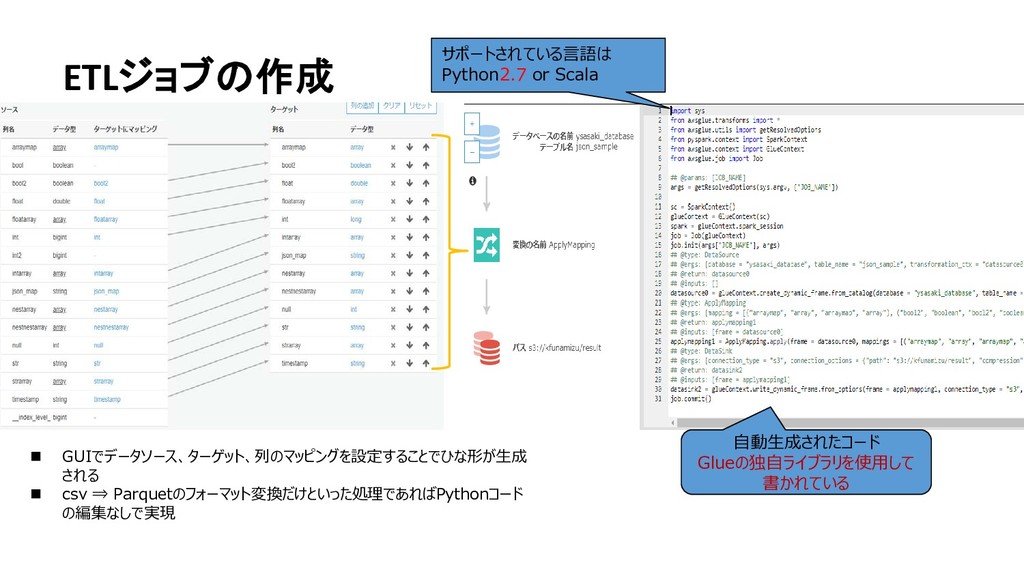
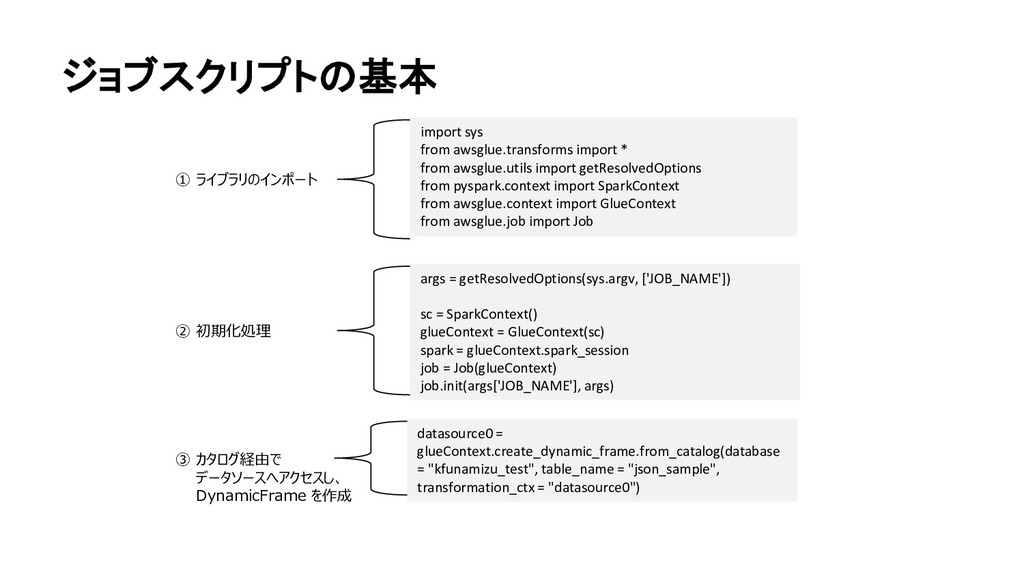
("arraymap", "array", "arraymap", "array"), ("bool2", "boolean", "bool2", "boolean"), ("float", "double", "float", "double"), ("floatarray", "array", "floatarray", "array"), ("int", "long", "int", "long"), ("intarray", "array", "intarray", "array"), ("json_map", "string", "json_map", "string"), ("nestarray", "array", "nestarray", "array"), ("nestnestarray", "array", "nestnestarray", "array"), ("null", "int", "null", "int"), ("str", "string", "str", "string"), ("strarray", "array", "strarray", "array"), ("timestamp", "string", "timestamp", "string") ], transformation_ctx = "applymapping1") … ④ DynamicFrameを操作してデータ変換 今回はただのマッピング処理で列数を減らした ⑤ 変換後のDynamicFrameを カタログ経由でターゲットに出力 datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://kfunamizu/result", "compression": "gzip"}, format = "json", transformation_ctx = "datasink2") job.commit()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
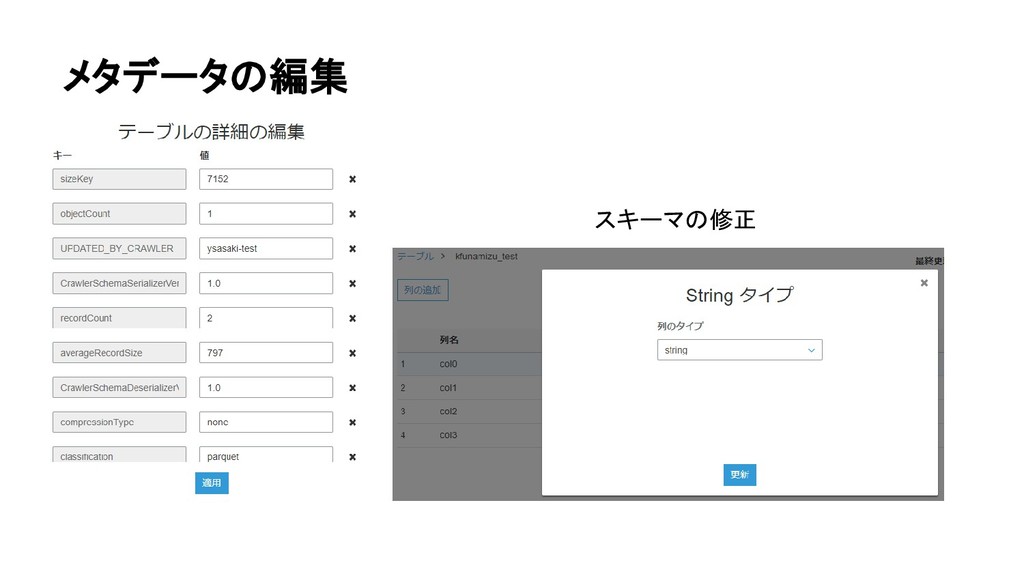{kind=link}
{kind=link}
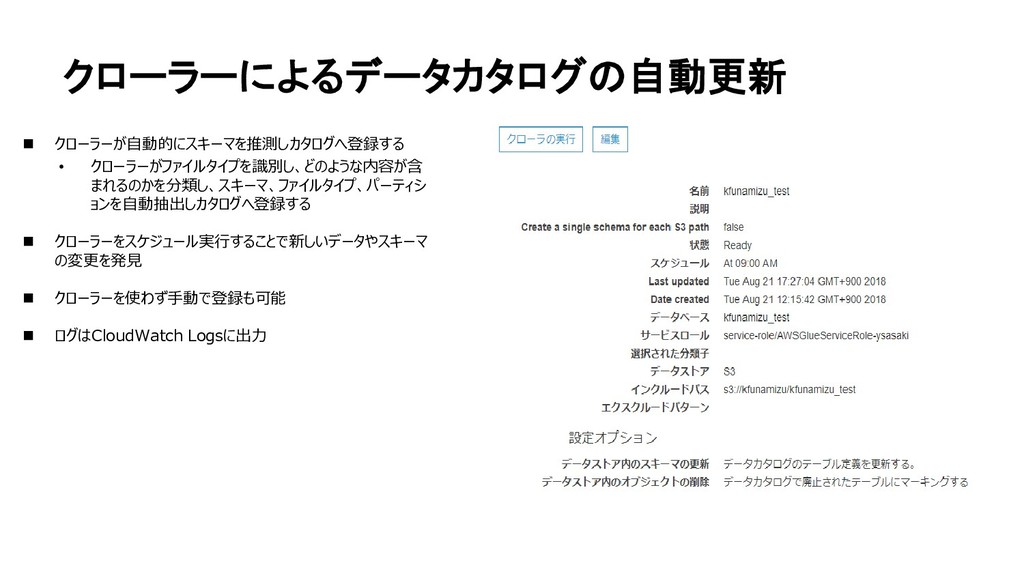{kind=link}
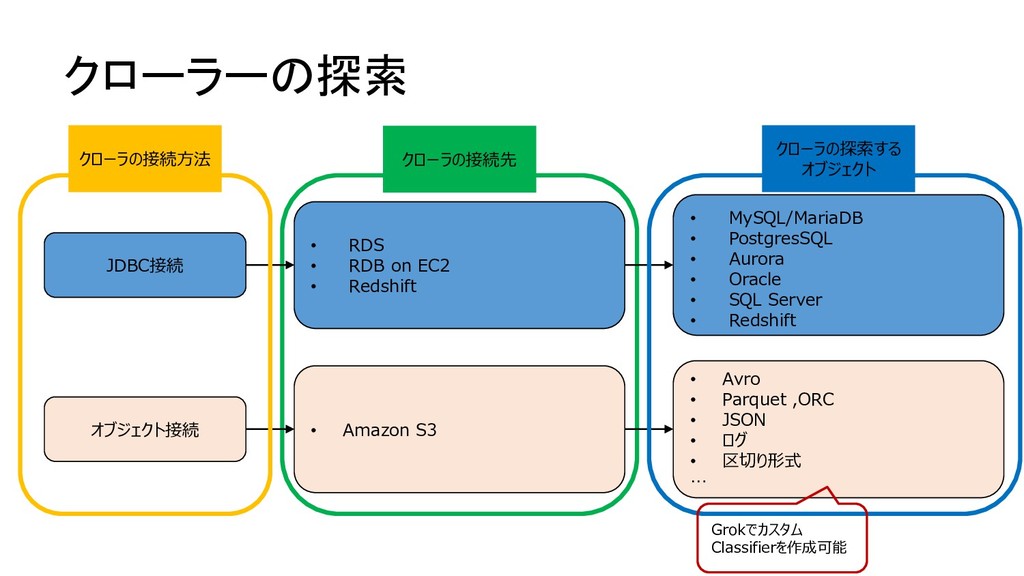{kind=link}
{kind=link}
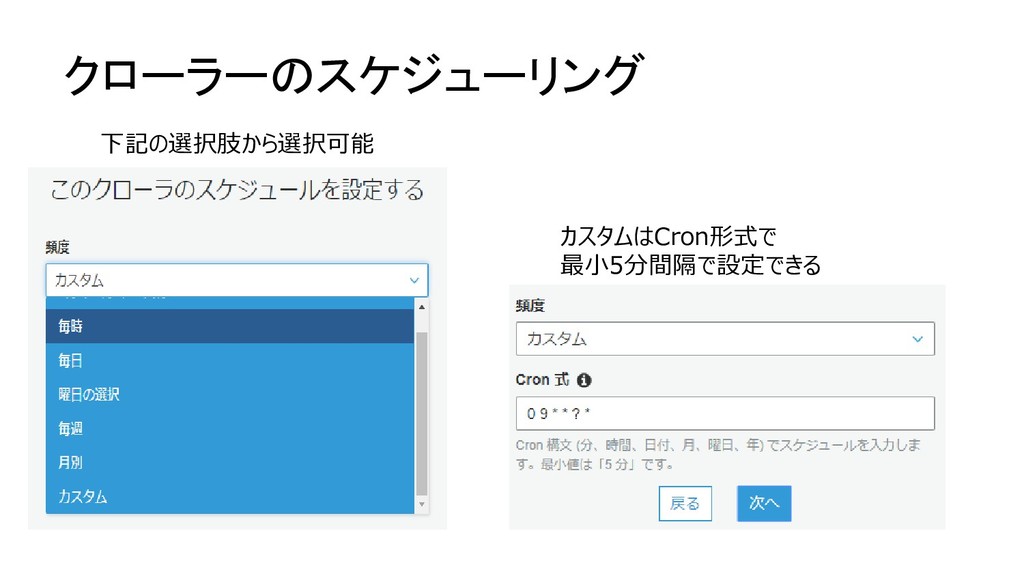{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}