Simple rules for building robust machine learning models
Sixteen (16) simple rules for building robust machine learning models. Invited talk for the AMA call of the Research Data Alliance (RDA) Early Career and Engagement Interest Group (ECEIG).
IN R Kyriakos Chatzidimitriou Research Fellow, Aristotle University of Thessaloniki PhD in Electrical and Computer Engineering [email protected] AMA Call Early Career and Engagement IG
Electrical and Computer Engineering, AUTH, GREECE • 2003-2004, Worked as a developer • 2004-2006, MSc in Computer Science, CSU, USA • 2006-2007, Greek Army • 2007-2012, PhD, AUTH, GREECE • Reinforcement learning and evolutionary computing mechanisms for autonomous agents • 2013-Now, Research Fellow, ECE, AUTH • 2017-Now, co-founder, manager and full stack developer of Cyclopt P.C. • Spin-off company of AUTH focusing on software analytics
No point thus in meaningless suffering J To be happy and for the problems you can choose, choose those that you like solving. By working on the 10K hour of more… …you will be too good to be ignored and you will achieve that by focusing on deep work and working on difficult problems Positive feedback loop, where good things happen
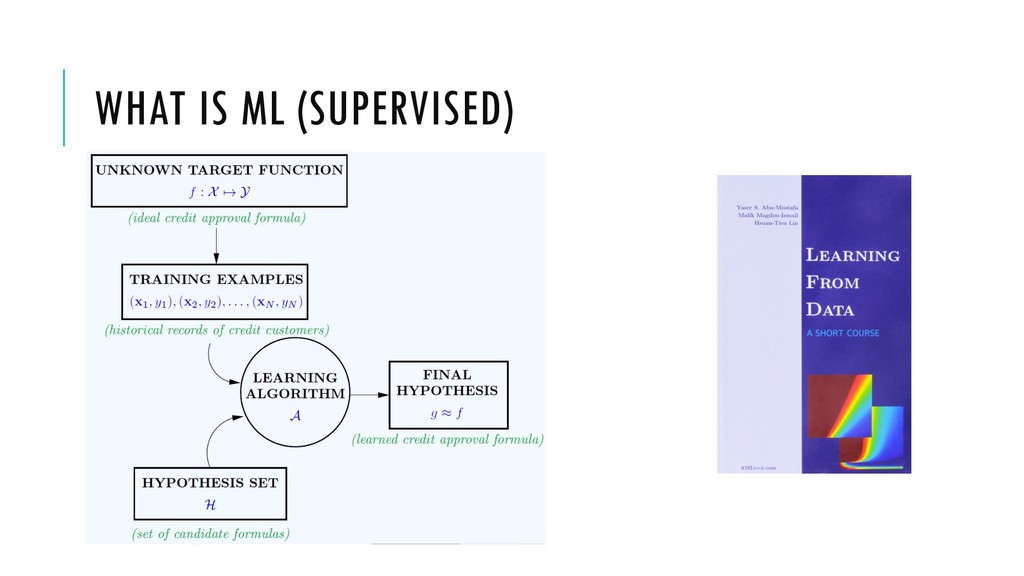
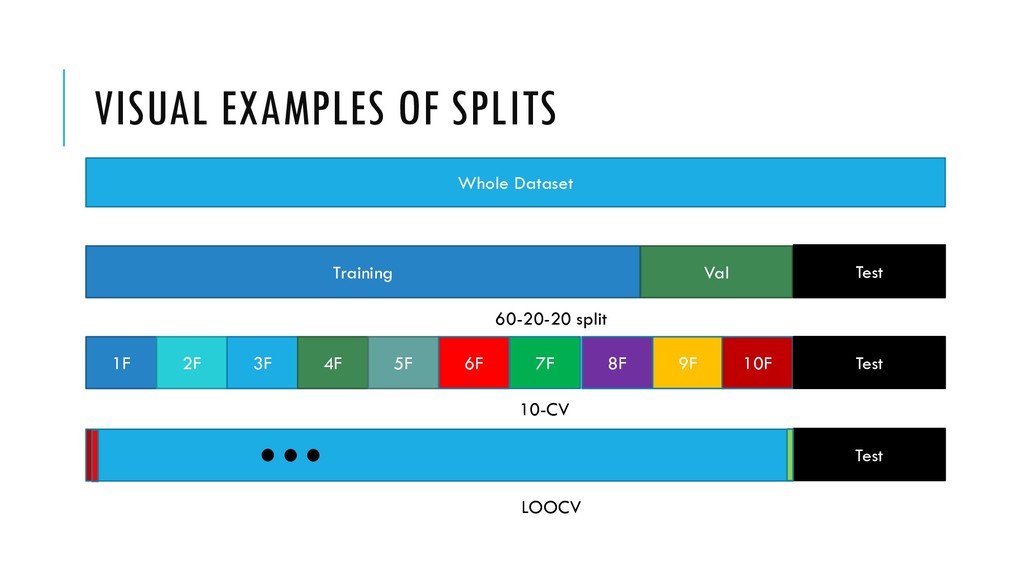
learning algorithms runs •Validation set — Used for making decisions: tuning parameters, selecting features, model complexity Test set — Only used for evaluating performance Else data snooping
data you expect to see in the future • Ideally performance in validation and test sets should be the same • Example: Let’s say validation set performance is super and test set performance is so and so • If from the same distribution: • You had overfitted the validation set • If from different distributions • You had overfitted the validation set • Test set is harder • Test set is different
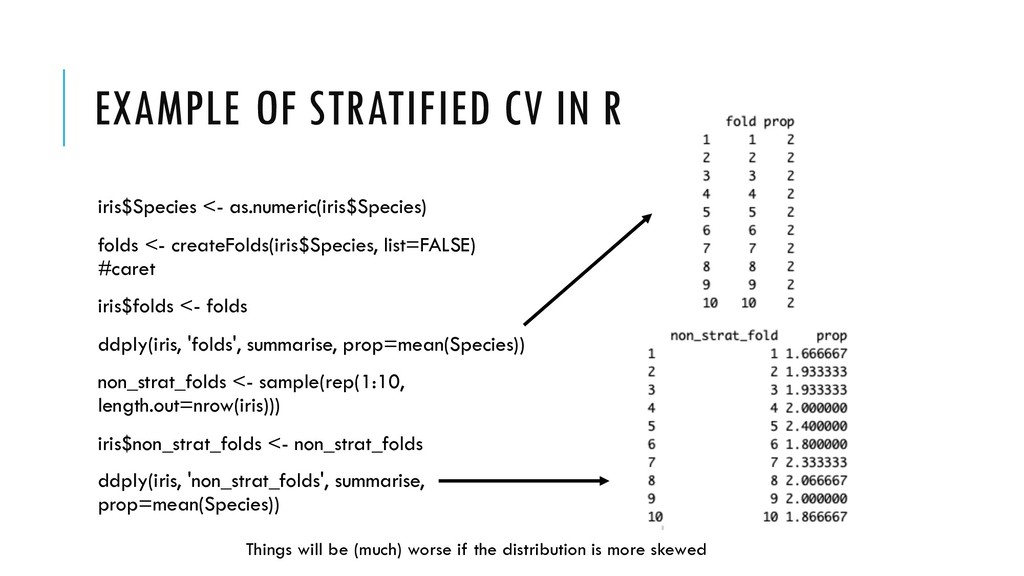
<- createFolds(iris$Species, list=FALSE) #caret iris$folds <- folds ddply(iris, 'folds', summarise, prop=mean(Species)) non_strat_folds <- sample(rep(1:10, length.out=nrow(iris))) iris$non_strat_folds <- non_strat_folds ddply(iris, 'non_strat_folds', summarise, prop=mean(Species)) Things will be (much) worse if the distribution is more skewed
1000 and 10K • #2 For the training set have at least 10x the VC-dimension • For a NN is roughly equal to the number of weights • #3 Popular heuristic for test size should be 30%, less for large problems • #4 If you have more data, put them in the validation set to reduce overfitting • #5 The validation set should be large enough to detect differences between algorithms • For distinguishing between classifier A with 90% accuracy and B with 90.1% accuracy then 100 validation examples will not do it.
faster iterations and focus • Are your classes balanced? Use accuracy • Are your classes imbalanced? Use the F1-score • Are you doing multilabel classification? Use for example macro-averaged accuracy • "#$%& = ( ) ∑ +,( ) (+ , + , + , + ) • B is a binary evaluation metric like Accuracy = :;<=:>< :;<=?;<=:><=?>< • The application dictates the metric • Continuous Implicit Authentication: Equal Error Rate • Combines two metrics: False Acceptance Rate and False Rejection Rate • Interested both in preventing impostors but also allowing legitimate users
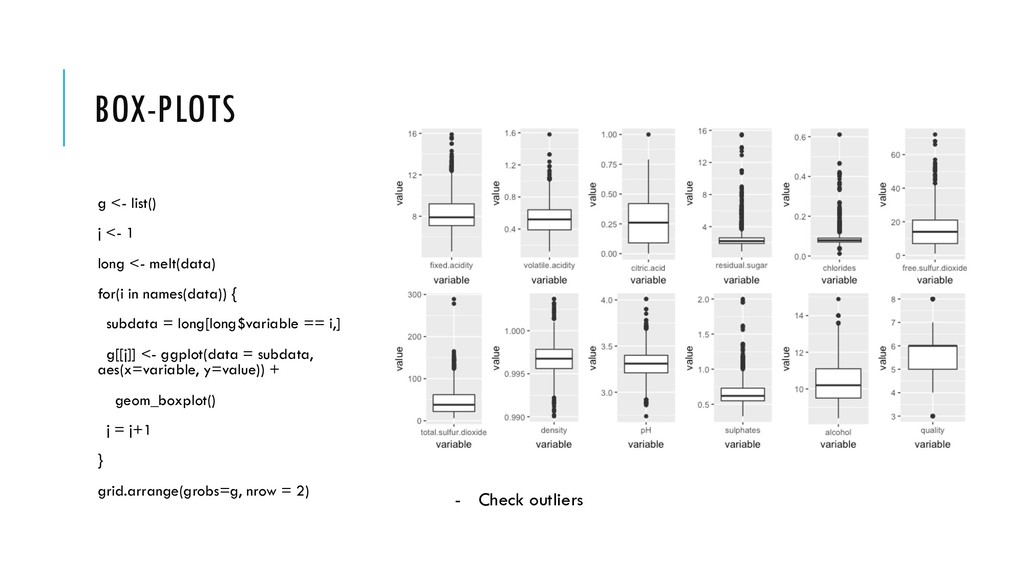
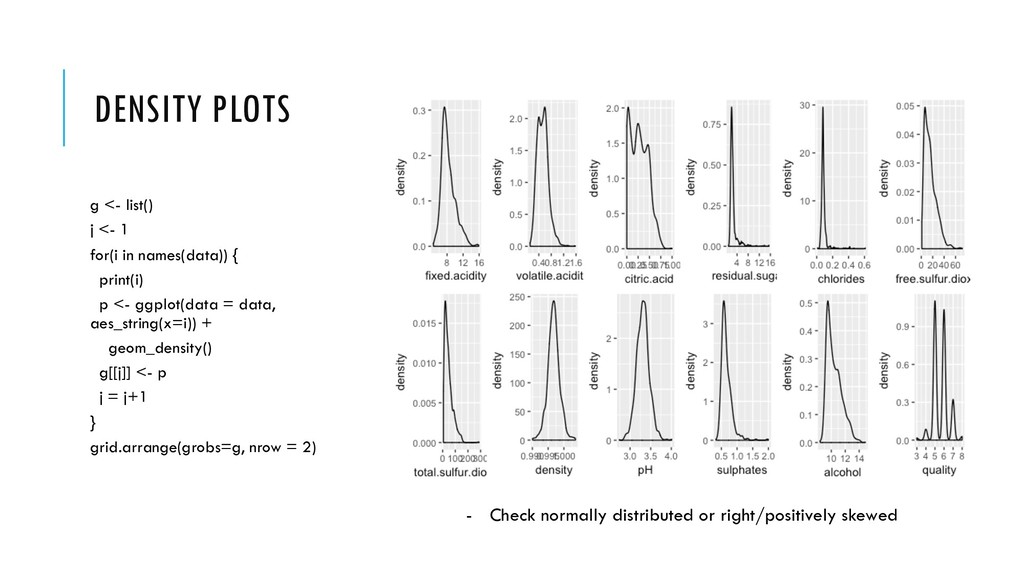
Exploratory Data Analysis refers to the critical process of performing initial investigations on data so as to discover patterns, to spot anomalies, to test hypothesis and to check assumptions with the help of summary statistics and graphical representations. • Do you see what you expect to see?
I read it OK? str(data) – Am I satisfied with the datatypes? dim(data) – Dataset size summary(data) – Summary statistics, missing values? table(data$quality) – Distribution of class variable
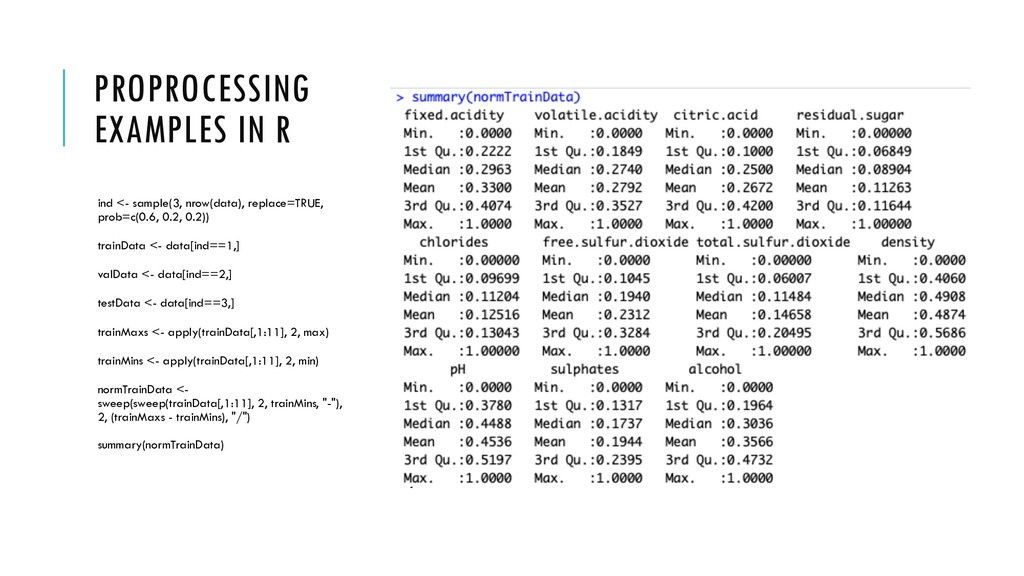
substituting values • Calculate statistics on training data, i.e. mean • Use this mean to replace missing data on both the validation and the testing datasets • Same for normalization or standardization • Normalization sensitive to outliers
ind <- sample(2, nrow(iris), replace=T, prob=c(0.9, 0.1)) trainData <- iris[ind==1,] valData <- iris[ind==2,] model <- naiveBayes(Species ~ ., data=trainData) pred <- predict(model, valData) results[i] <- Accuracy(pred, valData$Species) } • Even in this simple dataset and scenario….55/100 splits gave perfect score in one run. • With simple 10-fold cross-validation I could have gotten 100% validation accuracy. • In one run I got 70%...30% difference based on luck.
doing: If you work in a single dataset and you are in the industry, probably you go with the model that has the best metric in the validation data, backed by the testing data metric If you are doing research you can add statistical testing If you are building ML algorithms and you are comparing different algorithms on a whole lot of datasets, check J. Demsar’s 2006 JMLR paper (more than 7K citations)
• For a given confidence level, we will check whether the actual difference exceeds the confidence limit • Decide on a confidence level: 5% or 1% • Use Wilcoxon test • Other tests require more assumptions that are valid with large samples
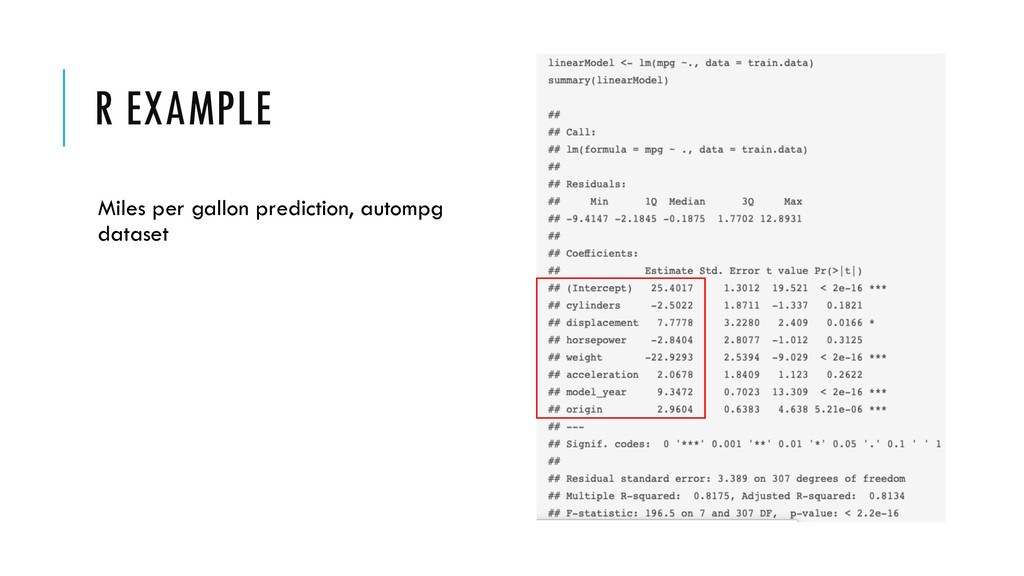
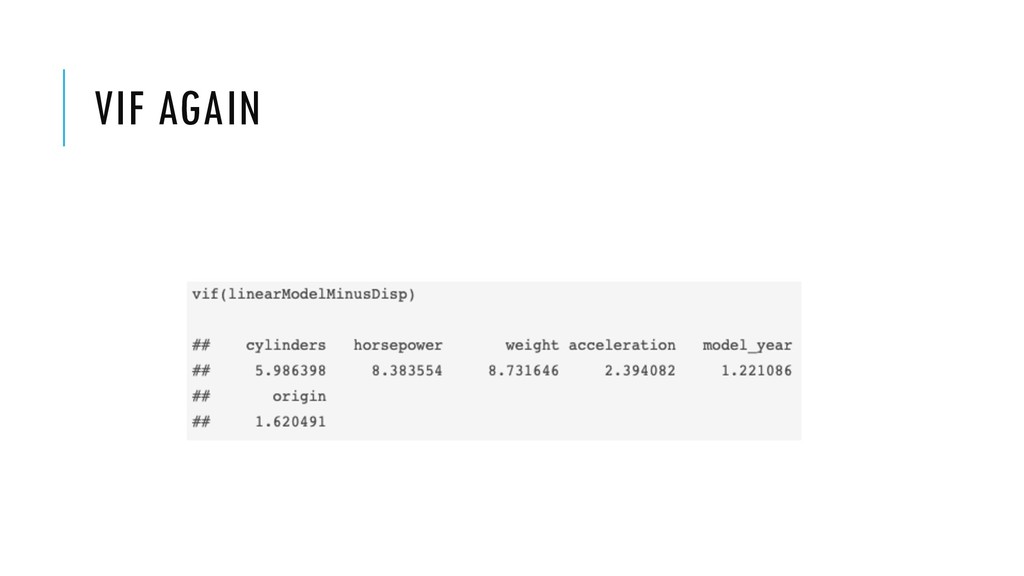
striving for. • (Multi)-Collinearity • X1 = a * X2 + b • Many different values of the features could predict equally well Y • Variance Inflation Factor (VIF) test • 1, no collinearity • >10, indication of collinearity • Discussed in: http://kyrcha.info/2019/03/22/on-collinearity-and-feature-selection
dataset (Fernandez-Delgado et al., JMLR, 2014) • Few important parameters to tune • Handles multiclass problems (unlike for example SVMs) • Can handle a mixture of features and scales
(Fernandez-Delgado et al., JMLR, 2014) - Robust theory behind it - Good for binary classification and 1-class classification We use it in Continuous Implicit Authentication - Can handle sparse data
hard to learn • If you have outliers, it will boost them to be the most important points • So have important outliers and not errors as outliers • Is more of a black-box, even though it is tree-based • Needs more tuning • Easy to overfit • Mostly better results that RF
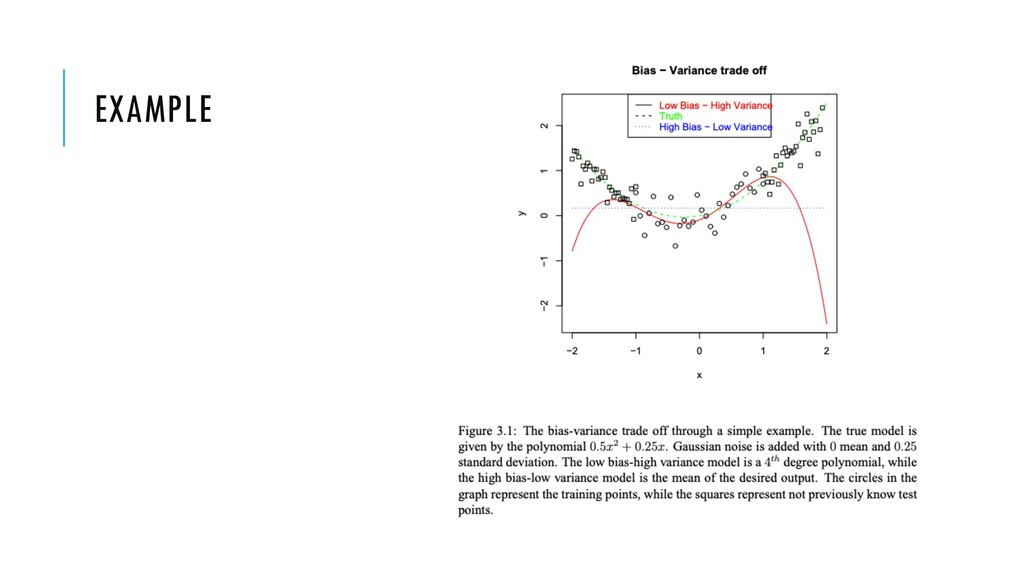
set. Erroneous assumptions in the learning algorithm. Variance: difference in error rate between training set and validation set. It is caused by overfitting to the training data and accounting for small fluctuations. Learning from Data slides: http://work.caltech.edu/telecourse.html
model size (more neurons/layers/trees/depth etc.) • Add more helpful features • Reduce/remove regularization (L2/L1/dropout) • Indifferent •Add more training data
•Add regularization •Early stopping (NN) •Remove features •Decrease model size (prefer regularization) • Usually big model to handle training data and then add regularization •Add more helpful features
be gained by parameter tuning (Bagnal and Crawley 2017) • Tons of parameters, we can’t tune them all • Understand how they influence training + read relevant papers/walkthroughs • Random forests (Fernandez-Delgado et al., JMLR, 2014) • mtry: Number of variables randomly sampled as candidates at each split. • SVM (Fernandez-Delgado et al., JMLR, 2014) • tuning the regularization and kernel spread
internet and the years • ML Yearning: https://www.mlyearning.org/ • Machine Learning from Data course: http://work.caltech.edu/telecourse.html • Practical Machine Learning with H2O book
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PROPROCESSING EXAMPLES IN R normValData <- sweep(sweep(valData[,1:11], 2, trainMins, "-"),](https://files.speakerdeck.com/presentations/588f7cad5c08434bb71ff3c74811695f/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}