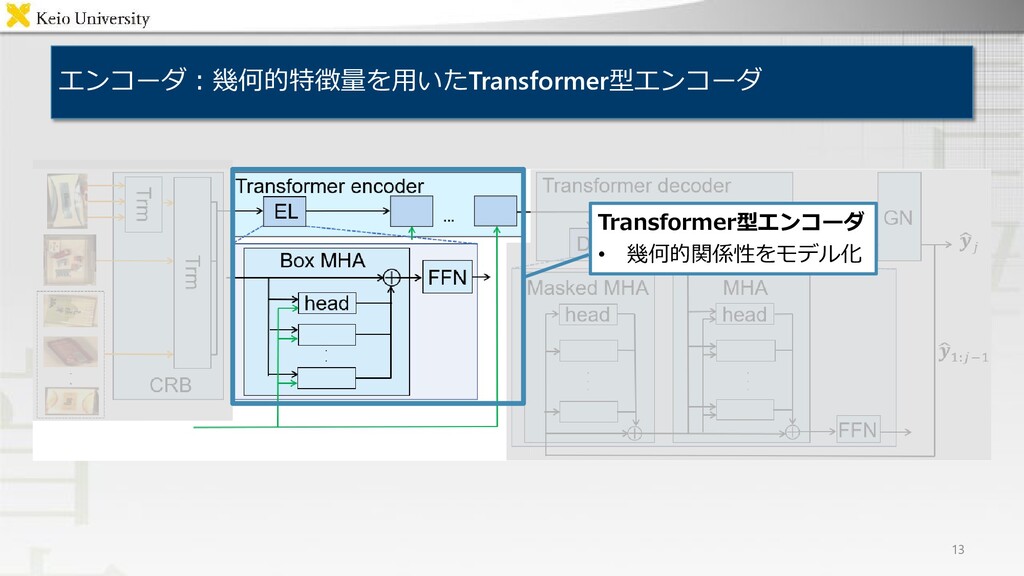
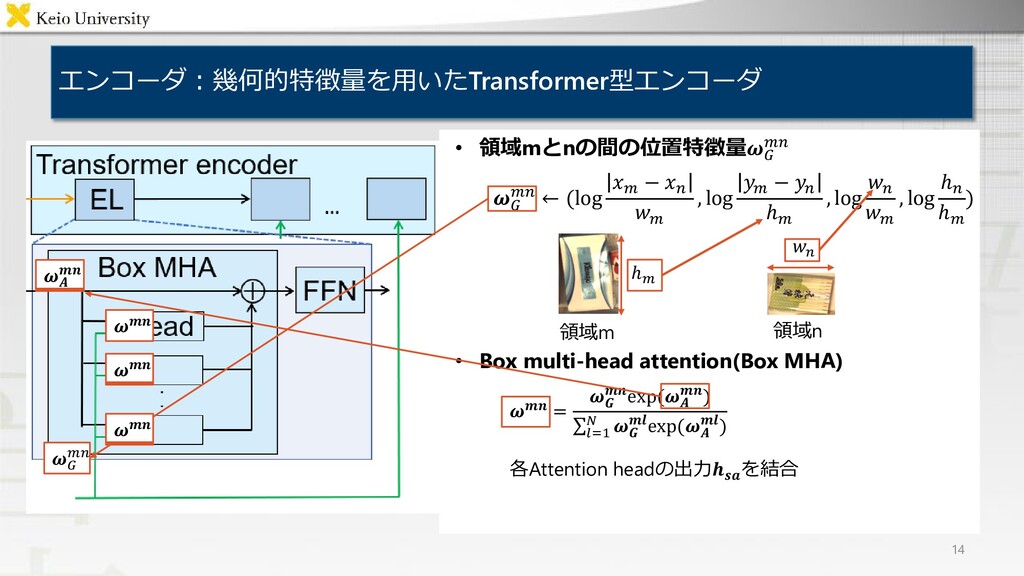
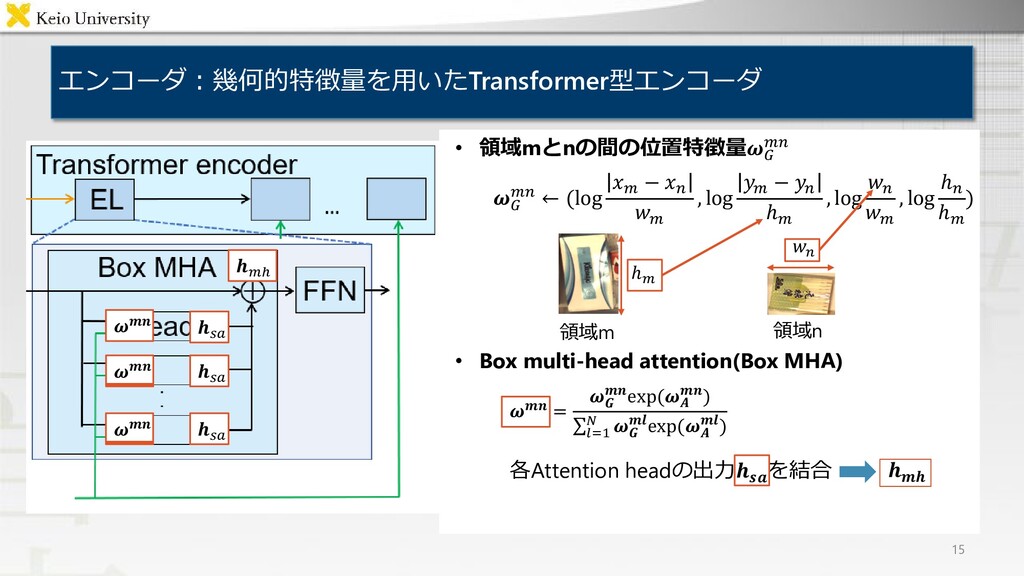
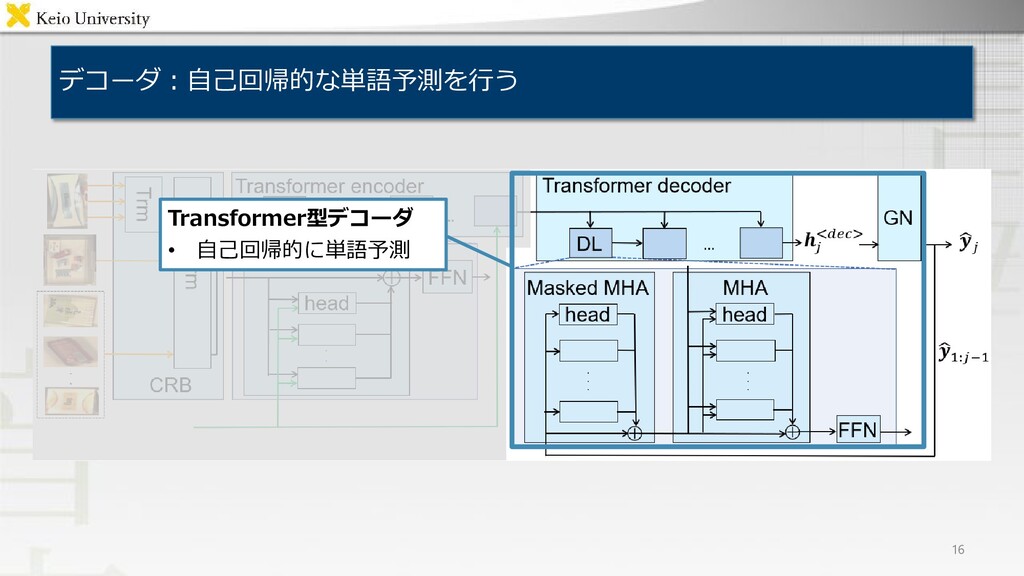
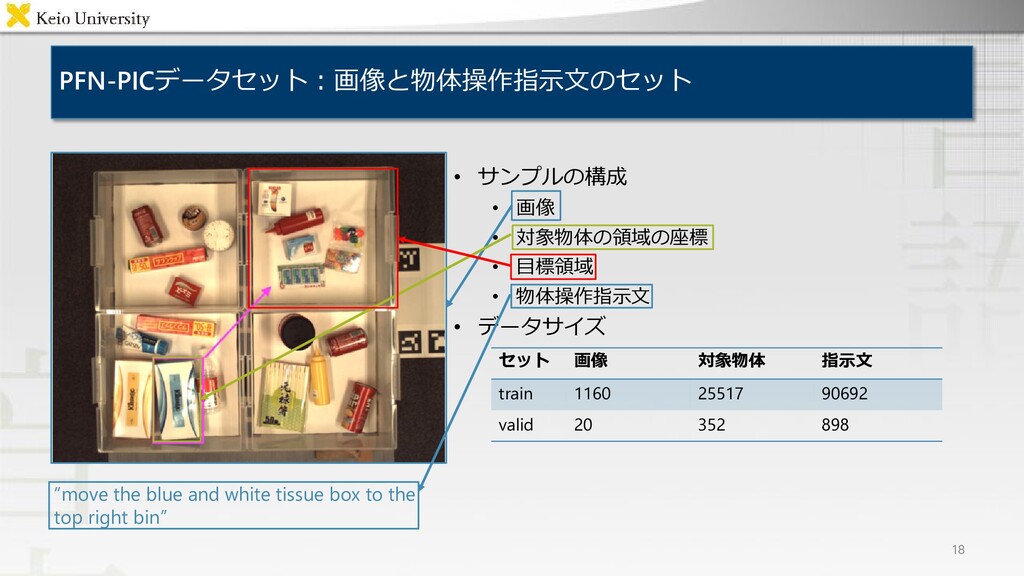
and put it into the lower left box 問題設定:物体操作指示文付与タスク 3 • 対象タスク: Fetching instruction generation(FIG)タスク 対象物体及び目標領域についての物体操作指示文付与 • 入力 対象物体,及び目標領域を含む画像 • 出力 物体操作指示文
white gloves and put it in the upper right box move the rectangular black thing from the box with an empty drink bottle in it to the box with a coke can in it 生成文 move the red can from the bottom right box to the top right box move the black mug to the lower left box
white gloves and put it in the upper right box move the rectangular black thing from the box with an empty drink bottle in it to the box with a coke can in it 生成文 move the red can from the bottom right box to the top right box move the black mug to the lower left box コーラ缶を参照表現により特定
white gloves and put it in the upper right box move the rectangular black thing from the box with an empty drink bottle in it to the box with a coke can in it 生成文 move the red can from the bottom right box to the top right box move the black mug to the lower left box 対象物体を明瞭に”black mug”と表現
and place it in the lower left box grab the round container in the right gand corner of the bottom right corner and place it in the top left corner 生成文 move the red can to the bottom left box move the white tin to the left upper box
and place it in the lower left box grab the round container in the right gand corner of the bottom right corner and place it in the top left corner 生成文 move the red can to the bottom left box move the white tin to the left upper box 赤いボトルに引っ張られている
and place it in the lower left box grab the round container in the right gand corner of the bottom right corner and place it in the top left corner 生成文 move the red can to the bottom left box move the white tin to the left upper box “銀色の缶”を”白い缶”としている
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
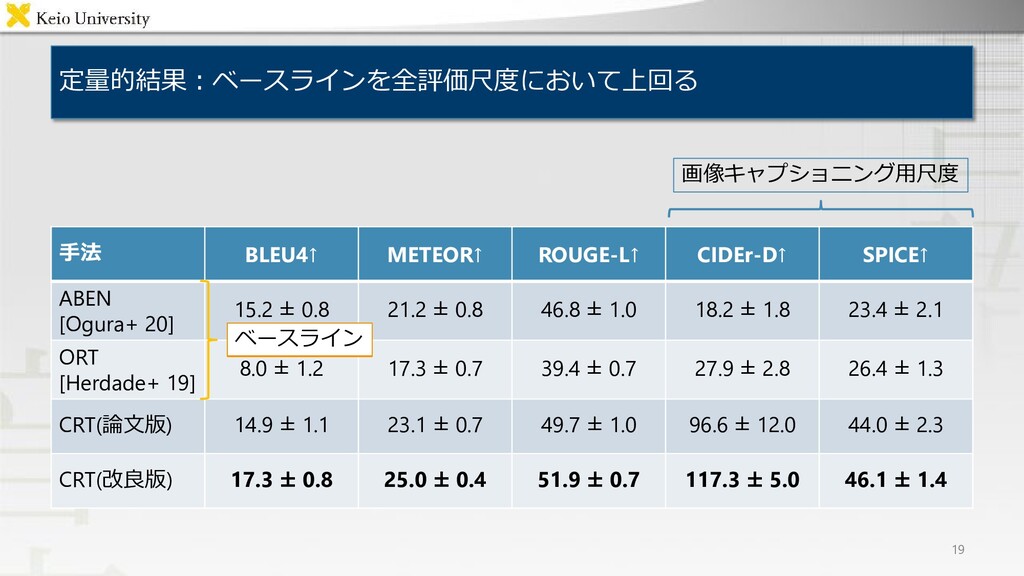
![既存研究:既存モデルでは生成文の品質が低い 5 VideoBERT Change Captioning[Park+ ICCV19] タスク 手法 概要 画像キャプショニング](https://files.speakerdeck.com/presentations/e15facfb283e41f69e500bb3cbceff6b/slide_5.jpg){kind=link}
![タスク 手法 概要 画像キャプショニング Object Relation Transformer [Hardade+ NeurIPS19] 領域間の幾何的参照表現をモデル化](https://files.speakerdeck.com/presentations/e15facfb283e41f69e500bb3cbceff6b/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
![対象物体,目標領域以外は自動検出された領域を入力とする 9 対象物体 目標領域 コンテキスト情報 • Up-Down Attention[Anderson+ CVPR18]により検出](https://files.speakerdeck.com/presentations/e15facfb283e41f69e500bb3cbceff6b/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}