Decision Process としての Order Dispatching 提案手法 • Population-Based Online Learning Objective • Value Ensemble With Offline Evaluation • Unified Framework For Dispatch and Reposition 実験結果
value function を更新させて学習 Positive Updates Negative Updates driver-order の matching が成功すると、 value function は 増大するように更新される driver が idle すると、 value function は減少するように更新される これらの Bellman Updates をもとに DQN 等と同様の考え方で bootstrapping-based の目的関数を構成し value function 𝑉𝑉𝜃𝜃 を学習 ここで、𝛿𝛿𝜃𝜃 𝑖𝑖 は temporal difference error Objective Key Idea to Learn Value Function
{kind=link}
{kind=link}
{kind=link}
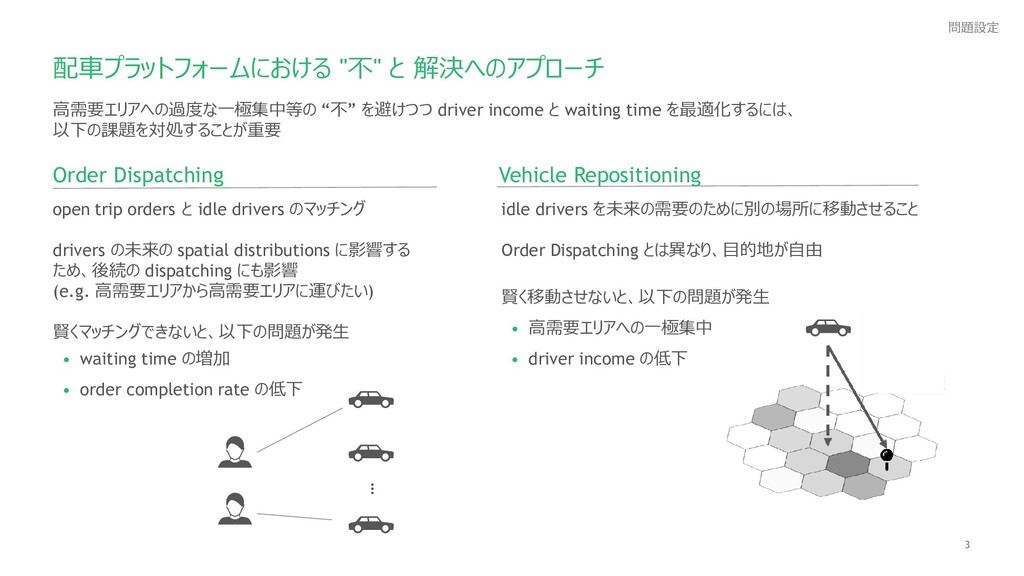{kind=link}
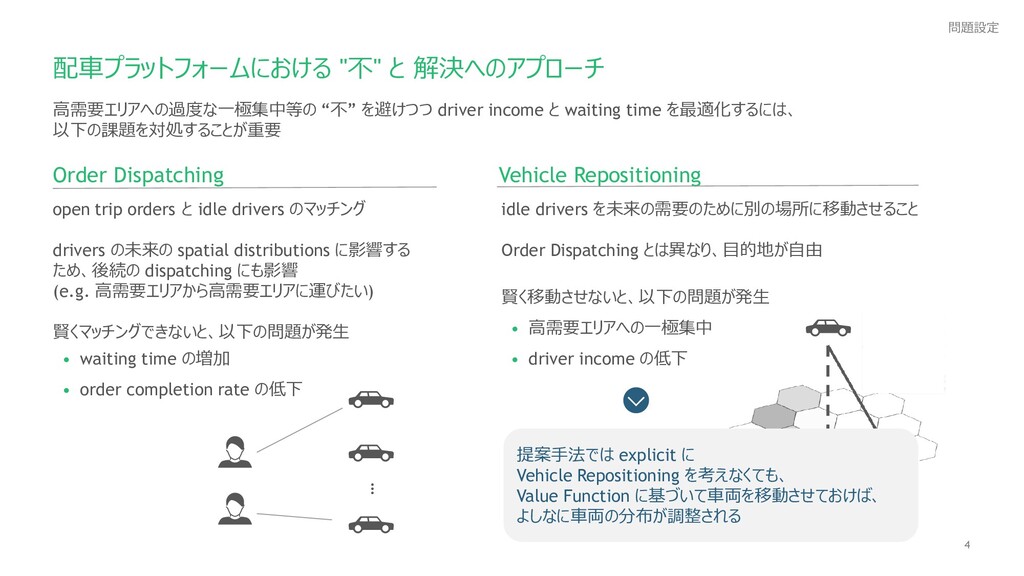{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}