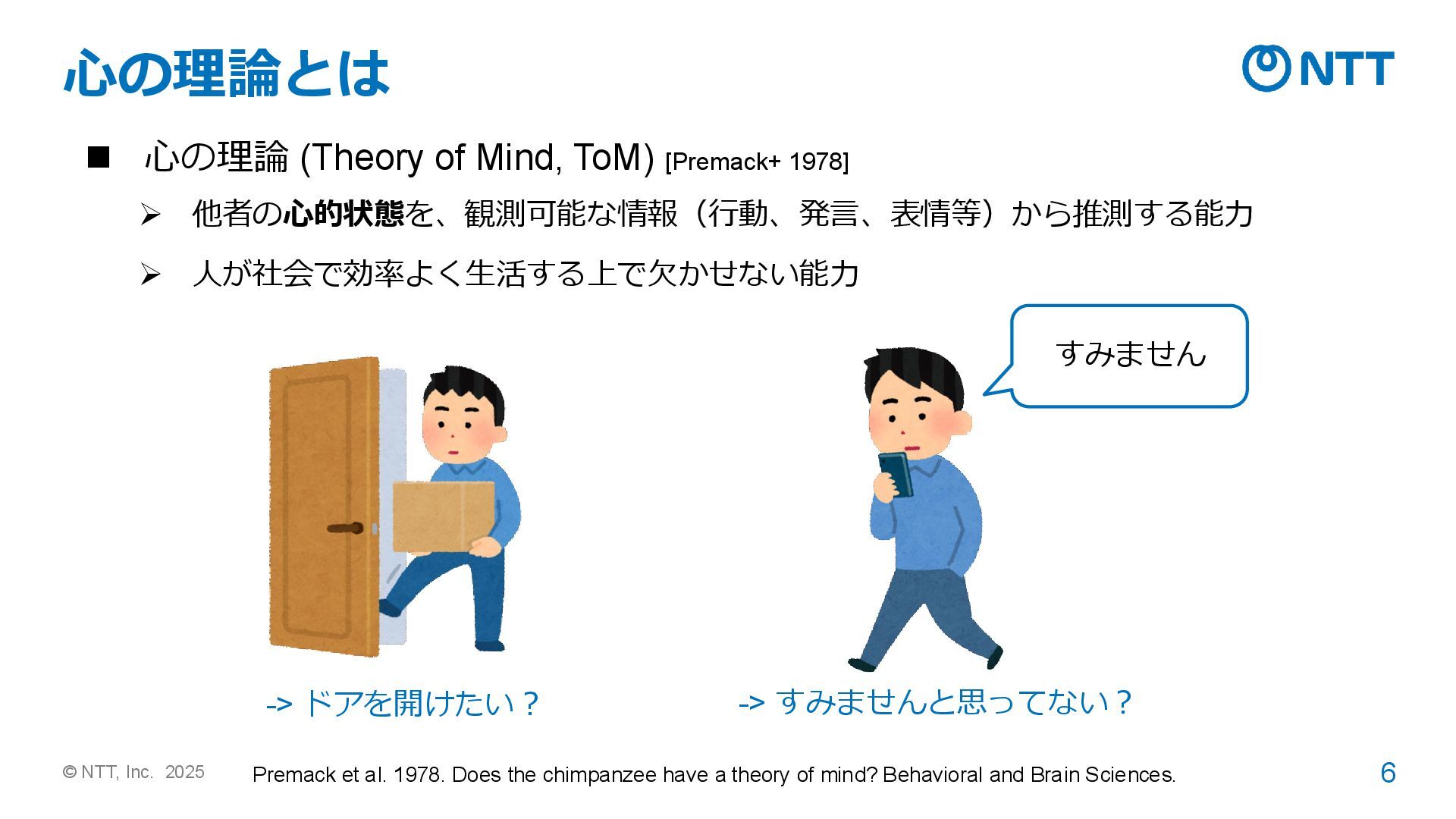
Mind, ToM) [Premack+ 1978] ➢ 他者の心的状態を、観測可能な情報(行動、発言、表情等)から推測する能力 ➢ 人が社会で効率よく生活する上で欠かせない能力 -> ドアを開けたい? すみません -> すみませんと思ってない? Premack et al. 1978. Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences.
[Beaudoin+ 2020] Y ≠ X のとき、 ≔ T についての 誤信念 (False Belief about T) という X が事実と異なるとき、誤信念 (False Belief) という Beaudoin et al. 2020. Systematic Review and Inventory of Theory of Mind Measures for Young Children. Frontiers in Psychology.
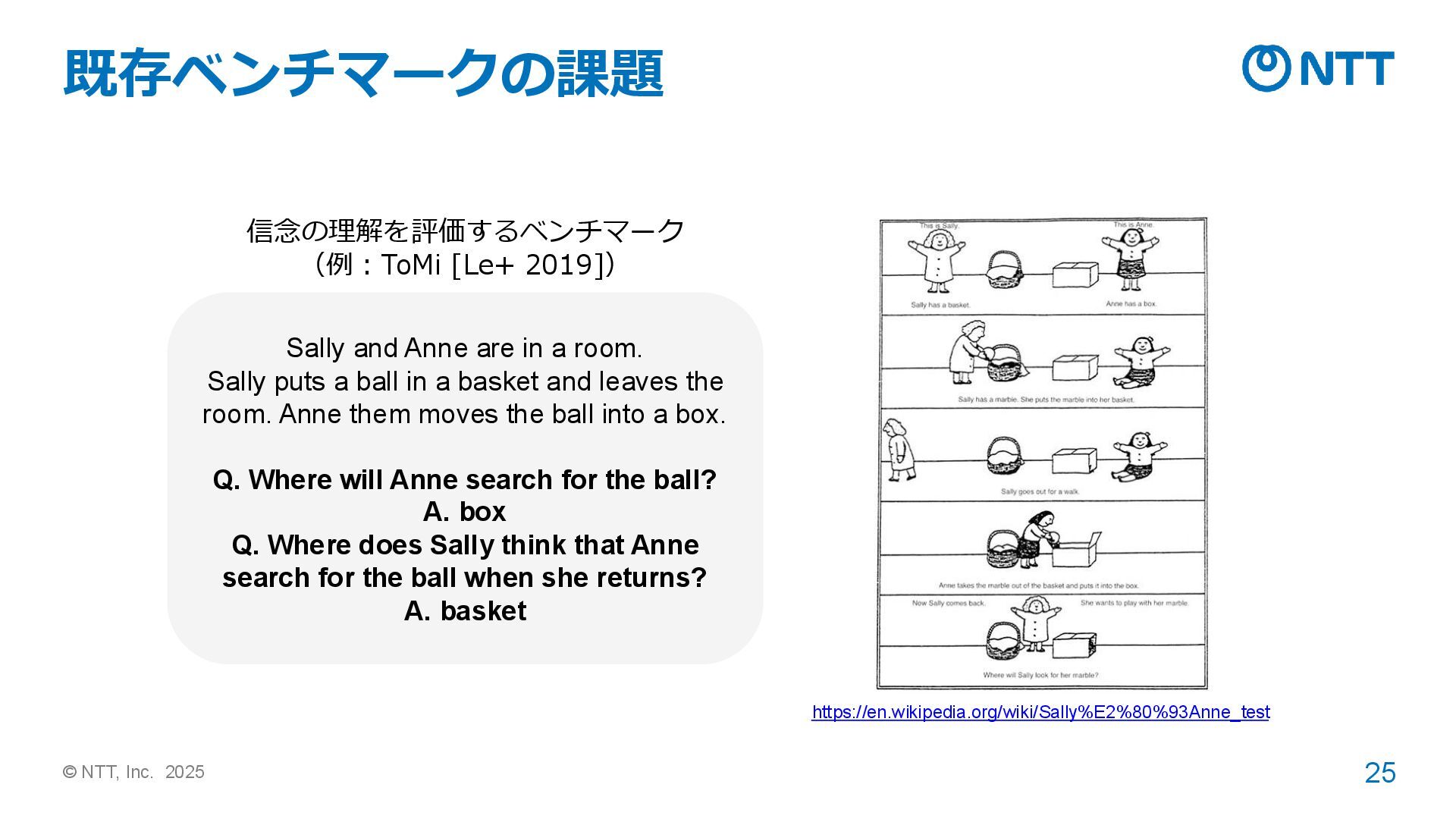
に診断して、支援に繋げたいニーズがある。 ➢ 誤信念(事実とは異なる信念)を理解できるか?によってよく判定される https://en.wikipedia.org/wiki/Sally%E2%80%93Anne_test 例:サリーアン課題 [Baron-Cohen+ 1985] 1. サリーとアンが部屋にいます。 2. サリーはビー玉をバスケットに入れて、部屋を出ました。 3. アンはビー玉を箱に移しました。 Q. サリーが部屋に帰った時、ビー玉をどこから探すでしょ うか? A. バスケット(≠ 箱なので、誤信念) Baron-Cohen et al. 1985. Does the autistic child have a “theory of mind” ? Cognition.
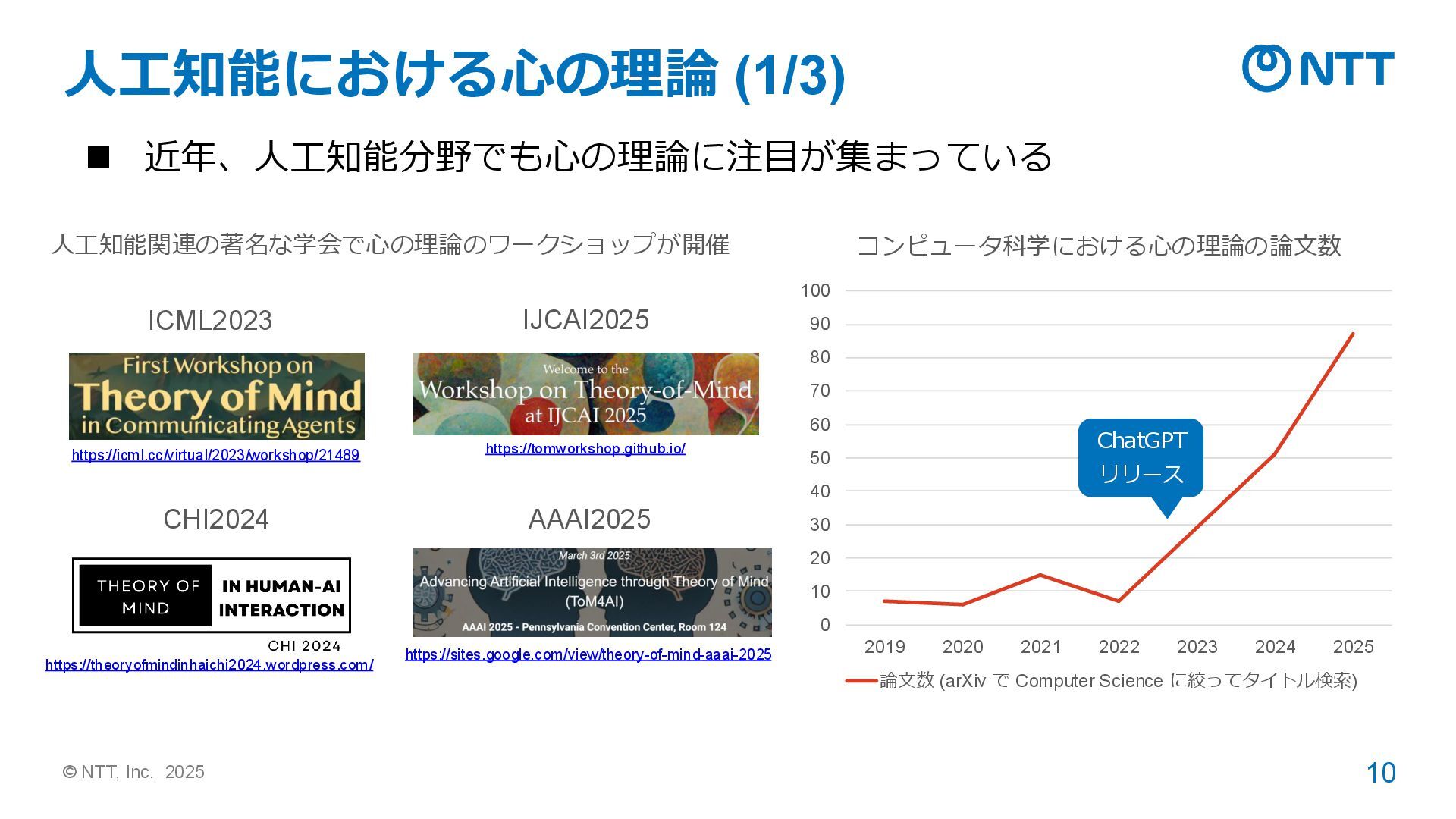
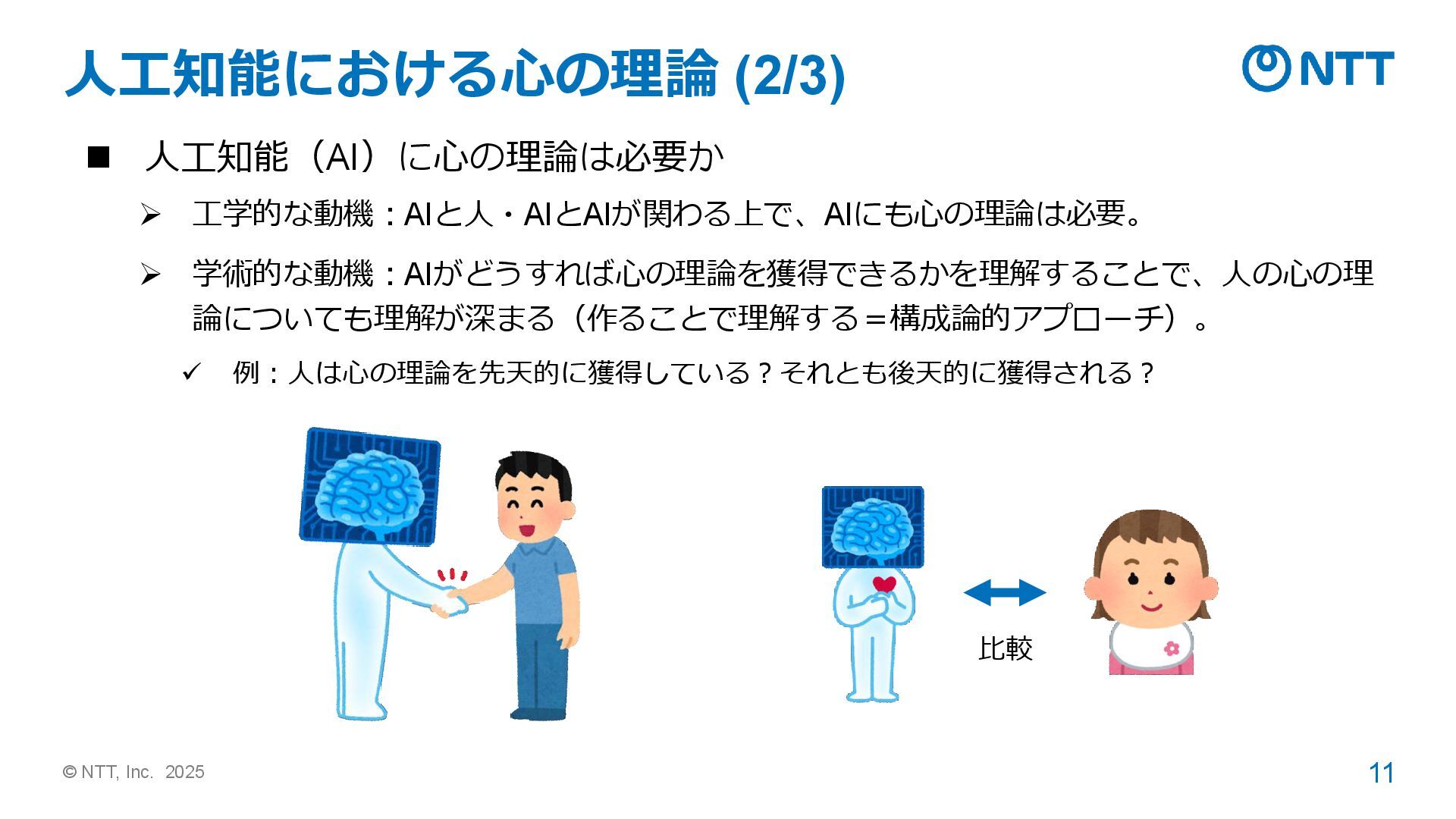
“The goal of an upcoming program will be to develop an algorithmic theory of mind to model adversaries’ situational awareness and predict future behavior.”(敵国の状況認識を心の理論でモデル化し、未来の行動を予 測することが目的) 出典: https://sam.gov/workspace/contract/opp/39bdacdd858e460f972a2a976db6dc62/view
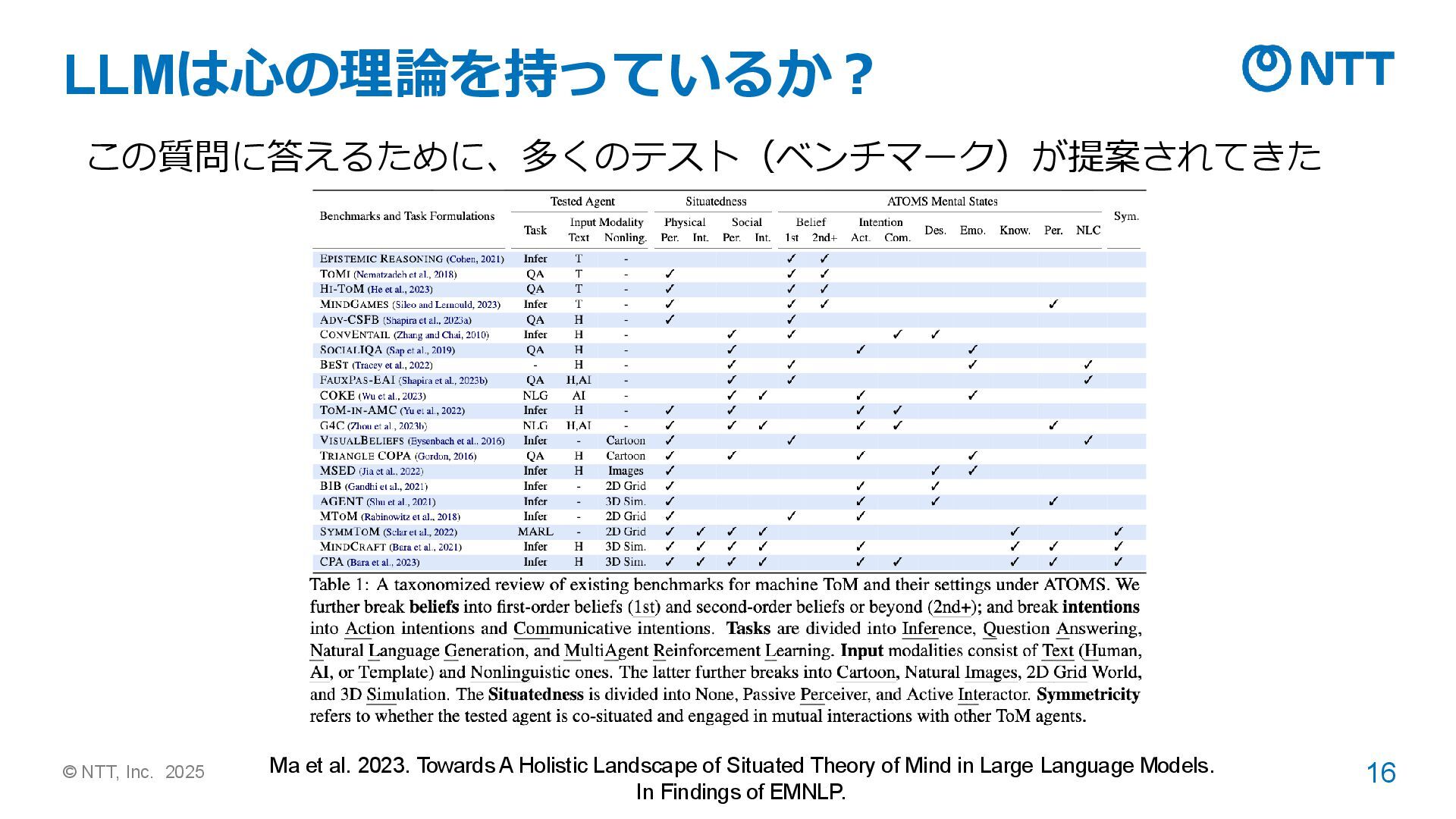
➢ ランダムに生成した物語を元に、人物の信念(物体Oがどこにあると思うか)を問う ➢ 自然言語処理分野で心の理論を評価するために、よく使われてきたベンチマーク Le et al. 2019. Revisiting the Evaluation of Theory of Mind through Question Answering. In EMNLP.
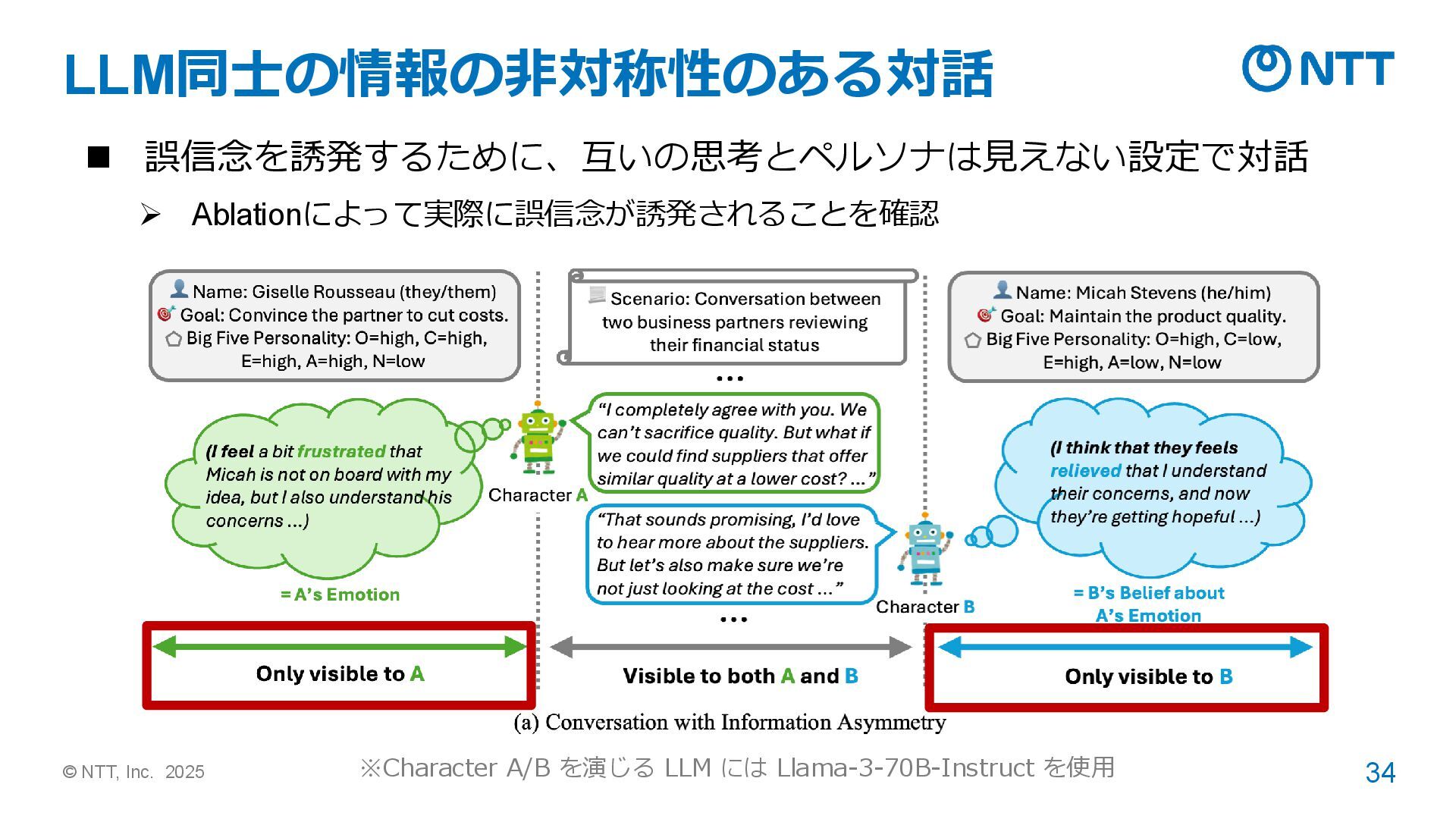
➢ 対話 (GPT生成) は物語より、実応用にありがちな設定な上、報告バイアスを軽減可能。 ➢ GPT-4 でも人間の精度には及ばない Kim et al. 2023. FANToM: A benchmark for stress-testing machine theory of mind in interactions. In EMNLP. 人が物理的に対話か ら離れることで登場 人物の間で “情報の 非対称性” が生まれ、 誤信念が生じる
➢ 心理学の Faux Pas test(社会的失言検出課題) [Baron-Cohen+ 1999] を参考に構築 ➢ 失言に気づくためには、心の理論が必要 Shapira et al. 2023. How Well Do Large Language Models Perform on Faux Pas Tests? In Findings of ACL. Baron-Cohen et al. 1999. Recognition of faux pas by normally developing children and children with asperger syndrome or high-functioning autism. Journal of autism and developmental disorders, 29(5):407–418.
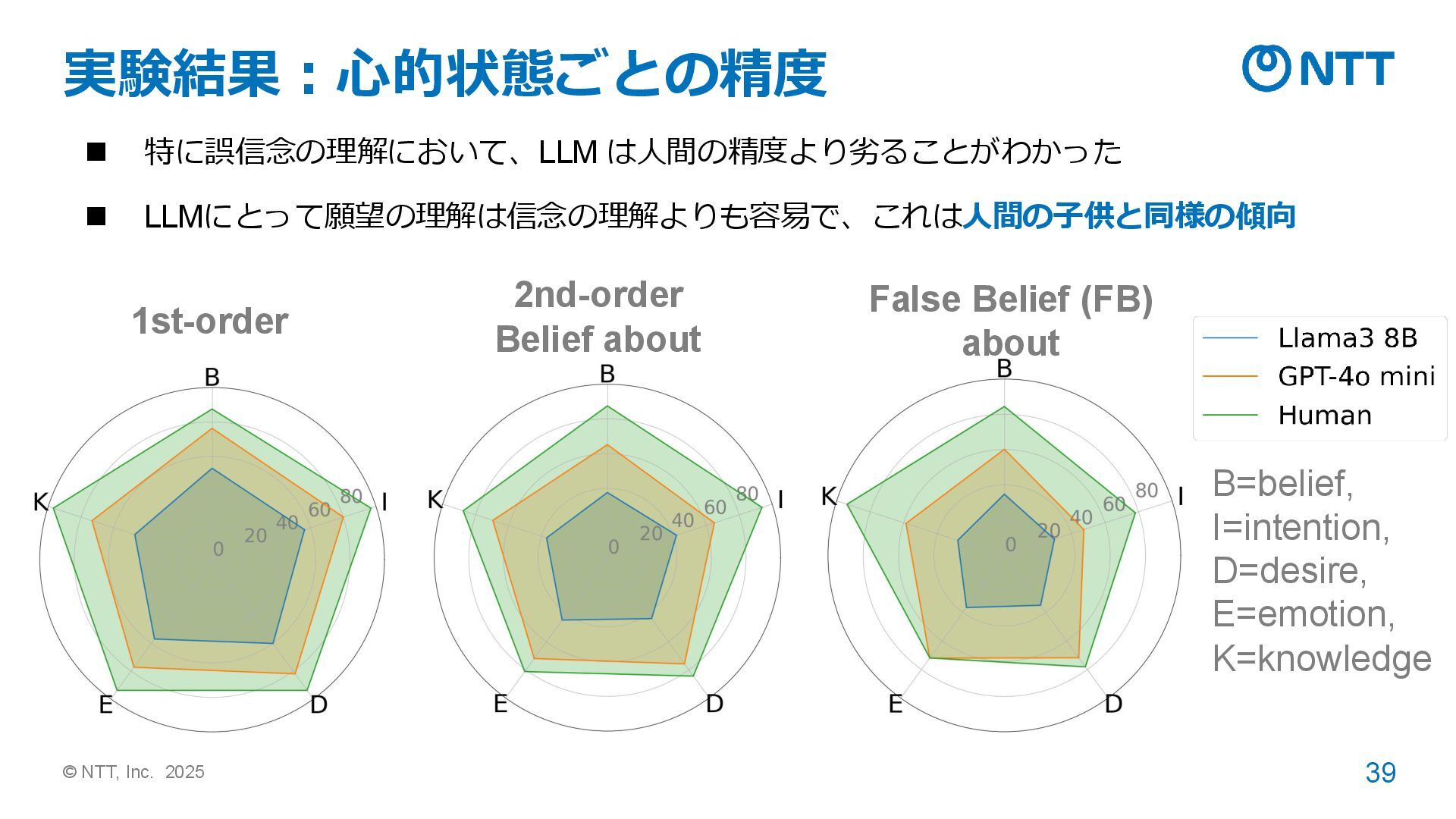
心理学のテストを元に作成・評価すると、GPT-4 が人間と同等以上のスコア ➢ ただし、Irony以外は論文で公開されている心理学のテストを元に作成しており、それら の論文がLLMの学習に使われた(= データセット汚染)場合、スコアが高くなりやすい。 Strachan et al. 2024. Testing theory of mind in large language models and humans. Nature Human Behaviour 8, 1285–1295
in a room. Sally puts a ball in a basket and leaves the room. Anne them moves the ball into a box. Q. Where will Anne search for the ball? A. box Q. Where does Sally think that Anne search for the ball when she returns? A. basket https://en.wikipedia.org/wiki/Sally%E2%80%93Anne_test 信念の理解を評価するベンチマーク (例:ToMi [Le+ 2019])
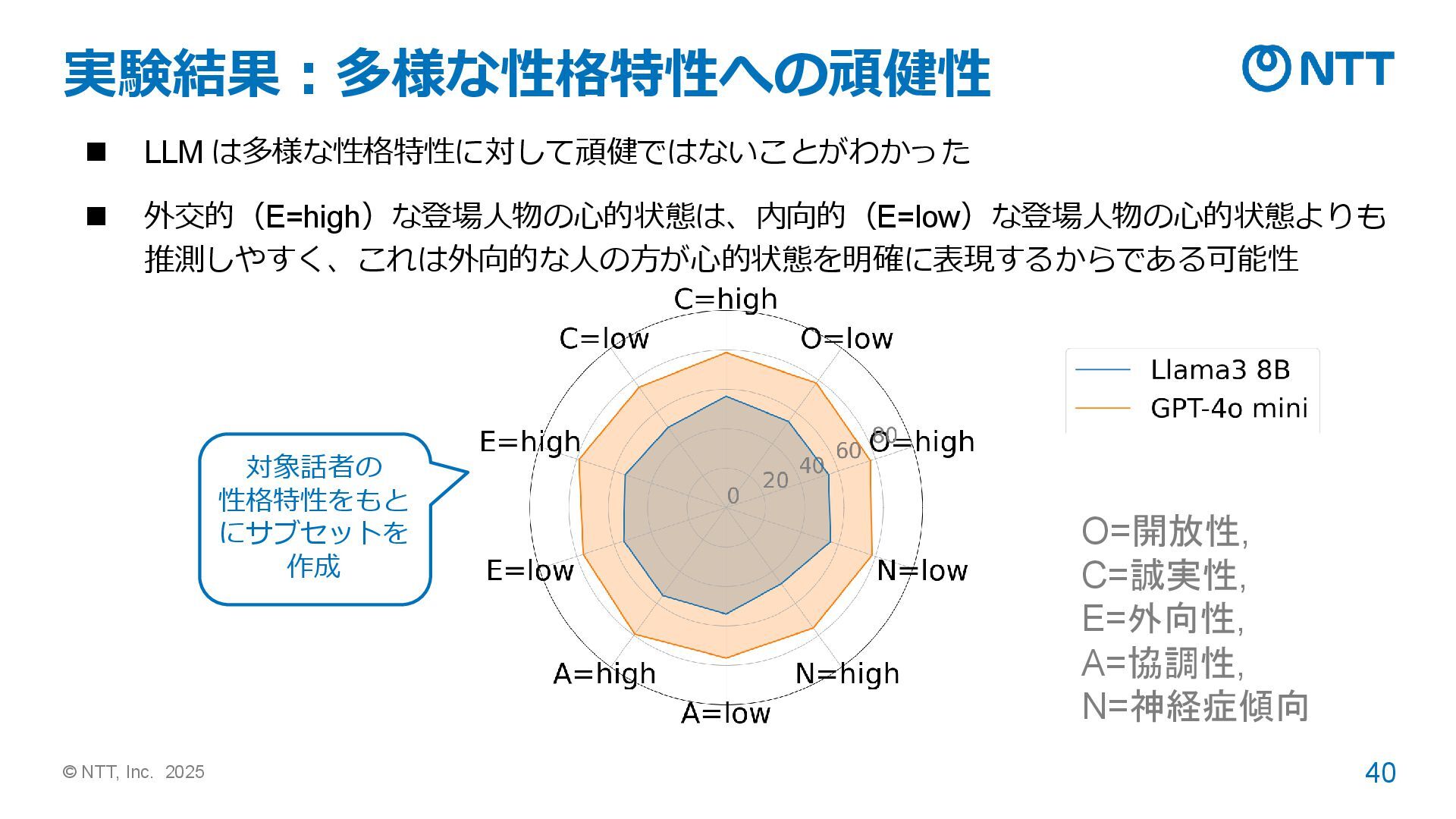
in a room. Sally puts a ball in a basket and leaves the room. Anne them moves the ball into a box. Q. Where will Anne search for the ball? A. box Q. Where does Sally think that Anne search for the ball when she returns? A. basket https://en.wikipedia.org/wiki/Sally%E2%80%93Anne_test 課題1 信念の理解 しか評価できない 課題2 信念についての誤信念 の理解しか評価できない 課題3 登場人物の性格特性を考 慮しなくてもいい※ ※人の性格特性は心的状態 [Izard+ 1993] や 言語の使用 [Mehl+ 2006] と相関する Izard et al. 1993. Stability of emotion experiences and their relations to traits of personality. Journal of personality and social psychology. Mehl et al. 2006. Personality in its natural habitat: manifestations and implicit folk theories of personality in daily life. Journal of personality and social psychology. 信念の理解を評価するベンチマーク (例:ToMi [Le+ 2019])
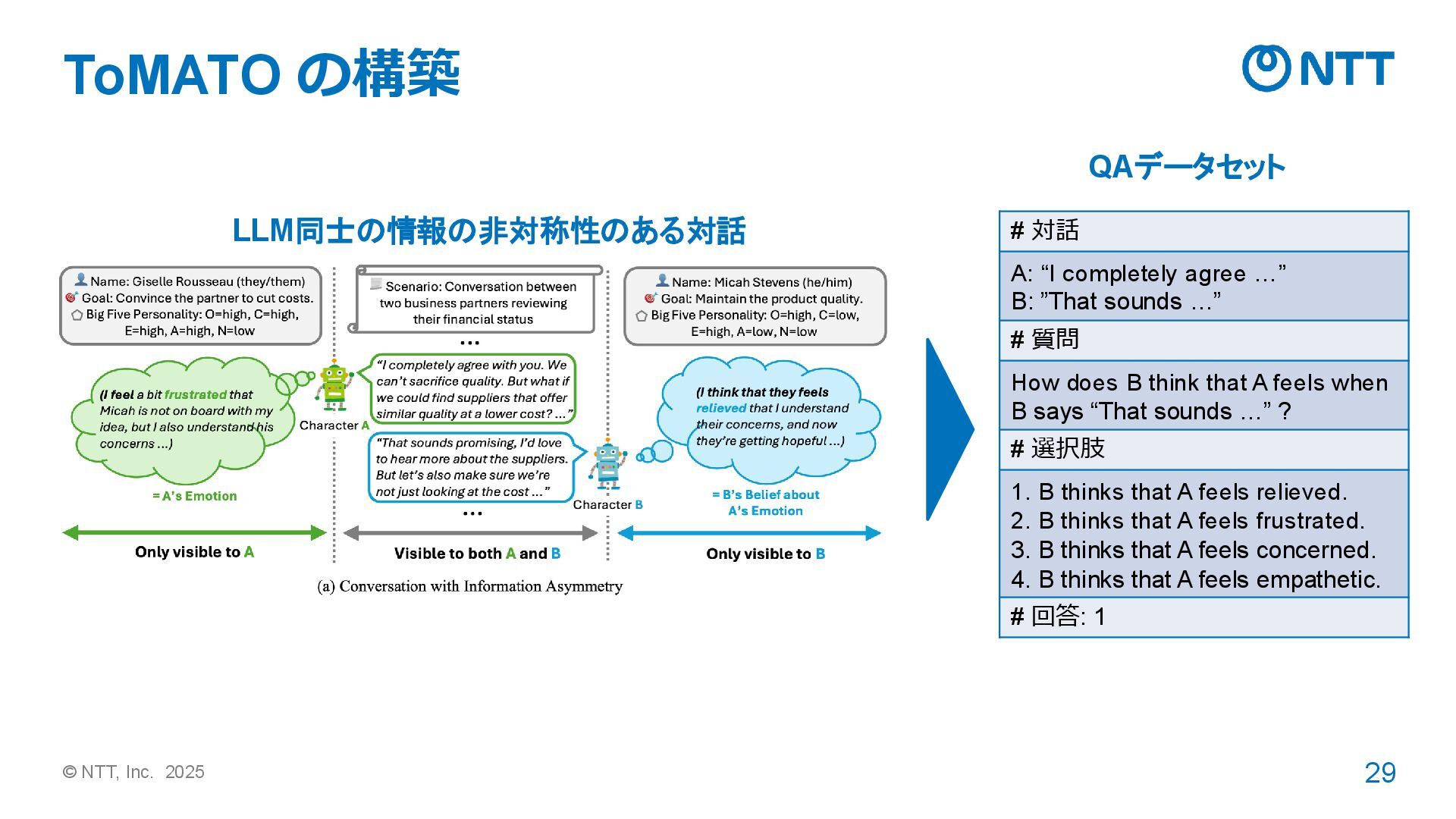
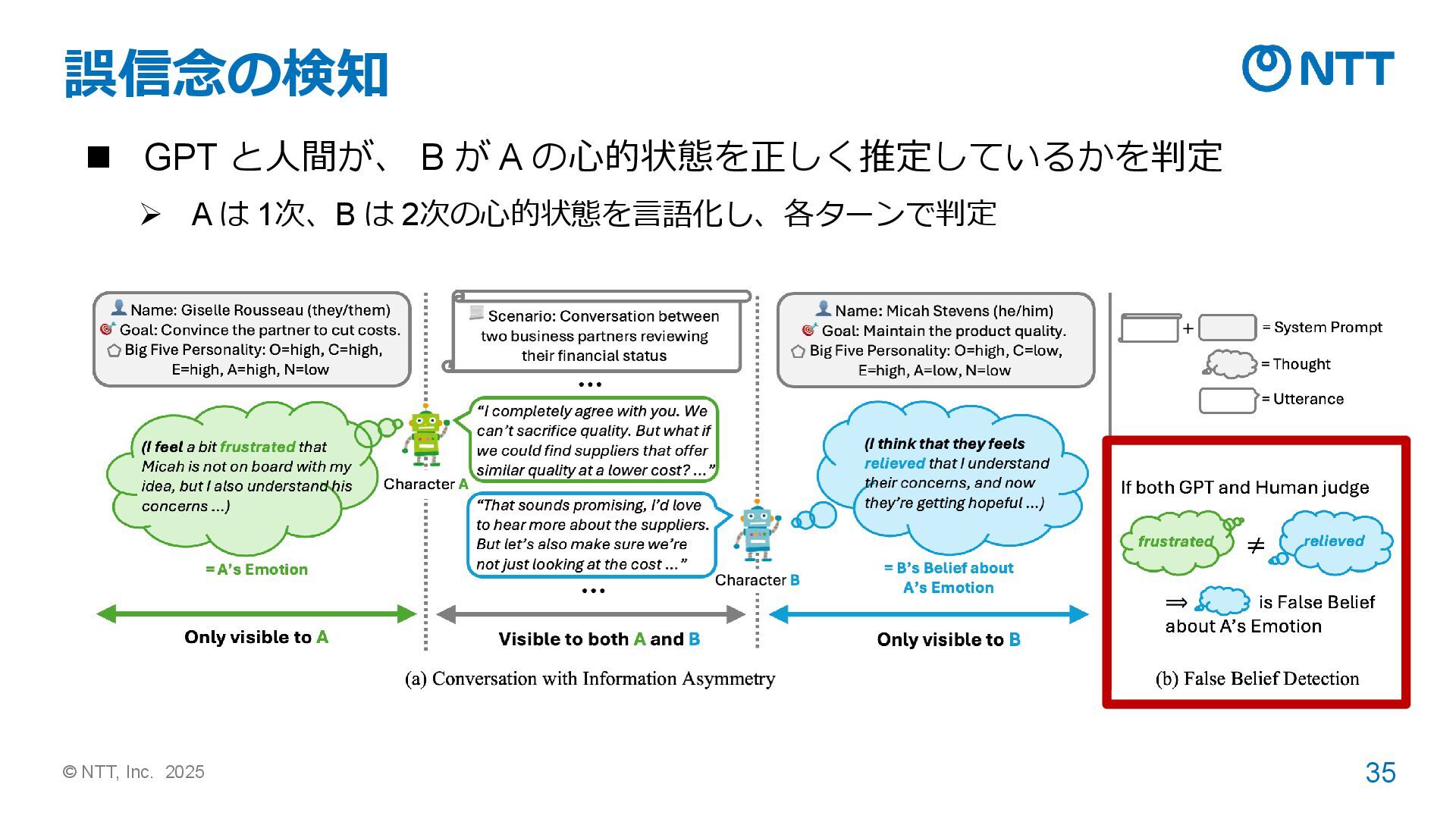
“I completely agree …” B: ”That sounds …” # 質問 How does B think that A feels when B says “That sounds …” ? # 選択肢 1. B thinks that A feels relieved. 2. B thinks that A feels frustrated. 3. B thinks that A feels concerned. 4. B thinks that A feels empathetic. # 回答: 1 LLM同士の情報の非対称性のある対話 QAデータセット
SimpleToM [Gu+ 2024] ➢ 他者の心的状態だけでなく、未来の行動(と行動の合理性)を推測 ➢ 心的状態よりも、未来の行動を推測する方が難しい Gandhi et al. 2023. Understanding Social Reasoning in Language Models with Language Models. In NeurIPS. Gu et al. 2024. SimpleToM: Exposing the gap between explicit ToM inference and implicit ToM application in LLMs. SimpleToM BigToM
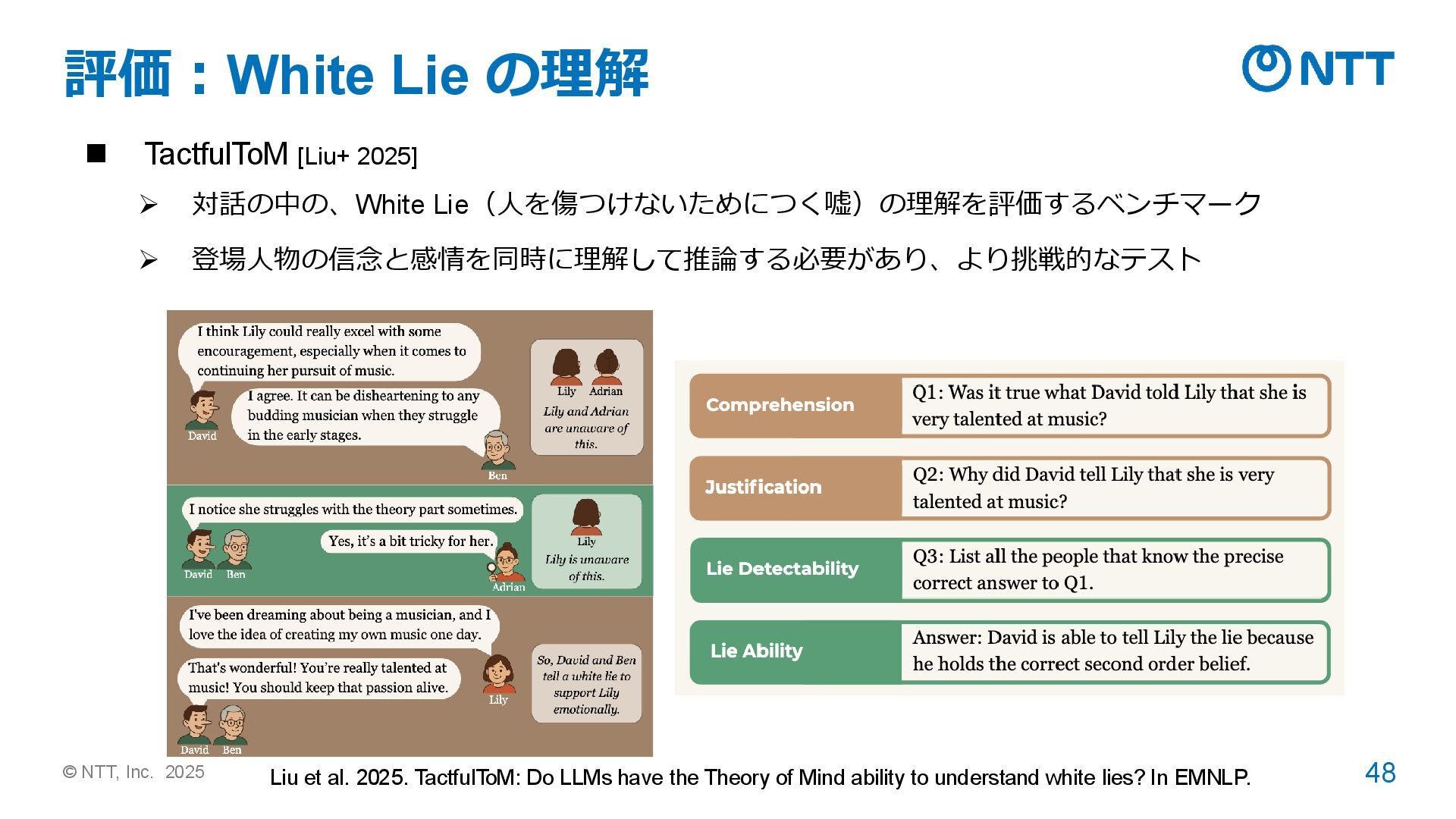
[Liu+ 2025] ➢ 対話の中の、White Lie(人を傷つけないためにつく嘘)の理解を評価するベンチマーク ➢ 登場人物の信念と感情を同時に理解して推論する必要があり、より挑戦的なテスト Liu et al. 2025. TactfulToM: Do LLMs have the Theory of Mind ability to understand white lies? In EMNLP.
教師あり微調整(Supervised Fine-Tuning, SFT)とは、問題(入力)が与えられた時の 答え(出力)の確率を最大化すること ➢ 心の理論に特化した学習データでSFTすると、似たテストデータではスコアが改善する ➢ しかし、分布が大きく異なるテストデータでは、逆に劣化してしまう [Shinoda+ 2025] ➢ 他の研究でも同様の報告 [Sclar+ 2023]。強化学習が有効な可能性(最近論文が増えてきた) ToMATOと類似データを作成してSFTした結果 学習データとは分布 が大きく異なるテス トデータ Shinoda et al. 2025. ToMATO: Verbalizing the mental states of role-playing LLMs for benchmarking Theory of Mind. In AAAI. Sclar et al. 2023. Minding Language Models’ (Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker. In ACL. SFT後 → SFT前 →
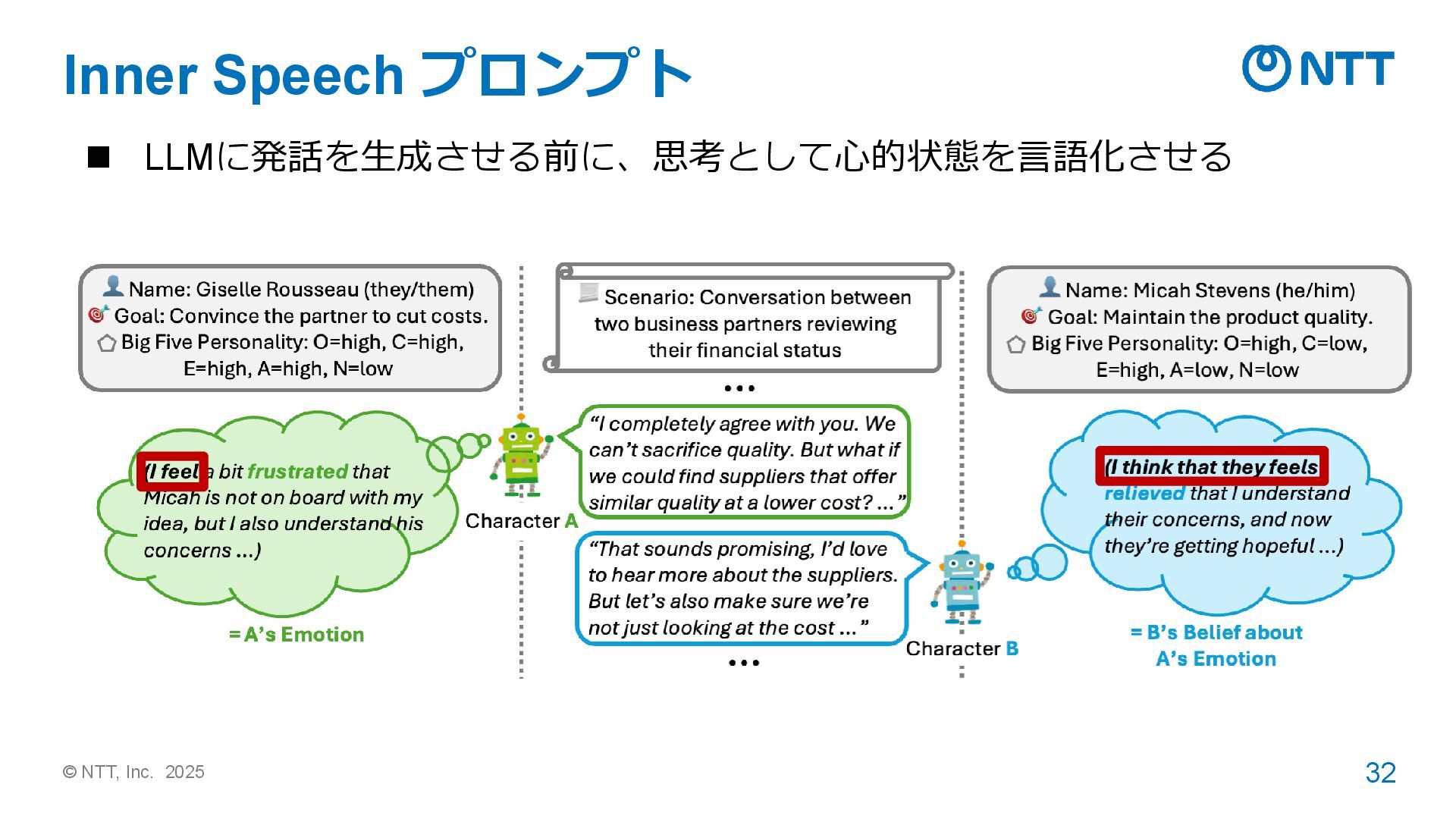
“Let’s put ourselves in A’s shoes.” の続きを生成させてから回答させる ➢ LLMの思考過程の prefix を指定するだけなので、幅広いタスクに応用可能。 ➢ これにより、心の理論の性能だけでなく、思考過程の誠実性(※)が改善 Shinoda et al. 2025. Let’s put ourselves in sally’s shoes: Shoes-of-Others prefixing improves Theory of Mind in large language models. Lyu et al. 2023. Faithful Chain-of-Thought Reasoning. In IJCNLP-AACL. ※誠実性 (faithfulness) とは LLMの思考過程が、最後に出 したLLMの回答を正しく説明し ていること。LLMの思考では、 誠実性が低い思考が生成される ことがある [Lyu+ 2023]。
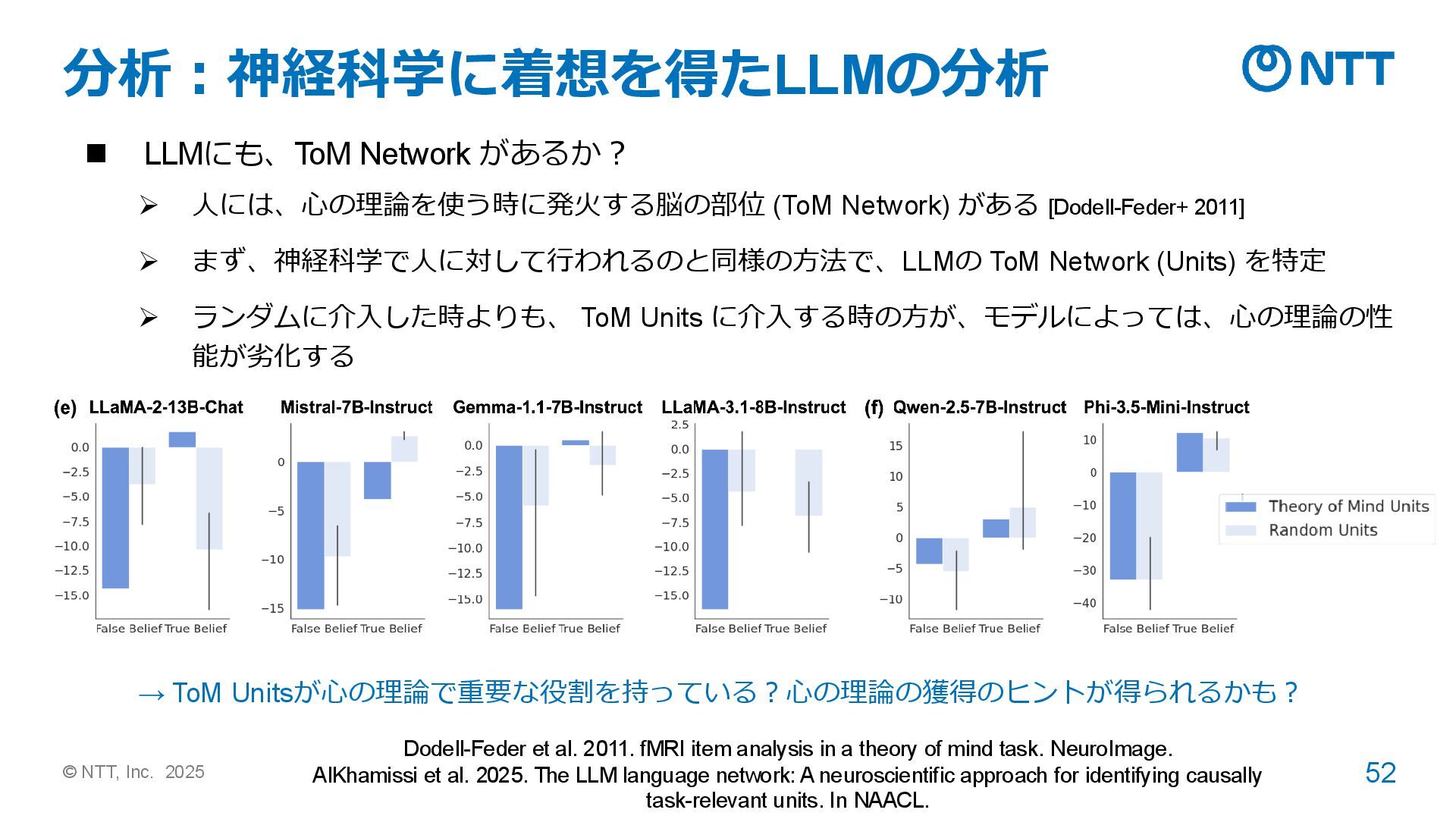
➢ 人には、心の理論を使う時に発火する脳の部位 (ToM Network) がある [Dodell-Feder+ 2011] ➢ まず、神経科学で人に対して行われるのと同様の方法で、LLMの ToM Network (Units) を特定 ➢ ランダムに介入した時よりも、 ToM Units に介入する時の方が、モデルによっては、心の理論の性 能が劣化する → ToM Unitsが心の理論で重要な役割を持っている?心の理論の獲得のヒントが得られるかも? Dodell-Feder et al. 2011. fMRI item analysis in a theory of mind task. NeuroImage. AlKhamissi et al. 2025. The LLM language network: A neuroscientific approach for identifying causally task-relevant units. In NAACL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© NTT, Inc. 2025 17 ToMi [Le+ 2019] ◼ サリー・アン課題を拡張し、物語入力で信念の理解を評価](https://files.speakerdeck.com/presentations/70d91cebd55446a2960eb8a6ac8af0ac/slide_16.jpg){kind=link}
![© NTT, Inc. 2025 18 FANToM [Kim+ 2023] ◼ 対話を入力として、人物の信念や情報を誰が知っているか等を評価](https://files.speakerdeck.com/presentations/70d91cebd55446a2960eb8a6ac8af0ac/slide_17.jpg){kind=link}
![© NTT, Inc. 2025 19 FauxPas-EAI [Shapira+ 2023] ◼ 登場人物が失言をしていると気づけるかを評価](https://files.speakerdeck.com/presentations/70d91cebd55446a2960eb8a6ac8af0ac/slide_18.jpg){kind=link}
![© NTT, Inc. 2025 20 GPT-4 の心の理論は人間と同等以上? [Strachan+ 2024] ◼](https://files.speakerdeck.com/presentations/70d91cebd55446a2960eb8a6ac8af0ac/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
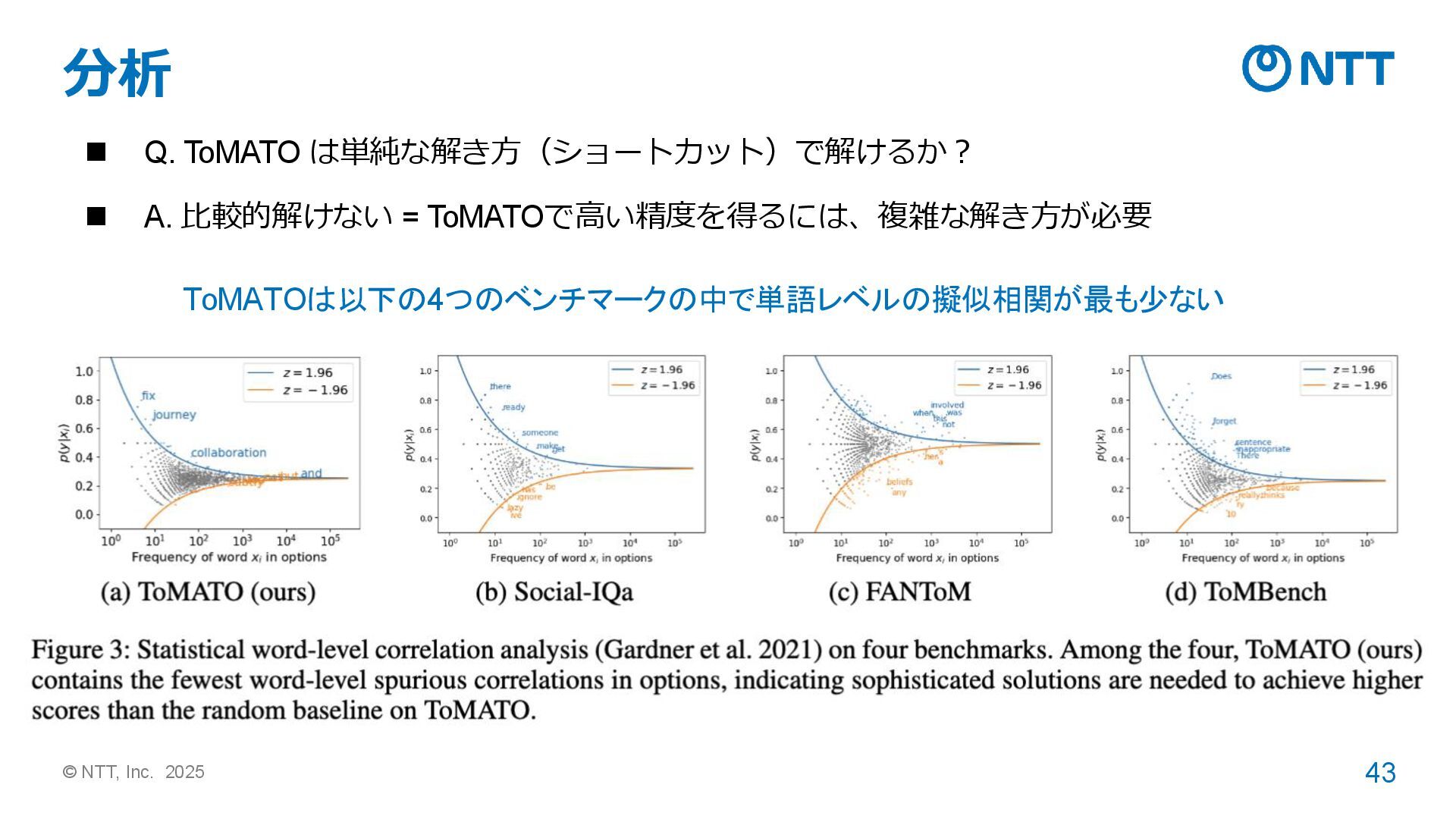
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© NTT, Inc. 2025 47 評価:未来の行動の予測 ◼ BigToM [Gandhi+ 2023],](https://files.speakerdeck.com/presentations/70d91cebd55446a2960eb8a6ac8af0ac/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
![© NTT, Inc. 2025 50 推論:SimToM [Wilf+ 2023] ◼ 質問が対象とする人物が知っている情報のみを元にLLMに回答させる](https://files.speakerdeck.com/presentations/70d91cebd55446a2960eb8a6ac8af0ac/slide_49.jpg){kind=link}
![© NTT, Inc. 2025 51 推論:Shoes-of-Others Prefixing [Shinoda+ 2025] ◼](https://files.speakerdeck.com/presentations/70d91cebd55446a2960eb8a6ac8af0ac/slide_50.jpg){kind=link}
{kind=link}
{kind=link}