Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
我が社のデータエンジニアリング現場#Chatwork編_2024/05/22
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
K.Mitsuhashi
May 23, 2024
Technology
2.9k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
我が社のデータエンジニアリング現場#Chatwork編_2024/05/22
K.Mitsuhashi
May 23, 2024
More Decks by K.Mitsuhashi
See All by K.Mitsuhashi
Snowflakeデータ基盤で挑むAI活用 〜4年間のDataOpsの基礎をもとに〜
kaz3284
1
640
試されるDataOps!? ~ここ4年間のデータ基盤の軌跡と成長と壁を北の大地で語る〜
kaz3284
2
570
[みん強第5回]_kubellのデータ基盤開発の最新状況とAIの活用の実践について
kaz3284
1
1.8k
TS-S205_昨年対比2倍以上の機能追加を実現するデータ基盤プロジェクトでのAI活用について
kaz3284
2
420
実用的なデータ分析基盤について(個人的に思うカジュアルトーク)
kaz3284
2
2.2k
Other Decks in Technology
See All in Technology
書籍セキュアAPIについて
riiimparm
0
390
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
6
2.6k
CTOキーノート:AI時代の「つなぐ」を再定義 ― 真のIoTとリアルワールドAI【SORACOM Discovery 2026】
soracom
PRO
0
330
AIがコードを書く時代、人間は何を保証するのか———馬場さんと考える、開発者に求められる新しい責任と価値 - TECH PLAY
netmarkjp
0
330
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
340
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
570
CloudWatchから始めるAWS監視
butadora
0
300
最新IoT事例11選に学ぶ!現場の成功パターンと実践のコツ【SORACOM Discovery 2026】
soracom
PRO
0
120
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
190
データ活用研修 データマネジメント【MIXI 26新卒技術研修】
mixi_engineers
PRO
4
800
自己解決や回答速度を上げる、サポート業務へのAIの組み込み方【SORACOM Discovery 2026】
soracom
PRO
0
120
AI エージェント時代のデジタルアイデンティティ
fujie
1
1.2k
Featured
See All Featured
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Accessibility Awareness
sabderemane
1
170
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
270
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
ラッコキーワード サービス紹介資料
rakko
1
4.1M
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
440
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
370
Transcript
1
© Chatwork オープニングトーク (本イベントで話したこと& 最新状況について) データエンジニア 三ツ橋和宏 2024年05月22日
発表者:三ツ橋(みっつ) 3 ◦業務経験 Chatwork入社以前はアド系ベンチャーのエンジニアとして、サー バ運搬から始まり、開発、新人育成と様々な役割を経験し、特に大 規模データ処理の効率化に情熱を注ぐ。 サービス拡大と比例して日々難度が増していくアド系データ処理に て、地獄の泥沼運用から生還した経験から、最先端のクラウド(マ ネージドサービス)を乗りこなして運用労力を最小化することに無 上の喜びを感じている。
◦Twitter @kaz3284 ◦Snowflake Data Superhero'24/'23, DataPolaris'22。
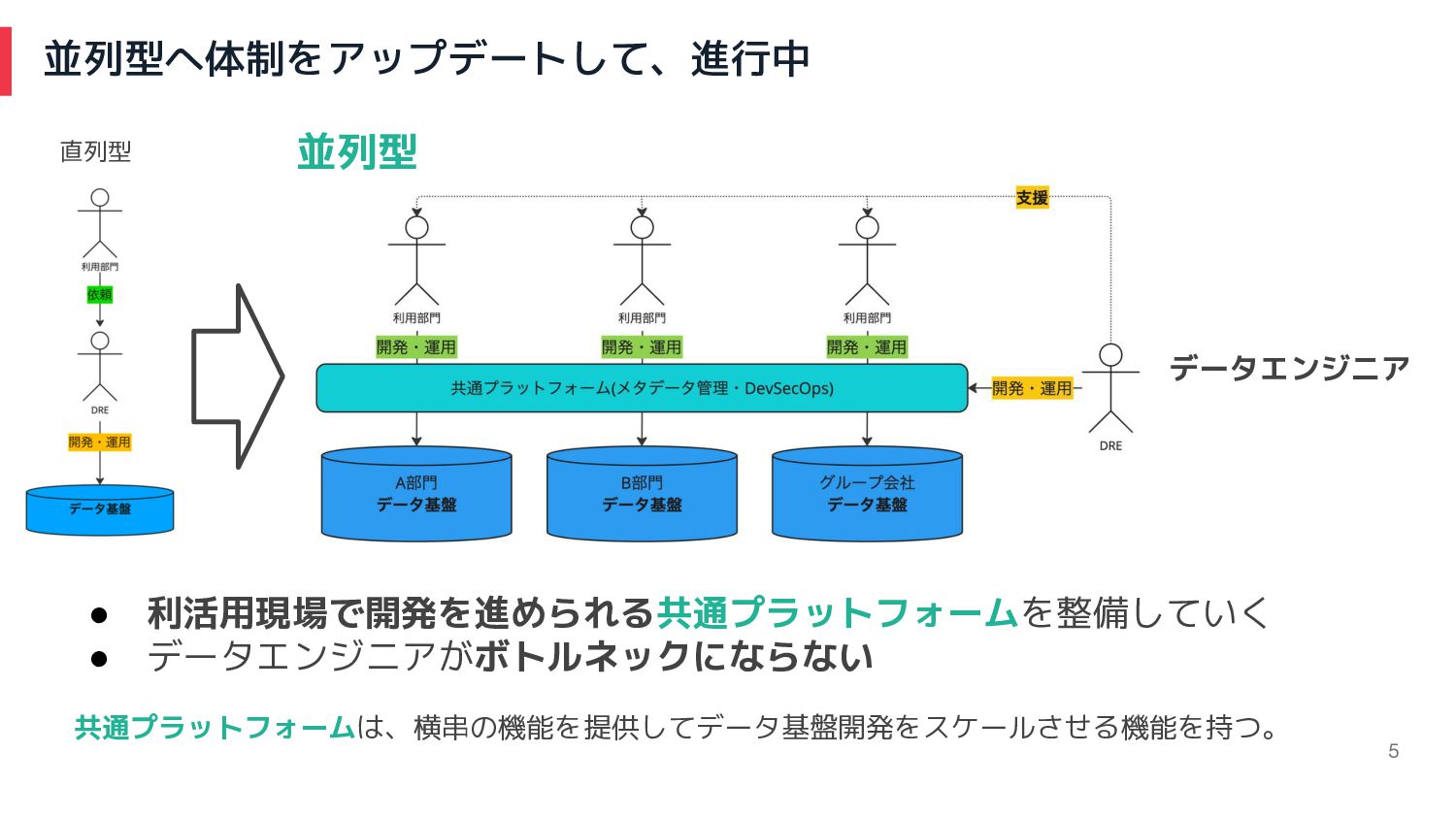
スモールスタートした新データ基盤、立ち上げることには成功したが... 4 • シンプルな体制で進めることで成功した。 • しかし、更にデータ利活用を推進するには、 データエンジニアがボトルネックになる弱点が見えてきた 直列型
並列型へ体制をアップデートして、進行中 5 データエンジニア • 利活用現場で開発を進められる共通プラットフォームを整備していく • データエンジニアがボトルネックにならない 共通プラットフォームは、横串の機能を提供してデータ基盤開発をスケールさせる機能を持つ。 直列型 並列型
プラットフォームエンジニアリング・DataOps 6 プラットフォーム・エンジニアリング(cf. https://www.gartner.co.jp/ja/articles/what-is-platform-engineering) • セルフサービス機能とインフラストラクチャ・オペレーションの自動化により、開発者のエクスペ リエンスと生産性を向上させる。 • 開発者だけでなく、オペレーションチームやビジネスチームなど、異なる役割の人々が技術的な作 業に参加することにより、より効率的なプロセスと意思決定が可能になる。
• ジェネレーティブAI(生成AI)もプラットフォームエンジニアリングの一環として活用される一つ の手段となりより創造的で革新的な方法で技術的な作業に取り組むことができる。 DataOps(cf. https://www.montecarlodata.com/blog-what-is-dataops/ ) • ソフトウェア開発のDevOpsと同様にデータを一連のフローで開発・運用していく仕組み • 生産者と消費者が一丸となってデータ利活用を進めていく
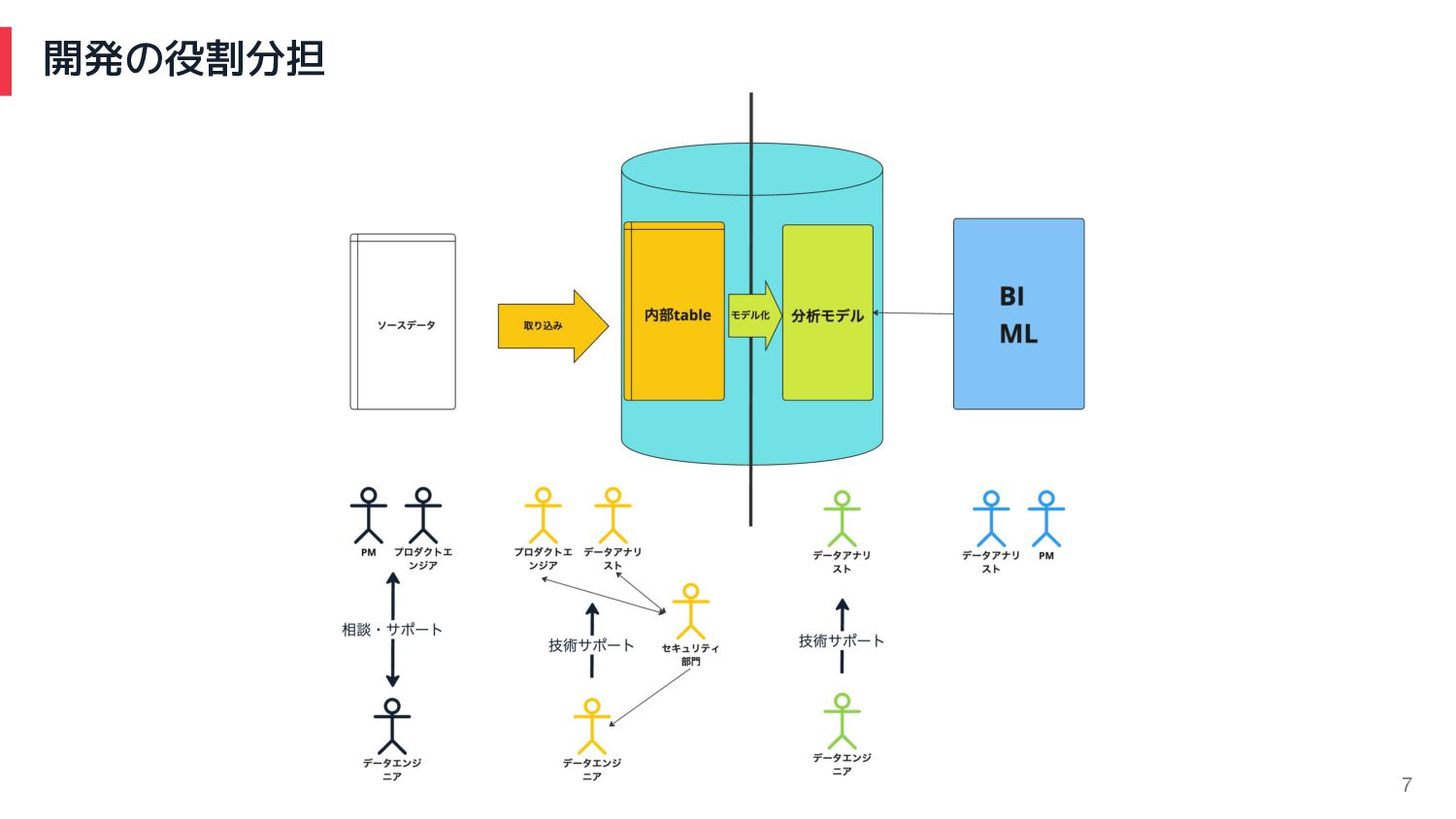
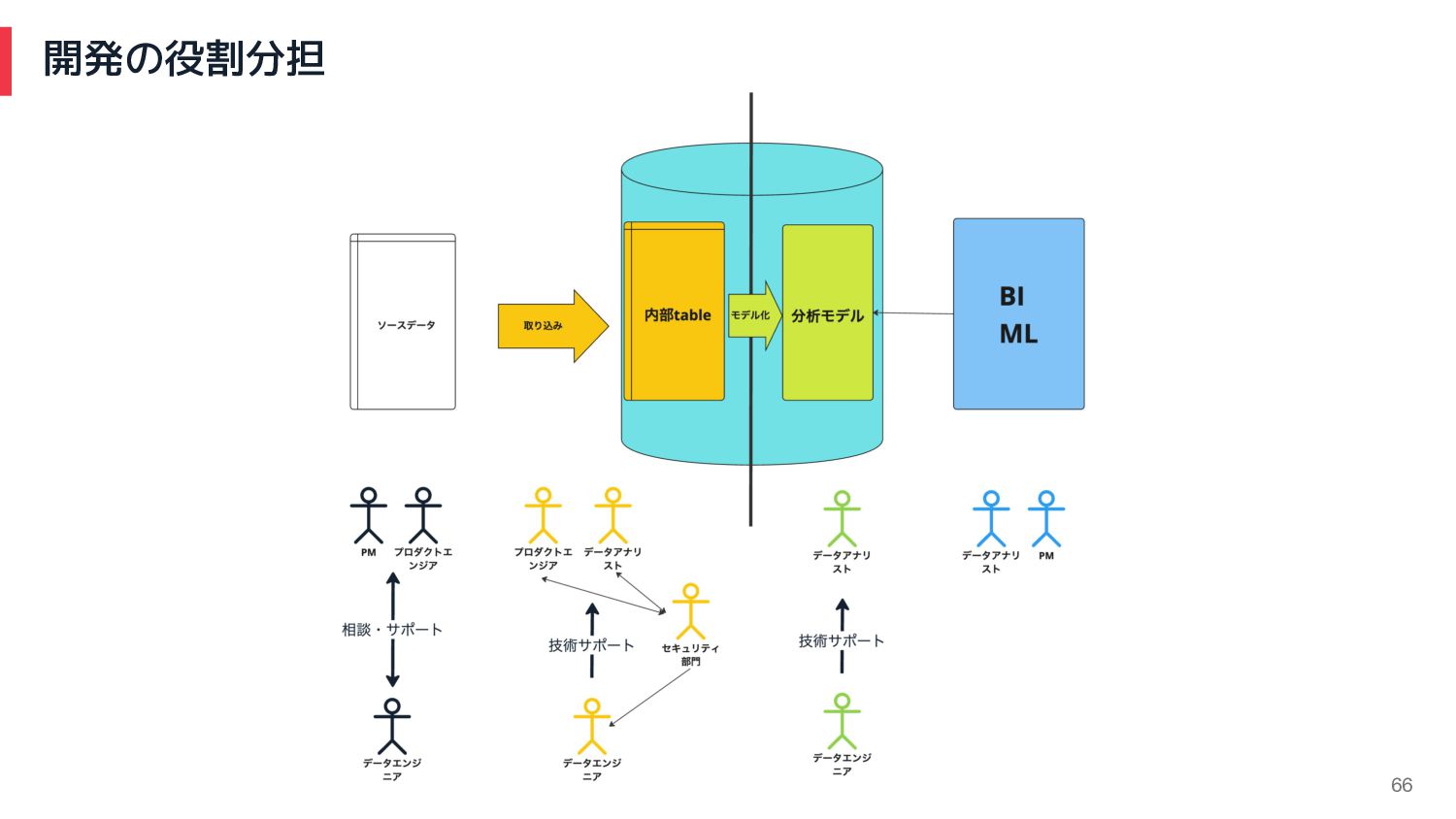
開発の役割分担 7
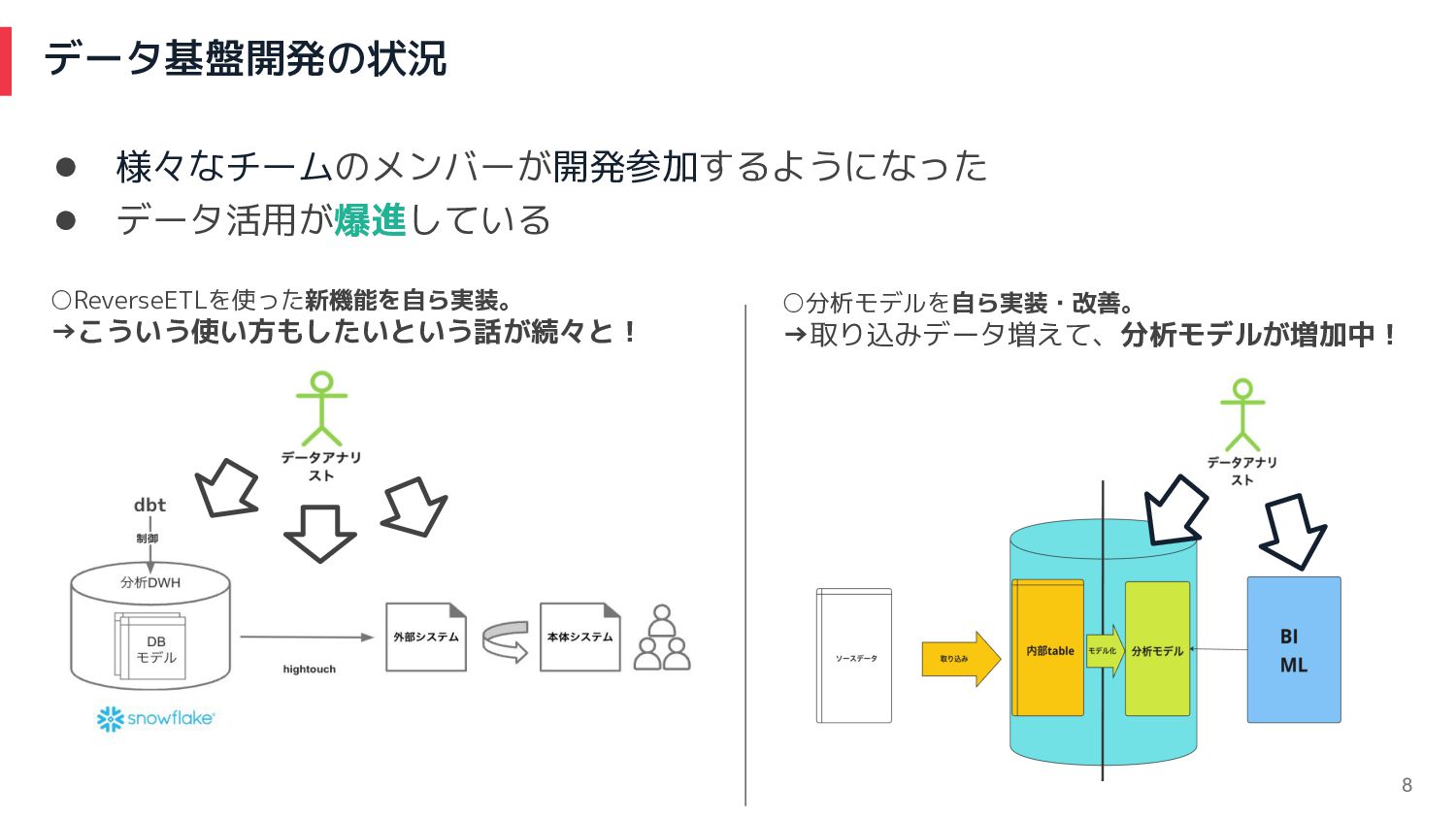
データ基盤開発の状況 8 • 様々なチームのメンバーが開発参加するようになった • データ活用が爆進している ◦ReverseETLを使った新機能を自ら実装。 →こういう使い方もしたいという話が続々と! ◦分析モデルを自ら実装・改善。 →取り込みデータ増えて、分析モデルが増加中!
'24/05時点の最新状況について 9 ◦LT1「プラットフォームエンジニアリングの理想と現実 〜希望の光はTVP〜」 → 従来比95%減を見込む自動化についてデータエンジニア飯島が語ります! ◦LT2「新米アナリストがデータ基盤開発って、無茶振りじゃないですか?」 → 並列体制に積極参加するアナリスト小林が利用側視点の体験談を語ります! ◦LT3「我が社が考える最強のデータ基盤・開発体制!」 →
アナリスト田中が、本イベントで感嘆の声が多く上がった アナリスト主導を実現した新機能開発について語ります!
© Chatwork データエンジニア 飯島知之 2024年5月22日 プラットフォーム エンジニアリング の理想と現実 〜希望の光はTVP〜
AGENDA アジェンダ 自己紹介 プラットフォームエンジニアリングの理想と現実 【事例1】データソース追加依頼のフォーマット化 【事例2】テスト環境構築の自動化 事例から見る共通点 1 2 3
4 5
自己紹介 12
自己紹介 飯島 知之 (Iijima Tomoyuki) 【略歴】 • SIerでデータベース管理者としてキャリアをスタート • データ基盤プロジェクトの企画から導入まで幅広く経験
• 二人目のデータエンジニアとしてChatworkに入社 【得意分野】 • RDBMS/DWH, AWS, Terraform, dbtなどのデータ基盤技術 【マイブーム】 • notionで日記を書くこと(いつまで続くか…!?) アウトプット:https://zenn.dev/jimatomo 13
プラットフォームエンジニアリングの 理想と現実 14
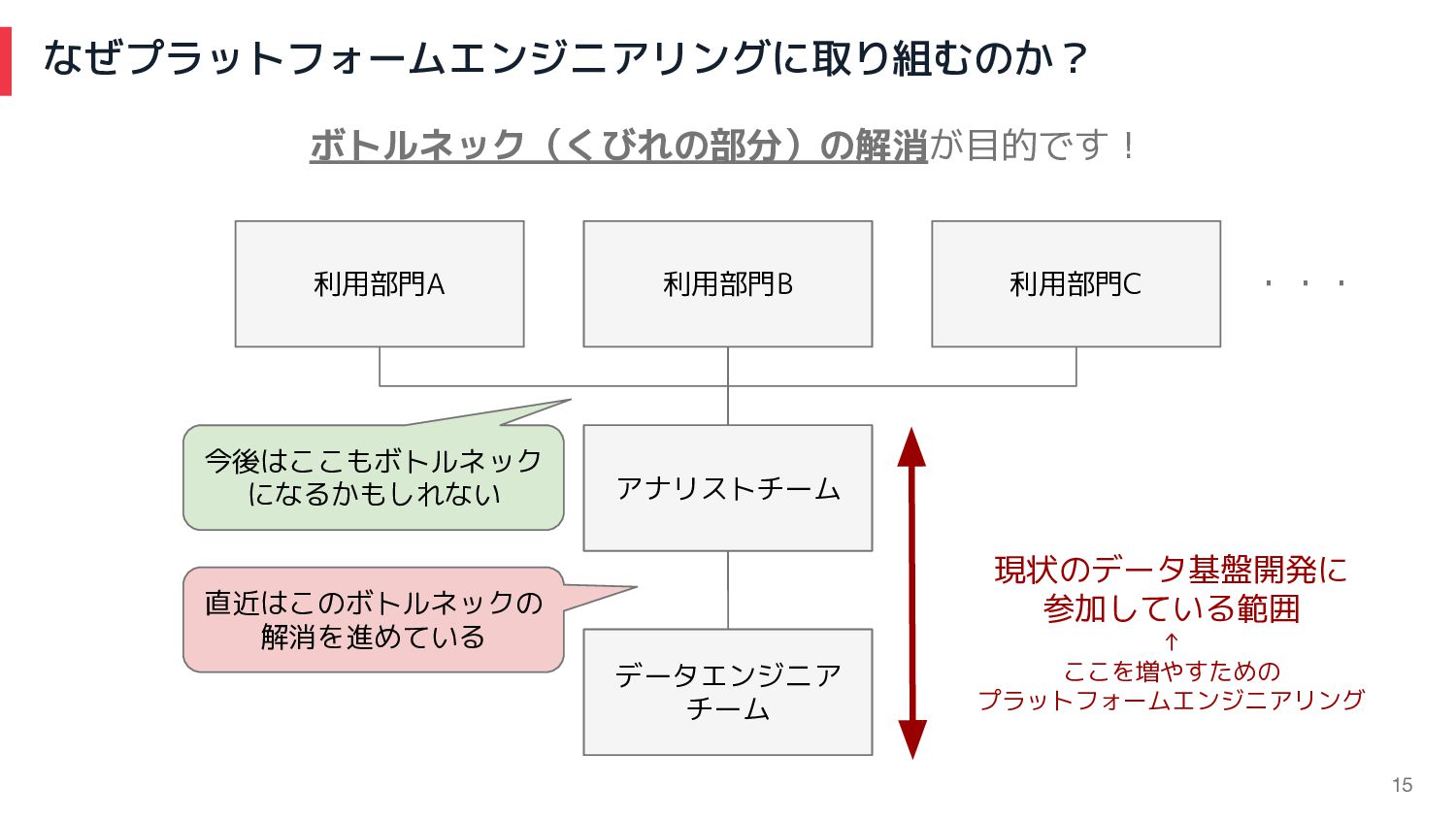
なぜプラットフォームエンジニアリングに取り組むのか? ボトルネック(くびれの部分)の解消が目的です! 利用部門B アナリストチーム データエンジニア チーム 利用部門C 利用部門A ・・・ 今後はここもボトルネック
になるかもしれない 直近はこのボトルネックの 解消を進めている 現状のデータ基盤開発に 参加している範囲 ↑ ここを増やすための プラットフォームエンジニアリング 15
プラットフォームエンジニアリングの理想と現実 理想 現実 【体制】 プラットフォームエンジニアリングの 専任チームが設計・開発 【機能の提供レベル】 ガードレールと自由度のバランスよく 提供できて、セルフサービス形式で利 用できている
(AWS的なXaaSが実現できている) 【投資対効果】 一度作れば長い間利用され続けて、投 資回収できる 【体制】 データエンジニア(DRE)が日々の 開発・運用作業の片手間でプラット フォーム機能の設計・開発 【機能の提供レベル】 時間が足りなくて、一定のスキルセッ トが前提となる最低限のものしか提供 できていない (属人的なものが多く残っている) 【投資対効果】 最善の選択肢が変わるスピードが速 く、投資回収できない場合もある 16
理想と現実のギャップに諦めそうになるが… (日々のタスクに追われてなかなか理想に近づけない) 17
希望の光はTVP (Thinnest Viable Platform) TVP (Thinnest Viable Platform) とは、(かなりざっくり解釈すると) 「最低限のプラットフォーム」のこと
最低限とは具体的に? → ドキュメント(開発者向けのWikiなど)でOK (ハードルが超低い…!) 参考:https://teamtopologies.com/key-concepts (本質的なところを見誤らなければ) こんな簡単なことでもいいんだ!と、 一歩踏み出す勇気をくれる考え方 18
TVPだなぁという事例を2つほどご紹介します (dbtなどのデータ基盤のツールの説明は割愛します) 19
【事例1】 データソース追加依頼のフォーマット化 20
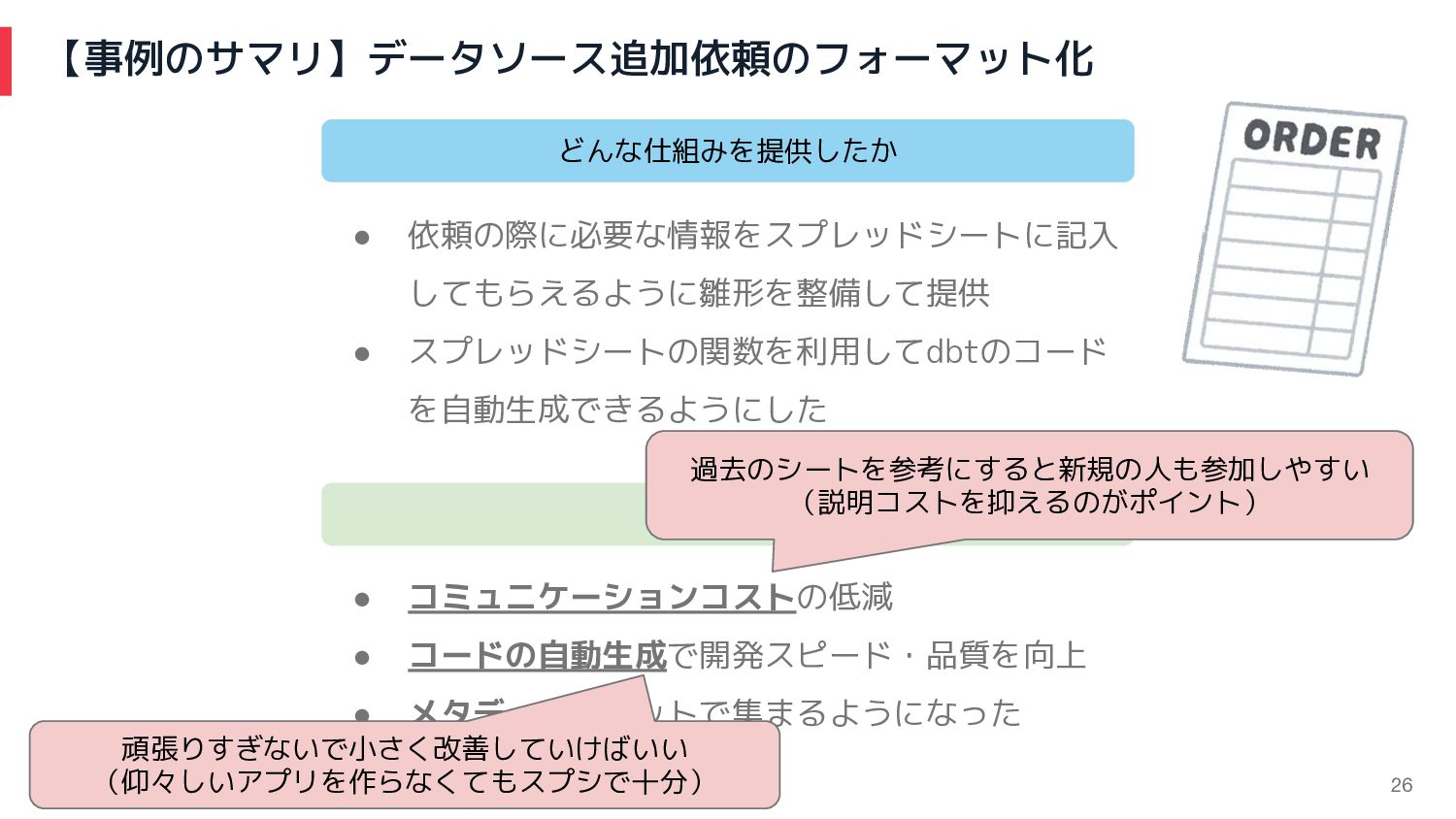
【事例のサマリ】データソース追加依頼のフォーマット化 効果 • コミュニケーションコストの低減 • コードの自動生成で開発スピード・品質を向上 • メタデータもセットで集まるようになった どんな仕組みを提供したか •
依頼の際に必要な情報をスプレッドシートに記入 してもらえるように雛形を整備して提供 • スプレッドシートの関数を利用してdbtのコード を自動生成できるようにした 21
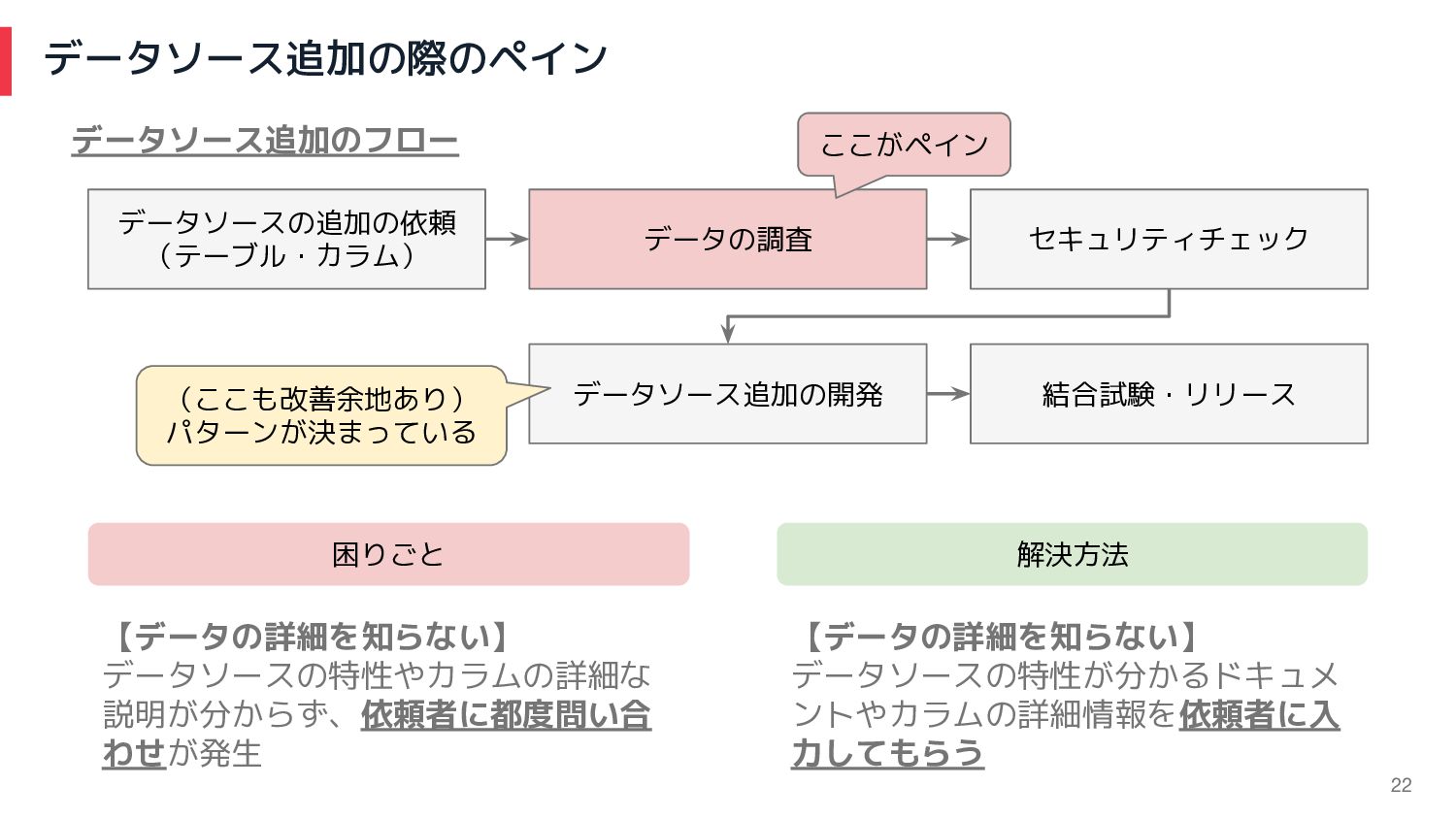
データソース追加の際のペイン 困りごと 解決方法 【データの詳細を知らない】 データソースの特性やカラムの詳細な 説明が分からず、依頼者に都度問い合 わせが発生 【データの詳細を知らない】 データソースの特性が分かるドキュメ ントやカラムの詳細情報を依頼者に入
力してもらう データソースの追加の依頼 (テーブル・カラム) データの調査 セキュリティチェック データソース追加の開発 結合試験・リリース データソース追加のフロー ここがペイン (ここも改善余地あり) パターンが決まっている 22
データソース追加依頼をフォーマット化 こんな感じのスプレッドシートを用意して入力してもらう 説明はしっかり書いておく (過去の入力例も参考にできる) 23
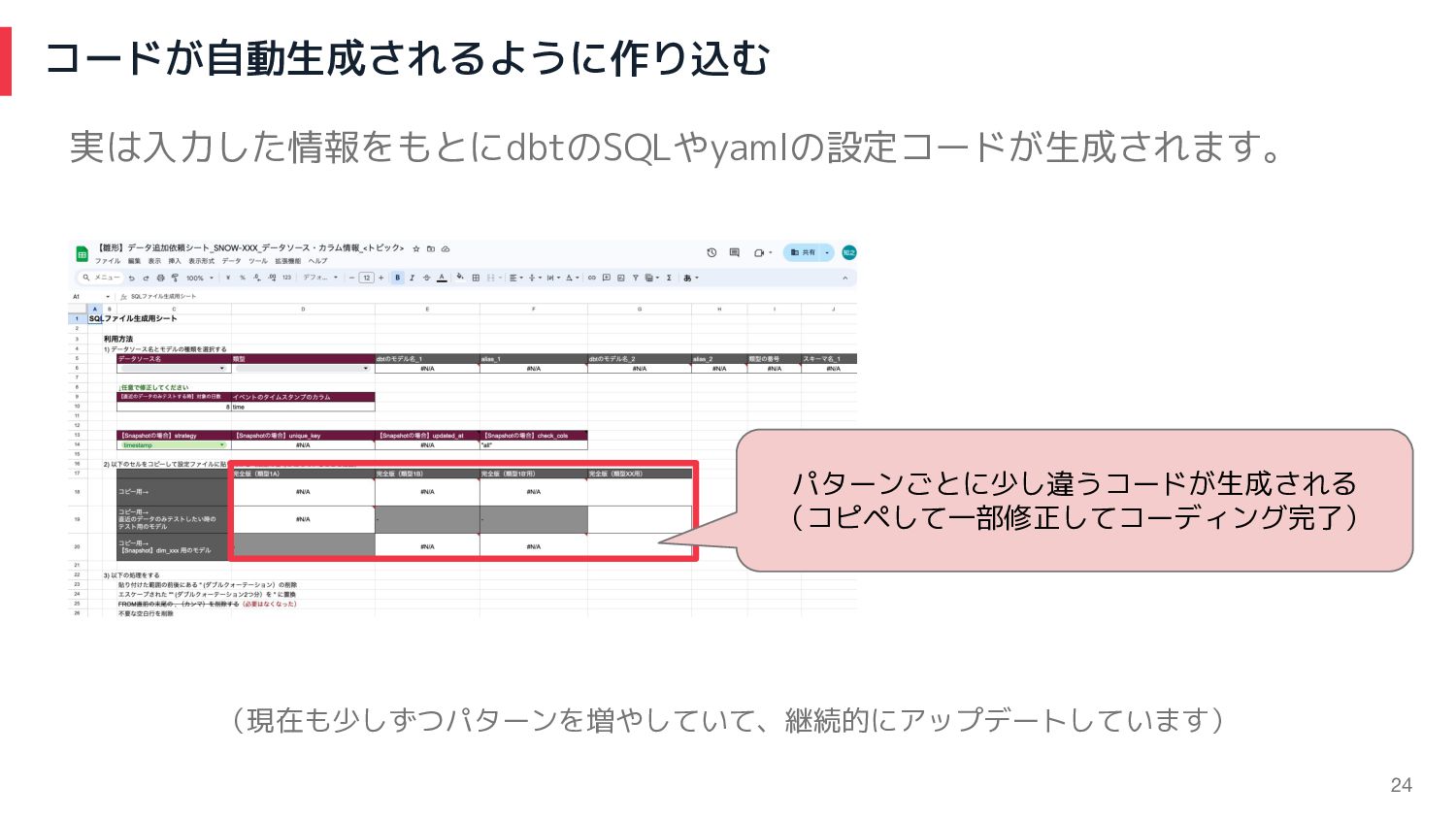
コードが自動生成されるように作り込む 実は入力した情報をもとにdbtのSQLやyamlの設定コードが生成されます。 パターンごとに少し違うコードが生成される (コピペして一部修正してコーディング完了) (現在も少しずつパターンを増やしていて、継続的にアップデートしています) 24
【事例のサマリ】データソース追加依頼のフォーマット化 効果 • コミュニケーションコストの低減 • コードの自動生成で開発スピード・品質を向上 • メタデータもセットで集まるようになった どんな仕組みを提供したか •
依頼の際に必要な情報をスプレッドシートに記入 してもらえるように雛形を整備して提供 • スプレッドシートの関数を利用してdbtのコード を自動生成できるようにした 25
【事例のサマリ】データソース追加依頼のフォーマット化 効果 • コミュニケーションコストの低減 • コードの自動生成で開発スピード・品質を向上 • メタデータもセットで集まるようになった どんな仕組みを提供したか •
依頼の際に必要な情報をスプレッドシートに記入 してもらえるように雛形を整備して提供 • スプレッドシートの関数を利用してdbtのコード を自動生成できるようにした 過去のシートを参考にすると新規の人も参加しやすい (説明コストを抑えるのがポイント) 頑張りすぎないで小さく改善していけばいい (仰々しいアプリを作らなくてもスプシで十分) 26
開発のパターンが決まっているものをフレーム化 (スプシを整えるだけでもいい) これも一つのTVP 27
【事例2】 テスト環境構築の自動化 28
【事例のサマリ】テスト環境構築の自動化 効果 • 結合試験環境の構築工数の低減(8時間/月 → 5分/月) • リリースまでのリードタイム短縮(2週間 → 2日)
• リグレッションテストなども実施しやすく変更を 気軽に試せるようになる ※今後開発量が増えていくほどに効果が高まっていく どんな仕組みを提供したか(予定) • 本番データを利用した新しいdbtモデルのテストの 環境構築を自動化 29
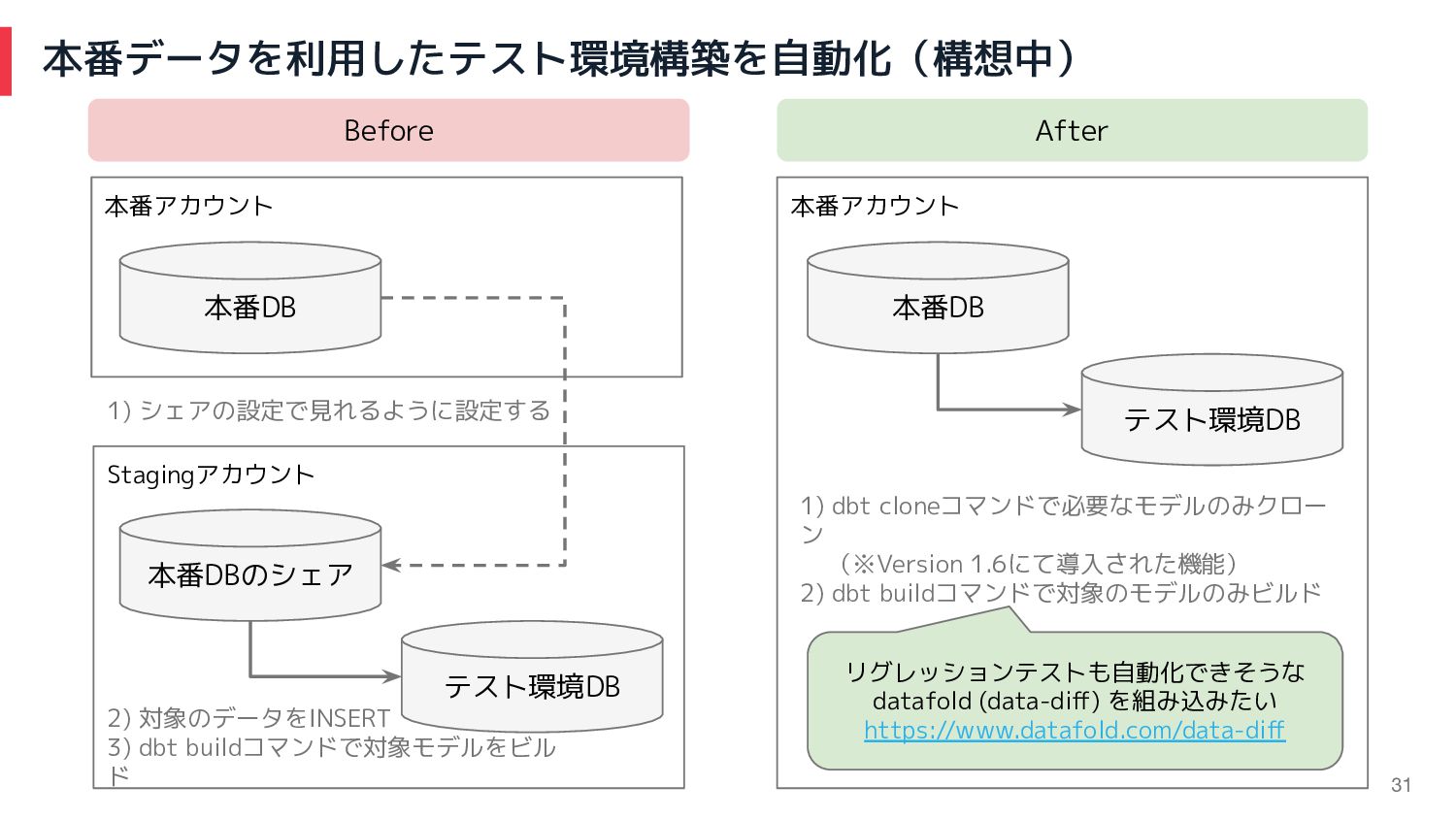
現状の開発プロセスのペイン 困りごと 解決方法 【準備】 データの準備が手動でとにかく時間が かかる(マスキングなしのデータの準 備がさらに手間がかかる) 開発環境(アカウント) Staging環境(アカウント) 本番環境(アカウント)
※セキュリティのリスク低減のためにSnowflakeのアカウント単位で環境分かれています(+環境破壊事故が起こらないように) dbtモデル開発のフロー SQLロジックのテスト (テストデータは手動投入) (コンパイルされたコードを本番 環境で投げてのテスト)ココもペイン 本番想定データでの結合テスト (テストデータは本番環境からコ ピー ※通常マスキング有) 本番データでの受け入れテスト 【準備】 本番アカウントでゼロコピークローン 機能を活用して回避 ここがペイン 30
本番アカウント 本番データを利用したテスト環境構築を自動化(構想中) 本番DB テスト環境DB 1) dbt cloneコマンドで必要なモデルのみクロー ン (※Version 1.6にて導入された機能)
2) dbt buildコマンドで対象のモデルのみビルド リグレッションテストも自動化できそうな datafold (data-diff) を組み込みたい https://www.datafold.com/data-diff Before After 本番アカウント Stagingアカウント 本番DB 本番DBのシェア テスト環境DB 1) シェアの設定で見れるように設定する 2) 対象のデータをINSERT 3) dbt buildコマンドで対象モデルをビル ド 31
自動化による効果(試算) 現状(小さめのリリース1回) 自動化 開発時にコンパイルしたコードを修正して本番でテスト incrementalモデルなどはdbtのdata testまで手が回らない 15〜30分 0分 結合試験でコピーが必要なテーブルの情報を整理 ※マスキングの影響などの調査も含めて
60〜120分 0分 結合試験でコピーの手順を準備 30〜60分 0分 結合試験環境にデータをコピーしてくるオペレーション 15〜30分 5分 • “モデルの複雑度” × “モデルの数” で増えていく → 並列開発体制で開発量が増え、今後右肩上がりで増えていく状態 • リリースまでのリードタイムを劇的に短縮できるメリットも大きい → 現状環境の準備の大変さからある程度まとめて結合試験を実施 • リグレッションテストまで自動化できるとリファクタリングなども積極的に チャレンジできる心理的ハードルを下げることができる 95% 削減 32
よく発生するオペレーションを効率化する これも一つのTVP 33
事例から見る共通点 34
本質はいつもシンプル 今回取り上げた事例に共通しているポイントは以下の3つ • 利用者の声を拾う ◦ 効果が高いものはユーザが一番知っている(自分もユーザの一人) • ペインが継続していくものを対象にする ◦ 繰り返し使えるものでないと投資対効果が出ない
• 最初から頑張り過ぎない ◦ これが一番大事(TVPという考え方が一歩踏みだす勇気をくれる) Thinnest Viable Platform で一歩先のデータ基盤へ進化させています! (今回取り上げられなかった他にもやりたいことが山積みです) 35 頑張ろうという気持ちは大事 頑張り過ぎないバランスも大事
働くをもっと楽しく、創造的に
© Chatwork 新米アナリストが データ基盤開発って、 無茶振りじゃないですか? データアナリスト 小林 嵩 2024年05月22日
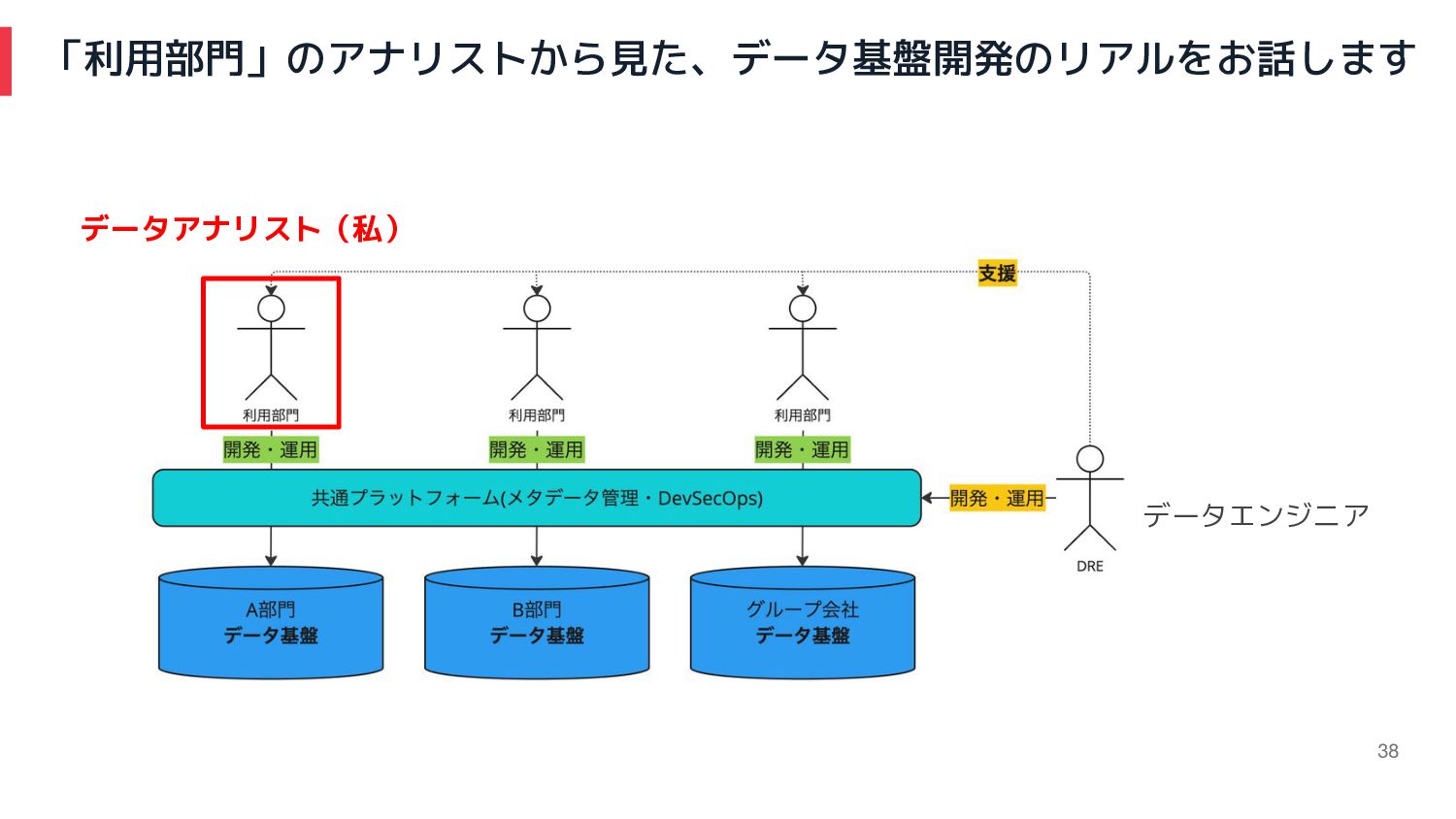
「利用部門」のアナリストから見た、データ基盤開発のリアルをお話します 38 データエンジニア データアナリスト(私)
発表者:小林 39 ◦業務経験 マーケティングリサーチャーとしてキャリアをスタート。 顧客企業向けに、アンケートやインタビュー調査、 ビジネスデータの分析などを実施してきた。 事業会社でデータ活用まで携わりたいと思い、 23年9月にデータアナリストとしてChatworkに入社。 主に、ビジネス部門向けのデータ分析・活用、 Lookerを使ったダッシュボード開発、dbtのモデル開発を担当。
リサーチャー → データアナリスト
データ基盤開発デビューまでの道 40 SECTION TITLE 1
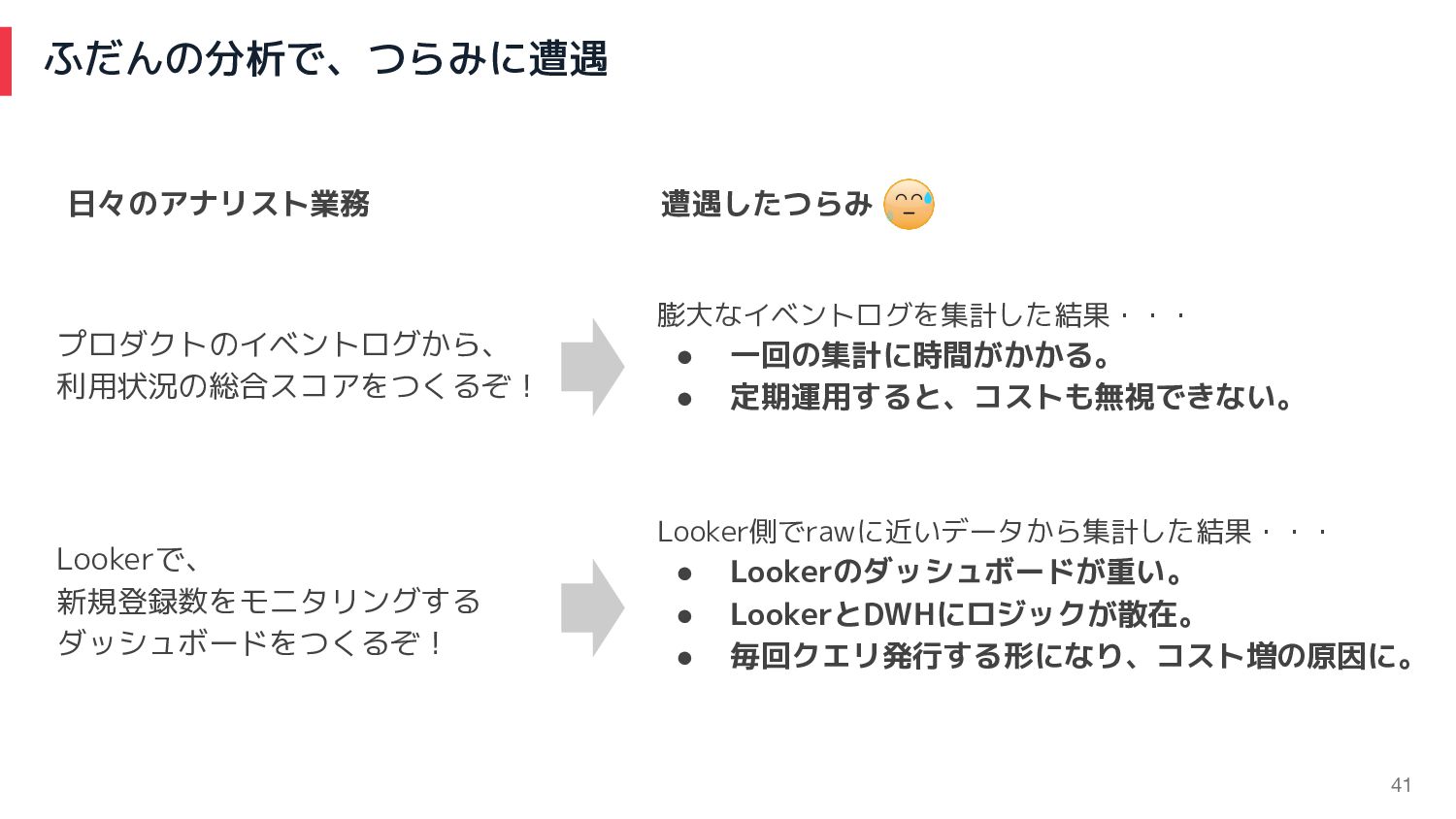
ふだんの分析で、つらみに遭遇 41 Looker側でrawに近いデータから集計した結果・・・ • Lookerのダッシュボードが重い。 • LookerとDWHにロジックが散在。 • 毎回クエリ発行する形になり、コスト増の原因に。 膨大なイベントログを集計した結果・・・
• 一回の集計に時間がかかる。 • 定期運用すると、コストも無視できない。 遭遇したつらみ 日々のアナリスト業務 Lookerで、 新規登録数をモニタリングする ダッシュボードをつくるぞ! プロダクトのイベントログから、 利用状況の総合スコアをつくるぞ!
「小林さん、dbtでモデル開発してみませんか?」 42 データエンジニアに相談したら、逆に開発に誘われる 当時の心境↓ • いやいや、無茶振りじゃないですか? • データエンジニアの仕事では?(リソースが足りないと見た ) • でも、先にdbt開発に参加していたチームメンバーは楽しそう
「まあ、いい機会だし、できる範囲でやるか」くらいの気持ちで参加
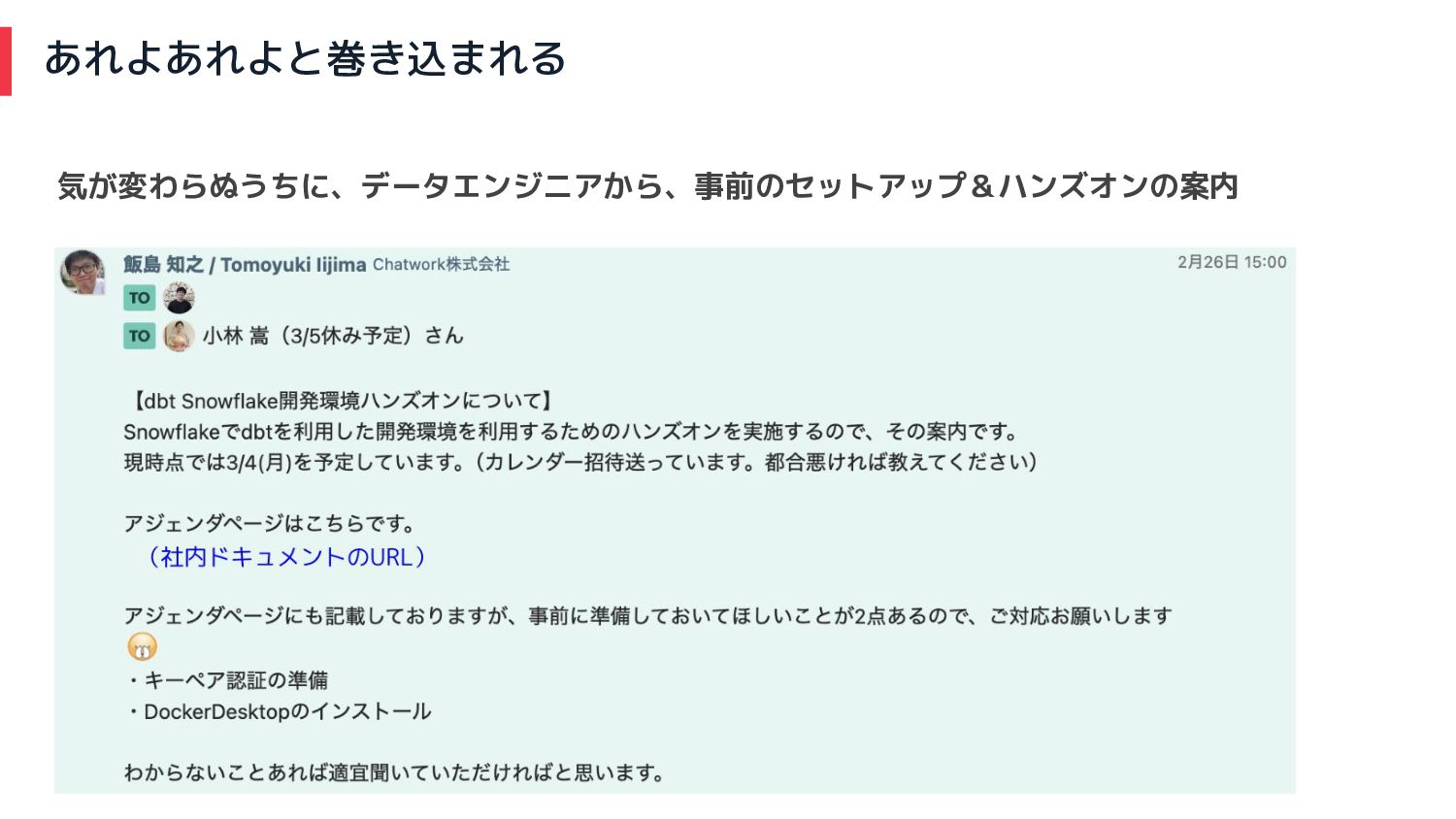
あれよあれよと巻き込まれる 気が変わらぬうちに、データエンジニアから、事前のセットアップ&ハンズオンの案内
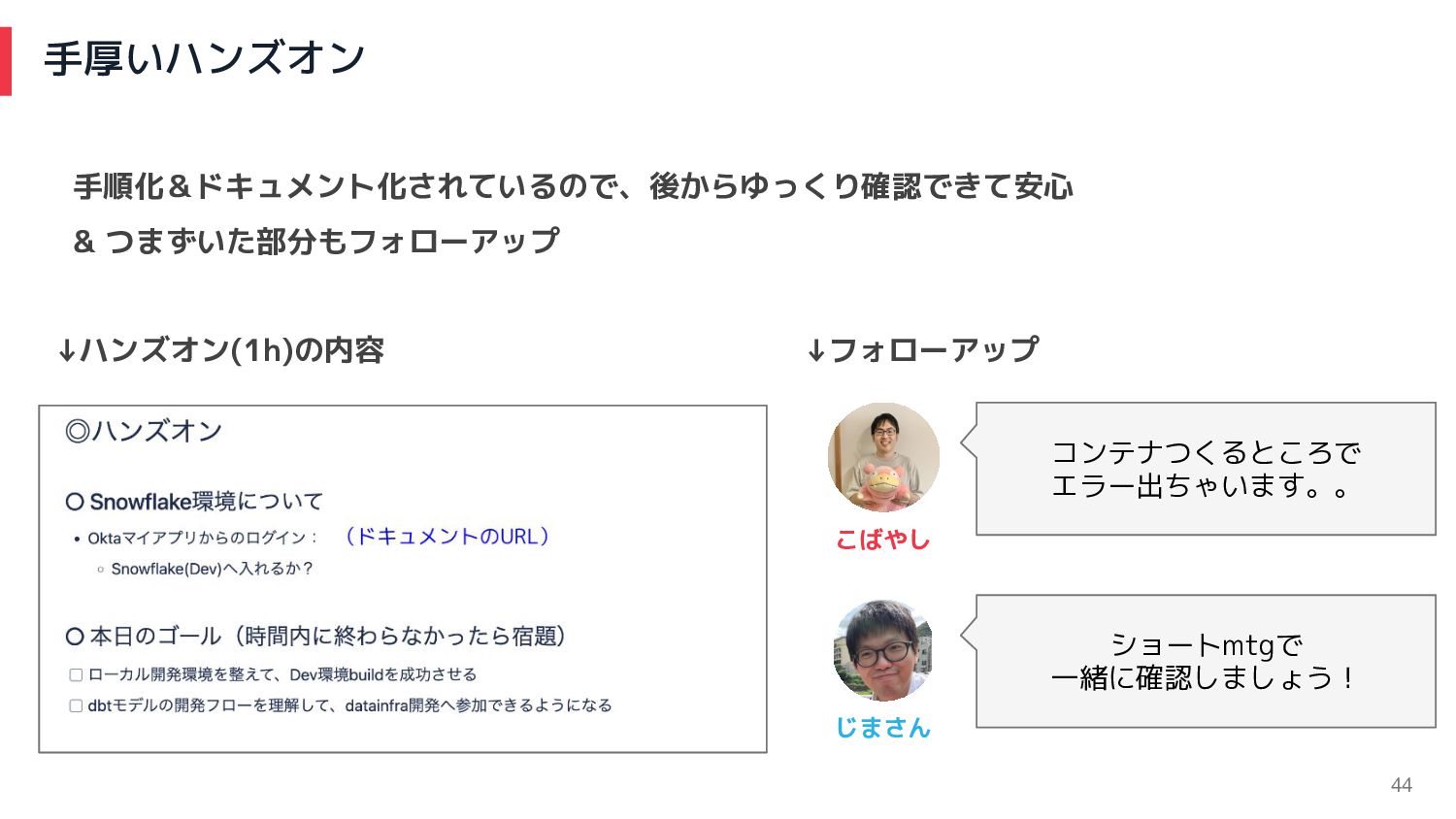
手厚いハンズオン 44 手順化&ドキュメント化されているので、後からゆっくり確認できて安心 & つまずいた部分もフォローアップ ↓ハンズオン(1h)の内容 ↓フォローアップ こばやし じまさん コンテナつくるところで
エラー出ちゃいます。。 ショートmtgで 一緒に確認しましょう!
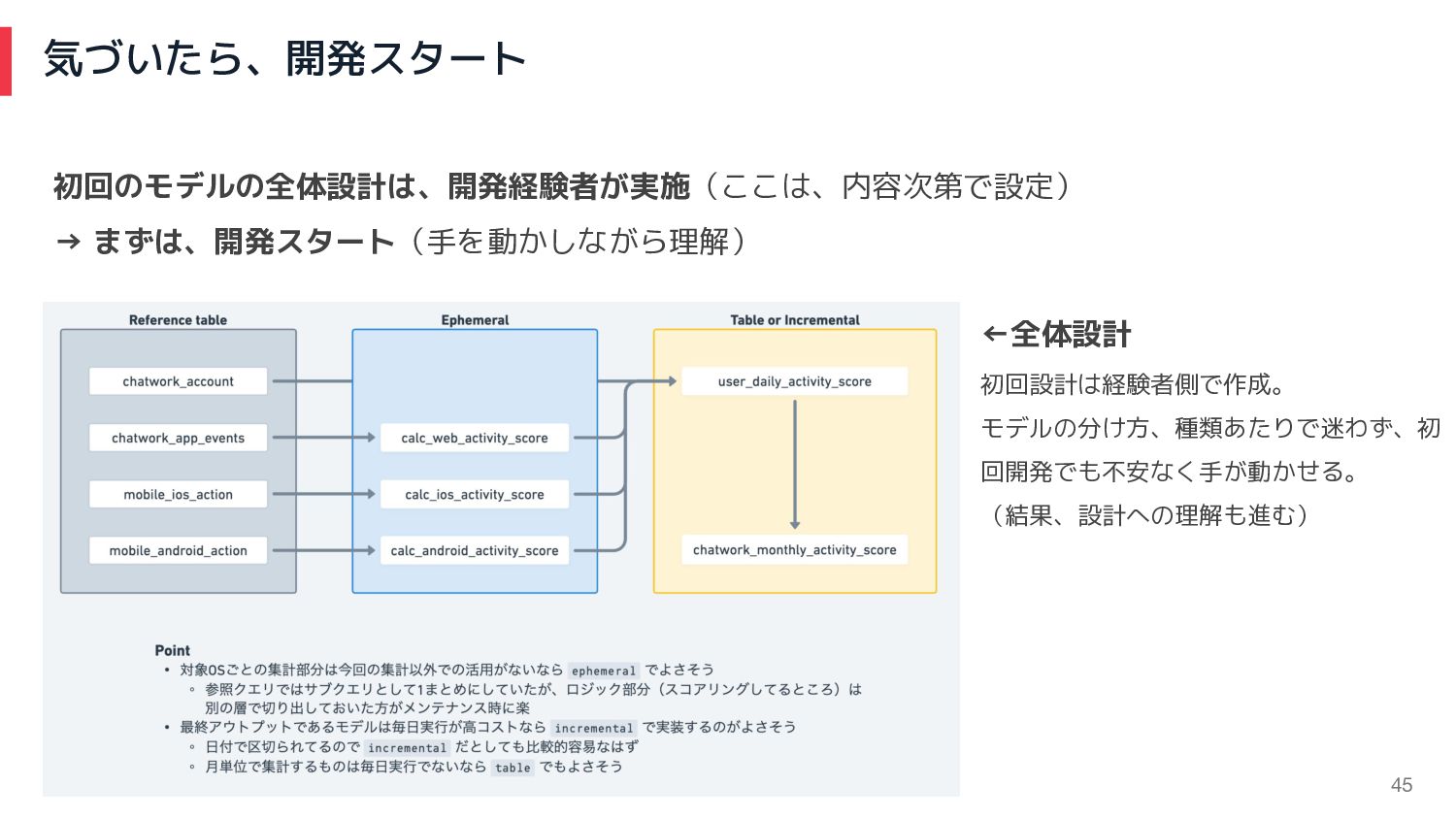
気づいたら、開発スタート 45 初回のモデルの全体設計は、開発経験者が実施(ここは、内容次第で設定) → まずは、開発スタート(手を動かしながら理解) ←全体設計 初回設計は経験者側で作成。 モデルの分け方、種類あたりで迷わず、初 回開発でも不安なく手が動かせる。 (結果、設計への理解も進む)
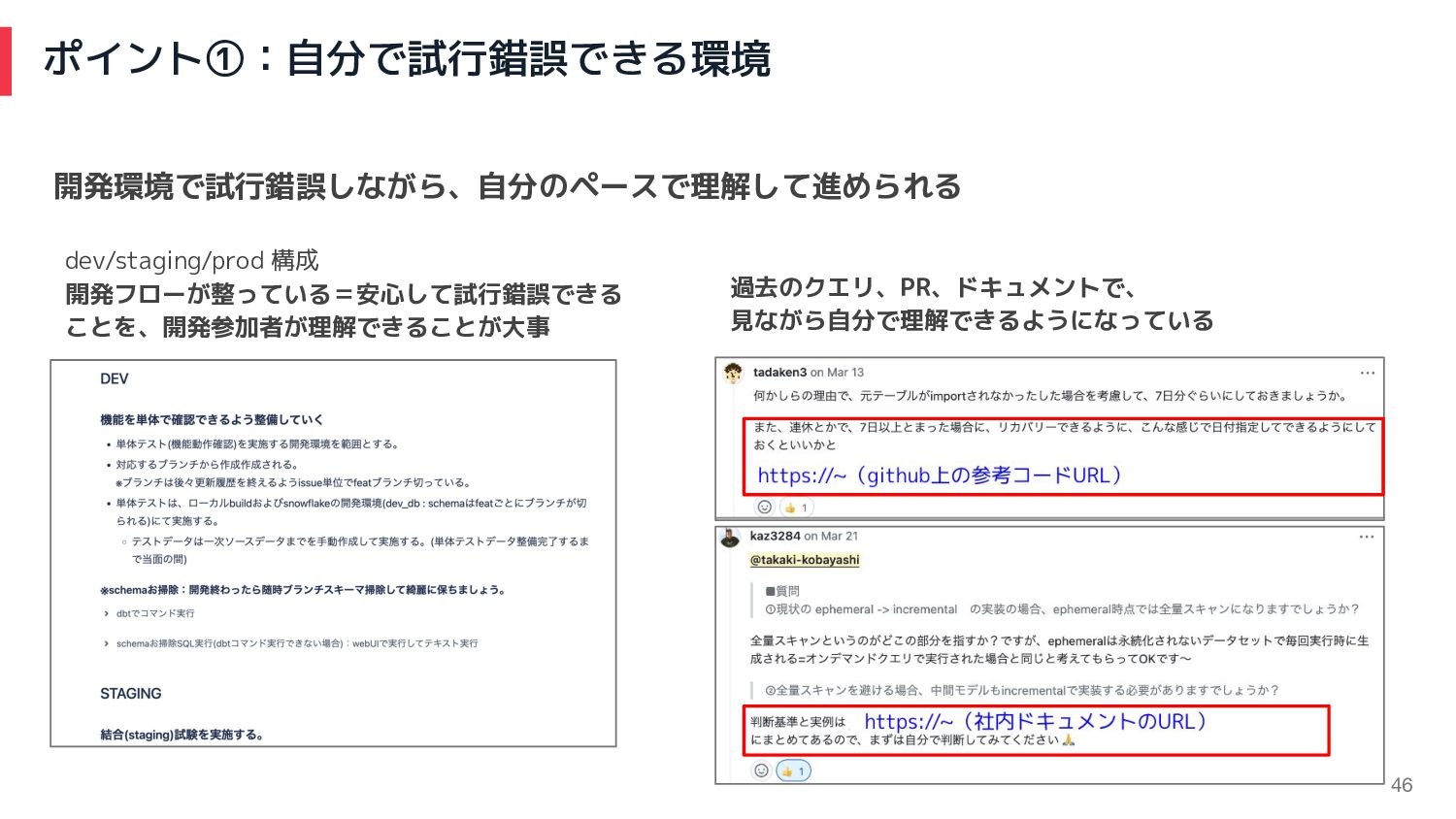
ポイント①:自分で試行錯誤できる環境 46 dev/staging/prod 構成 開発フローが整っている=安心して試行錯誤できる ことを、開発参加者が理解できることが大事 過去のクエリ、PR、ドキュメントで、 見ながら自分で理解できるようになっている 開発環境で試行錯誤しながら、自分のペースで理解して進められる
ポイント②:「便利で楽しい」を実感する開発体験 47 実際に触ってみることで、dbtの良さも実感できる ↓アナリスト視点で、感動した点 • dbt build一発で、モデル&テストがぶわーっとできる • 今まで手動でやっていたテストが自動で走る •
マクロを使って、クエリがスッキリ書ける ↓思わず感動を報告する私
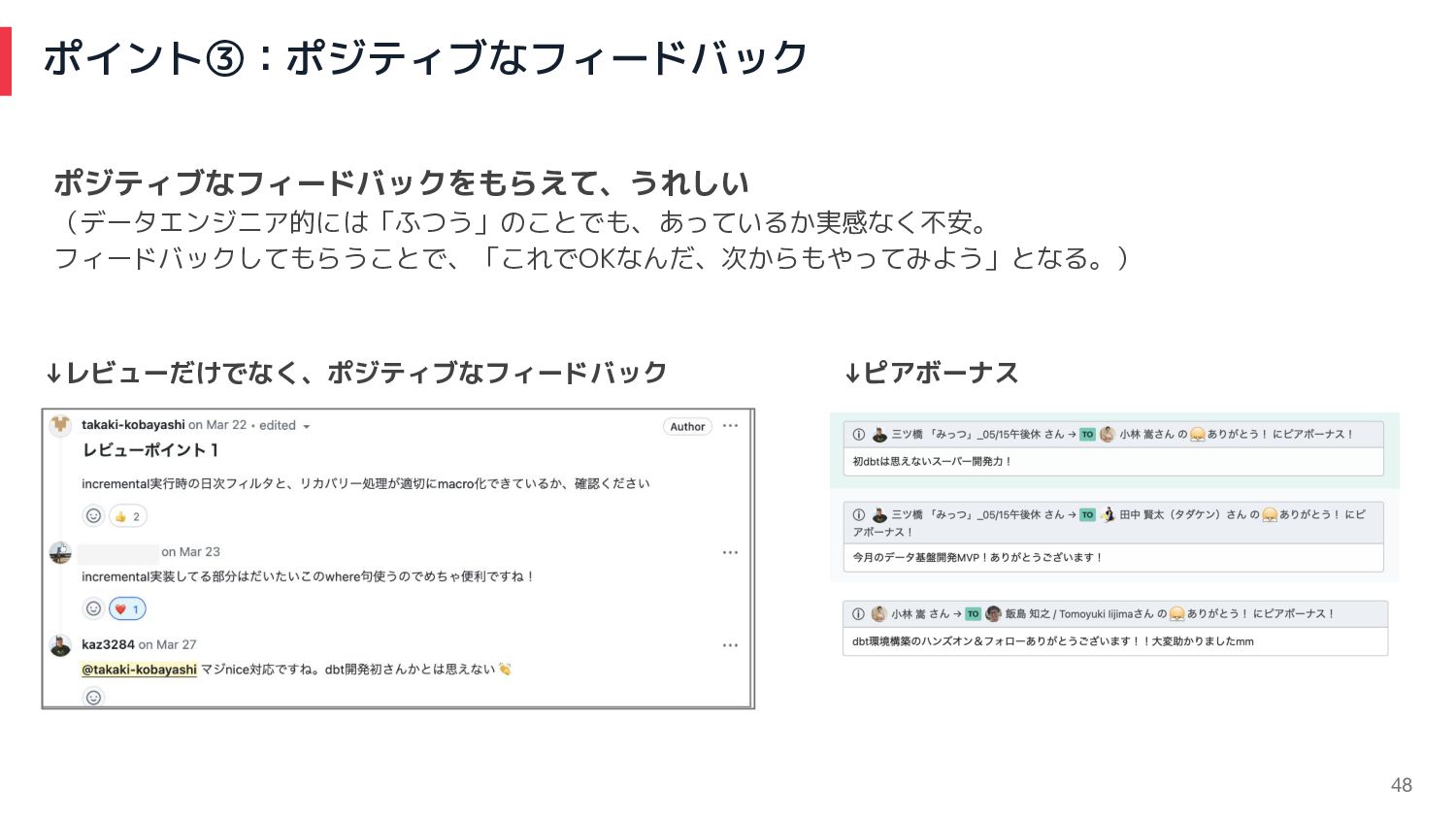
ポイント③:ポジティブなフィードバック 48 ↓レビューだけでなく、ポジティブなフィードバック ↓ピアボーナス ポジティブなフィードバックをもらえて、うれしい (データエンジニア的には「ふつう」のことでも、あっているか実感なく不安。 フィードバックしてもらうことで、「これでOKなんだ、次からもやってみよう」となる。)
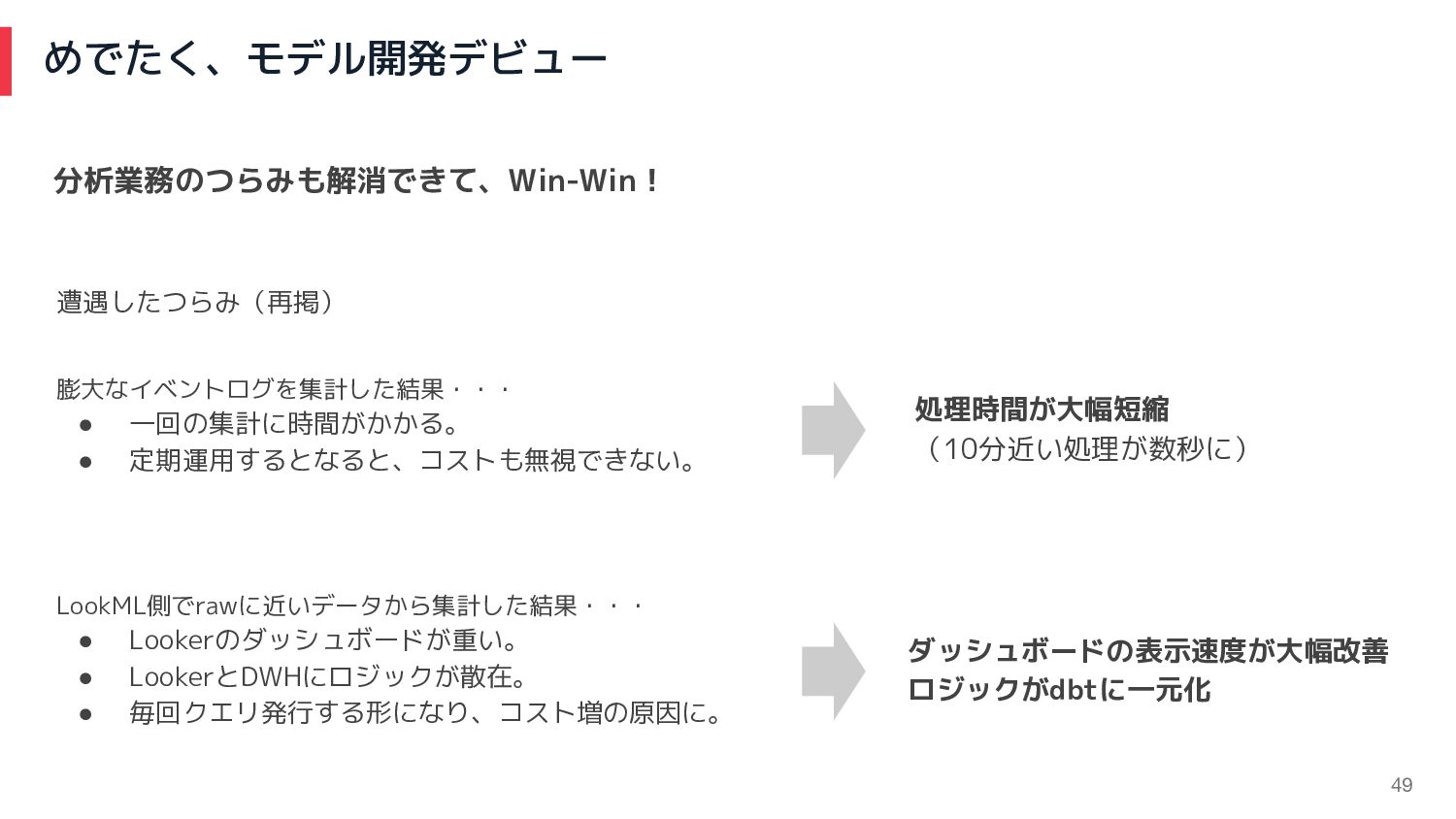
めでたく、モデル開発デビュー 49 LookML側でrawに近いデータから集計した結果・・・ • Lookerのダッシュボードが重い。 • LookerとDWHにロジックが散在。 • 毎回クエリ発行する形になり、コスト増の原因に。 膨大なイベントログを集計した結果・・・
• 一回の集計に時間がかかる。 • 定期運用するとなると、コストも無視できない。 遭遇したつらみ(再掲) ダッシュボードの表示速度が大幅改善 ロジックがdbtに一元化 処理時間が大幅短縮 (10分近い処理が数秒に) 分析業務のつらみも解消できて、Win-Win!
データ基盤開発に データ基盤「利用部門」を巻き込むには 50 SECTION TITLE 2
データ基盤「利用部門」がジョインするために、ポイントだった点 51 • やっている人が楽しそう & ポジティブなフィードバック ◦ 「dbt開発楽しいですよ」 ◦ 「ここの実装いいですね!こうすればもっとよくなりますよ!」
• 開発環境の構築がラク&手厚いサポート ◦ dbt + コンテナベースの開発環境 ◦ データエンジニアがハンズオン形式でサポート • 自分で試行錯誤できる環境 ◦ 一定開発が進んでおり、過去のクエリやPR、ドキュメントを見れば、なんとなくわかる ◦ dev/stag/prod構成の開発フローが理解でき、dev環境で安心して試行錯誤できる • 「便利で楽しい」を実感する開発体験 ◦ dbt buildでモデルがぶわーっとできる ◦ 今まで手動でやっていたテストが自動で走る ◦ マクロ機能で、クエリがスッキリ書ける
利用部門が参加する/巻き込むメリット 52 【利用部門側のメリット】 • データ基盤に、ビジネス部門のニーズを直接・素早く反映できる • 工程を理解することで、自分が使うデータへの信頼感 が高まる 【利用部門を巻き込むメリット】 •
開発リソースが増える(利用拡大に応じて開発リソースもスケールする) • データ基盤のファンが増える(浸透に協力してくれる人が増える) • 利用部門が、dbtモデル化できないか?と考えるようになる -> レビューされたロジックがdbtに一元化されるので、データカオス化しづらい • 利用部門目線でデータに疑問があった際に、自分である程度調査できる -> ドメイン知識観点でのデータ品質の向上につながる
これからのチャレンジ 53 • ユースケースに応じた、dbtモデル & BI層の開発・浸透 (dbt + Looker、Exploratory、Streamlit、・・・) •
ビジネス部門用ツールとのパイプライン構築 (↔Salesforce、スプレッドシート、・・・) • ビジネス部門と協働で、データ品質を向上する取り組み (広告用マスタの整備・運用、Salesforceデータの最適化、・・・) 一緒に作ってくださる方を絶賛募集中です! まだまだやりたいことはたくさん・・・
働くをもっと楽しく、創造的に
© Chatwork 我が社が考える最強のデータ基盤・開発体制! アナリスト x エンジニアの最強バディ 2024年05月22日 プロダクトエクスペリエンスユニット プロダクトオペレーションチーム
田中 賢太
自己紹介 56 • 田中賢太(たなかけんた) • @tadaken3(タダケン) • Chatwork ← LINE
← 任天堂 • データアナリスト • データをいい感じに集計・分析して、プロダクトの成長に繋げる • 嫁と子供(3歳👦)と3人ぐらし • 趣味:レトロゲーム集め https://chado.chatwork.com/entry/2024/03/12/100000 インタビュー
前回のハイライト
前回の「我が社が考える最強のデータ基盤'24最新版」 58
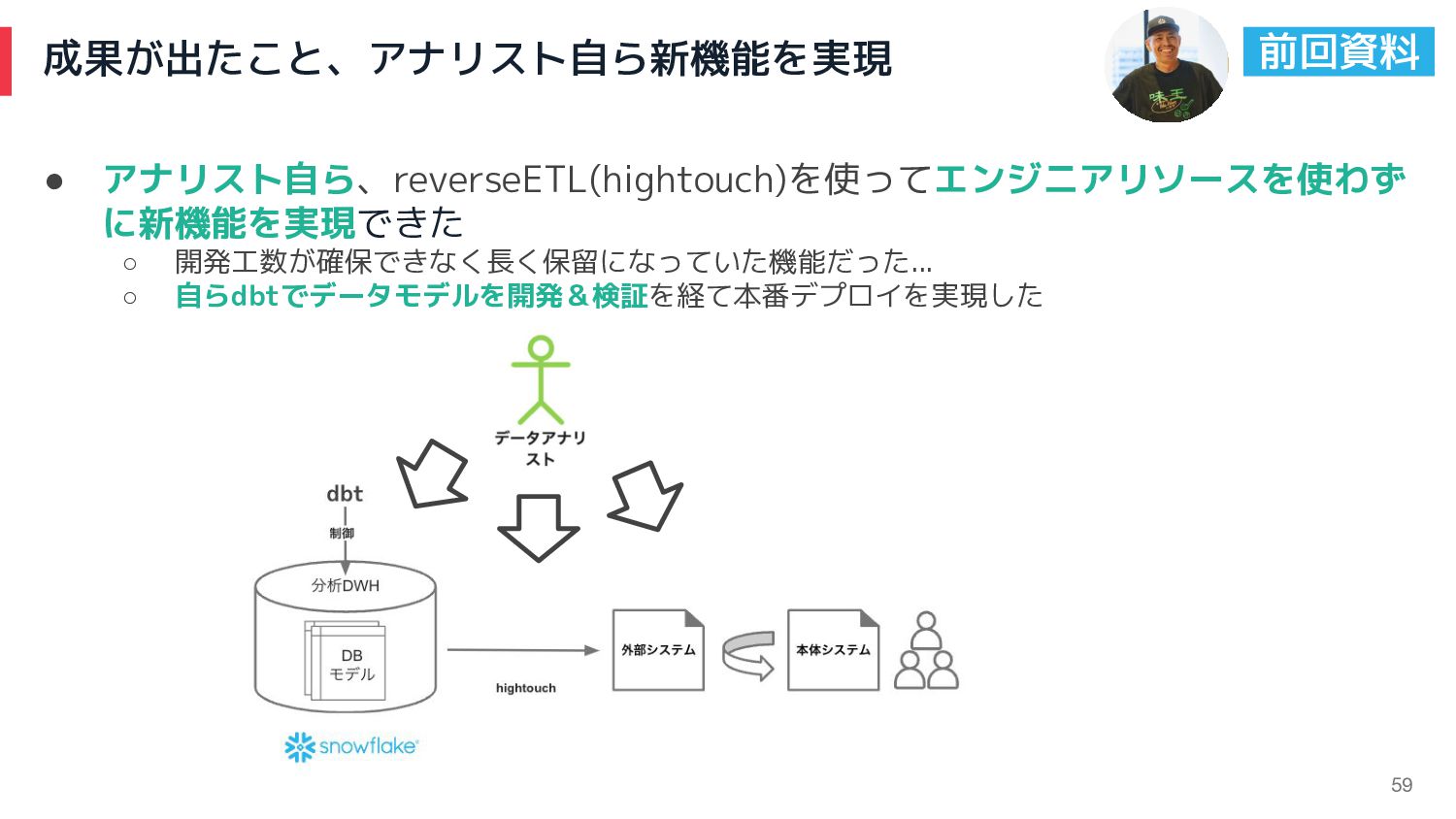
成果が出たこと、アナリスト自ら新機能を実現 59 • アナリスト自ら、reverseETL(hightouch)を使ってエンジニアリソースを使わず に新機能を実現できた ◦ 開発工数が確保できなく長く保留になっていた機能だった... ◦ 自らdbtでデータモデルを開発&検証を経て本番デプロイを実現した 前回資料
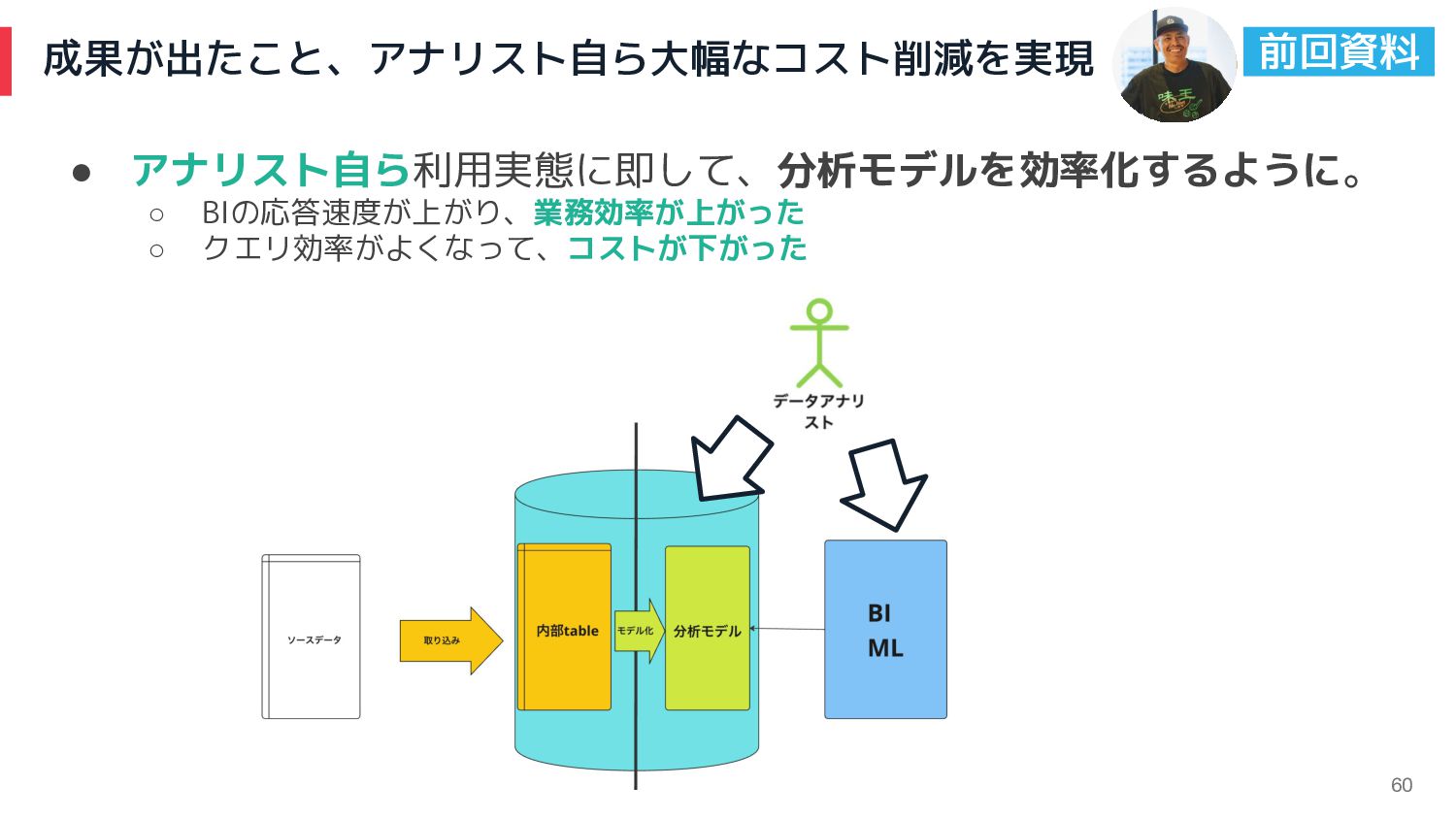
成果が出たこと、アナリスト自ら大幅なコスト削減を実現 60 • アナリスト自ら利用実態に即して、分析モデルを効率化するように。 ◦ BIの応答速度が上がり、業務効率が上がった ◦ クエリ効率がよくなって、コストが下がった 前回資料
• 利用部門が自分たちで開発するとか、アナリストの人が開発なしで 新機能実現とかすごい。いい話すぎる • アナリストだけでリバースETL構築。素晴らしい • 「アナリストが自ら分析機能を実現した」のは大きいな、データ民主 化はもはや当たり前で「データ分析」の民主化が必要 • データの利用者たちが横串でデータを利用できるようになることって
素敵。DataOpsだなあ 「我が社が考える最強のデータ基盤'24最新版」の反響 61 実際のX(旧Twitter)のコメントはこちら https://twitter.com/hashtag/ChatworkTechTalk?src=hashtag_click&f=live
それ、ワタシです 62
今日話すこと 63 データアナリストからみた並列開発体制の オモテガワとウラガワ
並列開発体制のオモテガワ
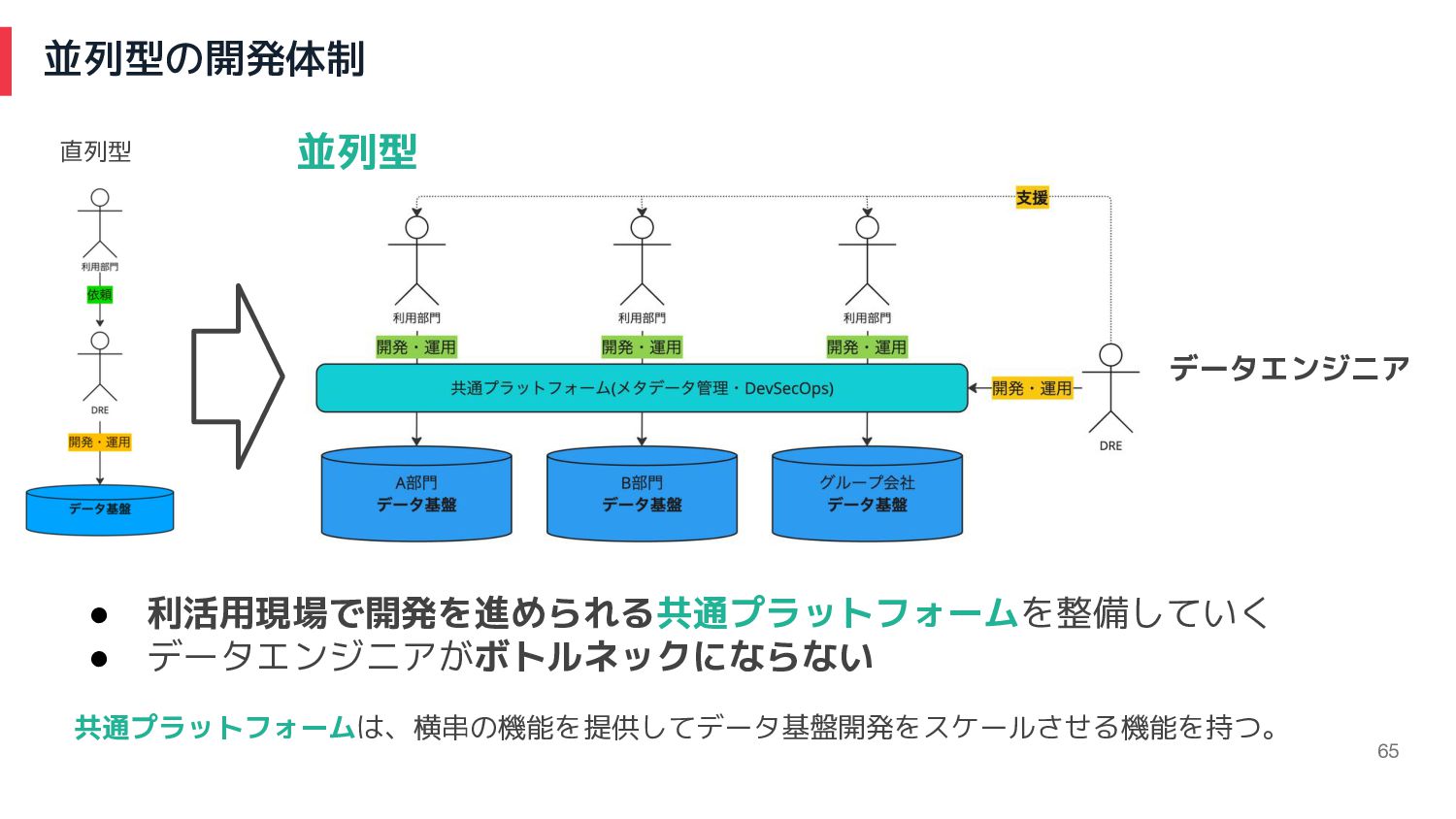
並列型の開発体制 65 データエンジニア • 利活用現場で開発を進められる共通プラットフォームを整備していく • データエンジニアがボトルネックにならない 共通プラットフォームは、横串の機能を提供してデータ基盤開発をスケールさせる機能を持つ。 直列型 並列型
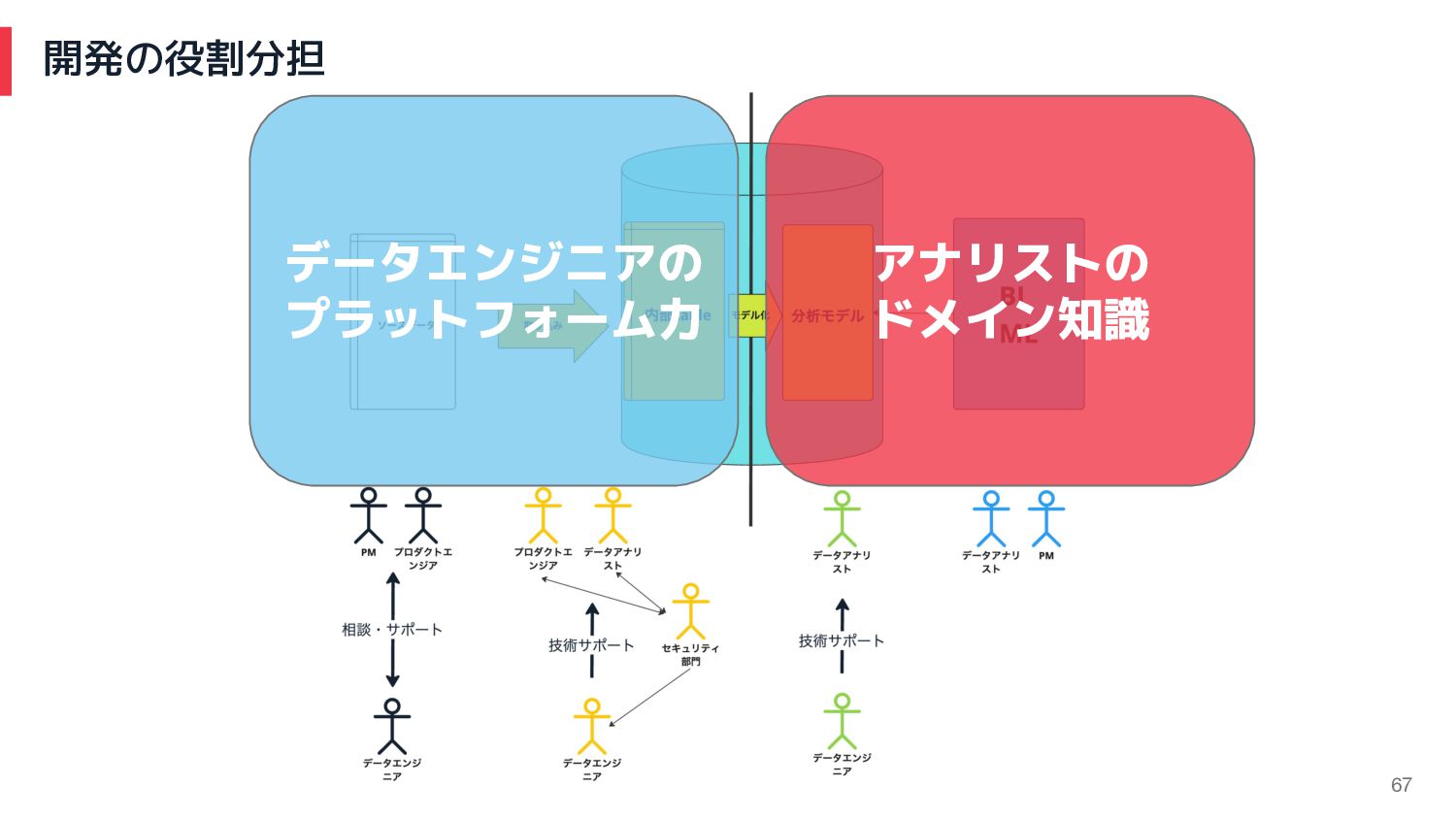
開発の役割分担 66
開発の役割分担 67 データエンジニアの プラットフォーム力 アナリストの ドメイン知識
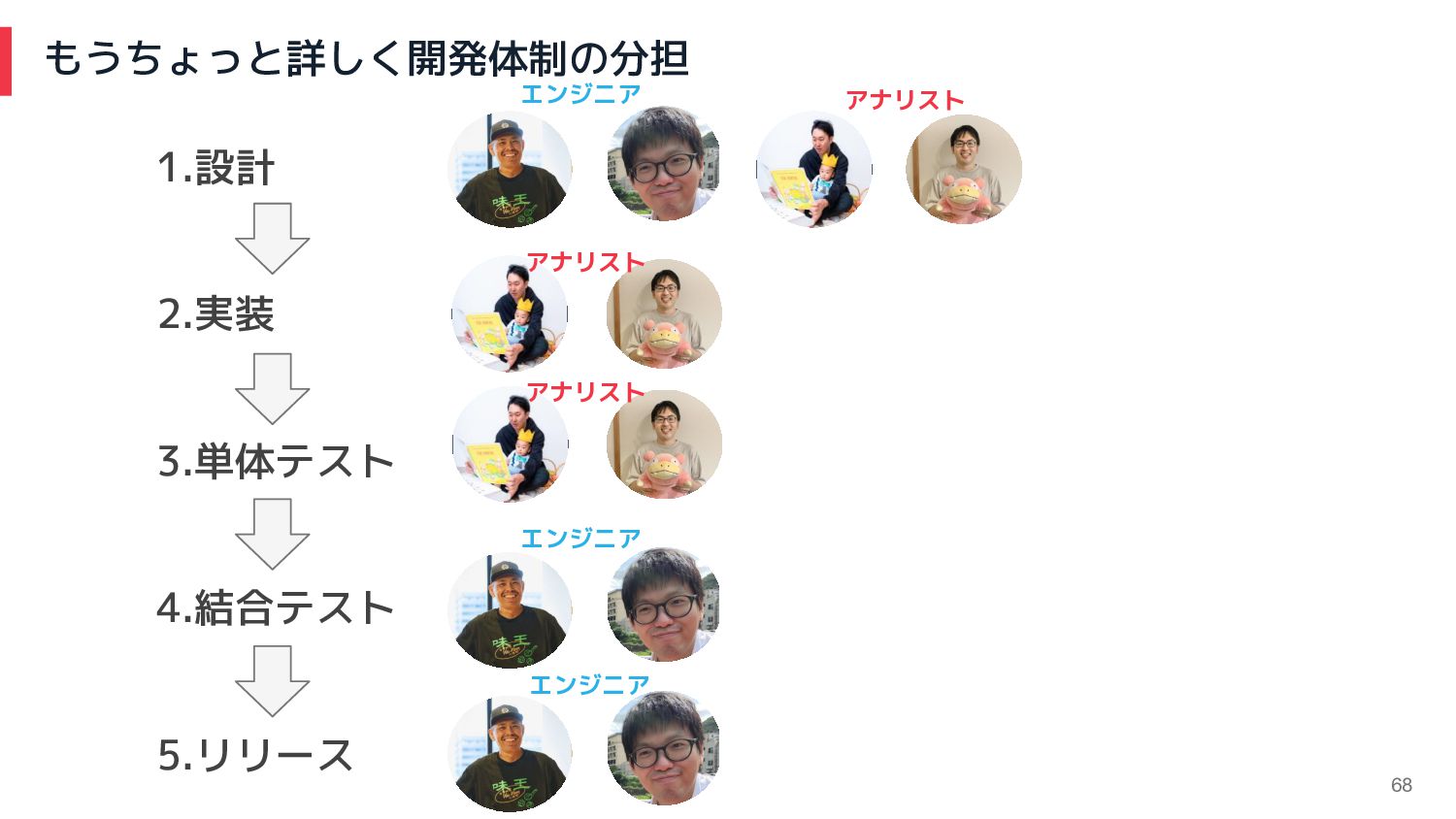
68 もうちょっと詳しく開発体制の分担 1.設計 2.実装 3.単体テスト 4.結合テスト 5.リリース エンジニア アナリスト エンジニア
エンジニア アナリスト アナリスト
並列開発体制のハジマリ (オモテガワ)
70 並列開発体制のハジマリ タダケン目線 dbtの開発に入りたい場合、以下のドキュメントを参考に、 開発コンテナをbuildするって感じでい ですよね?(すみません。ドキュメント見つけたので、勝手に) この辺りもご確認いただけるといいかなと思います。 操作がよくわからないとかあればMeetとかで画面共有しながらフォローとかも できますので、相談ください〜 基本的にはそうなります。
ただ、キャプチャのgitブランチ切ってないのでbuildは失敗します。 ブランチとタスクを紐づけるために こちらから〜検証みたいなタスク切った上でそれに紐づくブランチを作成して、 buildいただけると通るかと(新Dev環境整備中なので、できたら環境が切り替わ る感じにはなりますが じまさん みっつさん タダケン
全てはここから始まった (アナリストとしてdbt開発の第一号として飛び込む)
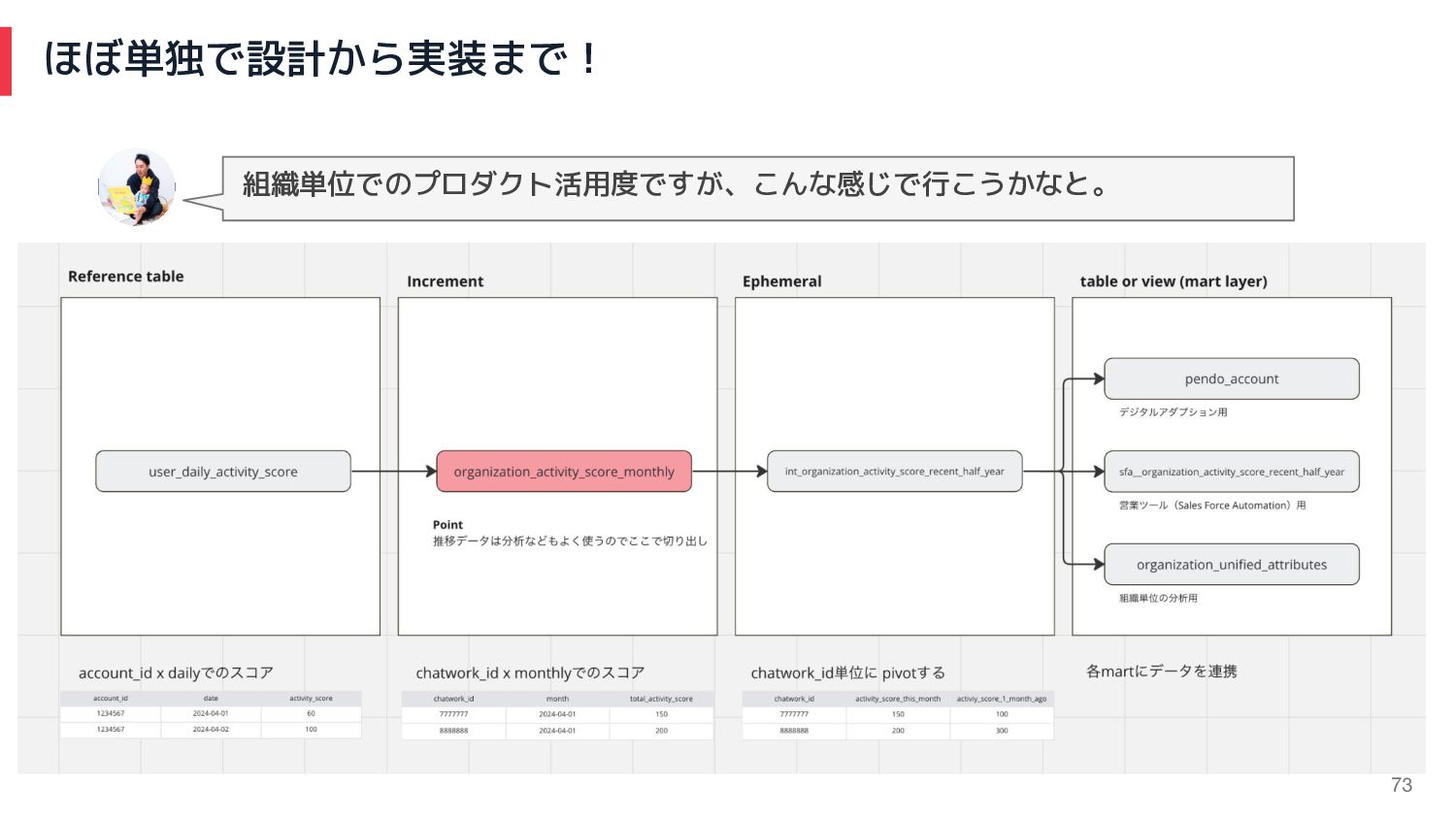
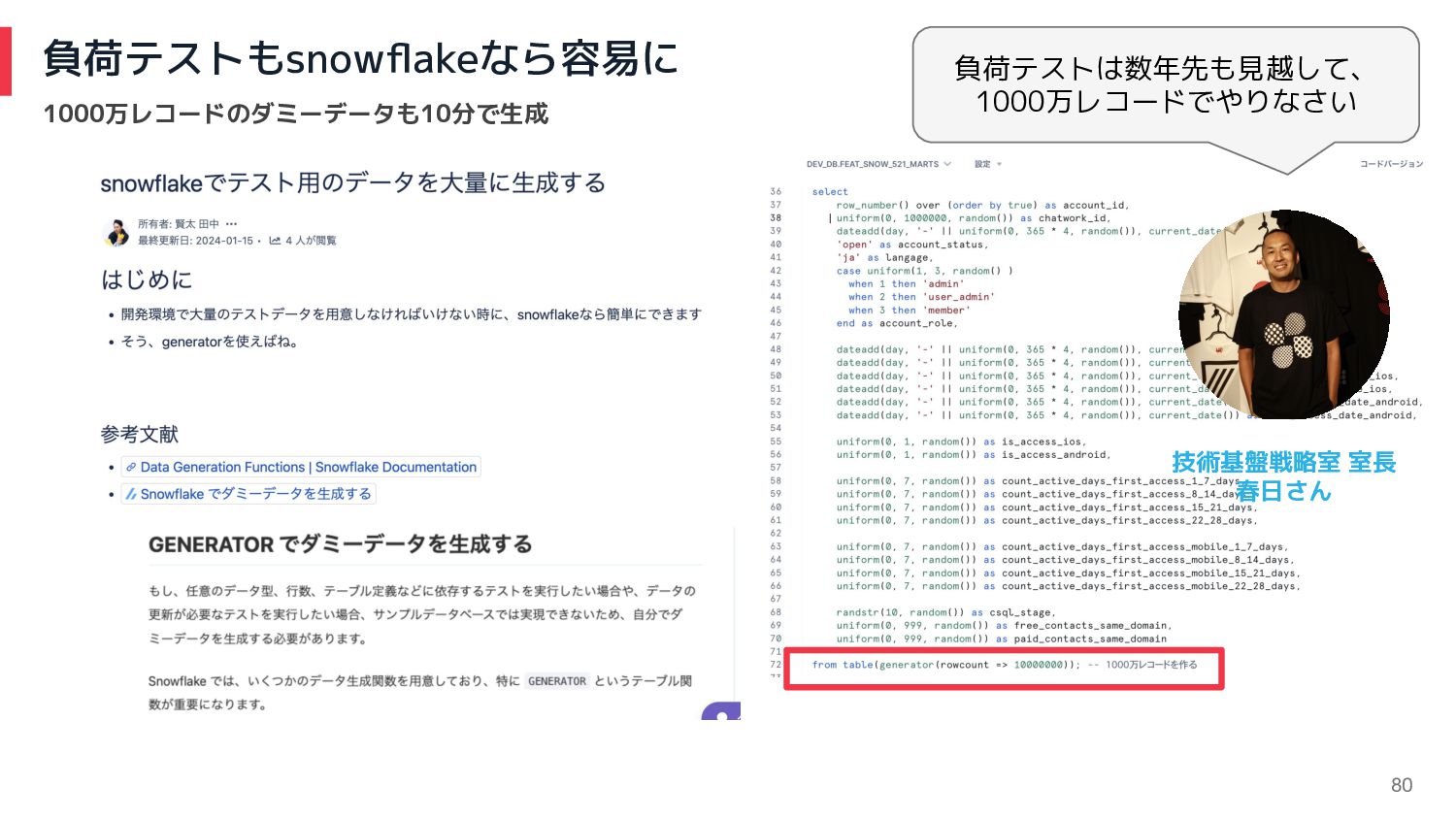
72 最初は既存モデルの修正から手をつけて、、、 やったこと 1. 既存のmodelの修正(まずはdbtになれる) 2. 既存のincremental modelの修正(差分更新の場合のお作法を学ぶ) 3. seedの開発(CSVデータなどの取り込み)
4. 新規のmodelの開発
73 ほぼ単独で設計から実装まで! 組織単位でのプロダクト活用度ですが、こんな感じで行こうかなと。
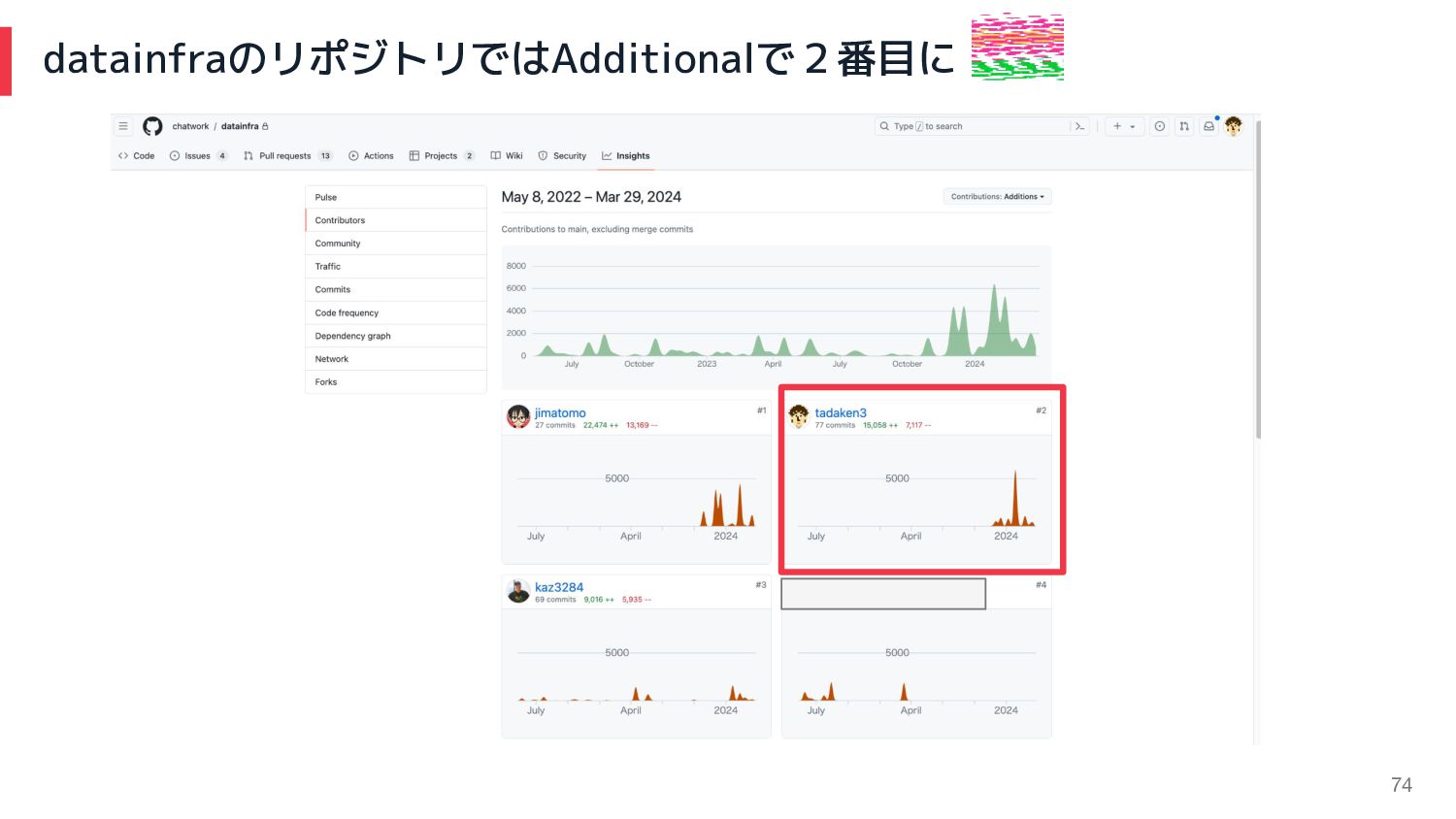
74 datainfraのリポジトリではAdditionalで2番目に
並列開発体制でのReverse ETL (オモテガワ)
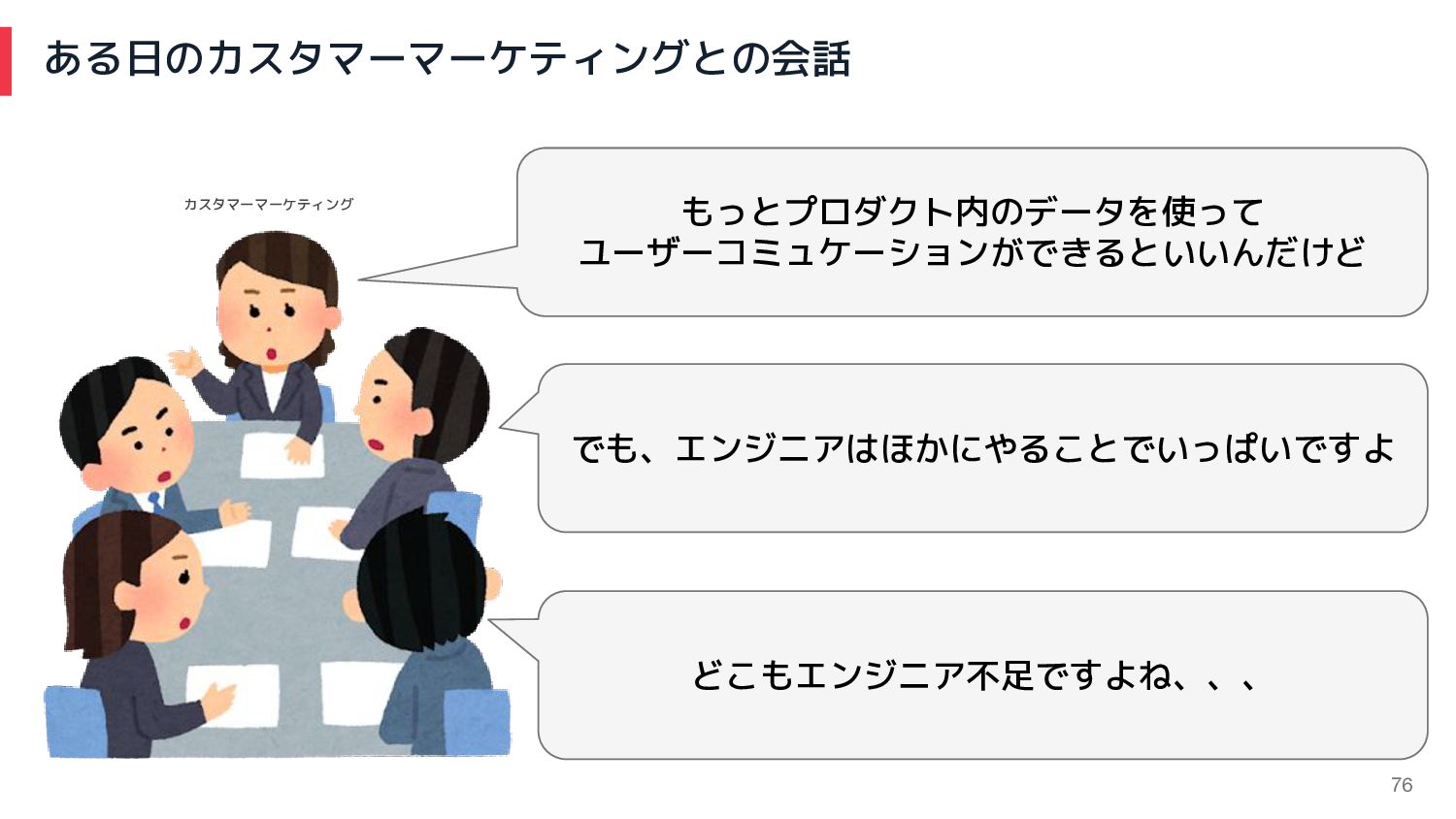
76 ある日のカスタマーマーケティングとの会話 もっとプロダクト内のデータを使って ユーザーコミュケーションができるといいんだけど でも、エンジニアはほかにやることでいっぱいですよ どこもエンジニア不足ですよね、、、 カスタマーマーケティング
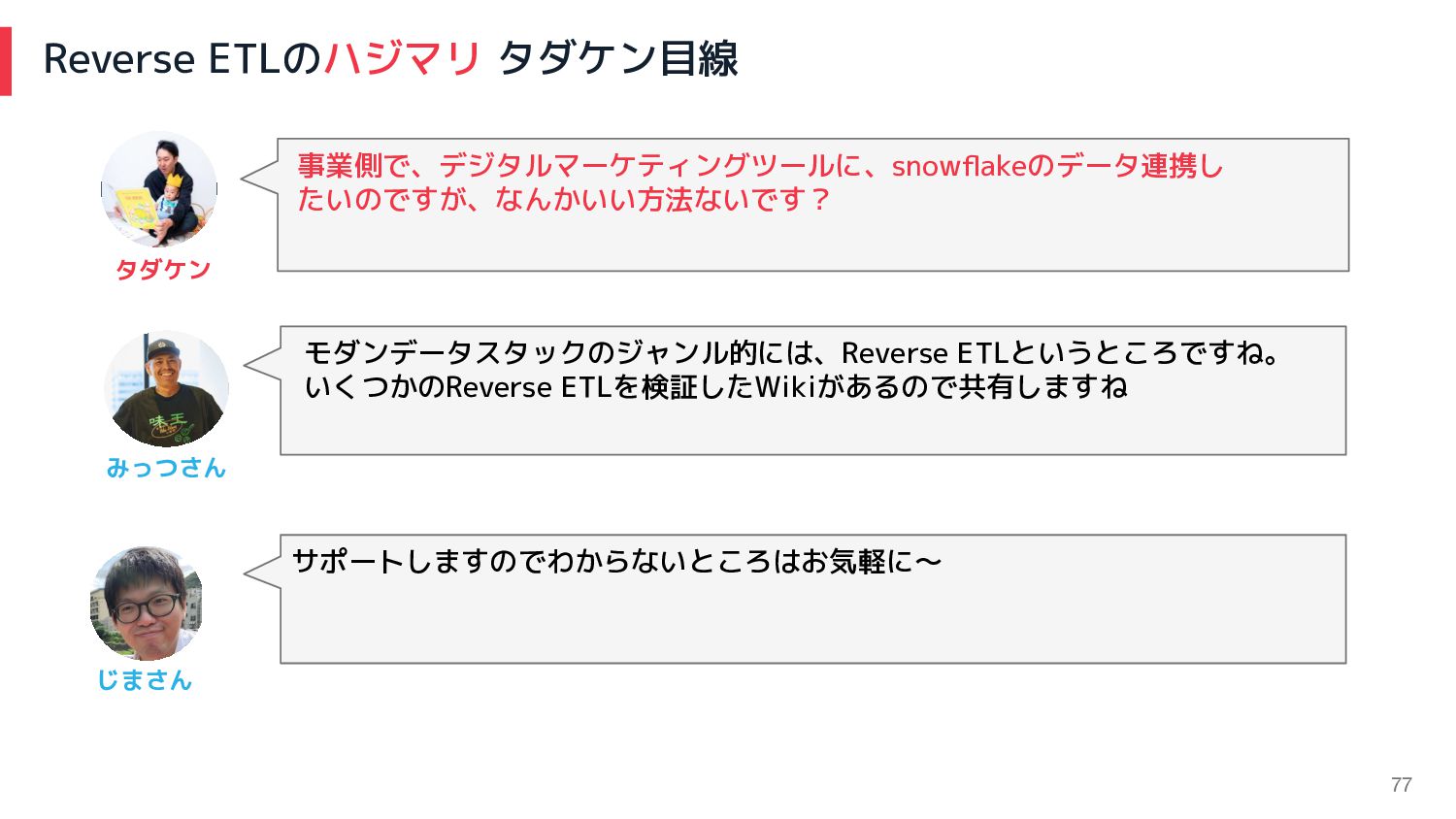
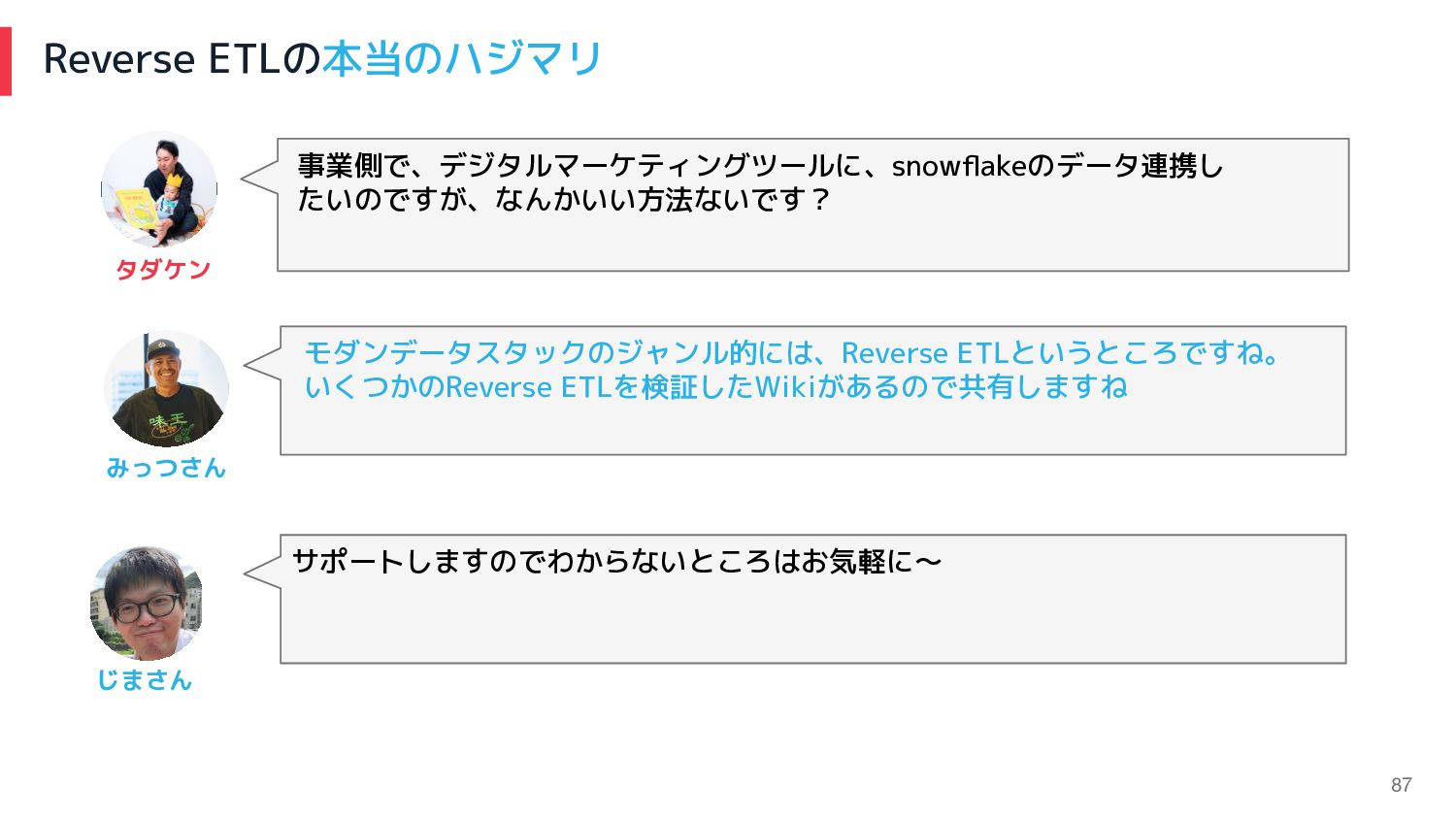
77 Reverse ETLのハジマリ タダケン目線 事業側で、デジタルマーケティングツールに、snowflakeのデータ連携し たいのですが、なんかいい方法ないです? モダンデータスタックのジャンル的には、Reverse ETLというところですね。 いくつかのReverse ETLを検証したWikiがあるので共有しますね
みっつさん タダケン サポートしますのでわからないところはお気軽に〜 じまさん
78 並列型の開発体制:Reverse ETLの実装 やったこと 1. 要求・要件整理 2. 検証(要件を満たせるか) 3. 負荷試験
4. データ連携用dbt modelの開発 5. Reverse ETLの実装
Reverse ETL 「hightouch」 79 データソースと連携先を選んで、データ連携が簡単に! 企業秘密
80 負荷テストもsnowflakeなら容易に 1000万レコードのダミーデータも10分で生成 負荷テストは数年先も見越して、 1000万レコードでやりなさい 技術基盤戦略室 室長 春日さん
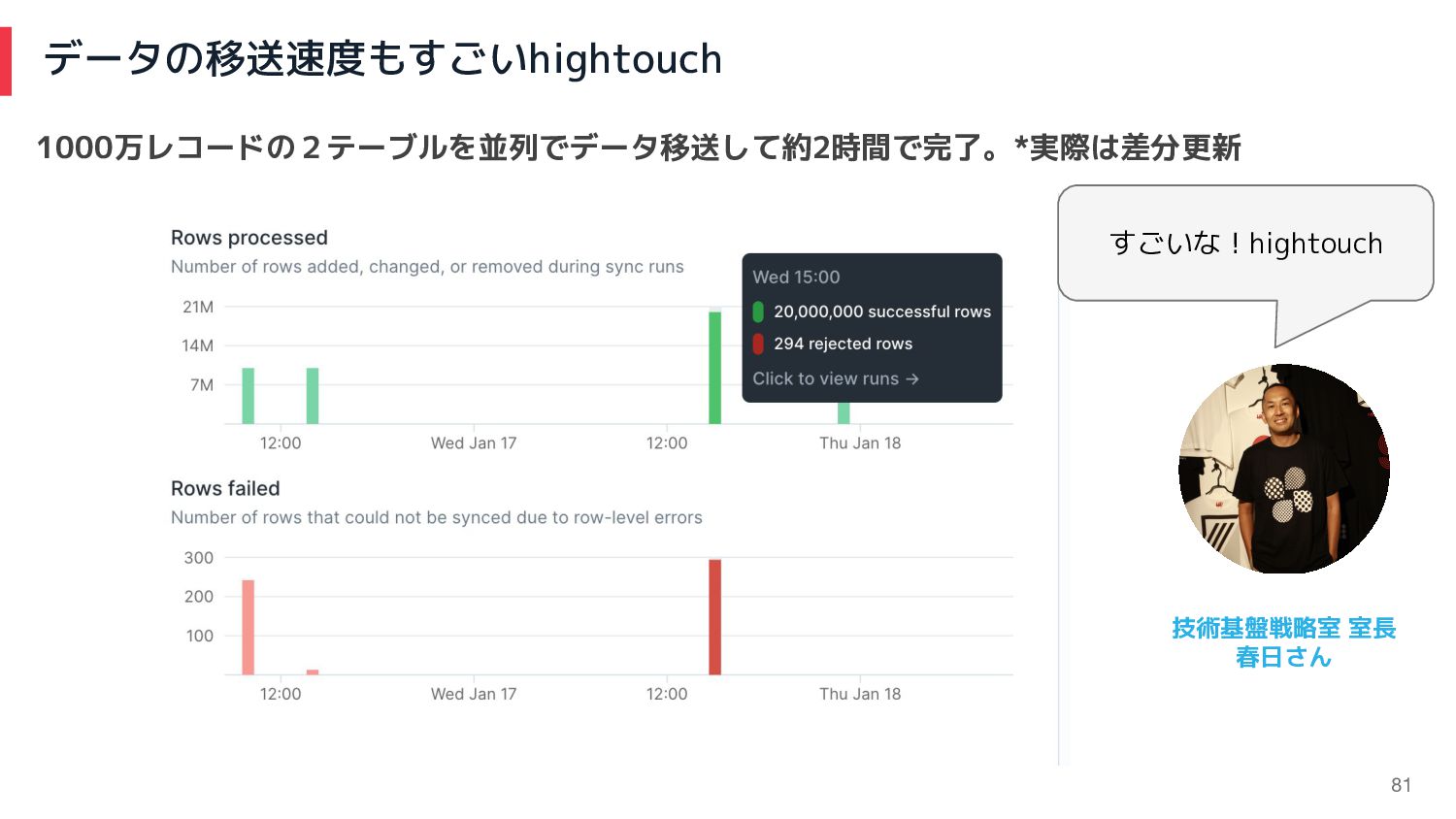
データの移送速度もすごいhightouch 81 1000万レコードの2テーブルを並列でデータ移送して約2時間で完了。*実際は差分更新 すごいな!hightouch 技術基盤戦略室 室長 春日さん
82 Reverse ETLを実装したおかげで カスタマーマーケティング アナリスト(タダケン) データに基づいて、 ユーザーコミュニケーションできるぞー 分析から施策への データ活用まで一気通貫してできるぞー
83 Reverse ETLを実装したおかげで Reverse ETLを実装したおかげで Reverse ETLを実装したおかげで Reverse ETLを実装したおかげで(2回目) エンジニアリソースを使わずに機能追加できてみんなHappy
並列開発体制のウラガワ
85 dbtの開発に入りたい場合、以下のドキュメントを参考に、 開発コンテナをbuildするって感じでい ですよね?(すみません。ドキュメント見つけたので、勝手に) この辺りもご確認いただけるといいかなと思います。 (別のドキュメントのURL) 操作がよくわからないとかあればMeetとかで画面共有しながらフォローとかも できますので、相談ください〜 基本的にはそうなります。 ただ、キャプチャのgitブランチ切ってないのでbuildは失敗します。
ブランチとタスクを紐づけるためにこちらから検証みたいなタスク切った上で それに紐づくブランチを作成して、buildいただけると通るかと 新Dev環境整備中なので、できたら環境が切り替わる感じにはなりますが じまさん みっつさん タダケン 並列開発体制の本当のハジマリ
86 dbtの開発にスッと入れた理由 • 部署を超えた協力関係 • ドキュメントがあったから飛び込めた
87 Reverse ETLの本当のハジマリ 事業側で、デジタルマーケティングツールに、snowflakeのデータ連携し たいのですが、なんかいい方法ないです? モダンデータスタックのジャンル的には、Reverse ETLというところですね。 いくつかのReverse ETLを検証したWikiがあるので共有しますね みっつさん
タダケン サポートしますのでわからないところはお気軽に〜 じまさん
Reverse ETL 「hightouch」をスッと実装できた理由は? 88 • 部署を超えた協力関係 • データエンジニアの方で、Reverese ETLの検証をしていたから •
しかも、実装が容易なモダンデータスタックで
• セルフサービスと自動化を通じて、開発業務の生産性を向上させること • アナリストチーム(not エンジニア)が開発に参加でき、より迅速に価値を提供できる • エンジニアは、プラットフォームをより拡充させる業務に取り組むことが可能 • 将来的には、生成AIを活用し、オペレーションチームやビジネスチームも 開発に参加できるかも
プラットフォームエンジニアリングとは? 89 *ガードナーが2022に提唱した概念 cf. https://www.gartner.co.jp/ja/articles/what-is-platform-engineering
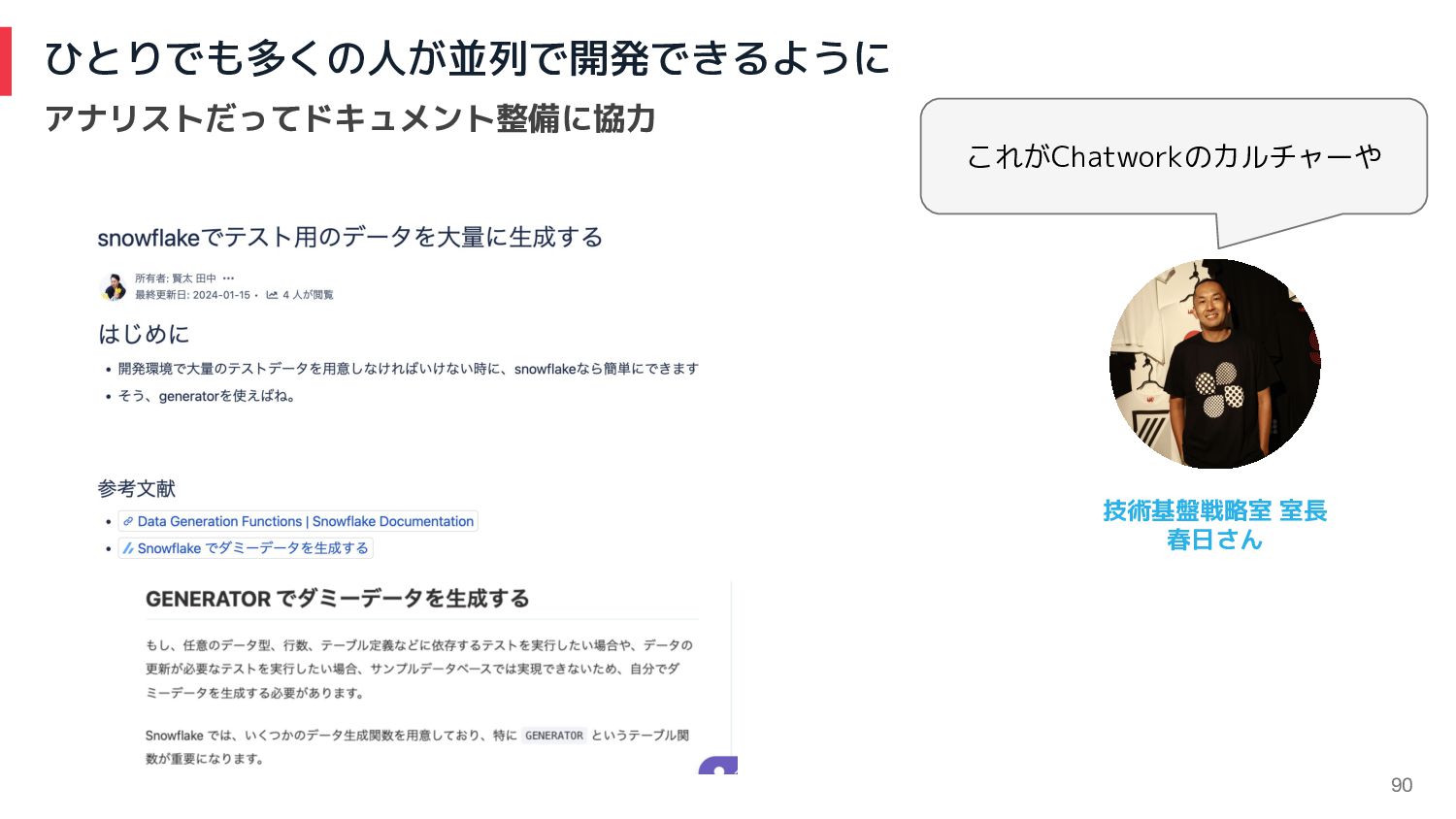
90 ひとりでも多くの人が並列で開発できるように アナリストだってドキュメント整備に協力 これがChatworkのカルチャーや 技術基盤戦略室 室長 春日さん
まとめ
まとめ 92 • 我が社が考える最強の開発体制は「並列開発体制」 ◦ データエンジニアとアナリストのバディ≒協業 • プラットフォームエンジニアリング ◦ ドキュメントの拡充
◦ マネージドされたサービスの利用(モダンデータスタック) エンジニア アナリスト えらい人
働くをもっと楽しく、創造的に
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}