Thoughts: Learning to Converse and Guide with Intents and Theory-of-Mind in Dungeons and Dragons (ACL2023 main) • Theory of Mind in Freely-Told Children’s Narratives: A Classification Approach (ACL2023 findings) • Speaking the Language of Your Listener: Audience-Aware Adaptation via Plug-and-Play Theory of Mind (ACL2023 findings) • Computational Language Acquisition with Theory of Mind (ICLR2023) ICML2023 では 1st Workshop on Theory-of-Mind が開催されるなど、研究者からの 注目が集まっている印象 4
を更新 ◦ NLI: “文→Gのエッジ” 矛盾するエッジを削除 ◦ GPT-3: “Bob then moves the celery to the box”→“The celery is in the box”に変換 ◦ OpenIE: “The celery is in the box” → (celery, box, is in) • 目撃者たち W を検知 ◦ 上記操作によって構築された G に繋がってい る登場人物を全員目撃者とする • (p1…pk) が全員目撃者である時に、G への更新を Bp1…pk に反映 この時、グラフの各エッジは文章中の1文と対応している 11
Choi. 2022. Neural Theory-of-Mind? On the Limits of Social Intelligence in Large LMs. In EMNLP. • Matthew Le, Y-Lan Boureau, Maximilian Nickel. 2019. Revisiting the Evaluation of Theory of Mind through Question Answering. In EMNLP. • Akshatha Arodi and Jackie Chi Kit Cheung. 2021. Textual Time Travel: A Temporally Informed Approach to Theory of Mind. In EMNLP. • Alan M Leslie, Ori Friedman, and Tim P German. 2004. Core mechanisms in ‘theory of mind’. Trends in cognitive sciences, 8(12):528–533. • Weiyan Shi* and Liang Qiu* and Dehong Xu and Pengwei Sui and Pan Lu and Zhou Yu. 2023. KokoMind: Can LLMs Understand Social Interactions? 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
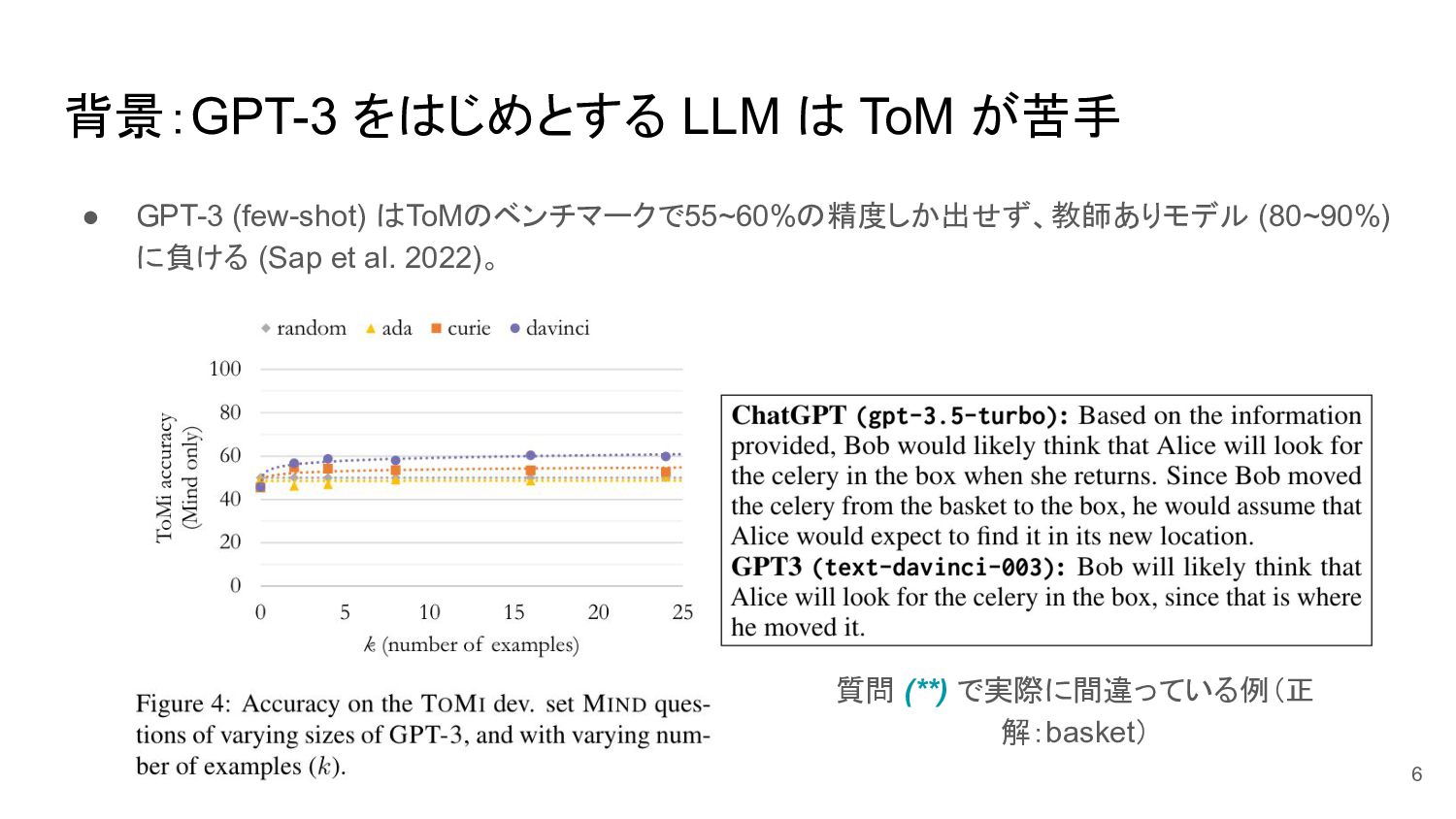{kind=link}
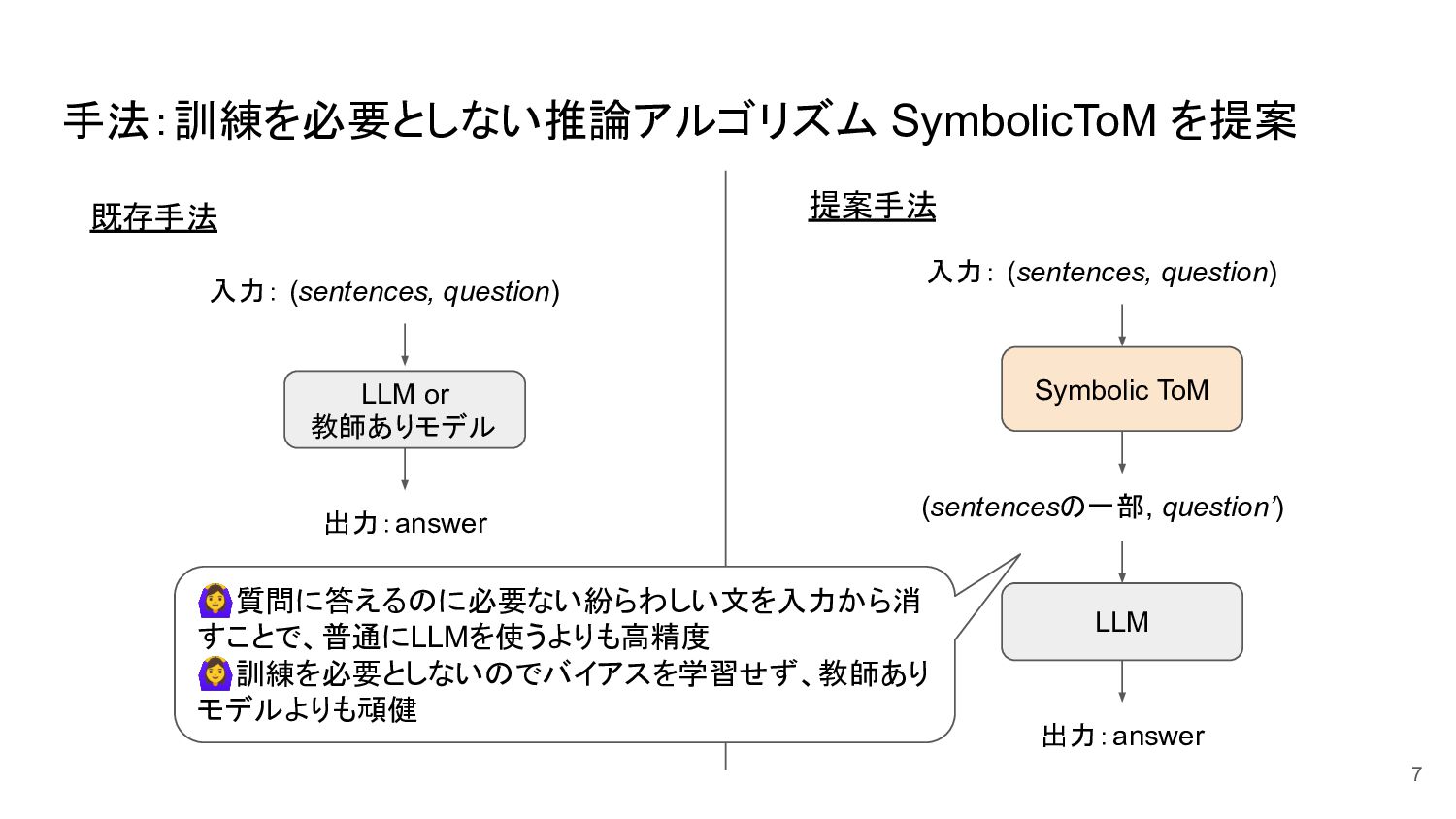{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
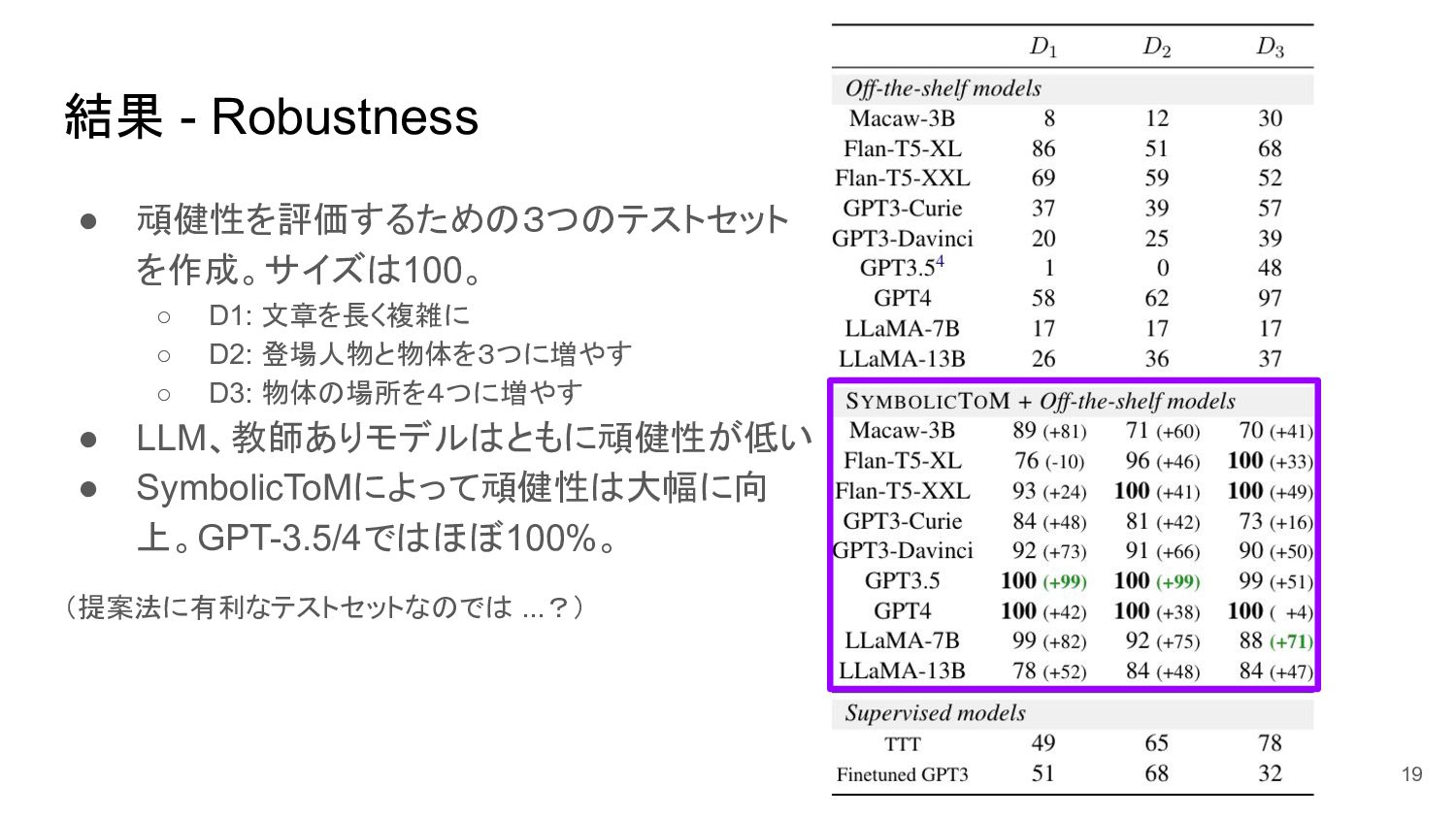{kind=link}
{kind=link}
{kind=link}
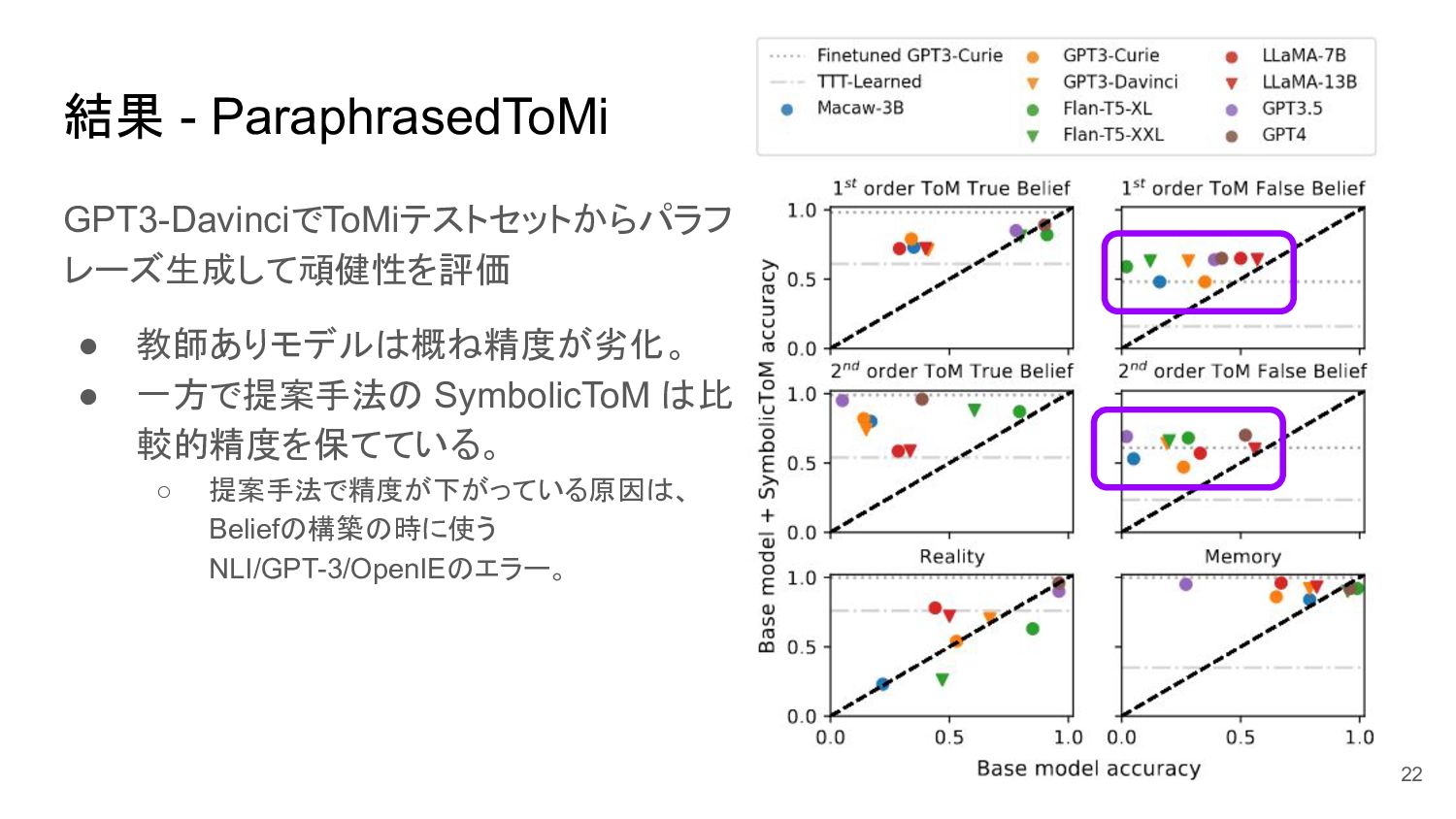{kind=link}
{kind=link}
{kind=link}
{kind=link}