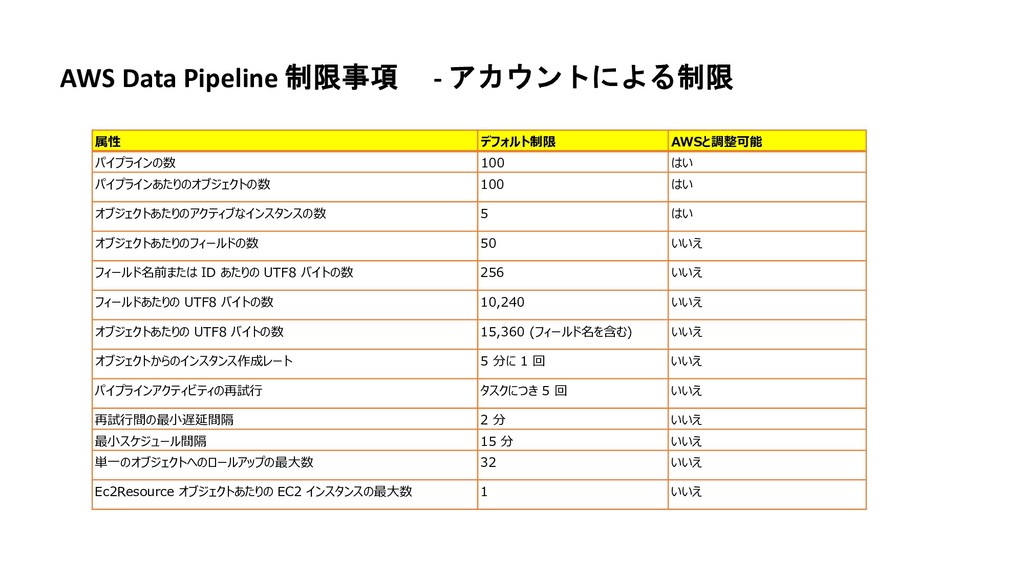
100 はい パイプラインあたりのオブジェクトの数 100 はい オブジェクトあたりのアクティブなインスタンスの数 5 はい オブジェクトあたりのフィールドの数 50 いいえ フィールド名前または ID あたりの UTF8 バイトの数 256 いいえ フィールドあたりの UTF8 バイトの数 10,240 いいえ オブジェクトあたりの UTF8 バイトの数 15,360 (フィールド名を含む) いいえ オブジェクトからのインスタンス作成レート 5 分に 1 回 いいえ パイプラインアクティビティの再試行 タスクにつき 5 回 いいえ 再試行間の最小遅延間隔 2 分 いいえ 最小スケジュール間隔 15 分 いいえ 単一のオブジェクトへのロールアップの最大数 32 いいえ Ec2Resource オブジェクトあたりの EC2 インスタンスの最大数 1 いいえ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
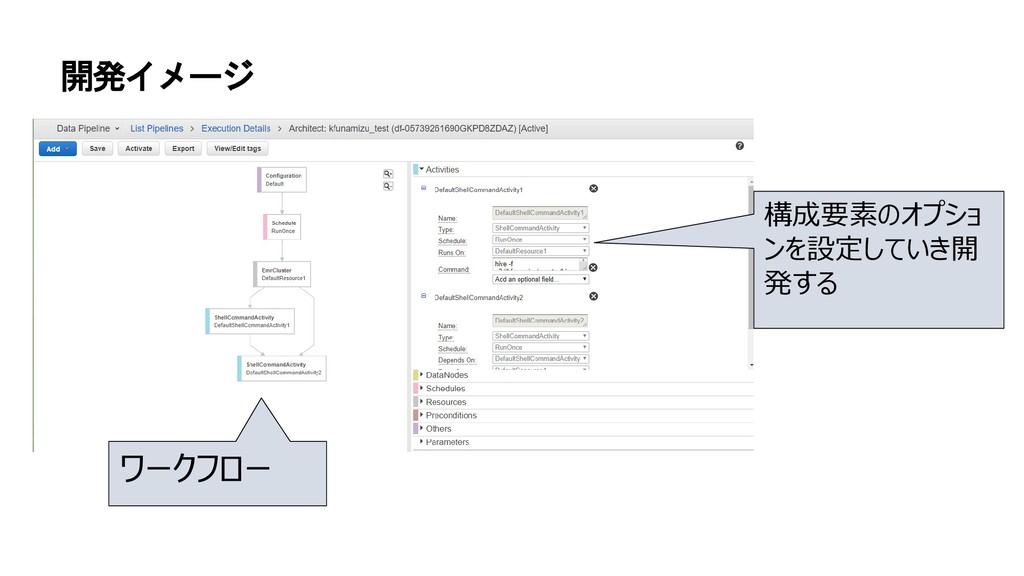{kind=link}
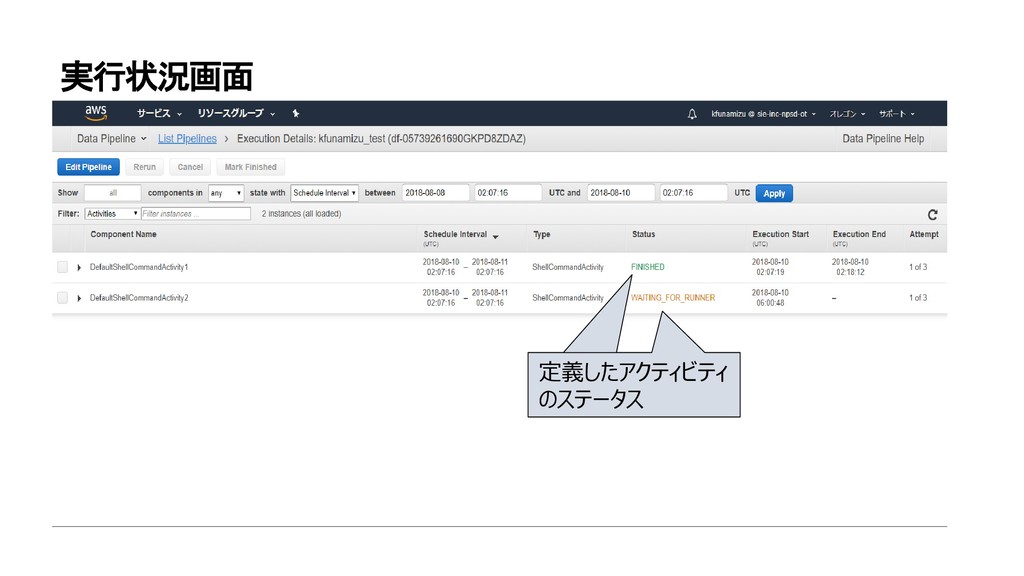{kind=link}
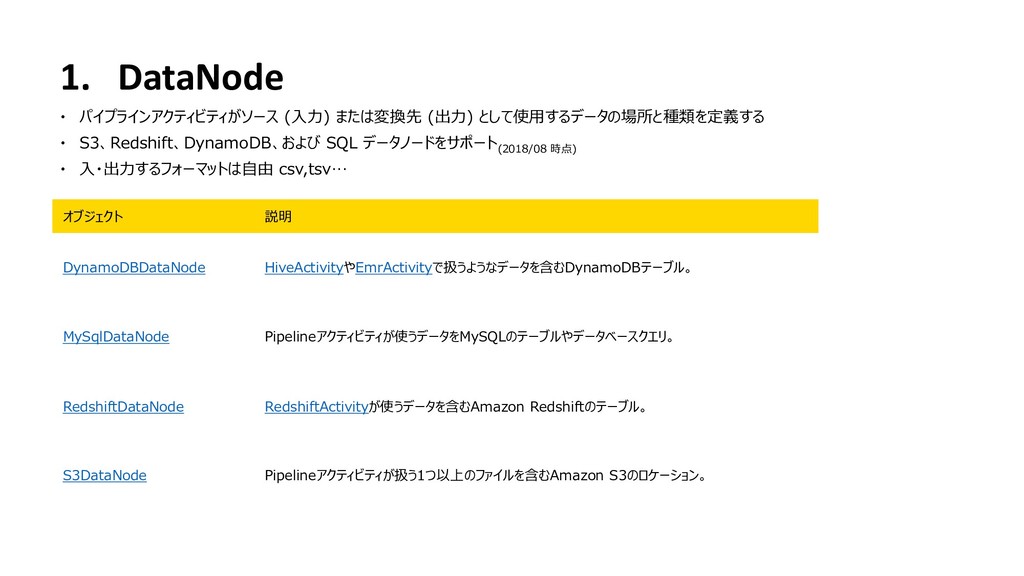{kind=link}
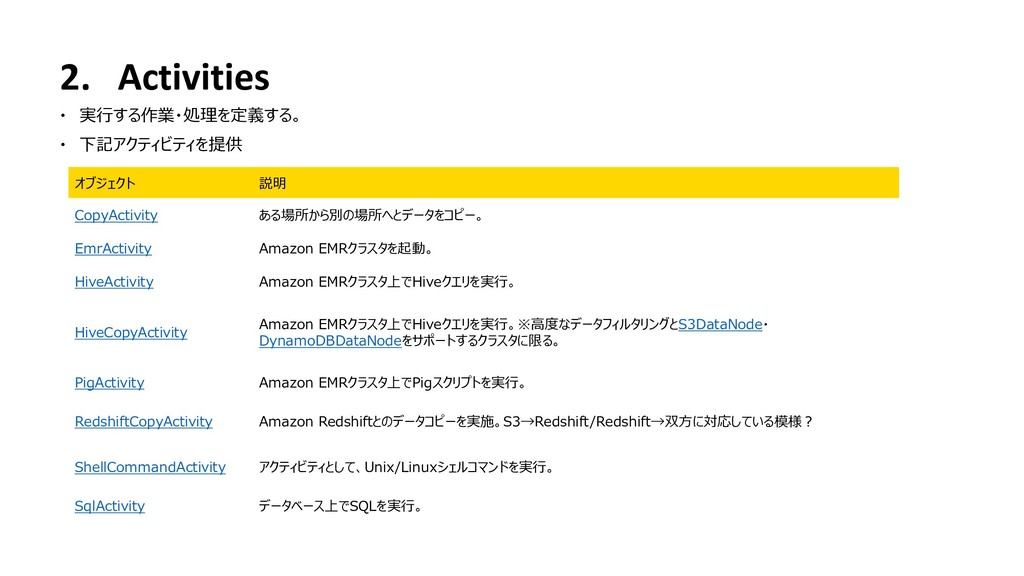{kind=link}
{kind=link}
{kind=link}
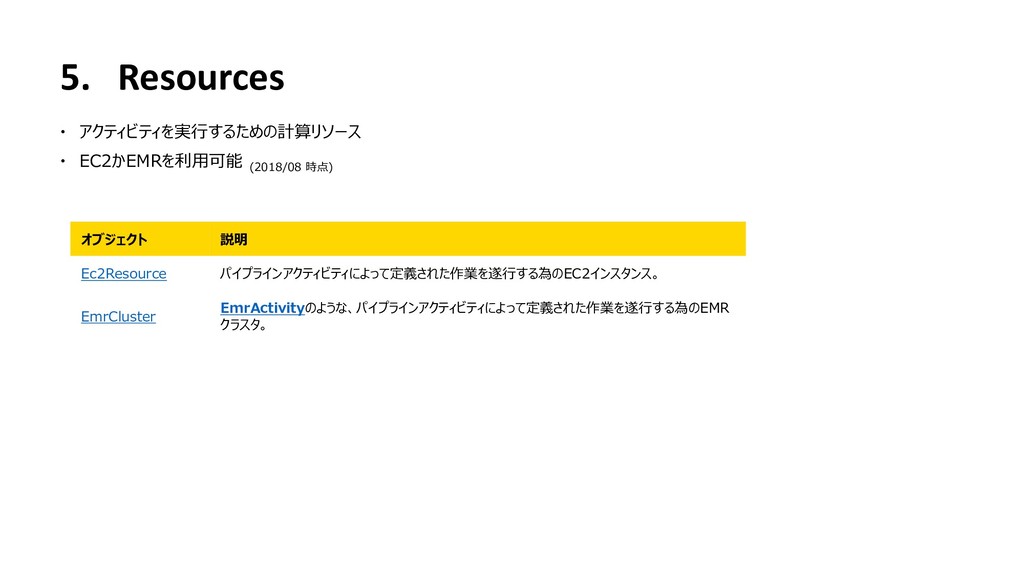{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}