Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
icml2021_reading_lenient_regret_and_good_action...
Search
Hideaki Kano
August 19, 2021
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
icml2021_reading_lenient_regret_and_good_action_identification_in_gaussian_process_bandits
Hideaki Kano
August 19, 2021
More Decks by Hideaki Kano
See All by Hideaki Kano
kdd2021_reading_value_function_is_all_you_need_a_unified_learning_framework_for_ride_hailing_platforms.pdf
kanohideaki
0
1.4k
Featured
See All Featured
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Site-Speed That Sticks
csswizardry
13
1.2k
Why Our Code Smells
bkeepers
PRO
340
58k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Code Reviewing Like a Champion
maltzj
528
40k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
How to build a perfect <img>
jonoalderson
1
5.8k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
The Limits of Empathy - UXLibs8
cassininazir
1
390
Transcript
0 Lenient Regret and Good-Action Identification in Gaussian Process Bandits
Xu Cai, Selwyn Gomes, Jonathan Scarlett ⿅野 英明 @ BCG GAMMA ICML2021 論⽂読み会 Twitter: #icml2021_reading
1 ⾃⼰紹介 ⿅野 英明 Kano, Hideaki 経歴 • 2019年 09⽉
– 現在: データサイエンティスト, BCG, DigitalBCG Japan, BCG GAMMA • 2018年 04⽉ - 2019年 08⽉: エンジニア, リクルートコミュニケーションズ (RCO) • 2017年 03⽉ – 2018年 03⽉: リサーチアシスタント, RIKEN AIP • 2018年 03⽉: 修⼠, 東京⼤学⼤学院 新領域創成科学研究科 複雑理⼯学専攻 杉⼭研究室 • 2016年 03⽉: 学⼠, 北海道⼤学 ⼯学部 情報エレクトロニクス学科 コンピュータサイエンスコース 今井研究室 経験領域 • シェアリングエコノミー: シミュレーション, 数理最適化 • 保険: 顧客特性分析 • ヘルスケア: 疾病予測 • ⼩売り: 需要予測, 商品特性分析 • 物流: 需要予測, 数理最適化 過去の活動 • JSAI2021 のランチョンセミナーにて以下の発表を⾏いました 「AI技術とデータによる社会変⾰のインパクト創出を⽬指した、AI⼈材教育と医療データ活⽤の取り組み」 https://www.ai-gakkai.or.jp/jsai2021/night-luncheon • 今年1⽉に TECH PLAY の以下のイベントに登壇いたしました 「ボストン コンサルティング グループ(BCG)が仕掛ける デジタル産業イノベーション事例【ビジネス(経営)×データサイエンス】 」 https://techplay.jp/column/1475 • リクルート在籍時に 「多腕バンディット問題と A/B テスト」 という解説記事を書きました https://www.rco.recruit.co.jp/career/engineer/blog/bandit/ • リクルート在籍時に以下の紹介記事を書きました 「新⼈エンジニア主催で ISUCON に機械学習の要素を取り⼊れた新しいタイプのコンテストを開催しました」 https://www.rco.recruit.co.jp/career/engineer/blog/pigicon/
2 本⽇の内容 論⽂の問い • Multi-Armed Bandits と Gaussian Process Bandits
• Lenient Regret と Good Arm Identification ― Optimal は Practical か︖ • 本論⽂の位置づけ 論⽂の貢献 • Theoretical な貢献: Lenient Regret を⽤いた Gaussian Process Bandits の Upper and Lower Bounds の導出 • Practical な貢献: Good-Action Identification を効率的に解くアルゴリズムの開発 • 実験結果 まとめ
3 単⼀のエージェントが複数台のスロットマシン** を繰り返しプレイ このとき、どのような戦略がベストかを考える問題 • アーム 𝑎 ∈ 𝐾 =
{1, … , 𝐾} は 期待報酬 𝜇! の確率分布 𝜈! を持つ • エージェントは 時刻 𝑡 = 1, … , 𝑇 で アーム 𝑎 𝑡 を引き、 報酬 𝑋! " 𝑡 ∼ $.$.&. 𝜈!(") を 得る 古典的な枠組みは以下の2つ • 累積リグレット最⼩化: 得られる報酬を最⼤化したい • Best Arm Identification: 最も当たる台を⾒つけたい 選択可能な候補の数は、離散的かつ有限個 Multi-Armed Bandits (多腕バンディット問題*) Multi-Armed Bandits と Gaussian Process Bandits * 多腕バンディット問題という名前は, スロットマシンをギャンブラーからお⾦を奪う “1本腕の盗賊 (one-armed bandit)” と喩える遊び⼼に由来しています ** スロットマシンのことを単に “アーム”, スロットマシンをプレイすることを “アームを引く” と呼ぶことが多いので, それに倣います 単⼀のエージェントが選択可能なアクションを繰り返し実⾏ このとき、どのような戦略がベストかを考える問題 • 選択可能なアクションは 𝑎 ∈ 𝒟 = 0, 1 & • エージェントは 時刻 𝑡 = 1, … , 𝑇 で アクション 𝑎" を⾏い、 報酬 𝑋" = 𝑓 𝑎" + 𝜖" , 𝜖" ∼ 𝒩(0, 𝜎)) を 得る (ただし 𝑓 は 𝒟 上の未知の関数) 古典的な枠組みは以下の2つ • 累積リグレット最⼩化: 得られる報酬を最⼤化したい • 単純リグレット最⼩化: 最適なアクションを実⾏したい 選択可能なの候補の数は、連続的かつ無限個 Gaussian Process Bandits
4 Lenient Regret と Good Arm Identification ― Optimal は
Practical か︖ 古典的な枠組みでは、最適な値や台を特定するための探索回数が多く、実応⽤できないケースがしばしば存在 → 最近、Multi-Armed Bandits では "near-optimal" な戦略 や "good enough" な台を求める⼿法が発展 near-optimal なアームを引いた場合は ペナルティが⽣じないように緩和したリグレット Standard Regret: 𝑅 𝑇 = 𝔼 Σ"*+ , Δ" • Δ" ≔ 𝜇∗ − 𝜇!(") • 𝜇∗ ≔ max !∈ / 𝜇! Lenient Regret: B 𝑅0 𝑇 ≔ 𝔼 [Σ"*+ , Φ(Δ" )] • 𝜖-gap 関数 Φ: 0, 1 → 0, ∞ s.t. Φ Δ = 0, ∀Δ < 𝜖 優良腕 (期待報酬がしきい値以上の台) を探索する問題 アルゴリズムが 𝛿-PAC (Probably Approximately Correct) という 条件下で、優良腕を出⼒し停⽌するまでの時刻 {𝜏+ , . . , 𝜏2345 } の同時最⼩化問題として定式化 • 𝛿-PAC: 𝜆, 𝛿 -PAC ∀𝜆 ∈ 𝐾 • (𝜆, 𝛿)-PAC: ℙ ) 𝑚 < 𝜆 ∪ ⋃"∈ $ %!,… , $ %" 𝜇" < 𝜉 ≤ 𝛿 if 𝜆 ≤ |𝒜())* |, ℙ ) 𝑚 ≥ 𝜆 ≤ 𝛿 if 𝜆 > |𝒜())* | , where 𝜆: 出⼒したい優良腕の数, ) 𝑚: 優良腕として出⼒した台の数, 𝜉: しきい値, 𝒜())* : 優良腕の集合 Dilemma of Confidence が発⽣し、累積リグレット最⼩化に類似 → この類似性を活⽤した探索アルゴリズムは漸近最適性を持つ Lenient Regret [Merlis and Manner, '21] Good Arm Identification [Kano+, '19]
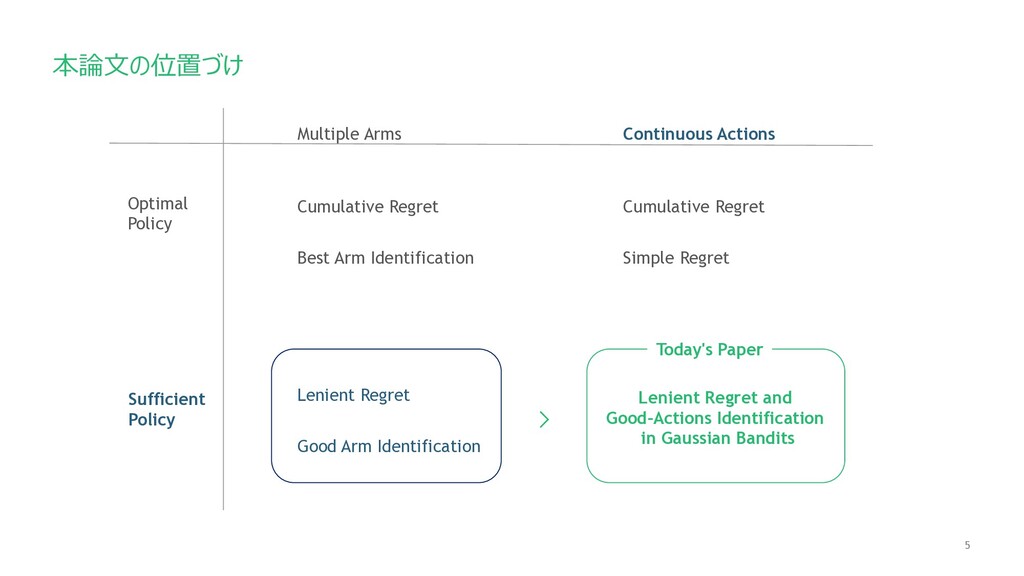
5 Cumulative Regret 本論⽂の位置づけ Best Arm Identification Multiple Arms Continuous
Actions Optimal Policy Sufficient Policy Lenient Regret Good Arm Identification Cumulative Regret Simple Regret Lenient Regret and Good-Actions Identification in Gaussian Bandits Today's Paper
6 Theoretical な貢献: Lenient Regret を⽤いた Gaussian Process Bandits の
Upper and Lower Bounds の導出 Upper Bound Lower Bound Squared Exponential (SE) Kernel においては以下が知られているので、 𝛾+ = 𝑂∗ log 𝑡 - , where 𝑂∗ ⋅ hides dimension-independent logarithmic factors 𝑁./0 に関して以下が成り⽴つ 𝑁./0 ≤ 𝑂∗ log 𝑇 ⋅ log 1 Δ - Δ1 GP-UCB を⽤いた Standard Regret の Regret bound: 𝑂 𝑇𝛾2 𝛽2 Lenient Regret の主要な項 は 𝑇 poly(log 𝑇) から poly(log 𝑇) へ削減
7 流体⼯学での研究 [Kushner, 1964] から着想 しきい値 𝜂 よりも上回っている確率が⾼い箇所を 以下のスコア 𝛼"
(x) で推定し、 𝛼"(x) = Φ 6345 7 8 9 :345 7 • Φ: 正規分布の累積分布関数 このスコアが最⼤のアクションを各時刻で実⾏ ここで、Φ は単調増加関数なので、 実装上は 6345 7 8 9 :345 7 のみを考慮すればよい Probability of Being Good (PG) Practical な貢献: Good-Action Identification を効率的に解くアルゴリズムの開発 PG 法では、しきい値を上回る確率のみを考えていたが、 期待改善幅も EG 法では考慮 以下のスコアが最⼤となるようなアクションを実⾏ 𝛼" x = 𝜇"8+ x − 𝜂 ⋅ Φ 6345 7 8 9 :345 7 + 𝜎"8+ x ⋅ 𝜙 6345 7 8 9 :345 7 • 𝜙: 正規分布の確率密度関数 単純リグレットを⽤いた Gaussian Process Bandits において 「⽬先の」 最⼤値改善を⽬指す貪欲法として Expected Improvement 法は知られている Expected Improvement Over Good (EG) Good Arm Identification を解く従来のアルゴリズムでは、探索時にしきい値の情報は未活⽤ 以下の提案⼿法*では、これを活⽤したより効率的な探索を実⾏ * この他にも, 論⽂内で Good-Action Search, Supplementary 内で Satisficing Thompson Sampling, Elimination Algorithm が提案されている
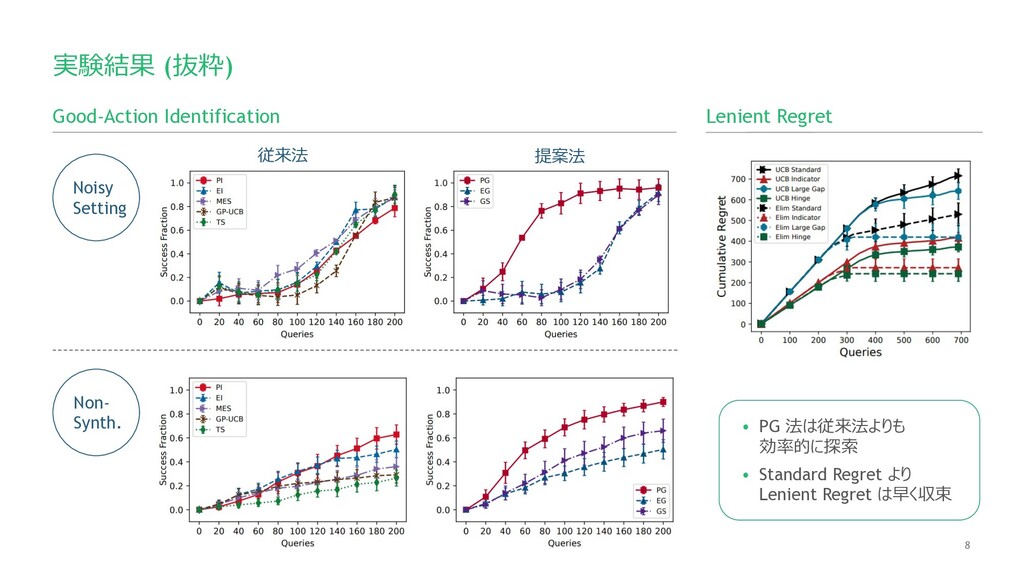
8 実験結果 (抜粋) Good-Action Identification 従来法 提案法 Noisy Setting Non-
Synth. Lenient Regret • PG 法は従来法よりも 効率的に探索 • Standard Regret より Lenient Regret は早く収束
9 まとめ • 問題設定: Lenient Regret と Good Arm Identification
を Multi-Armed Bandits から Gaussian Process Bandits へ拡張 • Theoretical な貢献: Lenient Regret を⽤いた Gaussian Process Bandits の Upper and Lower Bounds の導出 • Practical な貢献: Good-Action Identification を効率的に解くアルゴリズムの開発
10 DigitalBCG GAMMA - 募集要項 勤務地 選考プロセス 書類選考、テクニカルテスト、複数回の⾯接 東京・京都・⼤阪オフィス データサイエンティスト
ソフトウェアエンジニア/ データエンジニア 詳細はDigitalBCG Japanウェブサイト もしくは
[email protected]
へお問合せ下さい 職種
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![7 流体⼯学での研究 [Kushner, 1964] から着想 しきい値 𝜂 よりも上回っている確率が⾼い箇所を 以下のスコア 𝛼"](https://files.speakerdeck.com/presentations/0295d2f0c12640328fb8a4f1fea697bb/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}