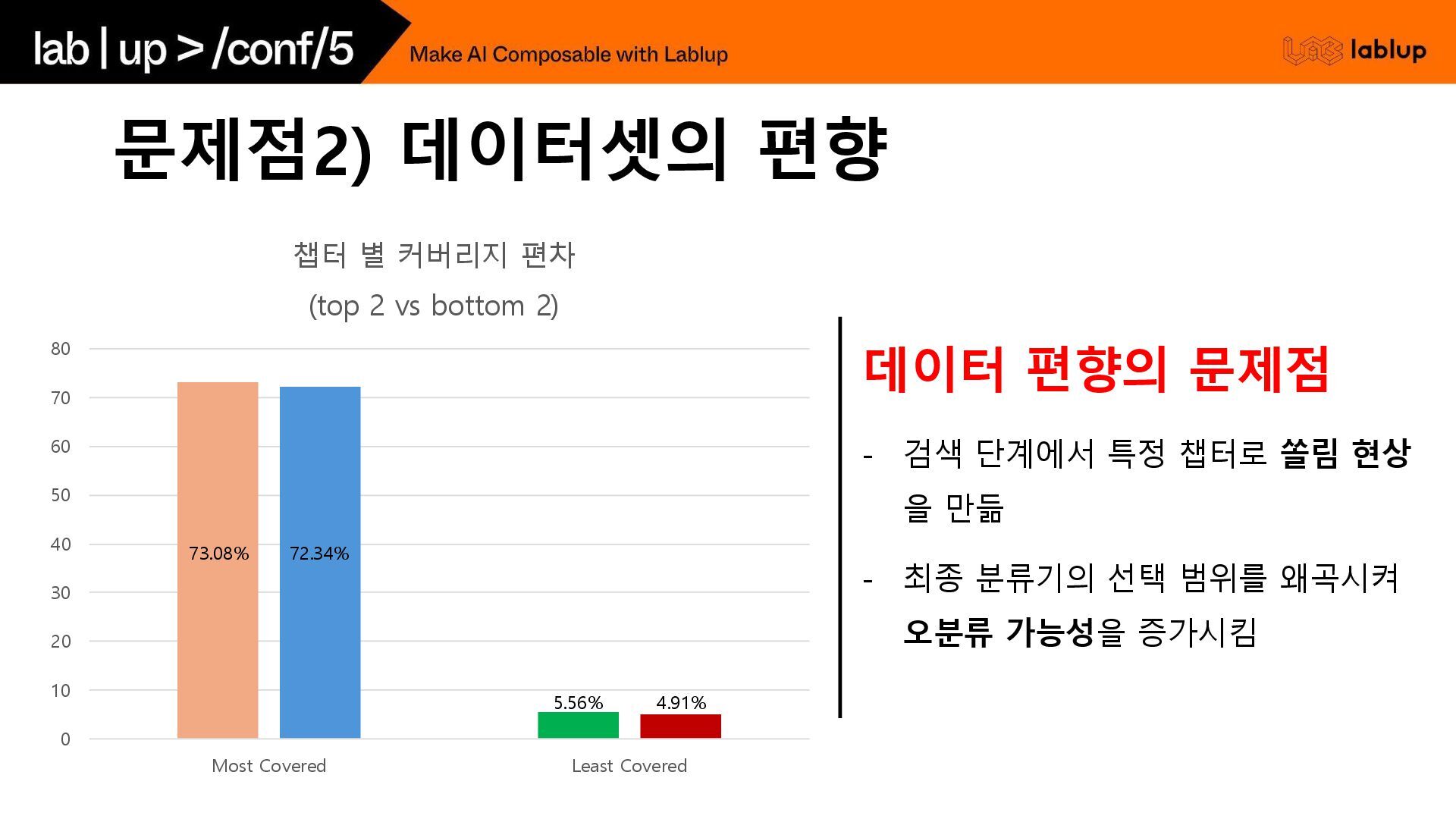
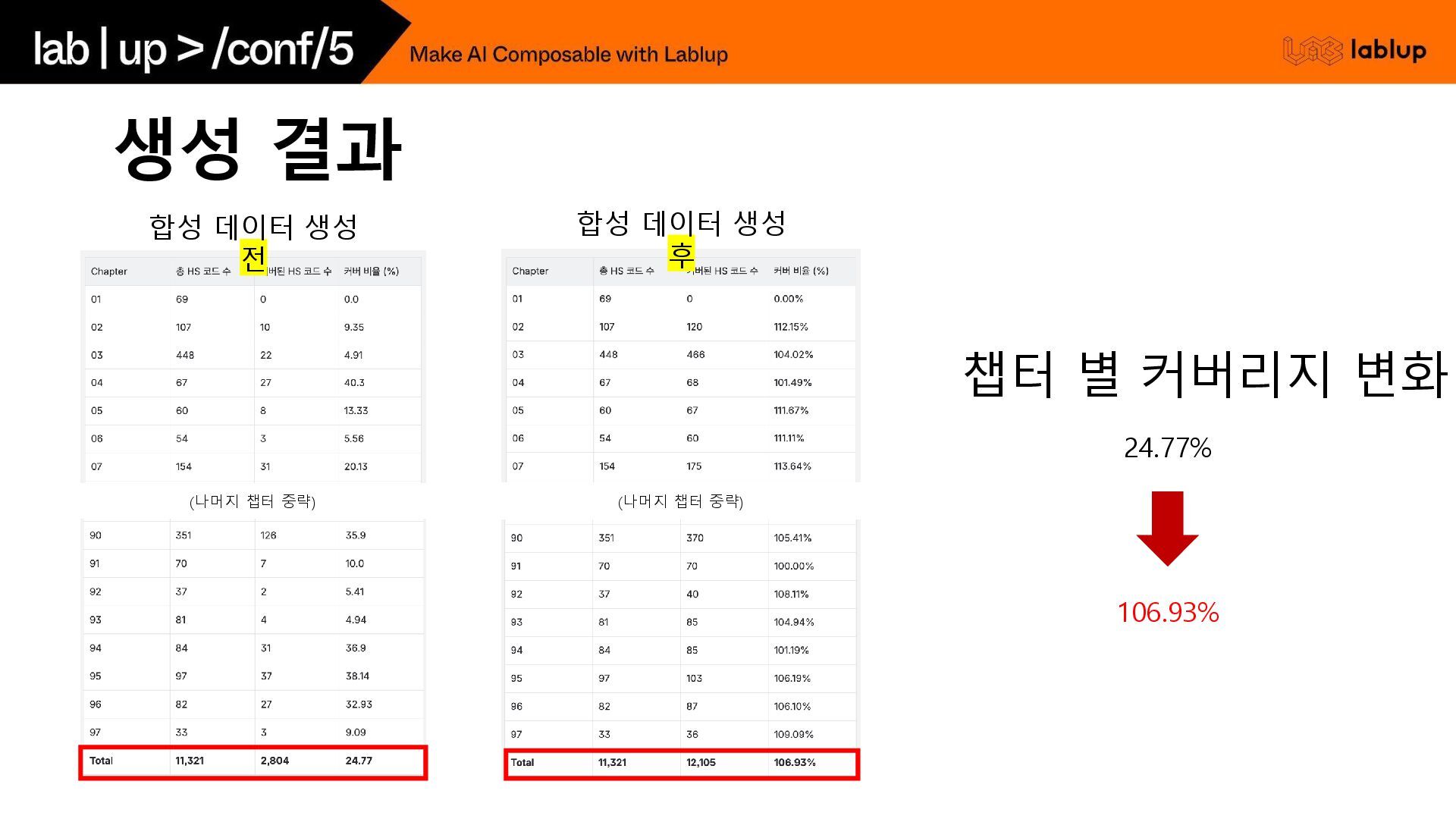
챕터로 쏠림 현상 을 만듦 - 최종 분류기의 선택 범위를 왜곡시켜 오분류 가능성을 증가시킴 0 10 20 30 40 50 60 70 80 Most Covered Least Covered 챕터 별 커버리지 편차 (top 2 vs bottom 2) 5.56% 4.91% 72.34% 73.08%
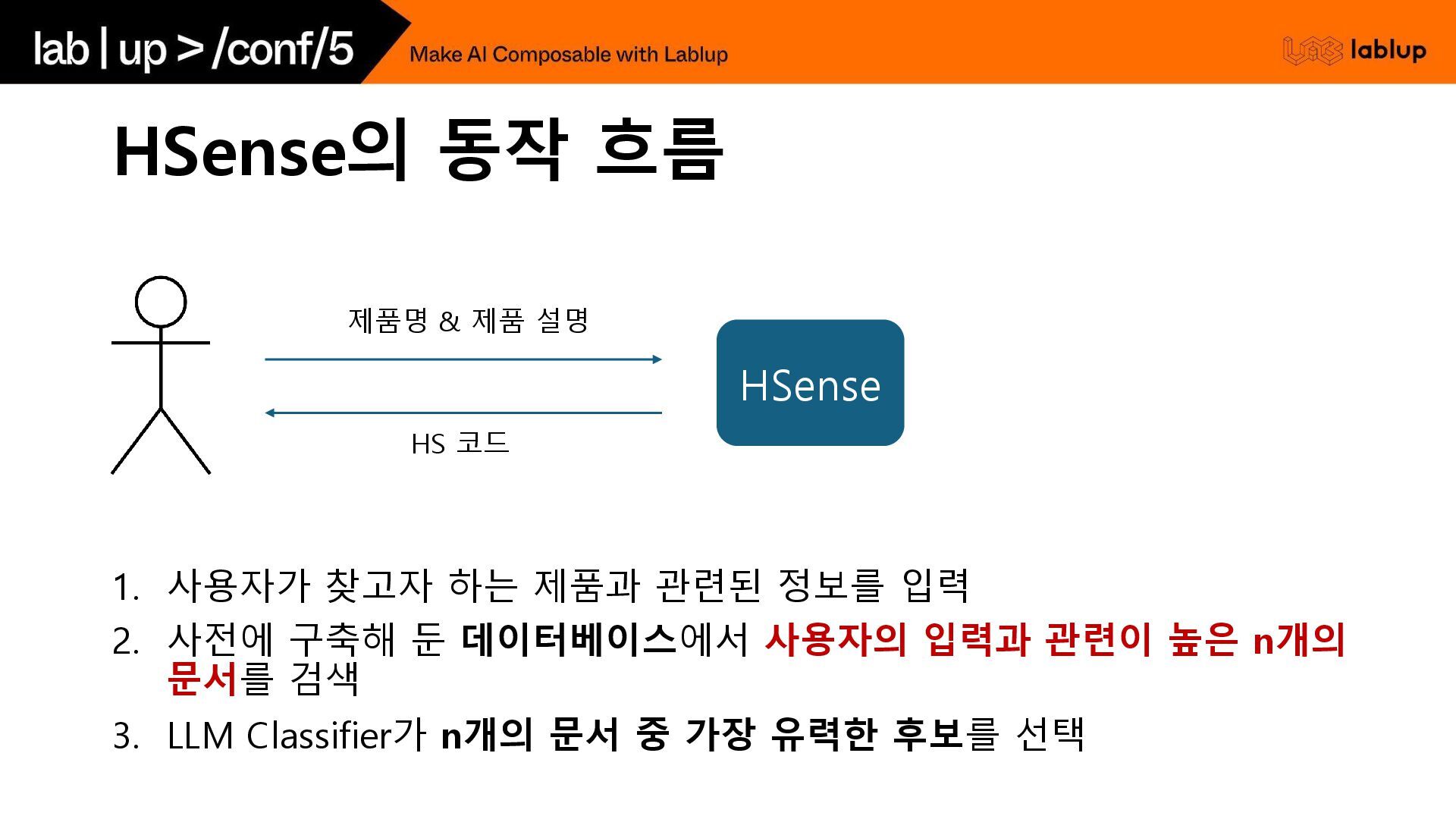
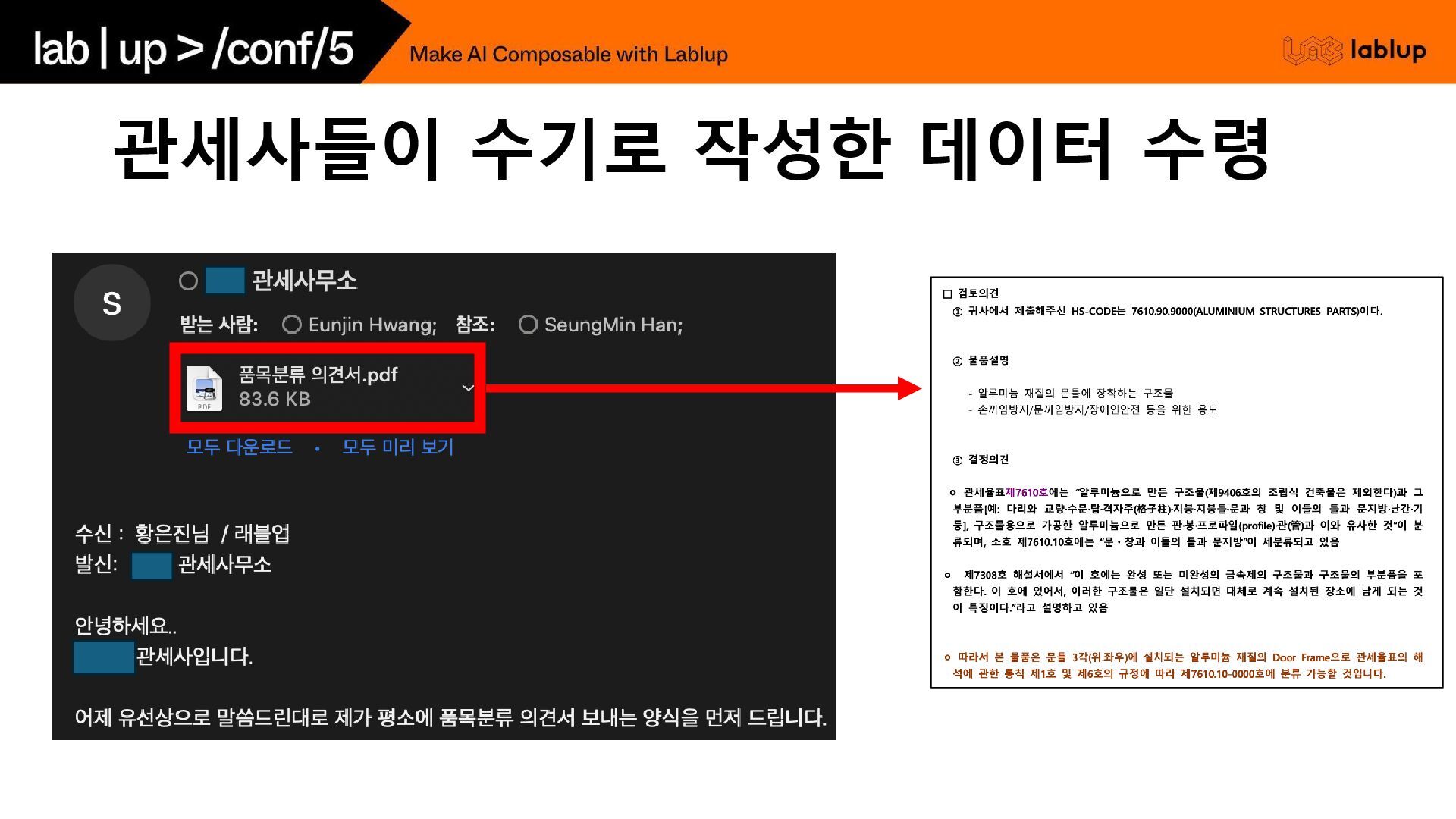
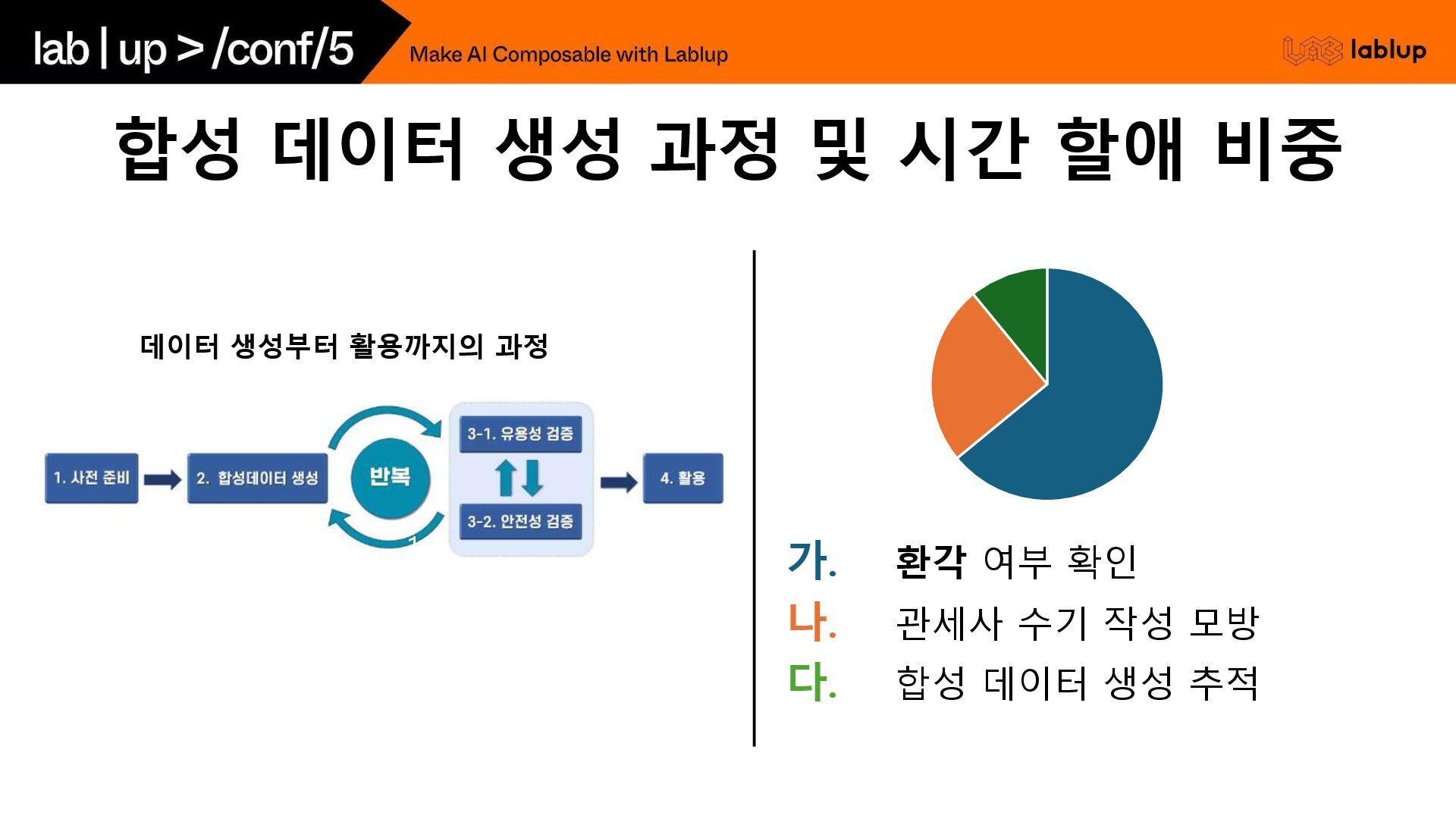
실제 관세사의 판단 과정을 정의해 둔 상태에서, 그들 의 접근과 논리 흐름을 모방하도록 하고, 유사 chapter 분류 사례를 참고하도록 지시 HS Code의 계층적 해설 데이터 (류/호/소호 해설) 구축하고, 공식 해설서의 계층 구조를 활용하여 체계적으로 데이터를 생성하는 데 중점 프롬프트 전략 관세사 판단 흐름 중심 - 단계적 논증 구조 (Few-shot 예시를 함께 주면서) 1. 제품 특성 분석 2. 관련 법조문 검토 3. HS해설서 참조 4. 비교 논리 5. 최종 결론 계층적 해설 참조 - 제공된 '류 해설', '호 해설', '소호 해설', '세부 분류' 내용을 최우 선으로 참고 두 가지 접근으로부터 생성한 합성 데이터를 관세사님에게 직접 평가받고, 더 나은 접근으로 첫 번째 접근으로 선택
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}