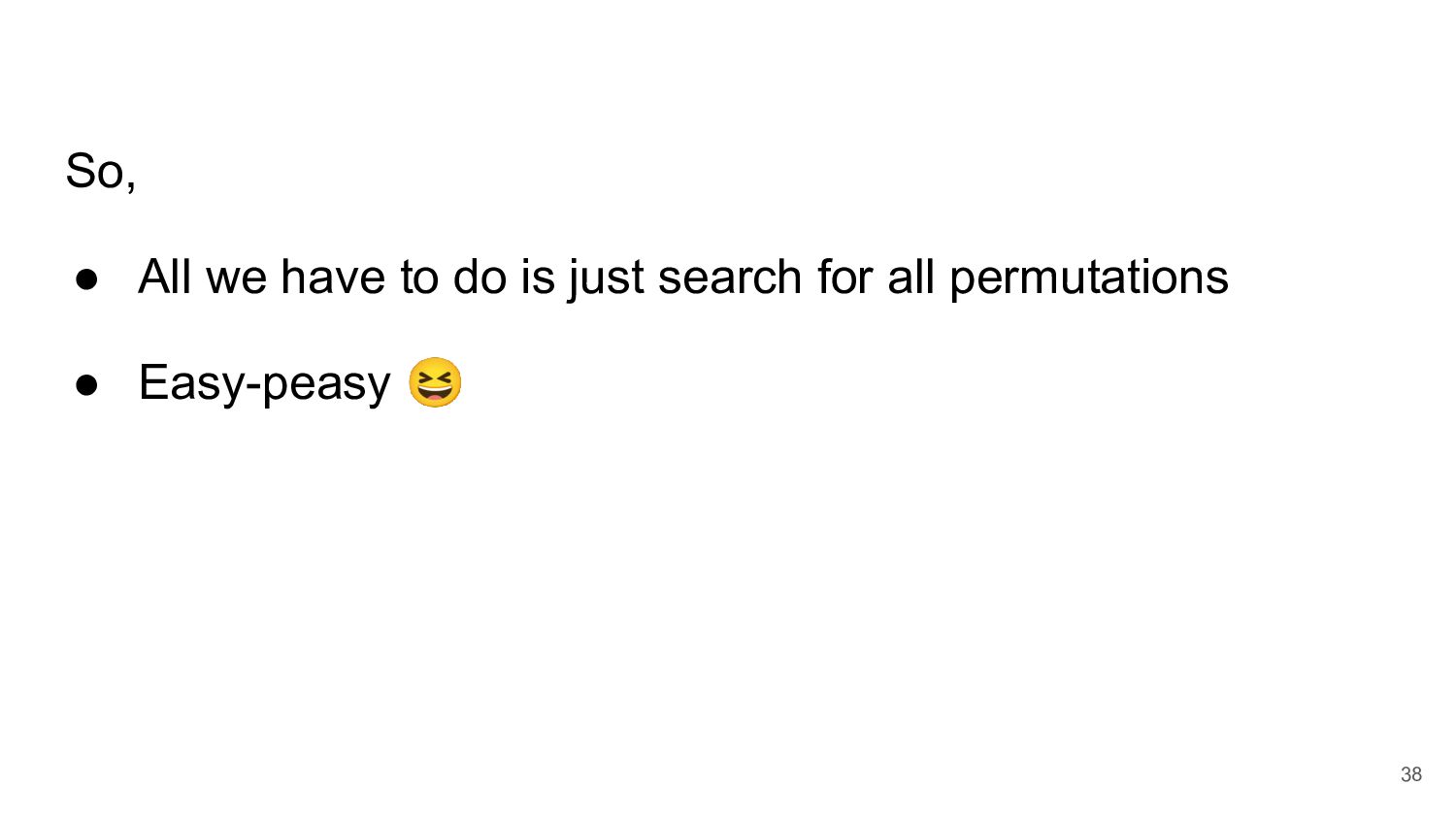
= 2 x = 1 P = 1 P = 1 x = 1 P = 1 a = 1 x = 1 y = 2 z = 3 x = 1 y = 2 P = 1 x = 1 P = 1 y = 2 x = 1 P = 1 a = 1 P = 1 x = 1 y = 2 P = 1 x = 1 a = 1 P = 1 a = 1 x = 1 P = 1 a = 1 b = 2 41
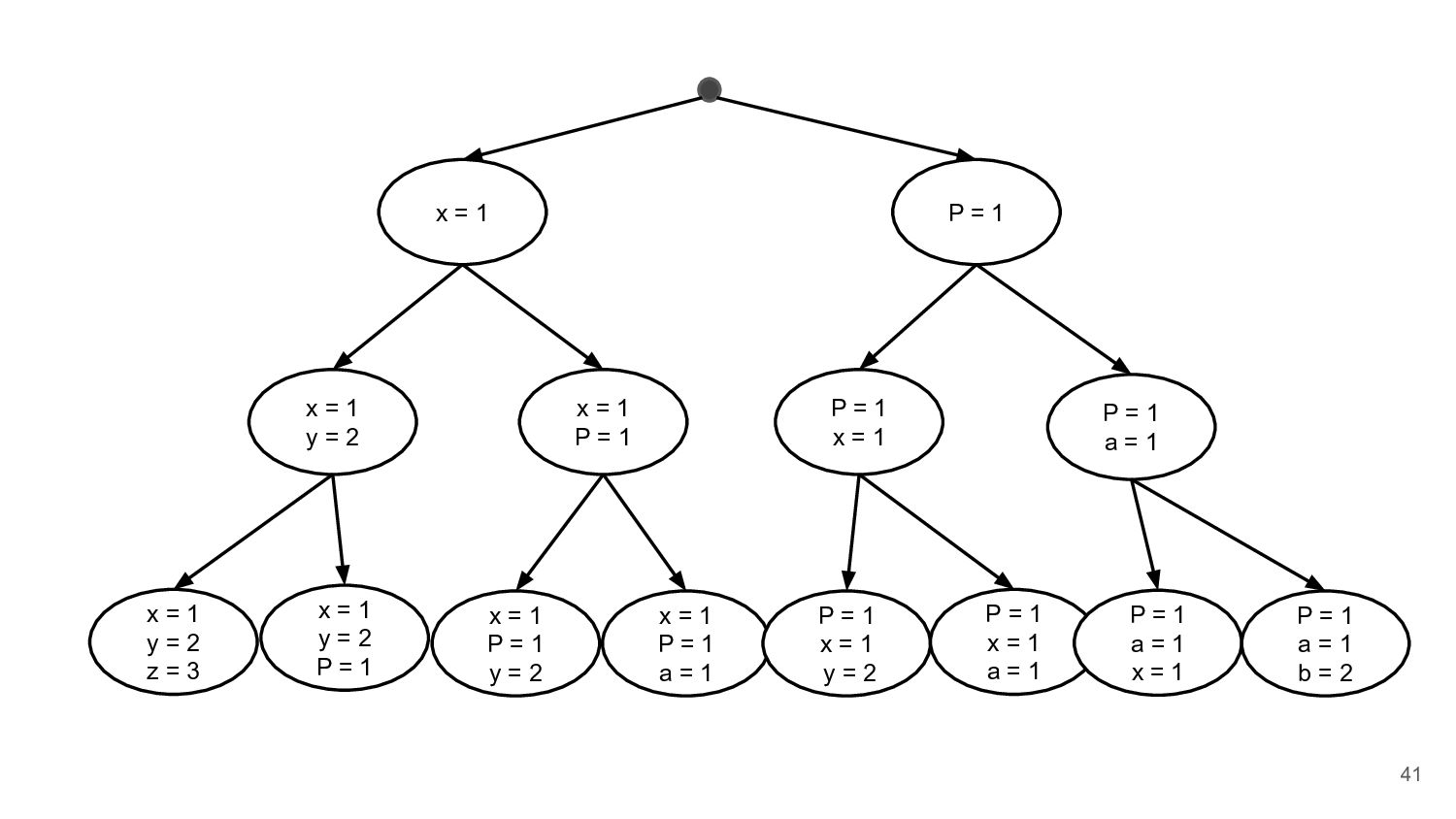
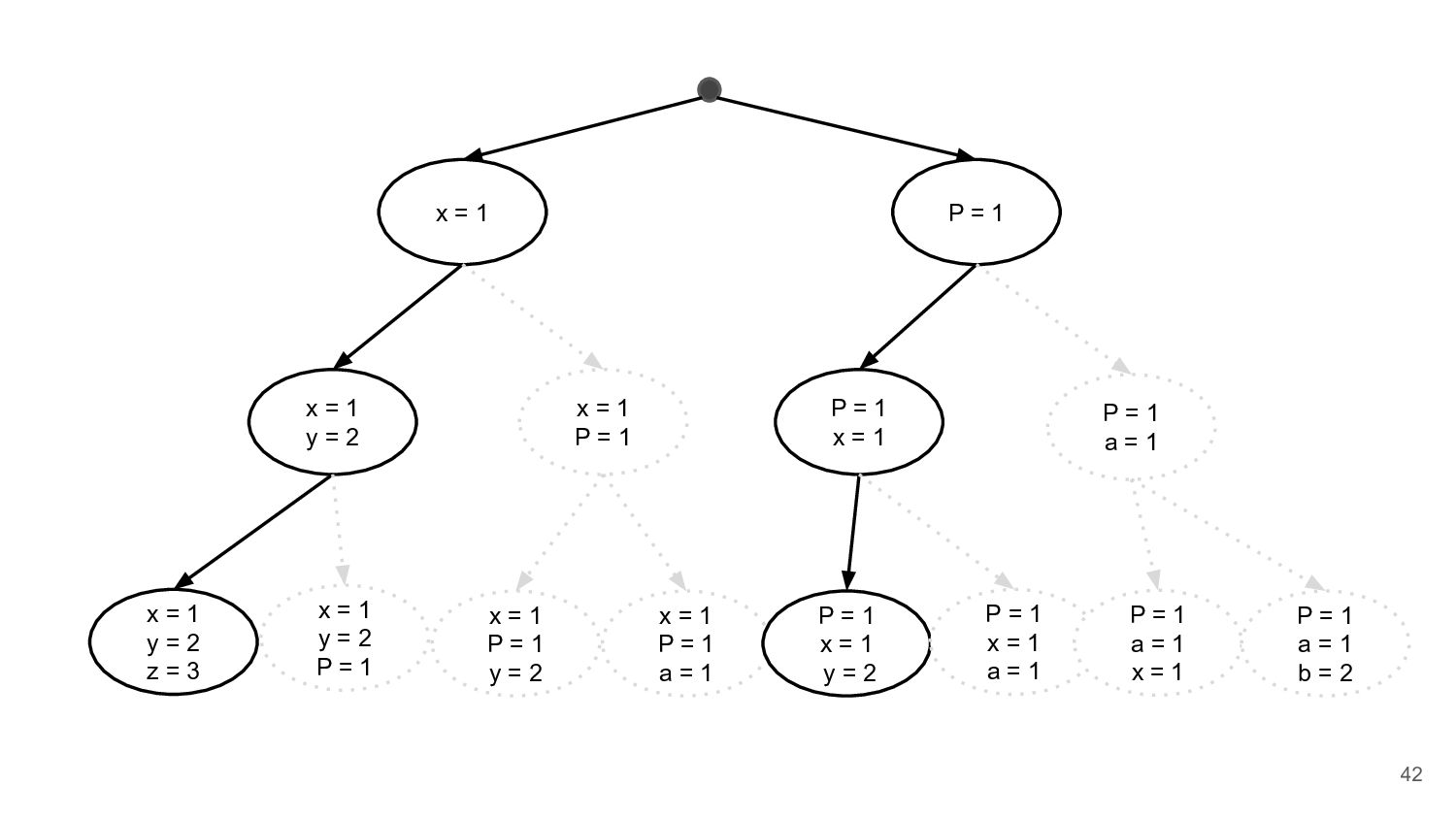
= 2 x = 1 P = 1 P = 1 x = 1 P = 1 a = 1 x = 1 y = 2 z = 3 x = 1 y = 2 P = 1 x = 1 P = 1 y = 2 x = 1 P = 1 a = 1 P = 1 x = 1 y = 2 P = 1 x = 1 a = 1 P = 1 a = 1 x = 1 P = 1 a = 1 b = 2 42
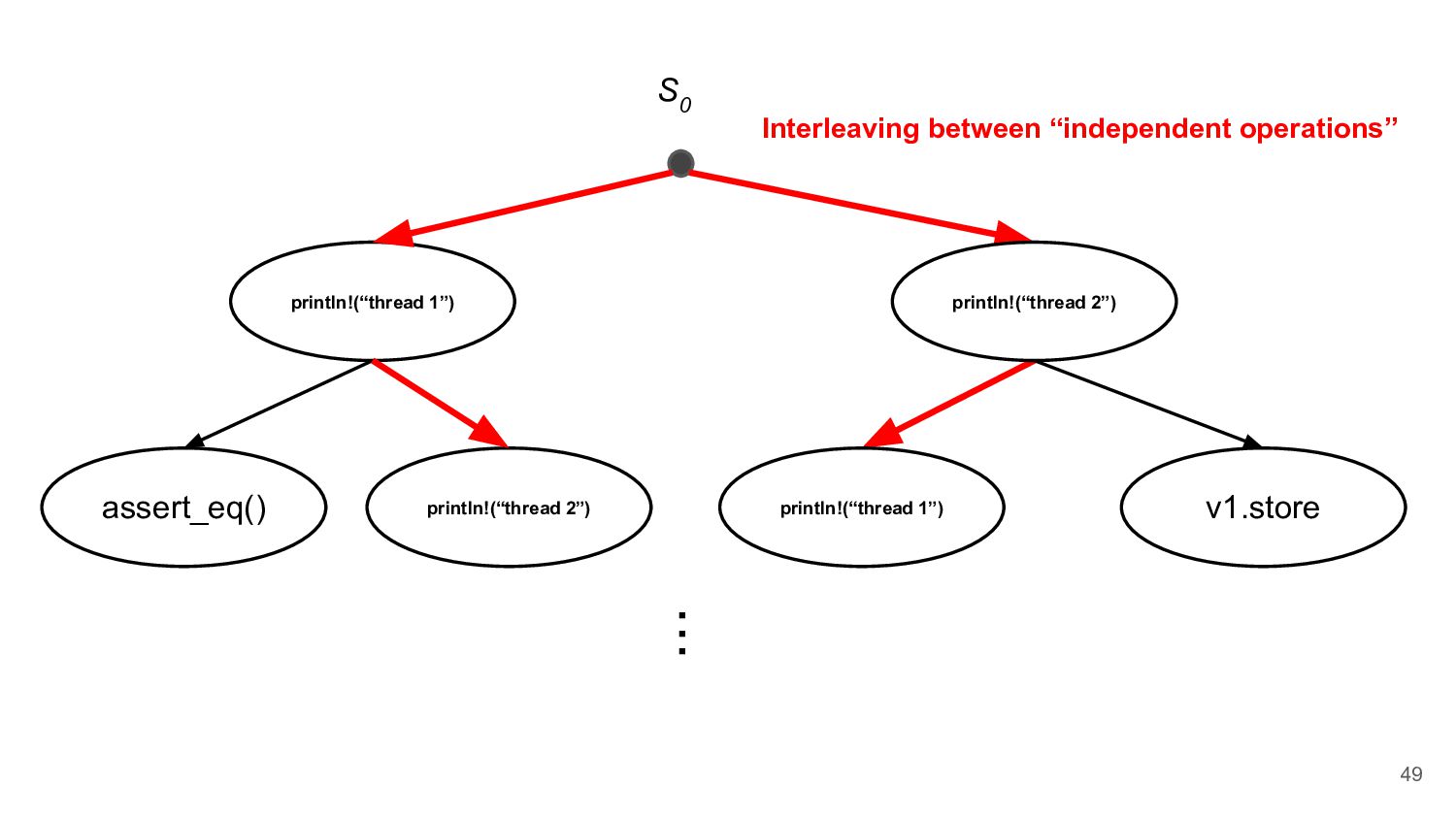
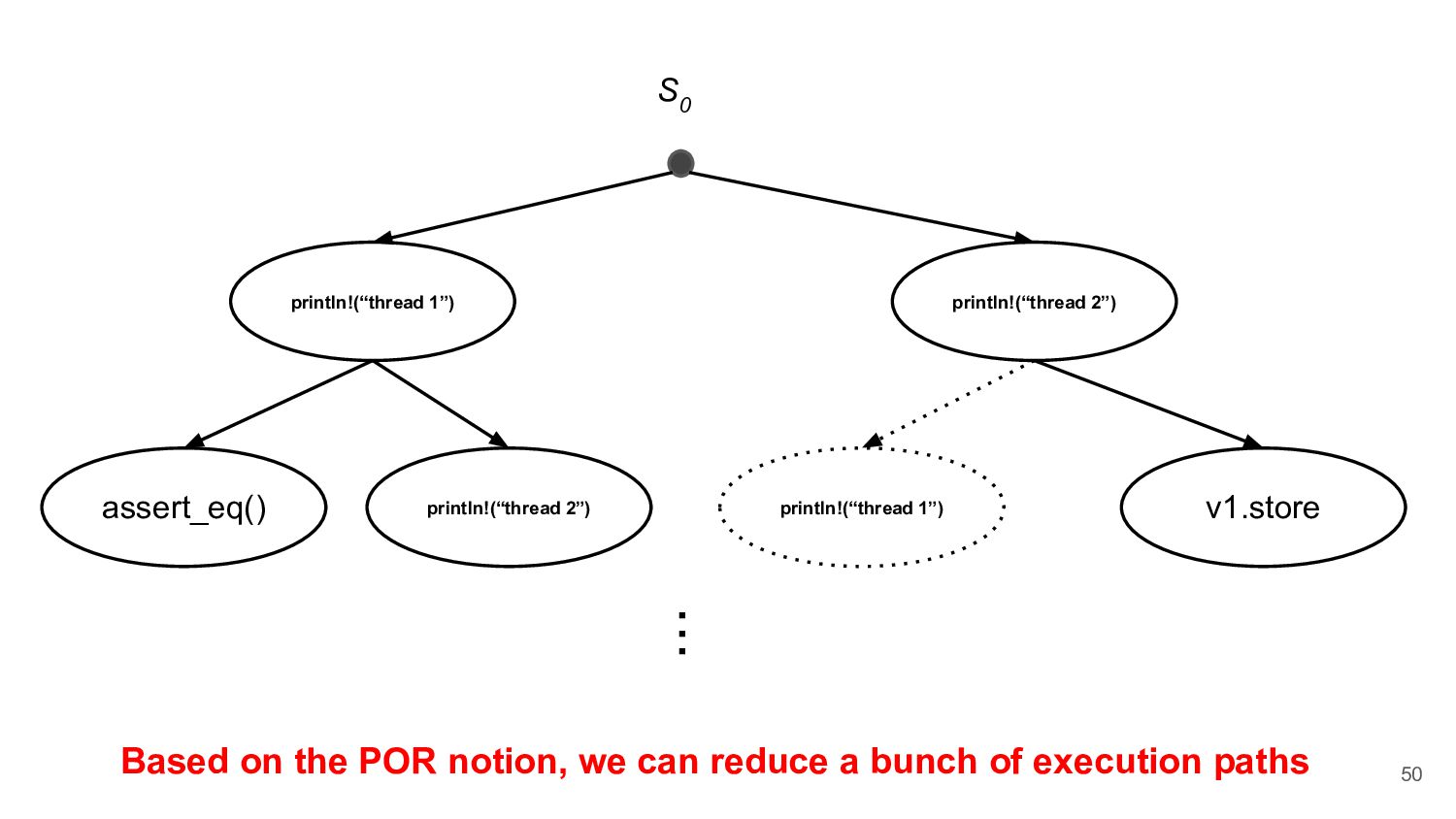
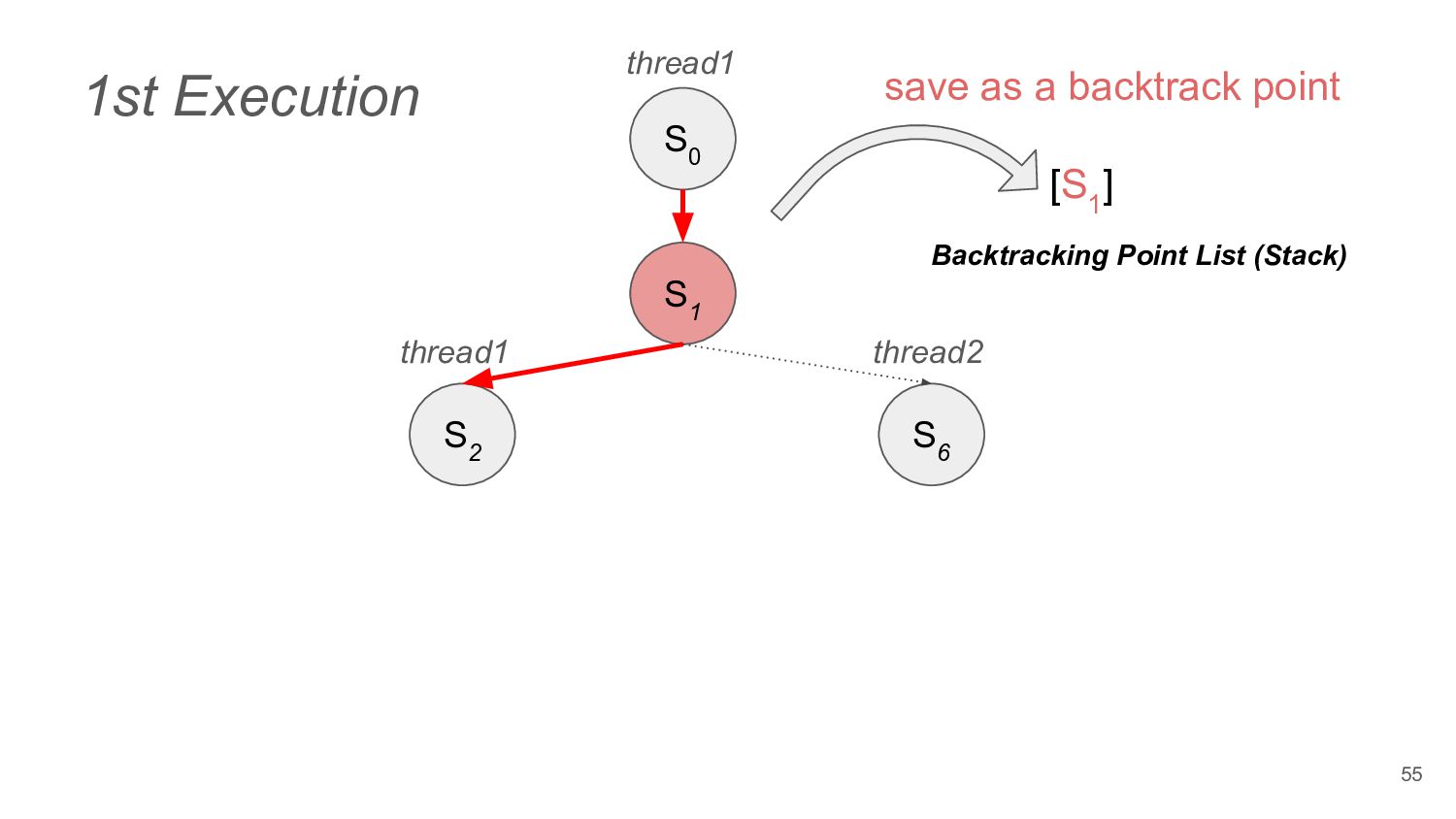
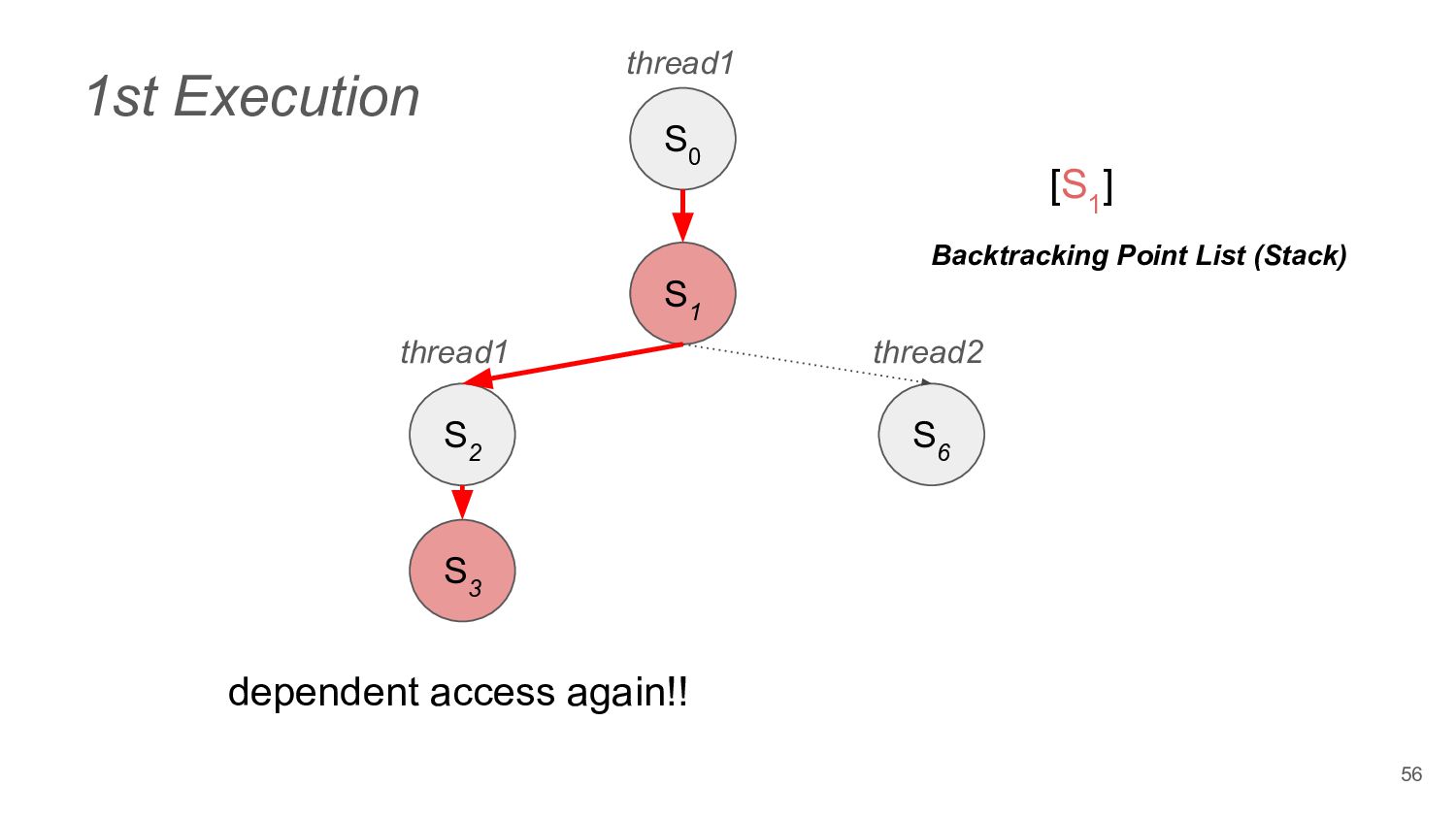
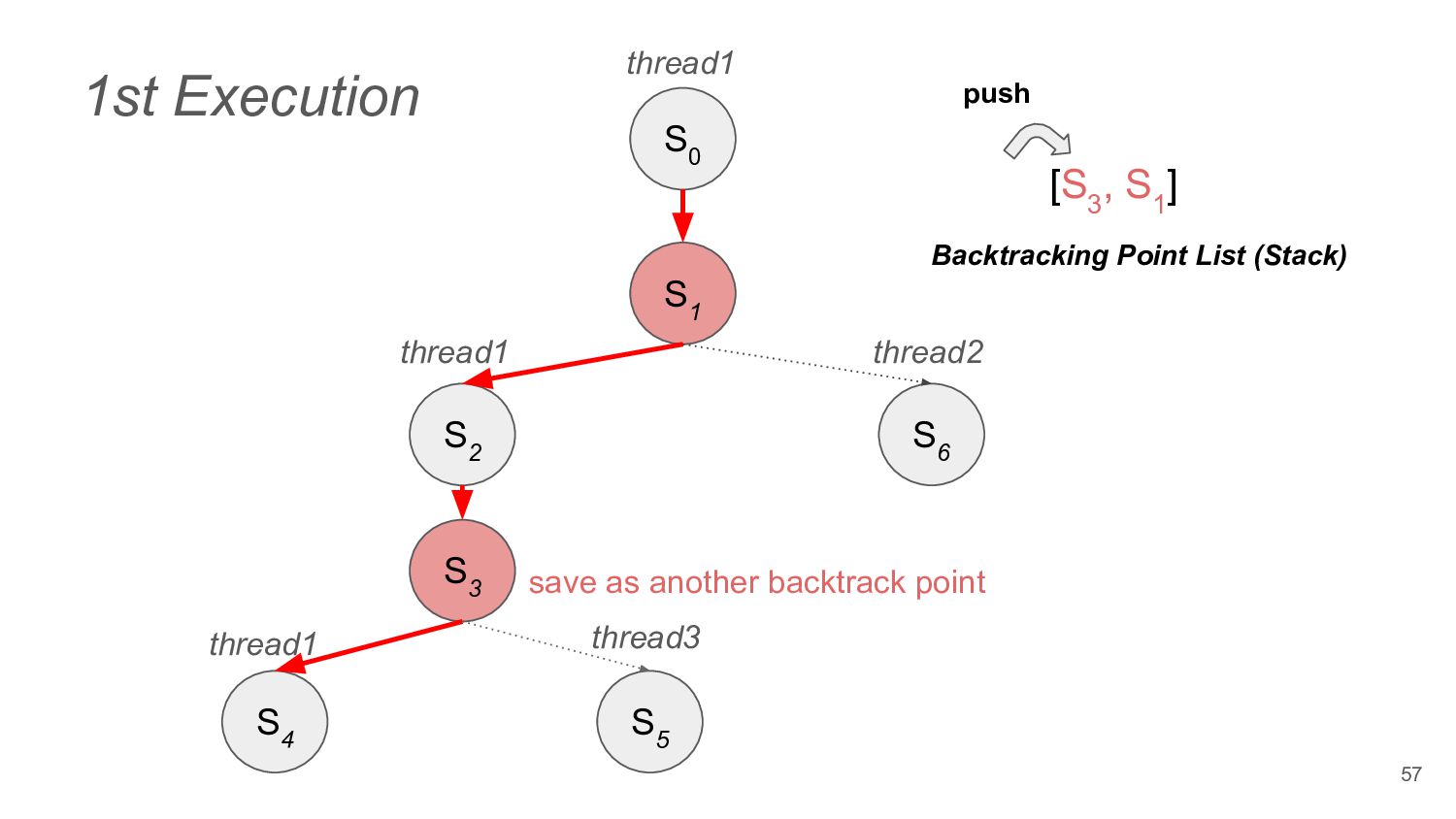
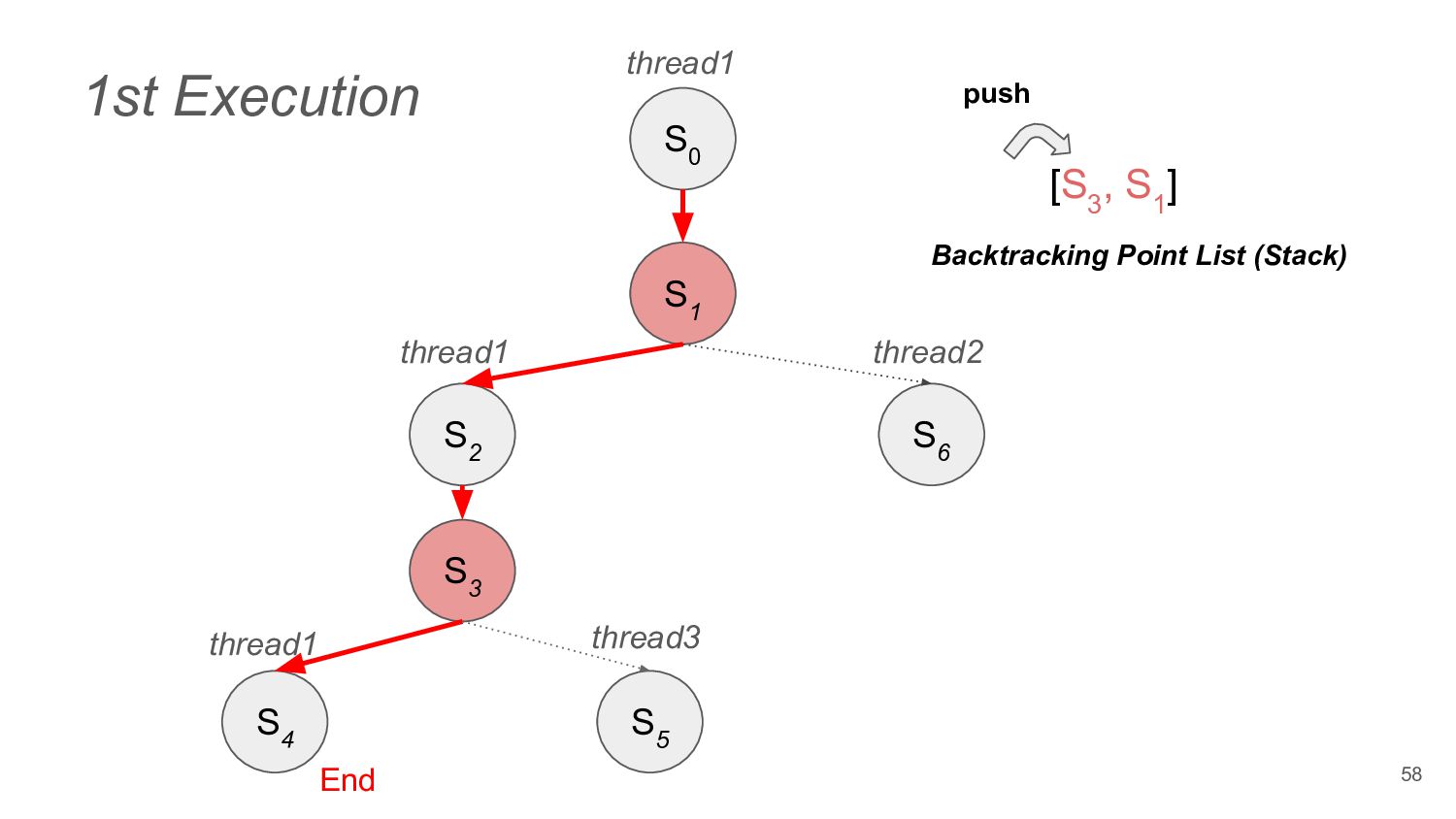
does not change the final state of the program, they are independent ◦ e.g. read from the thread local variables • Dependent Operation ◦ e.g. acquire a lock from the Mutex 44
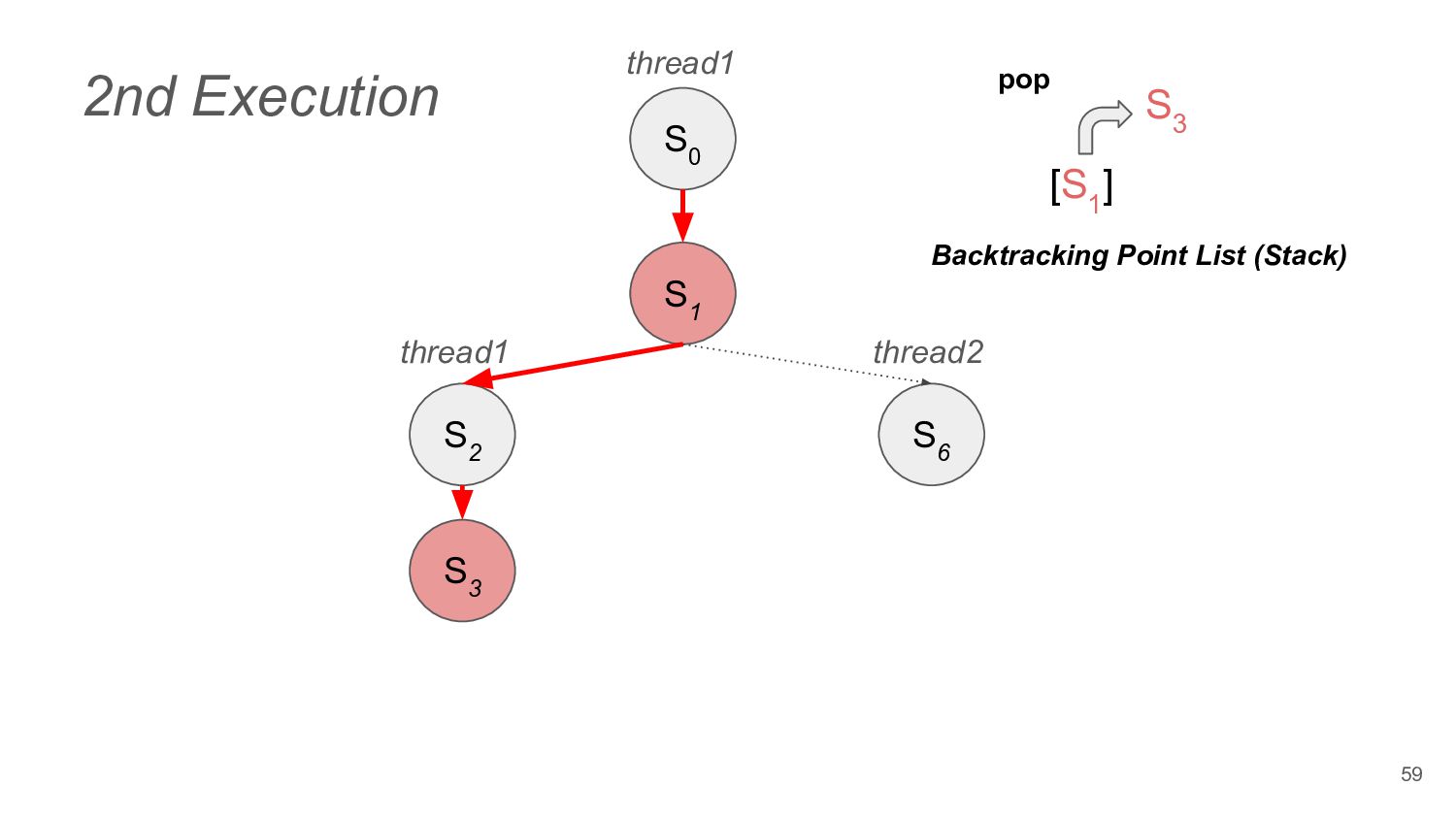
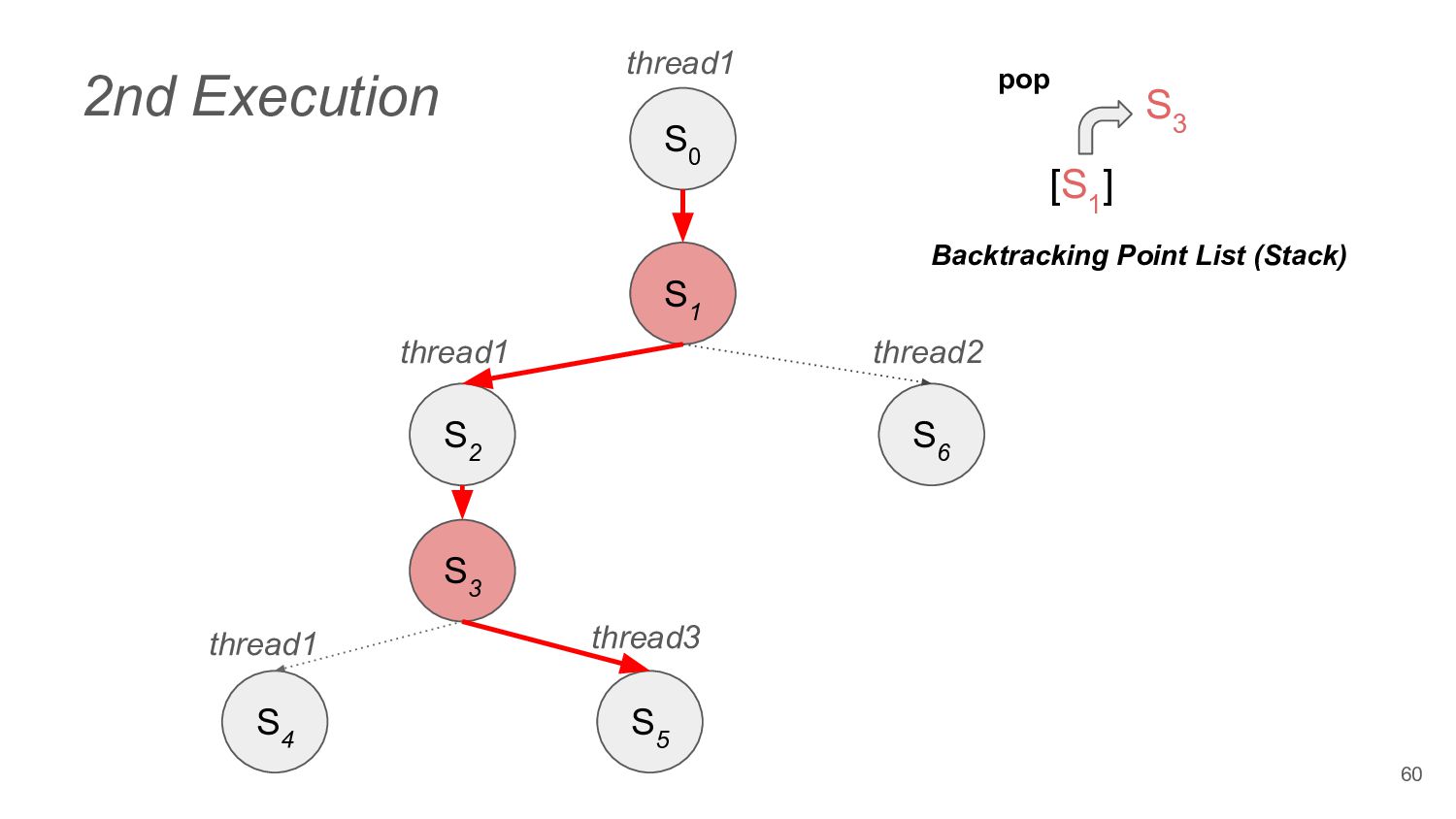
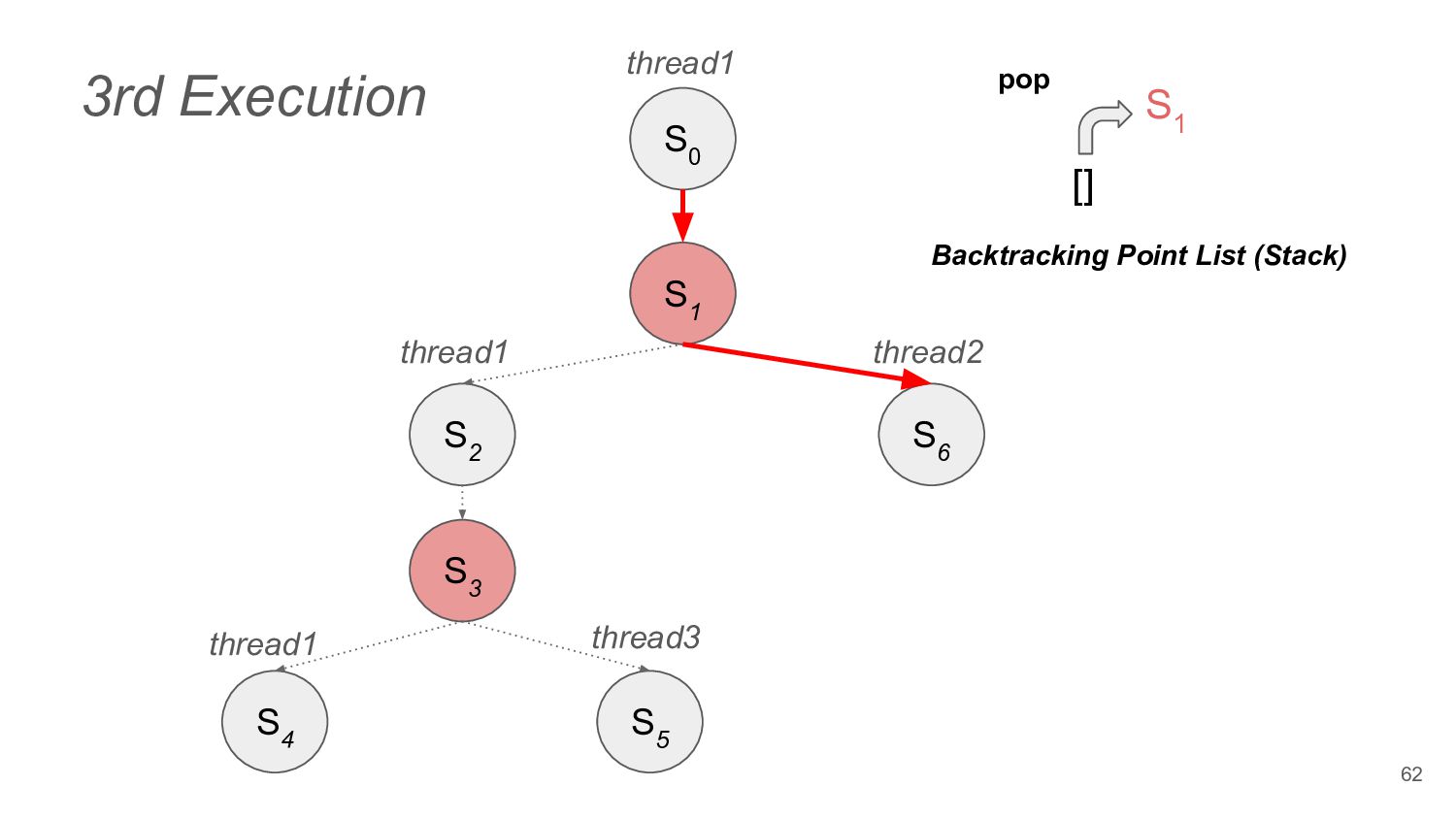
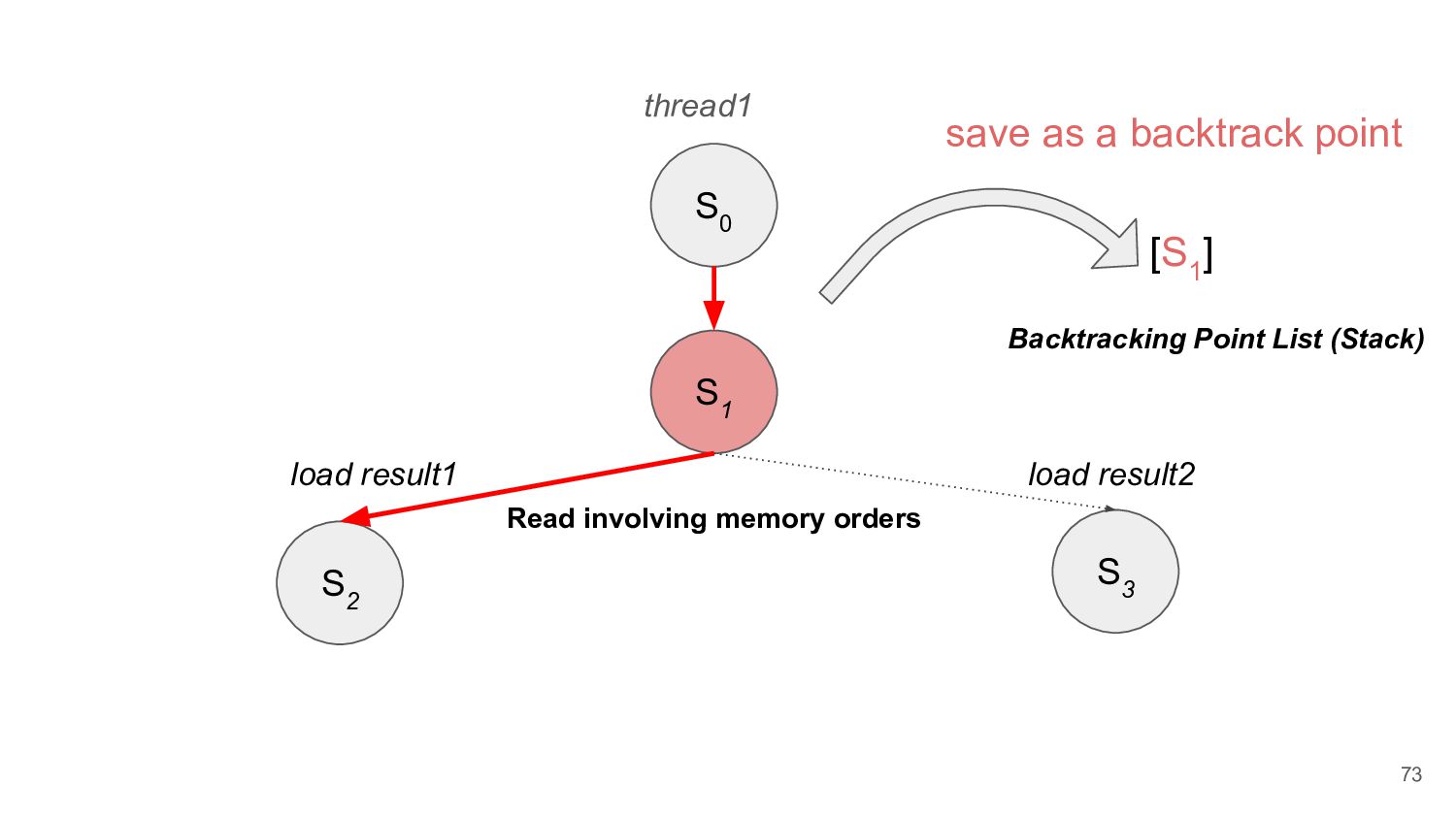
to read operation • In addition to DPOR's thread execution backtrack points, load result selection based on memory models is also added to the backtracking points 74
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![23 #[test] fn test_buggy_concurrent_logic() { let v1 = Arc::new(AtomicUsize::new(0)); let](https://files.speakerdeck.com/presentations/1bb71a5e06574ab7bcd16a4568567dfe/slide_22.jpg){kind=link}
![24 #[test] fn test_concurrent_logic_loom() { loom::model(|| { let v1 =](https://files.speakerdeck.com/presentations/1bb71a5e06574ab7bcd16a4568567dfe/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![S 0 S 1 thread1 3rd Execution [S 1 ]](https://files.speakerdeck.com/presentations/1bb71a5e06574ab7bcd16a4568567dfe/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![S 0 S 1 thread1 Backtracking Point List (Stack) []](https://files.speakerdeck.com/presentations/1bb71a5e06574ab7bcd16a4568567dfe/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}