Slides for a presentation of the semester project for deep neural networks course at MIM UW (2019-20).
Presentation: https://youtu.be/ckeKsM6obnM
GitHub: https://github.com/kowaalczyk/reformer-tts
Mateusz Olko: https://www.linkedin.com/in/mateusz-olko/
Tomasz Miśków: https://www.linkedin.com/in/tmiskow/
Krzysztof Kowalczyk: https://www.linkedin.com/in/kowaalczyk/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
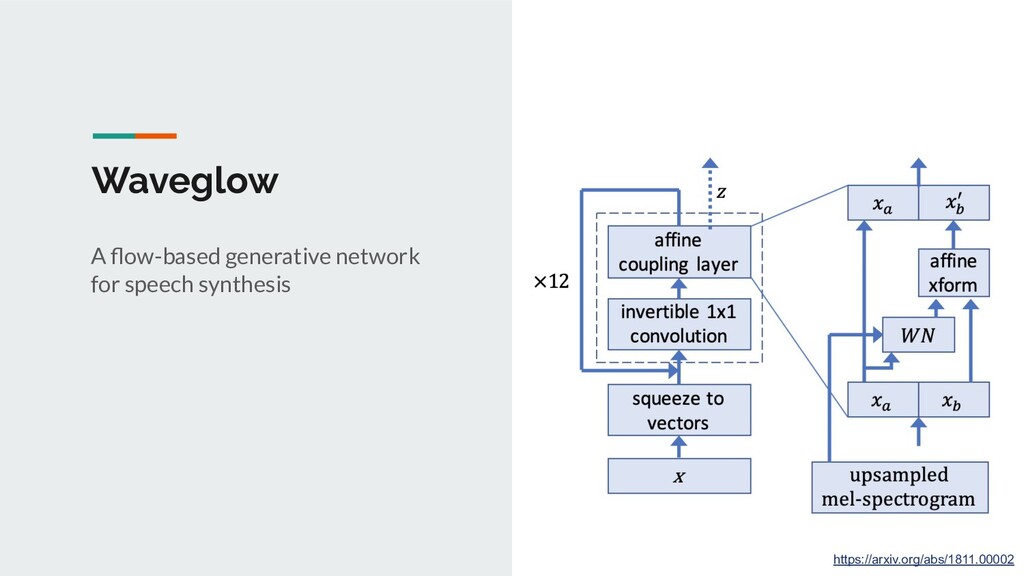{kind=link}
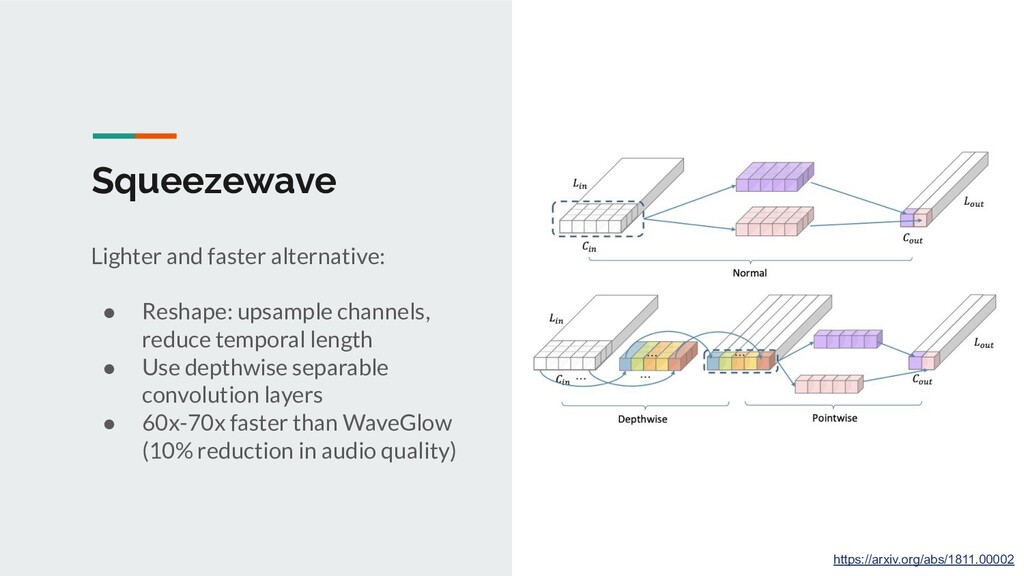{kind=link}
{kind=link}
{kind=link}
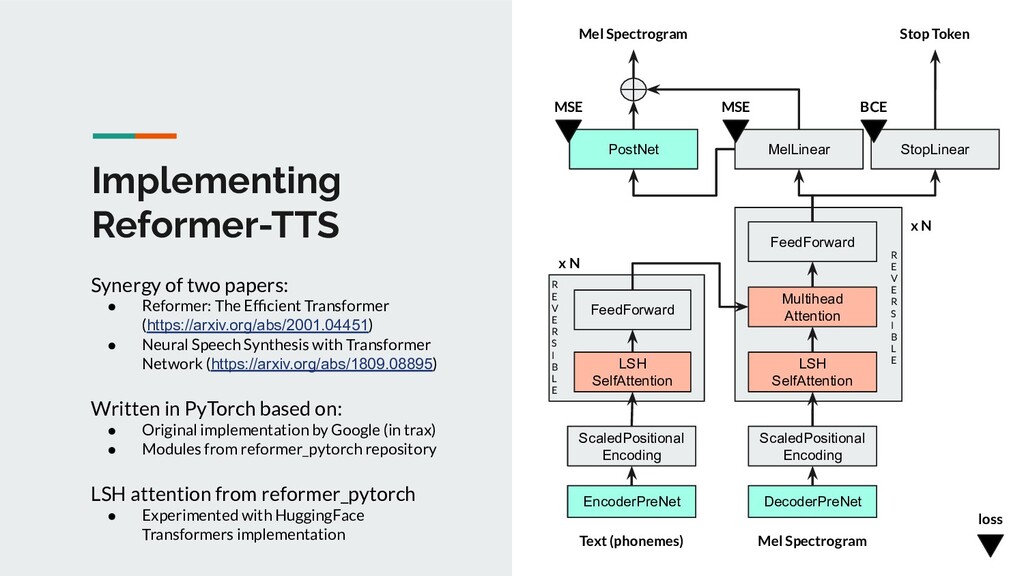{kind=link}
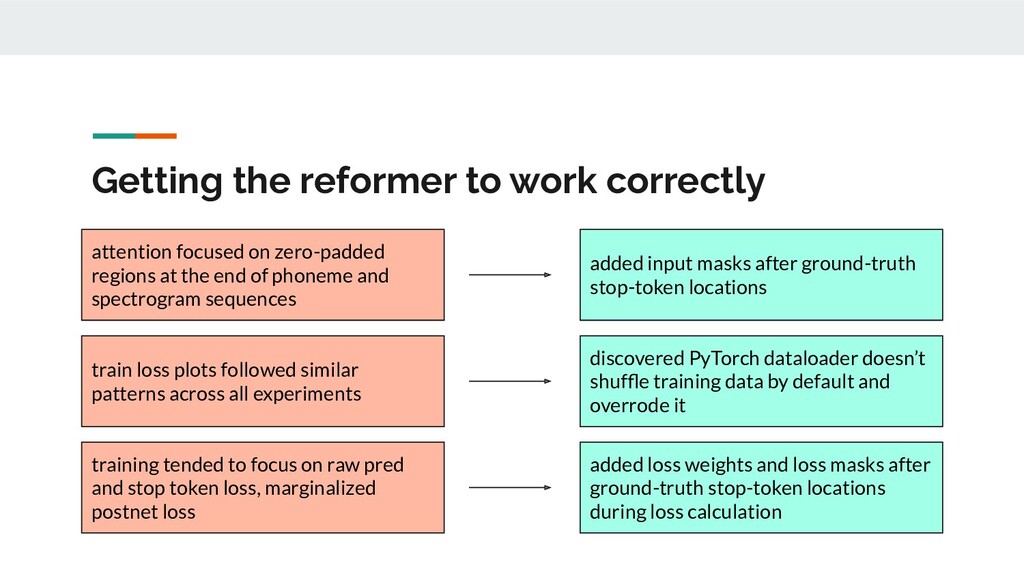{kind=link}
{kind=link}
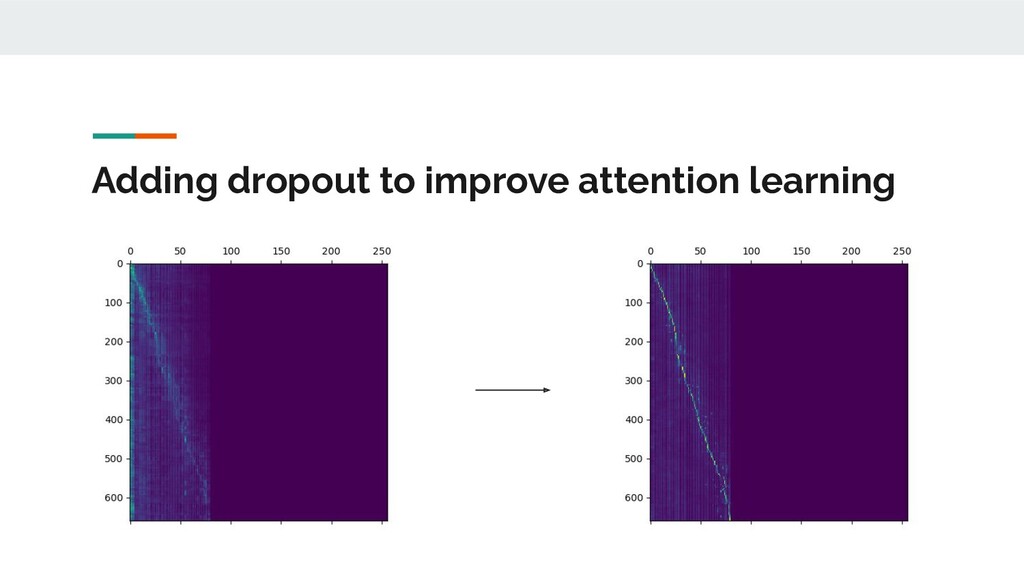{kind=link}
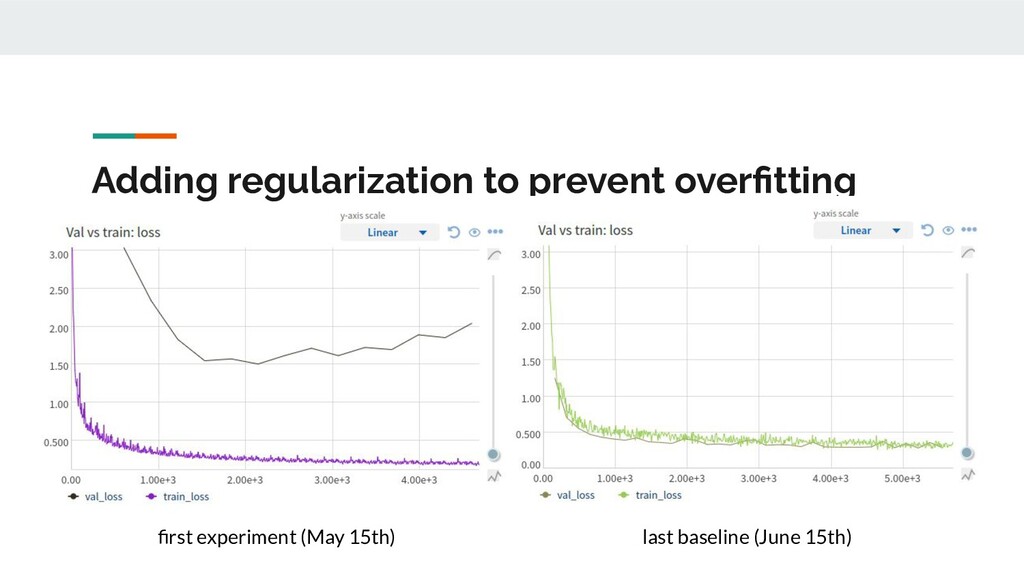{kind=link}
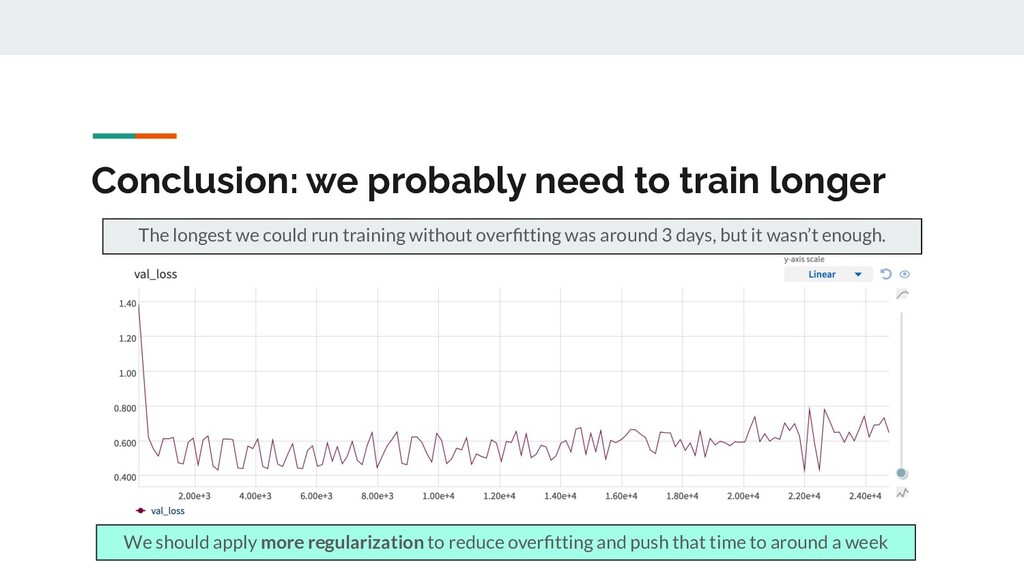{kind=link}
{kind=link}
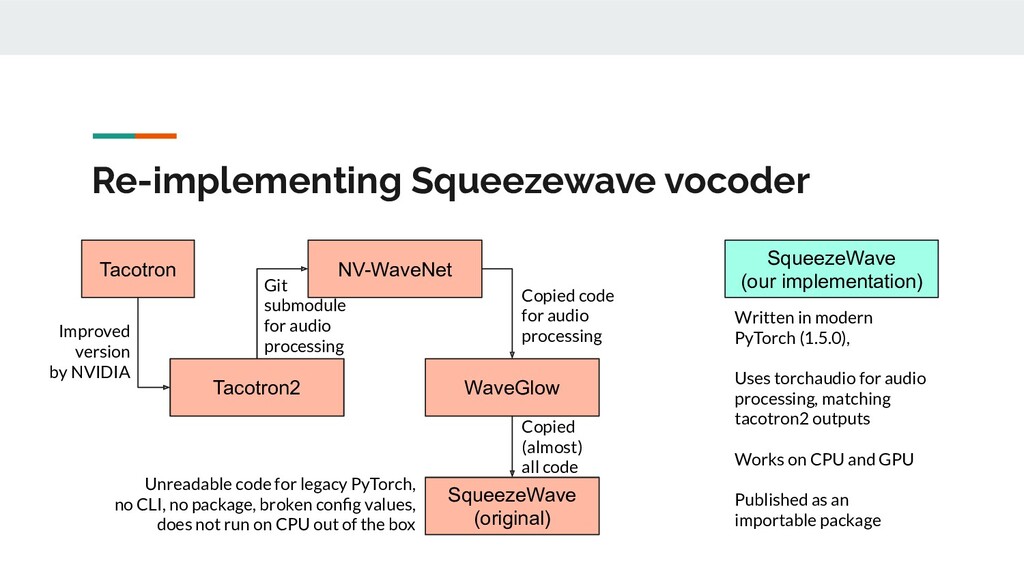{kind=link}
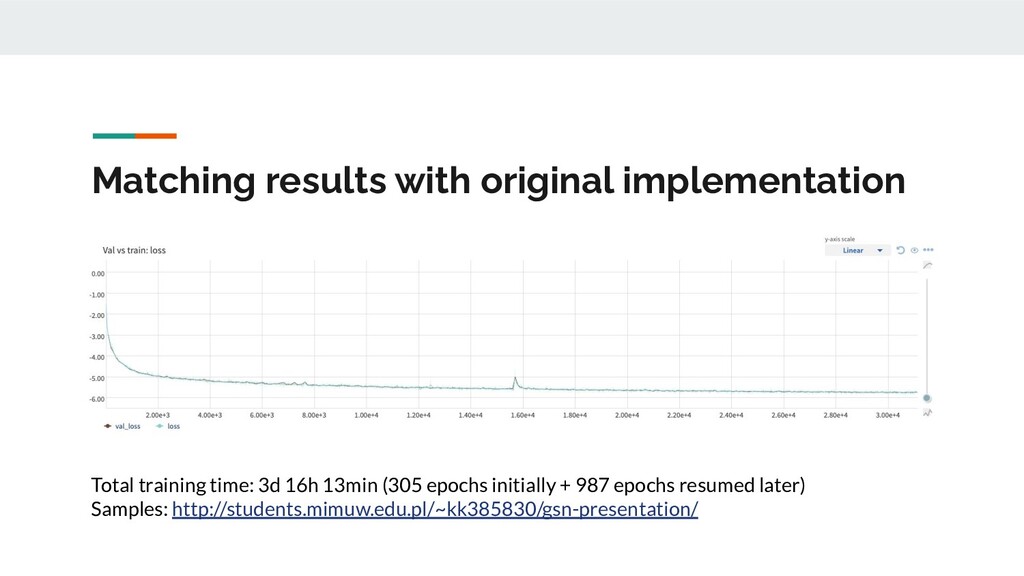{kind=link}
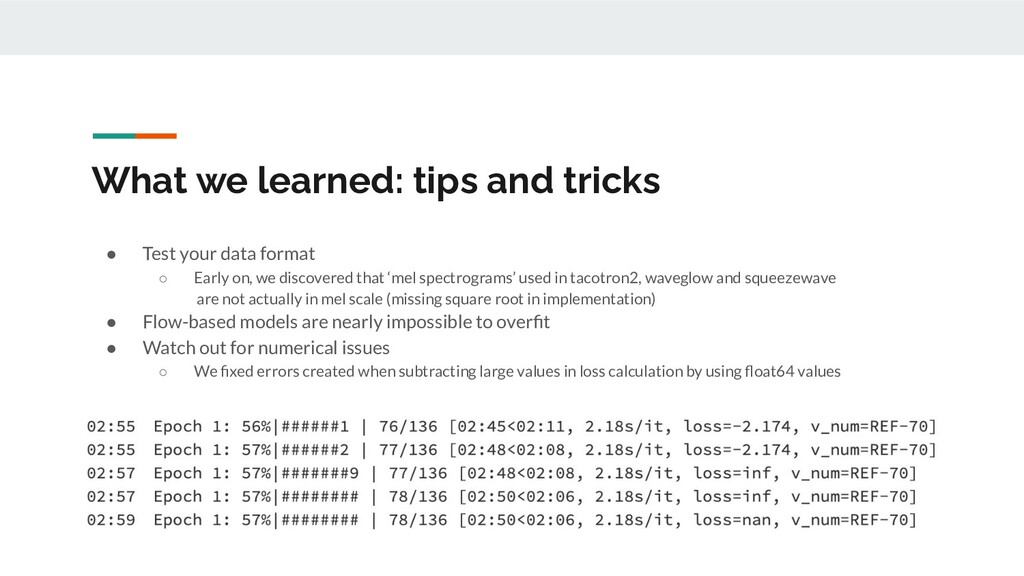{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}