Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
JOAI2026講評会スライド
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Haruki Katayama
April 15, 2026
350
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
JOAI2026講評会スライド
Haruki Katayama
April 15, 2026
Featured
See All Featured
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
ラッコキーワード サービス紹介資料
rakko
1
4M
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
980
Balancing Empowerment & Direction
lara
6
1.2k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
380
We Are The Robots
honzajavorek
0
280
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
350
Embracing the Ebb and Flow
colly
88
5.1k
Transcript
JOAI2026 4th solution 長野県諏訪清陵高等学校3年 片山悠輝 Public LB : 1位 /
Private LB : 4位
自己紹介 名前:片山悠輝(Katayama Haruki) 所属:長野県諏訪清陵高等学校 3年 主な活動:生物の研究, AIの勉強 JOAI前の自分のステータス: 松尾研の講座を複数修了 /
kaggle経験ほぼ0 / プログラミング力→読めるけど書けない 今回のタスクが生物 ×AIだったので、タスクとの相性がよかった
日程・順位の推移 1日目~3日目 ベースラインの作成: 特徴量、前処理、BiLSTM、補助損失関数 3日目~7日目 ひらすら実験: アンサンブルモデルの作成、Mouse_idごとの処理、 7日目~9日目 最終調整: ハイパラチューニング、Seedアンサンブル、 Public: 1位 Public:
3位 Public: 2位 Public: 1位 Public: 1位 Private: 4位
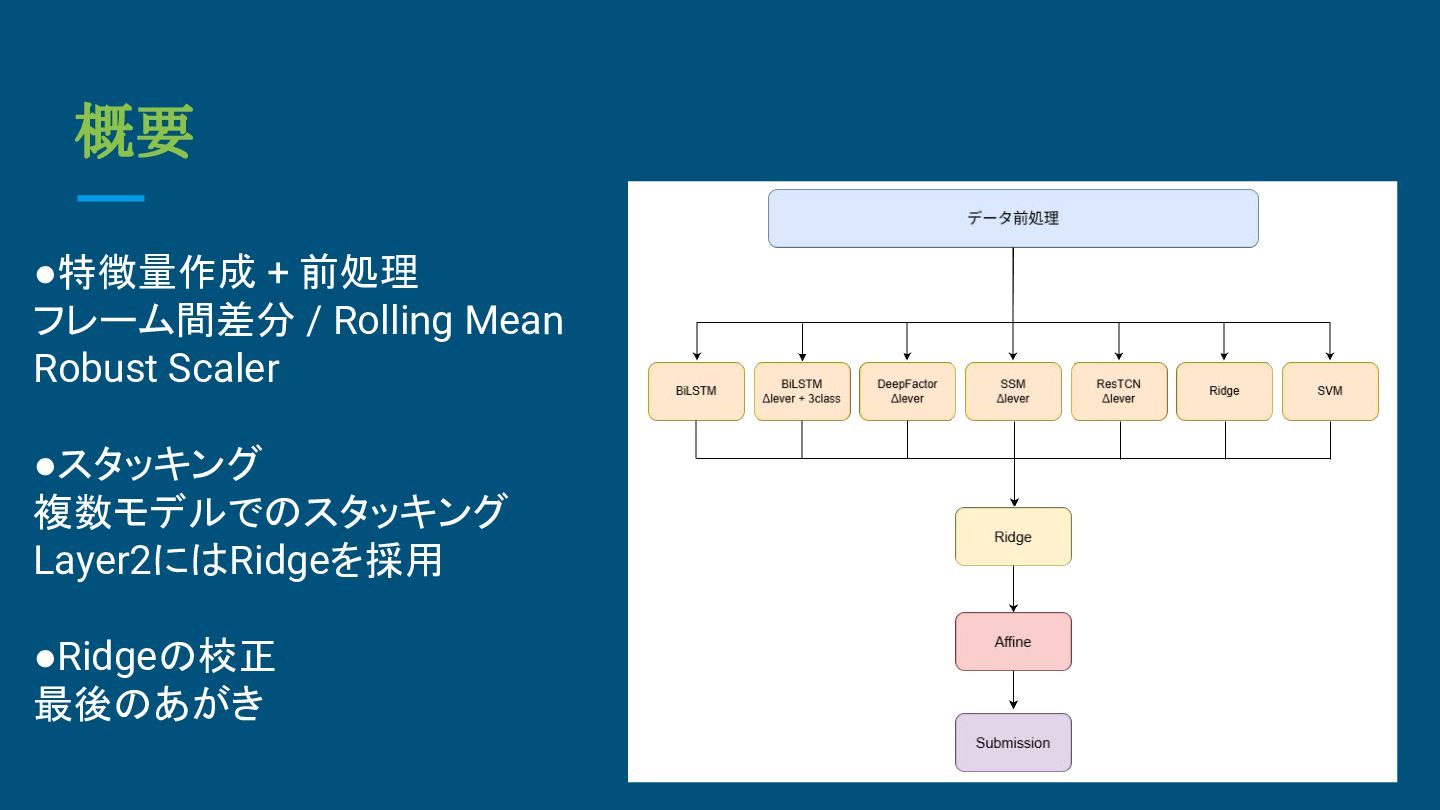
概要 •特徴量作成 + 前処理 フレーム間差分 / Rolling Mean Robust Scaler
•スタッキング 複数モデルでのスタッキング Layer2にはRidgeを採用 •Ridgeの校正 最後のあがき
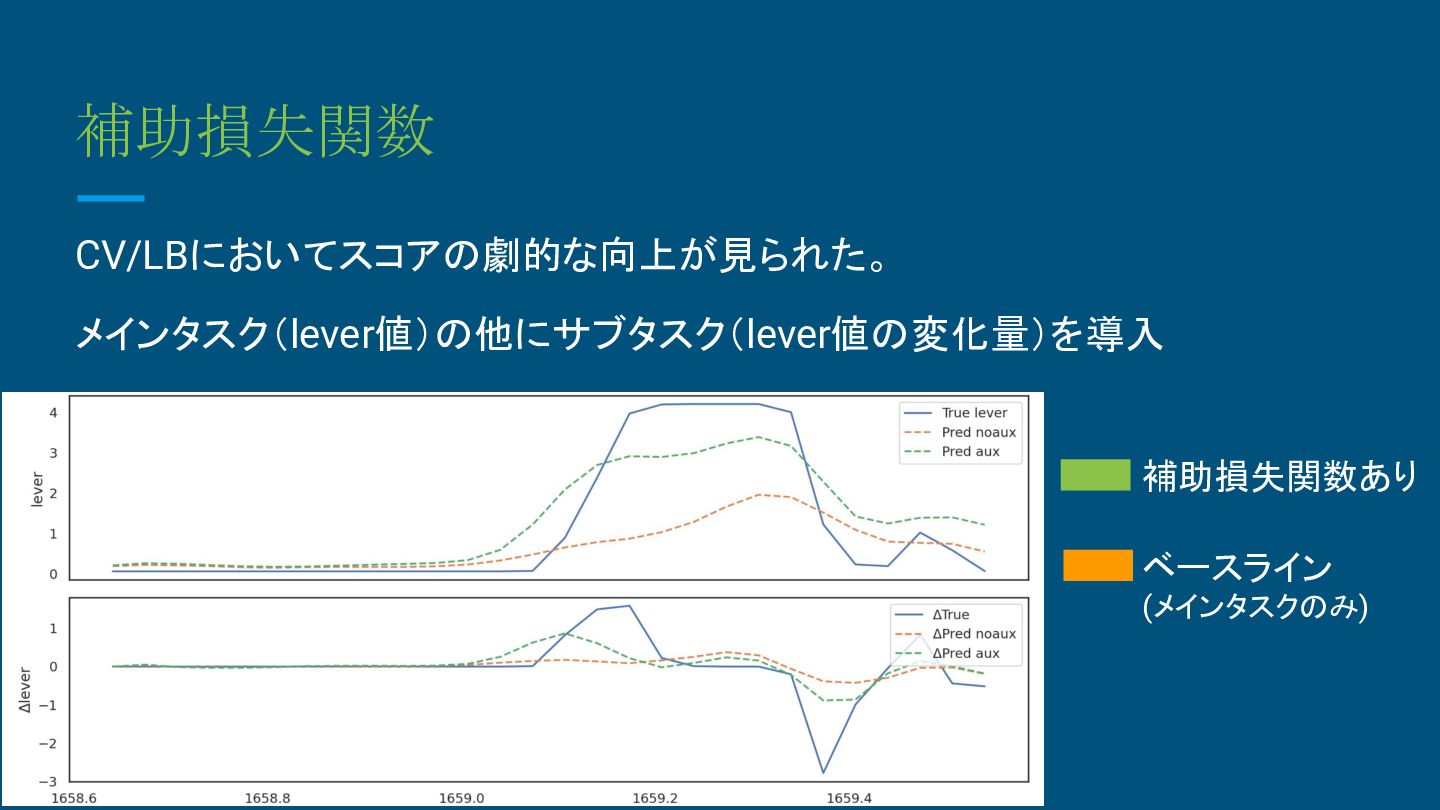
補助損失関数 CV/LBにおいてスコアの劇的な向上が見られた。 メインタスク(lever値)の他にサブタスク(lever値の変化量)を導入 補助損失関数あり ベースライン (メインタスクのみ)
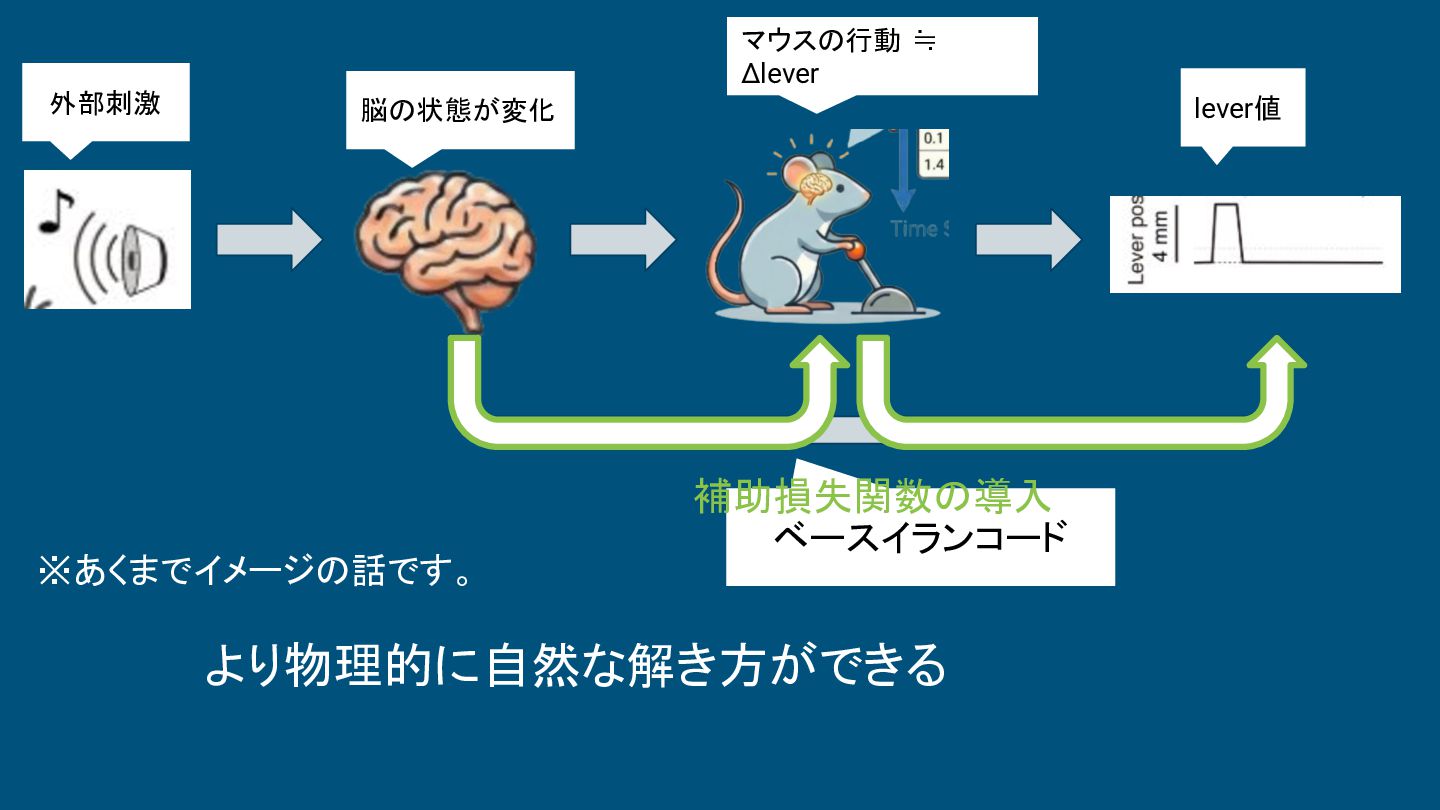
外部刺激 脳の状態が変化 マウスの行動 ≒ Δlever lever値 ベースイランコード ※あくまでイメージの話です。 より物理的に自然な解き方ができる 補助損失関数の導入
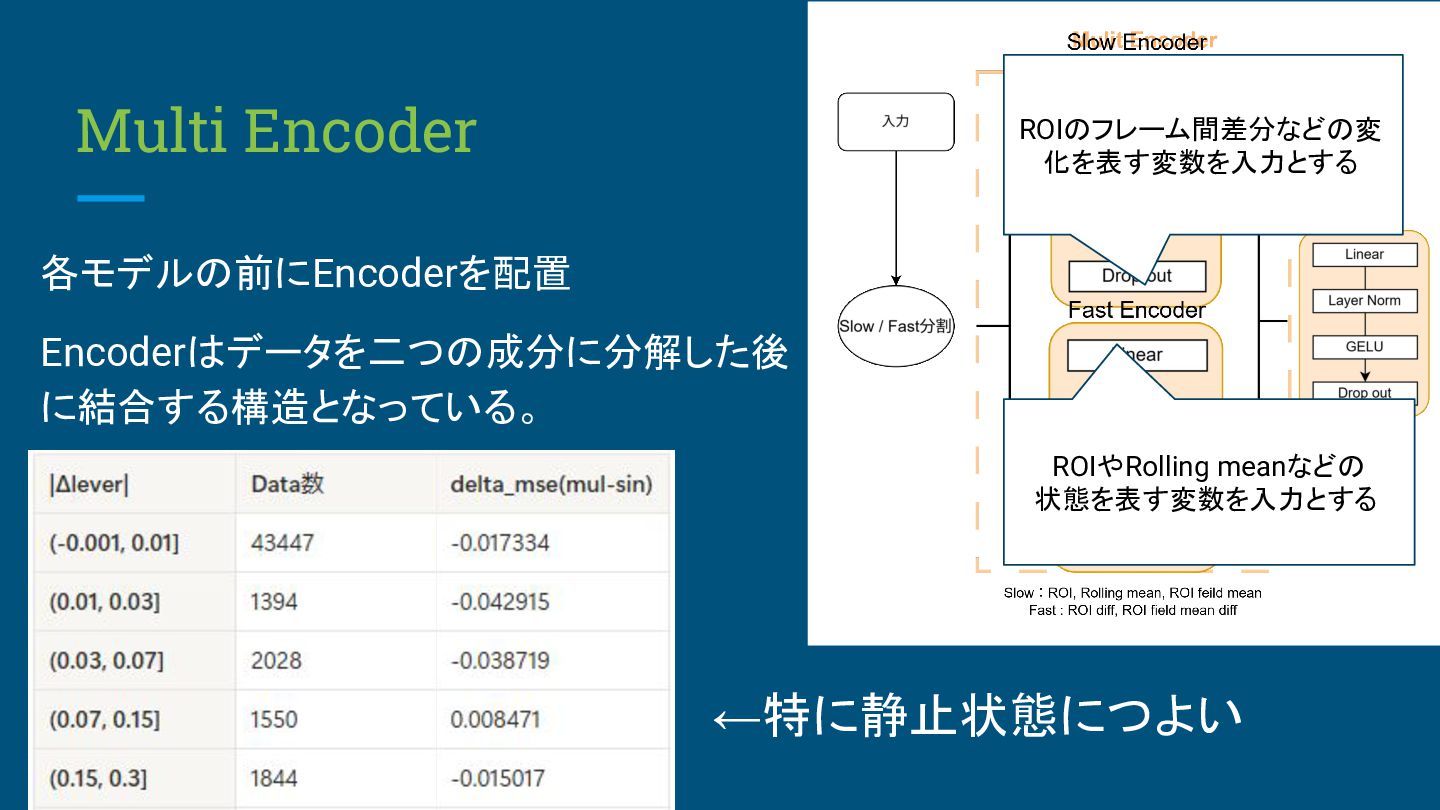
Multi Encoder 各モデルの前にEncoderを配置 Encoderはデータを二つの成分に分解した後 に結合する構造となっている。 ←特に静止状態につよい ROIやRolling meanなどの 状態を表す変数を入力とする ROIのフレーム間差分などの変
化を表す変数を入力とする
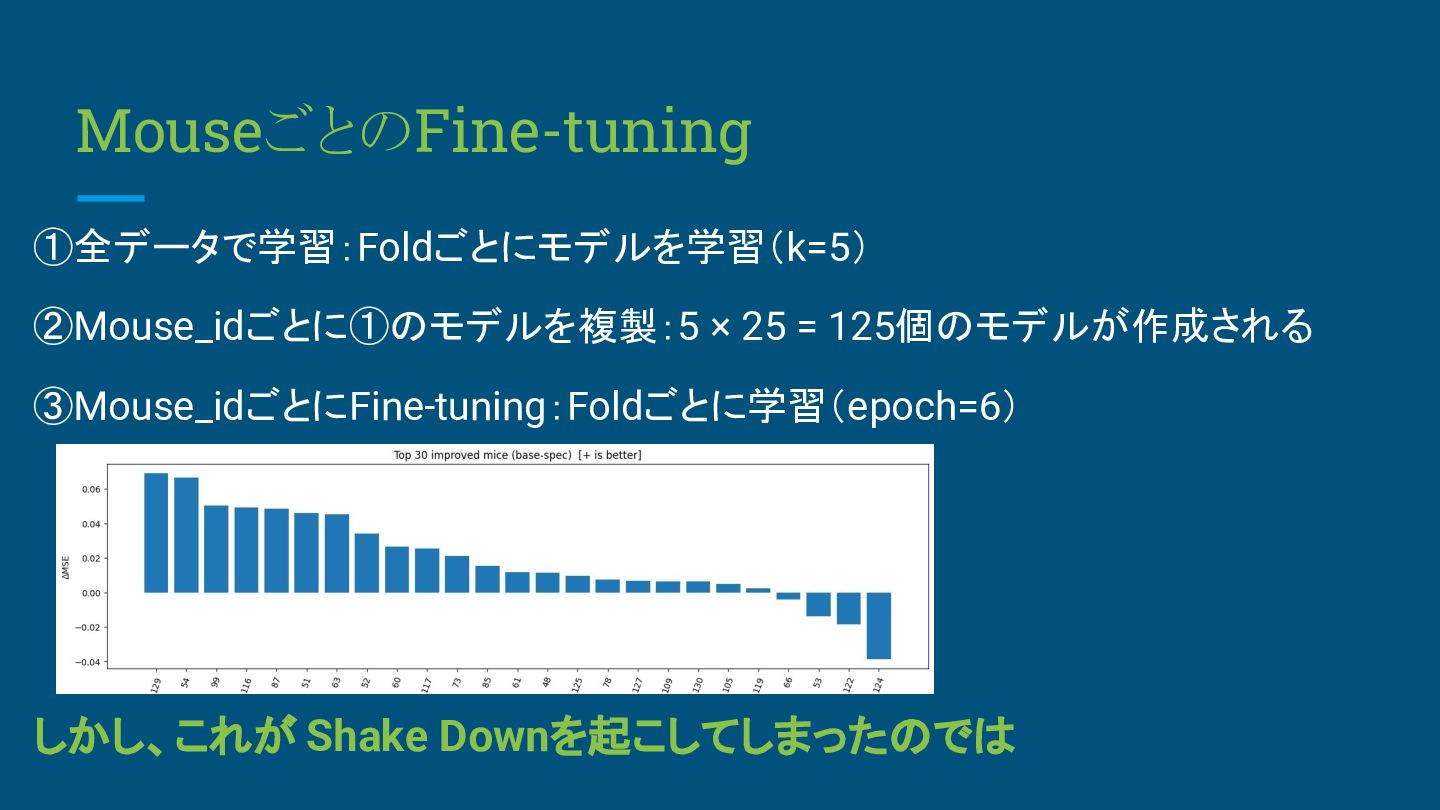
MouseごとのFine-tuning ①全データで学習:Foldごとにモデルを学習(k=5) ②Mouse_idごとに①のモデルを複製:5 × 25 = 125個のモデルが作成される ③Mouse_idごとにFine-tuning:Foldごとに学習(epoch=6) しかし、これが Shake
Downを起こしてしまったのでは
Ridgeの校正 スタッキングの結果を y = a * p + b で線形変換する。 mouse_id /
day_nのグループごとに行う。 極度の補正やOverfittingを防ぐために、 全体での変換とグループごとの変換を加重平均して調整、 傾きaはクリッピングで大きすぎる値をとらないようにした。
その他の工夫 ・活性化関数:GELU GELU関数はReLU関数と比べてモデルの表現力が向上する(ニューロンが死 なない) ・Optimizer:AdamW 一般的にはAdamよりも汎化性能が高いと言われている ・スケジューラ:OneCycleLR 学習初期に学習率を大きくすることで局所解への収束を防止する。
使用したモデル ・BiLSTM:今回は時系列データではあるが、回帰的に解く必要はないので(未 来情報を使用可能なため)双方向が有効だった。 ・ResTCN:1D-CNNをベースにしたモデル。BiLSTMよりもスコアが高かった。 ・DeepFactor:ローカル成分とグローバル成分の分解をする。詳しくは調べて みてください。 モデルは精度よりもモデル同士が異なる学習原理を持つことが大切。
来年の参加者に向けて ▪おすすめの取り組み方 少しのEDA→ベースライン作成→エラー分析→改善 本格的なEDAはエラー分析の段階で行ったほうが個人的にはやりやすい。 ▪おすすめのマインドセット 序盤の駆け出しがかなり大事。順位が低いとモチベーション低下につながる。 スコアが向上しなくても焦らない(時間をおいて考えればだいたい解決する) ▪おすすめのLLMの使い方 LLMは基本的にはコーディングと過去コンペの調査に使用する。 モデル選択やモデルの構造はなるべく自分できめる。
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}