Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[NLP23] JaSPICE: Automatic Evaluation Metric Us...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
March 13, 2023
Technology
980
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[NLP23] JaSPICE: Automatic Evaluation Metric Using Predicate-Argument Structures for Image Captioning Models
慶應義塾⼤学 杉浦孔明研究室 B4 和田唯我 / Yuiga Wada
project page:
ja
/
en
Semantic Machine Intelligence Lab., Keio Univ.
PRO
March 13, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
76
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
85
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
97
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
1
590
全員がリーダーである世界へ キリマンジャロ登頂とシェアド・リーダー
jinwatanabe
0
120
「休む」重要さ
smt7174
5
1.1k
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
310
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
950
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
940
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
900
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
590
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
710
現場との対話から始める “作る前に問い直す”業務改善
mochico50
0
120
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
530
Featured
See All Featured
Documentation Writing (for coders)
carmenintech
77
5.4k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
Bash Introduction
62gerente
615
220k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Speed Design
sergeychernyshev
33
1.9k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Typedesign – Prime Four
hannesfritz
42
3.1k
Automating Front-end Workflow
addyosmani
1370
210k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Transcript
JaSPICE : 日本語における述語項構造に基づく 画像キャプション生成モデルの自動評価尺度 和田唯我, 兼田寛大, 杉浦孔明 慶應義塾大学 B8-3
o ⽇本語における画像キャプション⽣成のための⾃動評価尺度JaSPICEを提案 • Project Page: https://yuiga.dev/jaspice 提案:⽇本語における画像キャプション⽣成のための⾃動評価尺度 - 2 -
クラウドソーシングサービス による被験者実験を実施 • 被験者 : 100⼈ • 22,350サンプル収集 相関係数にて他指標を上回る CIDEr << JaSPICE 0.31 0.50
JaSPICE: Automatic Evaluation Metric for Image Captioning Models - 3
- o pip install & dockerで簡単に実⾏できます o pycocoevalcapと同様の書き⽅で評価が実⾏できます
背景 : 画像キャプション⽣成では⽣成⽂の品質評価が重要 - 4 - 画像キャプション⽣成タスク : 画像を説明するキャプションを⽣成 •
視覚障害者の補助 [Gurari+, ECCV20] • 画像に関する対話⽣成 [White+, EMNLP21] • 画像に基づく質問応答 [Fisch+, EMNLP20] o 画像キャプション⽣成は様々な⽤途で 社会応⽤されている 円滑なモデル改良のためには⽣成⽂が 適切に評価できる⾃動評価尺度が必要 ⾚い傘を差した⼈が ベンチに座っている
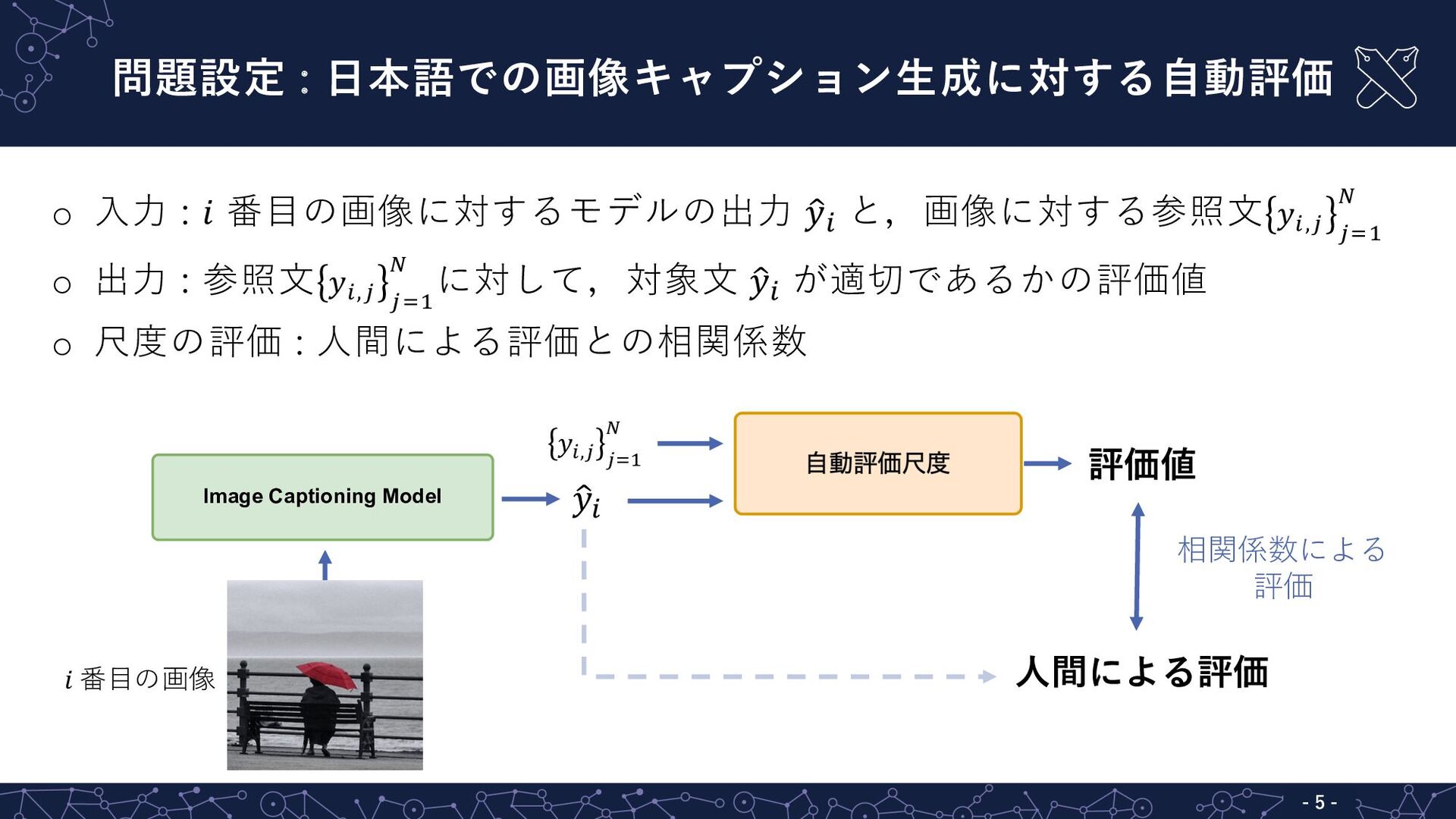
問題設定 : ⽇本語での画像キャプション⽣成に対する⾃動評価 - 5 - o ⼊⼒ : 𝑖
番⽬の画像に対するモデルの出⼒ " 𝑦! と,画像に対する参照⽂ 𝑦!,# #$% & o 出⼒ : 参照⽂ 𝑦!,# #$% & に対して,対象⽂ " 𝑦! が適切であるかの評価値 o 尺度の評価 : ⼈間による評価との相関係数 Image Captioning Model 𝑦!,# #$% & " 𝑦! 評価値 ⼈間による評価 相関係数による 評価 𝑖 番⽬の画像
⽇本語を評価可能なシーングラフに基づく⾃動評価尺度は存在しない - 6 - o 𝑛-gramに基づく⾃動評価尺度 • 代表例: BLEU, METEOR,
ROUGE, CIDEr → これらはいずれも⽇本語でも利⽤可 o SPICE [Anderson+, ECCV16] • 𝑛-gramに基づく評価尺度は⼈間による評価との相関が⾼くないことを報告 • Universal Dependency [Marneffe+, LREC14]に基づくシーングラフから評価 ⇒ ⽇本語キャプションを評価可能なシーングラフに基づく⾃動評価尺度は存在しない
JaSPICE: ⽇本語における画像キャプション⽣成のための⾃動評価尺度 - 7 - o 新規性 • ⽇本語キャプションを扱うことが可能 •
SPICEとは異なり, 係り受け構造と述語項構造に基づきシーングラフを⽣成 • 同義語を利⽤したグラフの拡張⼿法を導⼊ o Japanese Scene Graph Parser (JaSGP)とGraph Analyzer (GA)から構成
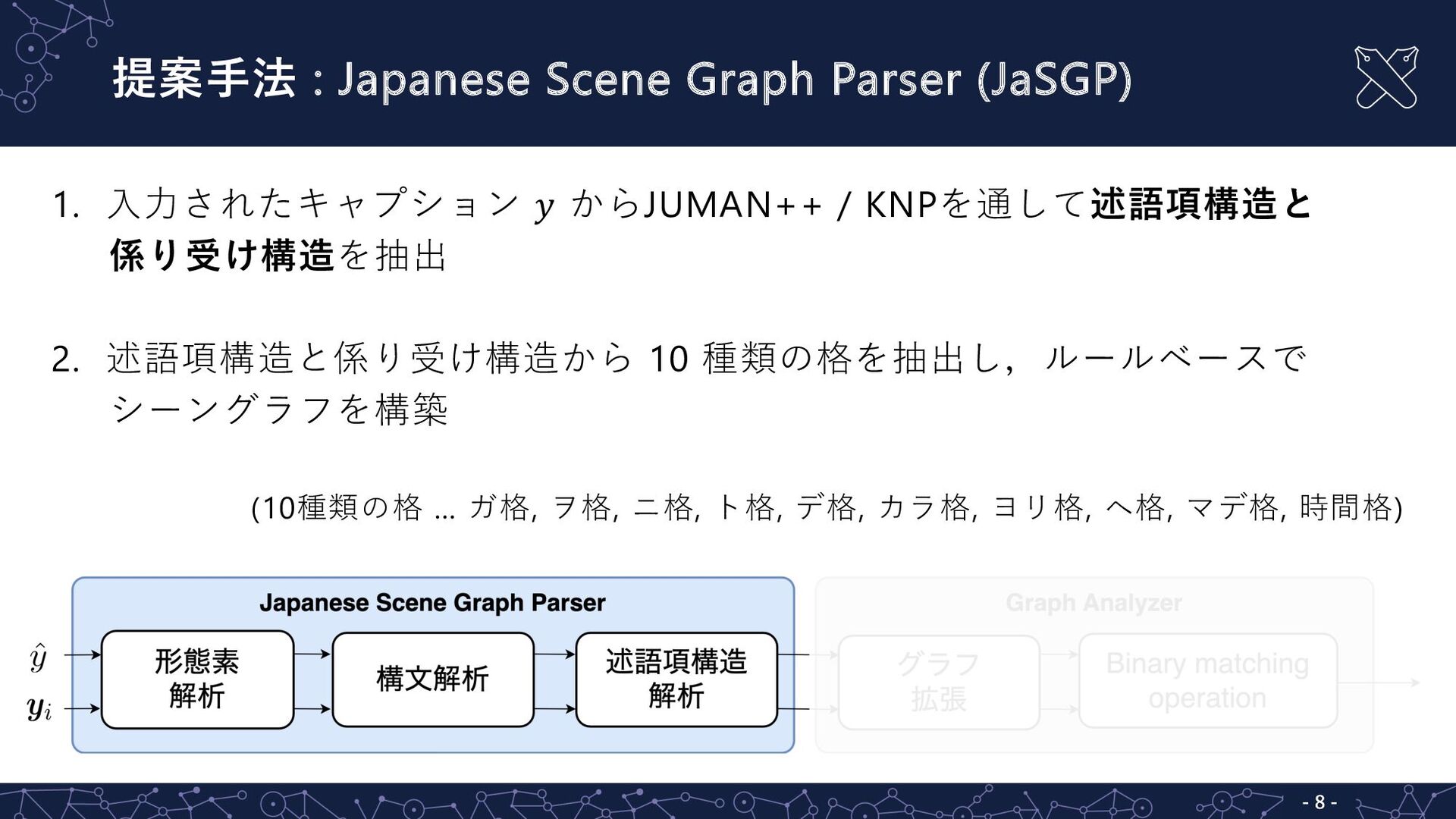
提案⼿法 : Japanese Scene Graph Parser (JaSGP) - 8 -
1. ⼊⼒されたキャプション 𝑦 からJUMAN++ / KNPを通して述語項構造と 係り受け構造を抽出 2. 述語項構造と係り受け構造から 10 種類の格を抽出し,ルールベースで シーングラフを構築 (10種類の格 … ガ格, ヲ格, ニ格, ト格, デ格, カラ格, ヨリ格, ヘ格, マデ格, 時間格)
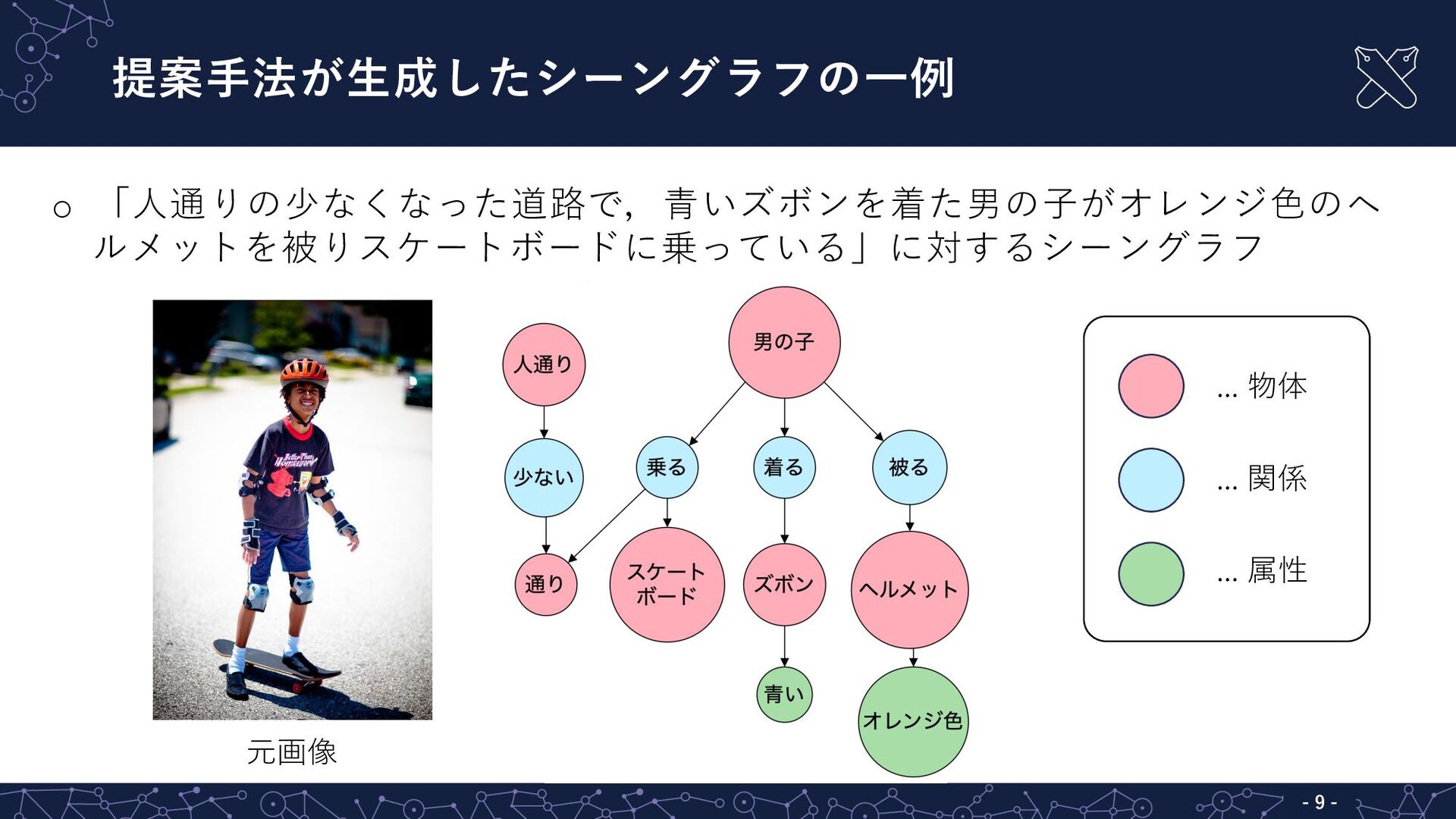
提案⼿法が⽣成したシーングラフの⼀例 - 9 - o 「⼈通りの少なくなった道路で,⻘いズボンを着た男の⼦がオレンジ⾊のヘ ルメットを被りスケートボードに乗っている」に対するシーングラフ 元画像 … 物体
… 関係 … 属性
GA : 同義語によるグラフ拡張 / Binary matching - 10 - o
グラフ拡張: 同義語によるグラフ拡張 o Binary matching: 参照⽂群と対象⽂のシーングラフを⽐較 ⊗は⼆つのシーングラフのうち ⼀致している組を返す演算⼦ 𝑇 𝐺 𝑥 ∶= 𝑂 𝑥 ∪ 𝐸 𝑥 ∪ 𝐾 𝑥 適合率 再現率 JaSPICE
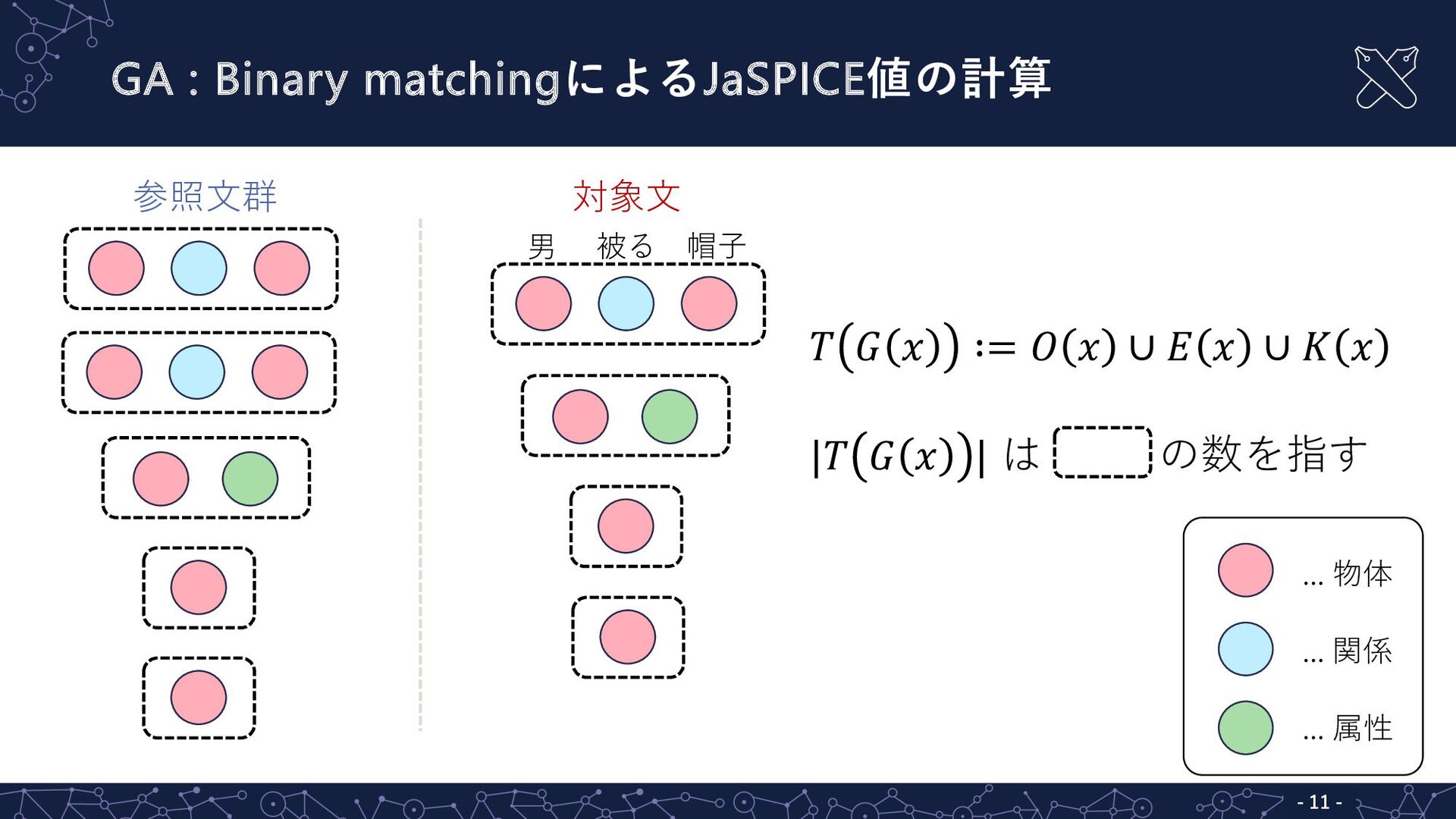
GA : Binary matchingによるJaSPICE値の計算 - 11 - 𝑇 𝐺 𝑥
∶= 𝑂 𝑥 ∪ 𝐸 𝑥 ∪ 𝐾 𝑥 |𝑇 𝐺 𝑥 | は の数を指す … 物体 … 関係 … 属性 参照⽂群 対象⽂ 男 被る 帽⼦
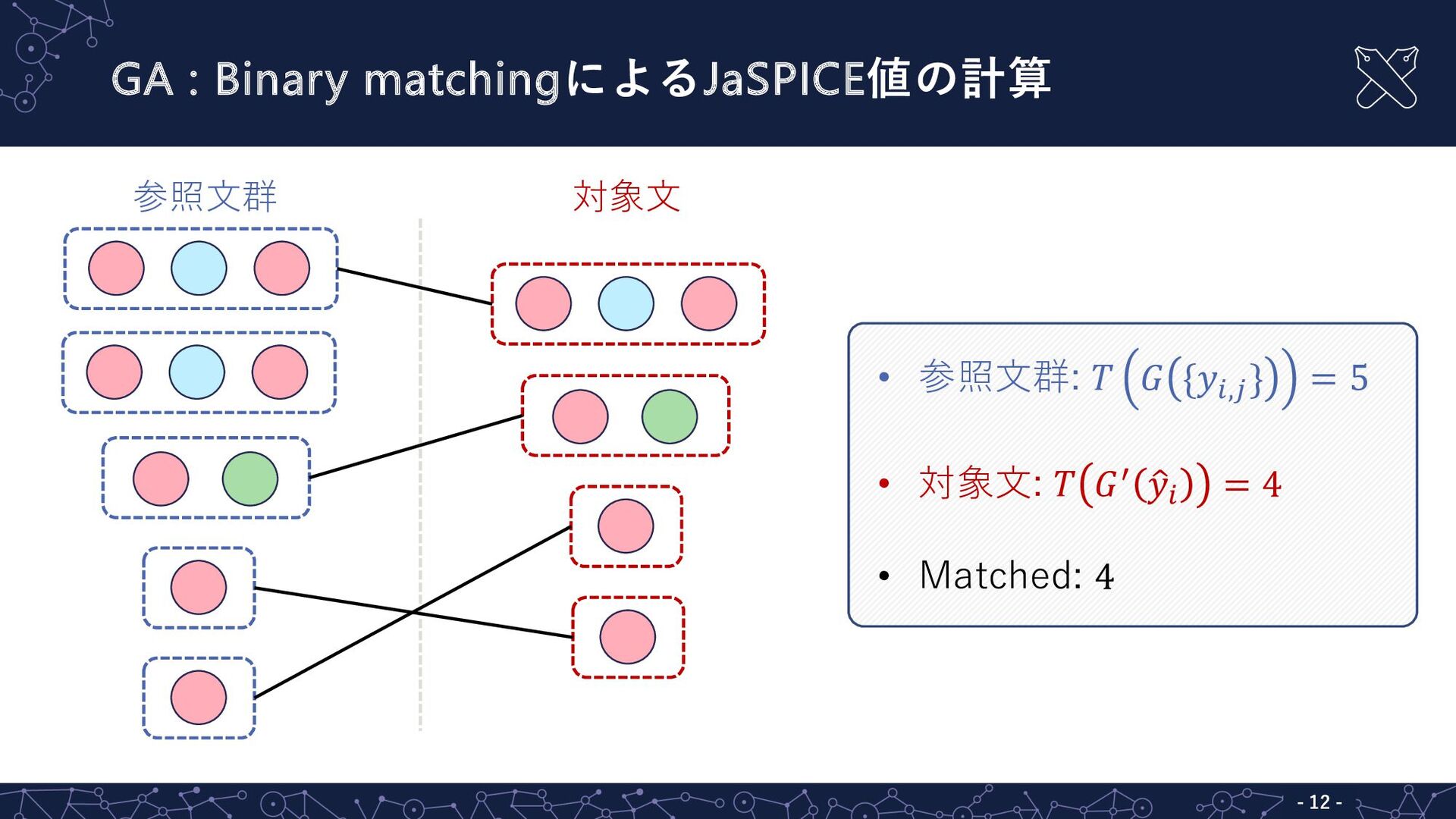
GA : Binary matchingによるJaSPICE値の計算 - 12 - 参照⽂群 対象⽂ •
参照⽂群: 𝑇 𝐺 {𝑦!,% } = 5 • 対象⽂: 𝑇 𝐺& ( 𝑦! = 4 • Matched: 4
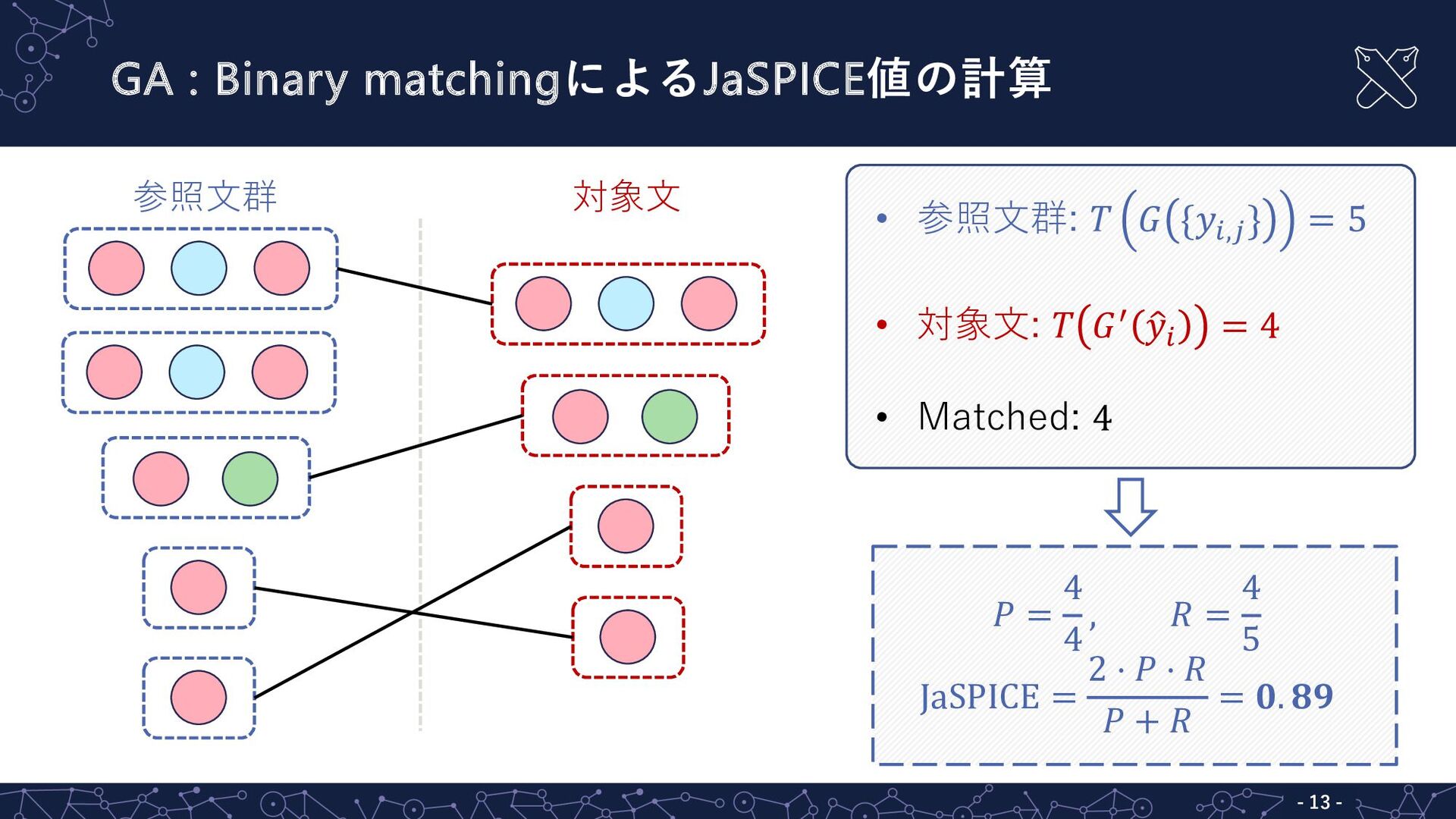
GA : Binary matchingによるJaSPICE値の計算 - 13 - 参照⽂群 対象⽂ 𝑃
= 4 4 , 𝑅 = 4 5 JaSPICE = 2 ⋅ 𝑃 ⋅ 𝑅 𝑃 + 𝑅 = 𝟎. 𝟖𝟗 • 参照⽂群: 𝑇 𝐺 {𝑦!,% } = 5 • 対象⽂: 𝑇 𝐺& ( 𝑦! = 4 • Matched: 4
被験者実験: 被験者100⼈から約2万サンプル収集 - 14 - o クラウドソーシングサービス により評価を収集 • 被験者
: 100⼈ • 22,350サンプル収集 o 与えられた 1 枚の画像と, 対応するキャプションの組に 対してキャプションの適切さ を 5 段階で評価.
Model SAT [Xu+, ICML15] ORT [Herdade+, NeurIPS19] ℳ'-Transformer [Cornia+, CVPR20]
DLCT [Luo+, AAAI21] ER-SAN [Li+, IJCAI22] ClipCapmlp [Mokady+, 21] ClipCaptrm [Mokady+, 21] Transformer𝐿 ∈ {3,6,12} 実験: 10個のモデル,2種類のデータセットで評価 - 15 - ⼤規模⽇本語キャプション データセット ・画像数 : 164,062 ・キャプション数 : 820,310 STAIR Captions o 10個の標準的なモデルを訓練 ロボットシステムにおける 指⽰⽂データセット ・画像数 : 1,080 ・指⽰⽂数 : 77,409 PFN-PIC
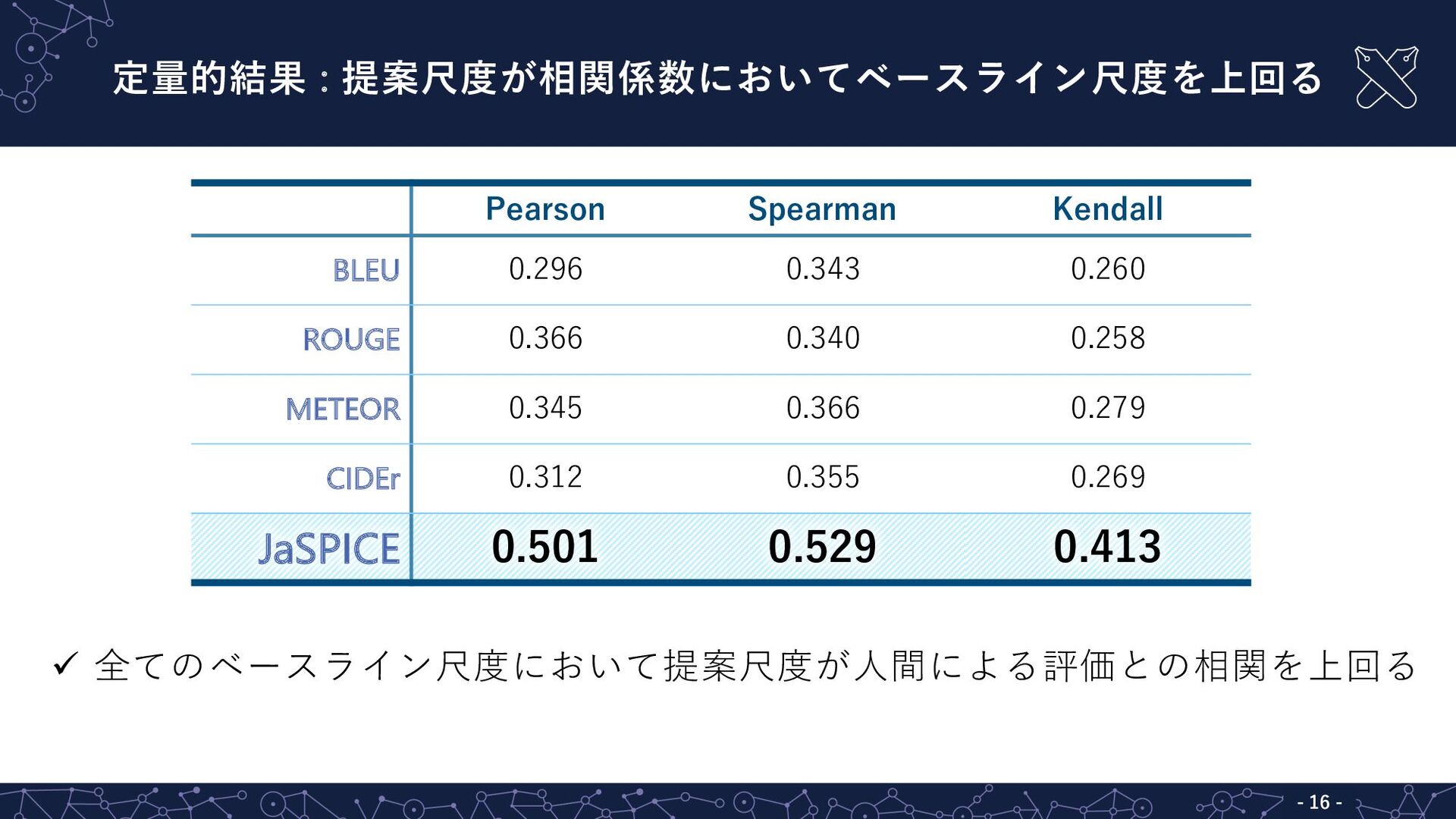
ü 全てのベースライン尺度において提案尺度が⼈間による評価との相関を上回る 定量的結果 : 提案尺度が相関係数においてベースライン尺度を上回る - 16 - Pearson Spearman
Kendall BLEU 0.296 0.343 0.260 ROUGE 0.366 0.340 0.258 METEOR 0.345 0.366 0.279 CIDEr 0.312 0.355 0.269 JaSPICE 0.501 0.529 0.413
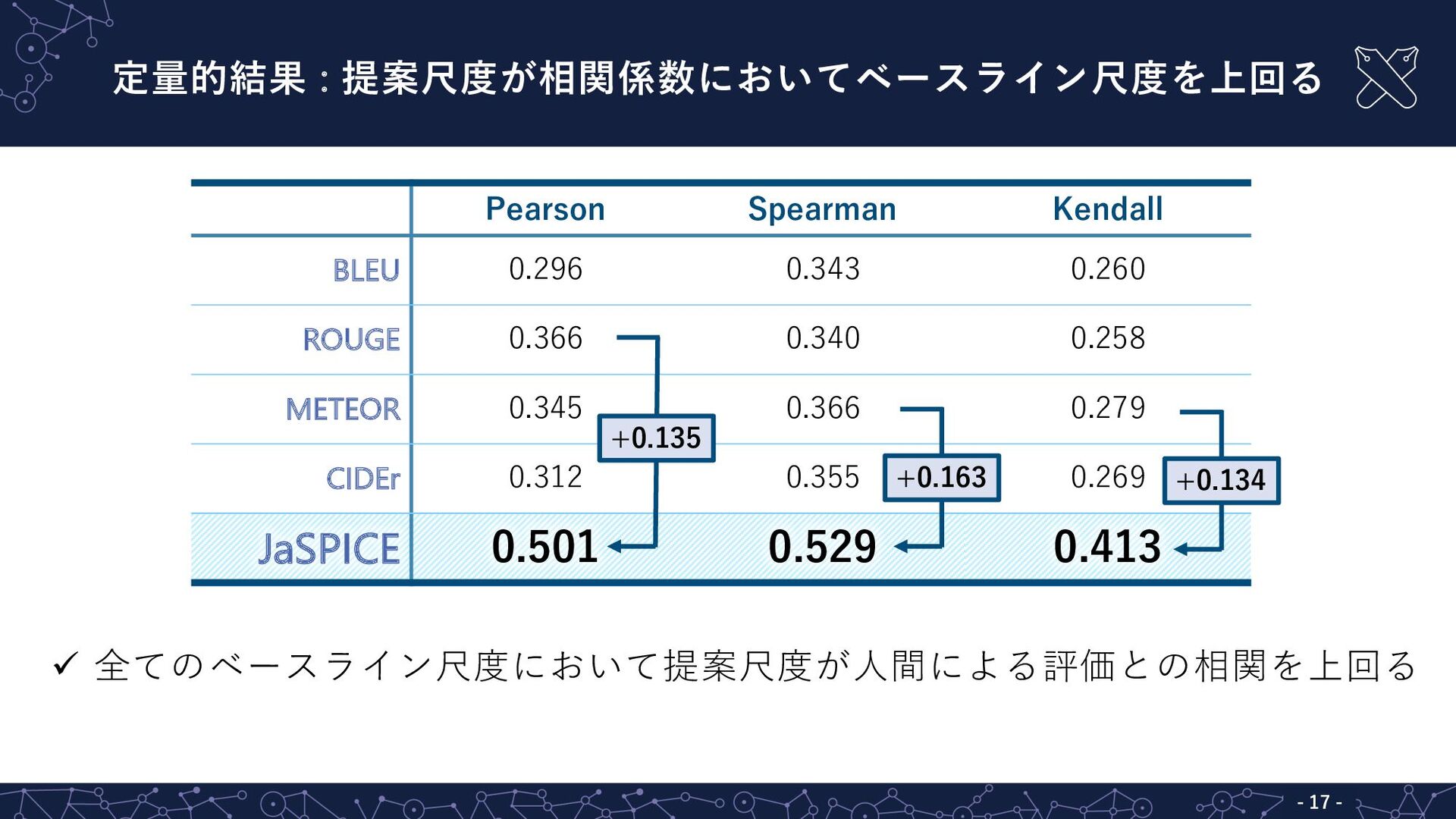
ü 全てのベースライン尺度において提案尺度が⼈間による評価との相関を上回る 定量的結果 : 提案尺度が相関係数においてベースライン尺度を上回る - 17 - Pearson Spearman
Kendall BLEU 0.296 0.343 0.260 ROUGE 0.366 0.340 0.258 METEOR 0.345 0.366 0.279 CIDEr 0.312 0.355 0.269 JaSPICE 0.501 0.529 0.413 +0.135 +0.163 +0.134
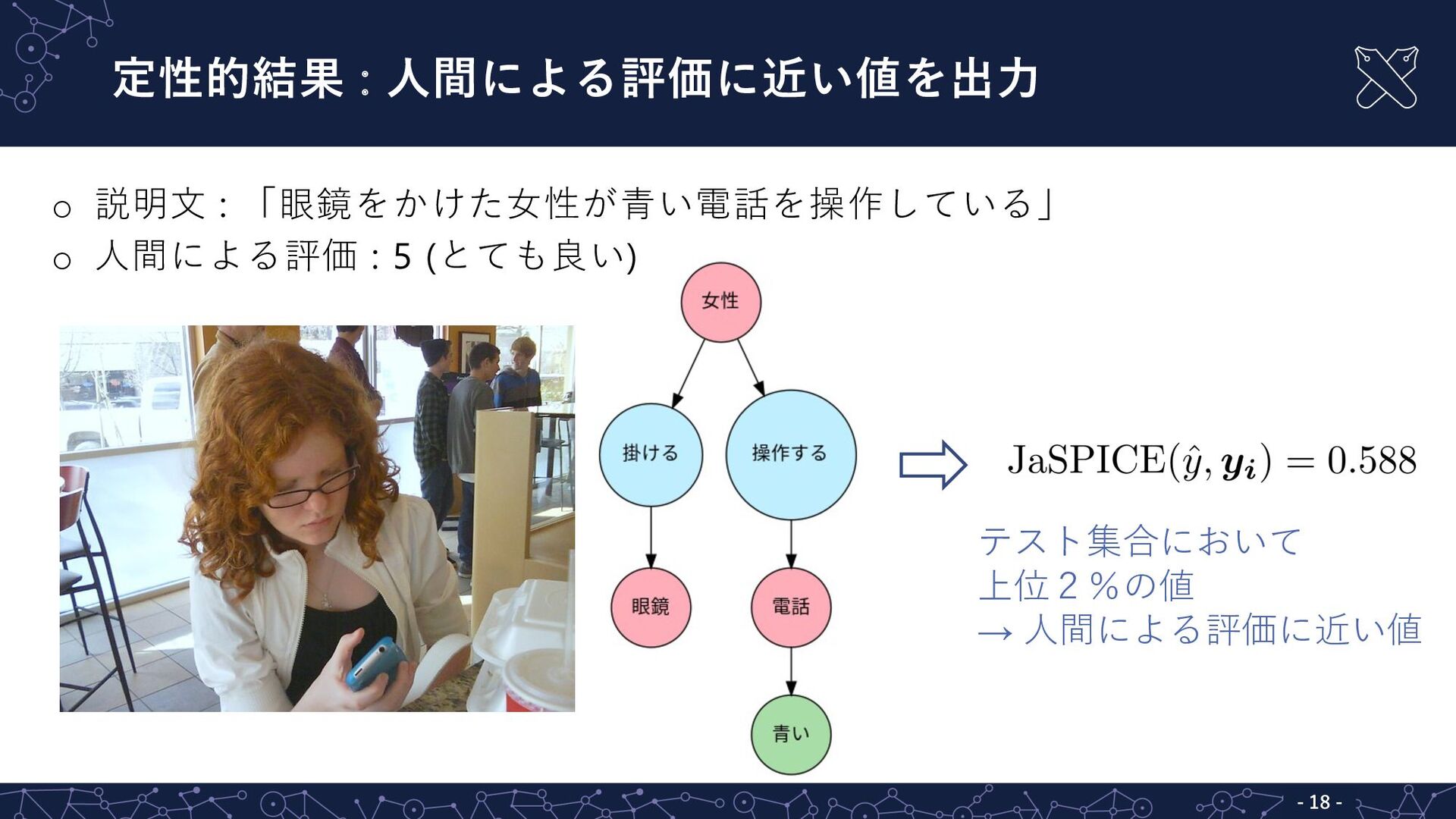
定性的結果 : ⼈間による評価に近い値を出⼒ - 18 - o 説明⽂ : 「眼鏡をかけた⼥性が⻘い電話を操作している」
o ⼈間による評価 : 5 (とても良い) テスト集合において 上位2%の値 → ⼈間による評価に近い値
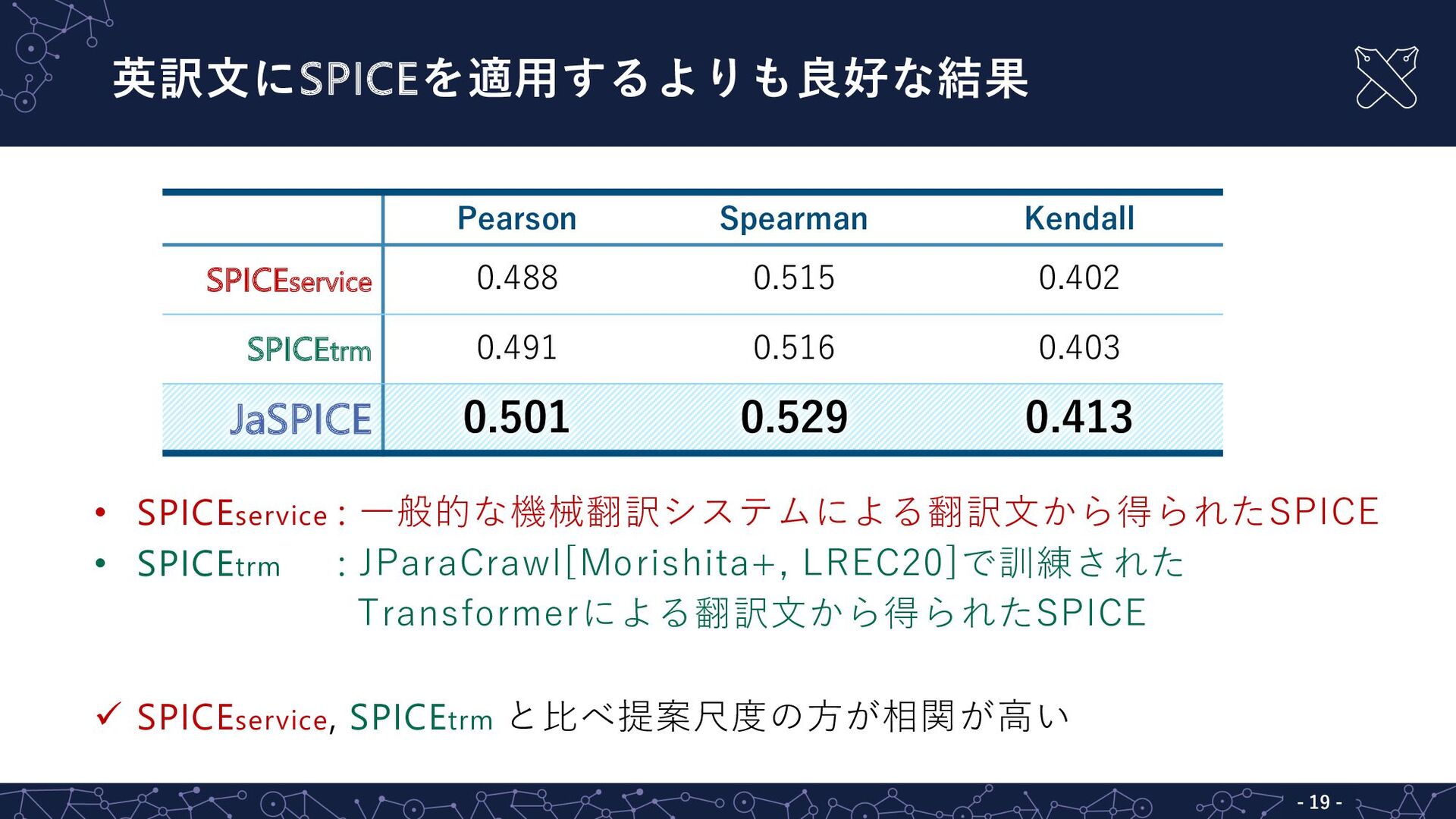
英訳⽂にSPICEを適⽤するよりも良好な結果 - 19 - • SPICEservice : ⼀般的な機械翻訳システムによる翻訳⽂から得られたSPICE • SPICEtrm
: JParaCrawl[Morishita+, LREC20]で訓練された Transformerによる翻訳⽂から得られたSPICE ü SPICEservice, SPICEtrm と⽐べ提案尺度の⽅が相関が⾼い Pearson Spearman Kendall SPICEservice 0.488 0.515 0.402 SPICEtrm 0.491 0.516 0.403 JaSPICE 0.501 0.529 0.413
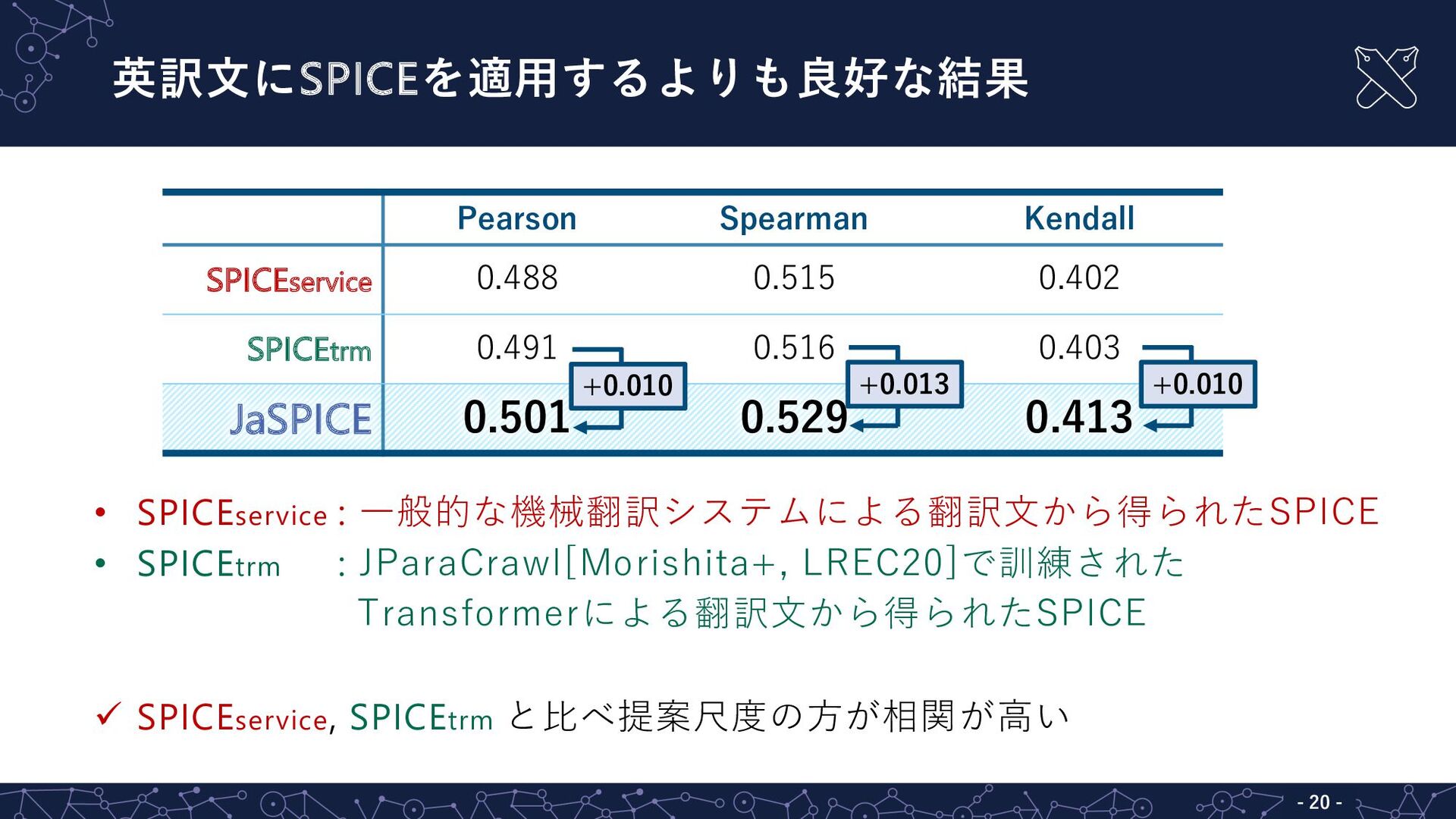
Pearson Spearman Kendall SPICEservice 0.488 0.515 0.402 SPICEtrm 0.491 0.516
0.403 JaSPICE 0.501 0.529 0.413 英訳⽂にSPICEを適⽤するよりも良好な結果 - 20 - • SPICEservice : ⼀般的な機械翻訳システムによる翻訳⽂から得られたSPICE • SPICEtrm : JParaCrawl[Morishita+, LREC20]で訓練された Transformerによる翻訳⽂から得られたSPICE ü SPICEservice, SPICEtrm と⽐べ提案尺度の⽅が相関が⾼い +0.010 +0.013 +0.010
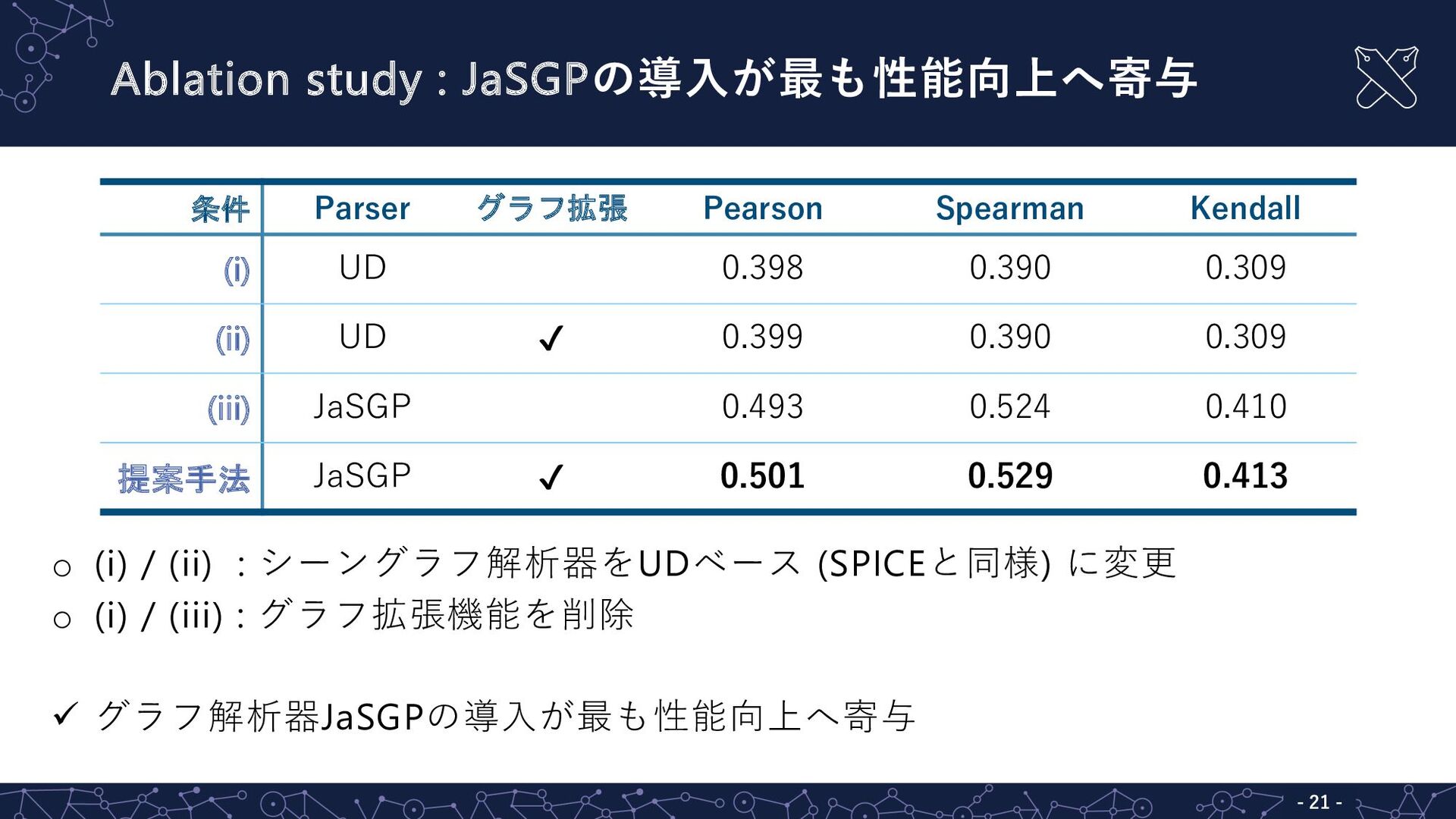
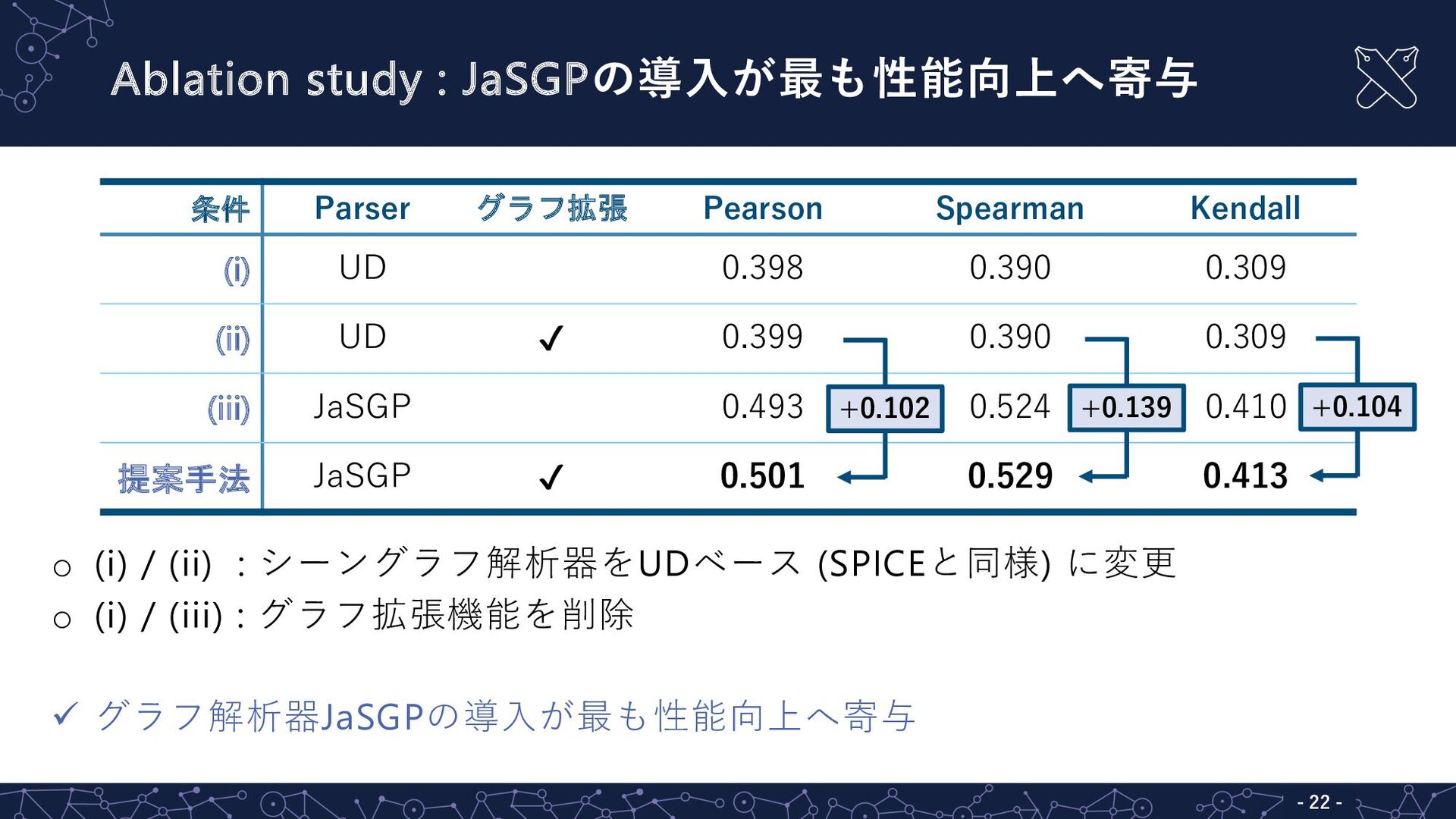
Ablation study : JaSGPの導⼊が最も性能向上へ寄与 - 21 - o (i) /
(ii) : シーングラフ解析器をUDベース (SPICEと同様) に変更 o (i) / (iii) : グラフ拡張機能を削除 ü グラフ解析器JaSGPの導⼊が最も性能向上へ寄与 条件 Parser グラフ拡張 Pearson Spearman Kendall (i) UD 0.398 0.390 0.309 (ii) UD ✔ 0.399 0.390 0.309 (iii) JaSGP 0.493 0.524 0.410 提案手法 JaSGP ✔ 0.501 0.529 0.413
Ablation study : JaSGPの導⼊が最も性能向上へ寄与 - 22 - o (i) /
(ii) : シーングラフ解析器をUDベース (SPICEと同様) に変更 o (i) / (iii) : グラフ拡張機能を削除 ü グラフ解析器JaSGPの導⼊が最も性能向上へ寄与 条件 Parser グラフ拡張 Pearson Spearman Kendall (i) UD 0.398 0.390 0.309 (ii) UD ✔ 0.399 0.390 0.309 (iii) JaSGP 0.493 0.524 0.410 提案手法 JaSGP ✔ 0.501 0.529 0.413 +0.102 +0.139 +0.104
まとめ - 23 - o ⽇本語における画像キャプション⽣成のための⾃動評価尺度JaSPICEを提案 o 新規性 • ⽇本語キャプションを扱うことが可能
• SPICEとは異なり, 係り受け構造と述語項構造に基づきシーングラフを⽣成 • 同義語を利⽤したグラフの拡張⼿法を導⼊
Project Page: JaSPICE - 24 - Project Page: https://yuiga.dev/jaspice
25 Appendix
問題設定 : シーングラフ - 26 - o キャプション 𝑦 におけるシーングラフ
o 𝑂 𝑦 , 𝐸 𝑦 , 𝐾 𝑦 はそれぞれ 𝑦 に含まれる物体,関係,属性の集合を指す. o また 𝐶, 𝑅, 𝐴をそれぞれ物体,関係,属性の全体集合とすると,
問題設定 : シーングラフ - 27 - o キャプション 𝑦 におけるシーングラフ
… 物体 … 関係 … 属性
問題設定 : シーングラフ - 28 - o キャプション 𝑦 におけるシーングラフ
… 物体 … 関係 … 属性
問題設定 : シーングラフ - 29 - o キャプション 𝑦 におけるシーングラフ
… 物体 … 関係 … 属性
問題設定 : シーングラフ - 30 - o キャプション 𝑦 におけるシーングラフ
… 物体 … 関係 … 属性
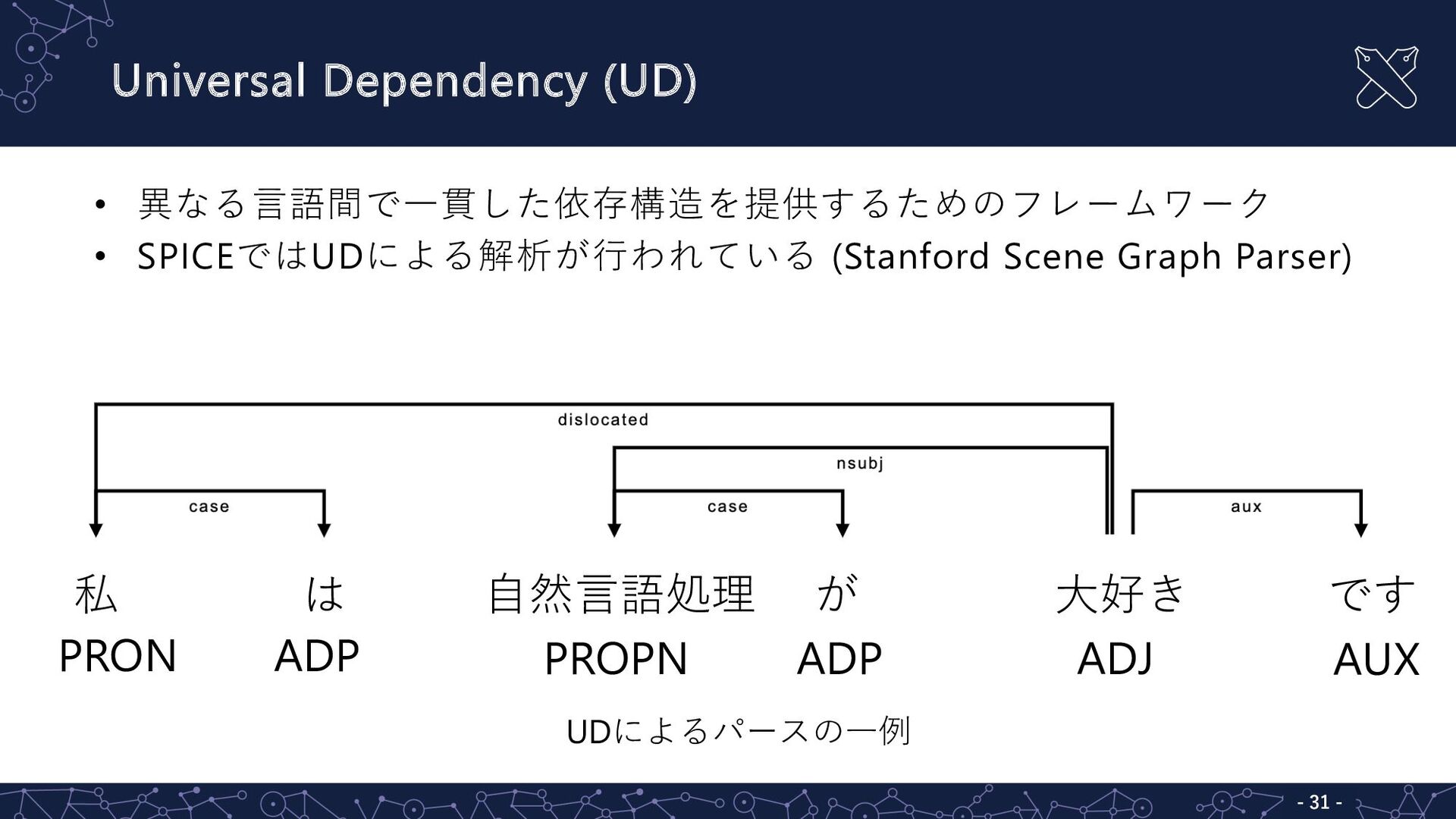
Universal Dependency (UD) - 31 - • 異なる⾔語間で⼀貫した依存構造を提供するためのフレームワーク • SPICEではUDによる解析が⾏われている
(Stanford Scene Graph Parser) UDによるパースの⼀例 私 は ⾃然⾔語処理 が ⼤好き です ADP PRON PROPN ADP ADJ AUX
既存研究 : SPICEを⽇本語へ直接適⽤することは難しい - 32 - o ⽇本語へSPICEを直接適⽤する⼆つの⽅法 1. SPICEと同様UDを⽤いてシーングラフを⽣成
→ UDは基本的な依存関係しか抽出できない → ⽇本語における「AのB」などの複雑な関係への対処が不⼗分 2. 翻訳器による英訳⽂からSPICEを計算 → TextCaps [Sidorov+, ECCV20]の問題設定のように,画像中の単語を翻訳 することが不適切な場合がある ⇒ SPICEを⽇本語へ直接適⽤することは困難 A B ? ?
既存研究 : SPICEを⽇本語へ直接適⽤することは難しい - 33 - o ⽇本語へSPICEを直接適⽤する⼆つの⽅法 1. SPICEと同様UDを⽤いてシーングラフを⽣成
→ UDは基本的な依存関係しか抽出できない → ⽇本語における「AのB」などの複雑な関係への対処が不⼗分 2. 翻訳器による英訳⽂からSPICEを計算 → TextCaps [Sidorov+, ECCV20]の問題設定のように,画像中の単語を翻訳 することが不適切な場合がある ⇒ SPICEを⽇本語へ直接適⽤することは困難 A B ? ?
既存研究 : SPICEを⽇本語へ直接適⽤することは難しい - 34 - o ⽇本語へSPICEを直接適⽤する⼆つの⽅法 1. SPICEと同様UDを⽤いてシーングラフを⽣成
→ UDは基本的な依存関係しか抽出できない → ⽇本語における「AのB」などの複雑な関係への対処が不⼗分 2. 翻訳器による英訳⽂からSPICEを計算 → TextCaps [Sidorov+, ECCV20]の問題設定のように,画像中の単語を翻訳 することが不適切な場合がある ⇒ SPICEを⽇本語へ直接適⽤することは困難 " 𝑦! :「美味しいご飯」と黒板に 文字を書く女性
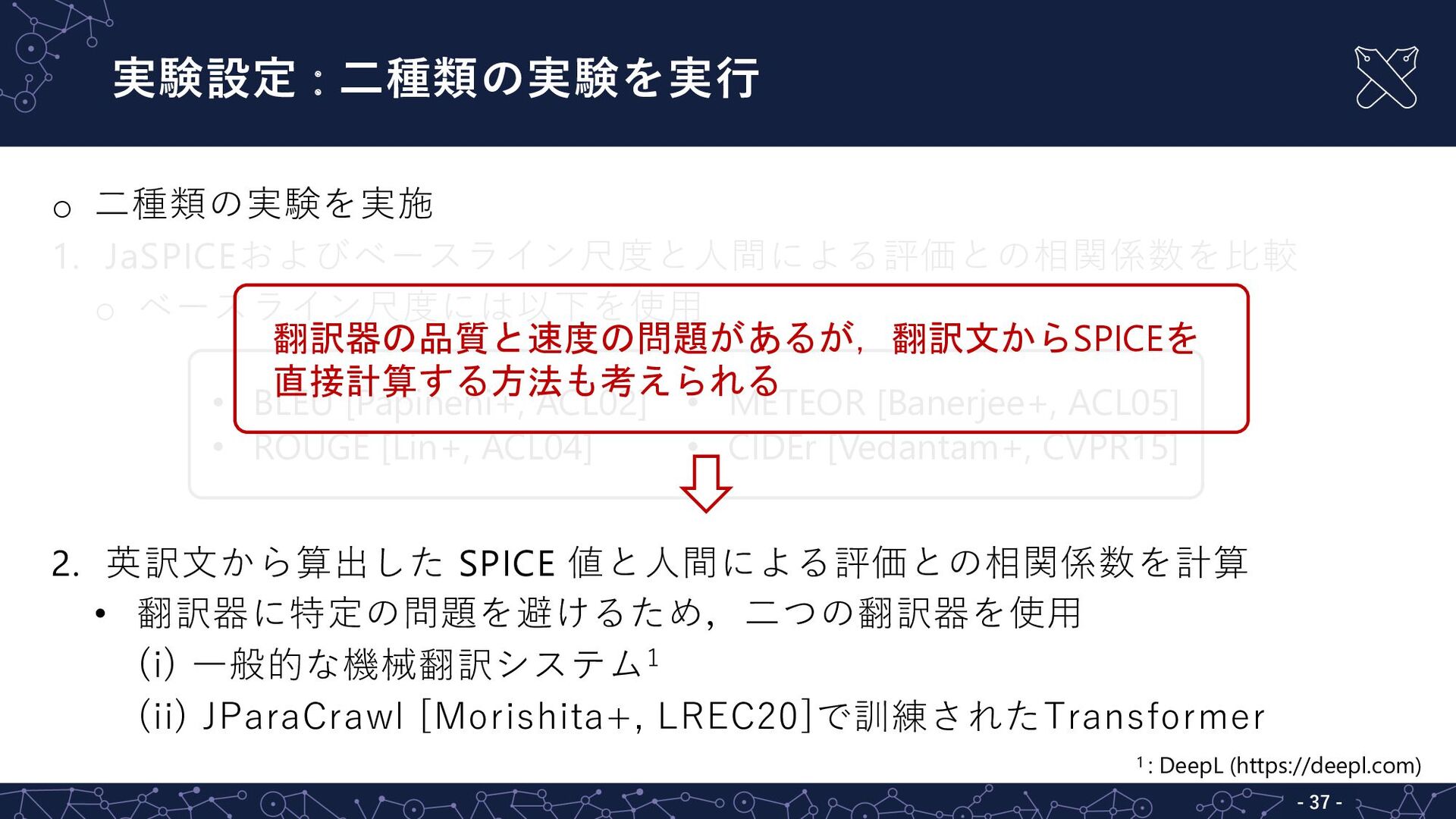
実験設定 : ⼆種類の実験を実⾏ - 35 - o ⼆種類の実験を実施 1. JaSPICEおよびベースライン尺度と⼈間による評価との相関係数を⽐較
o ベースライン尺度には以下を使⽤ 2. 英訳⽂から算出した SPICE 値と⼈間による評価との相関係数を計算 • 翻訳器に特定の問題を避けるため,⼆つの翻訳器を使⽤ (i) ⼀般的な機械翻訳システム1 (ii) JParaCrawl[Morishita+, LREC20]で訓練されたTransformer 1 : DeepL (https://deepl.com) • BLEU [Papineni+, ACL02] • ROUGE [Lin+, ACL04] • METEOR [Banerjee+, ACL05] • CIDEr [Vedantam+, CVPR15]
実験設定 : ⼆種類の実験を実⾏ - 36 - o ⼆種類の実験を実施 1. JaSPICEおよびベースライン尺度と⼈間による評価との相関係数を⽐較
o ベースライン尺度には以下を使⽤ 2. 英訳⽂から算出した SPICE 値と⼈間による評価との相関係数を計算 • 翻訳器に特定の問題を避けるため,⼆つの翻訳器を使⽤ (i) ⼀般的な機械翻訳システム1 (ii) JParaCrawl[Morishita+, LREC20]で訓練されたTransformer 1 : DeepL (https://deepl.com) • BLEU [Papineni+, ACL02] • ROUGE [Lin+, ACL04] • METEOR [Banerjee+, ACL05] • CIDEr [Vedantam+, CVPR15]
実験設定 : ⼆種類の実験を実⾏ - 37 - o ⼆種類の実験を実施 1. JaSPICEおよびベースライン尺度と⼈間による評価との相関係数を⽐較
o ベースライン尺度には以下を使⽤ 2. 英訳⽂から算出した SPICE 値と⼈間による評価との相関係数を計算 • 翻訳器に特定の問題を避けるため,⼆つの翻訳器を使⽤ (i) ⼀般的な機械翻訳システム1 (ii) JParaCrawl [Morishita+, LREC20]で訓練されたTransformer 1 : DeepL (https://deepl.com) • BLEU [Papineni+, ACL02] • ROUGE [Lin+, ACL04] • METEOR [Banerjee+, ACL05] • CIDEr [Vedantam+, CVPR15] 翻訳器の品質と速度の問題があるが,翻訳文からSPICEを 直接計算する方法も考えられる
「AのB」は画像キャプションに多く含まれる - 38 - o ⽇本語における「AのB」は複数の意味を持つ. o 例 [⿊橋+, 99]
• 私の⾞ : 所有 • グレーの制服 : 様態 • 机のあし : 全体部分 • 専⾨家の調査 : 動作主 – 述語 • ラグビーのコーチ : 対象 • 野球の選⼿ : 範疇 • ⾵邪のウイルス : 結果 AとBが「物体」「関係」「属性」 のいずれであるかをUDから 決定するのは困難 「AのB」は属性・所有・位置関係等を表すので,画像キャプションに多く含まれる
提案⼿法 : Graph Analyzer (GA) - 39 - o Graph
Analyzer (GA)における⼊⼒ • 参照分群のシーングラフ 𝐺 𝑦!,# !$% & • 対象⽂のシーングラフ𝐺 " 𝑦! o 同義語集合によるグラフの拡張と,グラフに対するBinary matchingを⾏う.
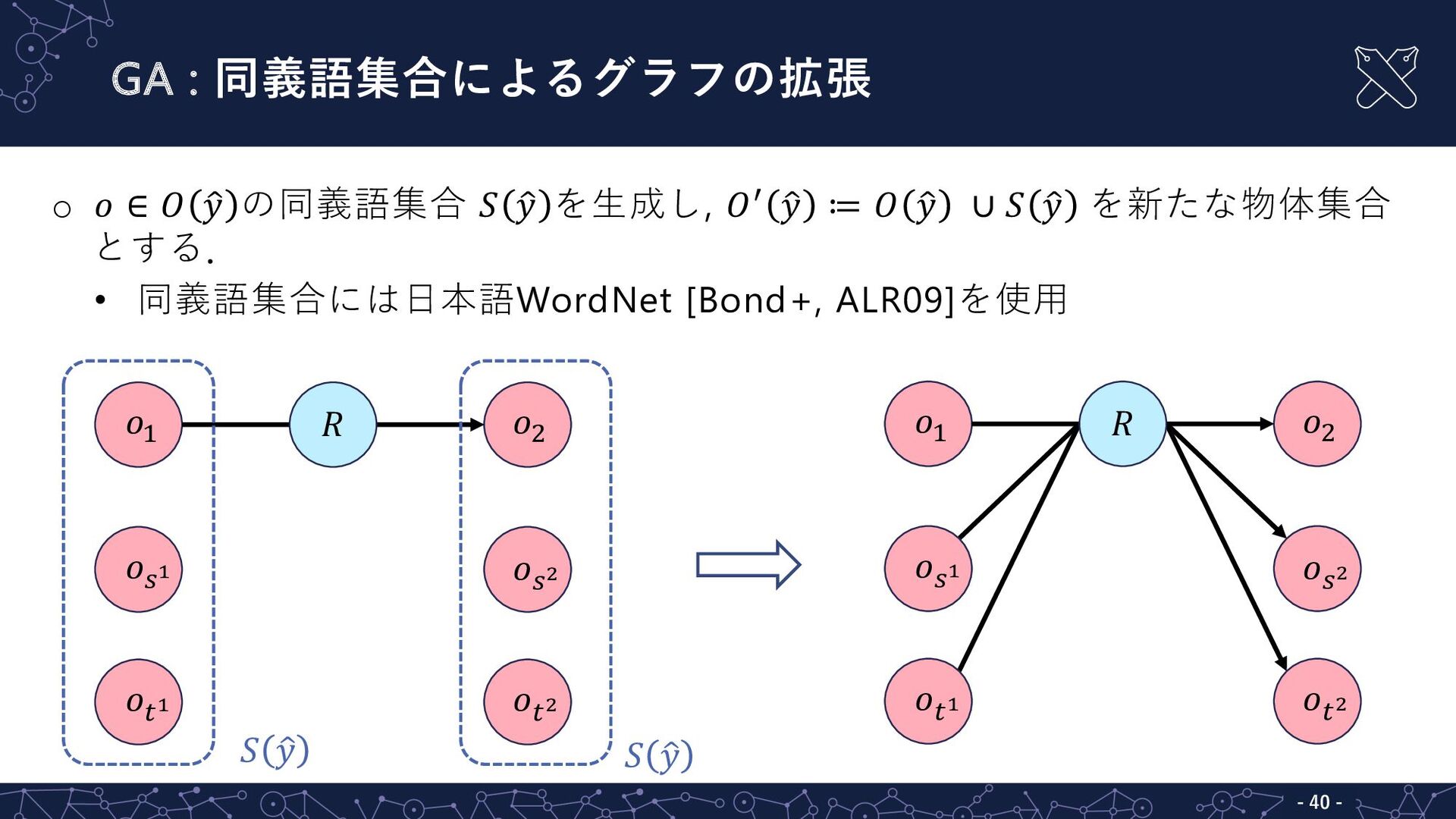
GA : 同義語集合によるグラフの拡張 - 40 - o 𝑜 ∈ 𝑂
" 𝑦 の同義語集合 𝑆 " 𝑦 を⽣成し, 𝑂& " 𝑦 ≔ 𝑂 " 𝑦 ∪ 𝑆 " 𝑦 を新たな物体集合 とする. • 同義語集合には⽇本語WordNet [Bond+, ALR09]を使⽤ 𝑜( 𝑜' 𝑅 𝑜)! 𝑜)" 𝑜*! 𝑜*" 𝑆 " 𝑦 𝑆 " 𝑦 𝑜( 𝑜' 𝑅 𝑜)! 𝑜)" 𝑜*! 𝑜*"
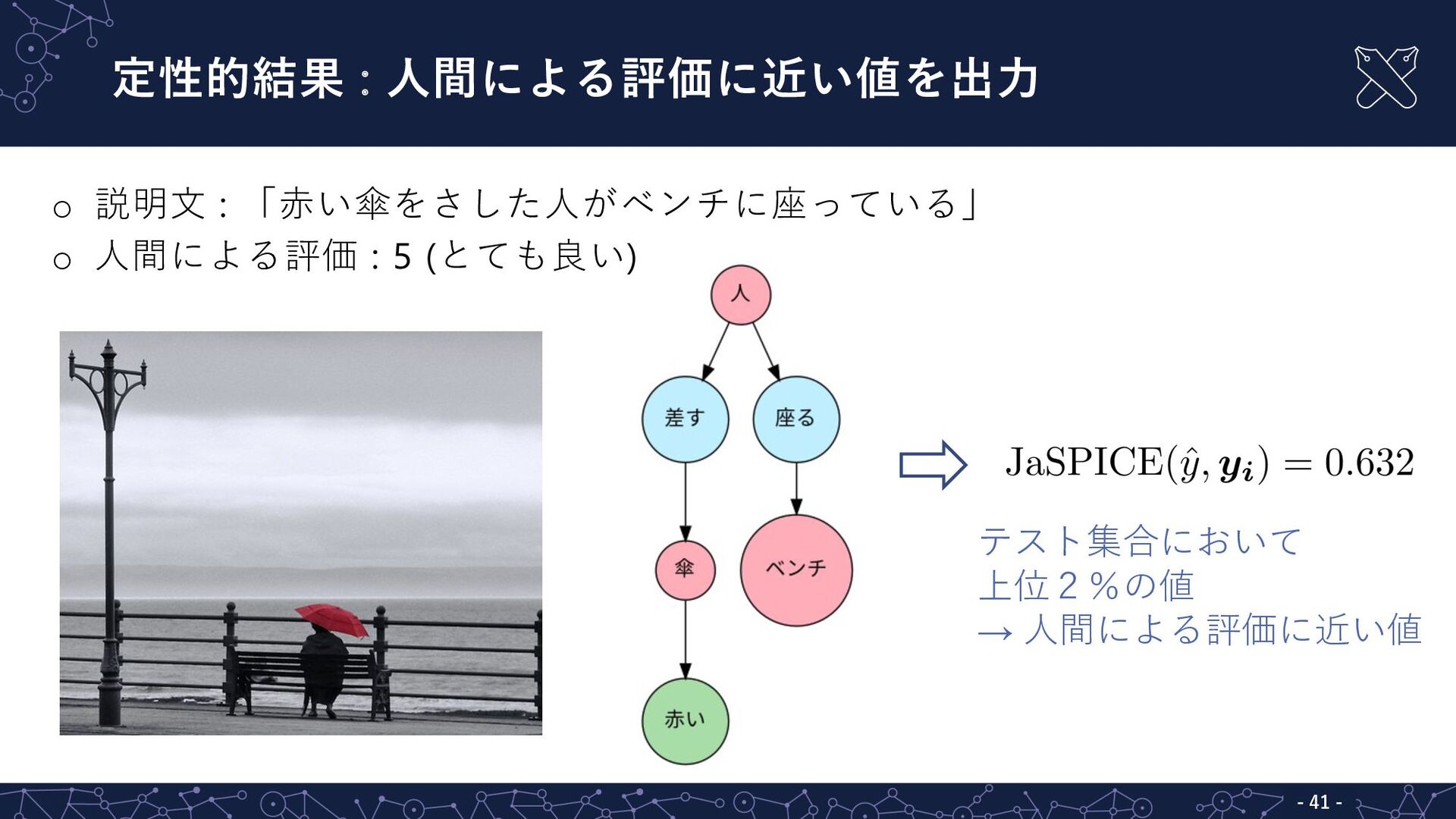
定性的結果 : ⼈間による評価に近い値を出⼒ - 41 - o 説明⽂ : 「⾚い傘をさした⼈がベンチに座っている」
o ⼈間による評価 : 5 (とても良い) テスト集合において 上位2%の値 → ⼈間による評価に近い値
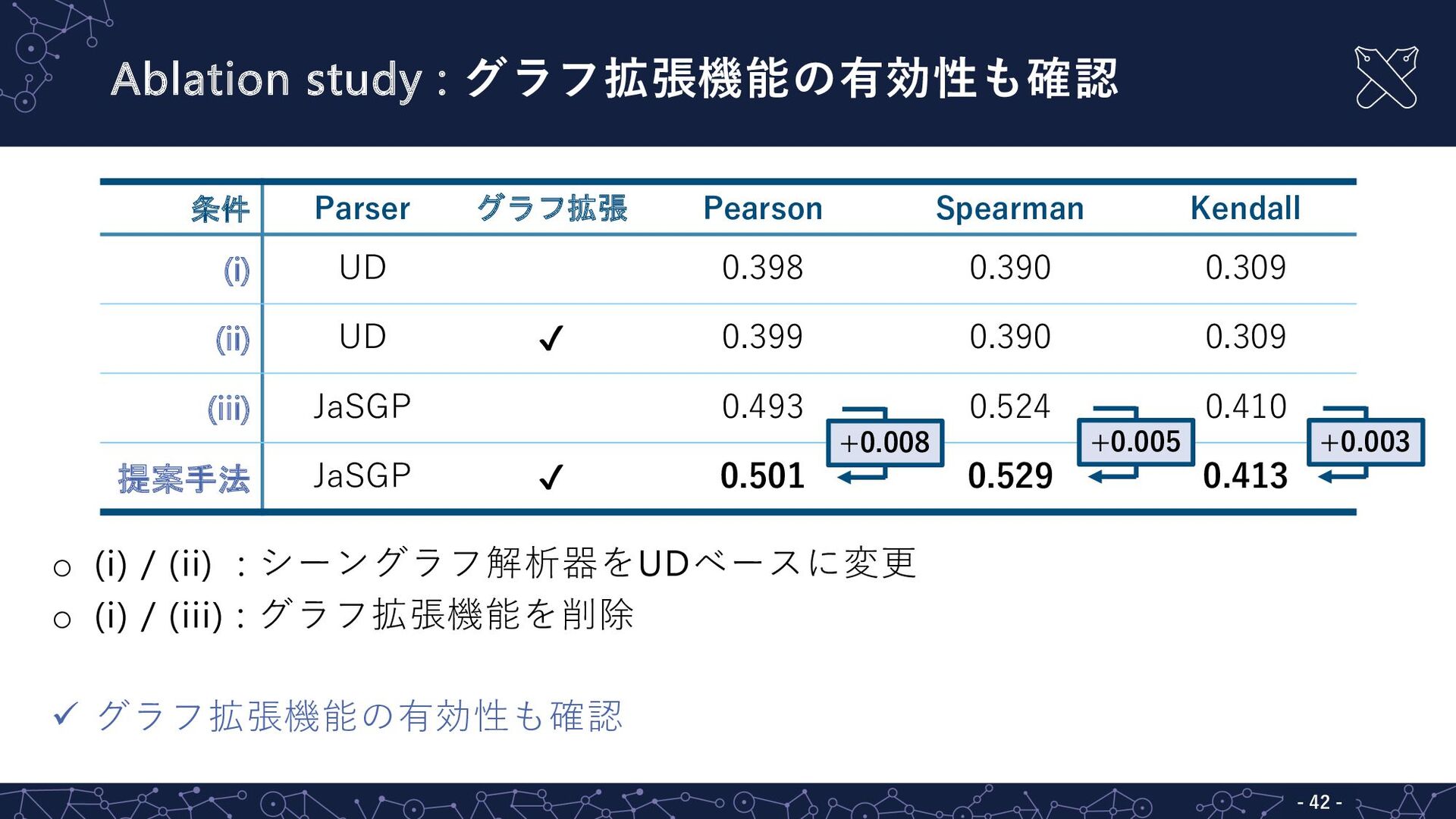
Ablation study : グラフ拡張機能の有効性も確認 - 42 - o (i) /
(ii) : シーングラフ解析器をUDベースに変更 o (i) / (iii) : グラフ拡張機能を削除 ü グラフ拡張機能の有効性も確認 条件 Parser グラフ拡張 Pearson Spearman Kendall (i) UD 0.398 0.390 0.309 (ii) UD ✔ 0.399 0.390 0.309 (iii) JaSGP 0.493 0.524 0.410 提案手法 JaSGP ✔ 0.501 0.529 0.413 +0.008 +0.005 +0.003
各モデルについて - 43 - o ClipCapmlp • Mapping NetworkをMLPにしたClipCap o
ClipCaptrm • Mapping NetworkをTransformerにしたClipCap o Transformer𝐿 ∈ 3,6,12 • Bottom-up Feature[Anderson+, CVPR18]を⼊⼒に⽤いた 3, 6, 12 層から なるTransformer ClipCap [Mokady+, 21]
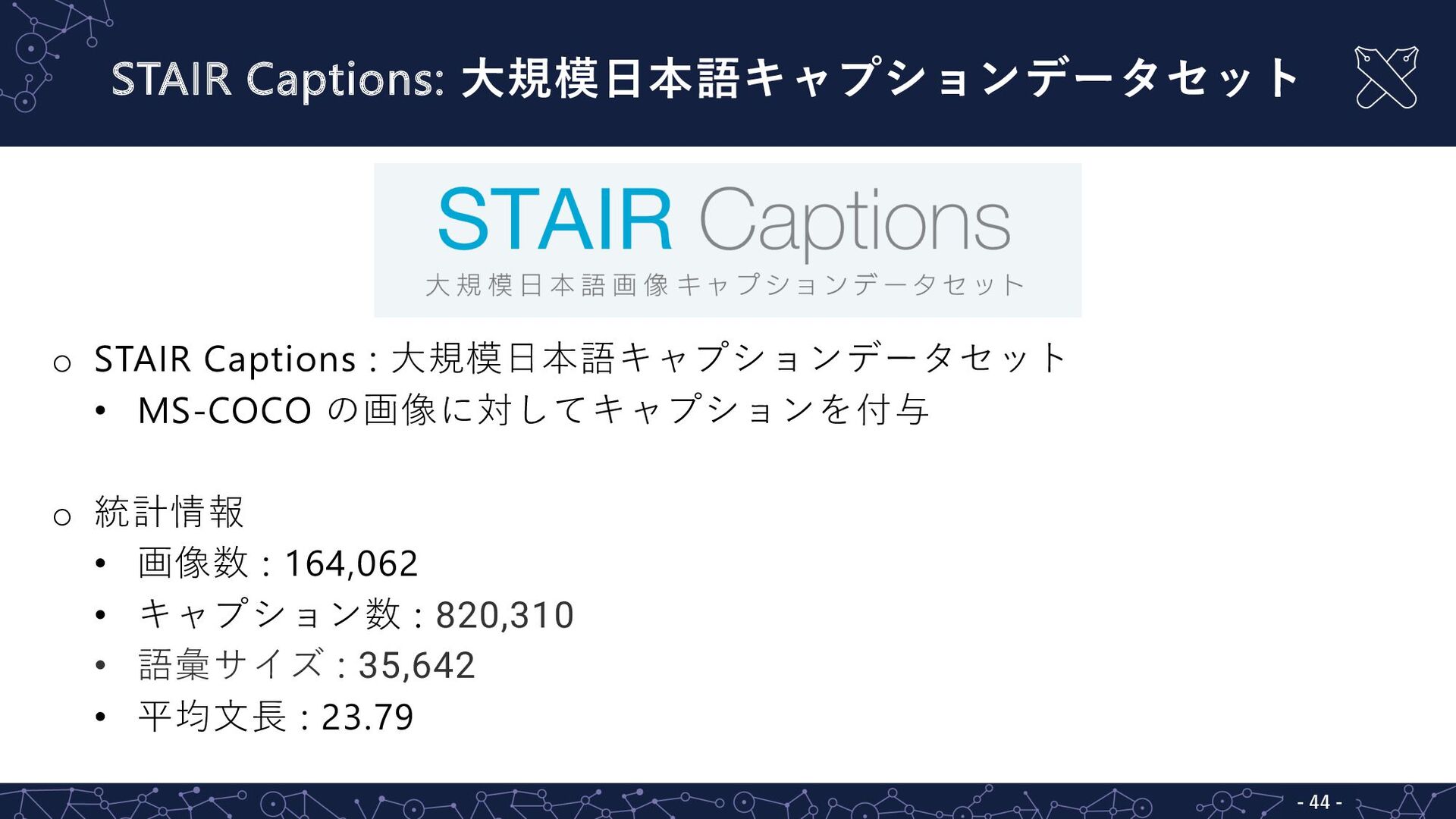
STAIR Captions: ⼤規模⽇本語キャプションデータセット - 44 - o STAIR Captions :
⼤規模⽇本語キャプションデータセット • MS-COCO の画像に対してキャプションを付与 o 統計情報 • 画像数 : 164,062 • キャプション数 : 820,310 • 語彙サイズ : 35,642 • 平均⽂⻑ : 23.79
PFN-PIC: ロボットシステムにおける指⽰⽂データセット - 45 - o PFN-PIC: ⽇本語と英語の指⽰⽂を含むデータセット • 各画像について最低三⼈のアノテータによって指⽰⽂が付与
o 統計情報 (train) • 画像数: 1,060枚 • 対象物体: 255,00個 • 指⽰⽂: 76,511⽂ o 統計情報 (test) • 画像数: 20枚 • 対象物体: 353個 • 指⽰⽂: 898⽂
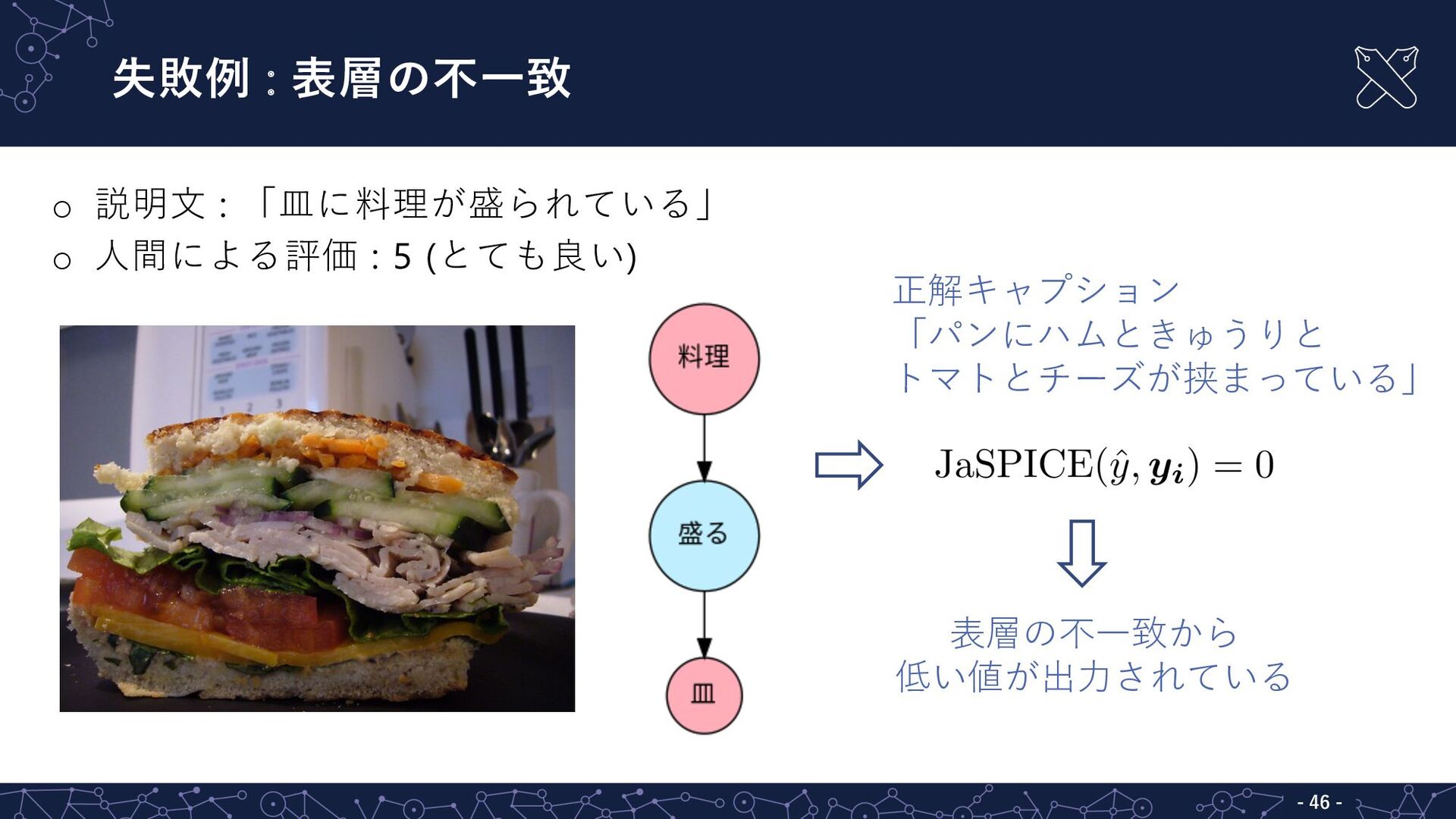
失敗例 : 表層の不⼀致 - 46 - o 説明⽂ : 「⽫に料理が盛られている」
o ⼈間による評価 : 5 (とても良い) 表層の不⼀致から 低い値が出⼒されている 正解キャプション 「パンにハムときゅうりと トマトとチーズが挟まっている」
TextCapsについて - 47 - o TextCaps[Sidorov+, ECCV20] • 画像中のテキストに依存した画像キャプション⽣成データセット
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Model SAT [Xu+, ICML15] ORT [Herdade+, NeurIPS19] ℳ'-Transformer [Cornia+, CVPR20]](https://files.speakerdeck.com/presentations/ee53e49efa8141e5959b0f5f4f58f8d3/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![「AのB」は画像キャプションに多く含まれる - 38 - o ⽇本語における「AのB」は複数の意味を持つ. o 例 [⿊橋+, 99]](https://files.speakerdeck.com/presentations/ee53e49efa8141e5959b0f5f4f58f8d3/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TextCapsについて - 47 - o TextCaps[Sidorov+, ECCV20] • 画像中のテキストに依存した画像キャプション⽣成データセット](https://files.speakerdeck.com/presentations/ee53e49efa8141e5959b0f5f4f58f8d3/slide_46.jpg){kind=link}