Computing & operations (how?) 3. Applications (why?) • Each part has some theory and notebook exercises • See https://kermit-ugent.github.io/HDC_tutorial/ for the notebook! • About one hour per part, feel free to take a break during the exercises 2
As of September 2023, a lecturer in applied dynamical systems at Faculty of Bioscience Engineering • Teaches mathematical modeling courses • Co-leading the KERMIT (knowledge- based systems) research unit • Primary research interest: computing for and computing by living systems My background 3
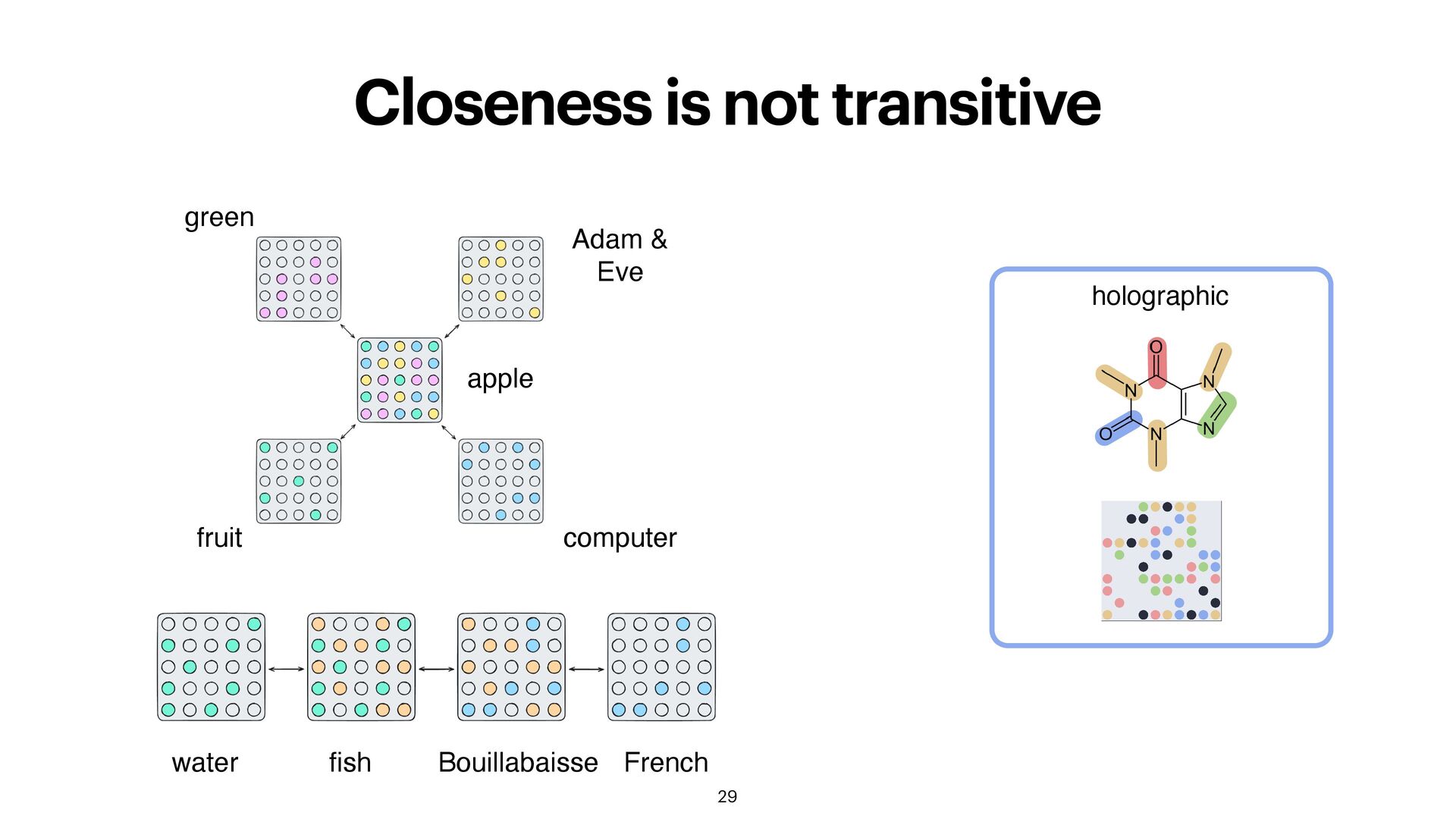
in f initely many new combinations? How do I represent new combinations, techniques? How do I compare two recipes? Which ingredient would be best to add?
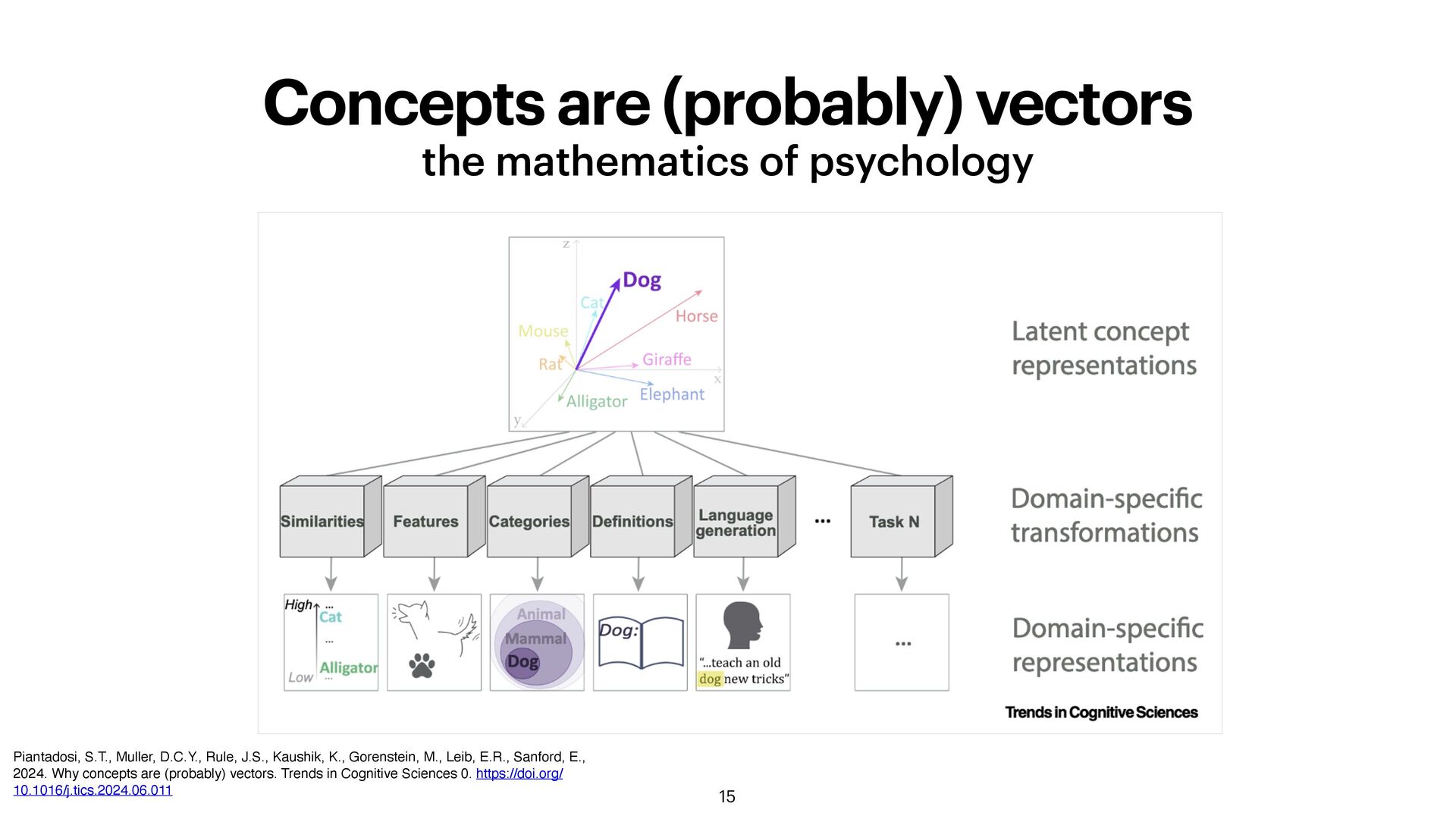
networks (ANN) and HDC are both (highly abstracted) models of the brain: •Arti fi cial Neural Networks model neurons and synapses (connectionist) •HDC models distributed memory and processing HDC is a kind of neuro-symbolic AI, i.e. brain-inspired models based on symbolic reasoning What is 🍏? ANN: inputs → Neural network → output = apple HDC: sphere ⊗ fruit ⊗ green ⊗ tree = apple
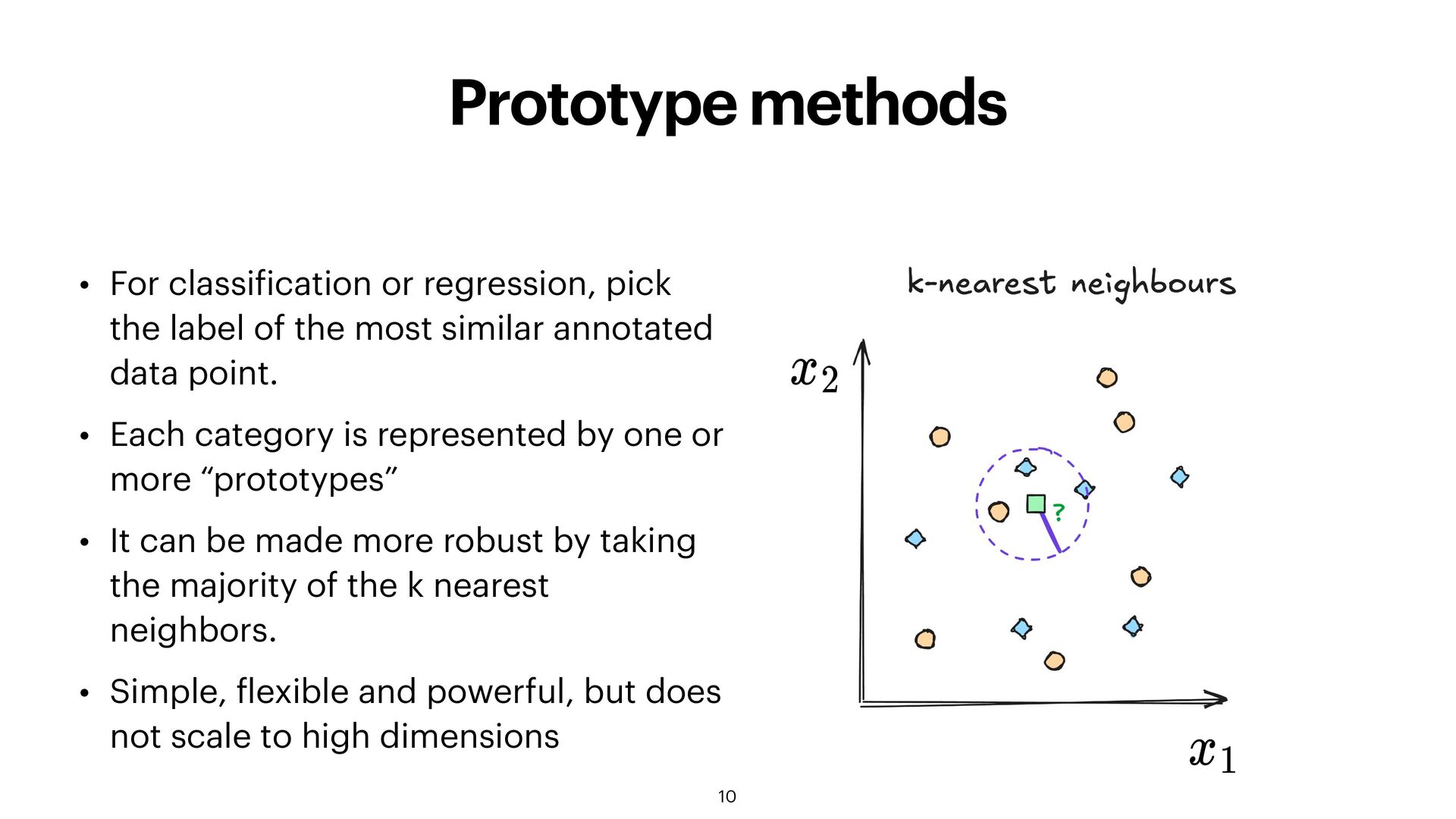
the label of the most similar annotated data point. • Each category is represented by one or more “prototypes” • It can be made more robust by taking the majority of the k nearest neighbors. • Simple, f lexible and powerful, but does not scale to high dimensions 10
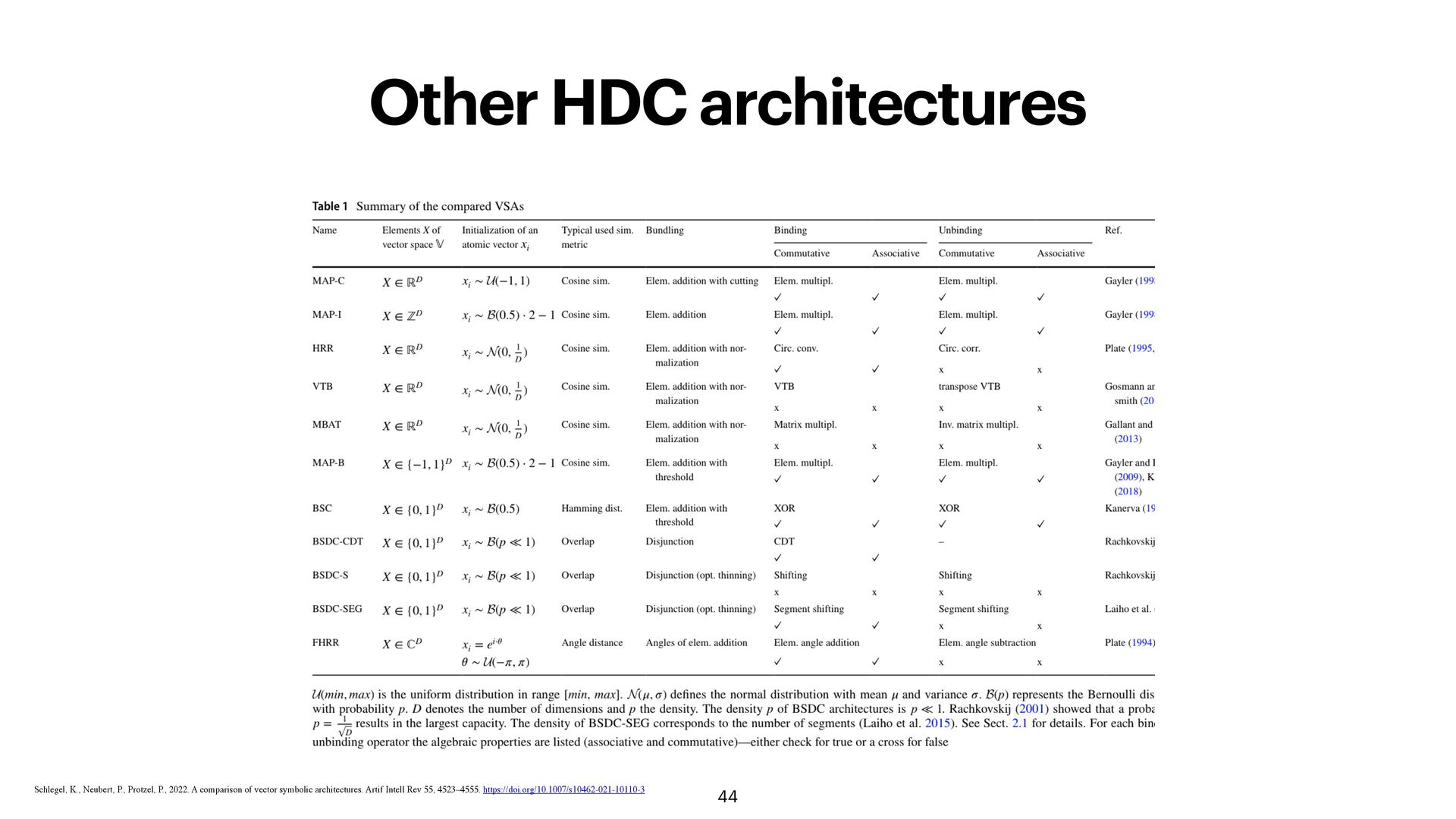
much of AI work was focused on connectionist models (Hinton, Hop fi eld, etc.) where the challenge was setting weights. •A different group focused on representations (how does the brain represent concepts without symbols?) •Pioneers: •Paul Smolensky (1990): Tensor Product Representations •Tony Plate (1995): Holographic Reduced Representations •Pentti Kanerva (1988/2009): Sparse Distributed Memory & HDC Family of methods also of Vector Symbolic Architectures (VSA)
• toy model of the mind • meaning/information from randomness • As AI/bioinformatics practitioners • low-energy/low-resource AI • compositional & reasoning on complex structures 13
McCoy, R. Fernandez, M. Goldrick, and J. Gao, “Neurocompositional computing: from the central paradox of cognition to a new generation of AI systems,” AI Magazine, vol. 43, no. 3, pp. 308–322, 2022, doi: 10.1002/aaai.12065. symbolic compositional computing encodes concepts via symbols and works via the composition principle neural computation encodes concepts via vectors and works via the continuity principle allows learning by gradients
hypervectors (“merely” atoms in the universe) 2 × 103010 1080 hypervector: very big (ca. 10,000 dimensions) randomly- generated binary vector Often binary (0/1) or bipolar (-1/1), but can also be real, graded, or even complex.
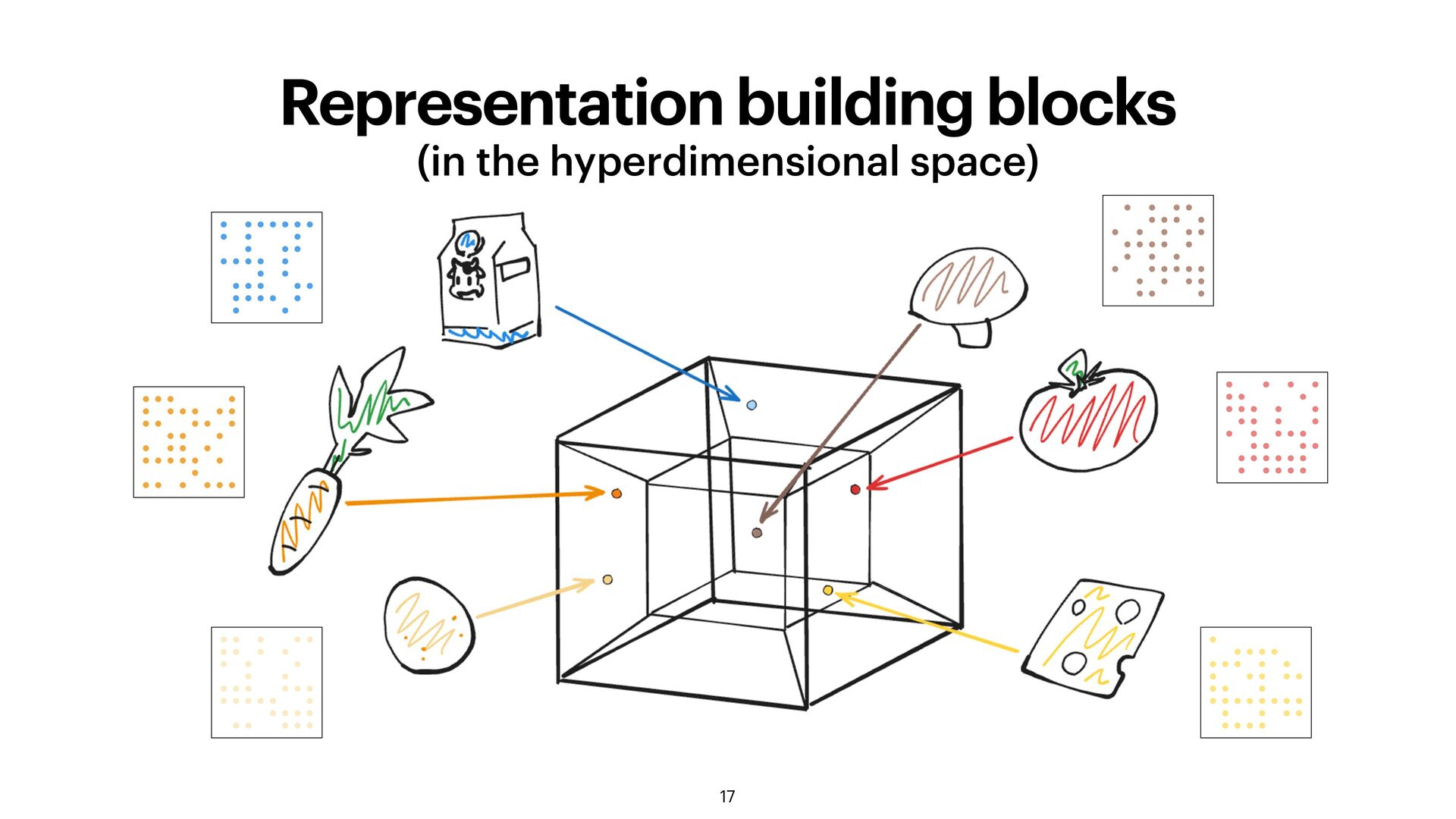
the building blocks for your concepts (letters, symbols, atoms…) type of the elements does not matter too much Clever idea: use a hash of the object as a seed for vector generation!
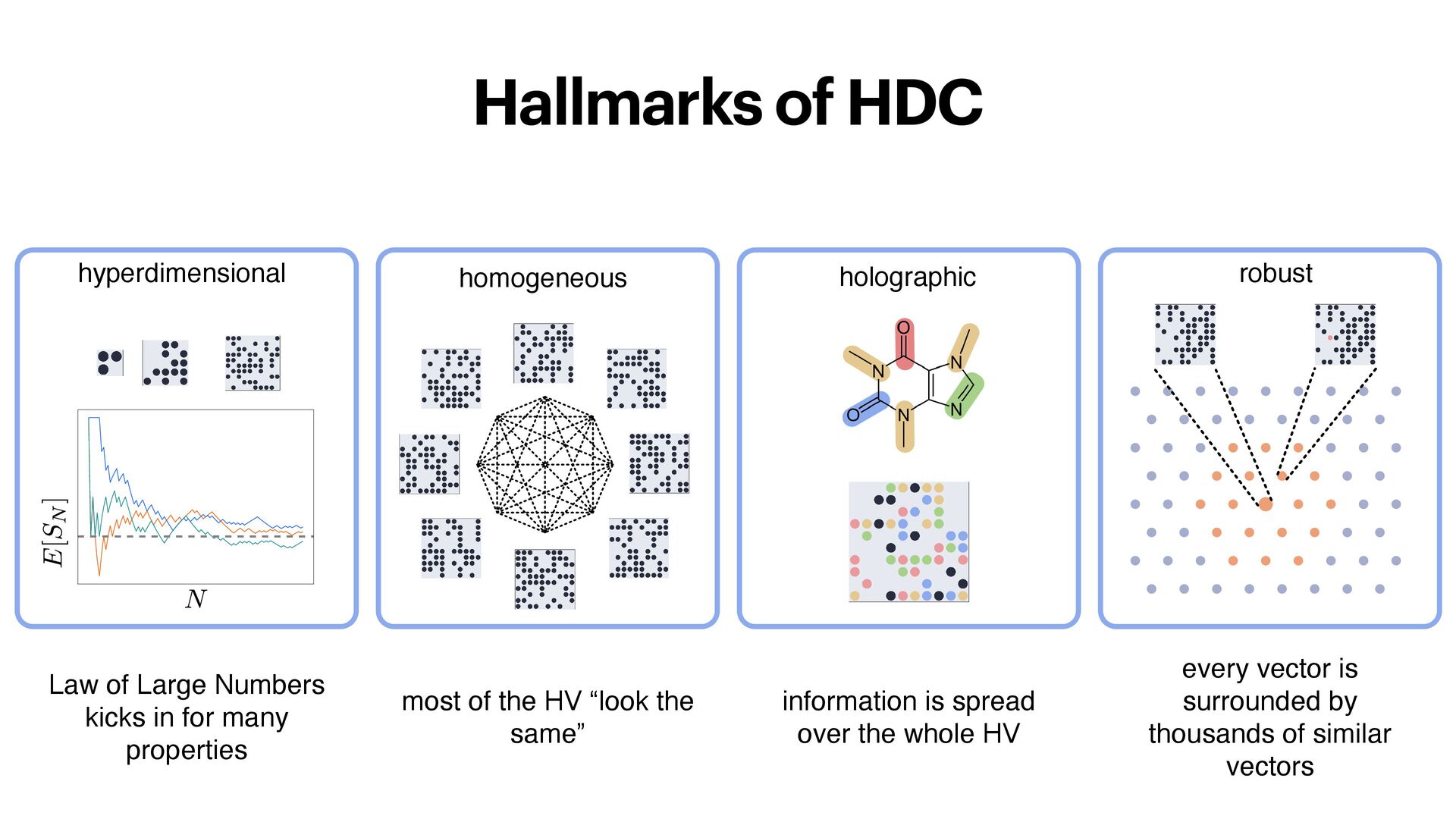
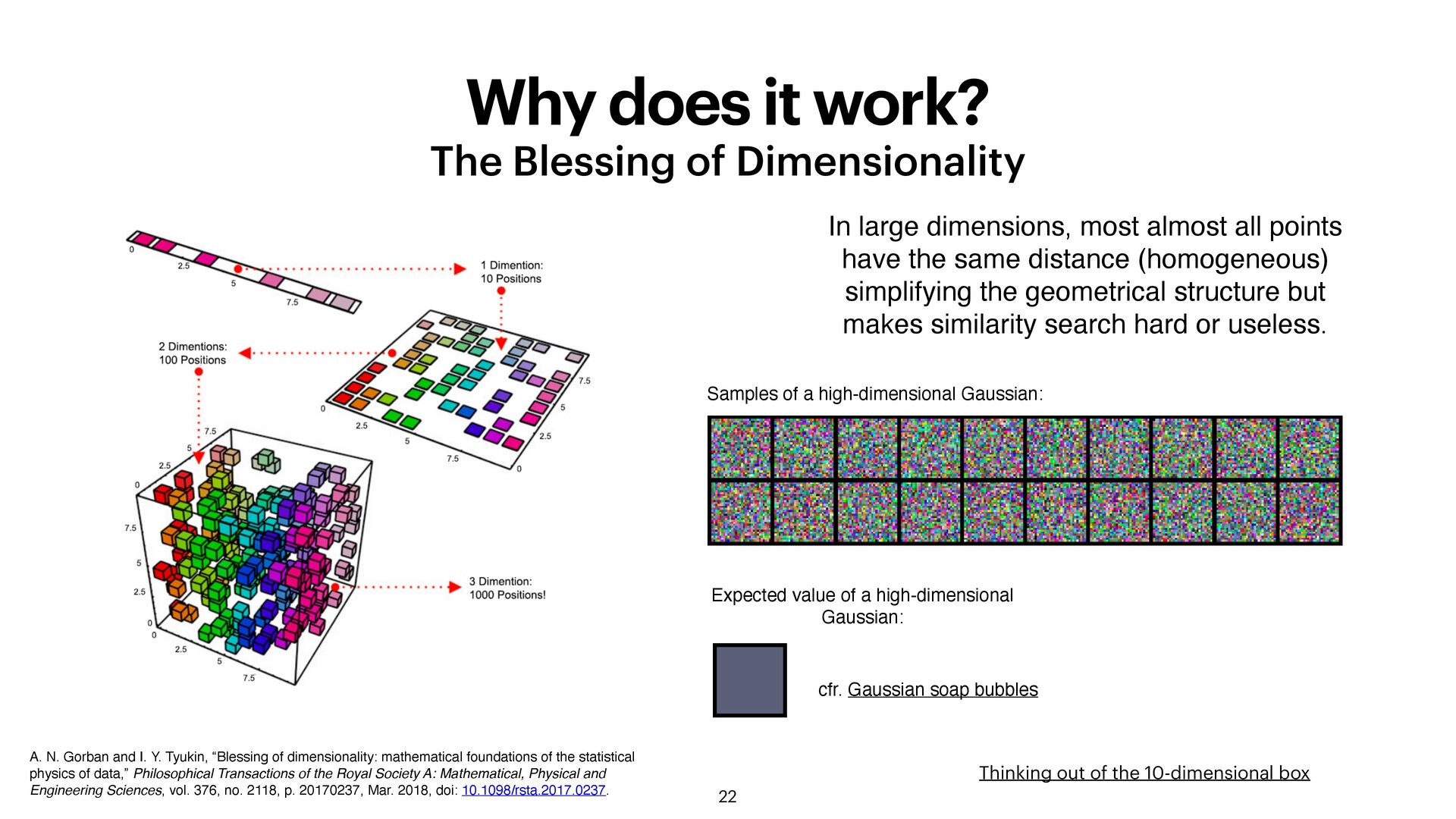
for many properties homogeneous most of the HV “look the same” holographic information is spread over the whole HV robust every vector is surrounded by thousands of similar vectors
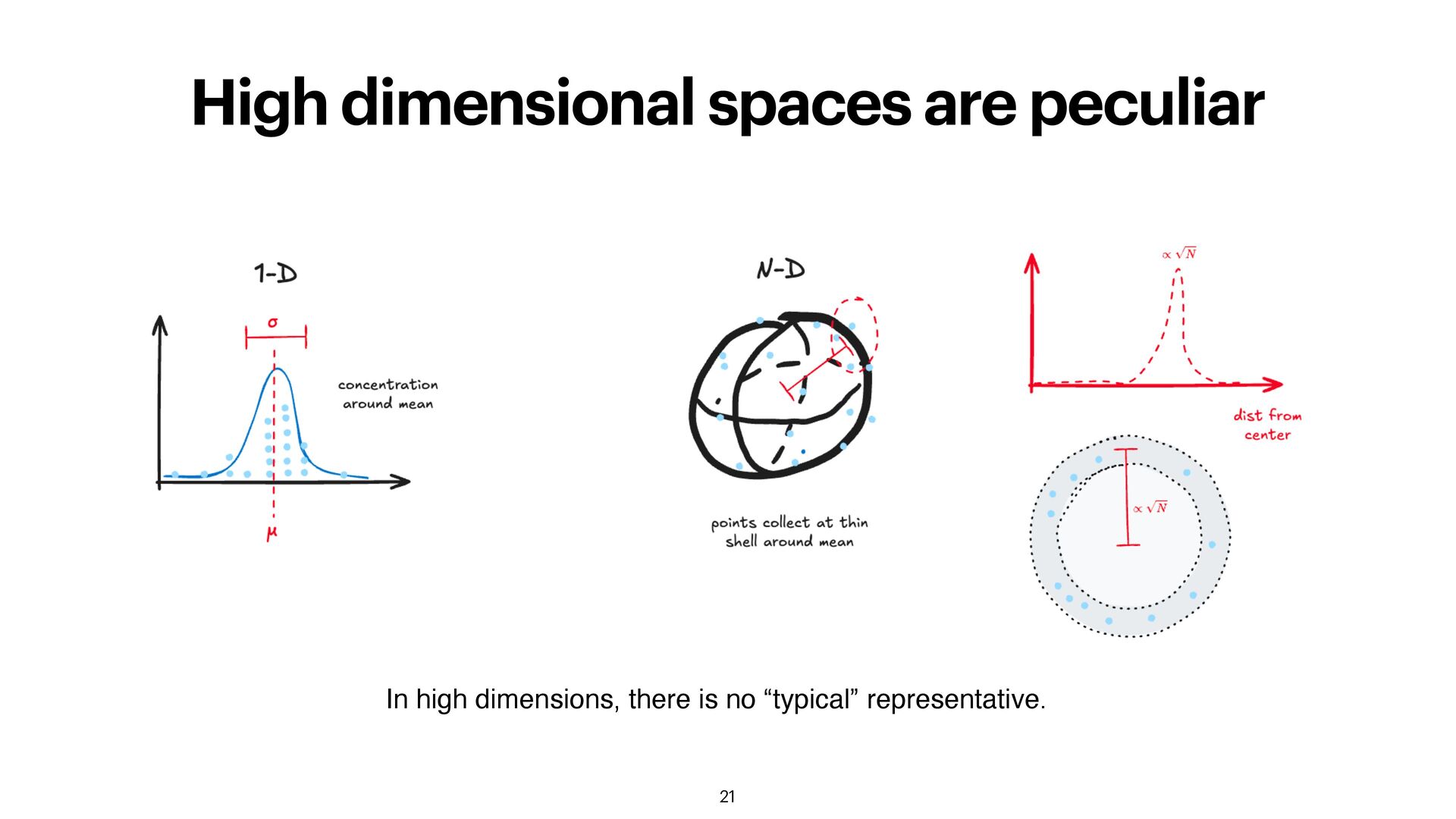
N. Gorban and I. Y. Tyukin, “Blessing of dimensionality: mathematical foundations of the statistical physics of data,” Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 376, no. 2118, p. 20170237, Mar. 2018, doi: 10.1098/rsta.2017.0237. In large dimensions, most almost all points have the same distance (homogeneous) simplifying the geometrical structure but makes similarity search hard or useless. Samples of a high-dimensional Gaussian: Expected value of a high-dimensional Gaussian: cfr. Gaussian soap bubbles Thinking out of the 10-dimensional box
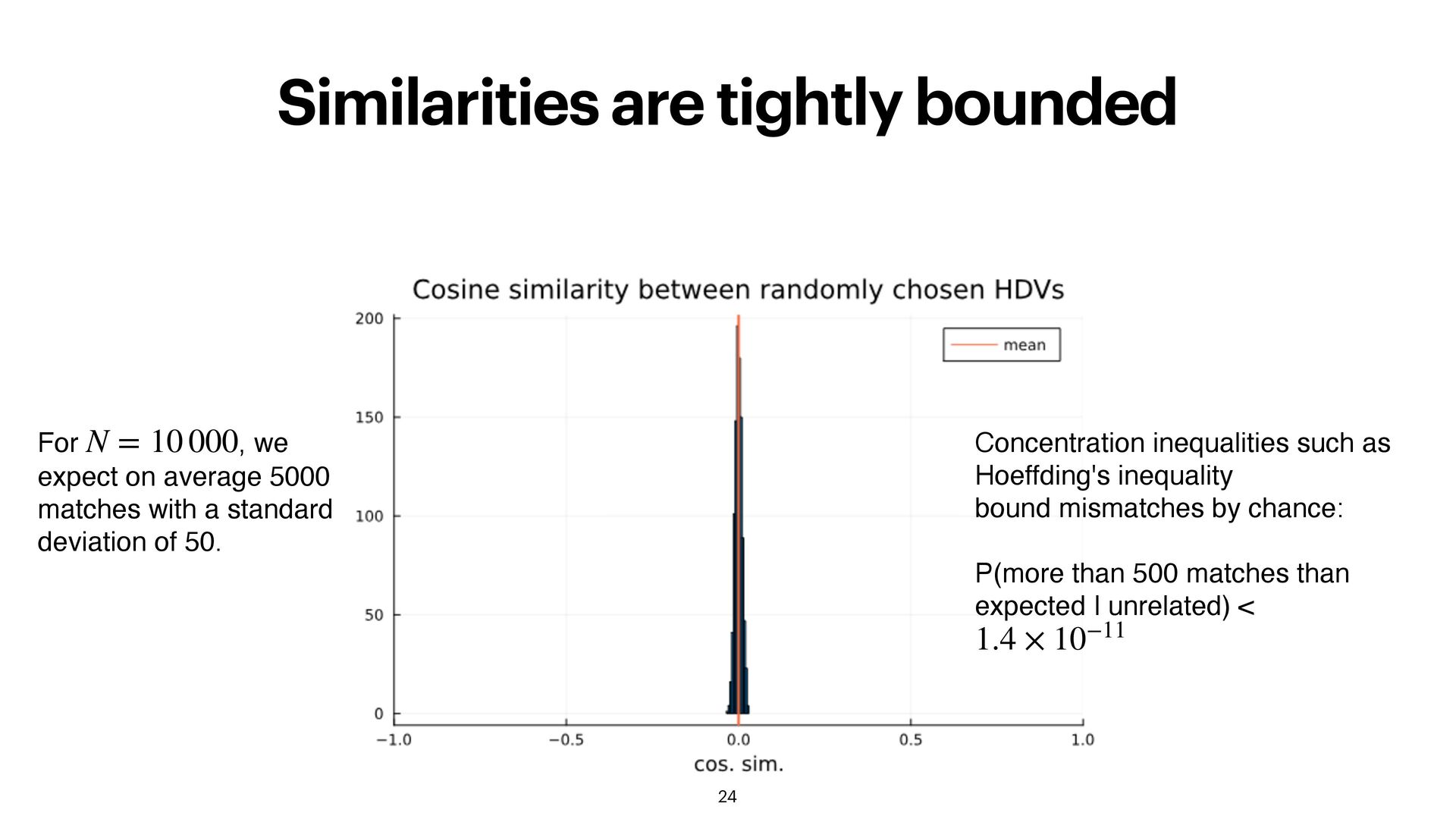
average 5000 matches with a standard deviation of 50. N = 10 000 Concentration inequalities such as Hoeffding's inequality bound mismatches by chance: P(more than 500 matches than expected | unrelated) < 1.4 × 10−11
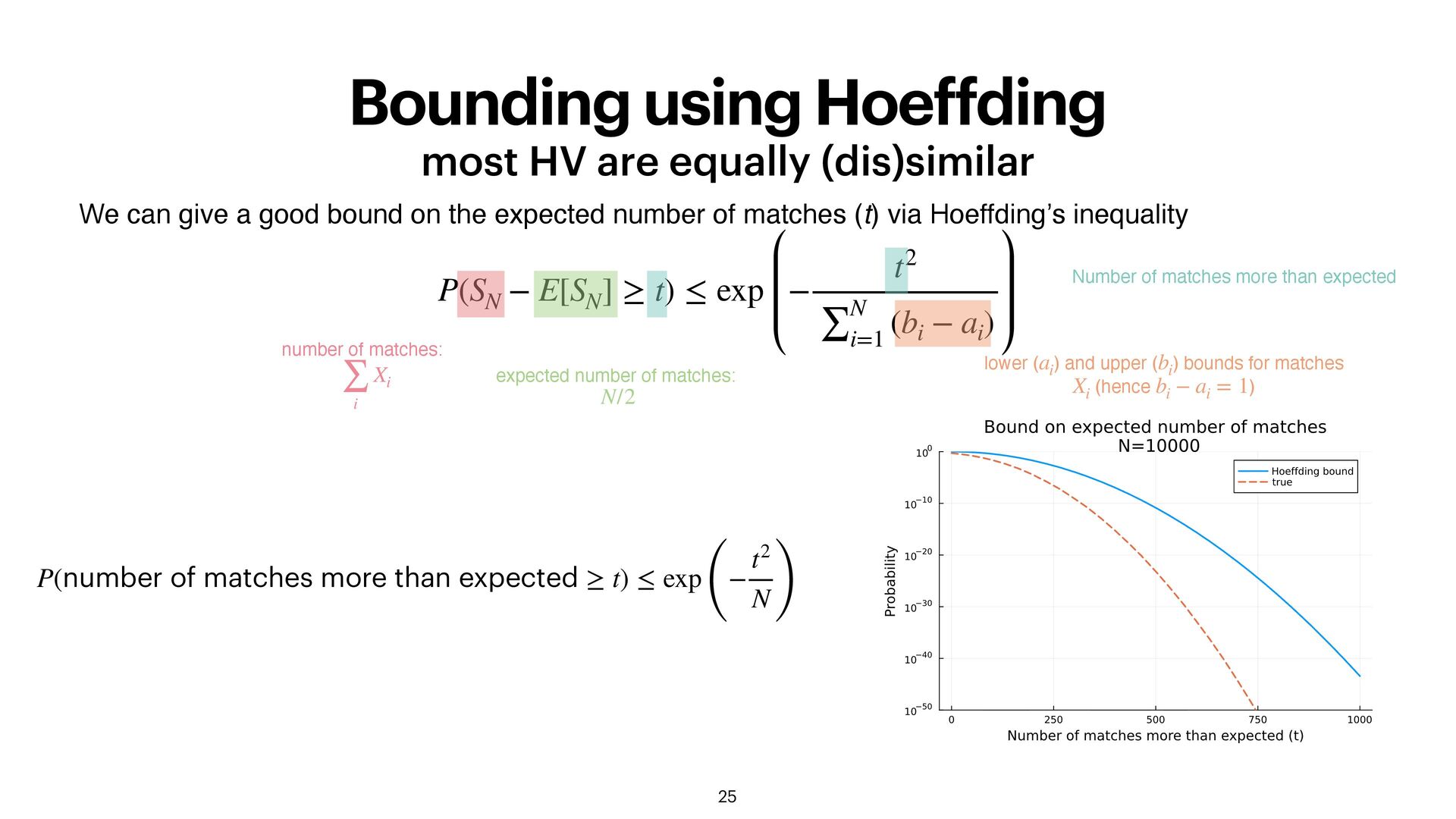
can give a good bound on the expected number of matches (t) via Hoeffding’s inequality P(SN − E[SN ] ≥ t) ≤ exp − t2 ∑N i=1 (bi − ai ) number of matches: ∑ i Xi expected number of matches: N/2 Number of matches more than expected lower ( ) and upper ( ) bounds for matches (hence ) ai bi Xi bi − ai = 1 P(number of matches more than expected ≥ t) ≤ exp ( − t2 N )
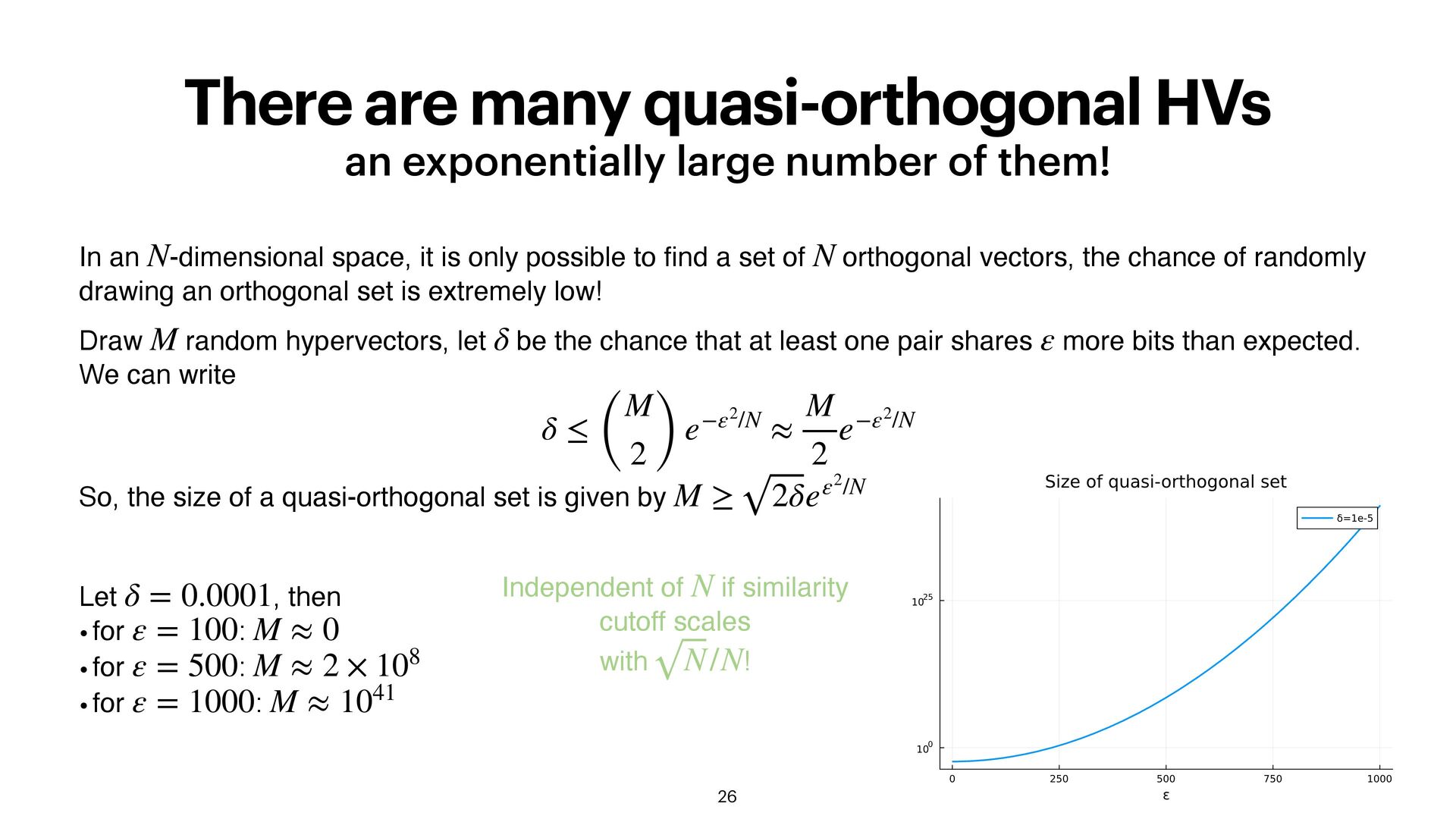
them! 26 Draw random hypervectors, let be the chance that at least one pair shares more bits than expected. We can write So, the size of a quasi-orthogonal set is given by M δ ε δ ≤ ( M 2 ) e−ε2/N ≈ M 2 e−ε2/N M ≥ 2δeε2/N In an -dimensional space, it is only possible to fi nd a set of orthogonal vectors, the chance of randomly drawing an orthogonal set is extremely low! N N Let , then • for : • for : • for : δ = 0.0001 ε = 100 M ≈ 0 ε = 500 M ≈ 2 × 108 ε = 1000 M ≈ 1041 Independent of if similarity cutoff scales with ! N N/N
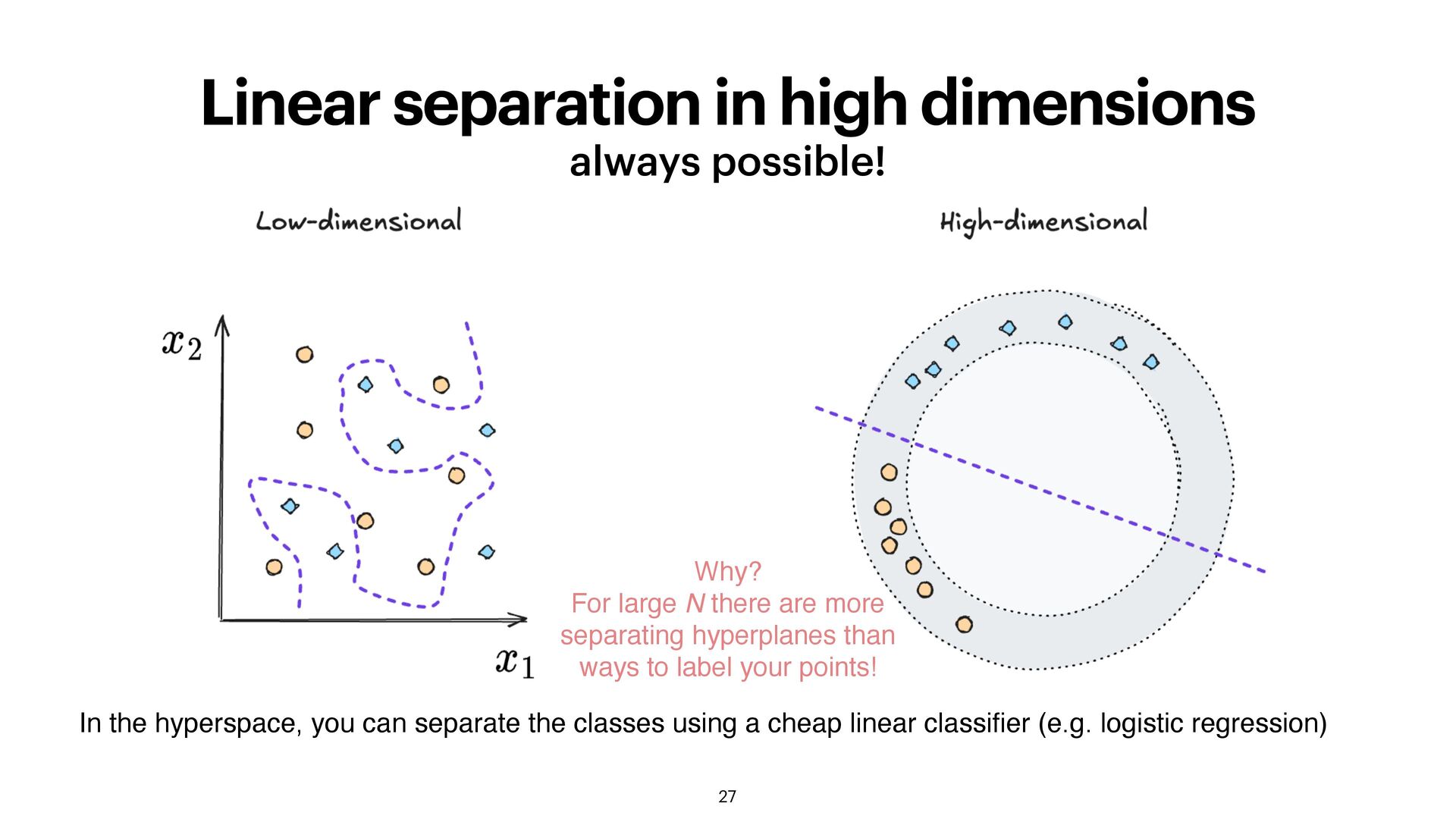
hyperspace, you can separate the classes using a cheap linear classi fi er (e.g. logistic regression) Why? For large N there are more separating hyperplanes than ways to label your points!
similar vectors Give a vector representing a concept. It will share 10000 elements with itself. Flip 40% of its elements: it will now share only 6000 elements with itself. It is still within the closest % of the closest vectors to the original concept! 10−42
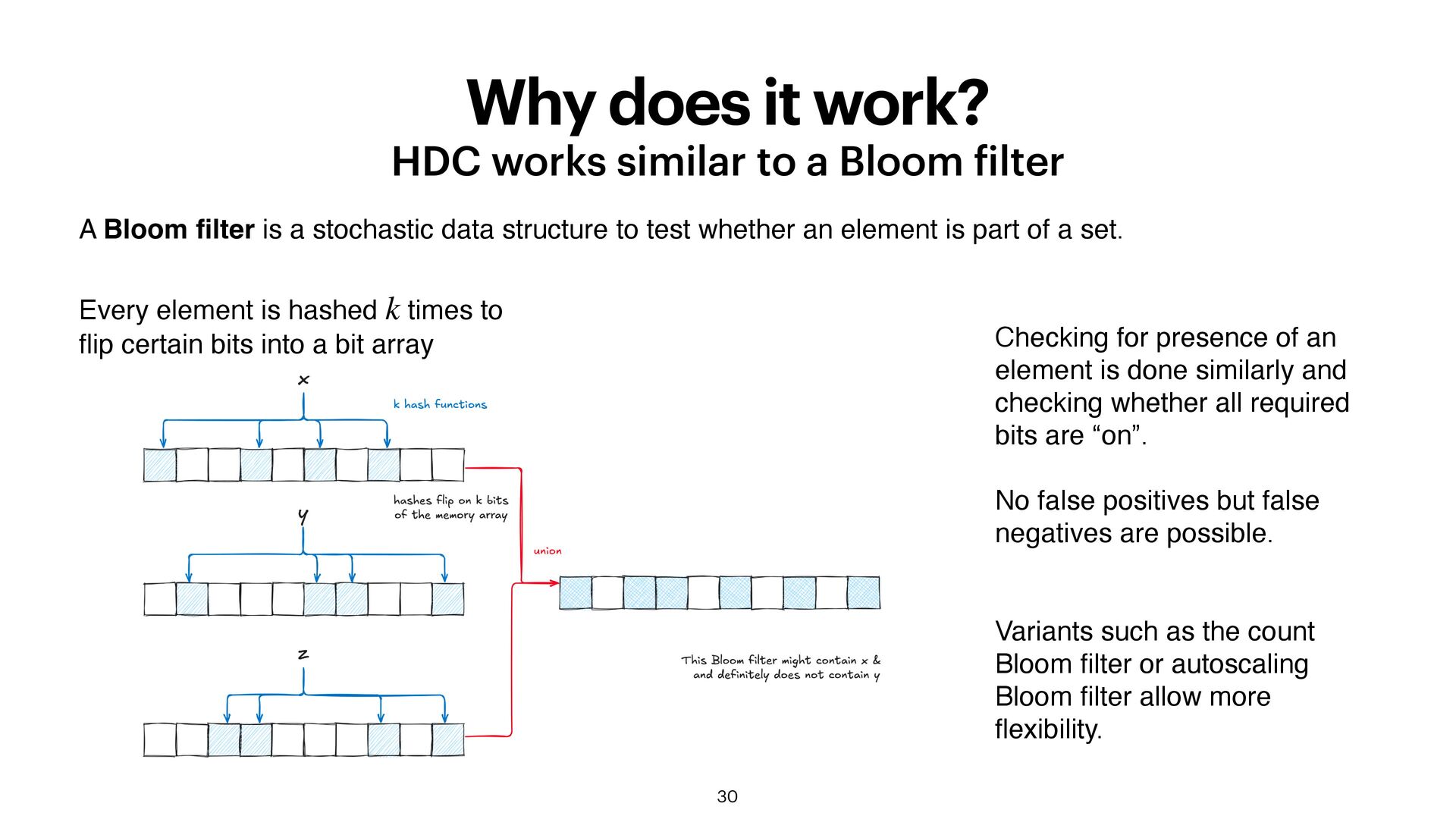
f ilter 30 A Bloom fi lter is a stochastic data structure to test whether an element is part of a set. Every element is hashed times to fl ip certain bits into a bit array k Checking for presence of an element is done similarly and checking whether all required bits are “on”. No false positives but false negatives are possible. Variants such as the count Bloom fi lter or autoscaling Bloom fi lter allow more fl exibility.
started (ideally live, otherwise via the HTML) • Go at your own pace through the examples and exercises of 2. Theory & Foundations: 1. Low and high dimensions 🧊 2. Hypervectors 🎲 3. Holographic property 👽 4. Robustness 🪨 5. Example: amino acids 🥩 • Make sure to do the 2.2 Hypervectors part; the remainder of the exercises will build upon it! 31
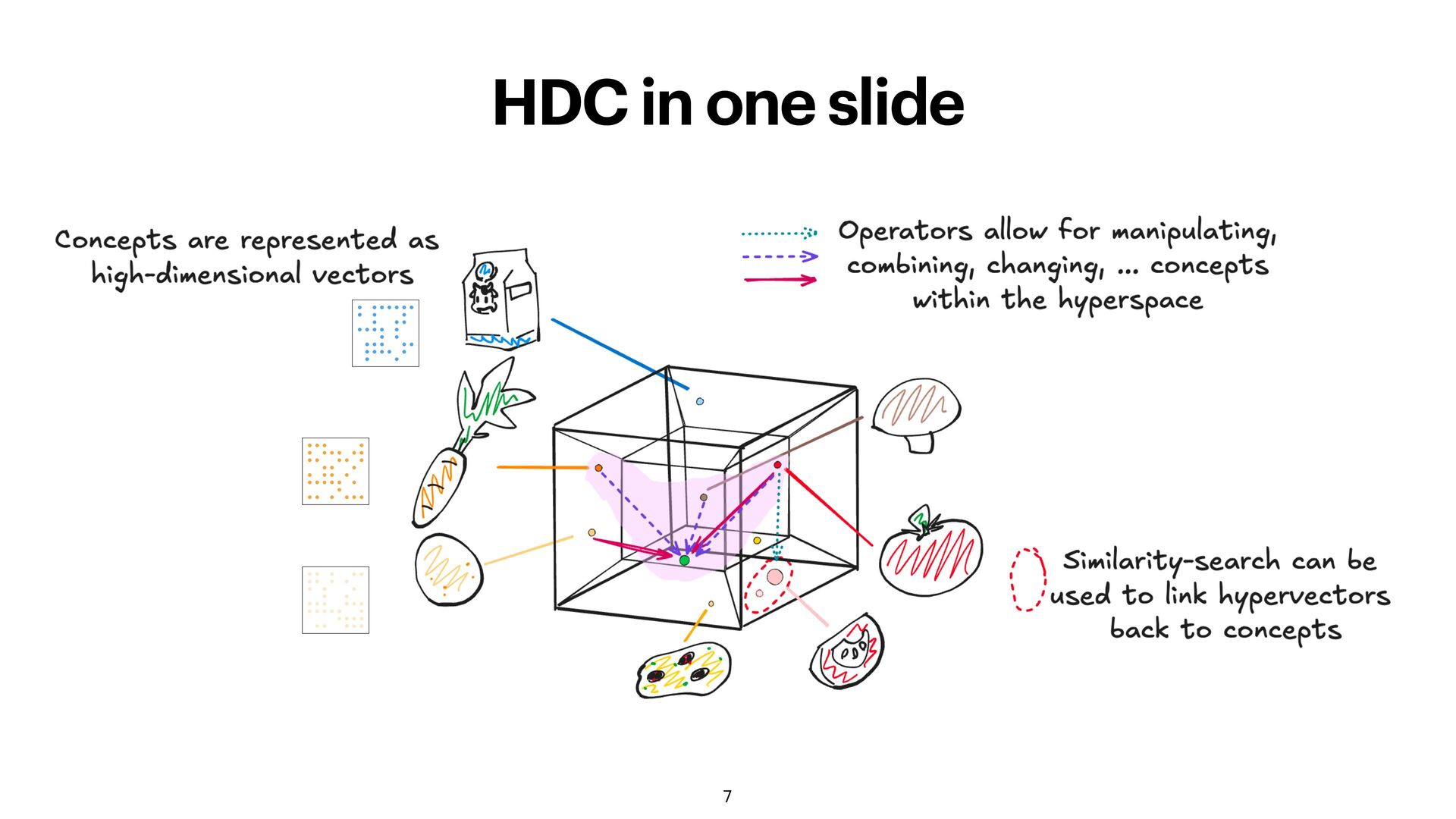
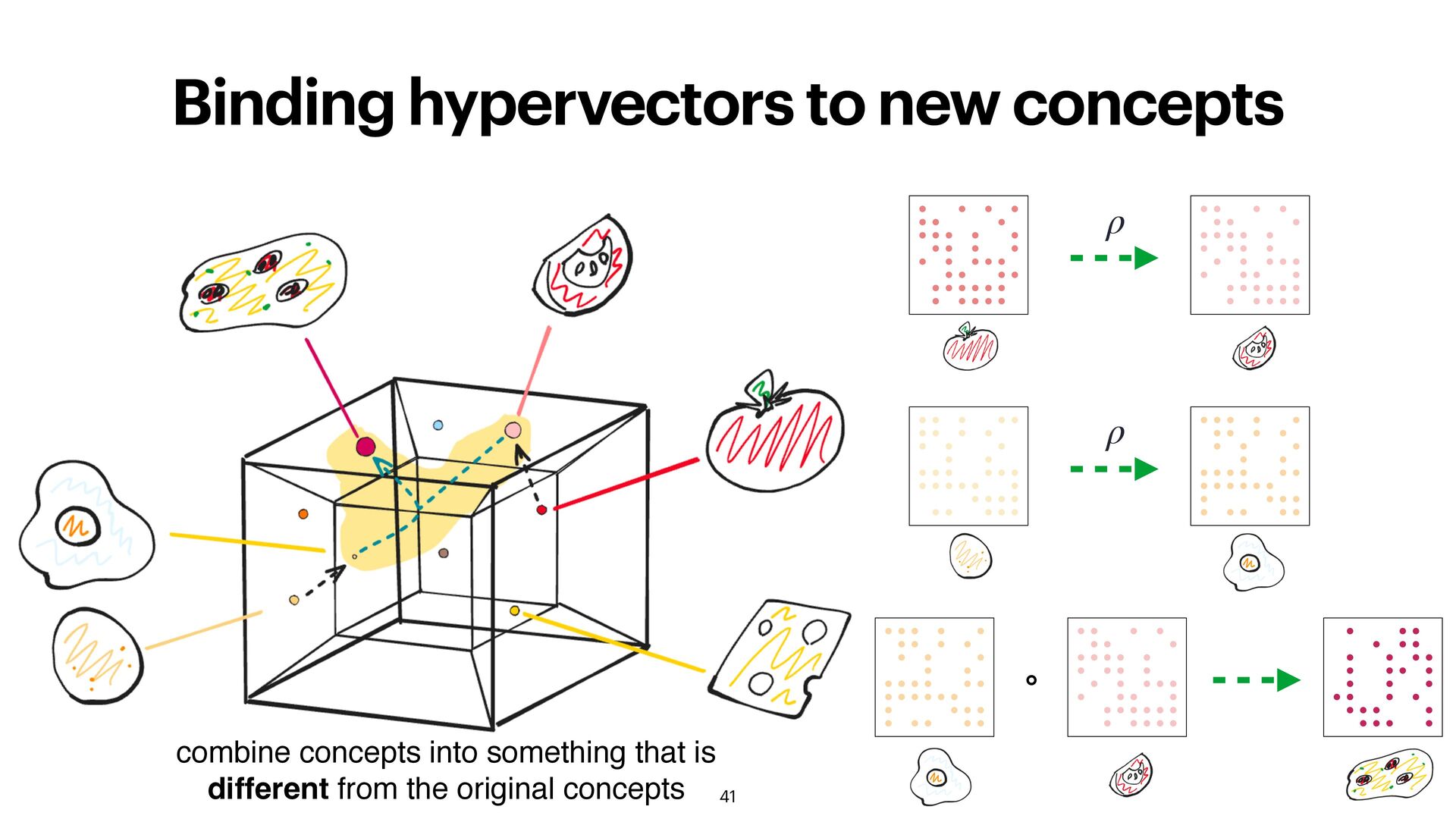
way to generate new unrelated concepts (random vectors) • a way to compare two vectors if they are related What is missing: • combining multiple HVs into a new, overacting concept • turning one or multiple HVs into a new, independent concept 34
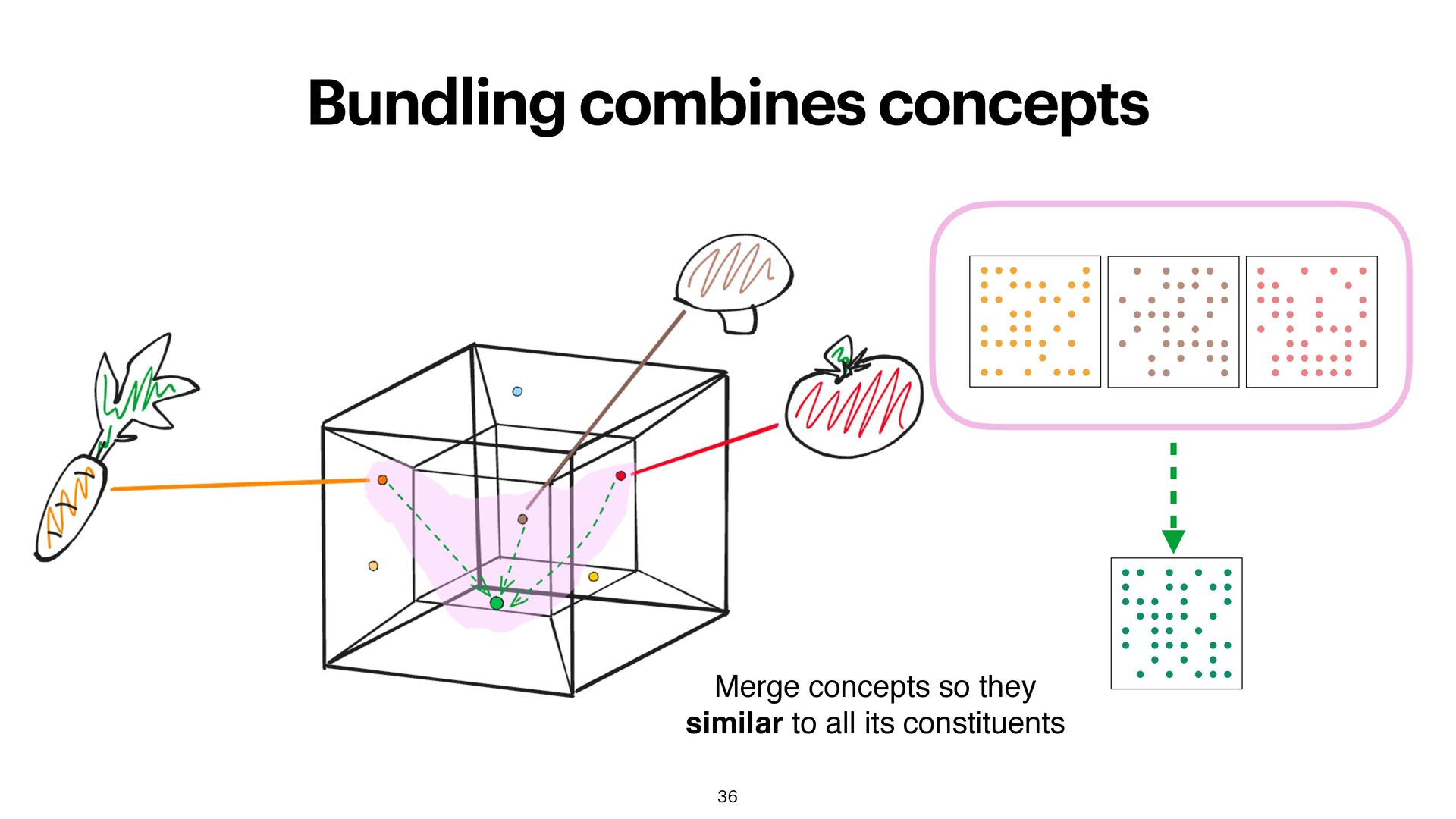
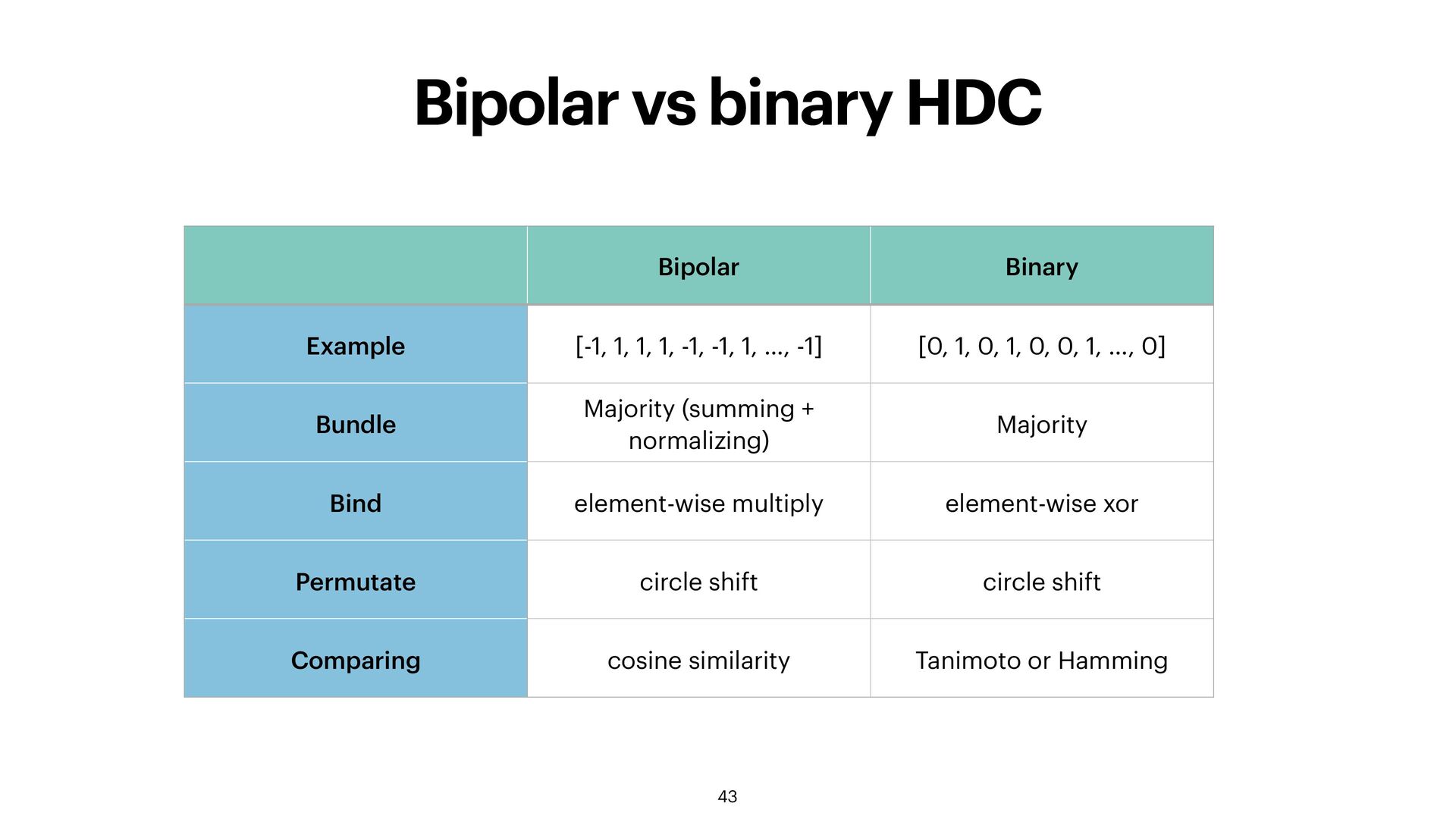
bipolar vectors! • Adding vectors without normalizing (thresholding) retains information on the relative importance of the elements and the number of elements that were combined. • Possibility of weighting concepts • Usually, it's best to normalize to compare sets of di ff erent sizes • Zero as neutral element (no longer bipolar!) 37
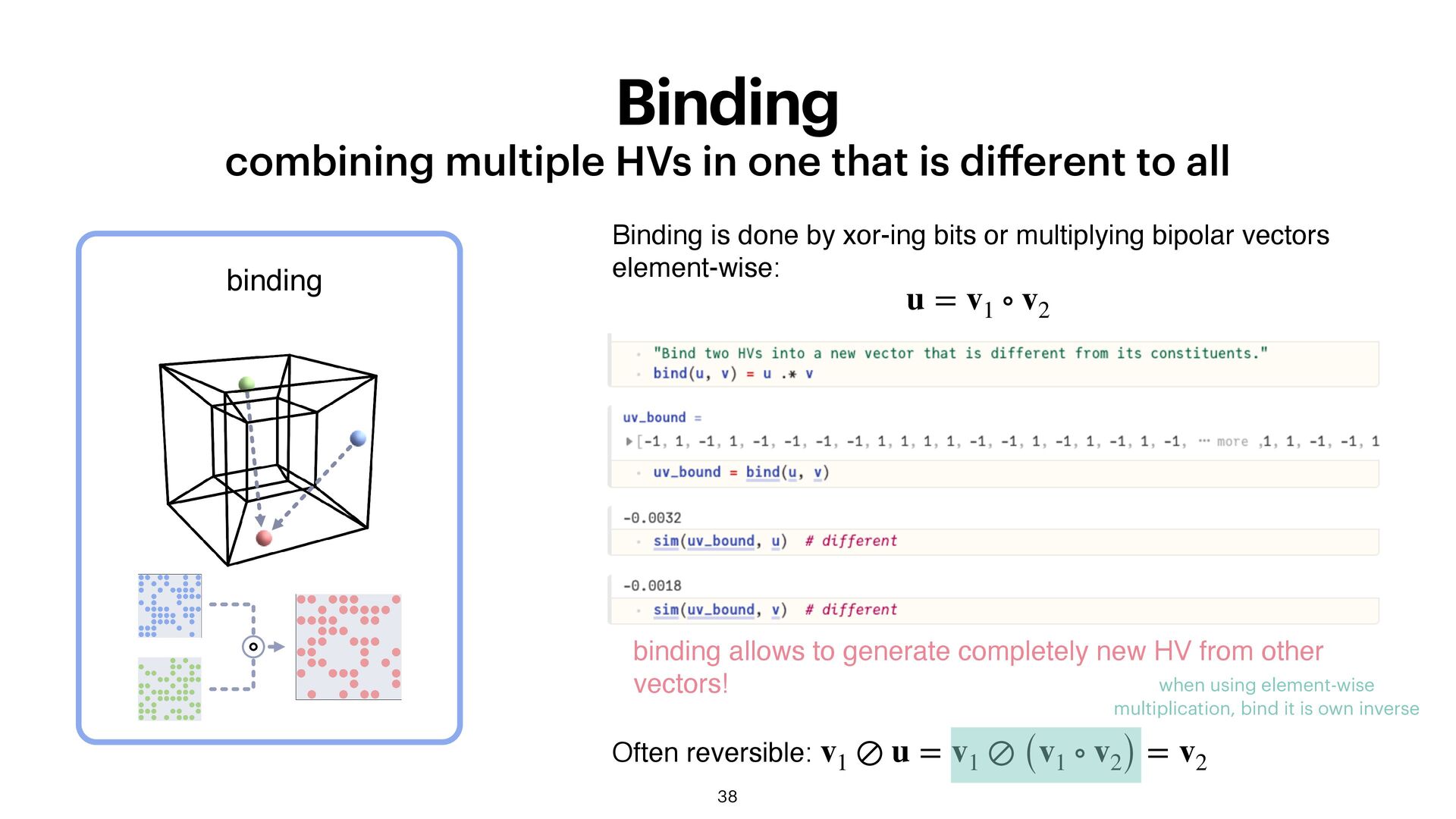
erent to all 38 Binding is done by xor-ing bits or multiplying bipolar vectors element-wise: u = v1 ∘ v2 binding binding allows to generate completely new HV from other vectors! Often reversible: v1 ⊘ u = v1 ⊘ (v1 ∘ v2) = v2 when using element-wise multiplication, bind it is own inverse
into a new embedding without them leaking is hard! For example composition of an image [1] K. Greff, S. van Steenkiste, and J. Schmidhuber, “On the binding problem in arti fi cial neural networks.” arXiv, Dec. 09, 2020. doi: 10.48550/arXiv.2012.05208. result of me generating an image of a fox and rabbit on my GPU to illustrate Lotka-Volterra equations Fundamental problem of neural embeddings! Binding operator solves this elegantly!
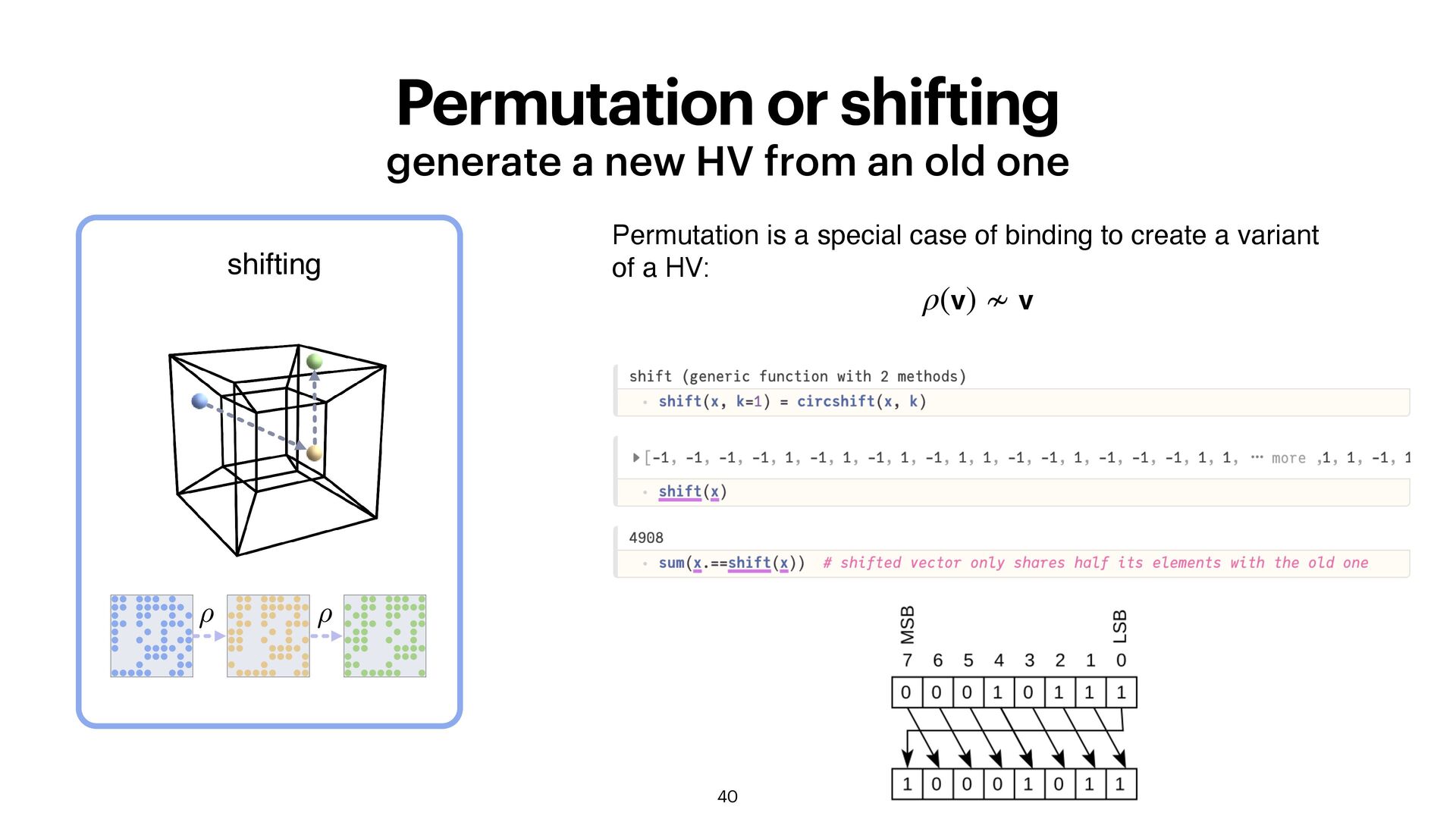
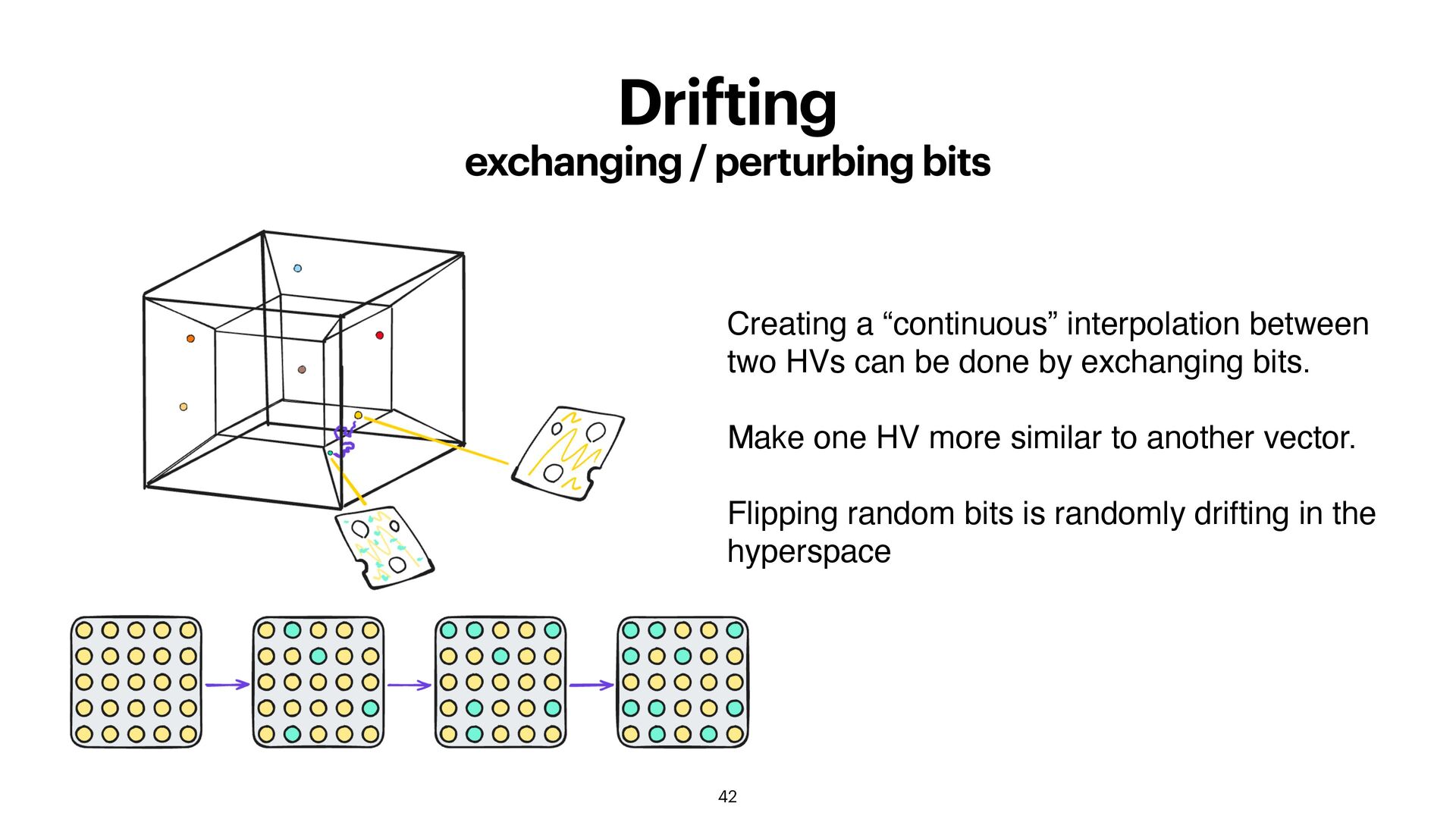
between two HVs can be done by exchanging bits. Make one HV more similar to another vector. Flipping random bits is randomly drifting in the hyperspace
building a learning system! Suppose we have a bunch of key-value pairs. We can bind each key ( ) to its corresponding value ( ) and bundle all pairs into a single HV: ui vi h = [u1 ∘ v1 + … + un ∘ vn ] Inference: ui ⊘ h ≈ [ui ∘ u1 ∘ v1 + … + ui ∘ un ∘ vn ] = [vi + noise] ≈ vi Most schemes of HDC are more advanced versions of this simple procedure! ui ∘ uj = noise (i ≠ j) ui ∘ ui = 1
by name (NAM), capital (CAP) and currency (MON) • USTATES = [(COUNTRY ◦ USA) + (CAPITAL ◦ WDC) + (MONEY ◦ DOL)] • MEXICO = [(COUNTRY ◦ MEX) + (CAPITAL ◦ MXC) + (MONEY ◦ PES)] • Dollar of Mexico? • DOL ◦ (USTATES ◦ MEXICO) ≈ PES 46 Kanerva, P., n.d. What We Mean When We Say “What’s the Dollar of Mexico?:” Prototypes and Mapping in Concept Space. links each of the corresponding concepts (USA - MEX, WDC - MXC, DOL - PES)
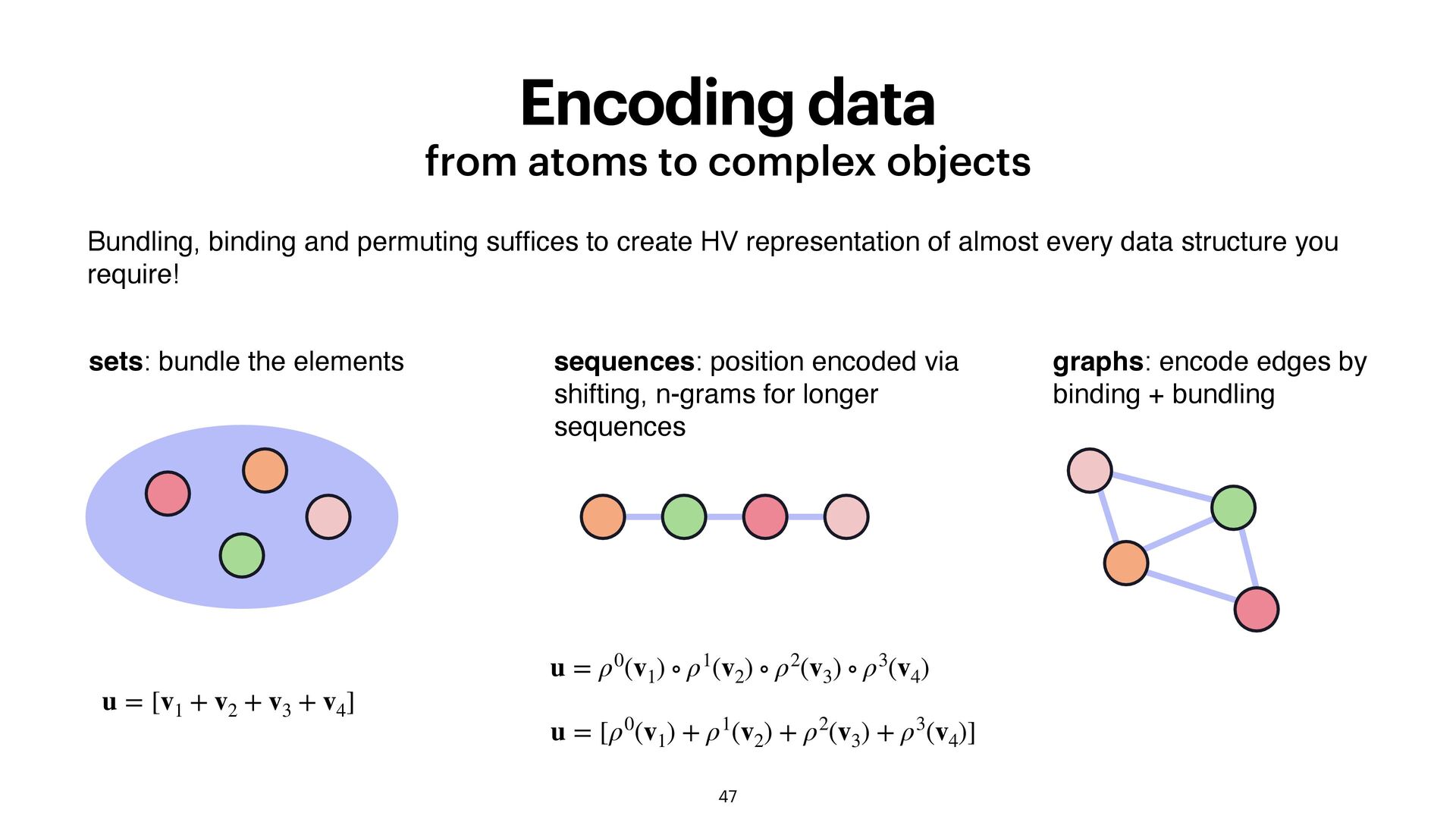
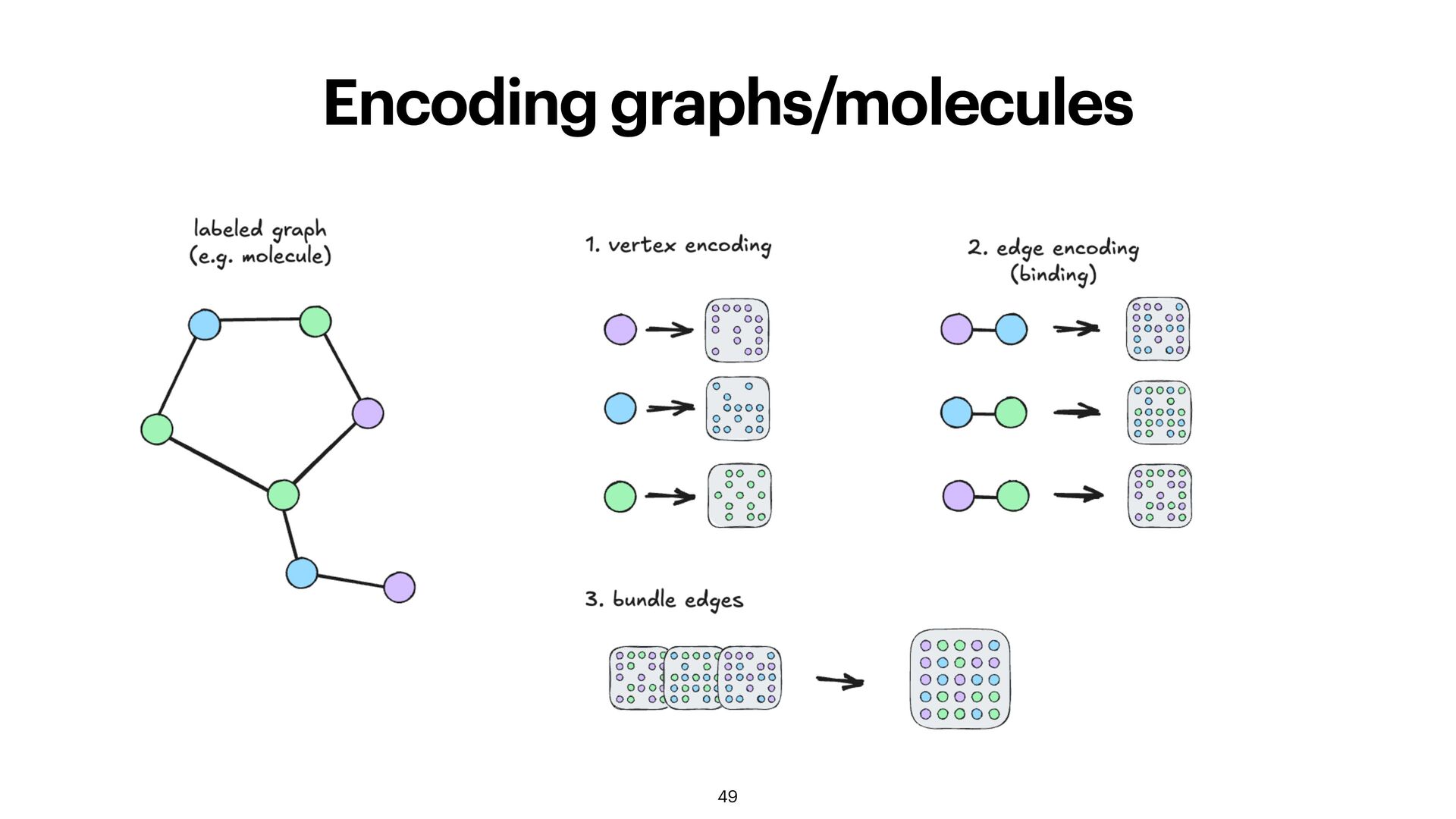
and permuting suf fi ces to create HV representation of almost every data structure you require! sets: bundle the elements u = [v1 + v2 + v3 + v4 ] graphs: encode edges by binding + bundling sequences: position encoded via shifting, n-grams for longer sequences u = ρ0(v1 ) ∘ ρ1(v2 ) ∘ ρ2(v3 ) ∘ ρ3(v4 ) u = [ρ0(v1 ) + ρ1(v2 ) + ρ2(v3 ) + ρ3(v4 )]
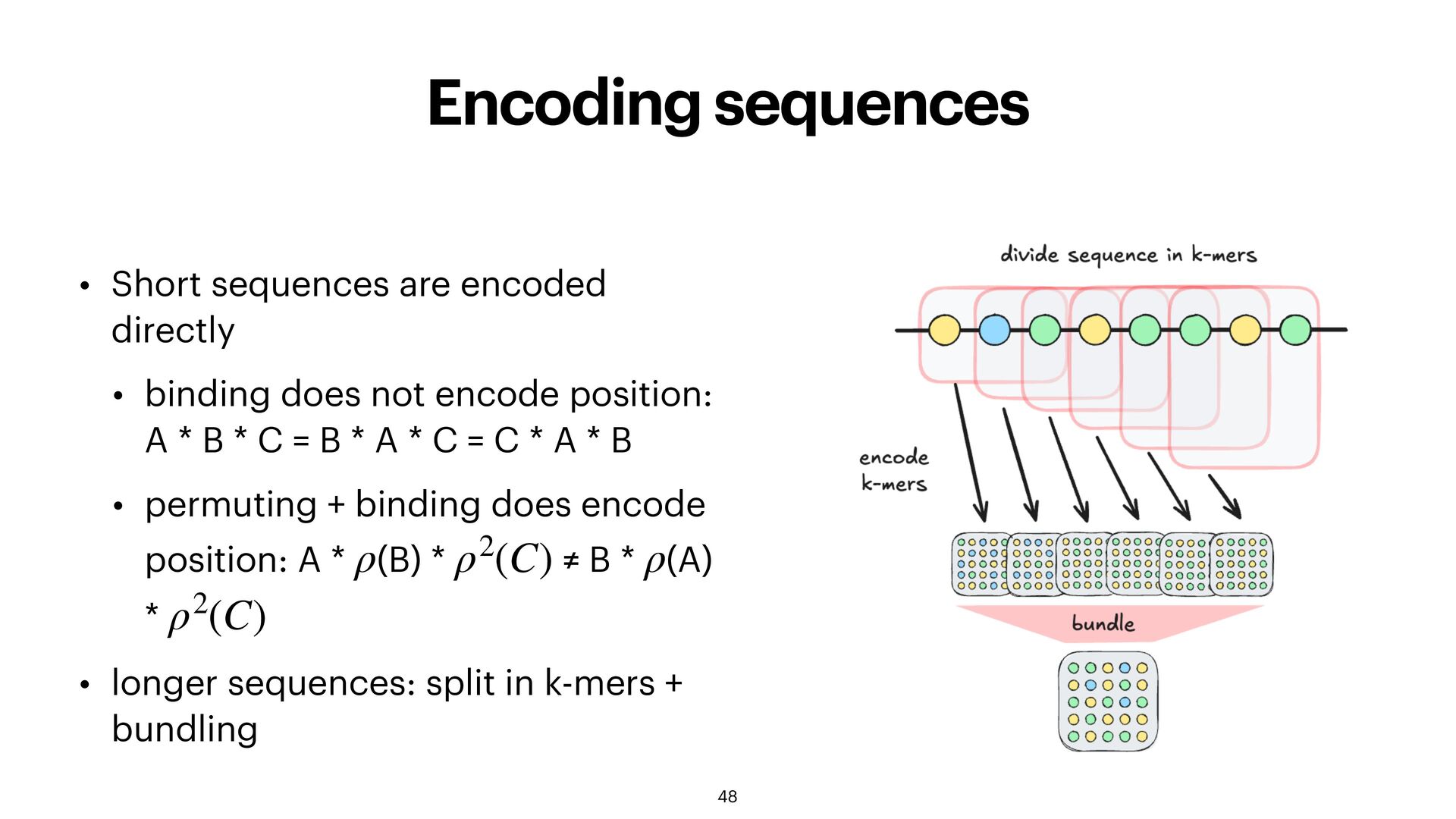
does not encode position: A * B * C = B * A * C = C * A * B • permuting + binding does encode position: A * (B) * ≠ B * (A) * • longer sequences: split in k-mers + bundling ρ ρ2(C) ρ ρ2(C) 48
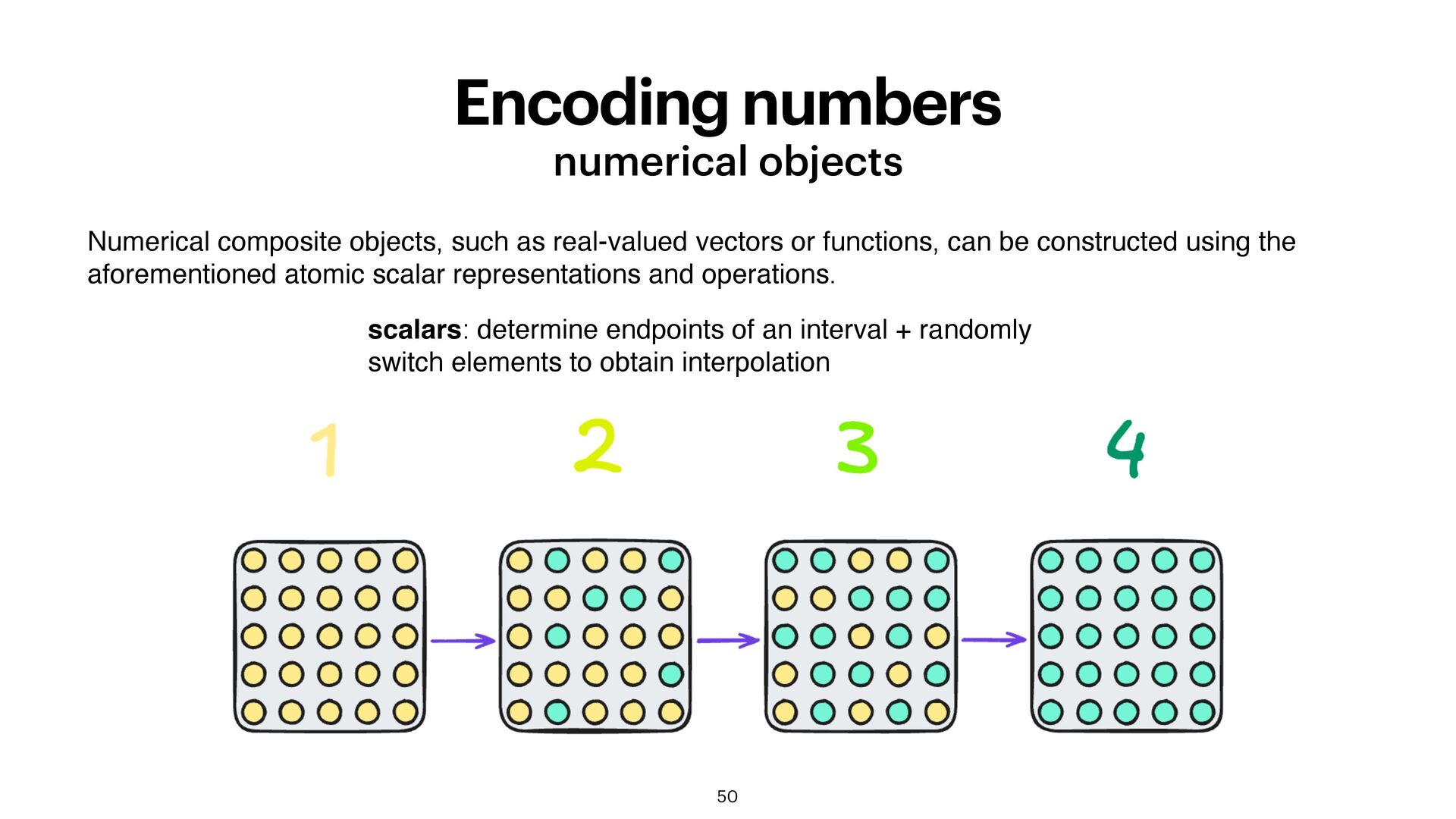
real-valued vectors or functions, can be constructed using the aforementioned atomic scalar representations and operations. scalars: determine endpoints of an interval + randomly switch elements to obtain interpolation
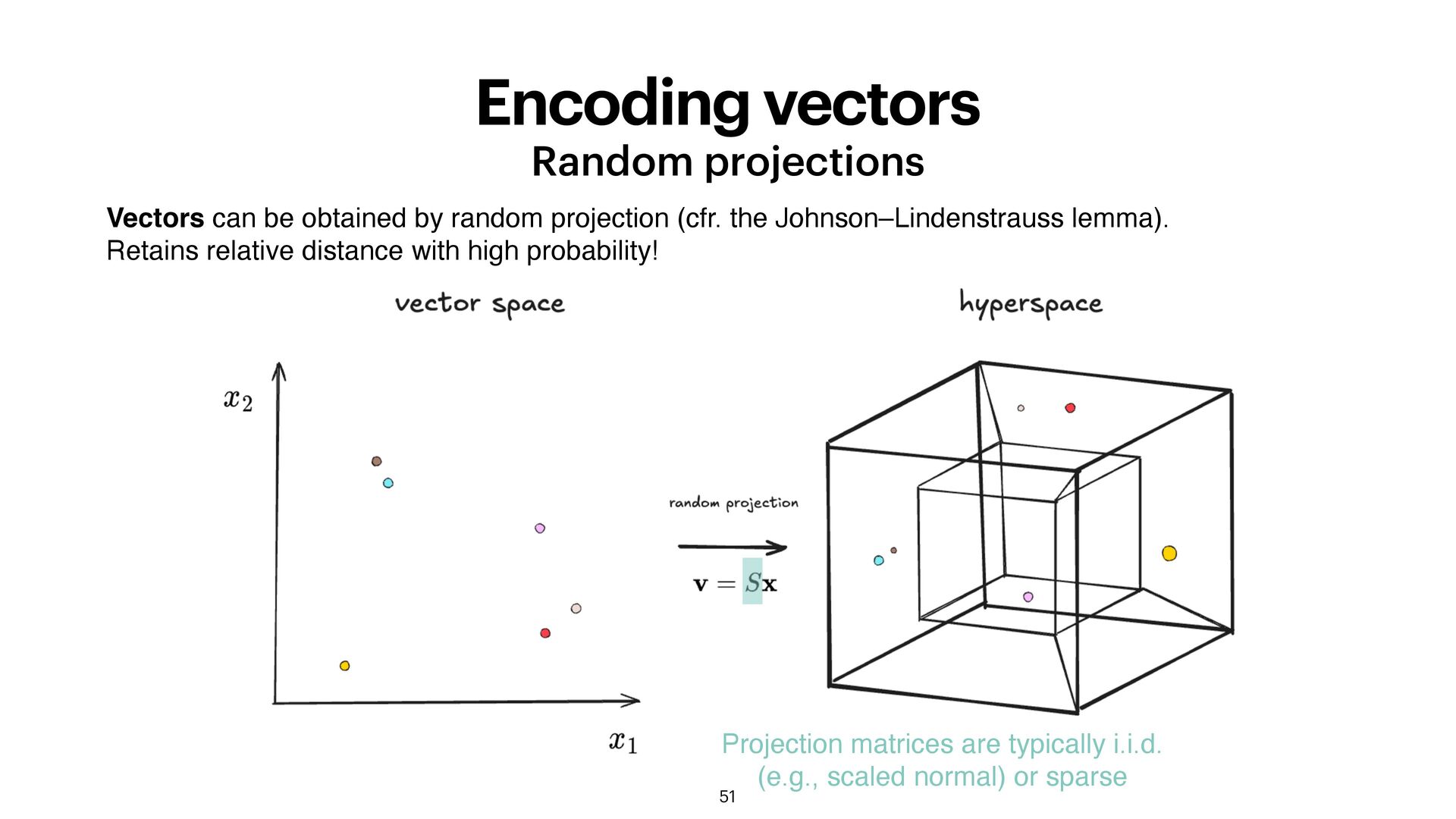
random projection (cfr. the Johnson–Lindenstrauss lemma). Retains relative distance with high probability! Projection matrices are typically i.i.d. (e.g., scaled normal) or sparse
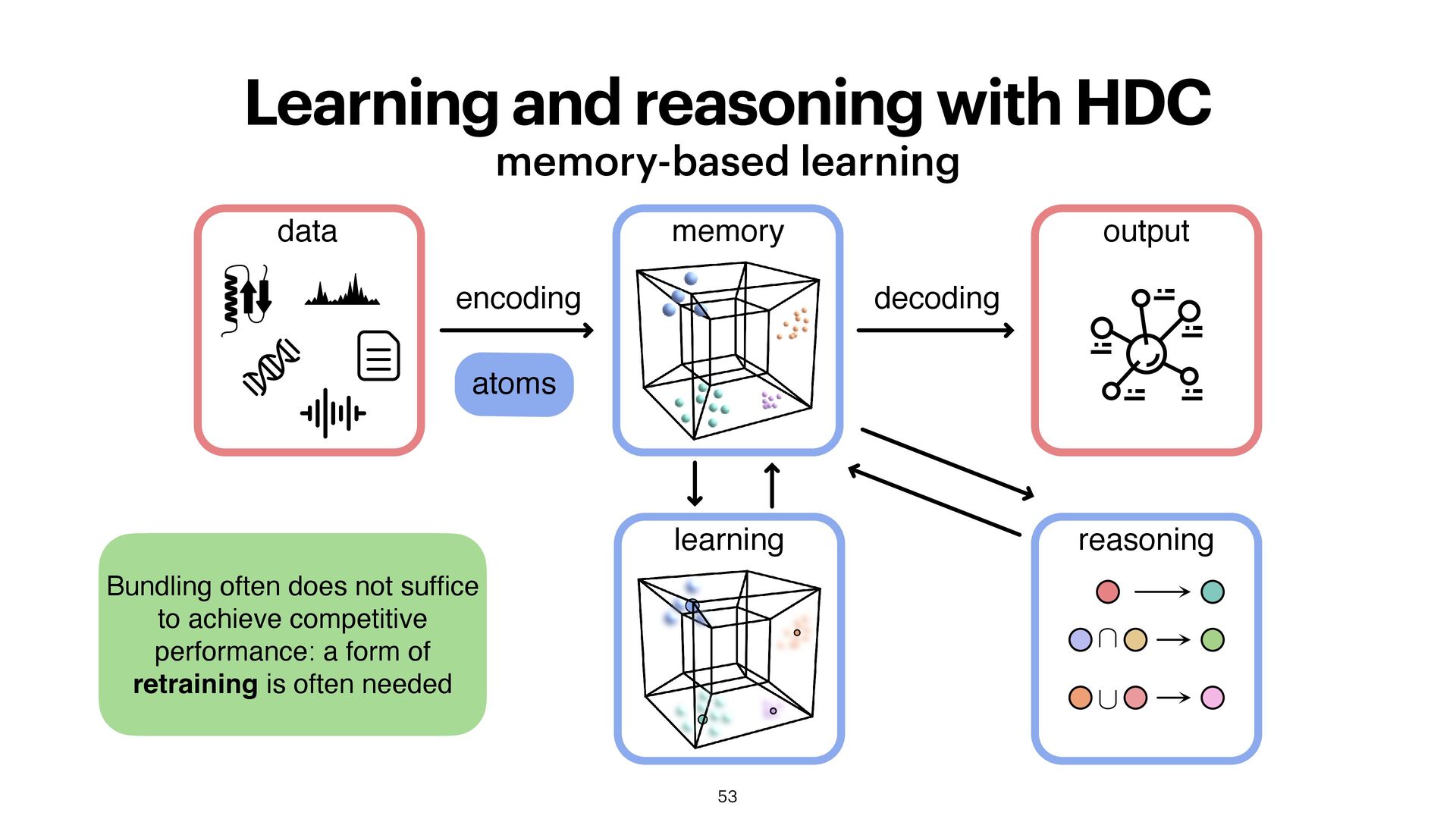
memory output learning reasoning encoding decoding Bundling often does not suf fi ce to achieve competitive performance: a form of retraining is often needed
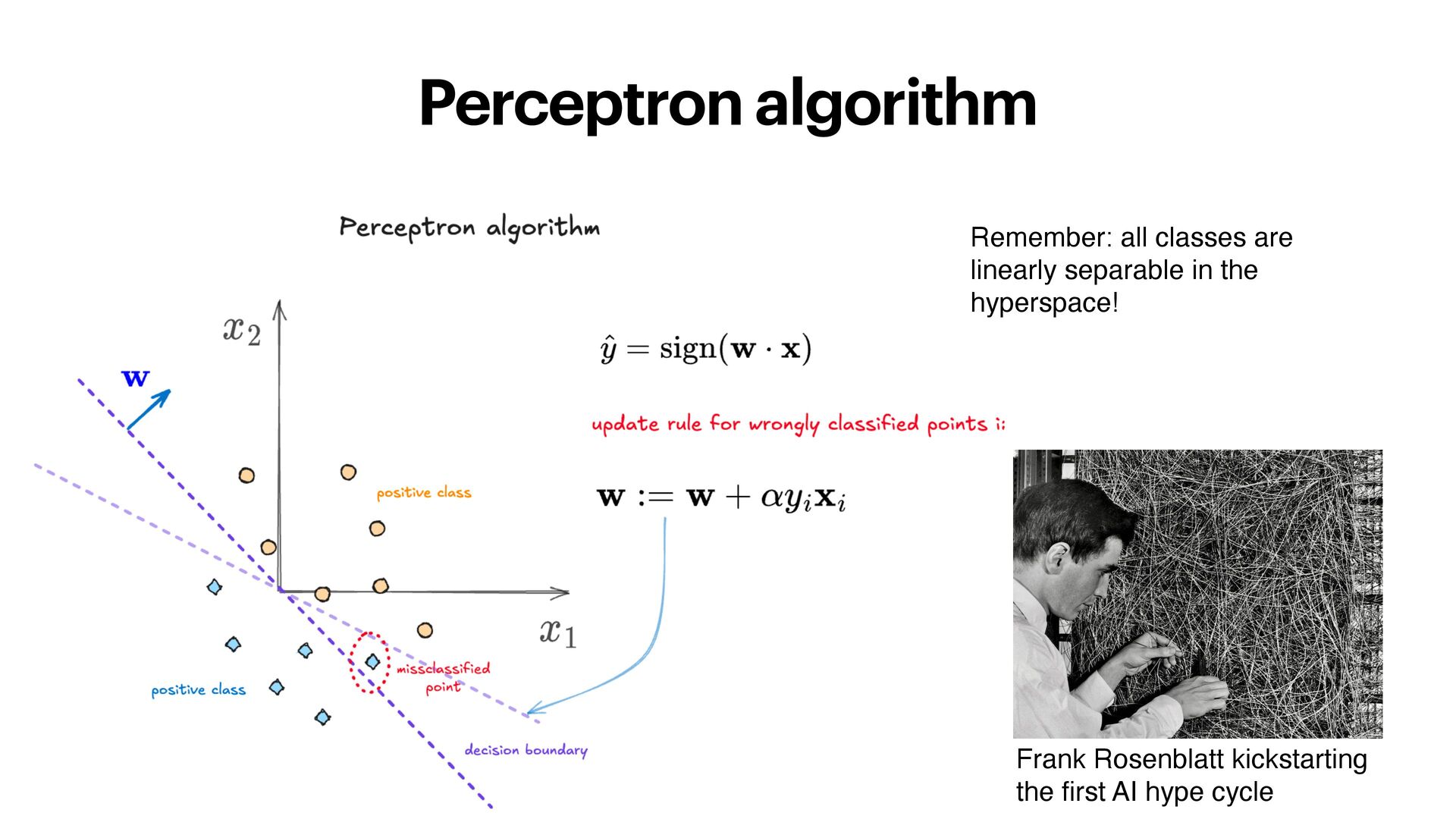
•In an ideal world, a computed HV would closely match its target concept. In practice, this might not perform well and a form of retraining is needed. •Common method: iteratively add/bundle wrongly classi fi ed data points to improve the prototype HV. •One can also use a linear classi fi er, such as Logistic Regression, Fisher Discriminant Analysis or the Perceptron
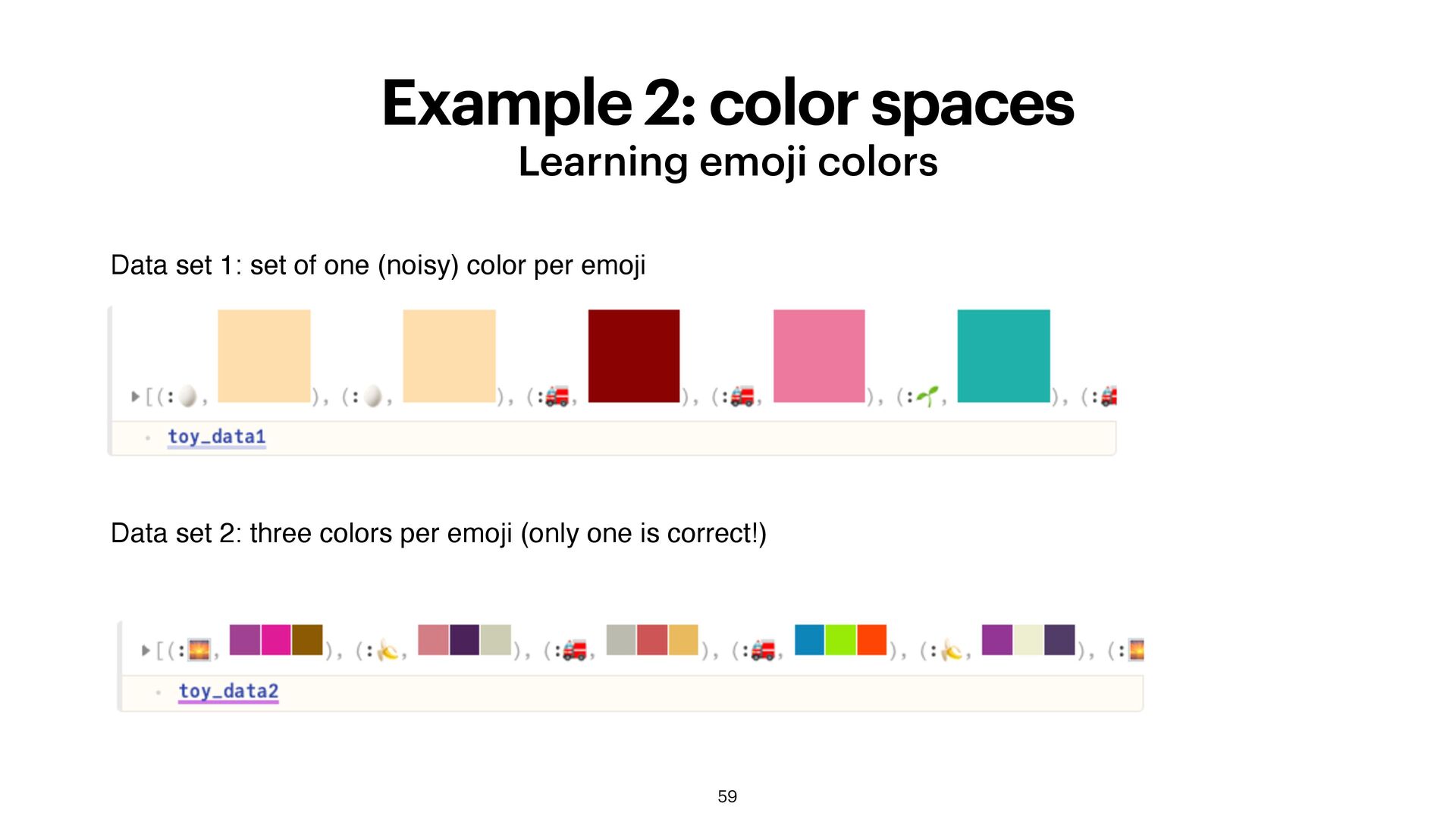
go through Section 2: Computing in the hyperspace. • Implementation and examples of bundling, binding, shifting and retraining (optional) • Example 1: text analysis • Example 2: color spaces 56
article in eight languages • Explore the N-gram/k-mer representation • Which languages are most similar? • Can you detect the presence of a sentence using the HVs? 57
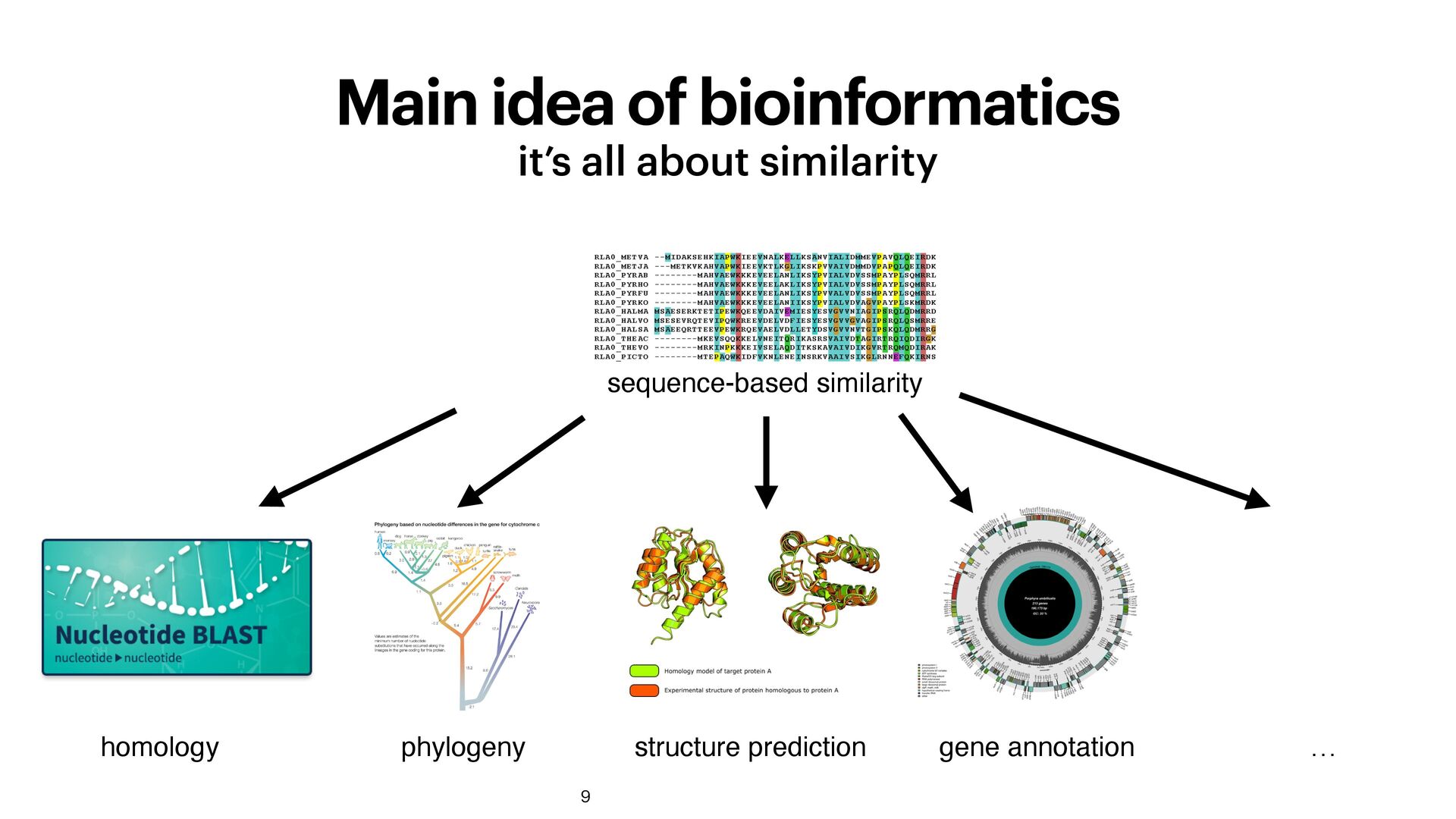
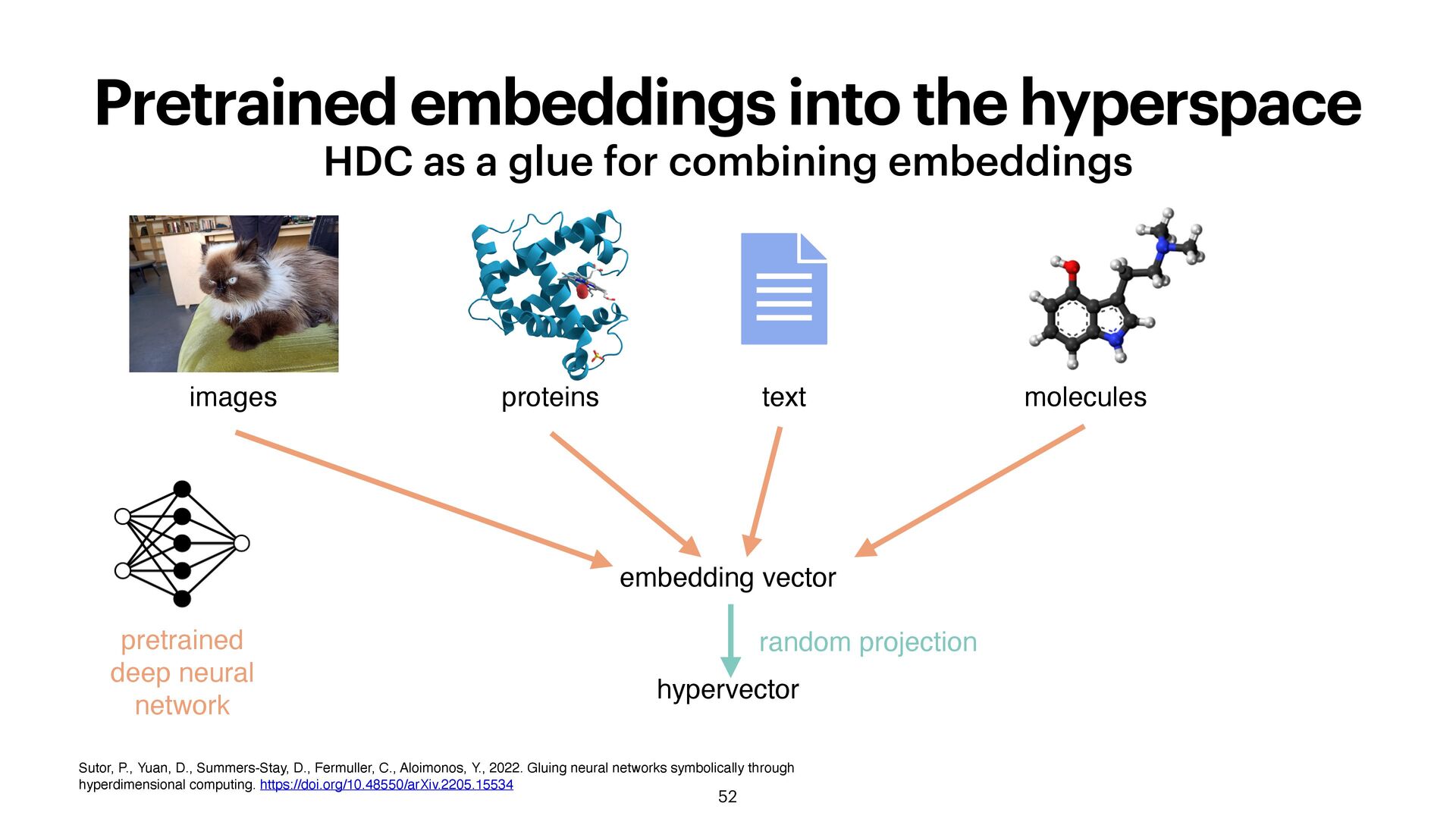
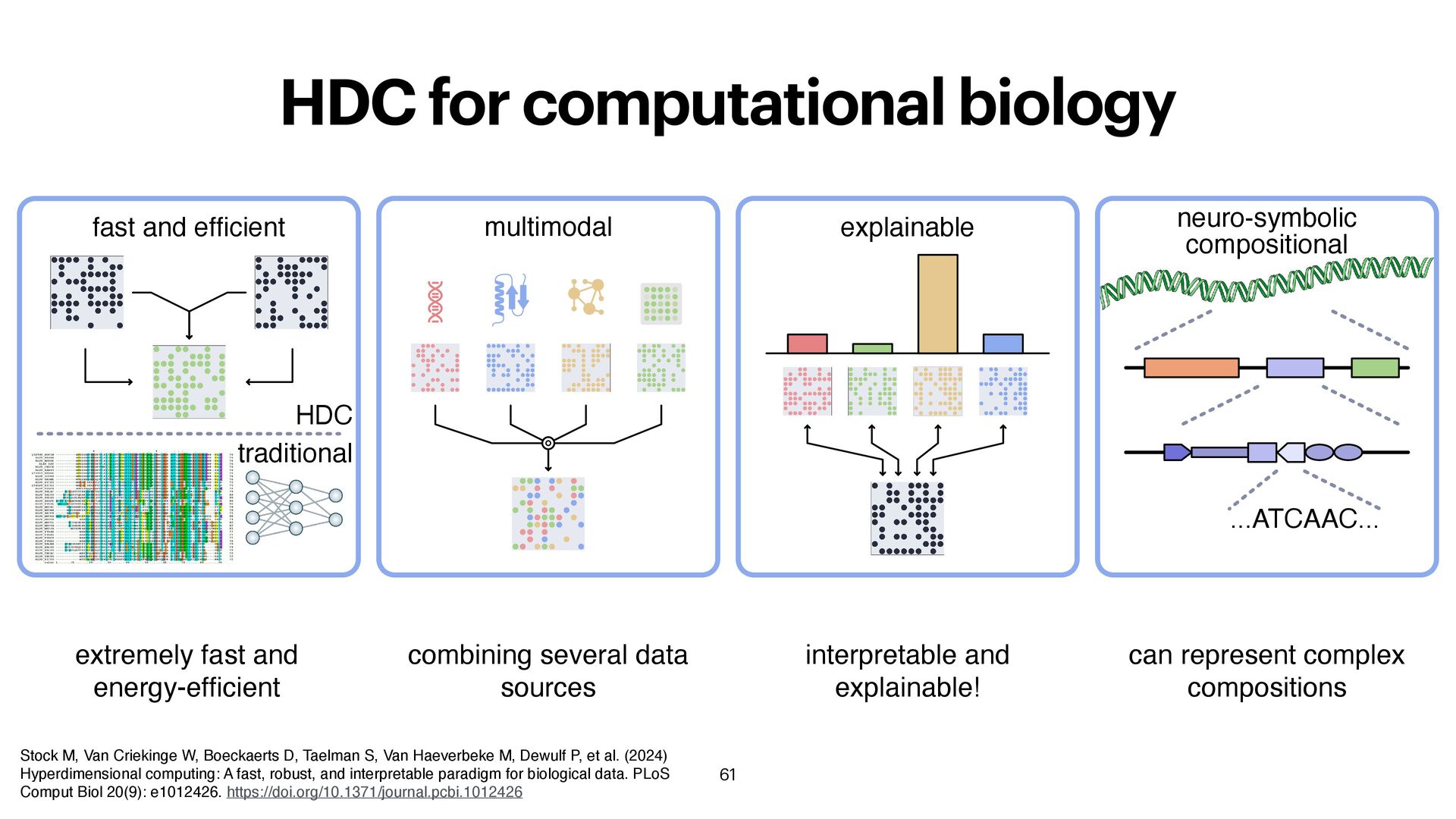
extremely fast and energy-ef fi cient multimodal combining several data sources explainable interpretable and explainable! neuro-symbolic compositional ...ATCAAC... can represent complex compositions Stock M, Van Criekinge W, Boeckaerts D, Taelman S, Van Haeverbeke M, Dewulf P, et al. (2024) Hyperdimensional computing: A fast, robust, and interpretable paradigm for biological data. PLoS Comput Biol 20(9): e1012426. https://doi.org/10.1371/journal.pcbi.1012426
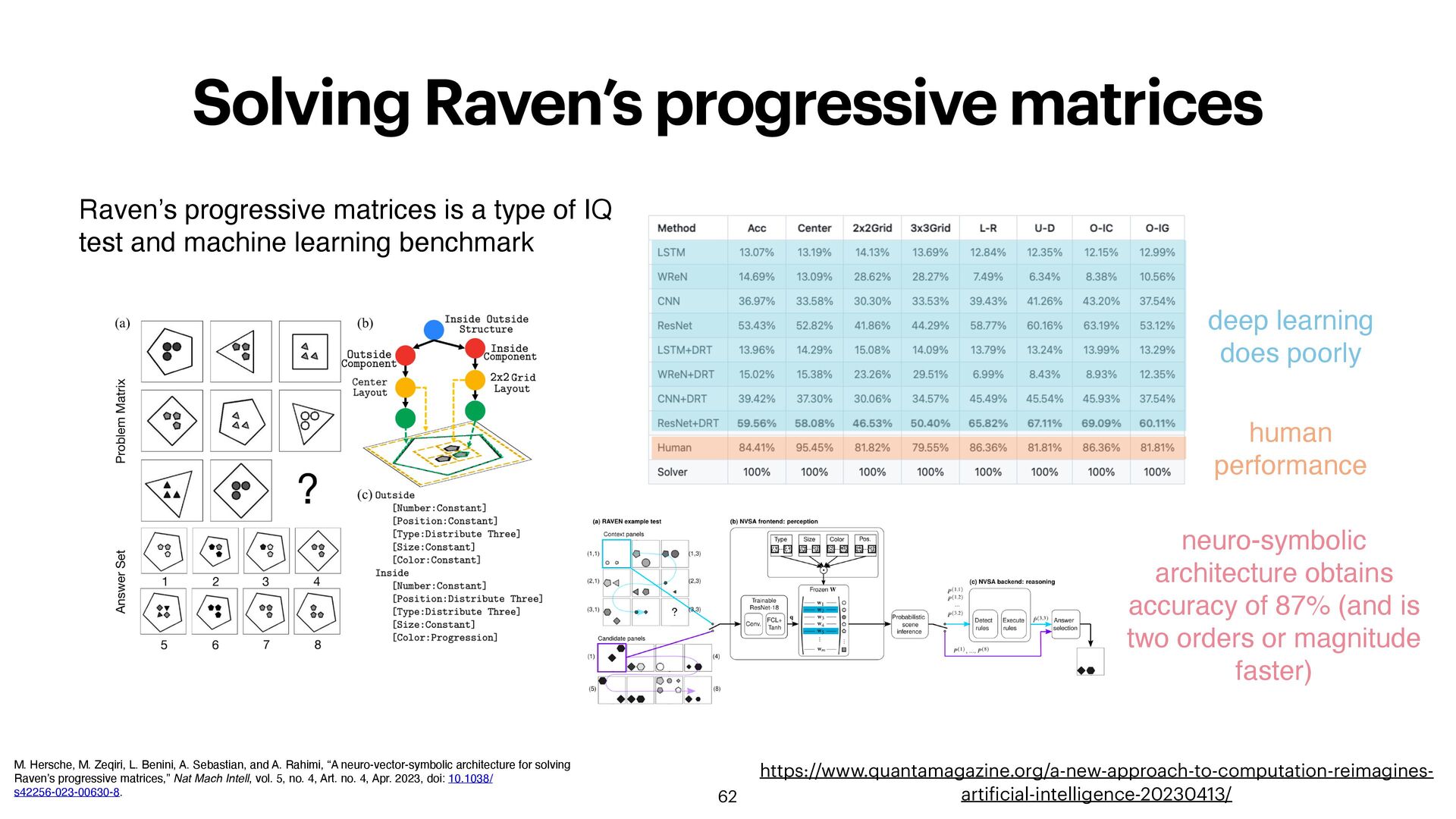
Benini, A. Sebastian, and A. Rahimi, “A neuro-vector-symbolic architecture for solving Raven’s progressive matrices,” Nat Mach Intell, vol. 5, no. 4, Art. no. 4, Apr. 2023, doi: 10.1038/ s42256-023-00630-8. https://www.quantamagazine.org/a-new-approach-to-computation-reimagines- arti f icial-intelligence-20230413/ Raven’s progressive matrices is a type of IQ test and machine learning benchmark deep learning does poorly human performance neuro-symbolic architecture obtains accuracy of 87% (and is two orders or magnitude faster)
L. Benini, and J. M. Rabaey, “Ef fi cient biosignal processing using hyperdimensional computing: network templates for combined learning and classi fi cation of ExG signals,” Proceedings of the IEEE, vol. 107, no. 1, pp. 123–143, Jan. 2019, doi: 10.1109/JPROC.2018.2871163. HDC is effective for biosignals such as EEG data due to ultra-low energy usage, robustness under low signal-to- noise ratios and online, fast learning “That is, good performance depends on good design rather than automated training, and this is a harder research task” Rahimi et al., 2019, p. 6 “(1) The HD classi fi er demands much less training data thanks to its simple and one-shot learning; (2) It also naturally operates with noisy and less preprocessed inputs; (3) There is no need for domain expert knowledge or electrode selection process. Last, but not least, the produced HD code is analyzable and interpretable.” Rahimi et al., 2019, p. 15
sequence length. HDC converts sequences into fi xed-size vectors, enabling constant-time matching and incredibly fast performance. • Genomics (BioHD): Uses Processing-in-Memory (PIM) to achieve 100x speedups and massive energy ef fi ciency compared to standard accelerators. • Metagenomics (Demeter): A food pro fi ler that is 100x faster and uses 30x less memory than state-of-the-art tools (Kraken2), enabling real-time monitoring on small devices. • Epigenetics: Successfully classi fi es tumor vs. non-tumor samples based on methylation pro fi les. 64
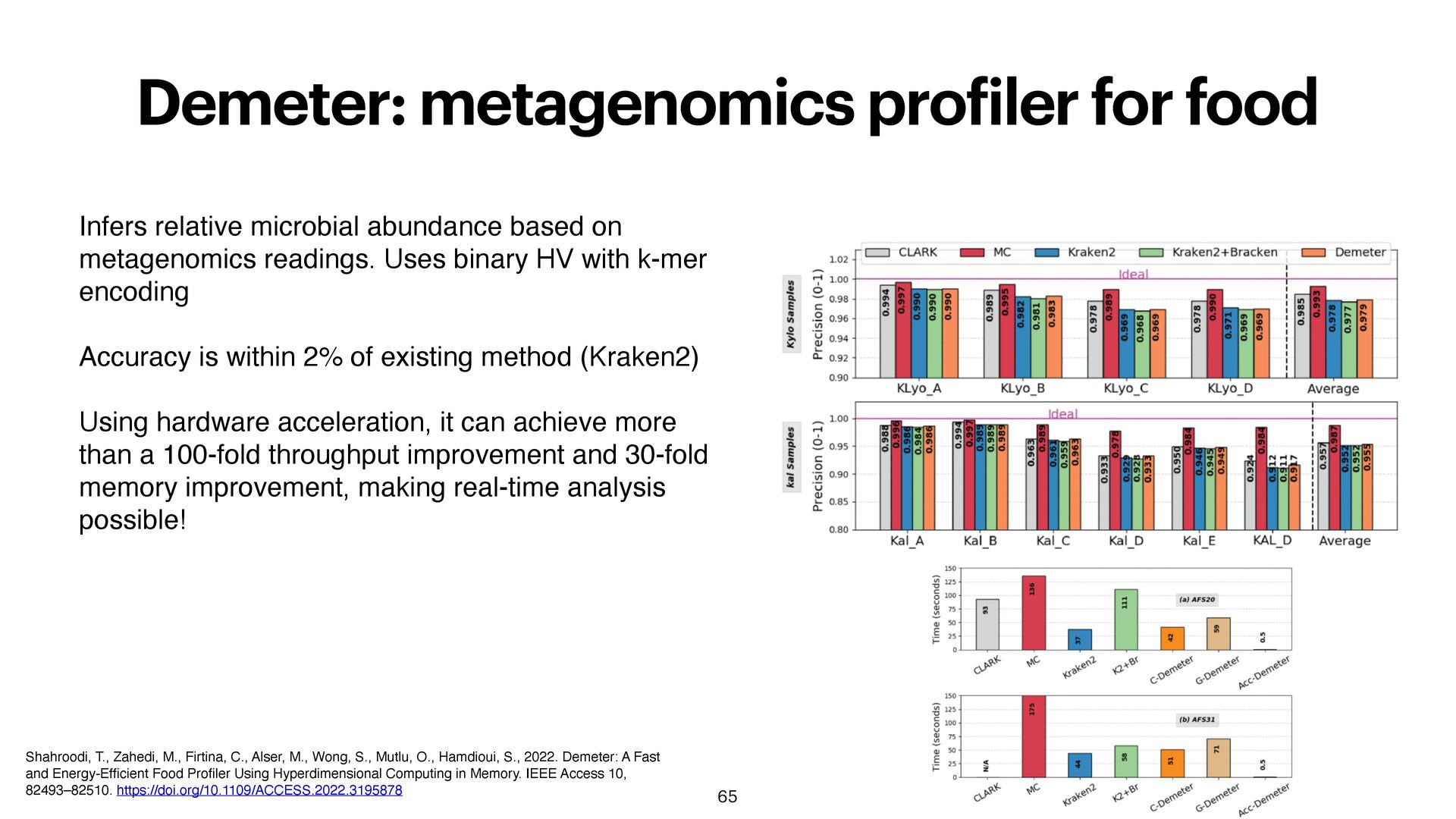
Zahedi, M., Firtina, C., Alser, M., Wong, S., Mutlu, O., Hamdioui, S., 2022. Demeter: A Fast and Energy-Ef fi cient Food Pro fi ler Using Hyperdimensional Computing in Memory. IEEE Access 10, 82493–82510. https://doi.org/10.1109/ACCESS.2022.3195878 Infers relative microbial abundance based on metagenomics readings. Uses binary HV with k-mer encoding Accuracy is within 2% of existing method (Kraken2) Using hardware acceleration, it can achieve more than a 100-fold throughput improvement and 30-fold memory improvement, making real-time analysis possible!
Ma, R. Thapa, and X. Jiao, “MoleHD: Ultra-Low-Cost Drug Discovery using Hyperdimensional Computing.” arXiv, Feb. 05, 2022. Accessed: Jun. 27, 2023. [Online]. Available: http://arxiv.org/abs/2106.02894 “For all the reported datasets together, MoleHD is able to achieve the reported accuracy within 10 minutes using CPU only from the commodity desktop” can compete with graph convolutional neural networks
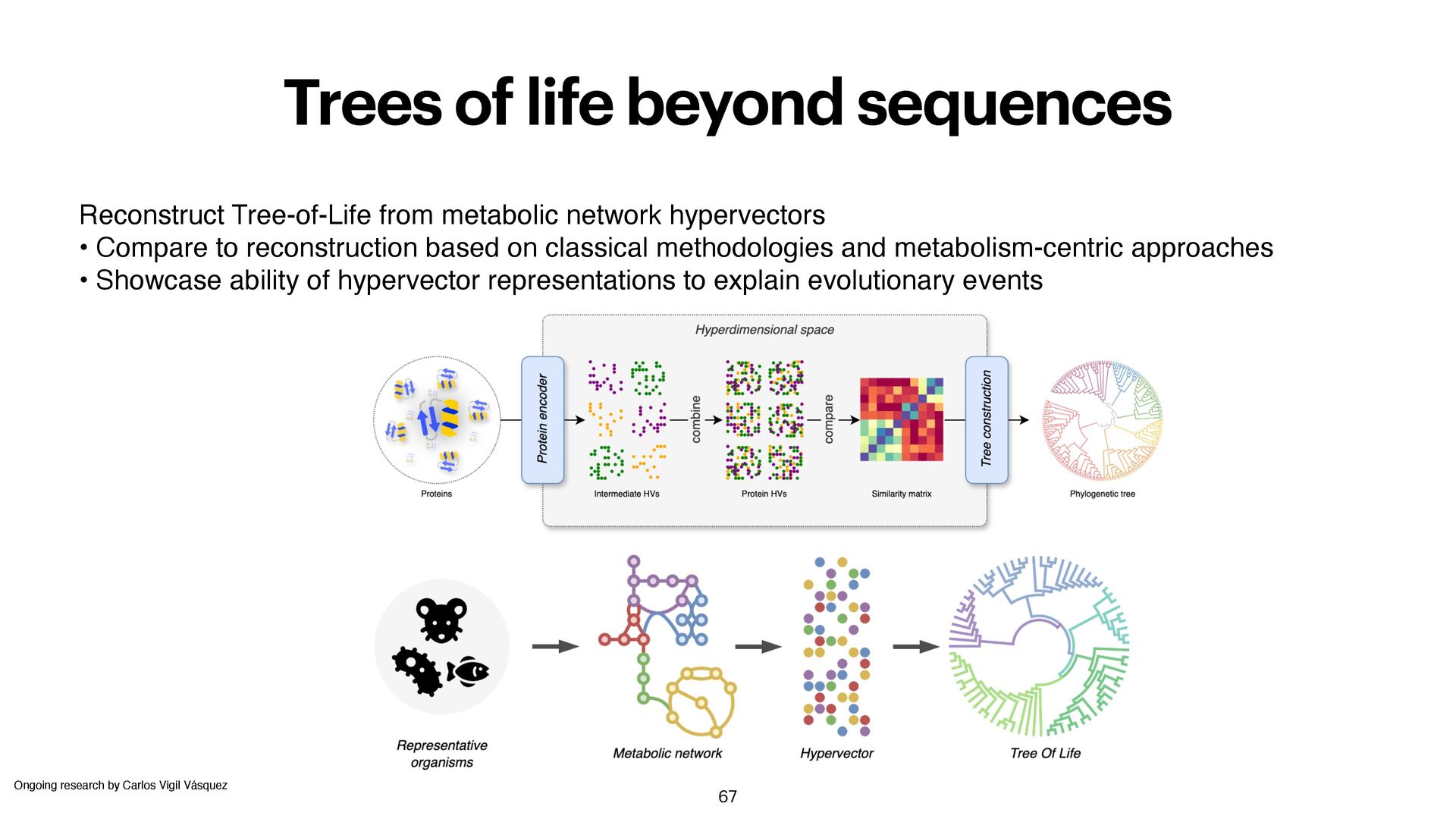
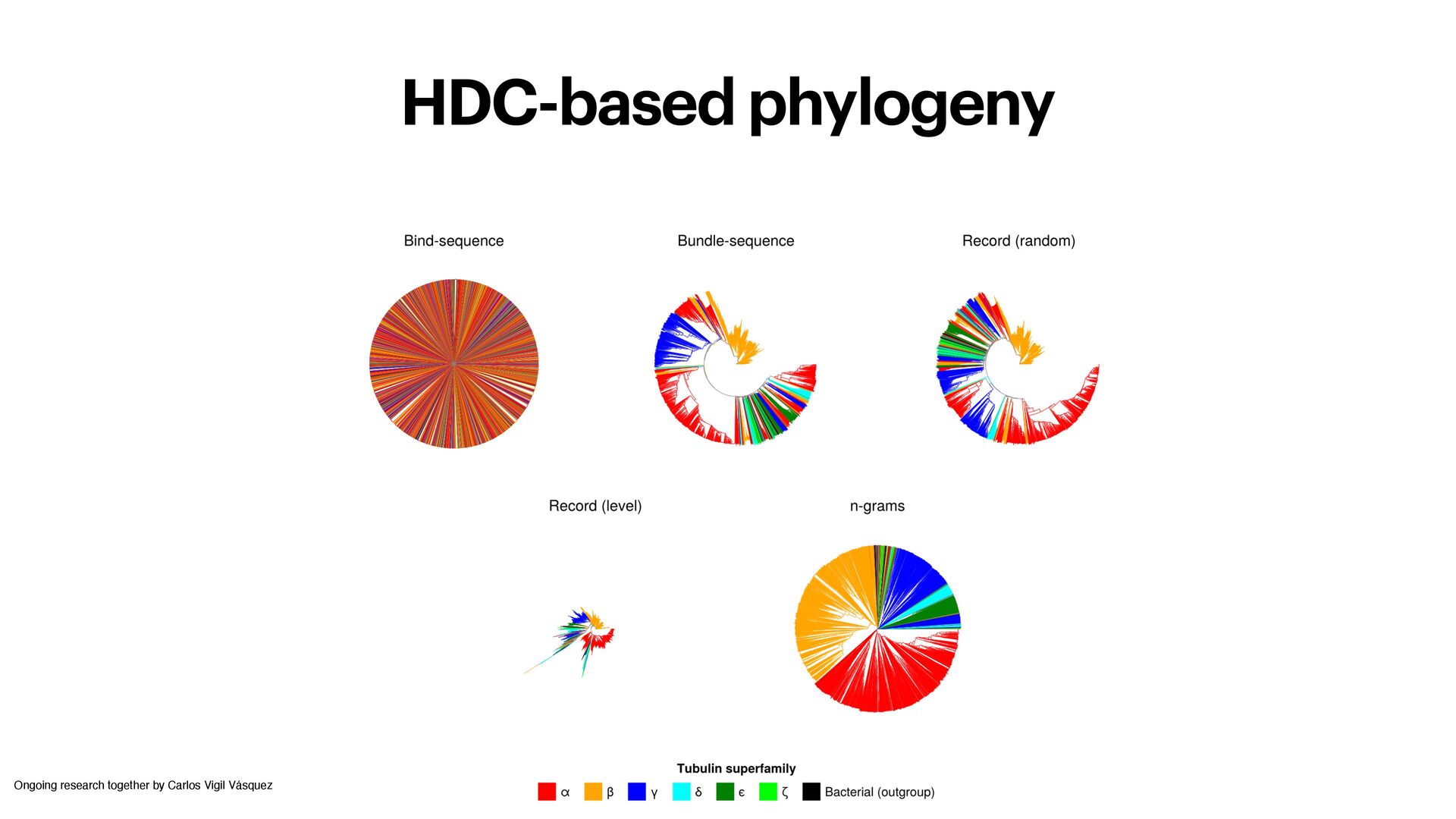
Vigil Vásquez Reconstruct Tree-of-Life from metabolic network hypervectors • Compare to reconstruction based on classical methodologies and metabolism-centric approaches • Showcase ability of hypervector representations to explain evolutionary events
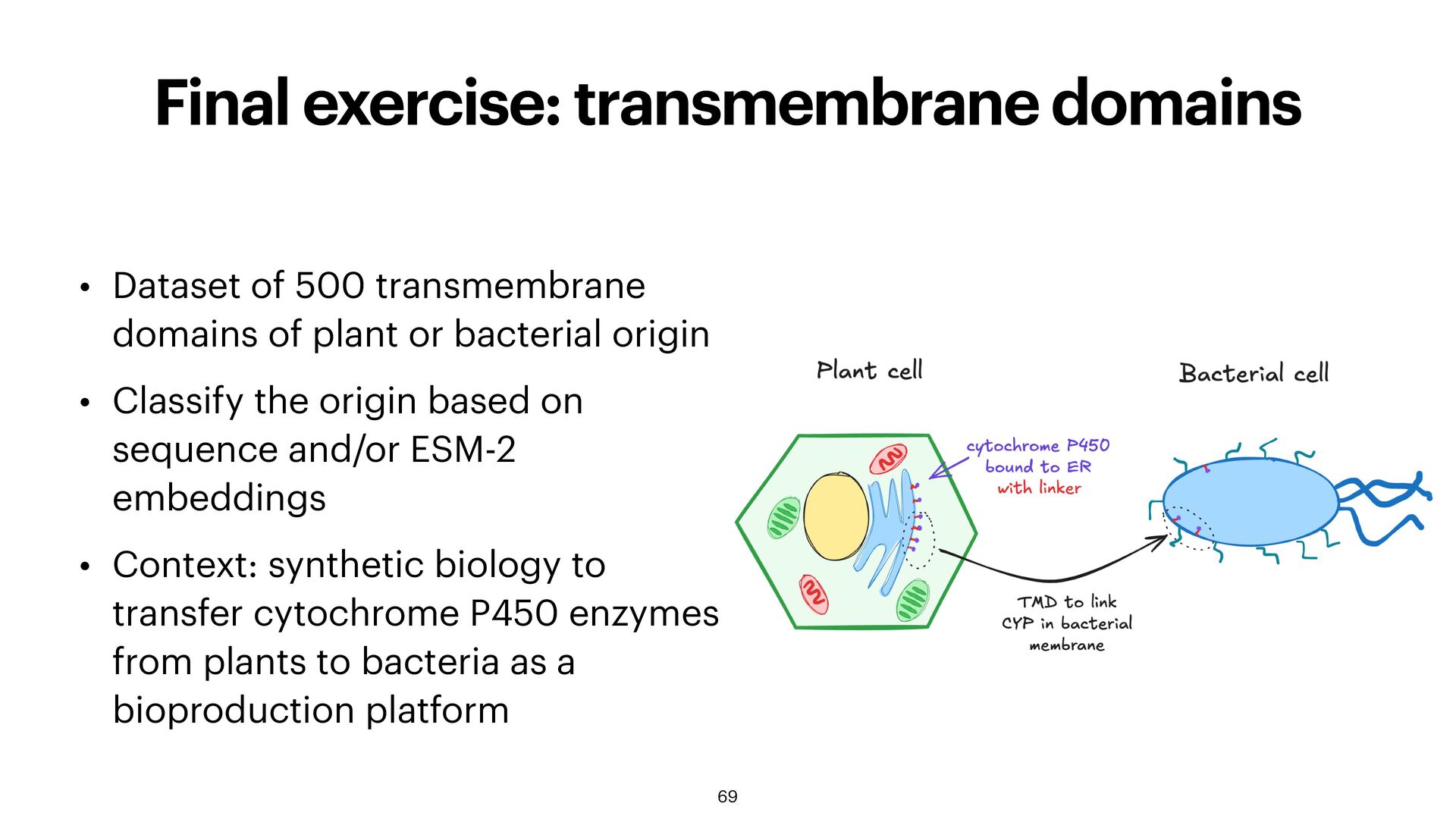
of plant or bacterial origin • Classify the origin based on sequence and/or ESM-2 embeddings • Context: synthetic biology to transfer cytochrome P450 enzymes from plants to bacteria as a bioproduction platform 69
from discussions with Dimi Boeckaerts, Steff Taelman, Maxime Van Haeverbeke, Pieter Dewulf, Bernard De Baets, Denis Kleyko, Carlos Vigil Vásquez and several thesis students. Thanks to Bram Spanoghe for many of the visuals. Thanks to Miguel De Block for the TMD dataset! Thanks to Tom Gorochowski for the invitation!
![Engineering Biology Doctoral School 2025 28 November 2025 [email protected] How](https://files.speakerdeck.com/presentations/1bdfc578481d4d3fb7001ddd92a8906a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Low power machine learning 63 [1] A. Rahimi, P. Kanerva,](https://files.speakerdeck.com/presentations/1bdfc578481d4d3fb7001ddd92a8906a/slide_62.jpg){kind=link}
{kind=link}
{kind=link}
![Drug discovery predicting pharmaceutical properties from molecules 66 [1] D.](https://files.speakerdeck.com/presentations/1bdfc578481d4d3fb7001ddd92a8906a/slide_65.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Engineering Biology Doctoral School 2025 28 November 2025 [email protected] How](https://files.speakerdeck.com/presentations/1bdfc578481d4d3fb7001ddd92a8906a/slide_73.jpg){kind=link}