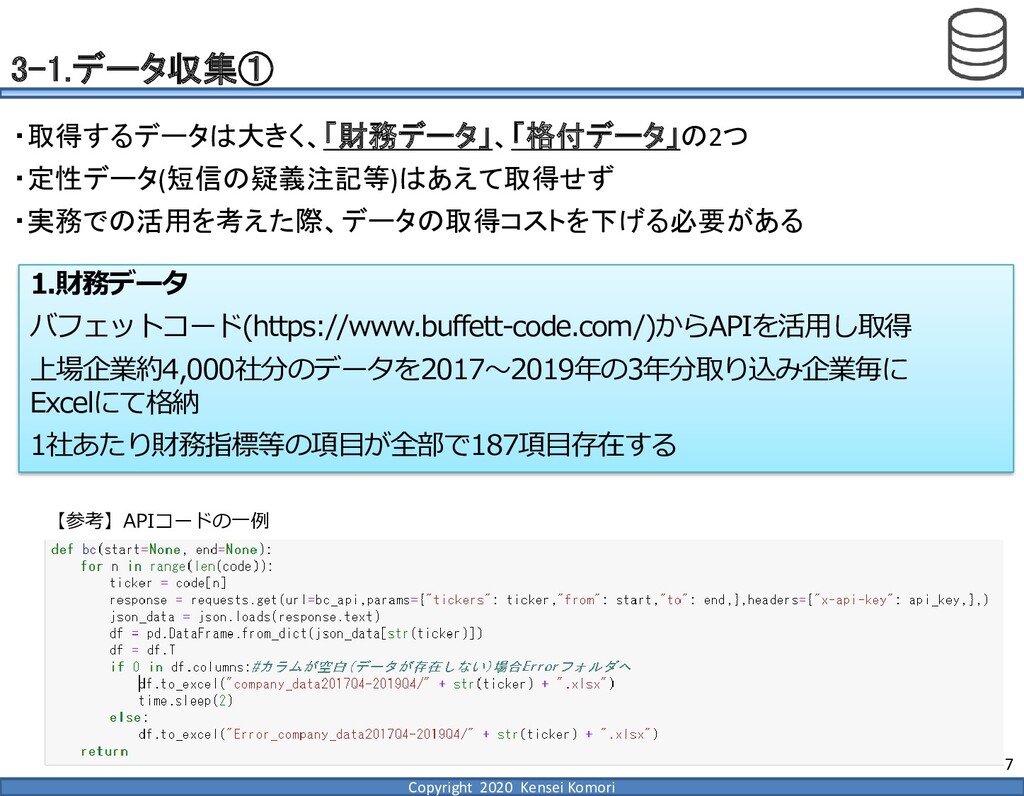
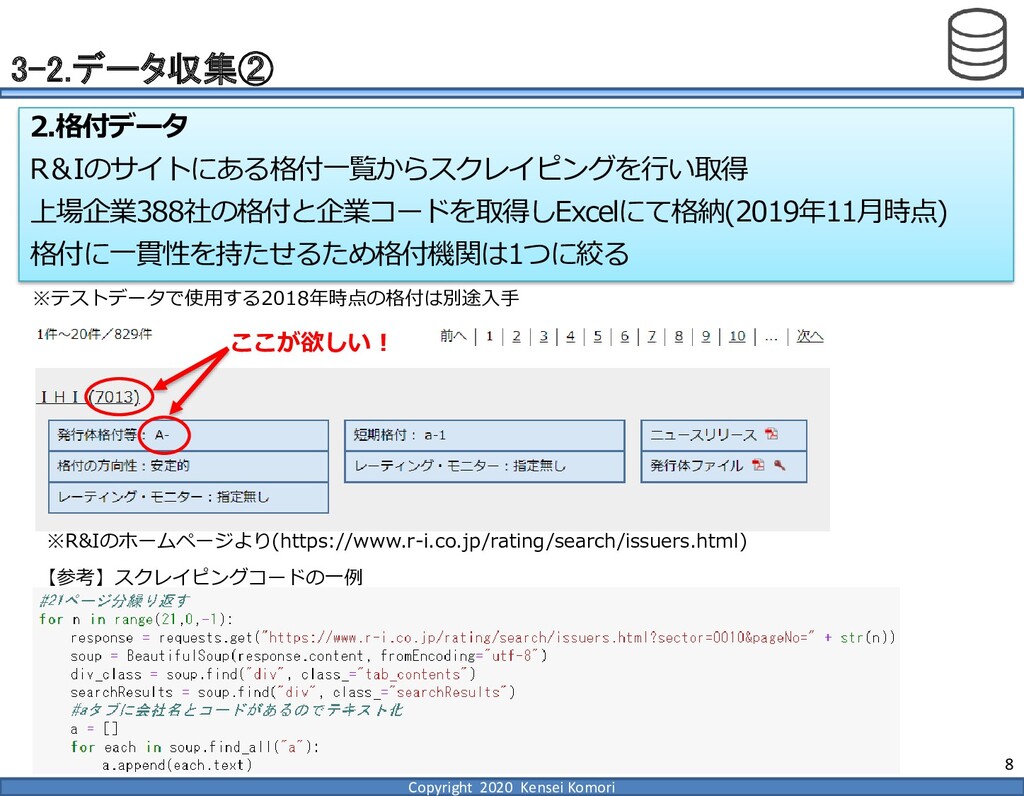
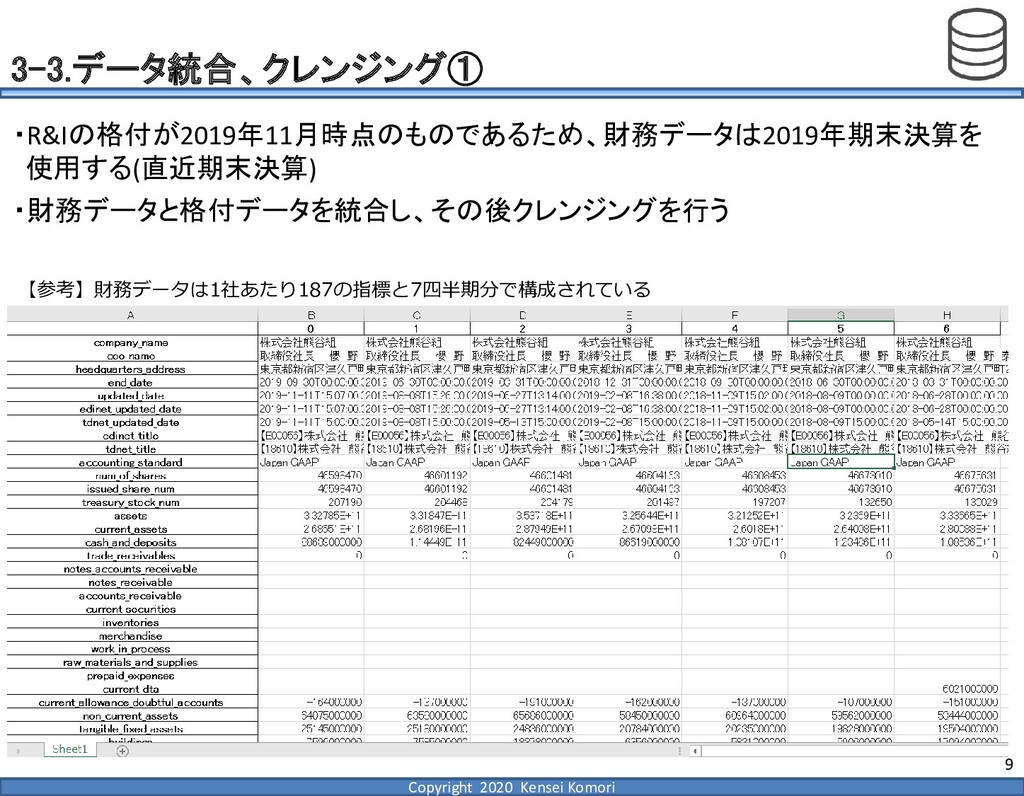
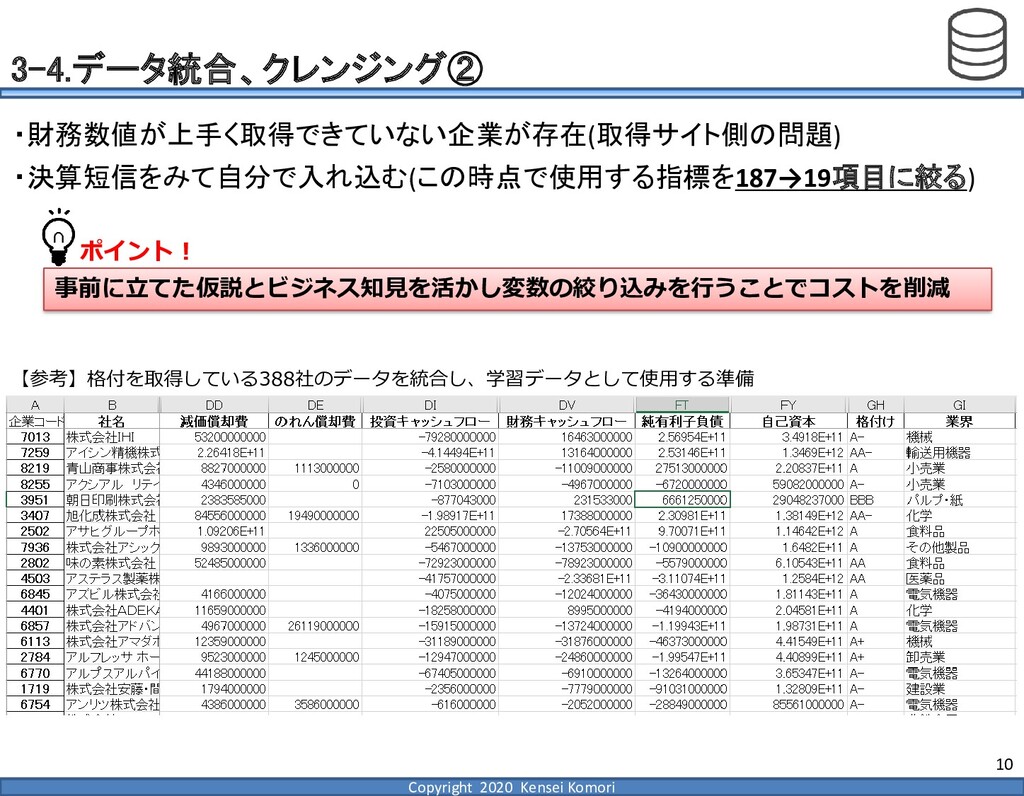
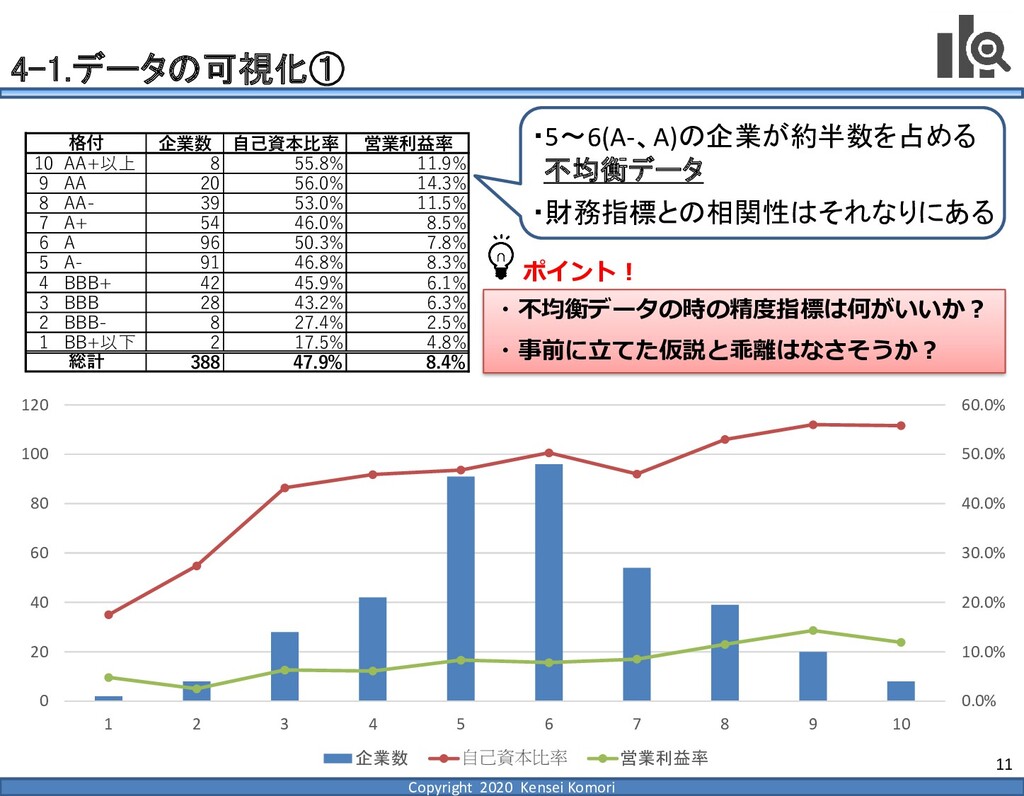
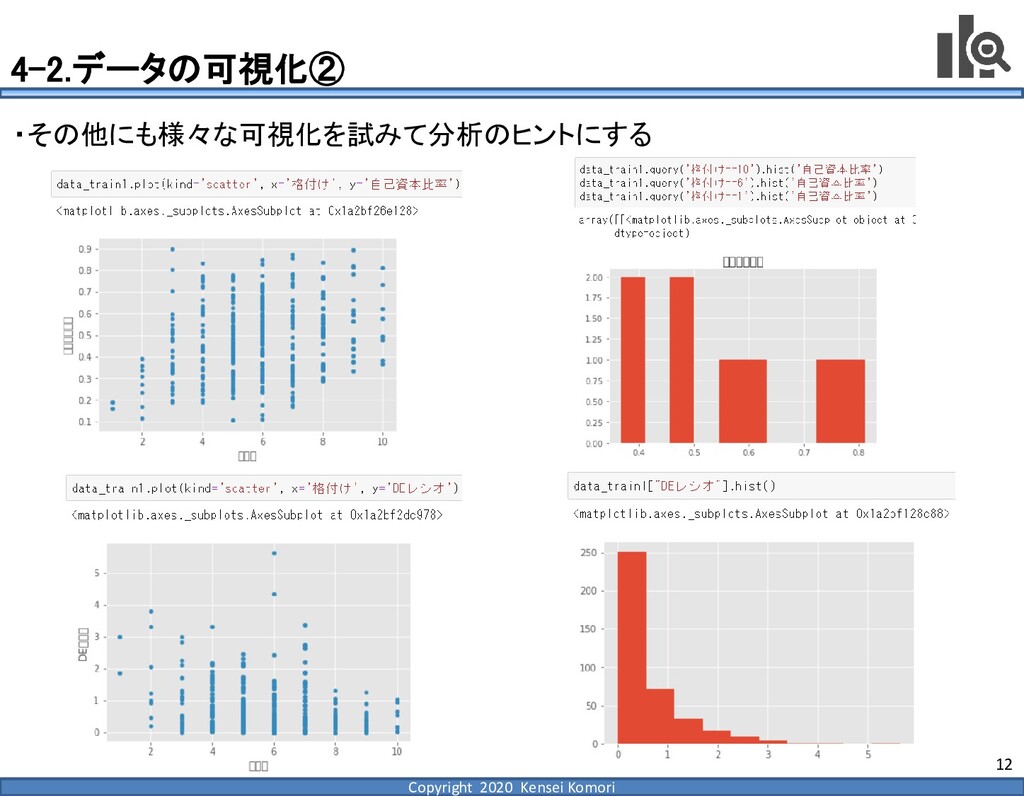
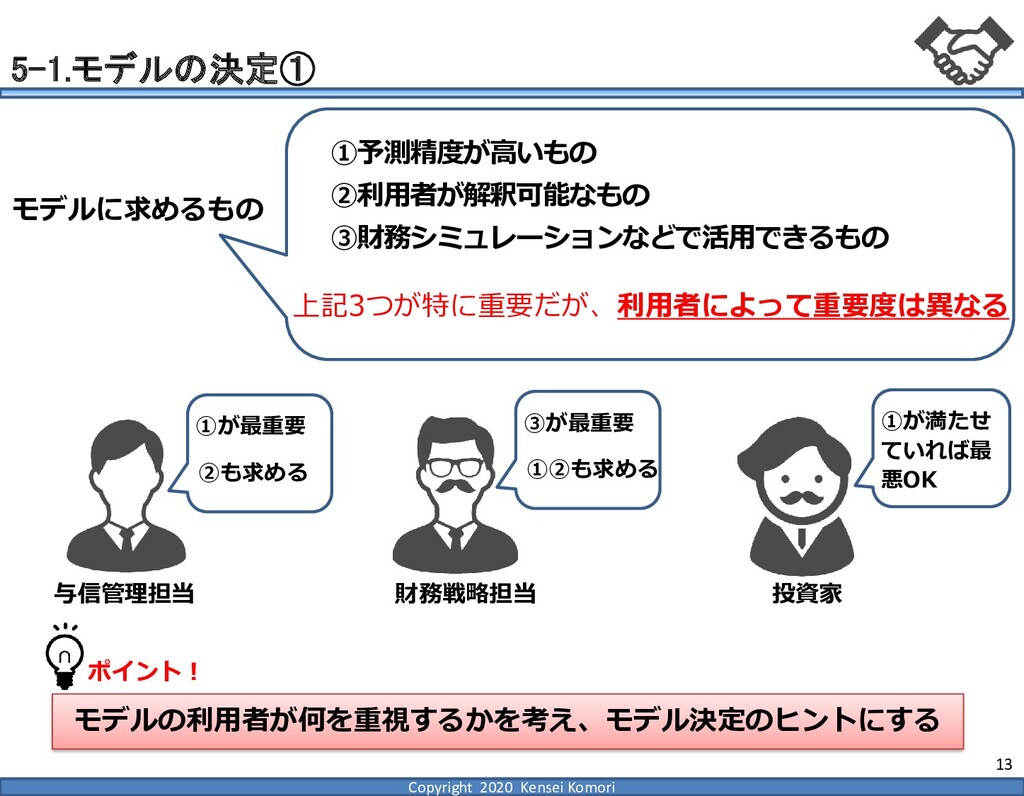
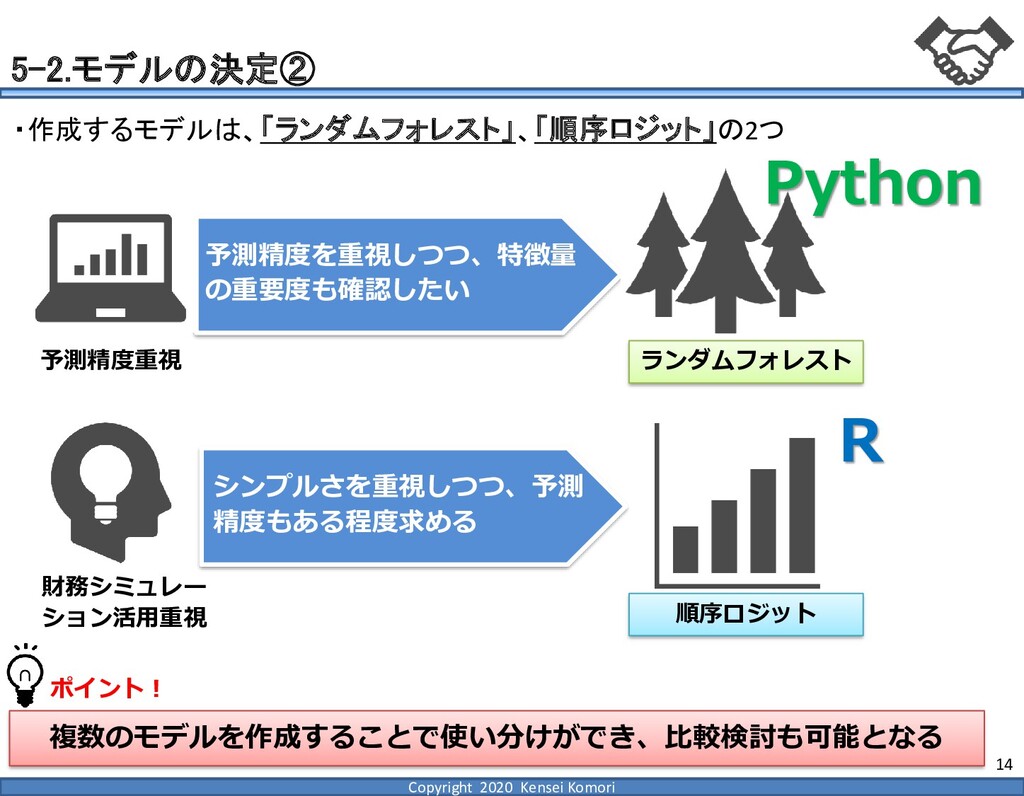
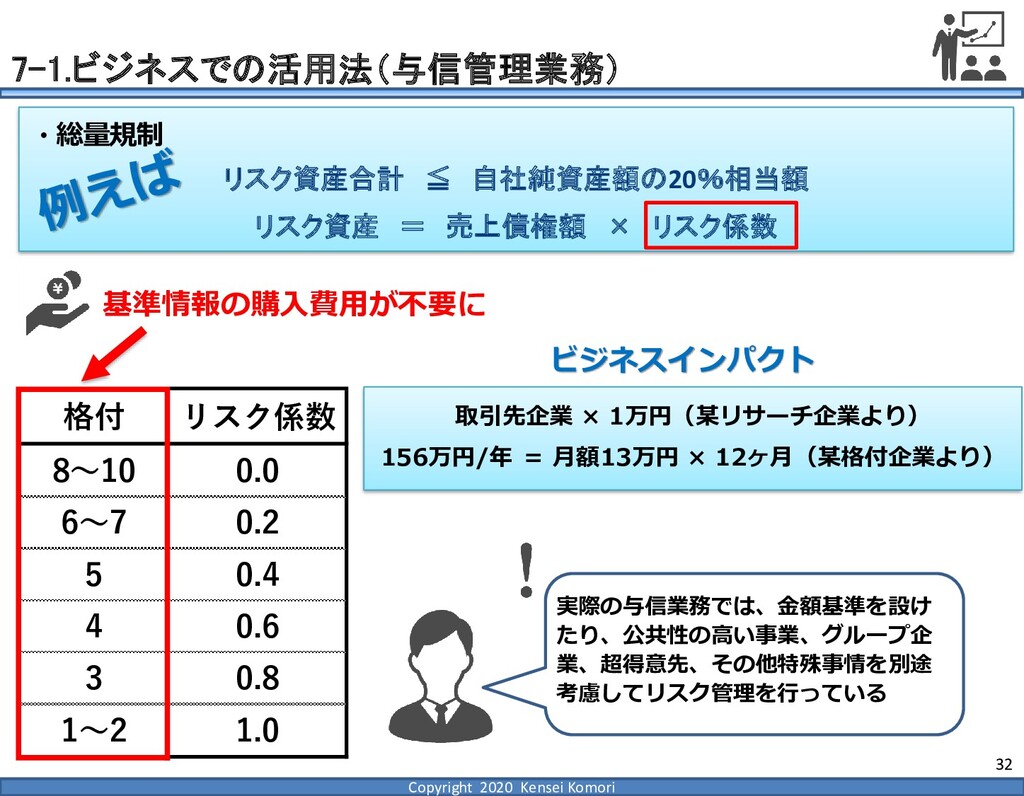
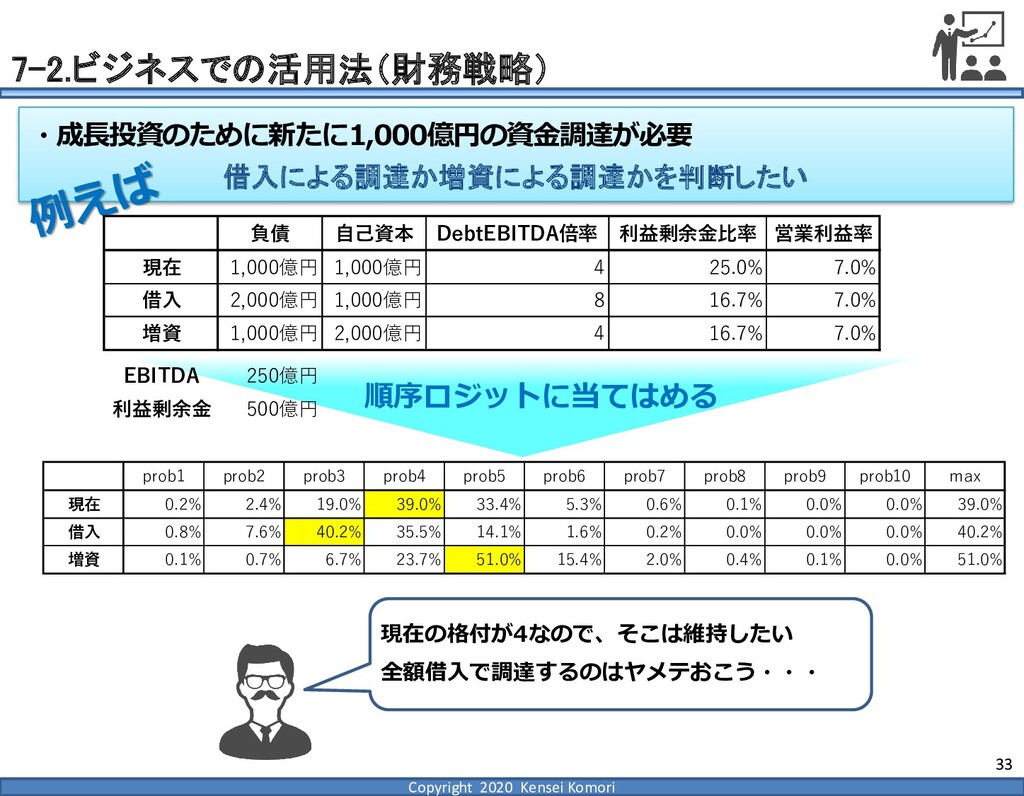
DebtEBITDA倍率 利益剰余金比率 営業利益率 現在 1,000億円 1,000億円 4 25.0% 7.0% 借入 2,000億円 1,000億円 8 16.7% 7.0% 増資 1,000億円 2,000億円 4 16.7% 7.0% EBITDA 250億円 利益剰余金 500億円 順序ロジットに当てはめる prob1 prob2 prob3 prob4 prob5 prob6 prob7 prob8 prob9 prob10 max 現在 0.2% 2.4% 19.0% 39.0% 33.4% 5.3% 0.6% 0.1% 0.0% 0.0% 39.0% 借入 0.8% 7.6% 40.2% 35.5% 14.1% 1.6% 0.2% 0.0% 0.0% 0.0% 40.2% 増資 0.1% 0.7% 6.7% 23.7% 51.0% 15.4% 2.0% 0.4% 0.1% 0.0% 51.0% 現在の格付が4なので、そこは維持したい 全額借入で調達するのはヤメテおこう・・・
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
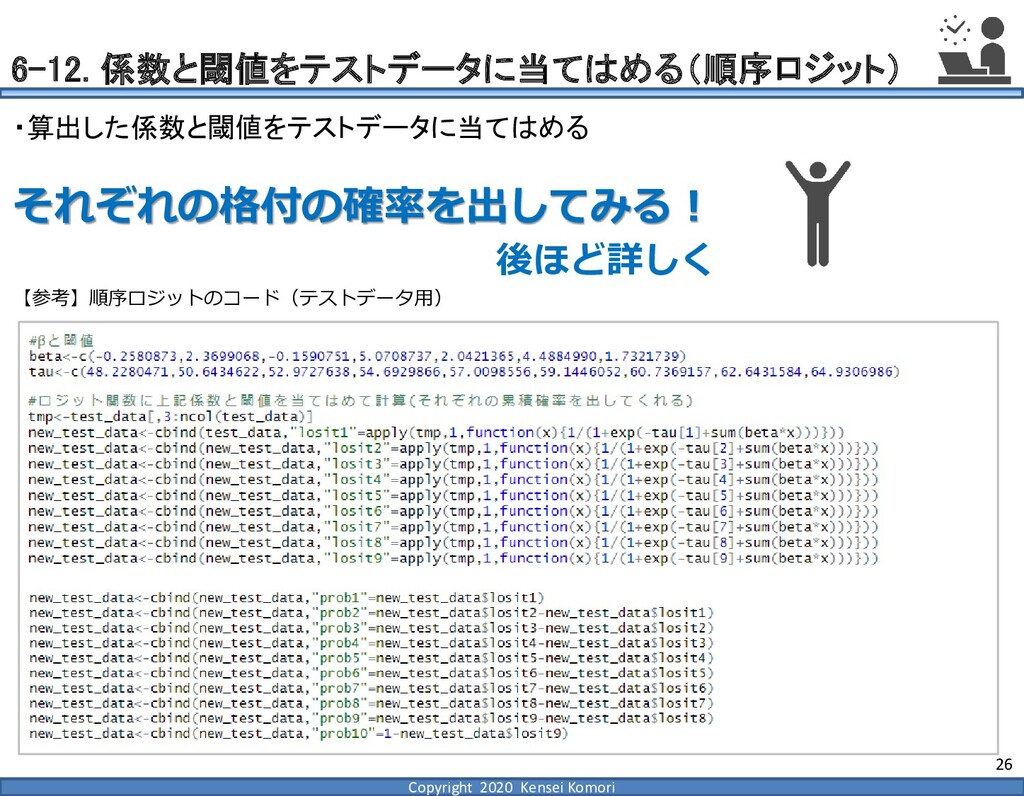{kind=link}
{kind=link}
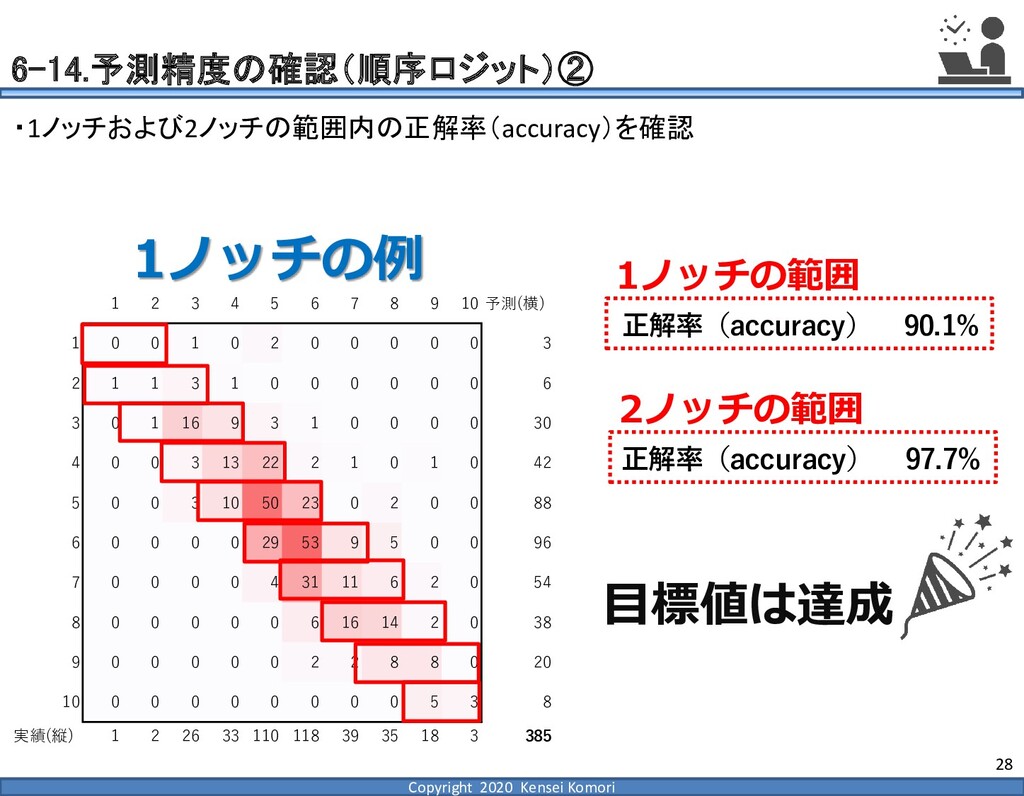{kind=link}
{kind=link}
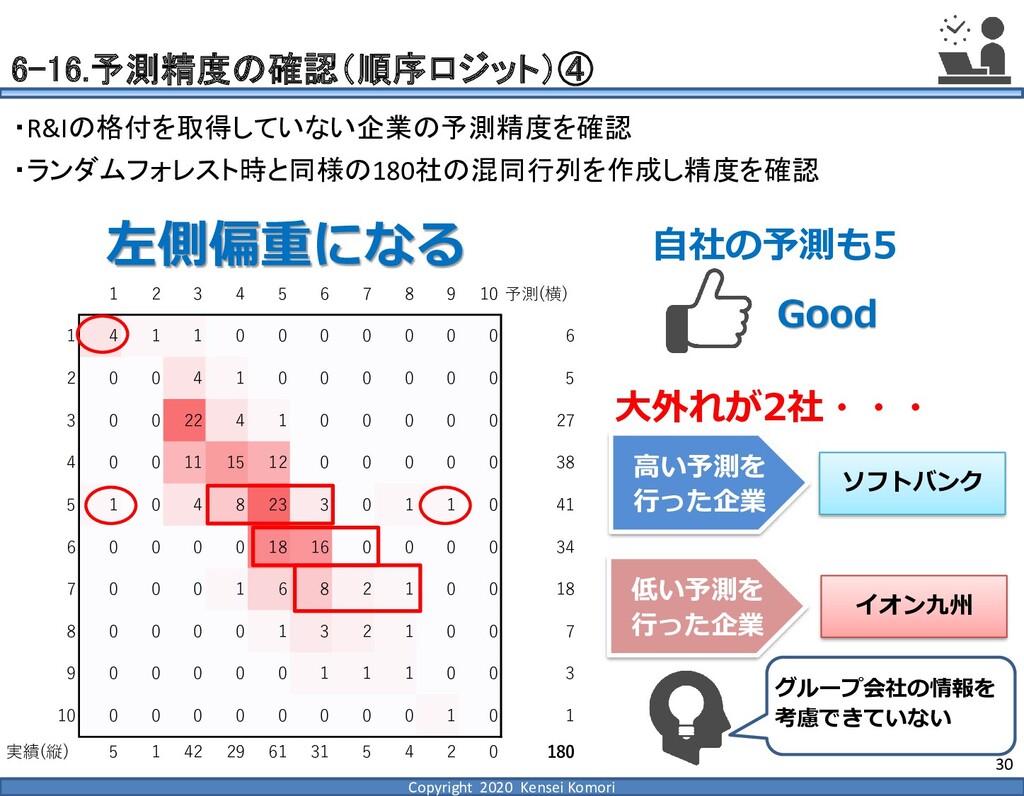{kind=link}
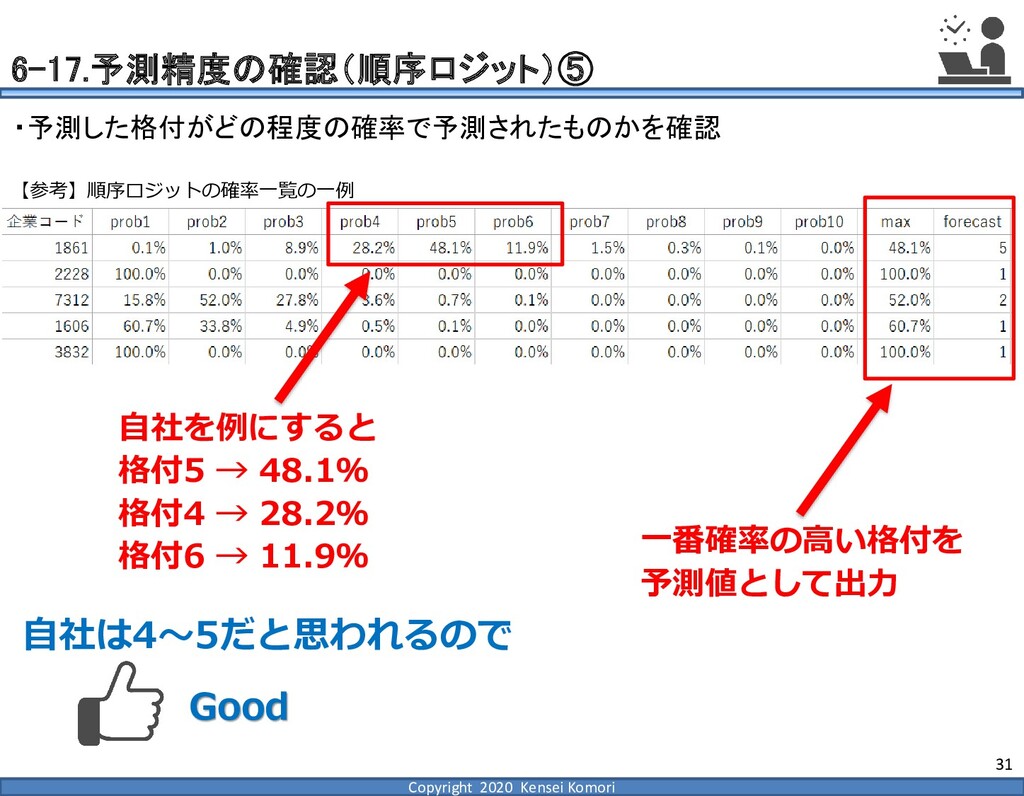{kind=link}
{kind=link}
{kind=link}
{kind=link}