de Montreal (P.I. Yoshua Bengio) Research Intern, CUHK (P.I. Xiaogang Wang) CTO / Co-Founder, Nota B.S. Bio and Brain Engineering, KAIST M.S. Electrical Engineering, KAIST 08' 13' 15' 15' 17' Ph.D. (ABD) Electrical Engineering, KAIST 15' CEO / Co-Founder, Nota 14' 20'
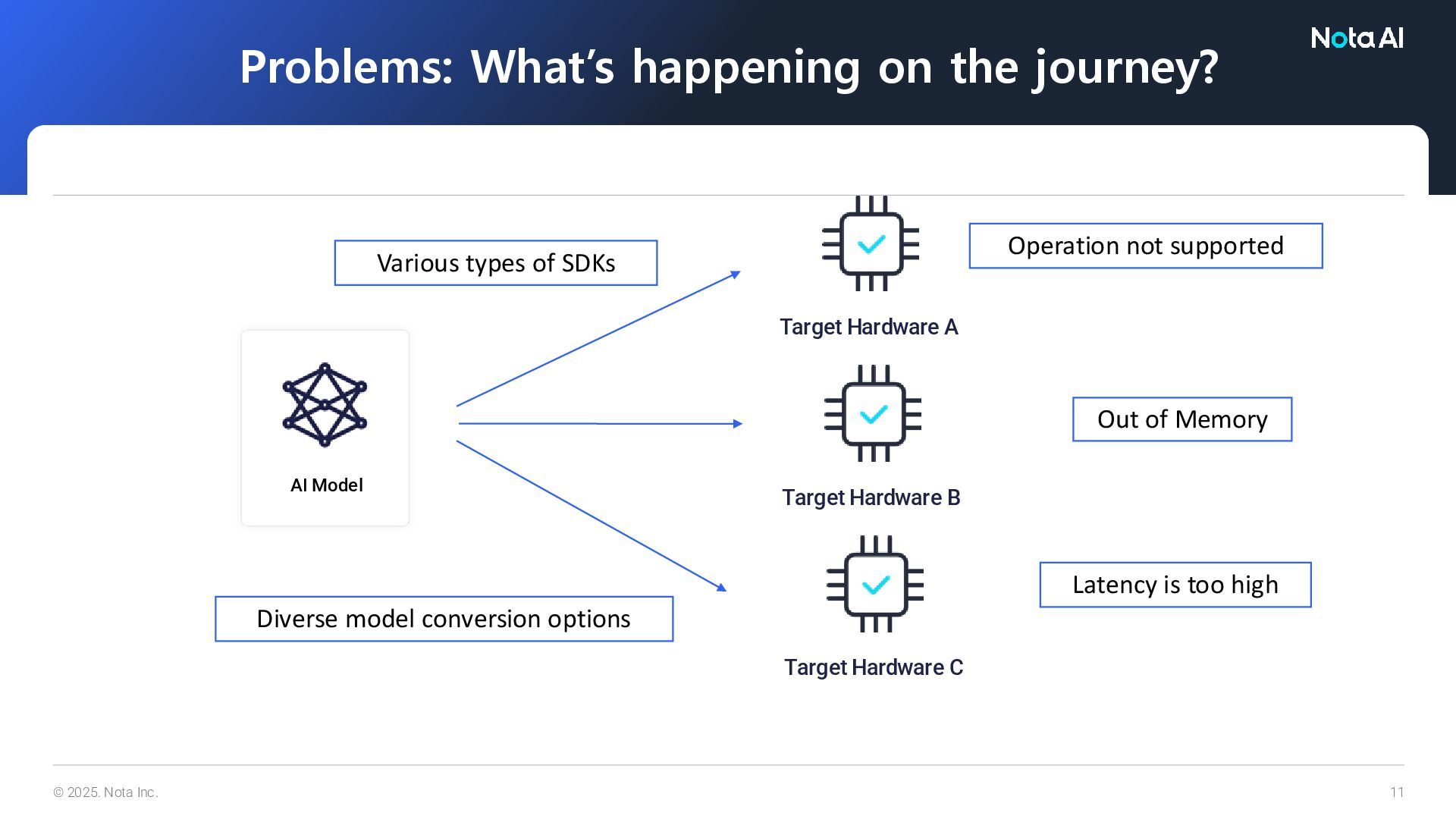
journey? Diverse model conversion options Out of Memory Operation not supported Latency is too high Various types of SDKs AI Model Target Hardware A Target Hardware B Target Hardware C
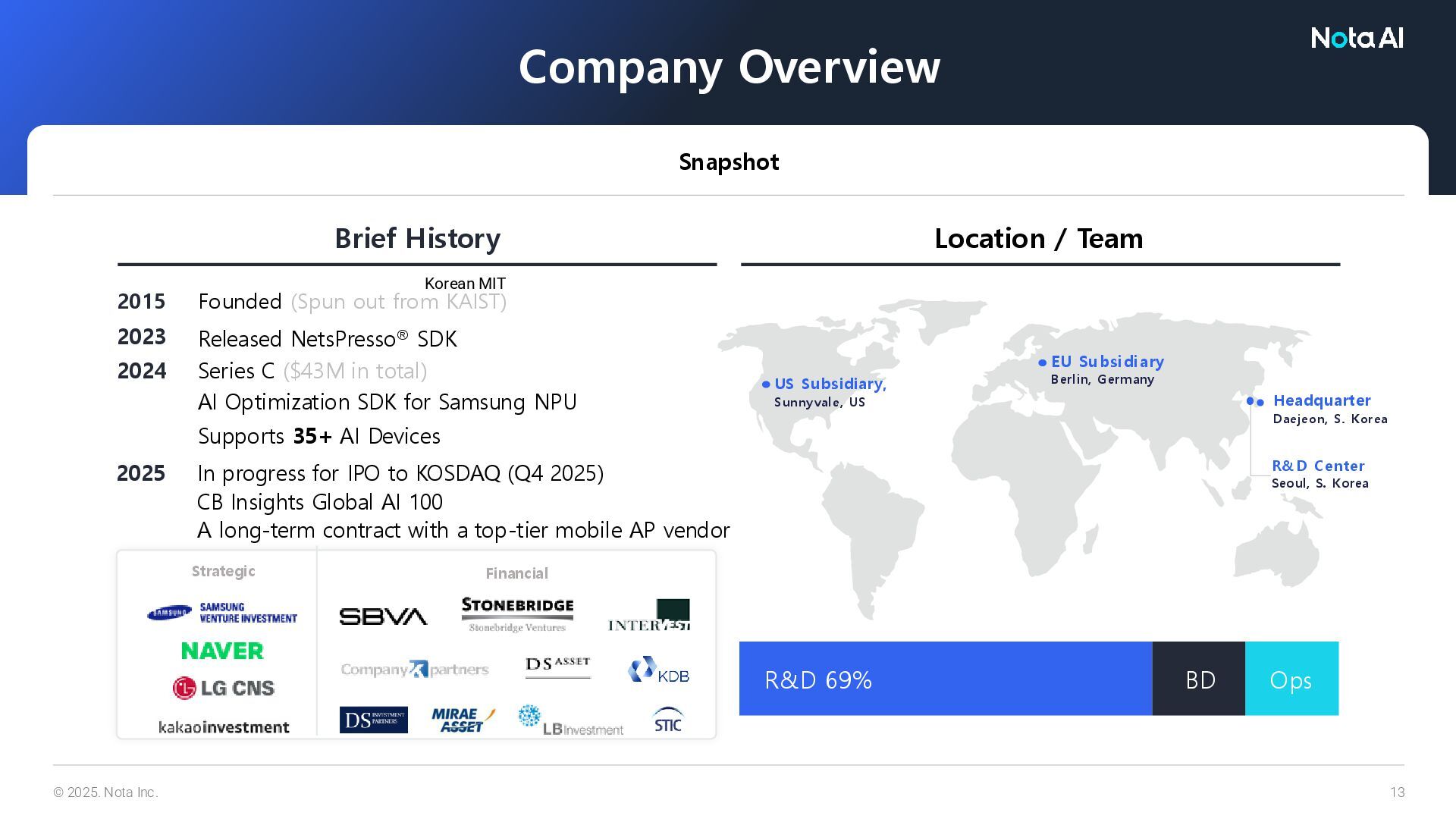
AI Optimization SDK for Samsung NPU Supports 35+ AI Devices Founded (Spun out from KAIST) Released NetsPresso® SDK Brief History 2024 2015 2023 Strategic Financial Location / Team Company Overview Snapshot EU Subsidiary Berlin, Germany Headquarter Daejeon, S. Korea R&D Center Seoul, S. Korea US Subsidiary, Sunnyvale, US R&D 69% BD Ops In progress for IPO to KOSDAQ (Q4 2025) CB Insights Global AI 100 A long-term contract with a top-tier mobile AP vendor 2025 Korean MIT
2025 AI 100 by CB Insights • Recognized for its cutting- edge AI technology and transformative impact. • Being named by CB Insights as one of the top 100 most promising private AI companies in 2025 is a significant achievement and a strong indicator of its innovation and potential in the accelerated computing and hardware space, particularly within AI infrastructure at the edge.
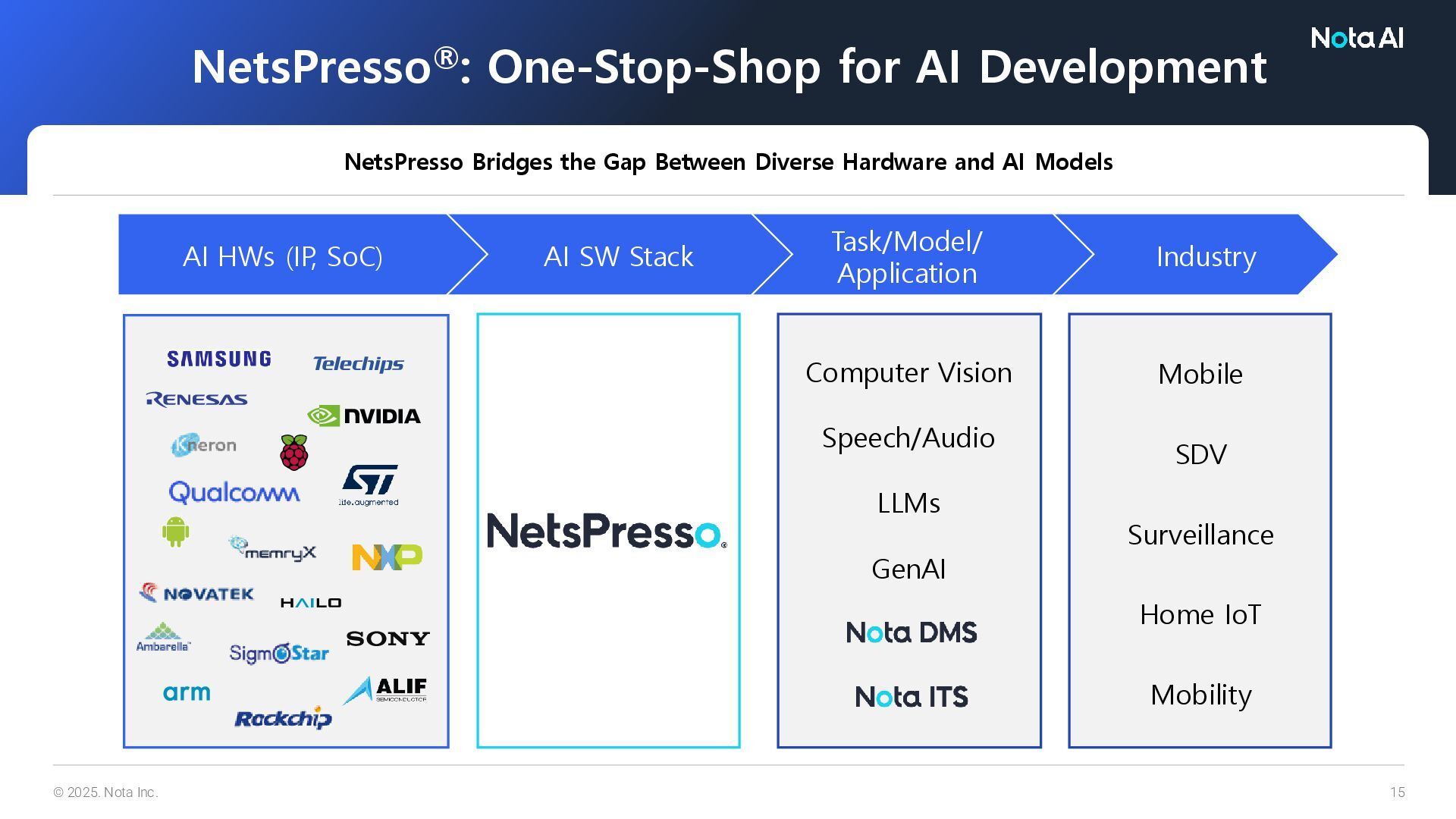
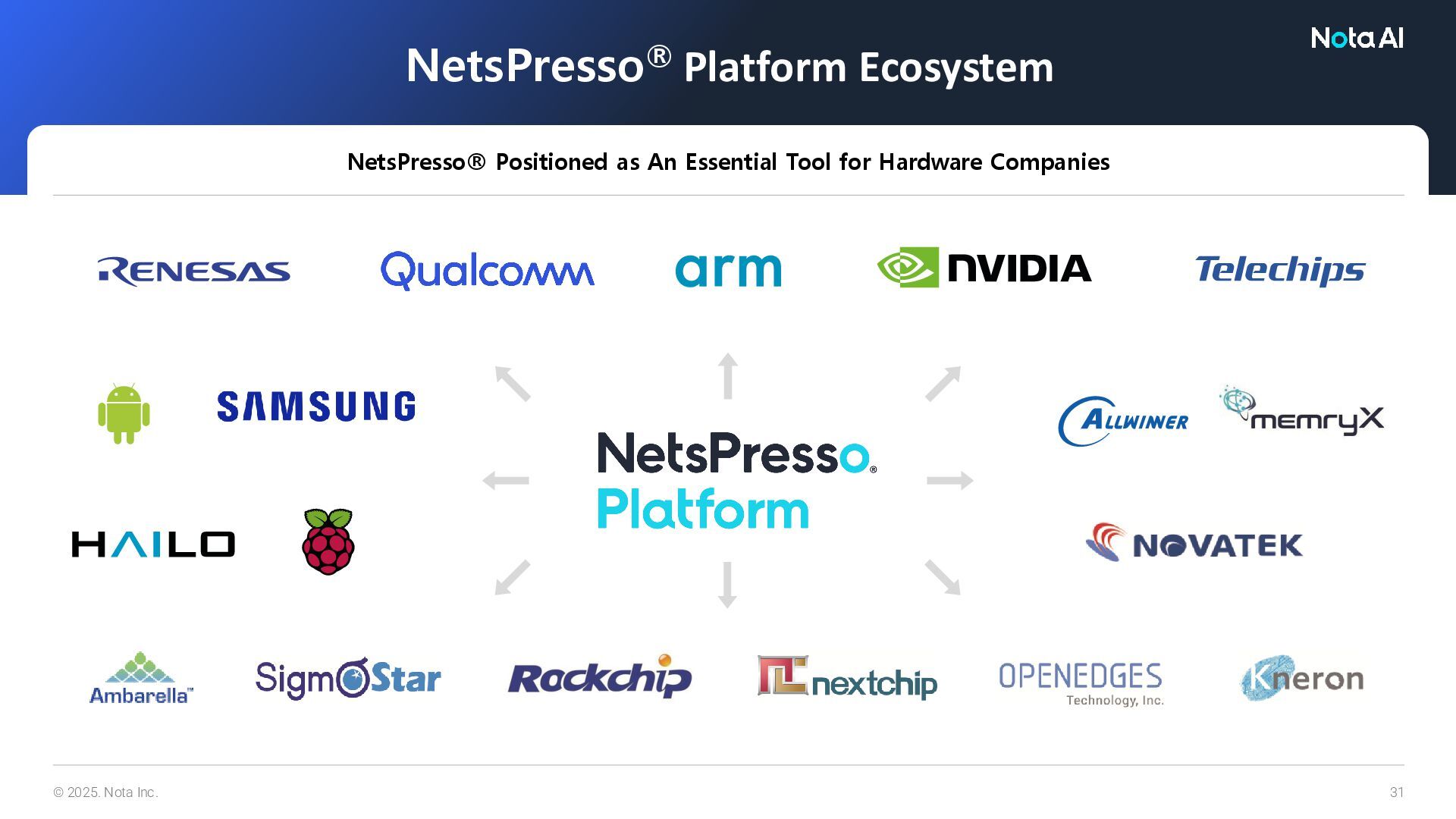
NetsPresso Bridges the Gap Between Diverse Hardware and AI Models AI HWs (IP, SoC) AI SW Stack Industry SDV Mobile Surveillance Home IoT Task/Model/ Application Mobility Computer Vision Speech/Audio LLMs GenAI
Accelerates Edge AI Development Process Platform • Type: Traffic accident • Percentage: 80% • Emergency Level: 4 (Serious) • Possibility of second accident: 20% • Expected level of traffic congestion: 5 (Very serious) • Immediate action: Slow down, move over, and give right of way to emergency vehicles. • Variable message sign: "Accident ahead, slow down and be cautious." • Summary: A traffic accident occurred on the road, causing traffic congestion and the need for immediate attention to clear the incident and ensure road safety. Accident Alert Type Message …
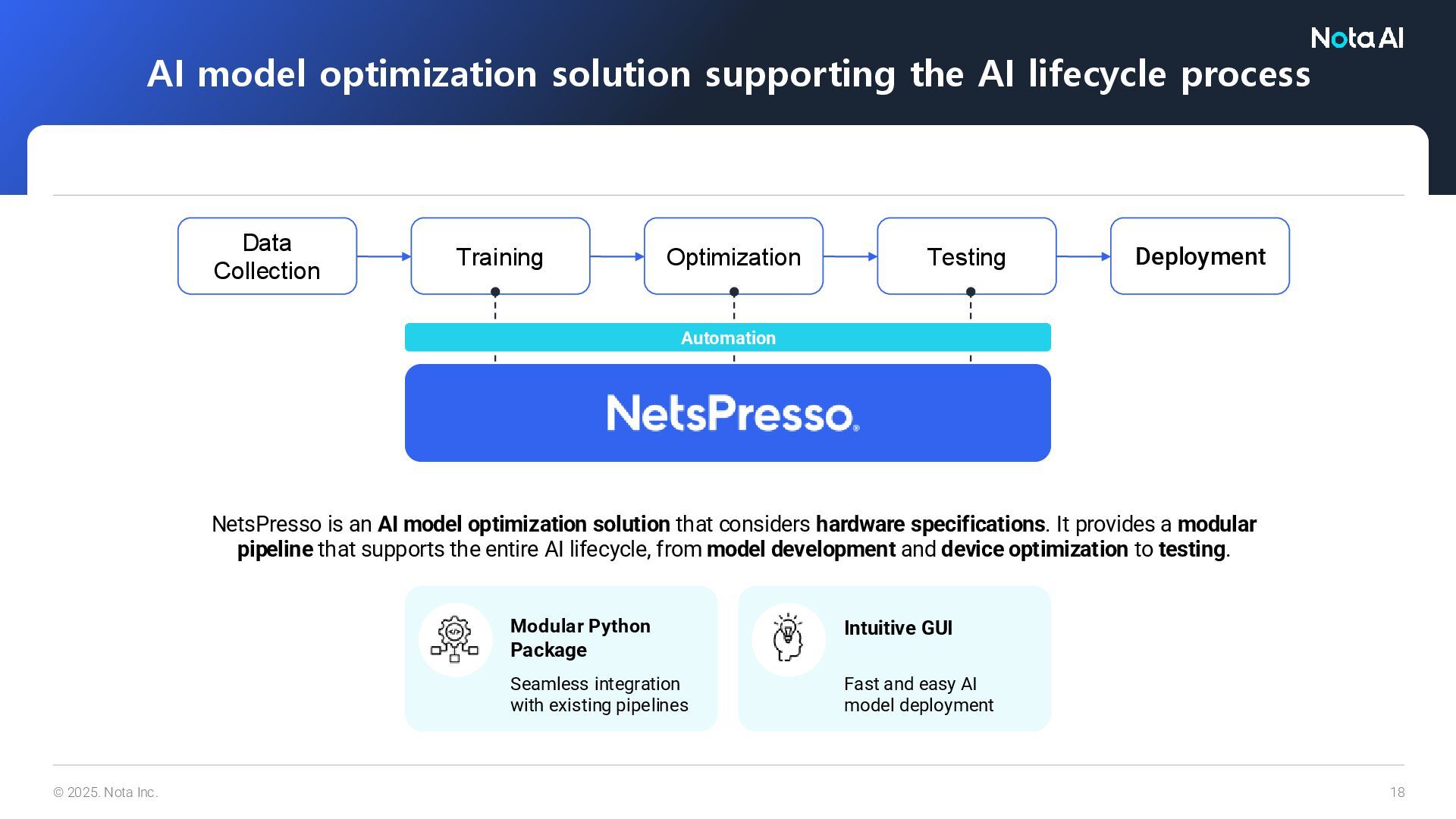
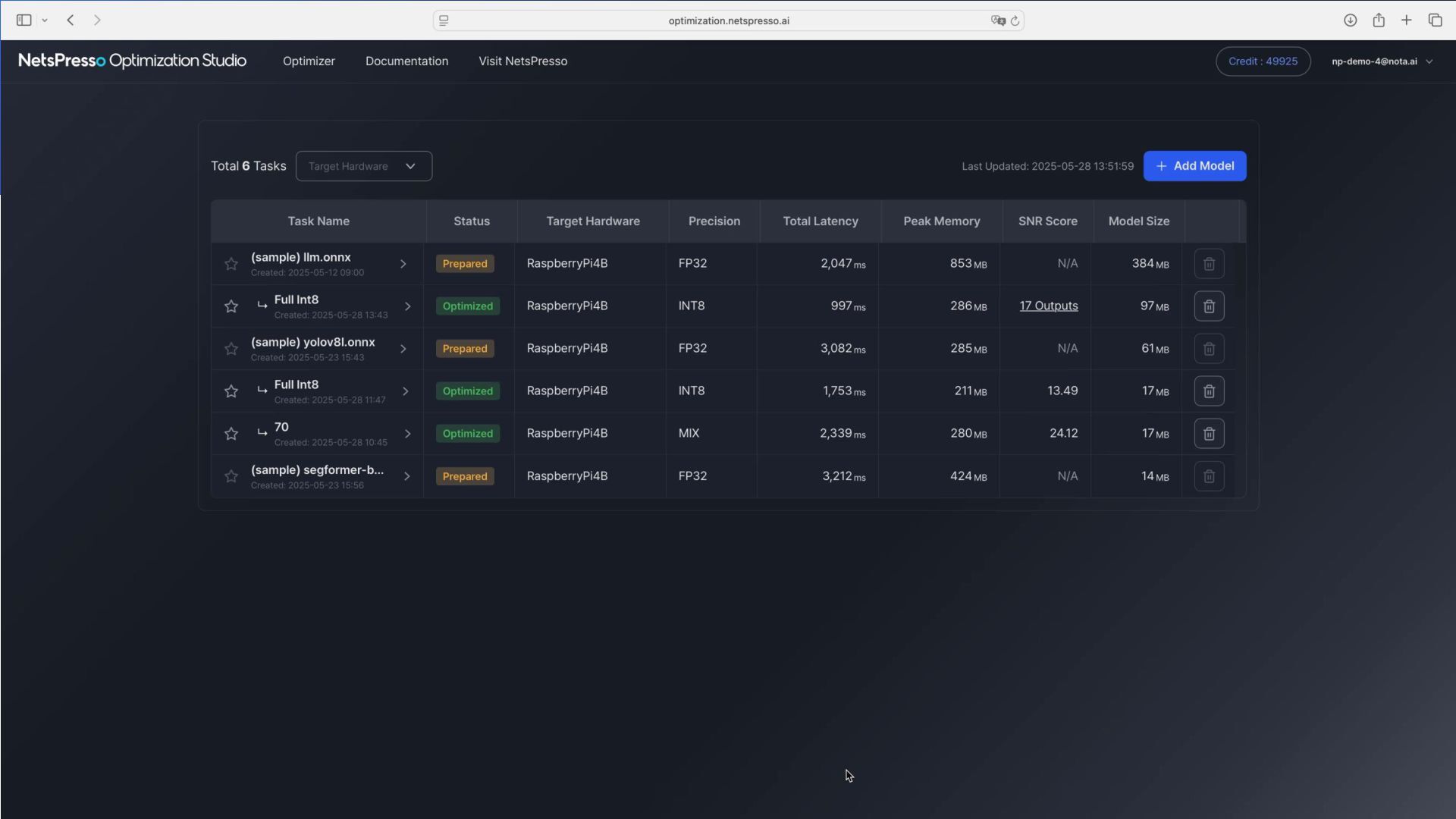
Testing NetsPresso is an AI model optimization solution that considers hardware specifications. It provides a modular pipeline that supports the entire AI lifecycle, from model development and device optimization to testing. AI model optimization solution supporting the AI lifecycle process Automation Modular Python Package Seamless integration with existing pipelines Intuitive GUI Fast and easy AI model deployment
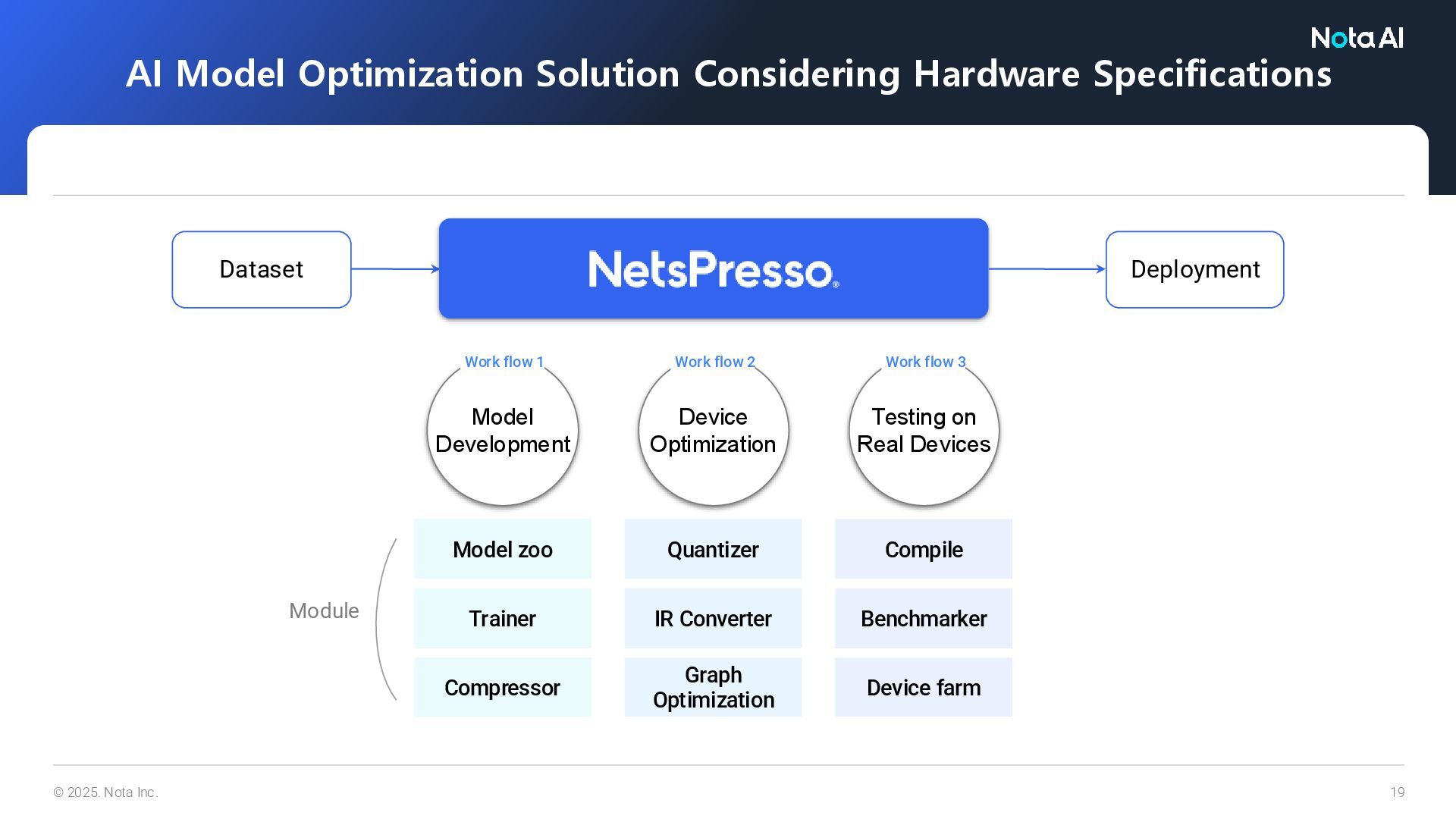
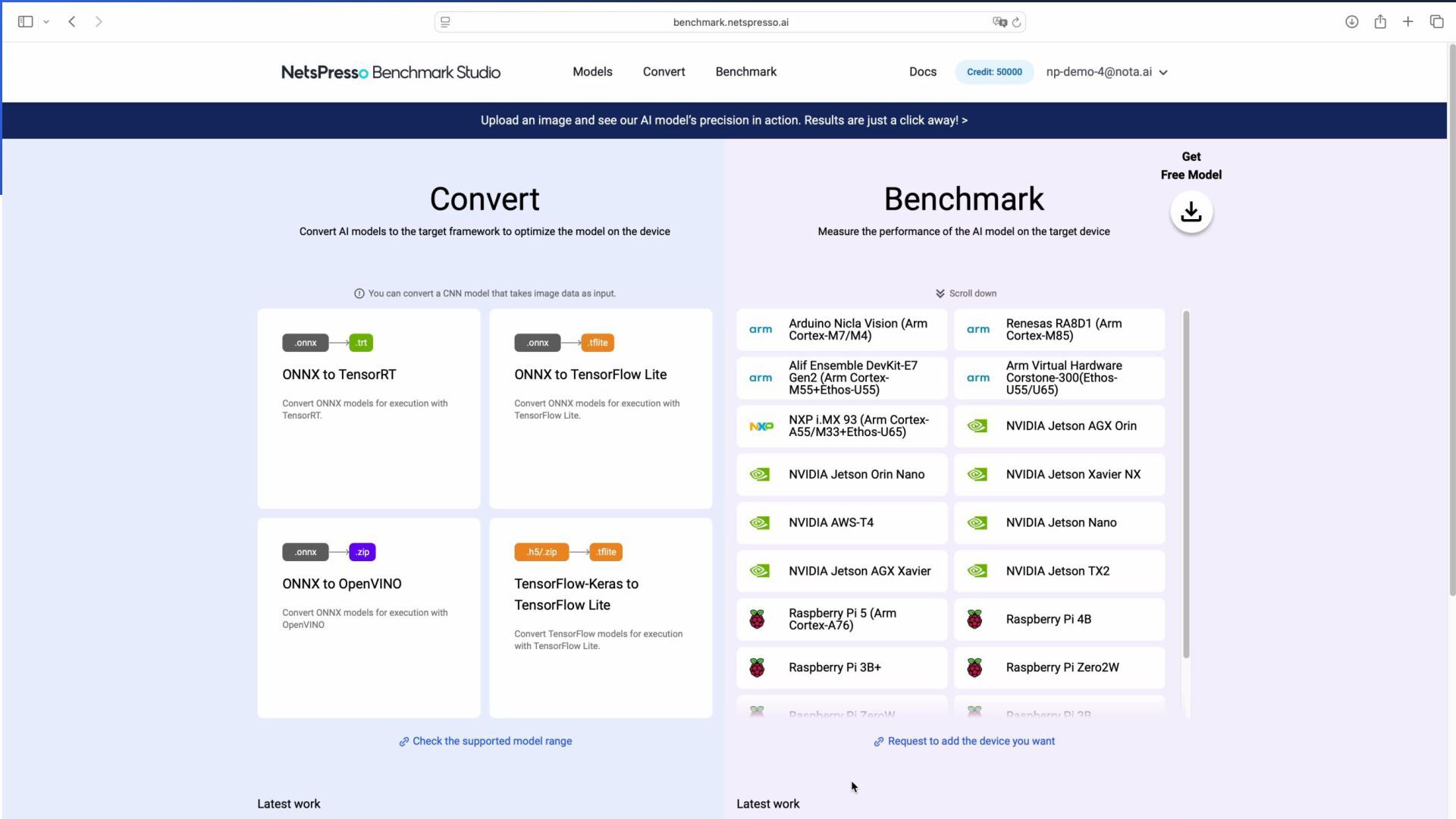
Optimization Solution Considering Hardware Specifications Model zoo Work flow 1 Model Development Trainer Compressor Work flow 2 Device Optimization Quantizer IR Converter Graph Optimization Work flow 3 Testing on Real Devices Compile Benchmarker Device farm
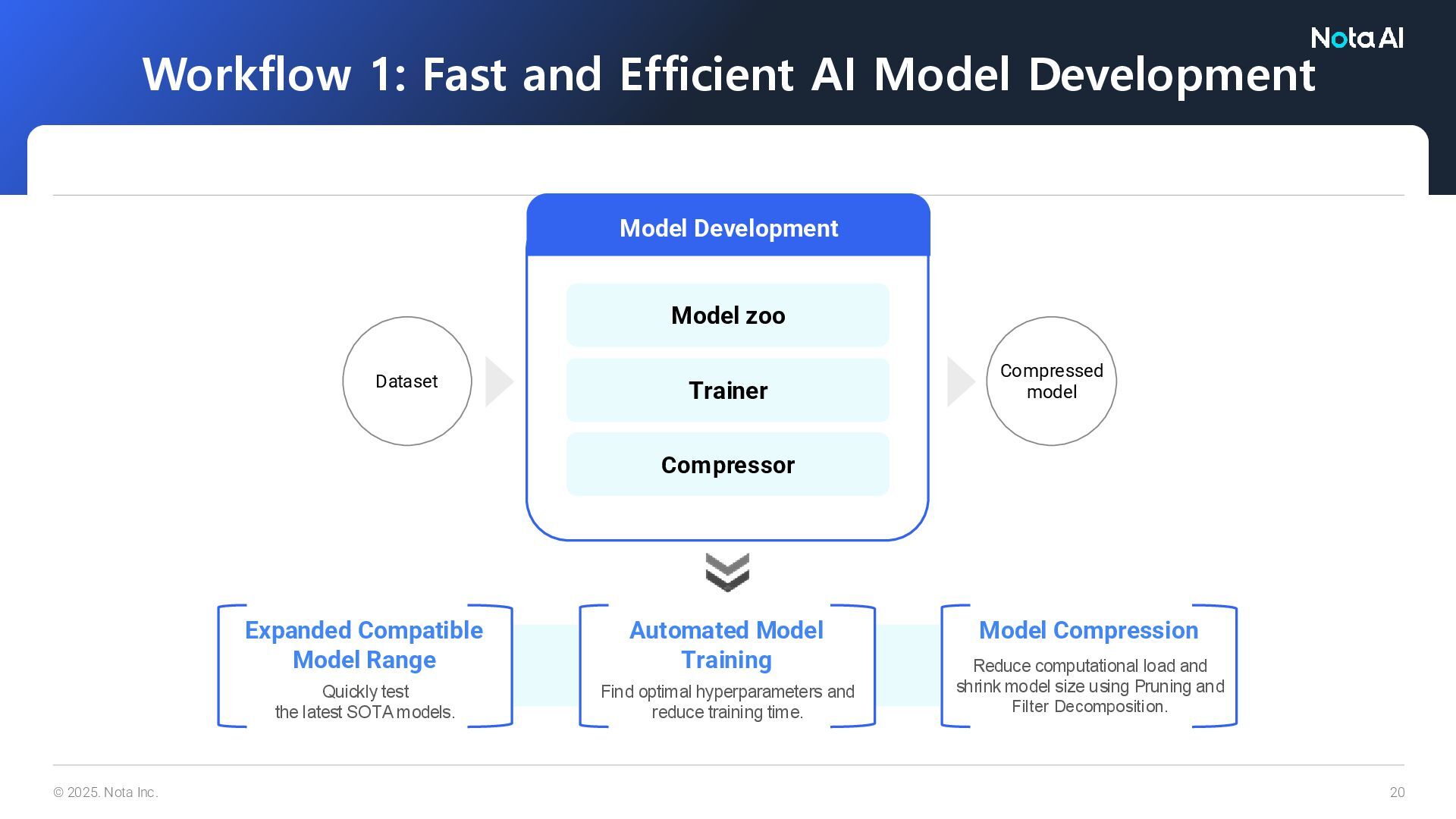
Workflow 1: Fast and Efficient AI Model Development Model Development Compressed model Expanded Compatible Model Range Quickly test the latest SOTA models. Automated Model Training Find optimal hyperparameters and reduce training time. Model Compression Reduce computational load and shrink model size using Pruning and Filter Decomposition.
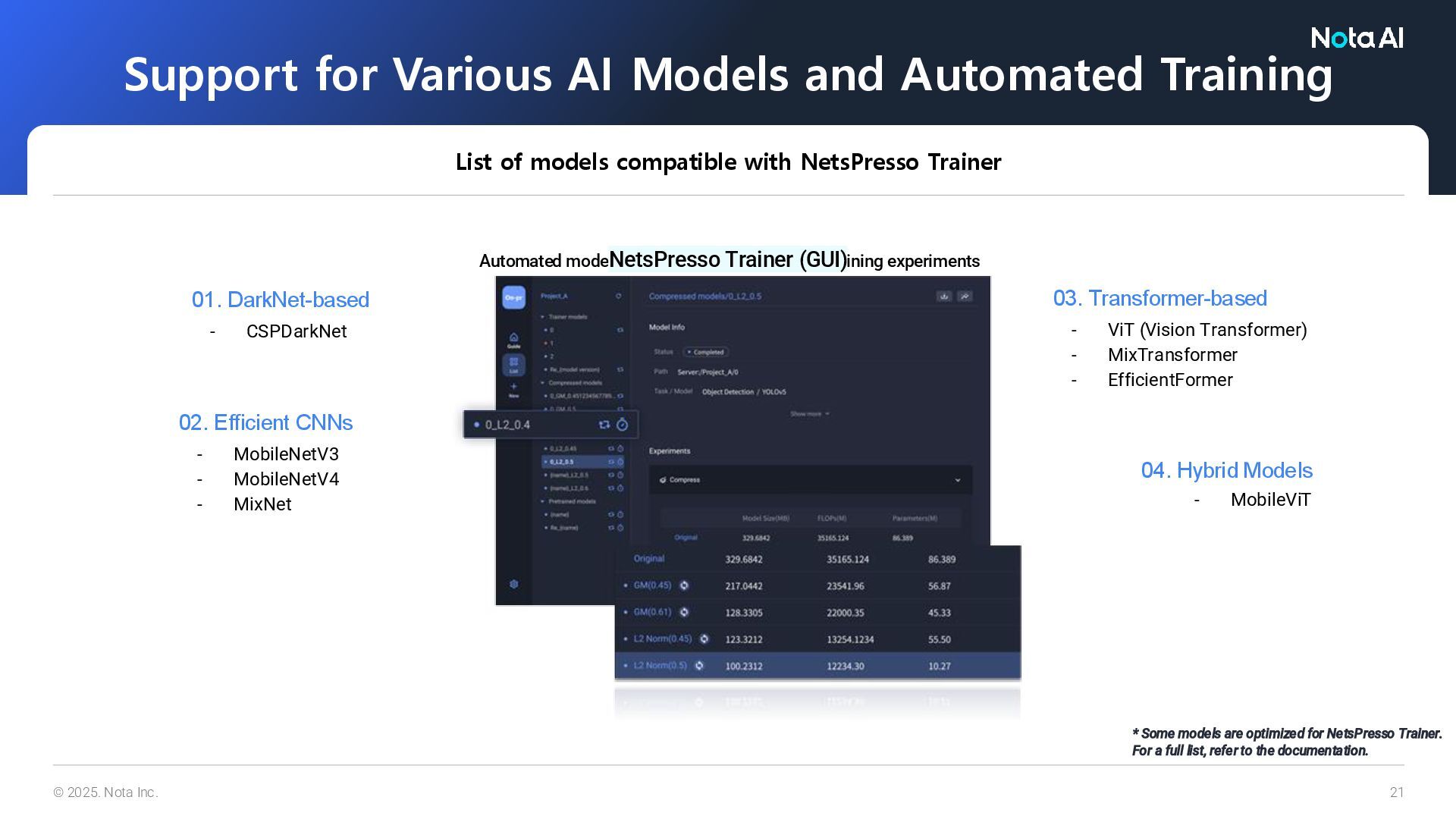
Efficient CNNs - MobileNetV3 - MobileNetV4 - MixNet Support for Various AI Models and Automated Training List of models compatible with NetsPresso Trainer * Some models are optimized for NetsPresso Trainer. For a full list, refer to the documentation. Automated model training and visualization of training experiments 04. Hybrid Models - MobileViT 03. Transformer-based - ViT (Vision Transformer) - MixTransformer - EfficientFormer NetsPresso Trainer (GUI)
Compression Results ▪ Measured on QCS6490 ▪ Input Resolution: 224 x 224 input shape ▪ Latency reduced by 80.98% ▪ Accepted at ECCV 2024: https://arxiv.org/abs/2404.11630 * The smaller the value, the faster the inference speed ▪ Measured on Snapdragon Gen3 ▪ Input Resolution: 512 x 512 ▪ Latency reduced by 81.59% ▪ All operations run on the NPU AI Acceleration Benefits Using NetsPresso 371.7 70.7 -80.98% Image Classification (DeiT) 101.6 18.7 -81.59% Semantic Segmentation (SegFormer-b0)
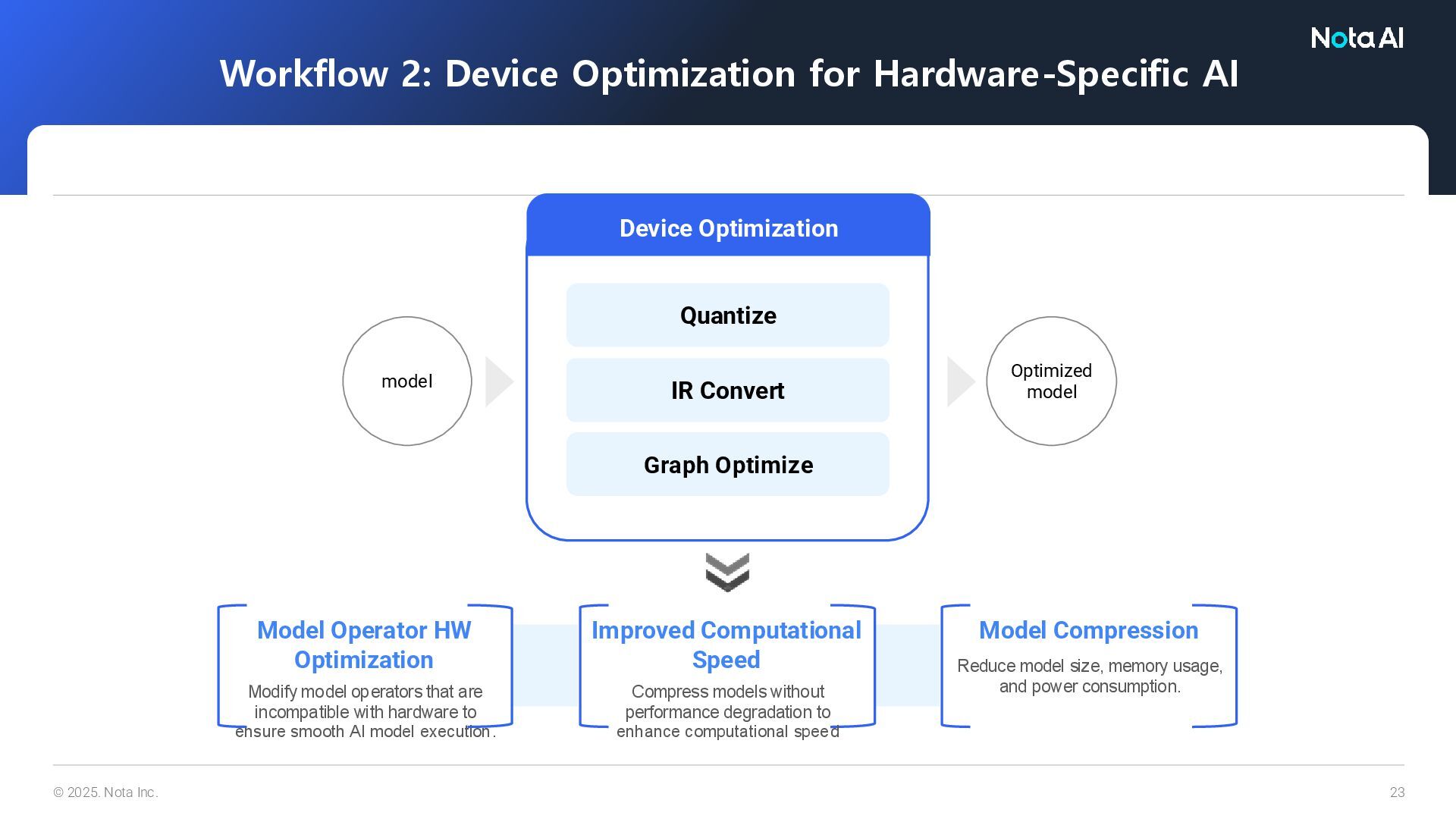
Optimize Workflow 2: Device Optimization for Hardware-Specific AI Device Optimization Optimized model Model Operator HW Optimization Modify model operators that are incompatible with hardware to ensure smooth AI model execution. Improved Computational Speed Compress models without performance degradation to enhance computational speed Model Compression Reduce model size, memory usage, and power consumption.
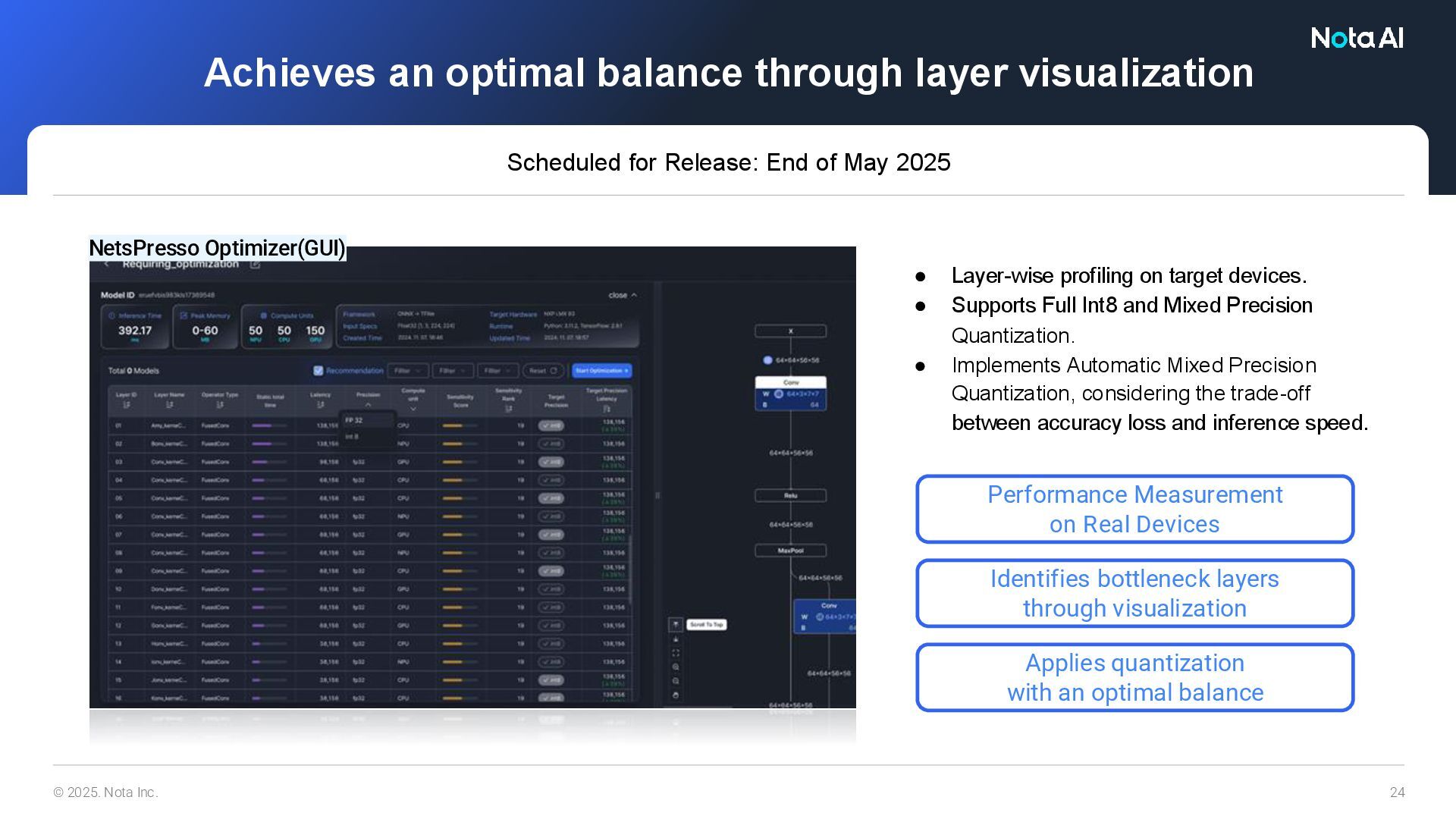
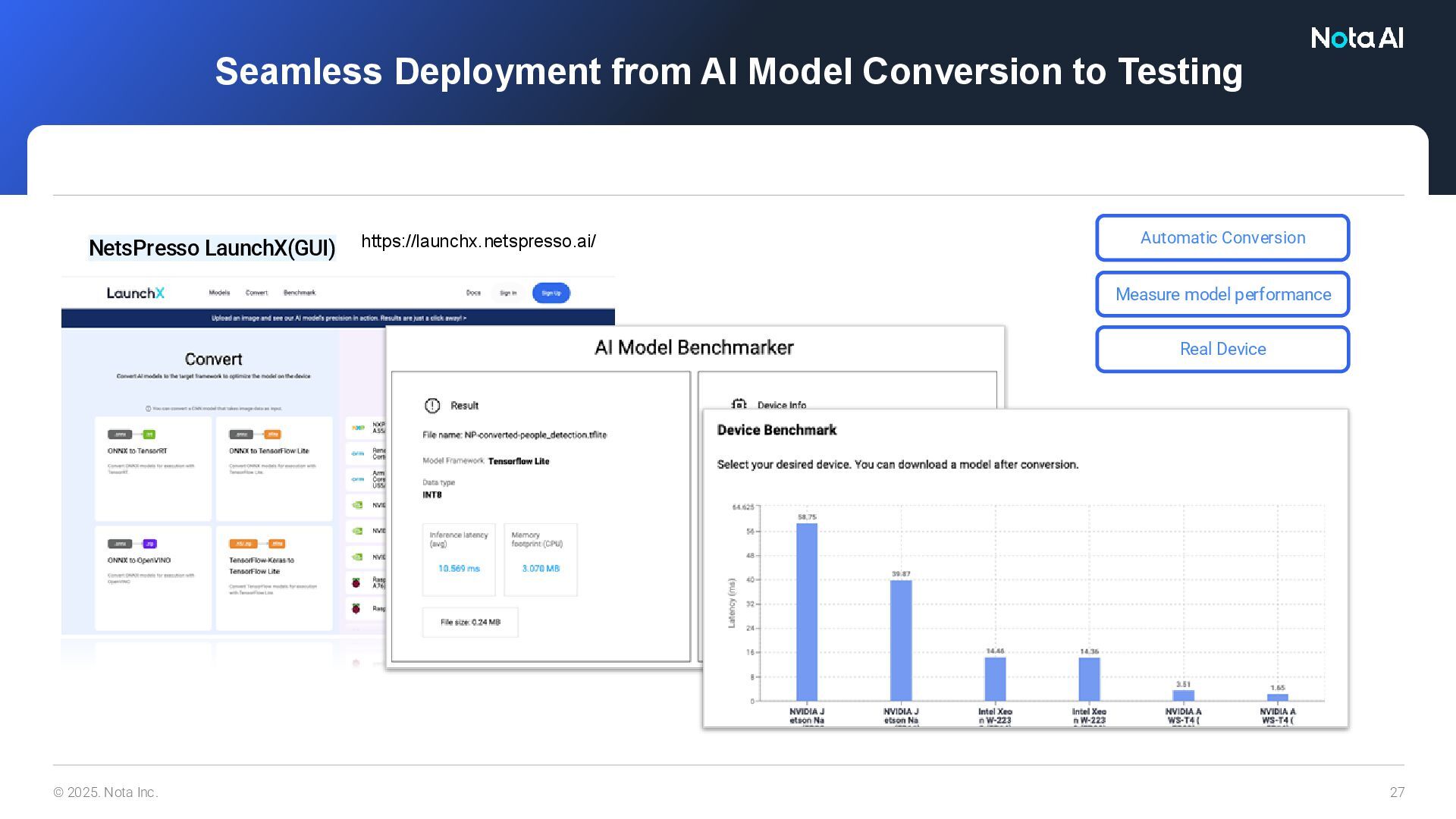
devices. • Supports Full Int8 and Mixed Precision Quantization. • Implements Automatic Mixed Precision Quantization, considering the trade-off between accuracy loss and inference speed. Applies quantization with an optimal balance Performance Measurement on Real Devices Identifies bottleneck layers through visualization Achieves an optimal balance through layer visualization Scheduled for Release: End of May 2025 NetsPresso Optimizer(GUI)
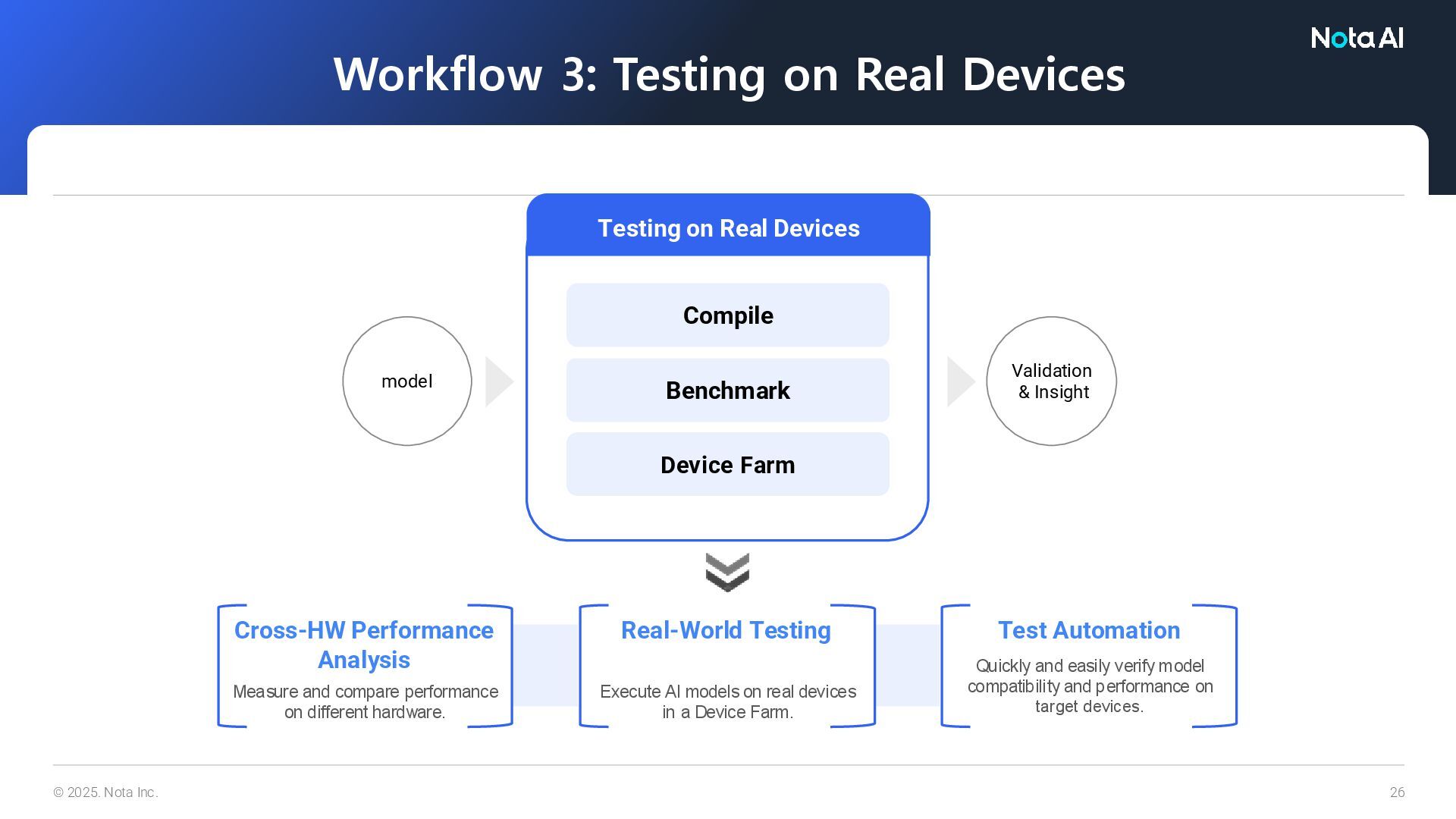
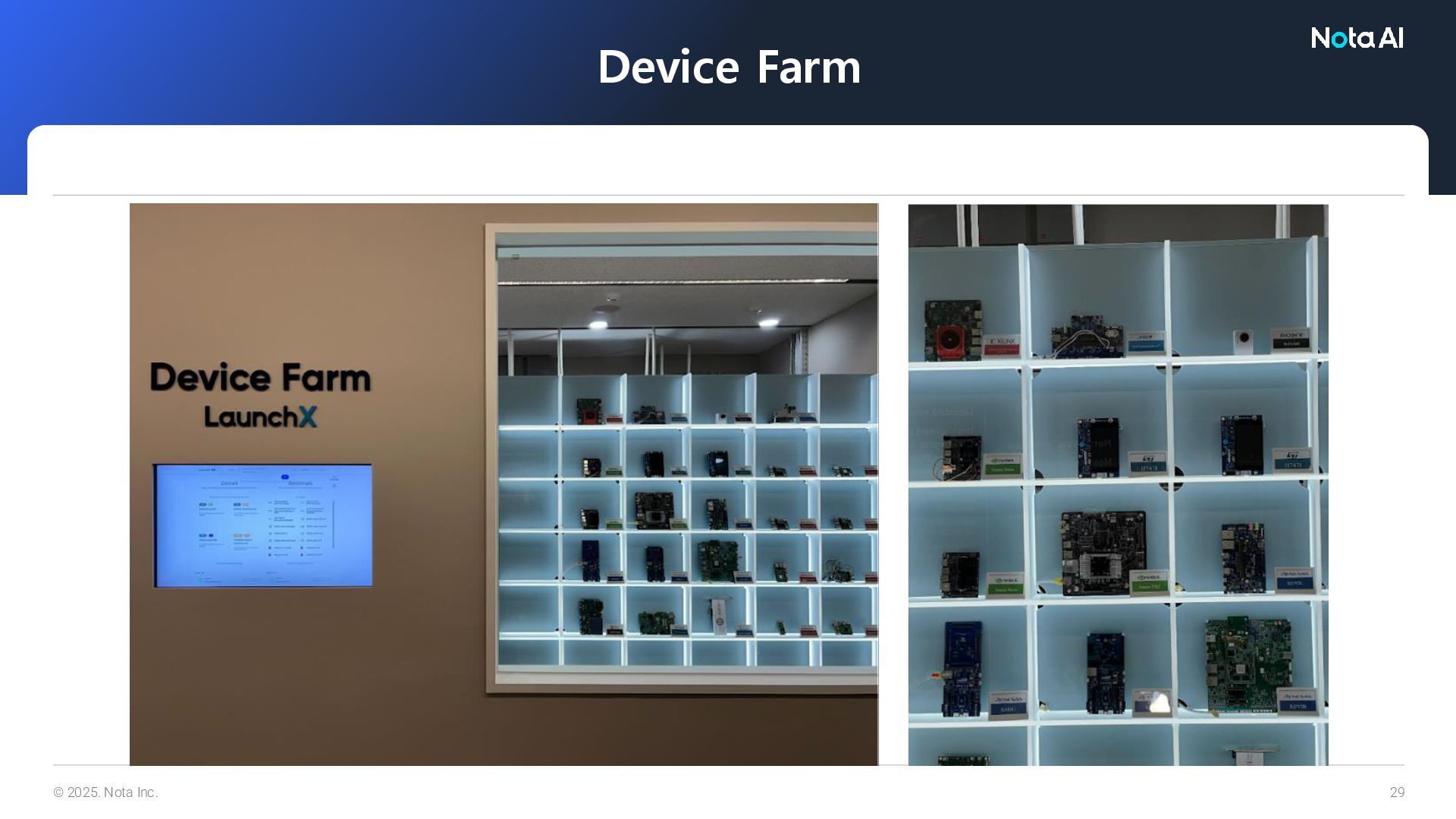
Workflow 3: Testing on Real Devices Testing on Real Devices Validation & Insight Cross-HW Performance Analysis Measure and compare performance on different hardware. Real-World Testing Execute AI models on real devices in a Device Farm. Test Automation Quickly and easily verify model compatibility and performance on target devices.
AI 불가능 생성형 AI 4.47 ms 최적화 이미지 생성 1885.8 ms 이미지 생성 738.5 ms 2.4x 가속 회사 Without Nota AI With Nota AI Transformer Model 101.6 ms 5.4x 가속 Transformer Model 18.7 ms Transformer Model 3.93 ms 5.4x 가속 Transformer Model 0.73 ms ViT Model 불가능 최적화 ViT Model 가능 Transformer Model 2.09 ms 5.2x 가속 Transformer Model 0.40 ms * Measured on Qualcomm Snapdragon 8 Gen 3, Arm Ethos-U55, Renesas RZ/V2L, and NXP i.MX 93 respectively.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}