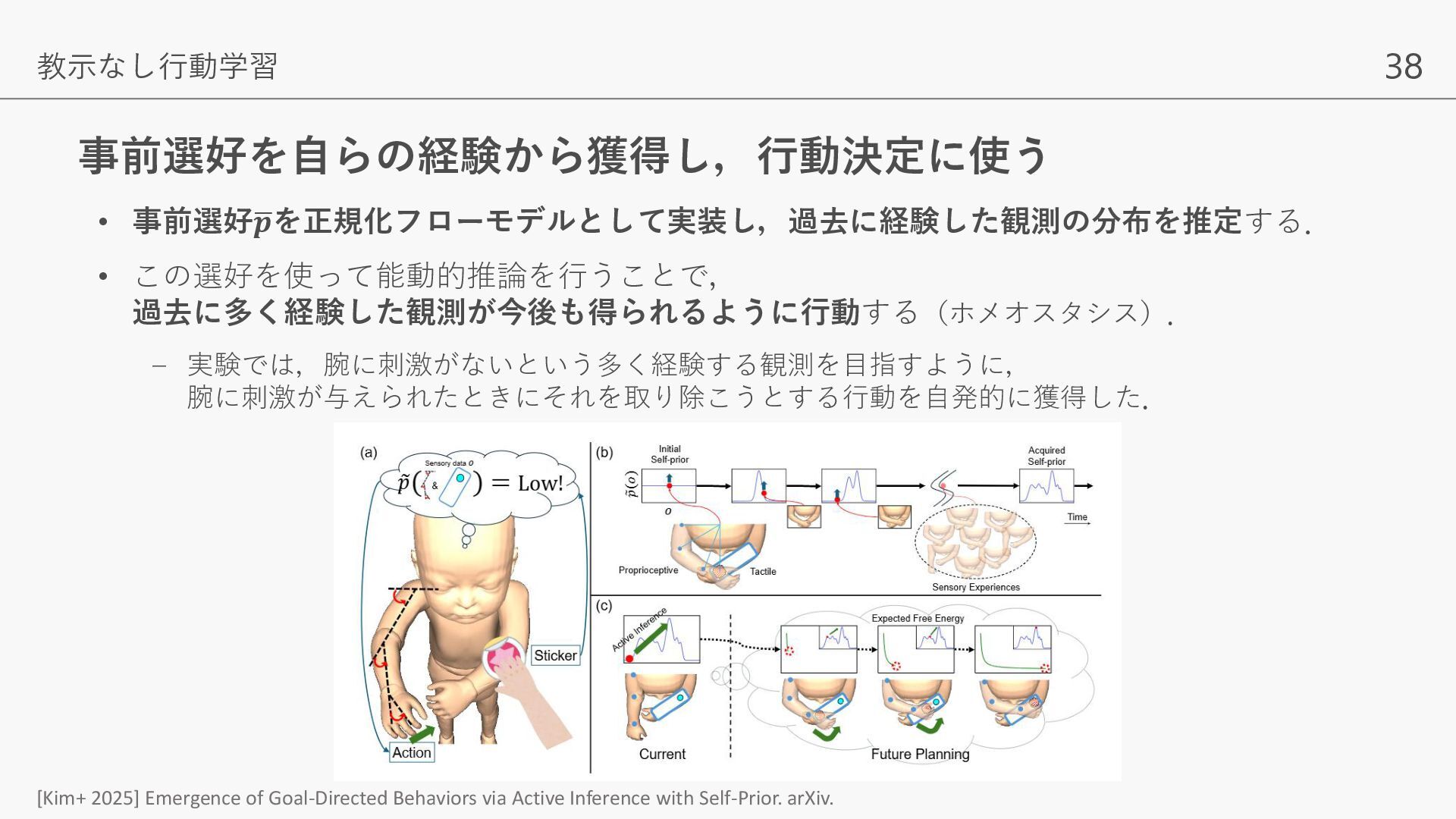
実験では,腕に刺激がないという多く経験する観測を目指すように, 腕に刺激が与えられたときにそれを取り除こうとする行動を自発的に獲得した. [Kim+ 2025] Emergence of Goal-Directed Behaviors via Active Inference with Self-Prior. arXiv.
• AIFによる行動選択の際に,Diffusion policyから候補となる行動系列を複数サンプリングする. ‒ Diffusionモデルの高品質かつ多様性を担保したサンプル精製能力を活用. • 画像観測からの移動ロボットのナビゲーションタスクに成功. [Yokozawa+ 2025] Deep Active Inference with Diffusion Policy and Multiple Timescale World Model for Real-World Exploration and Navigation. arXiv.
Preference(RSSP)を学習. • さらに,成功/失敗に応じて各時刻の選好度合いを調整. • これにより低品質のデモやRL policyで集めたデータから,それらを超えた性能を探索的に実現. • Dreamer V3や他のAIF手法よりも学習が早く,性能もよい. [Nguyen+ 2025] SR-AIF: Solving Sparse-Reward Robotic Tasks From Pixels with Active Inference and World Models. ICRA 2025.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
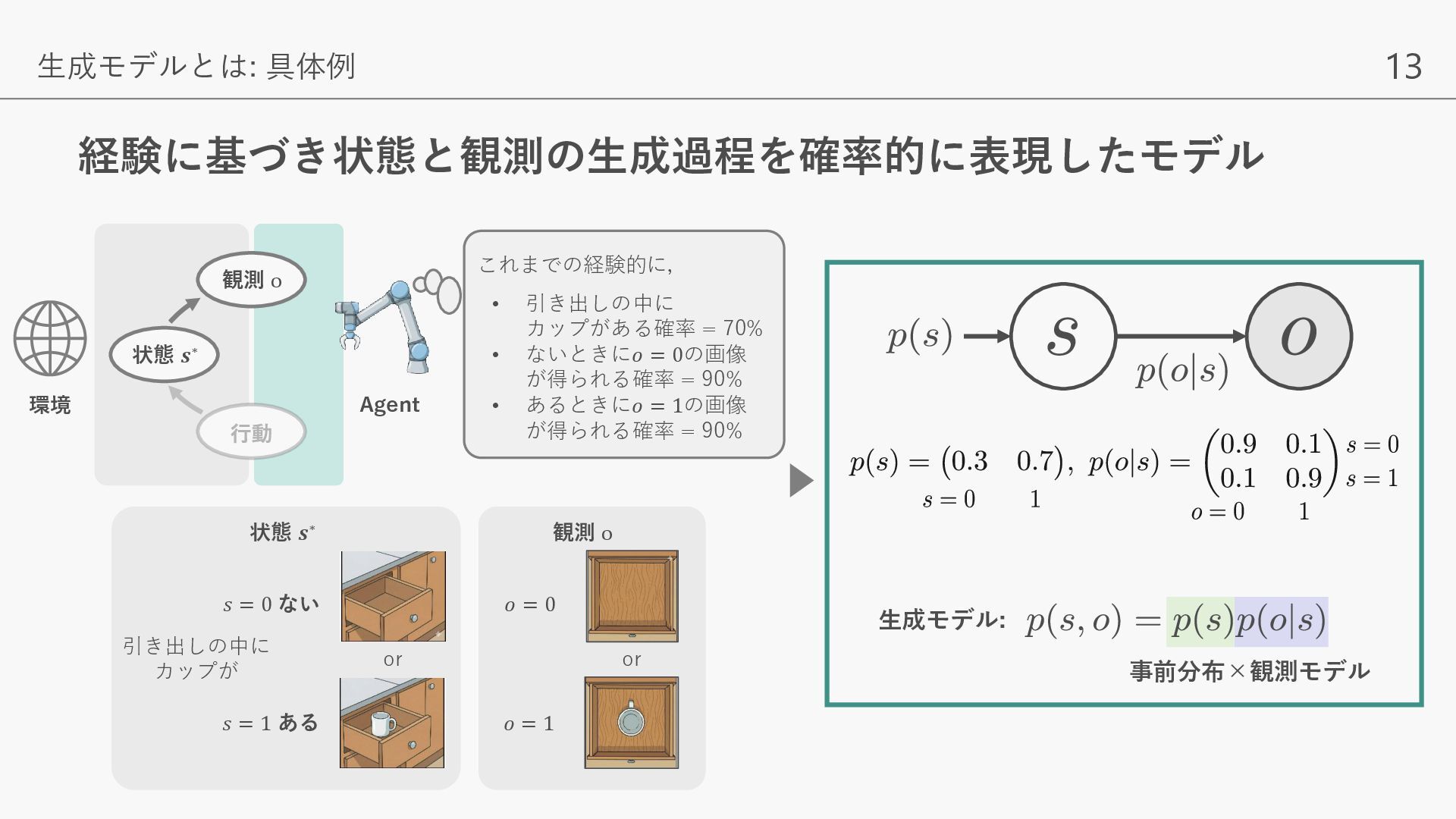{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
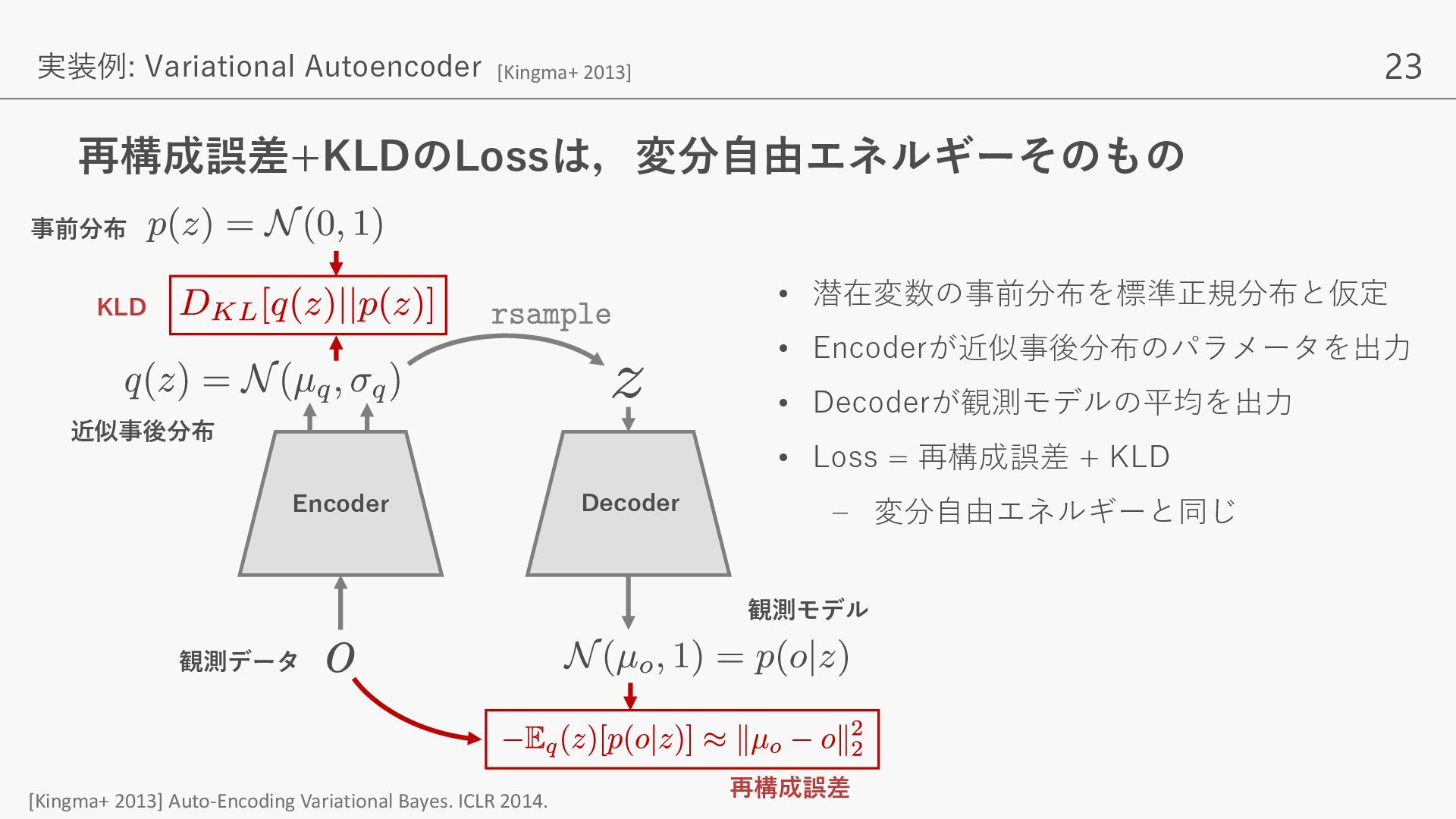{kind=link}
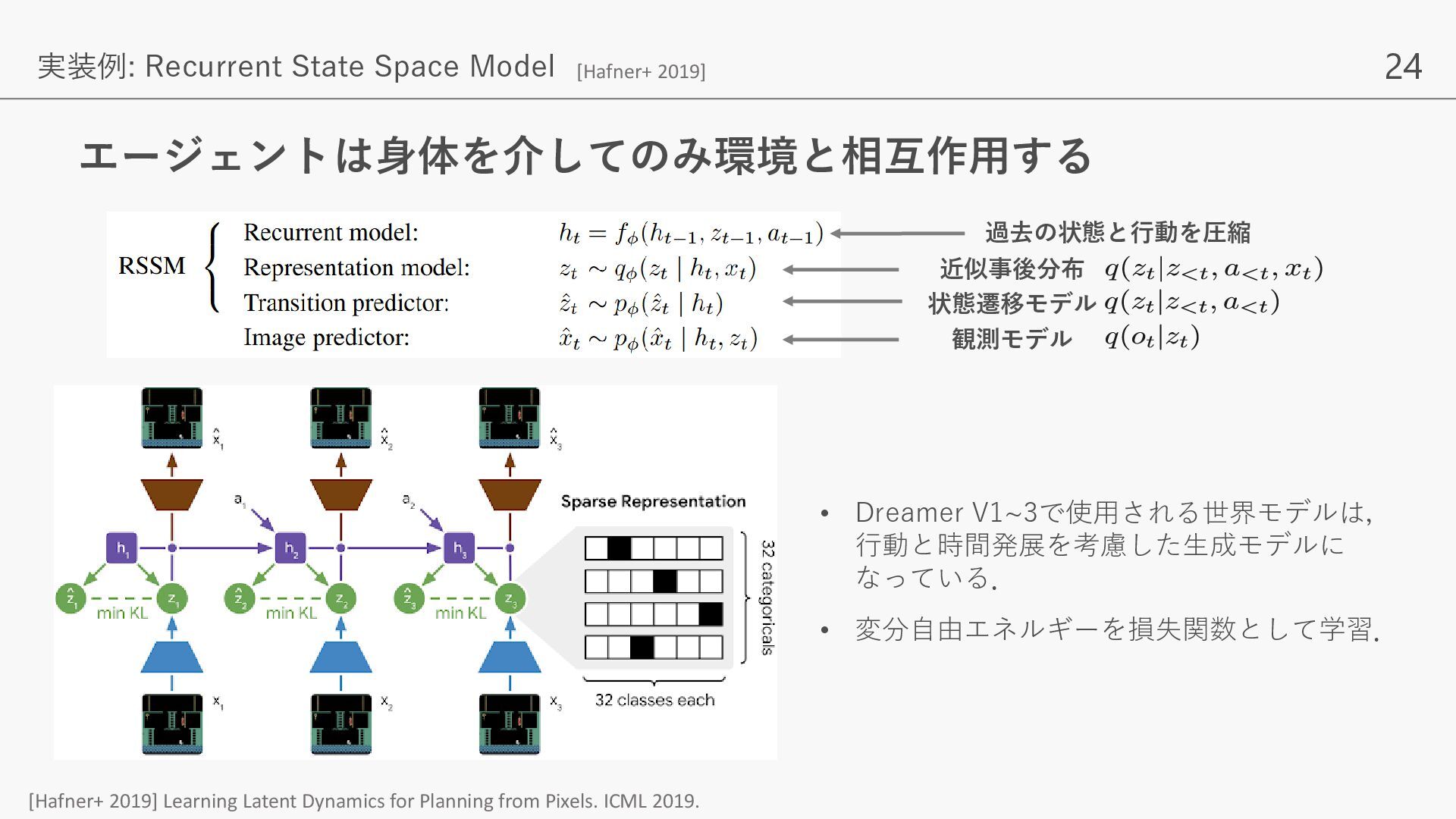{kind=link}
{kind=link}
{kind=link}
{kind=link}
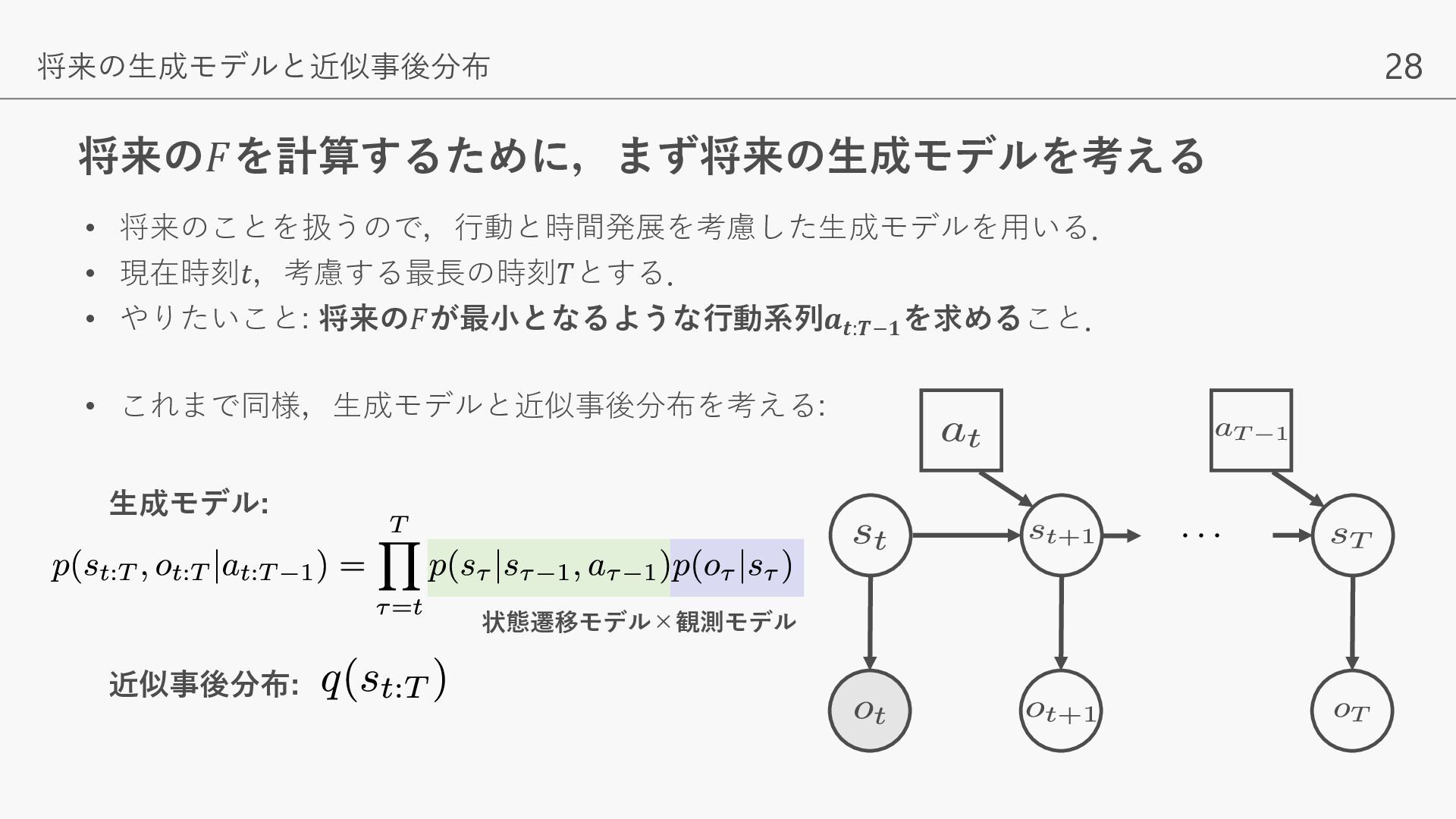{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}