Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AgentCoreMemory_FinJAWS
Search
Koheiawa
March 31, 2026
17
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AgentCoreMemory_FinJAWS
Koheiawa
March 31, 2026
More Decks by Koheiawa
See All by Koheiawa
CCoEセミナー_第33回_AWS_reInvent_社内Recap_v0.1.pdf
koheiawa
0
35
Organizations_JAWS_Yokohama
koheiawa
0
62
AWS VerifiedAccess
koheiawa
1
550
IAMAccessAnalyzer_Security-JAWS
koheiawa
1
1.8k
SecurityHub_FinJAWS
koheiawa
8
1.3k
DirectConnectSiteLink_みのるんさん勉強会
koheiawa
1
4.8k
Featured
See All Featured
The Pragmatic Product Professional
lauravandoore
37
7.4k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
Site-Speed That Sticks
csswizardry
13
1.2k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Code Review Best Practice
trishagee
74
20k
Done Done
chrislema
186
16k
The Invisible Side of Design
smashingmag
301
52k
Visualization
eitanlees
152
17k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Faster Mobile Websites
deanohume
310
32k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Transcript
Code Talks から学ぶ、 AIエージェントのデータ分離
2020年に某大手証券グループのシンクタンクに新卒入社。 Fin-JAWS 運営。 クラウドセキュリティ担当でしたが時代の波にさらわれてAI エージェントの面倒も見るようになりました。 CISSP / 2023-25 AWS Top
Engineer(Security) あわ が くぼ 粟ケ窪 康平
話の参考にしているセッション AIエージェントのデータ分離 Amazon Bedrock AgentCoreによるマルチテナントSaaSエージェント構築手法
話の参考にしているセッション AIエージェントのデータ分離 Amazon Bedrock AgentCoreによるマルチテナントSaaSエージェント構築手法 Lv.400 のセッション
話の参考にしているセッション AIエージェントのデータ分離 「Amazon Bedrock AgentCoreによるマルチテナントSaaSエージェント 構築手法」 ✓ 前半は Identity に関する話→こっちは難しい
✓ 後半はデータ分離に関する話→こっちは比較的易しい
話の参考にしているセッション AIエージェントのデータ分離 「Amazon Bedrock AgentCoreによるマルチテナントSaaSエージェント 構築手法」 ✓ 前半は Identity に関する話→こっちは難しい
✓ 後半はデータ分離に関する話→こっちは比較的易しい 後半のデータ分離に焦点を当ててお話
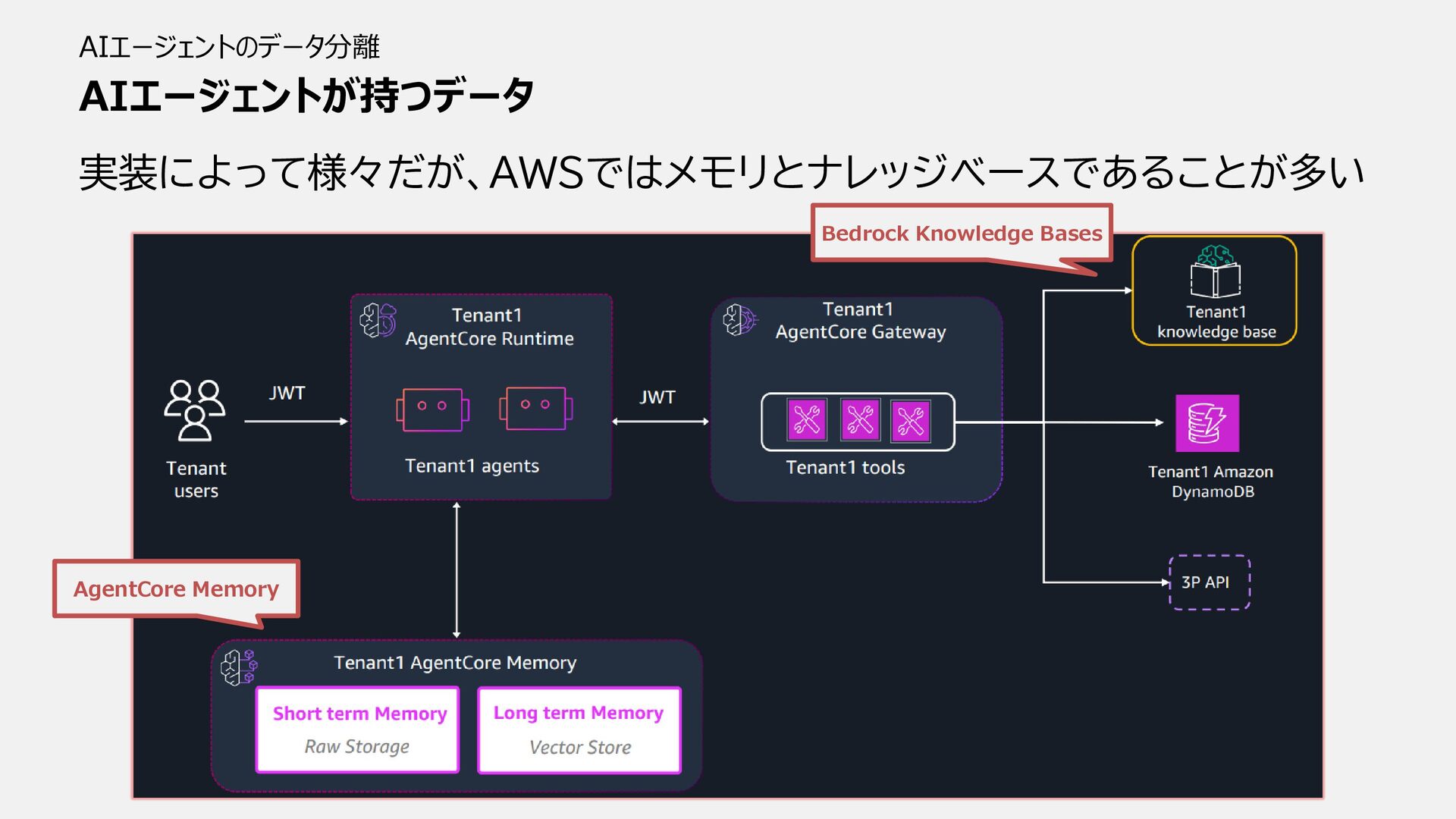
AIエージェントが持つデータ AIエージェントのデータ分離 実装によって様々だが、AWSではメモリとナレッジベースであることが多い AgentCore Memory Bedrock Knowledge Bases
AIエージェントが持つデータ AIエージェントのデータ分離 実装によって様々だが、AWSではメモリとナレッジベースであることが多い AgentCore Memory Bedrock Knowledge Bases メモリについて話します
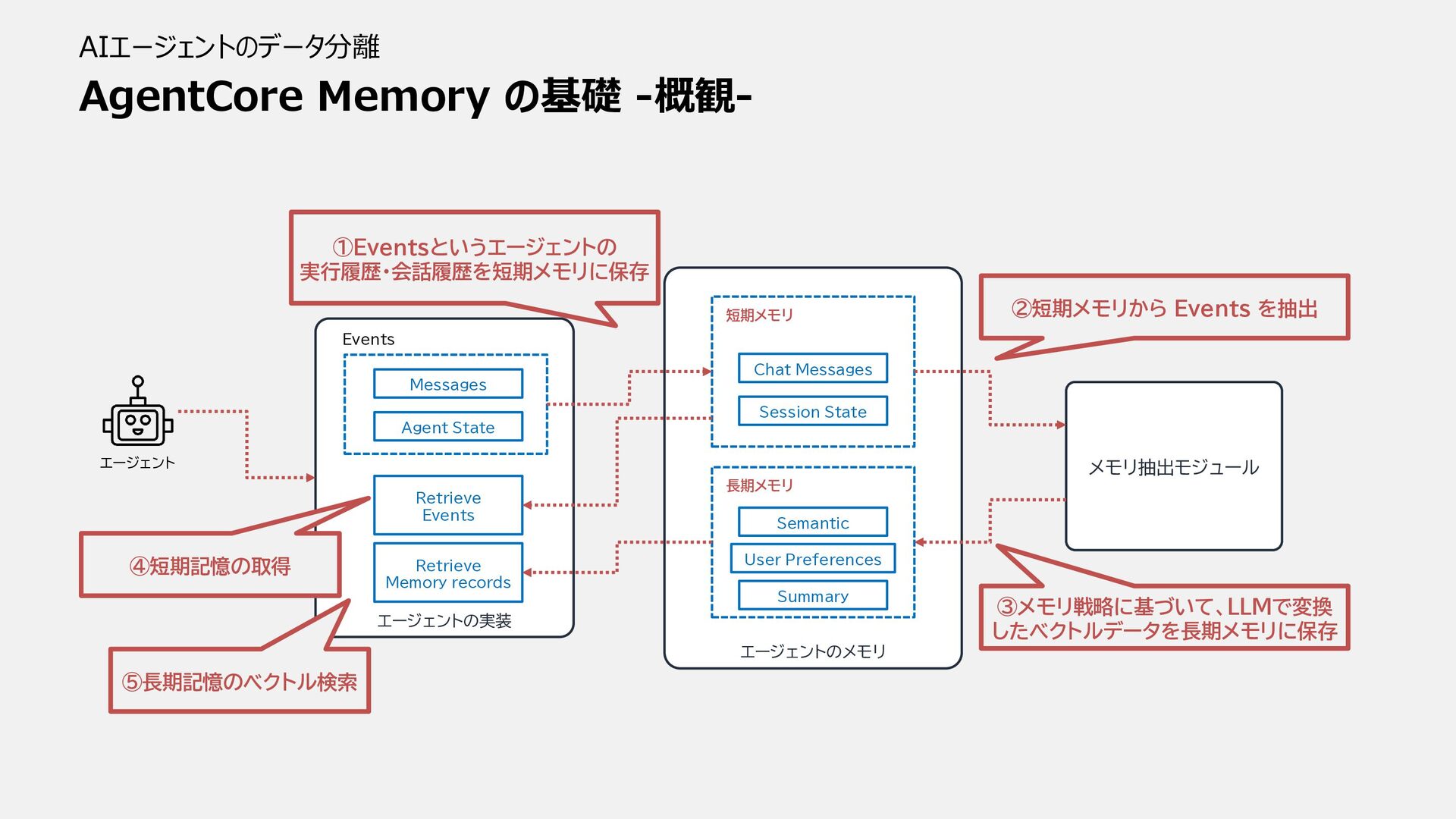
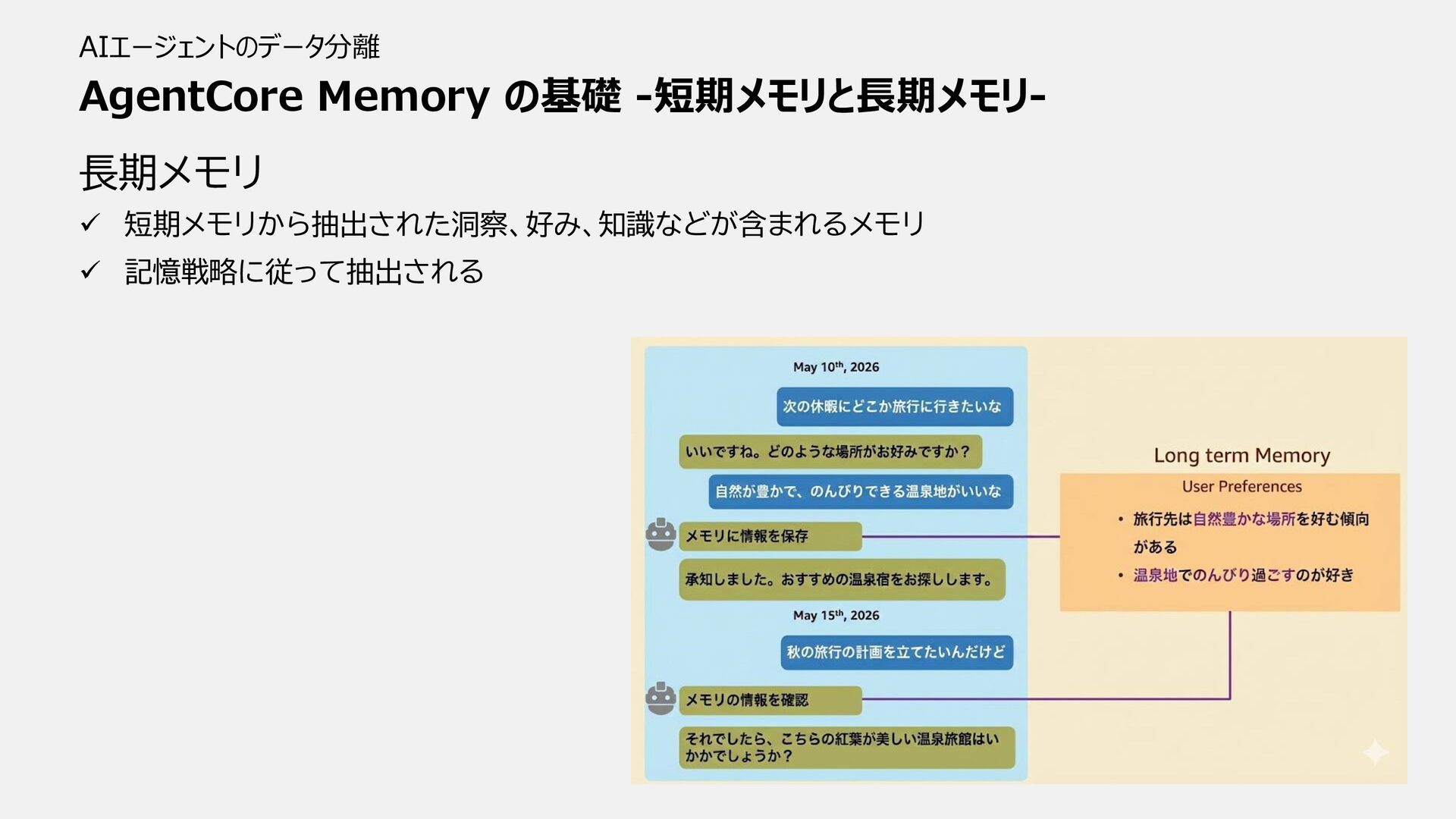
AgentCore Memory の基礎 -概観- AIエージェントのデータ分離 エージェント メモリ抽出モジュール エージェントの実装 Events Messages
Agent State Retrieve Events Retrieve Memory records エージェントのメモリ 短期メモリ Chat Messages Session State 長期メモリ Semantic User Preferences Summary ①Eventsというエージェントの 実行履歴・会話履歴を短期メモリに保存 ②短期メモリから Events を抽出 ③メモリ戦略に基づいて、LLMで変換 したベクトルデータを長期メモリに保存 ⑤長期記憶のベクトル検索 ④短期記憶の取得
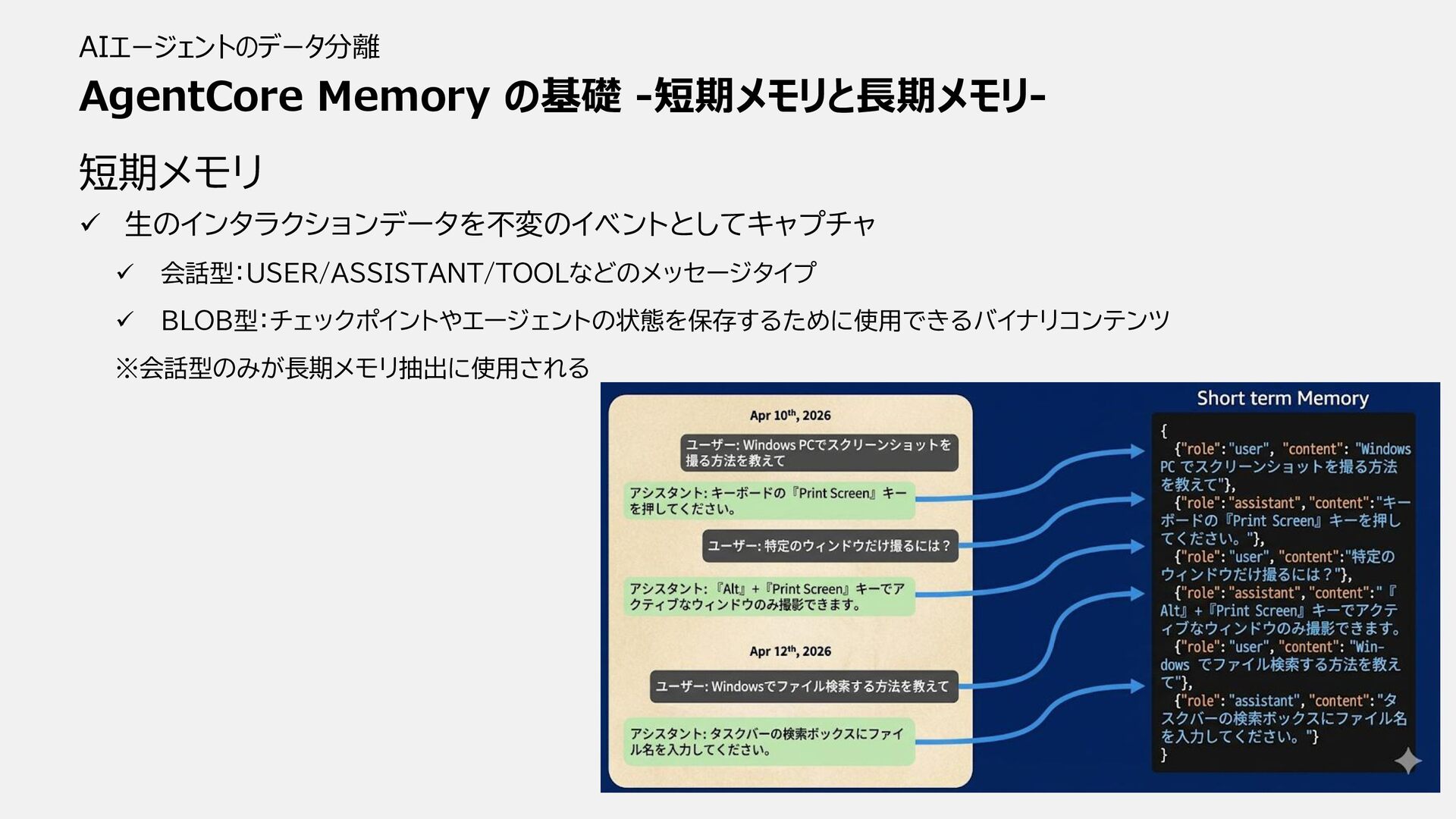
AgentCore Memory の基礎 -短期メモリと長期メモリ- AIエージェントのデータ分離 短期メモリ ✓ 生のインタラクションデータを不変のイベントとしてキャプチャ ✓ 会話型:USER/ASSISTANT/TOOLなどのメッセージタイプ
✓ BLOB型:チェックポイントやエージェントの状態を保存するために使用できるバイナリコンテンツ ※会話型のみが長期メモリ抽出に使用される
AgentCore Memory の基礎 -短期メモリと長期メモリ- AIエージェントのデータ分離 長期メモリ ✓ 短期メモリから抽出された洞察、好み、知識などが含まれるメモリ ✓ 記憶戦略に従って抽出される
メモリのデータ分離の重要性 AIエージェントのデータ分離 なぜデータ分離が重要? ✓ ユーザ間での記憶の混同が起こる ✓ Aさんが言った内容をBさんが言ったものと取り違える ✓ 長期メモリは短期メモリから抽出されるため、長期メモリの汚染が起こる ✓
セキュリティとプライバシーの欠如 ✓ Aさんの機密情報(口座番号や住所)がBさんの回答に混入するリスク ✓ 長期メモリの質の低下 ✓ 分離が不十分だと複数のユーザの情報が混ざり、平均化された無意味な「好み」しか残らなくなる
メモリのデータ分離の重要性 AIエージェントのデータ分離 なぜデータ分離が重要? ✓ ユーザ間での記憶の混同が起こる ✓ Aさんが言った内容をBさんが言ったものと取り違える ✓ 長期メモリは短期メモリから抽出されるため、長期メモリの汚染が起こる ✓
セキュリティとプライバシーの欠如 ✓ Aさんの機密情報(口座番号や住所)がBさんの回答に混入するリスク ✓ 長期メモリの質の低下 ✓ 分離が不十分だと複数のユーザの情報が混ざり、平均化された無意味な「好み」しか残らなくなる メモリを利用する際はデータ分離の検討が最優先事項
短期メモリのデータ分離 AIエージェントのデータ分離 短期メモリは3つのIDを持つ 1. memoryId : 新しいメモリリソースを作成すると自動的に作成される 2. actorId :
システム内のエンティティ(ユーザ、エージェント、プロジェクト)を識別する 3. sessionId : セッション自体の識別子(短期メモリはセッション単位でグルーピングされる)
短期メモリのデータ分離 AIエージェントのデータ分離 短期メモリは3つのIDを持つ 1. memoryId : 新しいメモリリソースを作成すると自動的に作成される 2. actorId :
システム内のエンティティ(ユーザ、エージェント、プロジェクト)を識別する 3. sessionId : セッション自体の識別子(短期メモリはセッション単位でグルーピングされる) memoryId と sessionId は自動作成
短期メモリのデータ分離 AIエージェントのデータ分離 短期メモリは3つのIDを持つ 1. memoryId : 新しいメモリリソースを作成すると自動的に作成される 2. actorId :
システム内のエンティティ(ユーザ、エージェント、プロジェクト)を識別する 3. sessionId : セッション自体の識別子(短期メモリはセッション単位でグルーピングされる) actorId は自分で定義
短期メモリのデータ分離 AIエージェントのデータ分離 短期メモリは3つのIDを持つ 1. memoryId : 新しいメモリリソースを作成すると自動的に作成される 2. actorId :
システム内のエンティティ(ユーザ、エージェント、プロジェクト)を識別する 3. sessionId : セッション自体の識別子(短期メモリはセッション単位でグルーピングされる) actorId は自分で定義 メモリは actorId で分離する
短期メモリのデータ分離 AIエージェントのデータ分離 { "iss": "https://login.microsoftonline.com/91234567-89ab-cdef-0123-456789abcdef/v2.0", "tid": "91234567-89ab-cdef-0123-456789abcdef", // テナントID "oid":
"aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", // ユーザーのオブジェクトID "sub": "XyZ...base64...", // ユーザー識別子 "upn": "
[email protected]
", // ユーザー名 "name": "Kouhei Awagakubo", "roles": ["Department_Sales", "Agent_User"], // ロール "groups": ["88888888-4444-4444-4444-121212121212"], // グループID "extension_department": "Sales_Dev_Tokyo", // カスタム属性 "ver": "2.0", "iat": 1718806000, "exp": 1718810000 } エンプラ御用達の EntraID におけるJWTトークンのサンプル actorId はJWTトークン内の要素を組み合わせてユニークなものを作成する ✓ actorId はデータベースにおける主キーのようなもの
短期メモリのデータ分離 AIエージェントのデータ分離 actorId はJWTトークン内の要素を組み合わせてユニークなものを作成する ✓ actorId はデータベースにおける主キーのようなもの { "iss": "https://login.microsoftonline.com/91234567-89ab-cdef-0123-456789abcdef/v2.0",
"tid": "91234567-89ab-cdef-0123-456789abcdef", // テナントID "oid": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", // ユーザーのオブジェクトID "sub": "XyZ...base64...", // ユーザー識別子 "upn": "
[email protected]
", // ユーザー名 "name": "Kouhei Awagakubo", "roles": ["Department_Sales", "Agent_User"], // ロール "groups": ["88888888-4444-4444-4444-121212121212"], // グループID "extension_department": "Sales_Dev_Tokyo", // カスタム属性 "ver": "2.0", "iat": 1718806000, "exp": 1718810000 } エンプラ御用達の EntraID におけるJWTトークンのサンプル actorId → ${tid}:${oid}
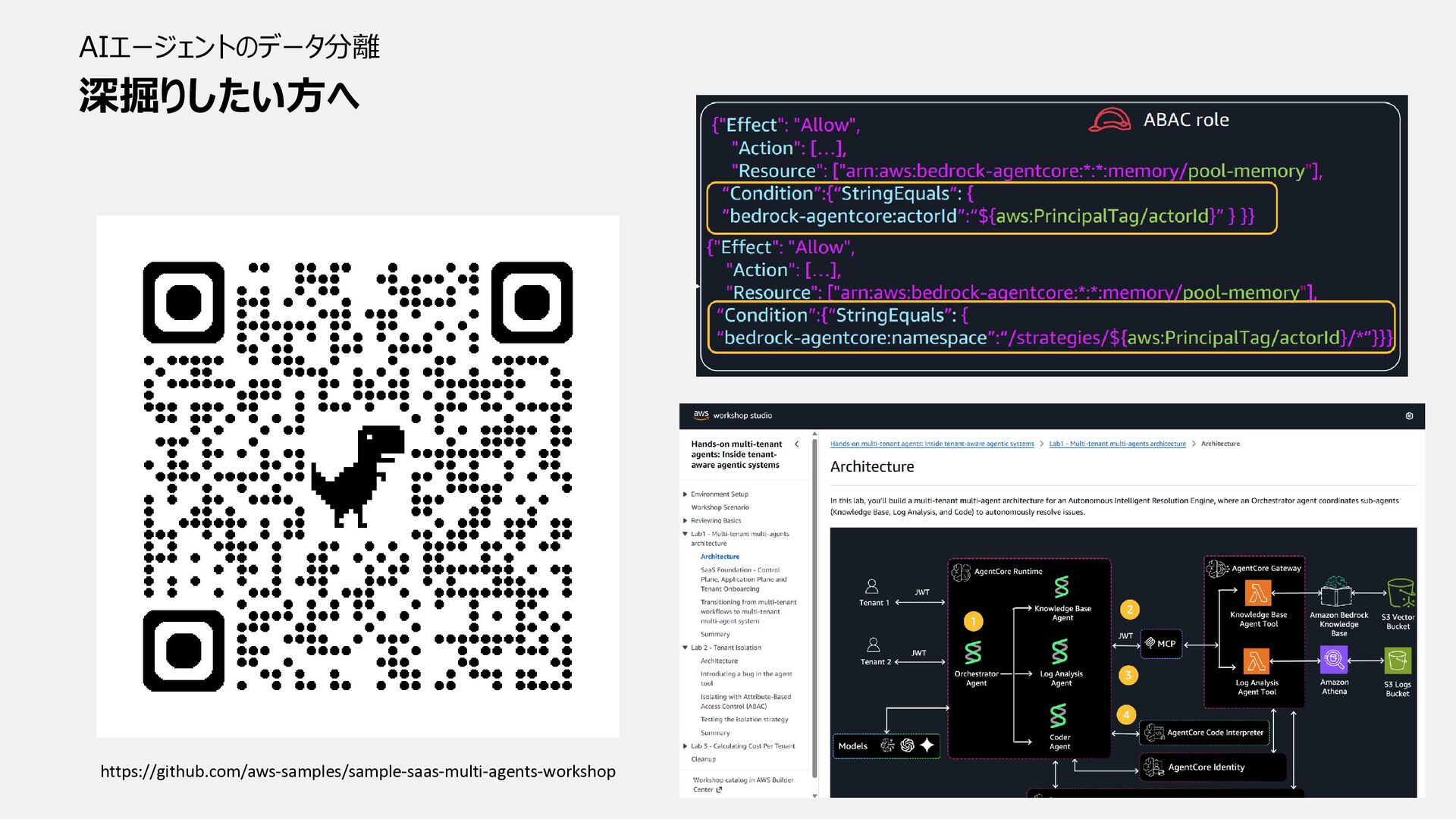
長期メモリのデータ分離 AIエージェントのデータ分離 長期メモリは namespaces で分離する "namespaces": [“/strategy/{strategyId}/actor/{actorId}/session/{sessionId}”] 1. actorId :
処理中のイベントのアクター識別子(短期メモリの actorId と同様) 2. sessionId : イベントからのセッション識別子(短期メモリの sessionId と同様) 3. strategyId : 組織の抽出戦略識別子
長期メモリのデータ分離 AIエージェントのデータ分離 長期メモリは namespaces で分離する "namespaces": [“/strategy/{strategyId}/actor/{actorId}/session/{sessionId}”] 1. actorId :
処理中のイベントのアクター識別子(短期メモリの actorId と同様) 2. sessionId : イベントからのセッション識別子(短期メモリの sessionId と同様) 3. strategyId : 組織の戦略識別子 長期メモリでも actorId を利用 すれば同様にデータ分離が可能
AgentCore Memory のデータ分離は actorId が鍵!
深掘りしたい方へ AIエージェントのデータ分離 https://github.com/aws-samples/sample-saas-multi-agents-workshop
ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![長期メモリのデータ分離 AIエージェントのデータ分離 長期メモリは namespaces で分離する "namespaces": [“/strategy/{strategyId}/actor/{actorId}/session/{sessionId}”] 1. actorId :](https://files.speakerdeck.com/presentations/87c98cb934e24aff89327a5465547bec/slide_19.jpg){kind=link}
![長期メモリのデータ分離 AIエージェントのデータ分離 長期メモリは namespaces で分離する "namespaces": [“/strategy/{strategyId}/actor/{actorId}/session/{sessionId}”] 1. actorId :](https://files.speakerdeck.com/presentations/87c98cb934e24aff89327a5465547bec/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}