Share
2025年5月2日に行われた進化計算×ニューラルネットワーク論文読み会(https://abeja-innovation-meetup.connpass.com/event/352604/)の発表資料です
{kind=link}
{kind=link}
{kind=link}
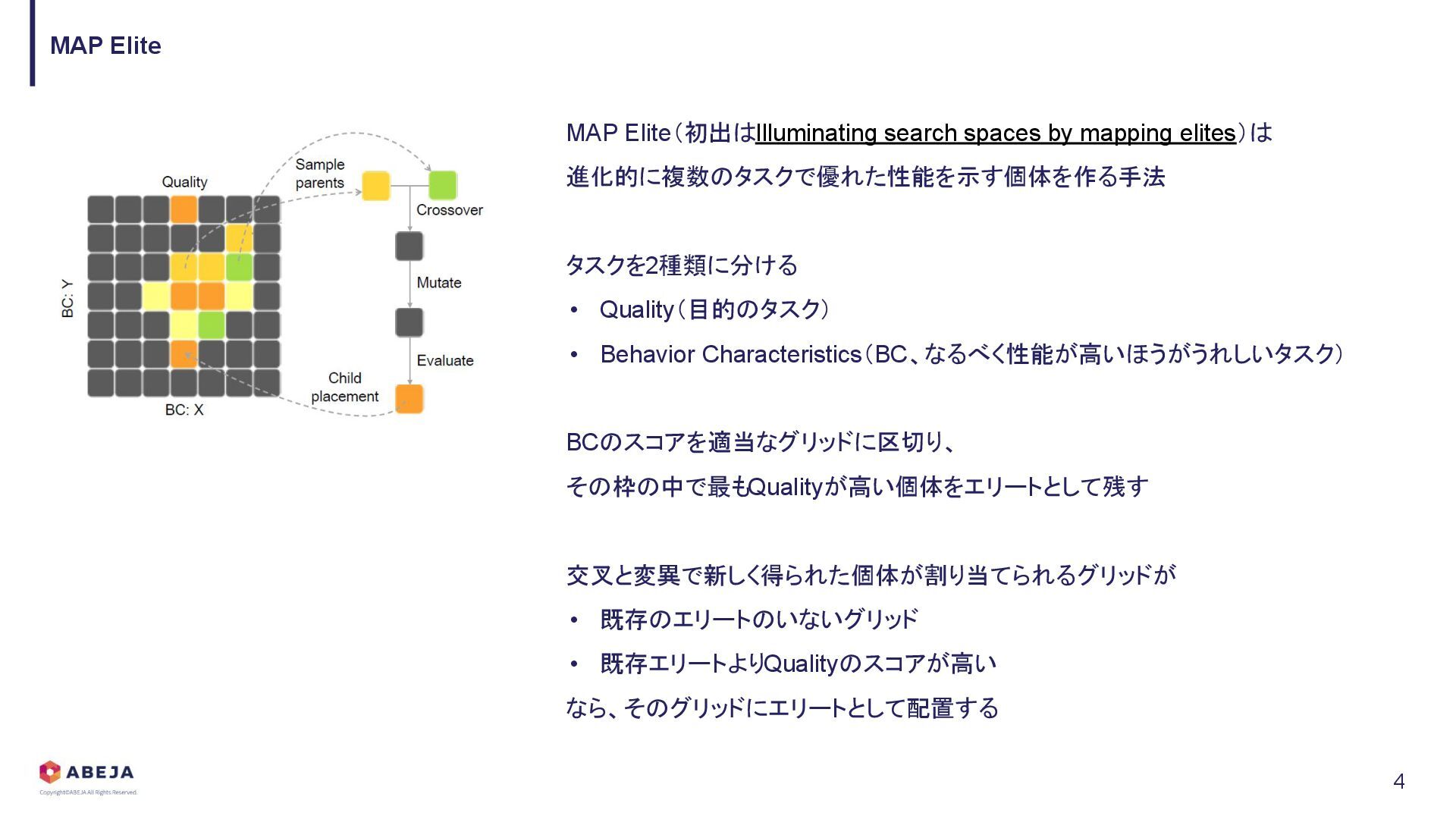{kind=link}
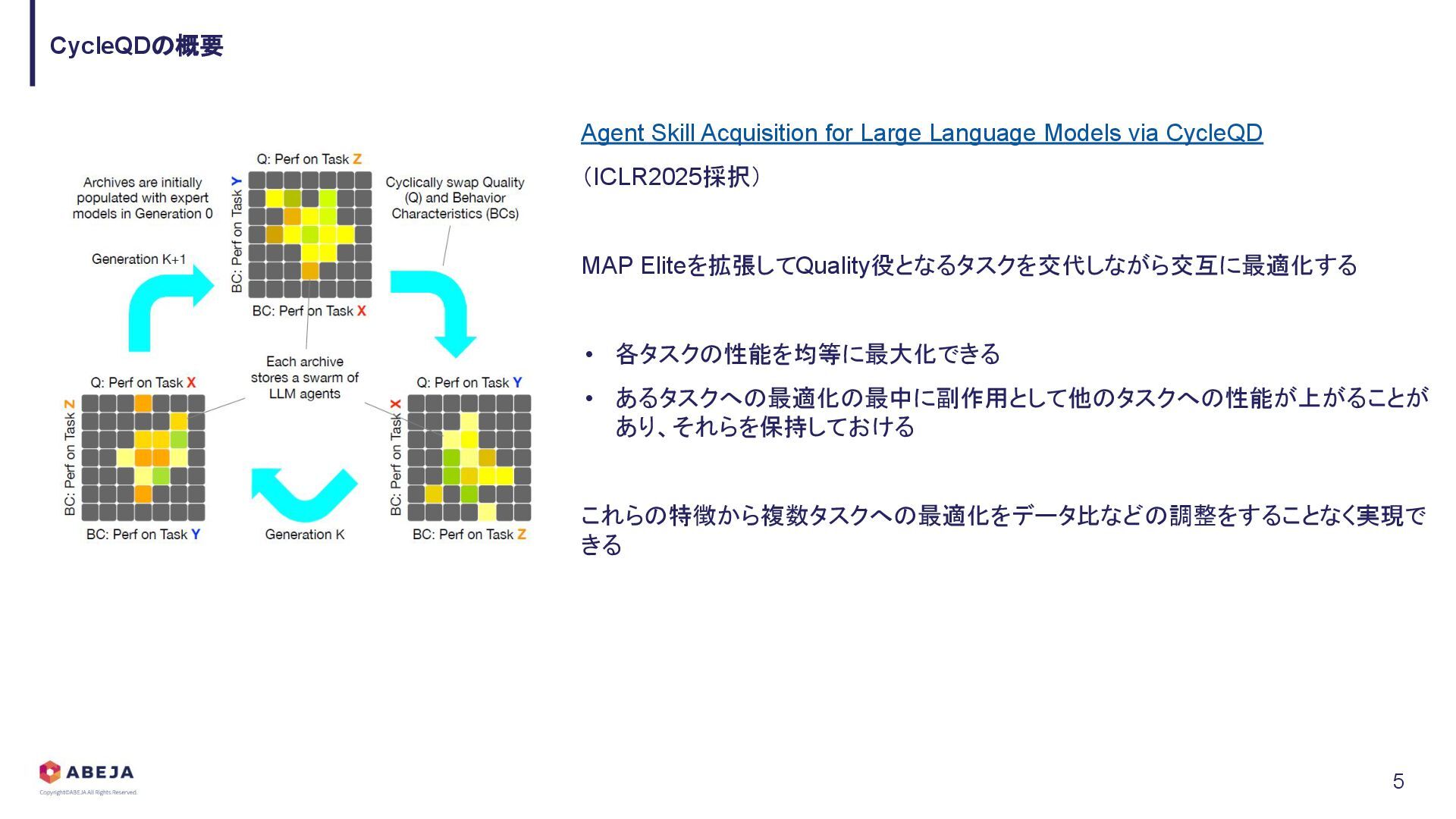{kind=link}
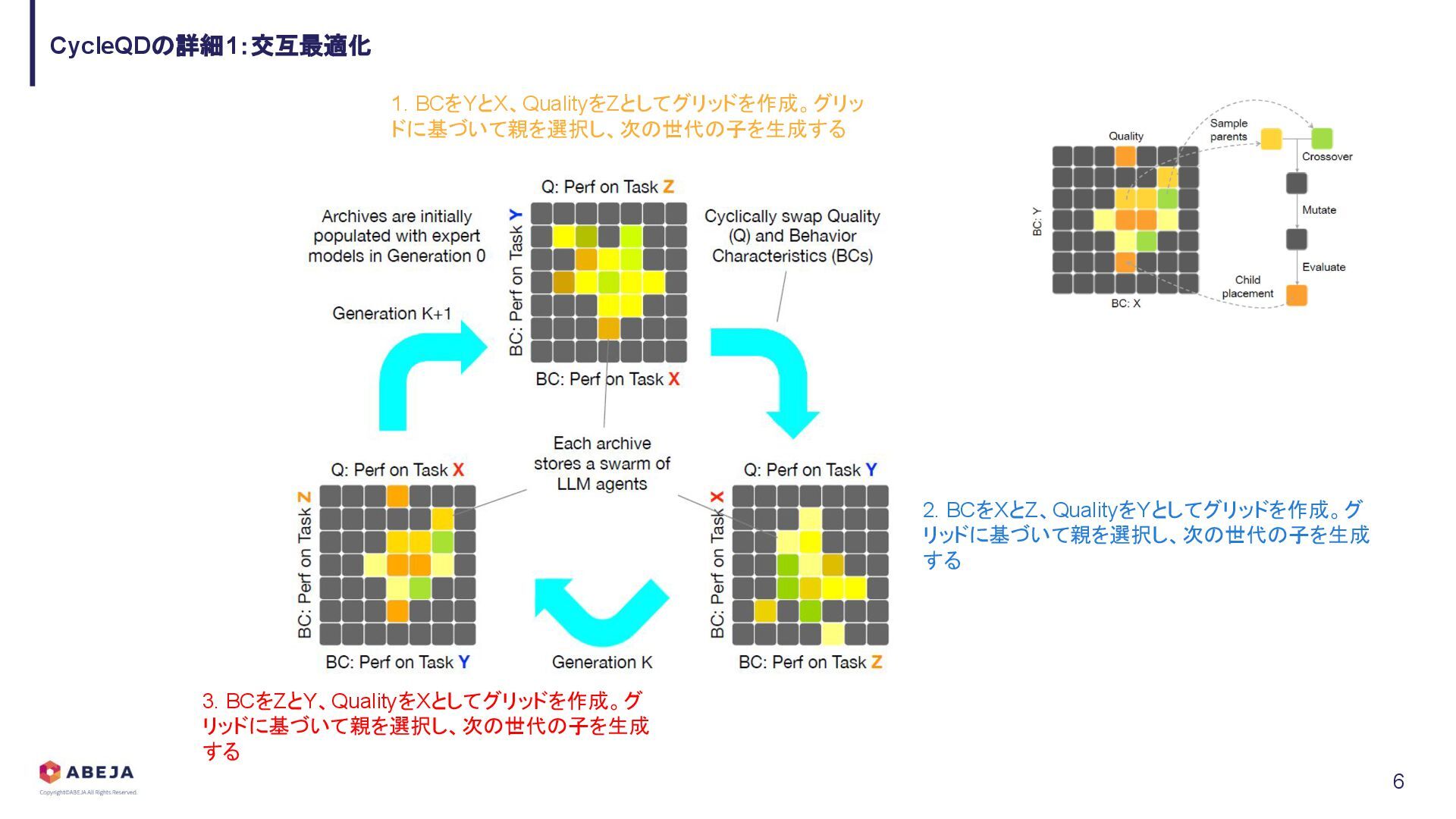{kind=link}
{kind=link}
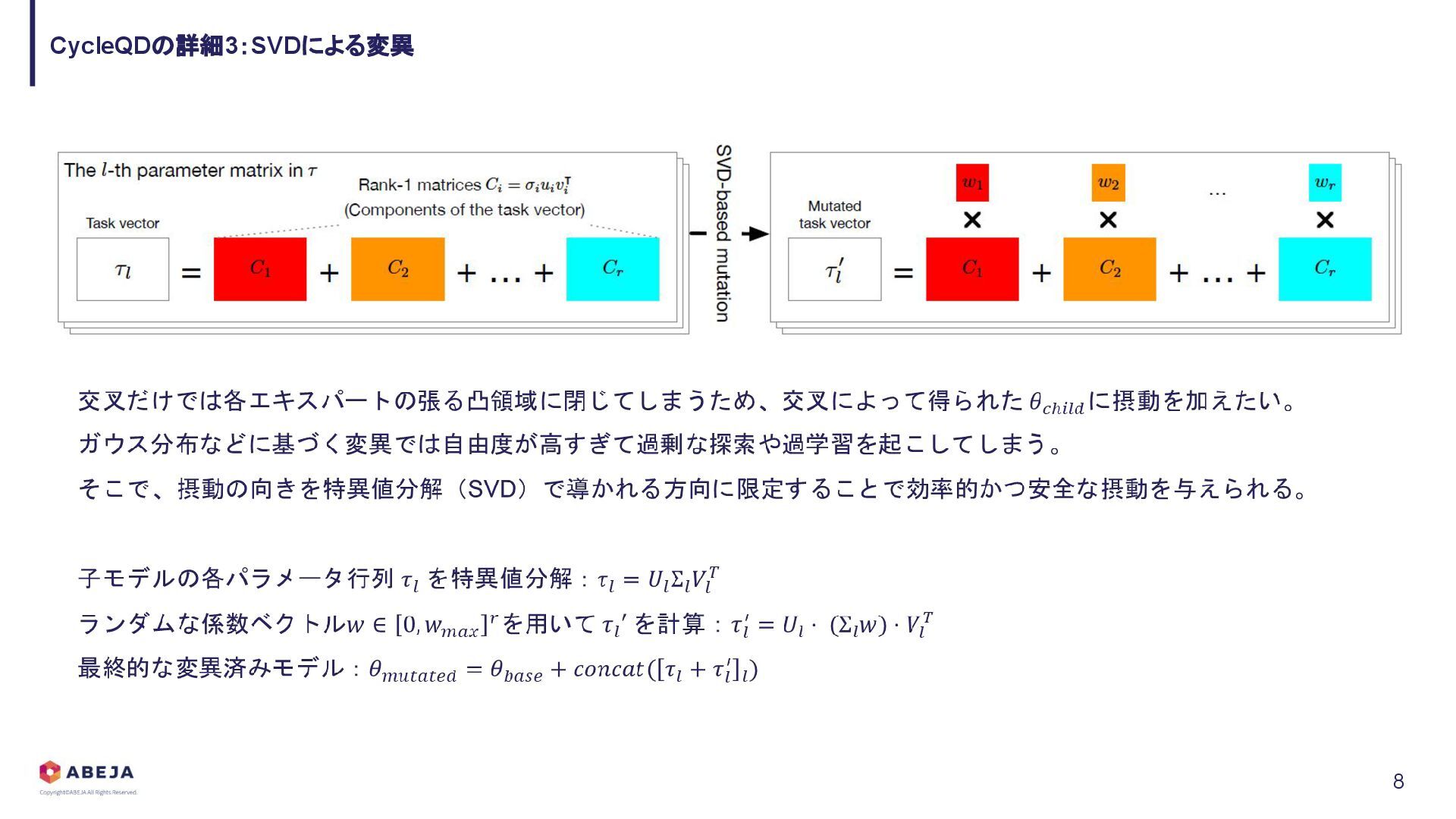{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}