Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Agentic AI를 위한 MCP Sidecar sLM 학습(시도)기
Search
Lablup Inc.
November 03, 2025
81
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Agentic AI를 위한 MCP Sidecar sLM 학습(시도)기
Track 3_1730_Lablup Conf 2025_이준범
Lablup Inc.
November 03, 2025
More Decks by Lablup Inc.
See All by Lablup Inc.
효율적인 Agentic 아키텍처 구성을 위한 개발 Tip
lablup
0
64
Tokens/$ 극대화를 위한 소프트웨어 기술
lablup
0
42
Backend.AI Continuum을 이용한 AI Product 개발하기
lablup
1
38
Making Sense of HS Codes: HSense AI System for Automated Tariff Classfication
lablup
0
34
LLM을 통한 합성 데이터 생성
lablup
0
65
당신의 기업, AI 전환이 안되는 3가지 이유
lablup
1
47
[Keynote] Composable AI, Composable Software
lablup
0
70
[Keynote] AAA: Agentic, Autonomous, Adaptive Intelligence
lablup
0
67
Take the FastTrack 3: A Backend.AI approach to LLMOps
lablup
0
46
Featured
See All Featured
Documentation Writing (for coders)
carmenintech
77
5.4k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Optimizing for Happiness
mojombo
378
71k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
It's Worth the Effort
3n
188
29k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
450
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Speed Design
sergeychernyshev
33
2k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
240
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
430
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
340
Transcript
None
Agentic AI를 위한 MCP Sidecar sLM 학습(시도) 기 이준범 (래블업)
[email protected]
발표자 소개 이준범 (aka Beomi) - 래블업 Researcher - AI/ML
GDE - 한국어 언어모델 연구하다 스마트스팸필터 앱도 만들다 가 - 작년 발표는 온디바이스 모 델 - 올해 발표도 온디바이스(?) 모델
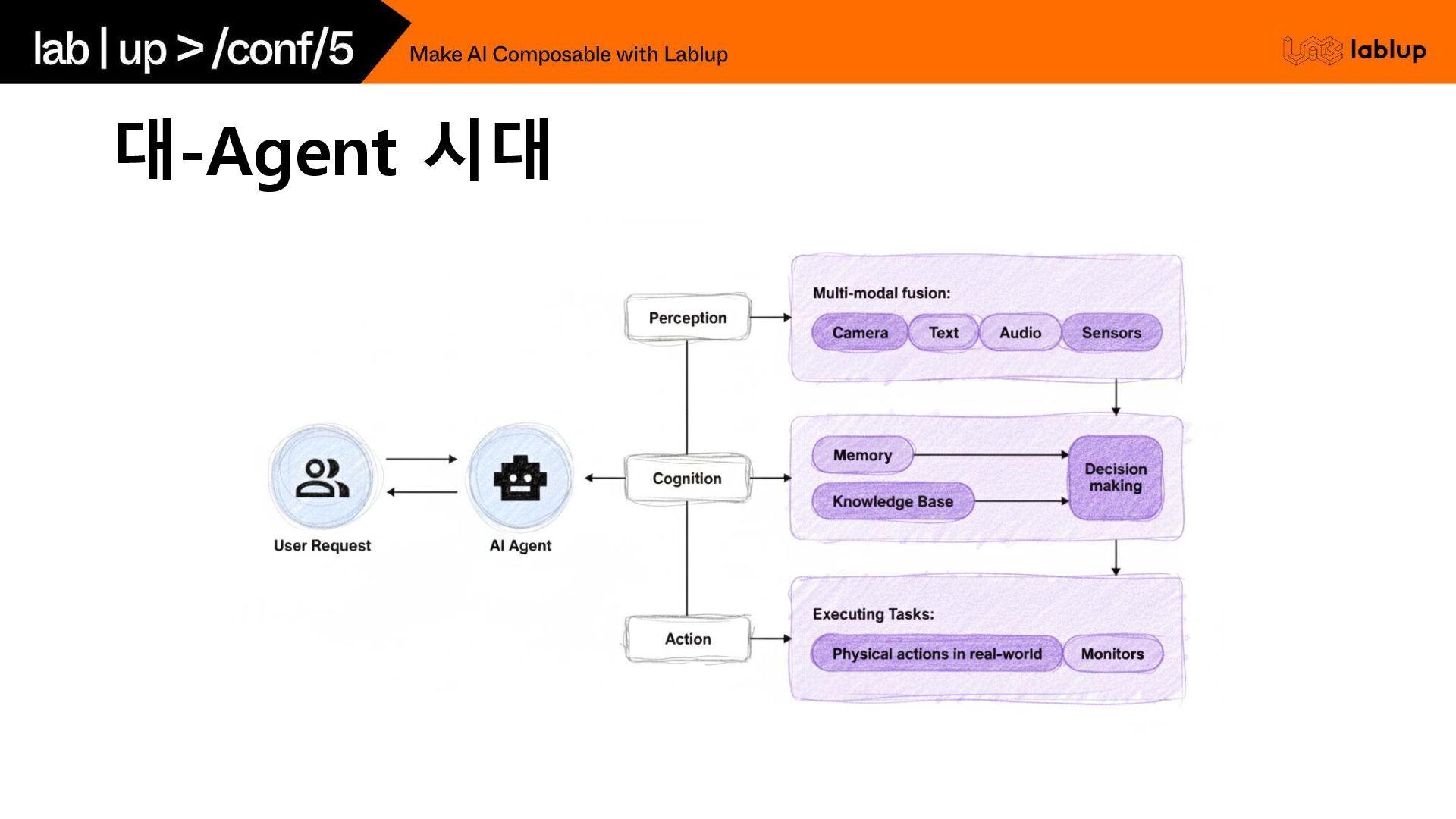
대-Agent 시대
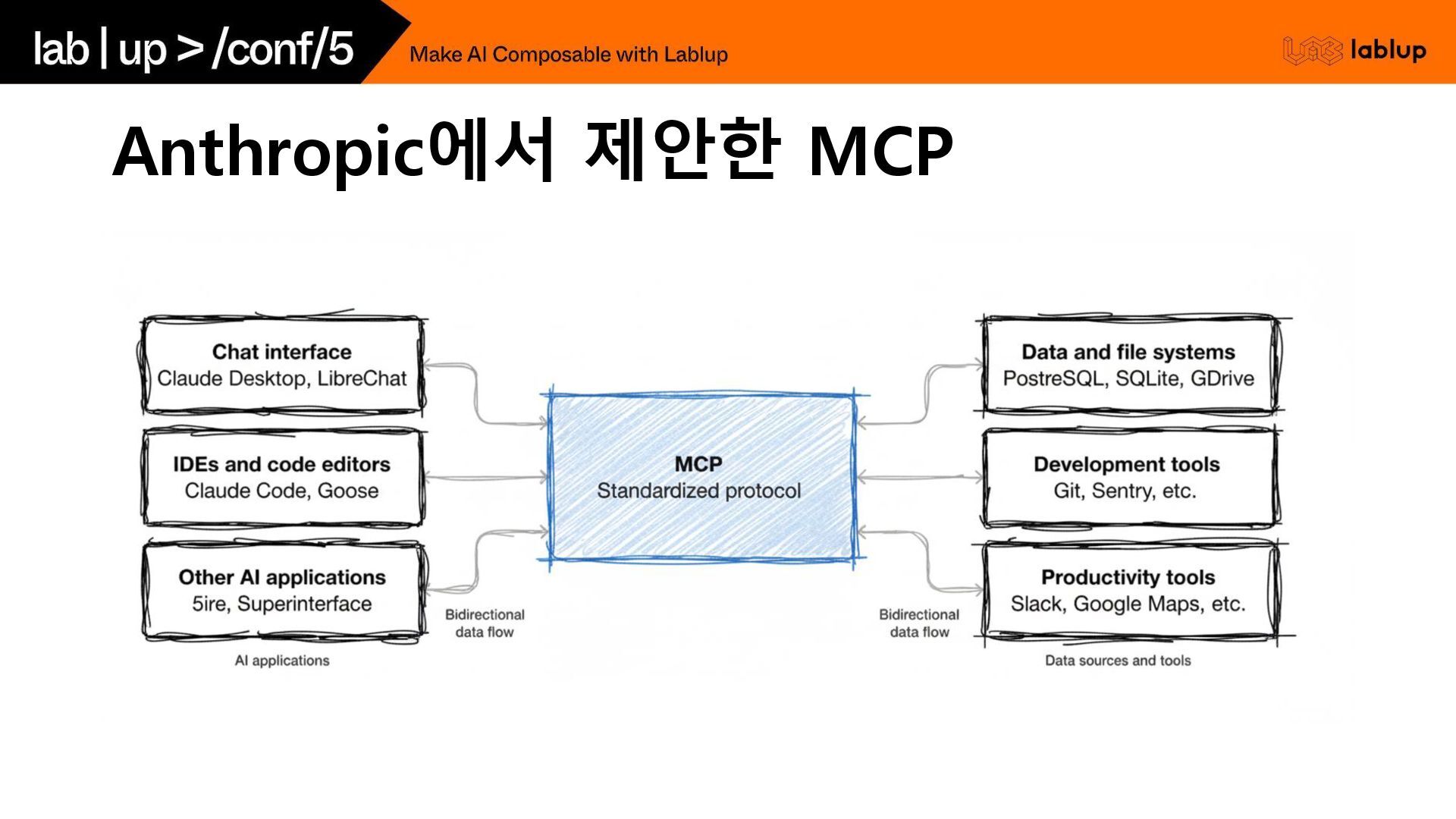
Anthropic에서 제안한 MCP
OpenAI도 도입하는 MCP
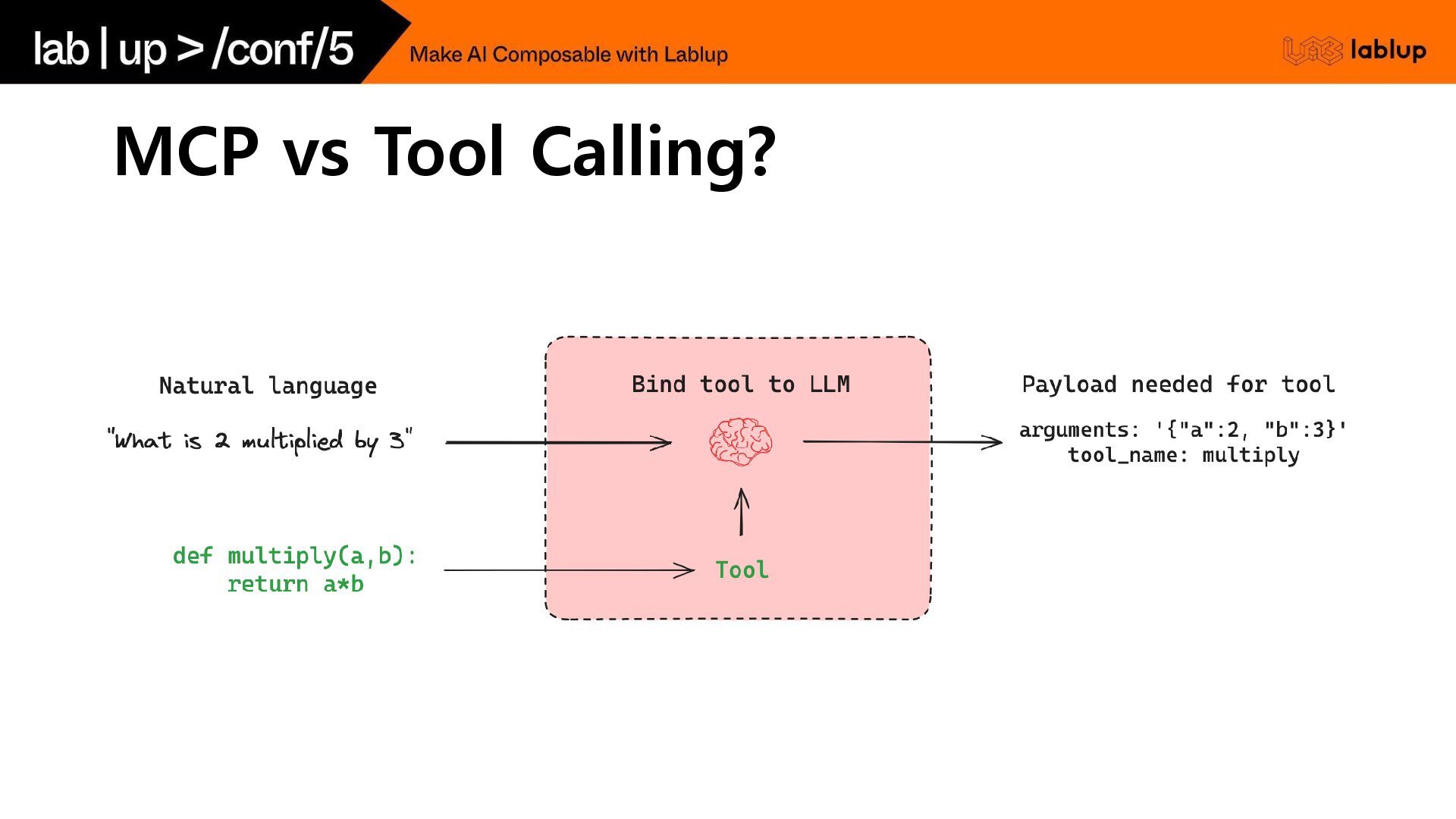
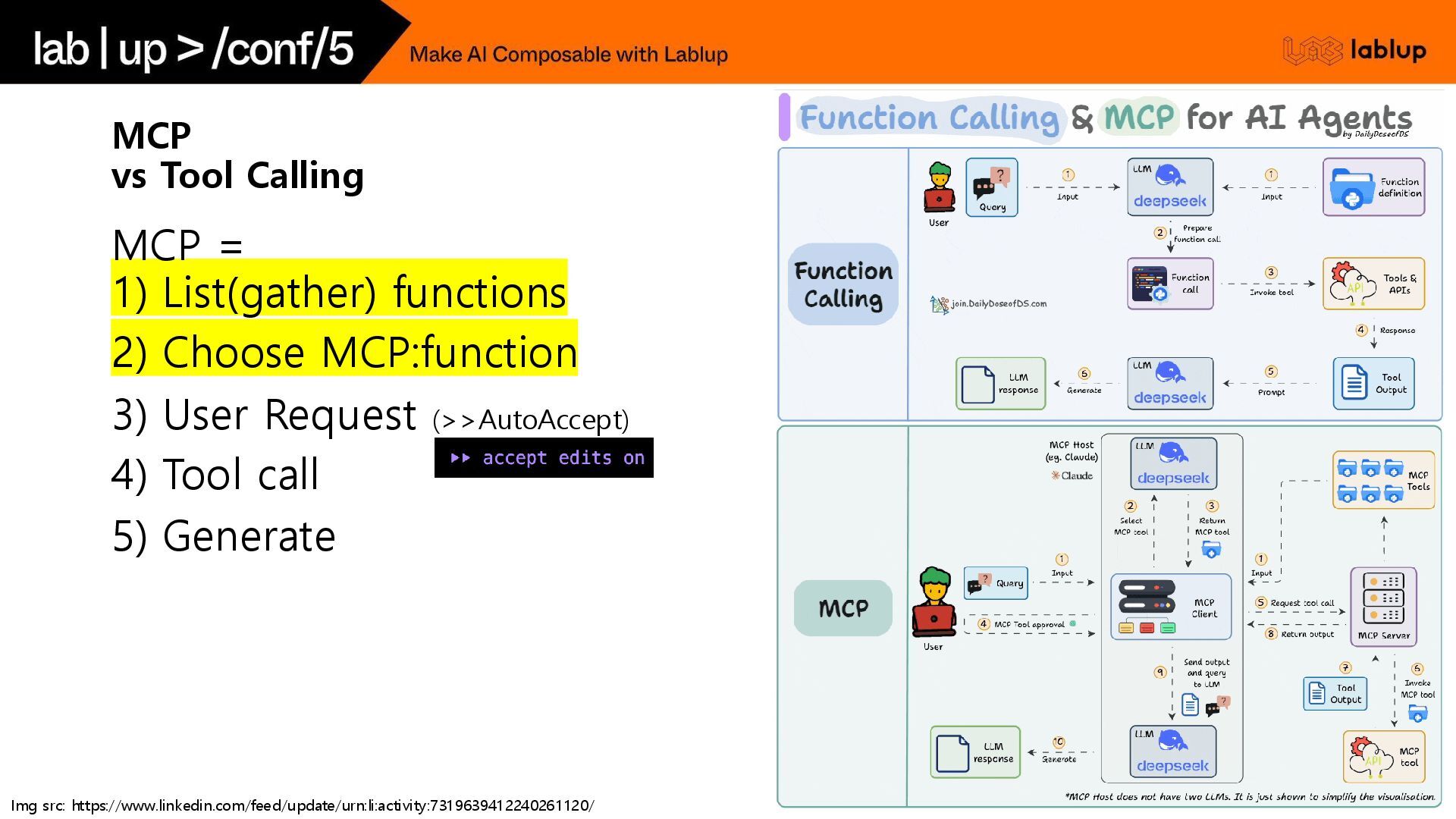
MCP vs Tool Calling?
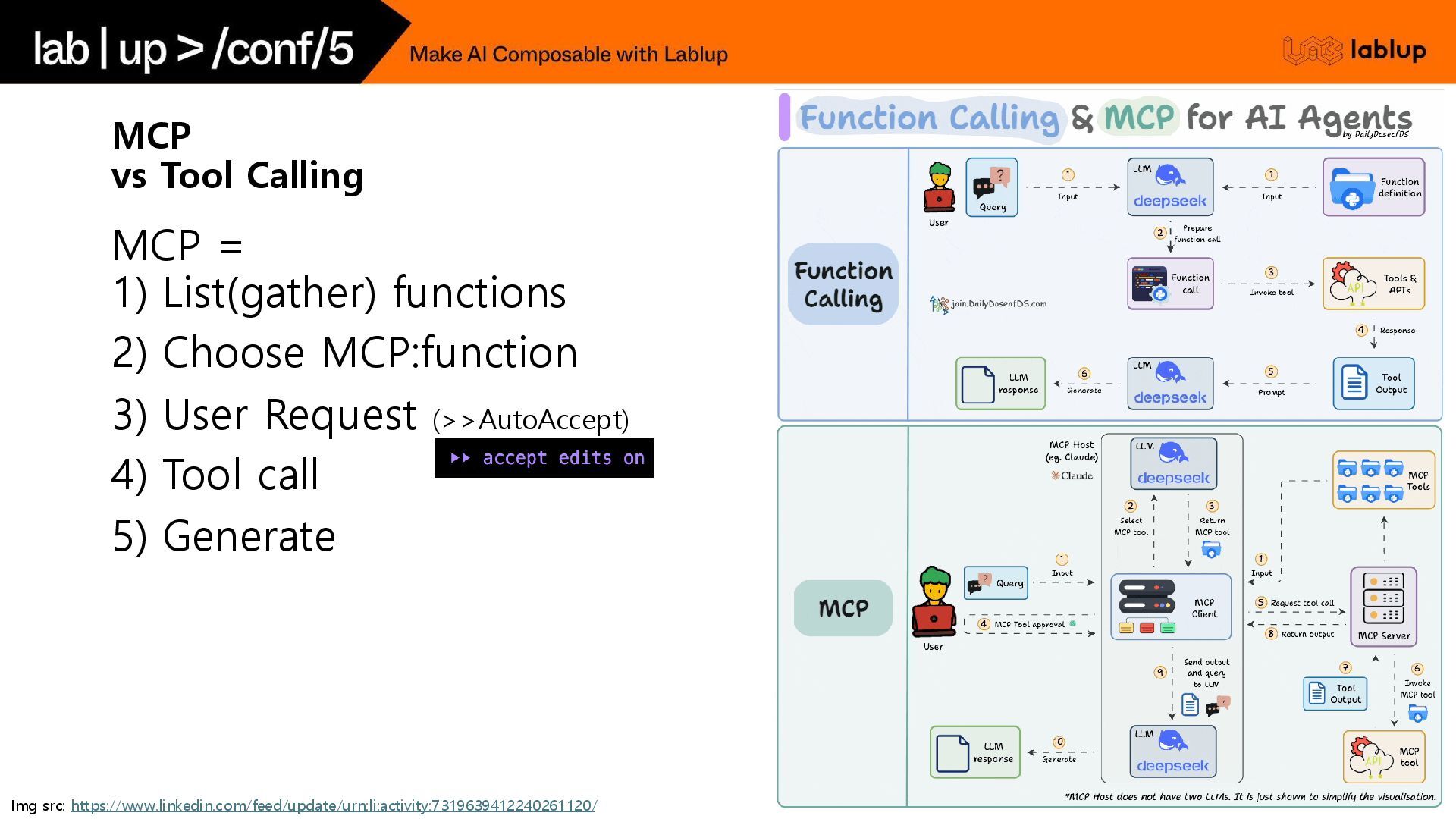
MCP vs Tool Calling MCP = 1) List(gather) functions 2)
Choose MCP:function 3) User Request (>>AutoAccept) 4) Tool call 5) Generate Img src: https://www.linkedin.com/feed/update/urn:li:activity:7319639412240261120/
MCP vs Tool Calling MCP = 1) List(gather) functions 2)
Choose MCP:function 3) User Request (>>AutoAccept) 4) Tool call 5) Generate Img src: https://www.linkedin.com/feed/update/urn:li:activity:7319639412240261120/
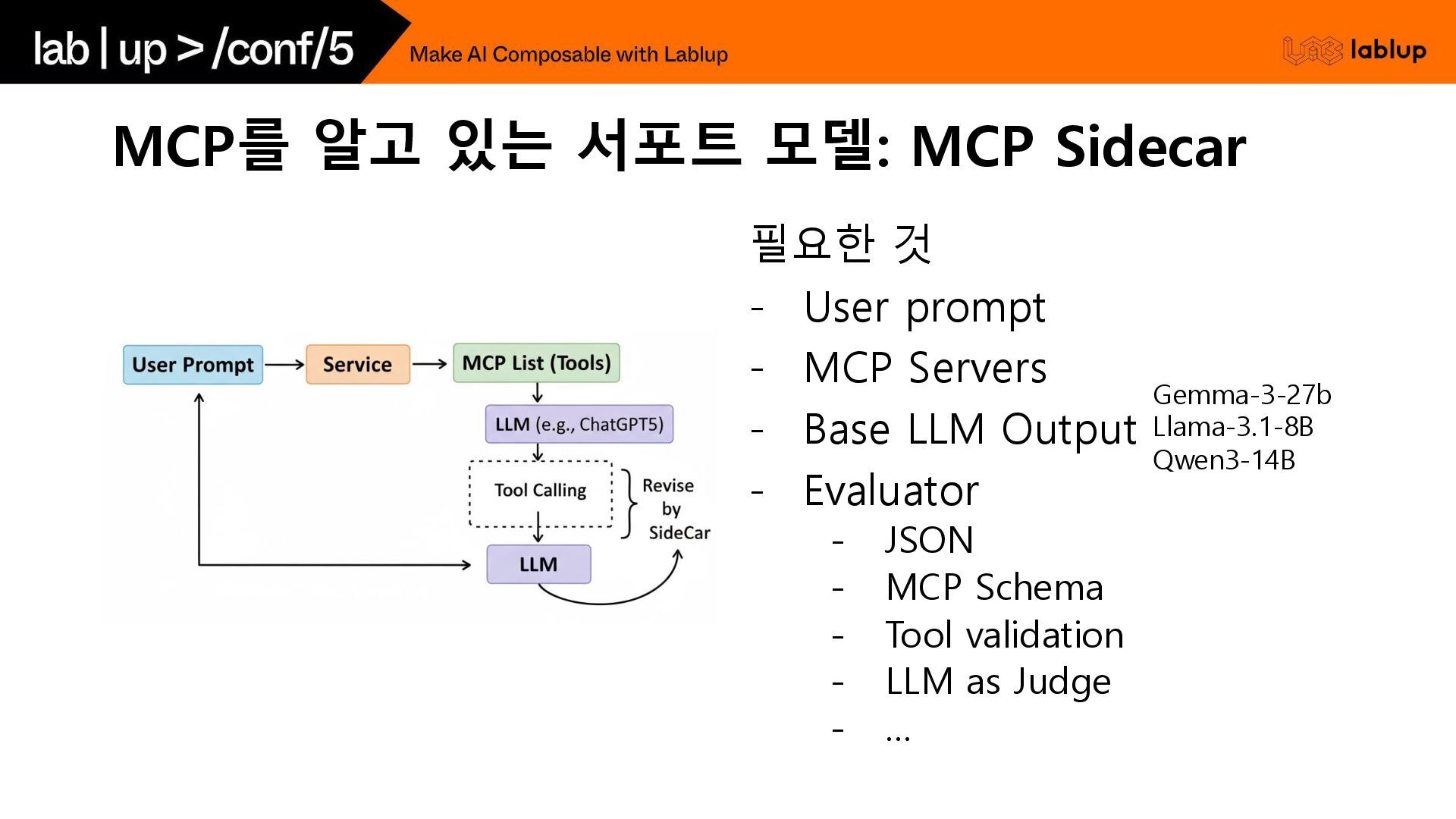
모델이 ‘MCP’를 알고 있을까?
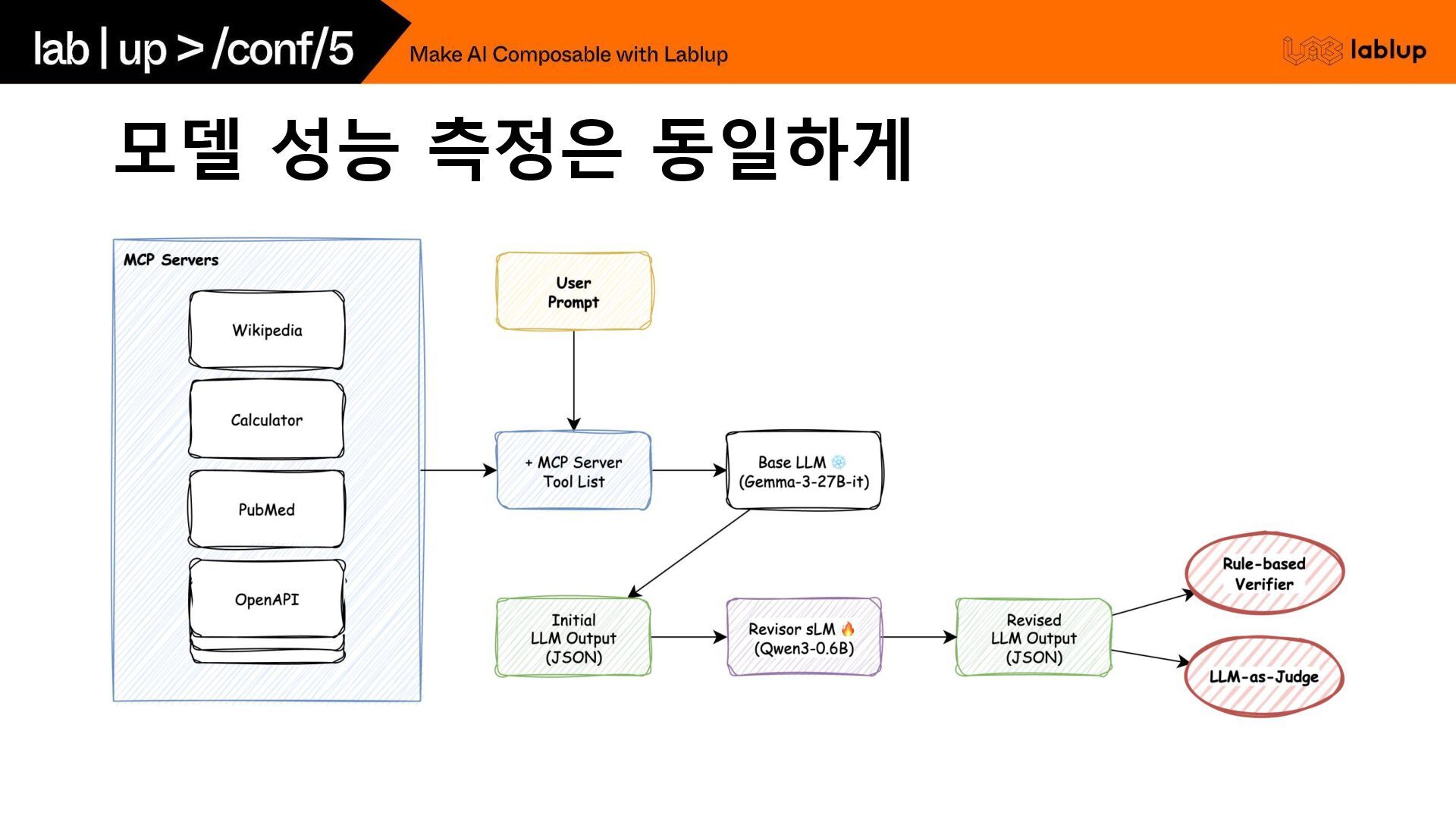
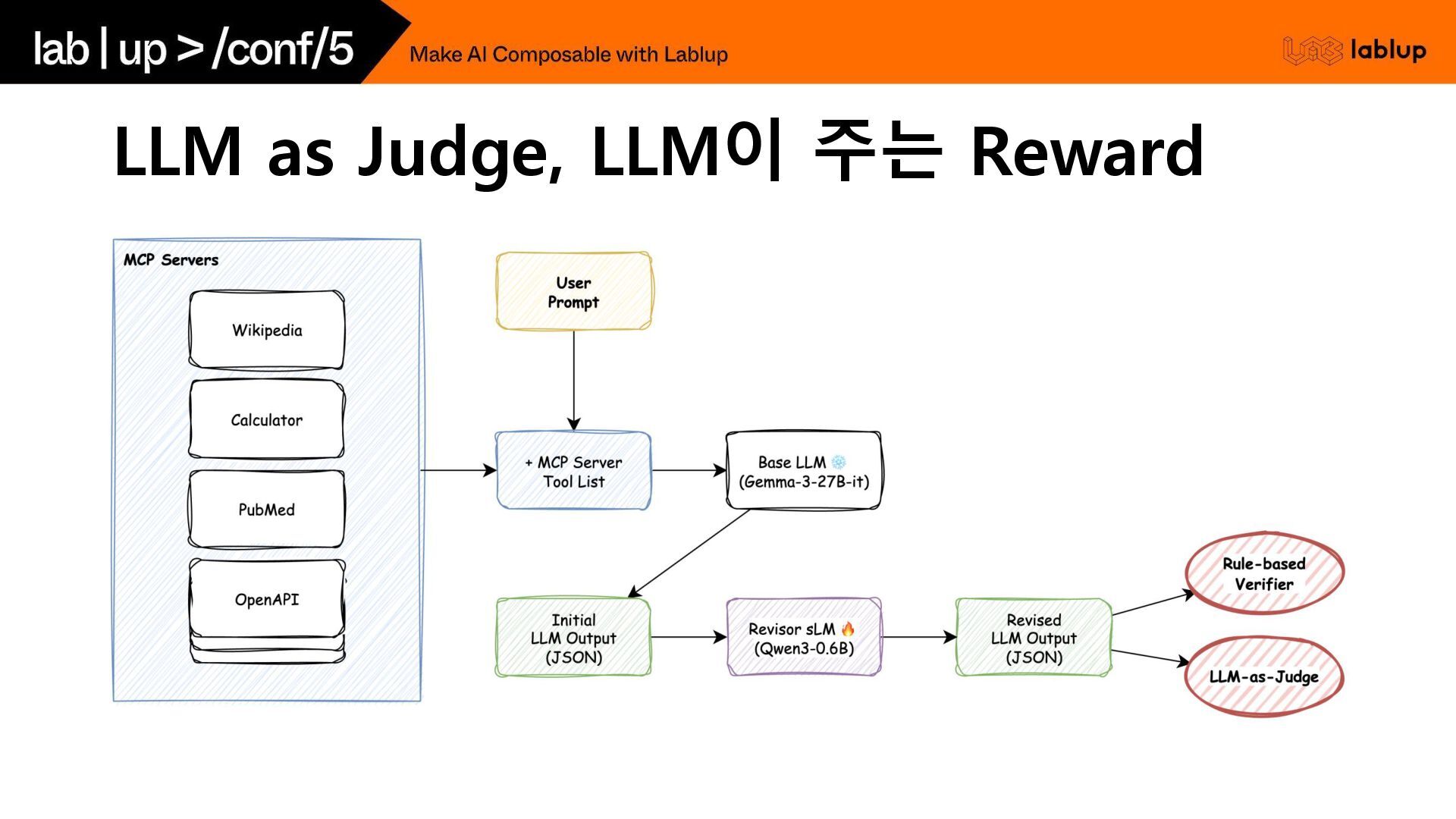
MCP를 알고 있는 서포트 모델: MCP Sidecar 필요한 것 -
User prompt - MCP Servers - Base LLM Output - Evaluator - JSON - MCP Schema - Tool validation - LLM as Judge - … Gemma-3-27b Llama-3.1-8B Qwen3-14B
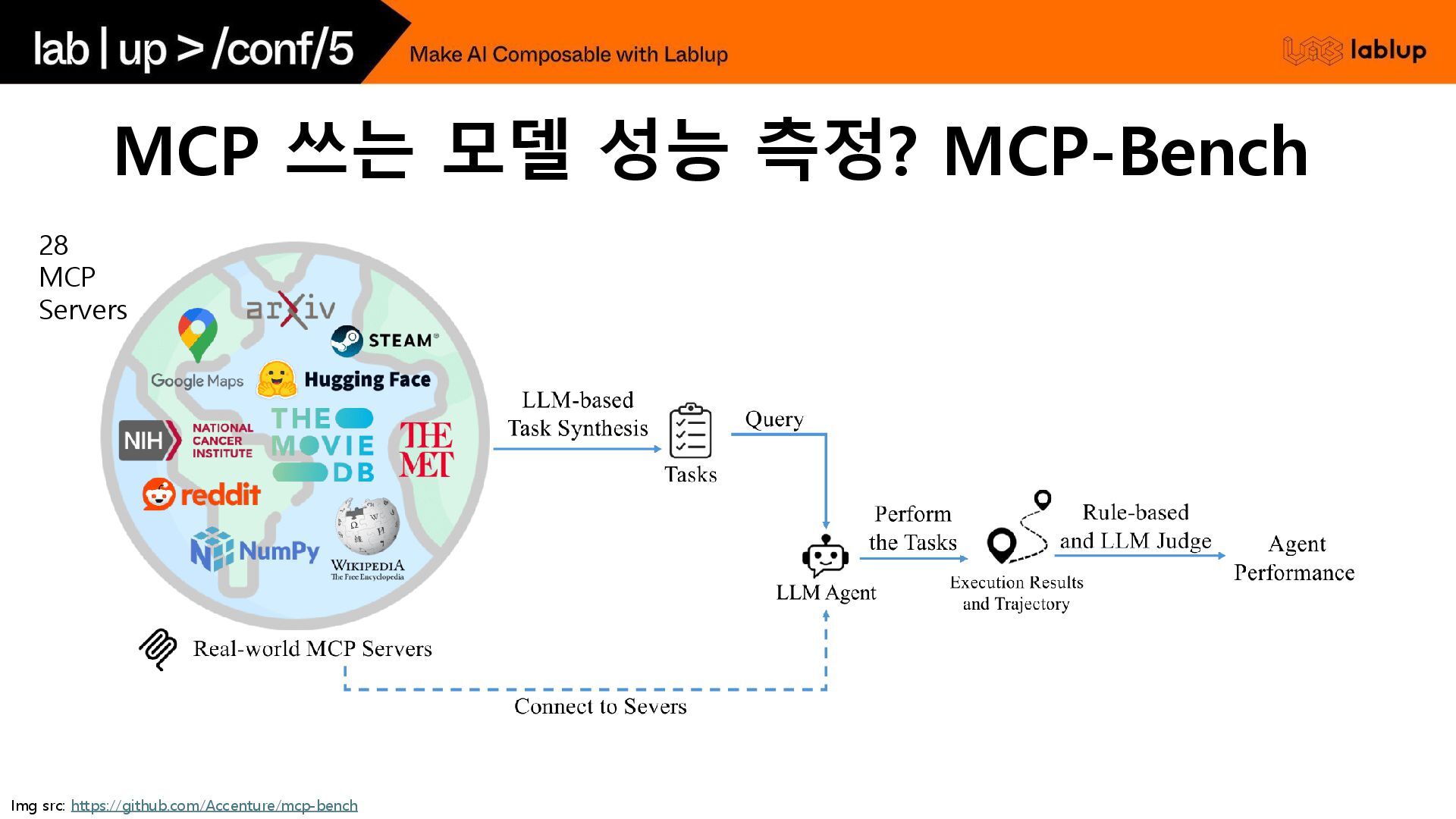
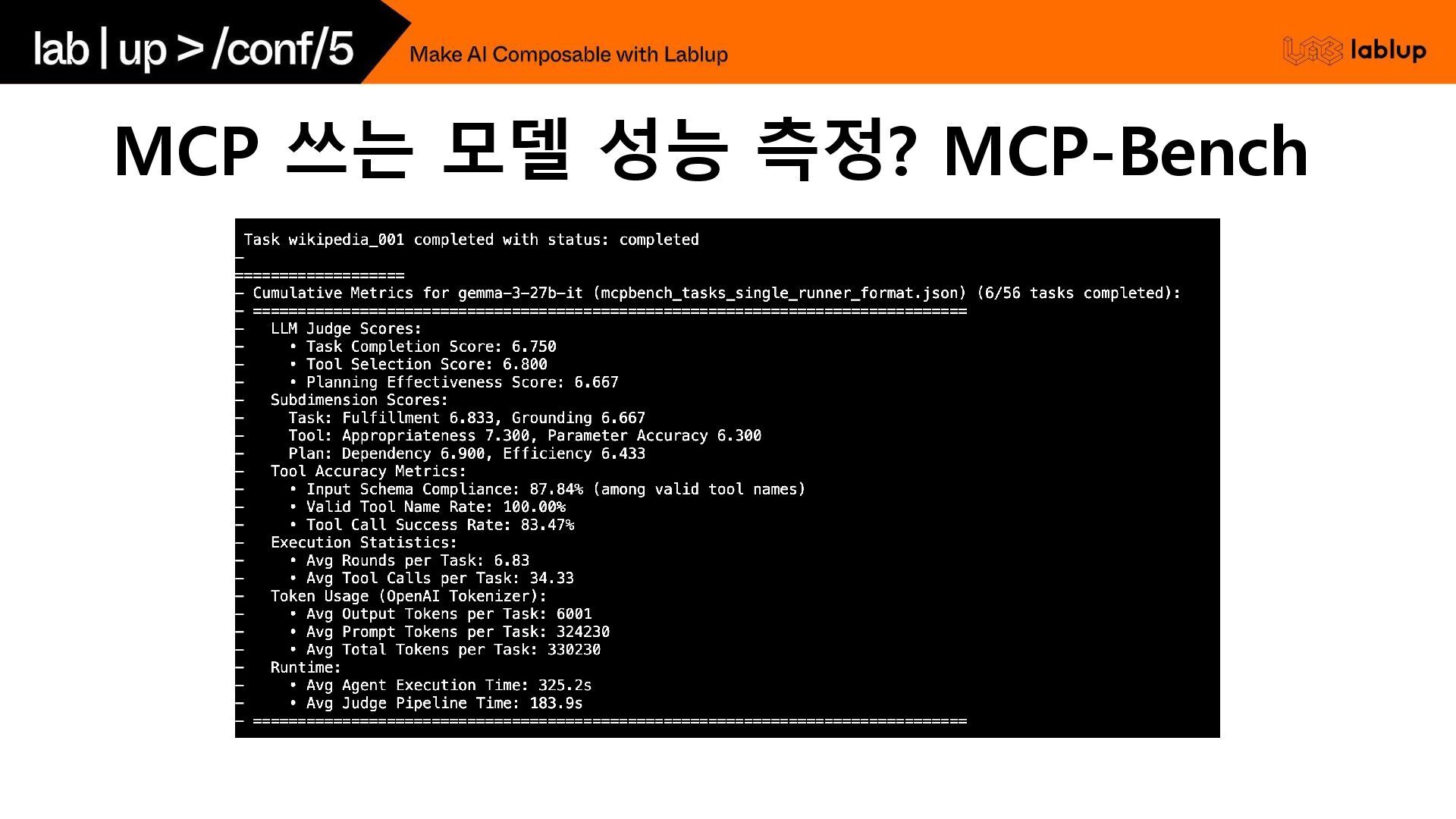
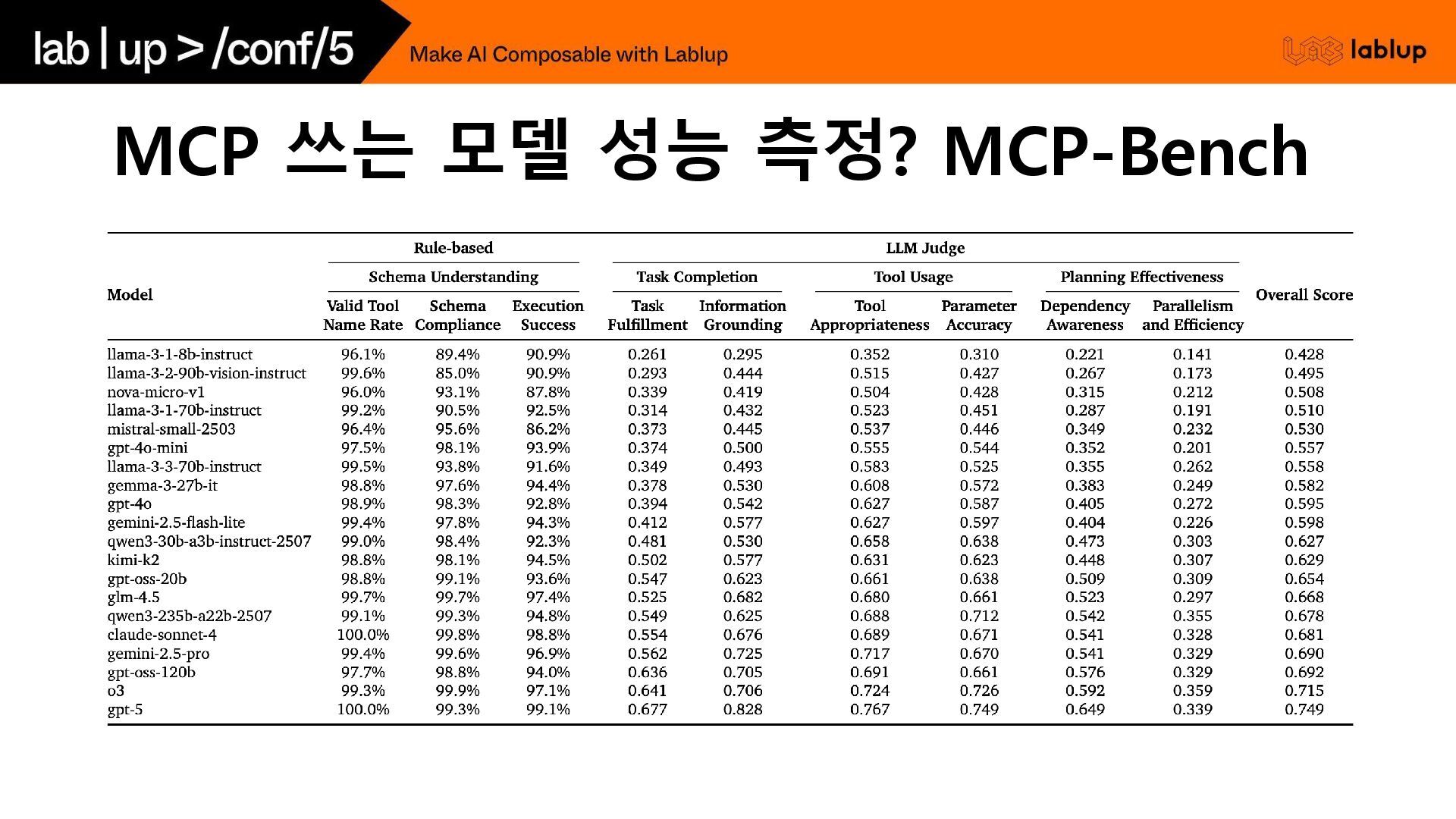
MCP 쓰는 모델 성능 측정? MCP-Bench Img src: https://github.com/Accenture/mcp-bench 28
MCP Servers
MCP-Bench
MCP 쓰는 모델 성능 측정? MCP-Bench
MCP 쓰는 모델 성능 측정? MCP-Bench
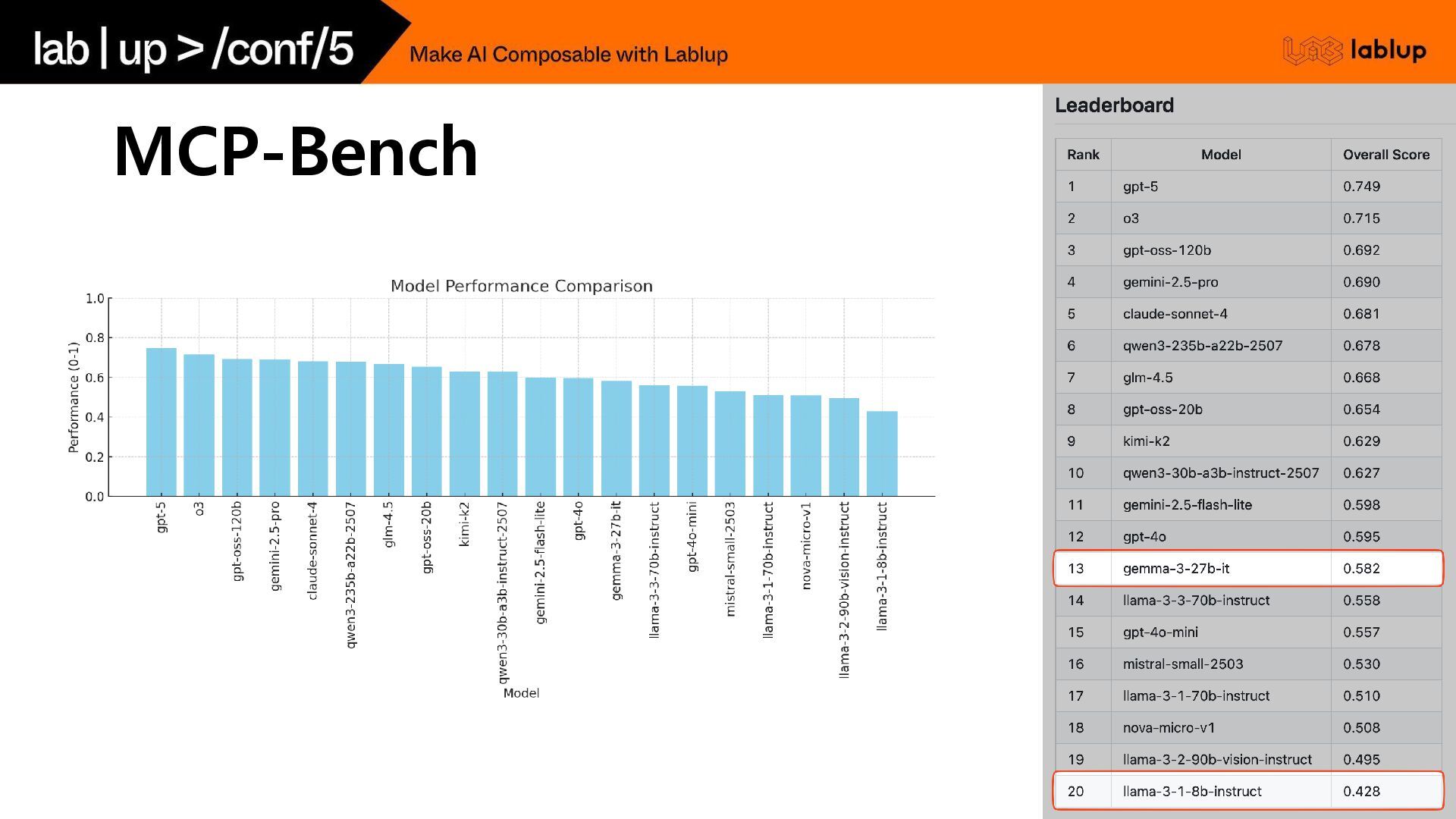
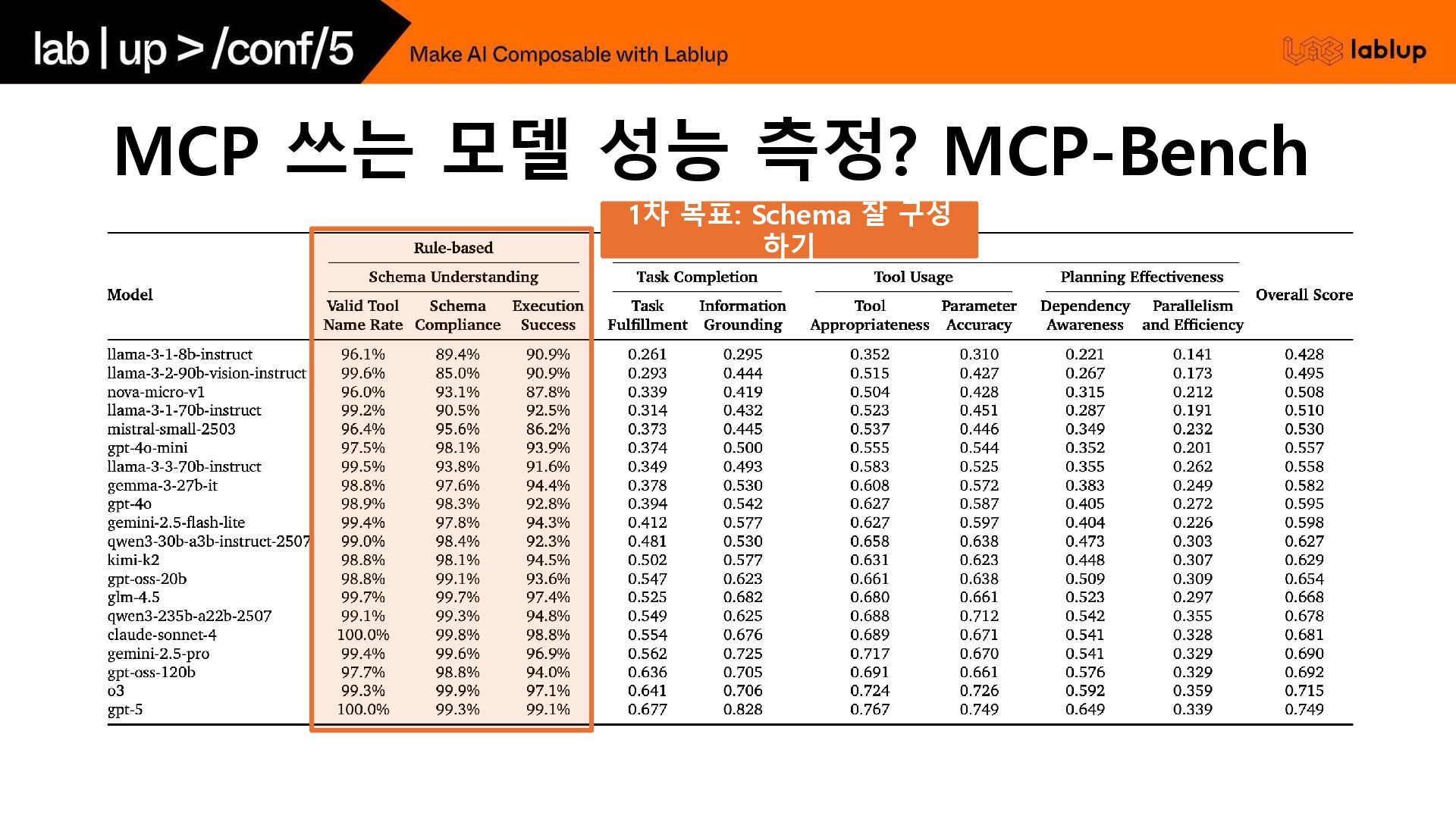
1차 목표: Schema 잘 구성 하기 MCP 쓰는 모델 성능
측정? MCP-Bench
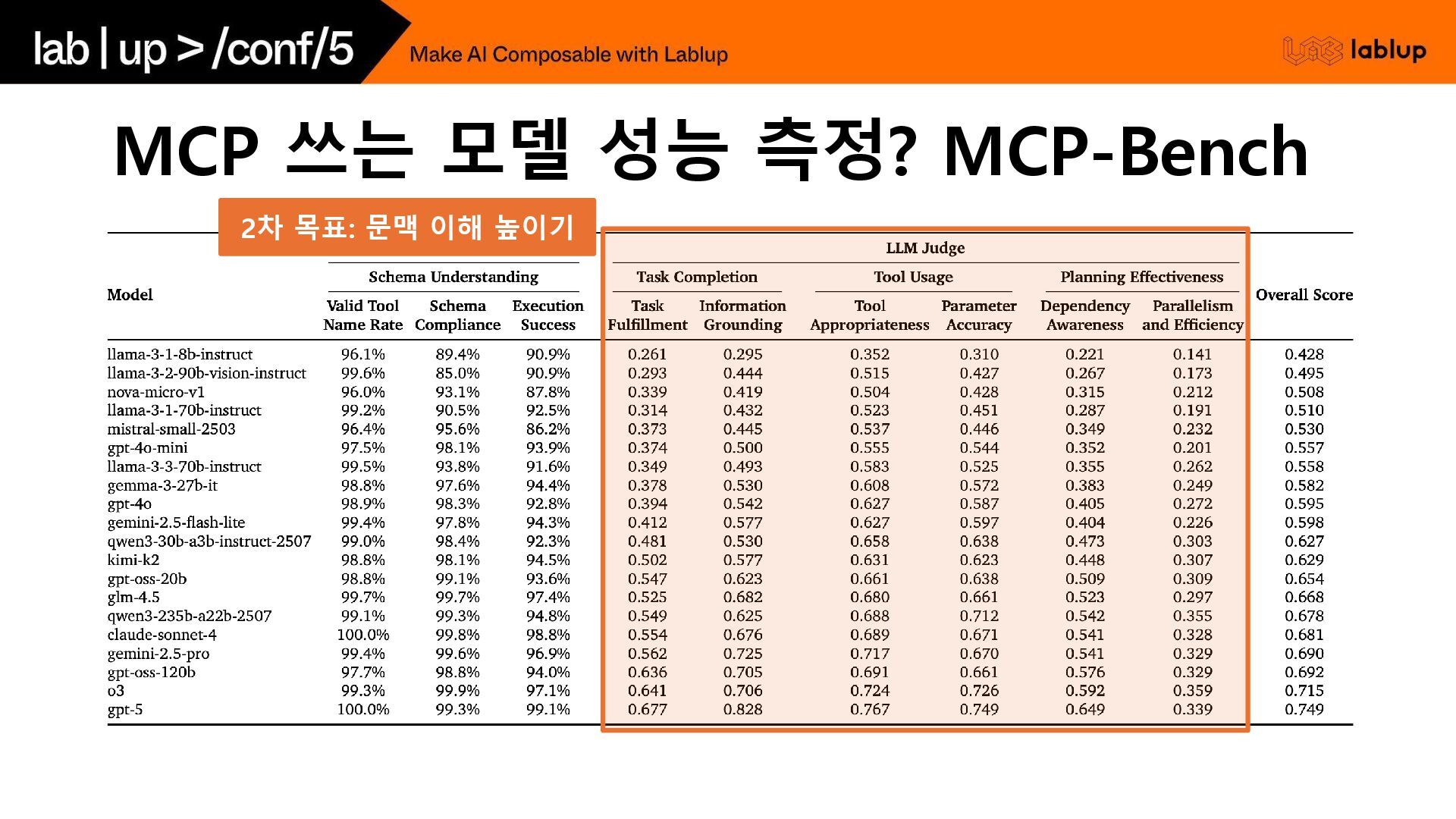
2차 목표: 문맥 이해 높이기 MCP 쓰는 모델 성능 측정?
MCP-Bench
MCP-Bench는 Evaluation Kit
학습 데이터는 어디서? 1) 가상 Task 만들고 2) Trajectory 모으고
3) Revise or Verify
Train Set = (가상) User Prompt 시나리오 • MCP-bench는 Eval
Set Only • 독립된 Train Set 필요 • MCP 서버들 정보 기반 → 신규 User Query 생성 • GPT-5, GPT-5-mini 이용
Train Set = (가상) User Prompt 시나리오 User Query 생성
• MCP 서버 목록 + Tool 목록 • GPT-5/mini로 • Task Goal 설정하기 • Fuzzy Description (= 사용자 프롬프트) • 실제 사용할 함수 /Parameter (→ 이후 Verifier 사용)
Train Set = (가상) User Prompt 시나리오
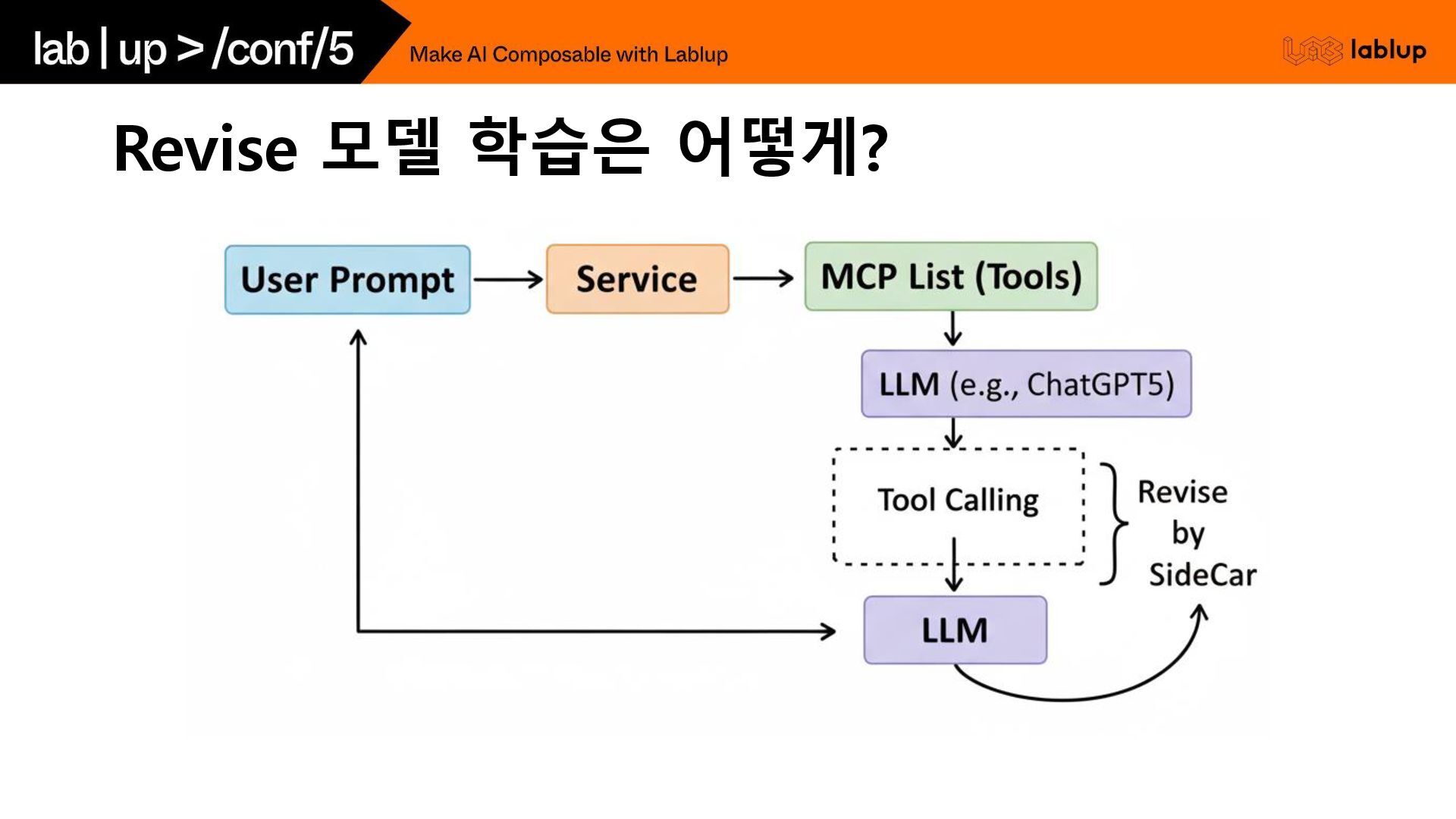
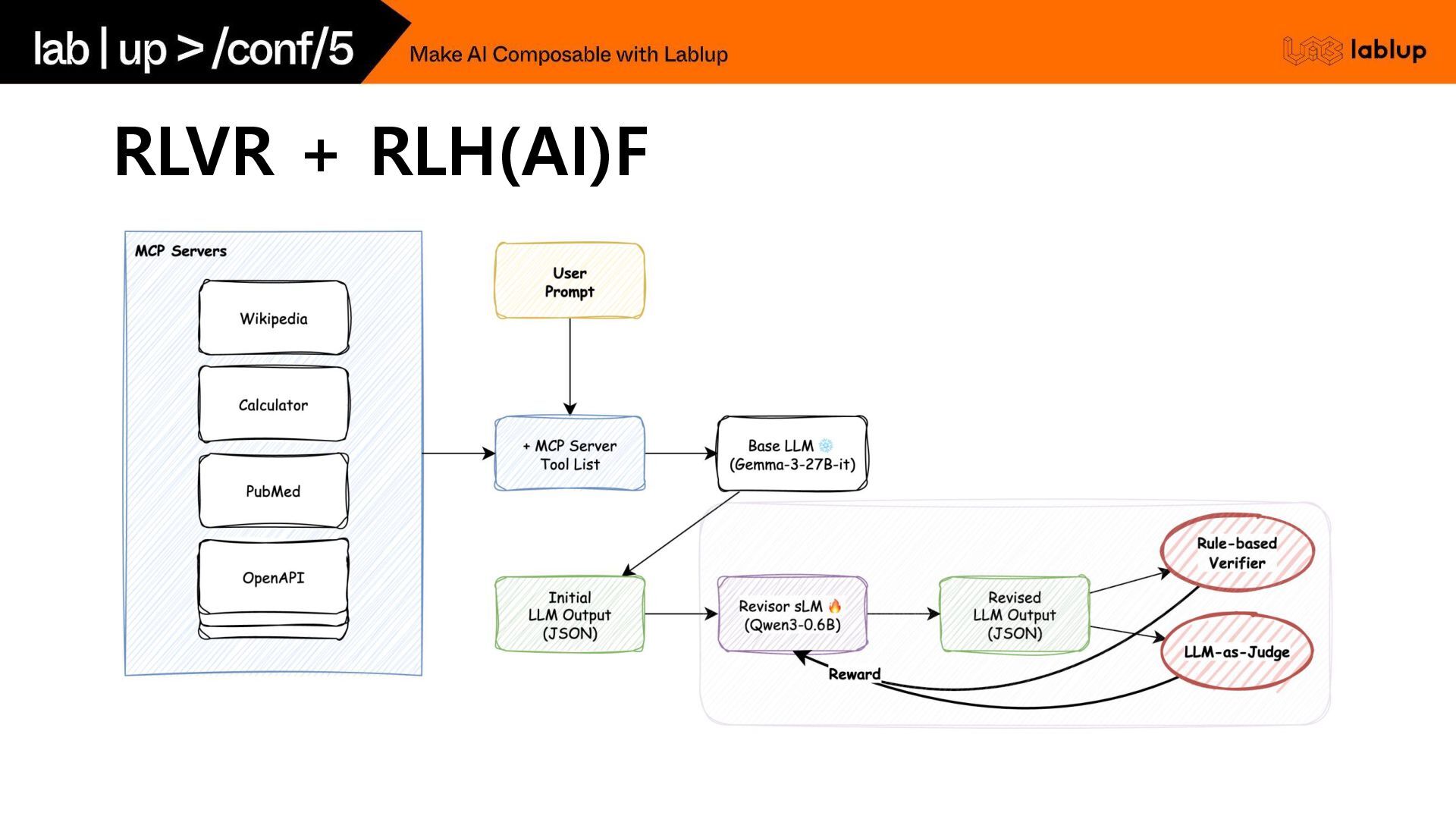
Revise 모델 학습은 어떻게?
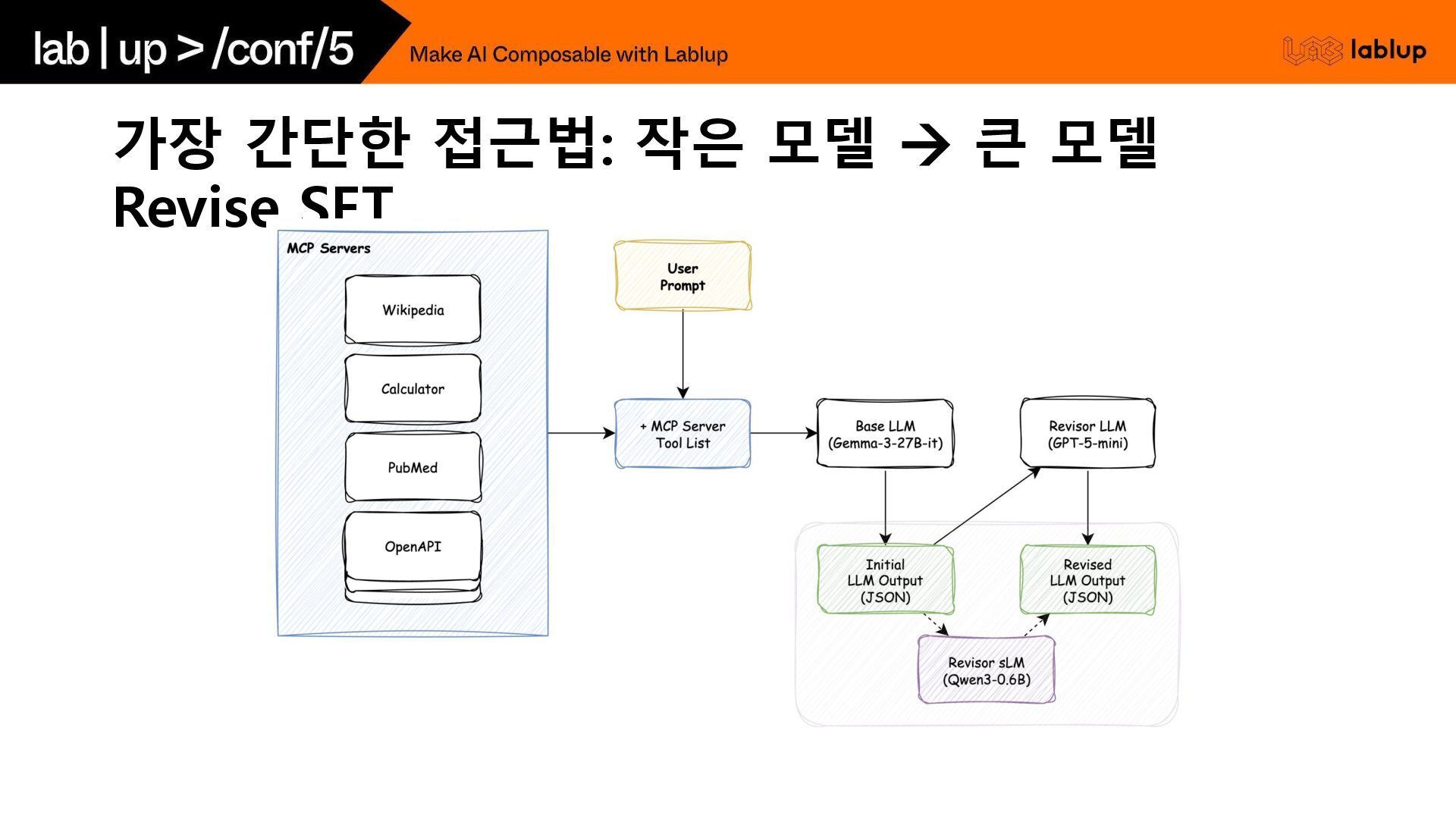
가장 간단한 접근법: 작은 모델 → 큰 모델 Revise SFT
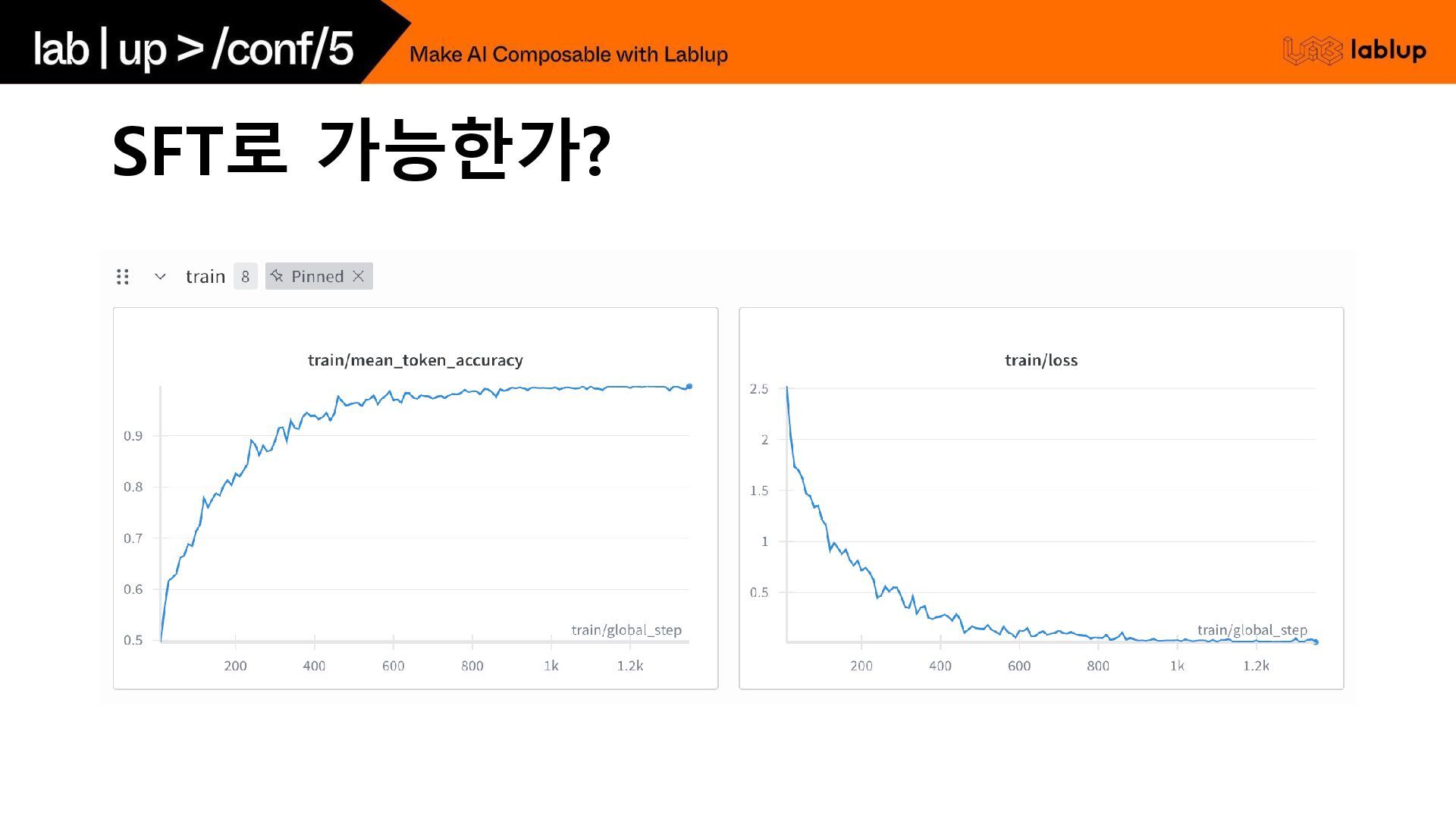
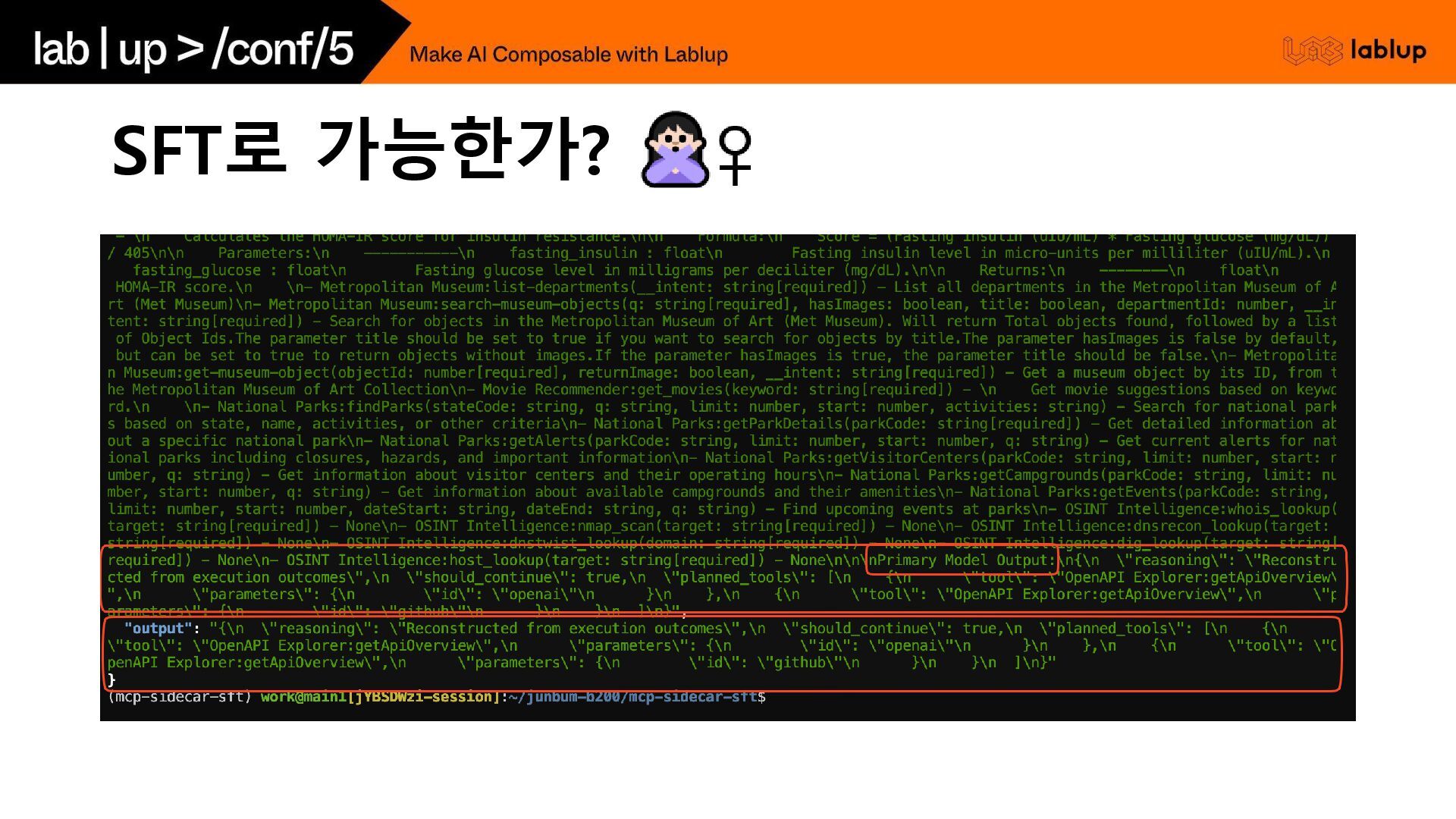
SFT로 가능한가?
SFT로 가능한가?
RLVR + RLH(AI)F
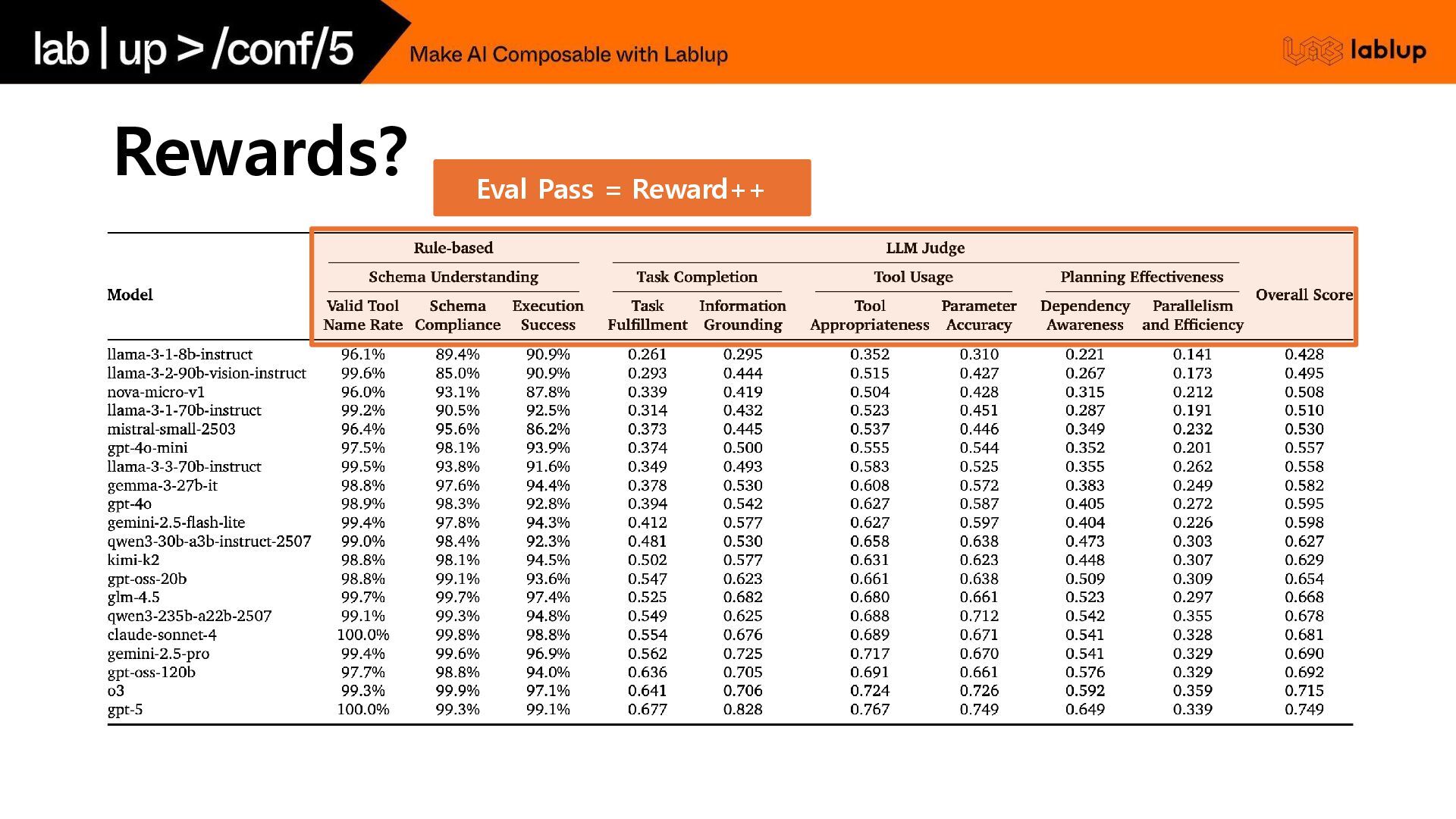
Rewards? Eval Pass = Reward++
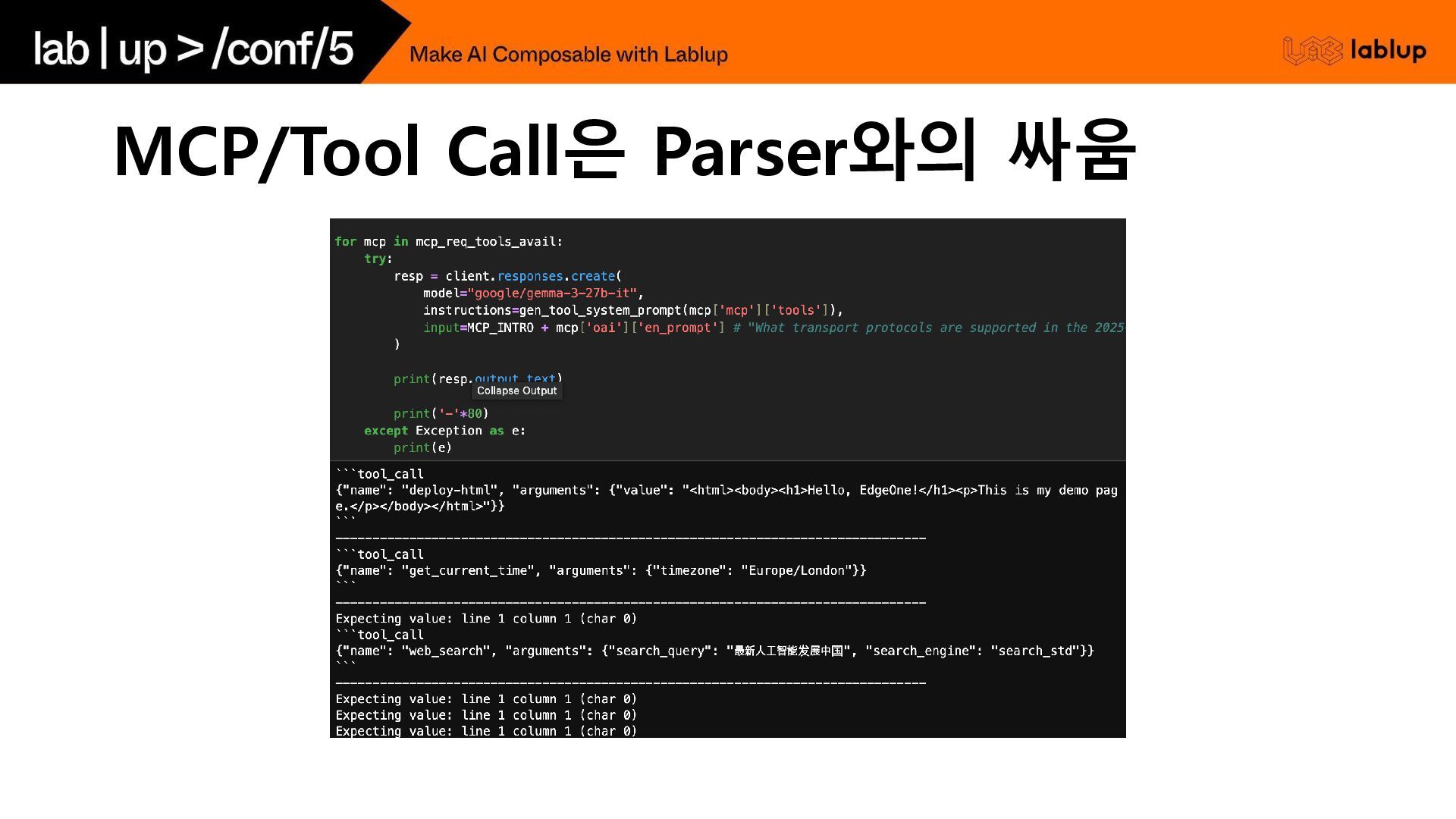
MCP/Tool Call은 Parser와의 싸움
MCP/Tool Call은 Parser와의 싸움
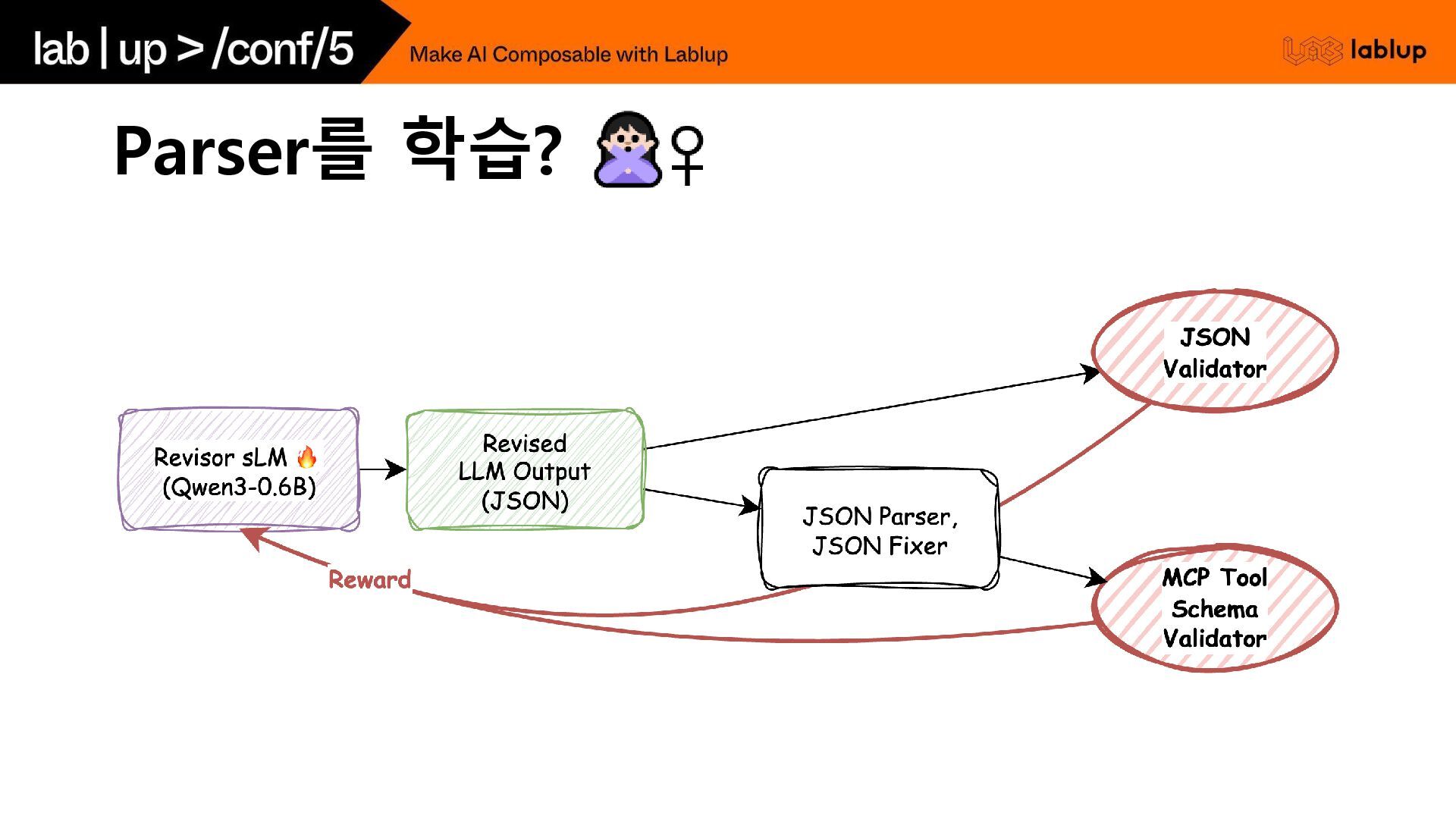
Parser를 학습?
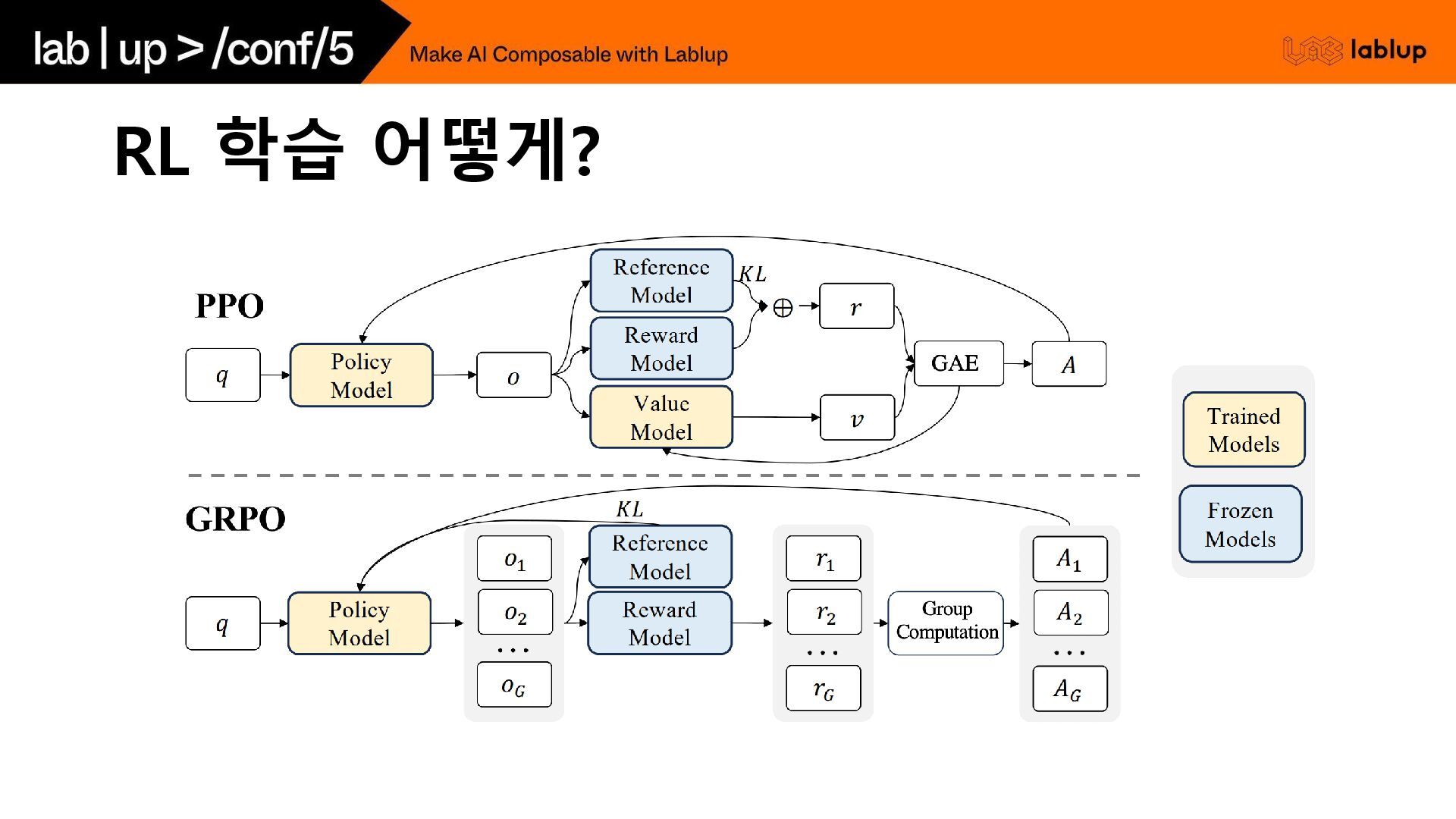
RL 학습 어떻게?
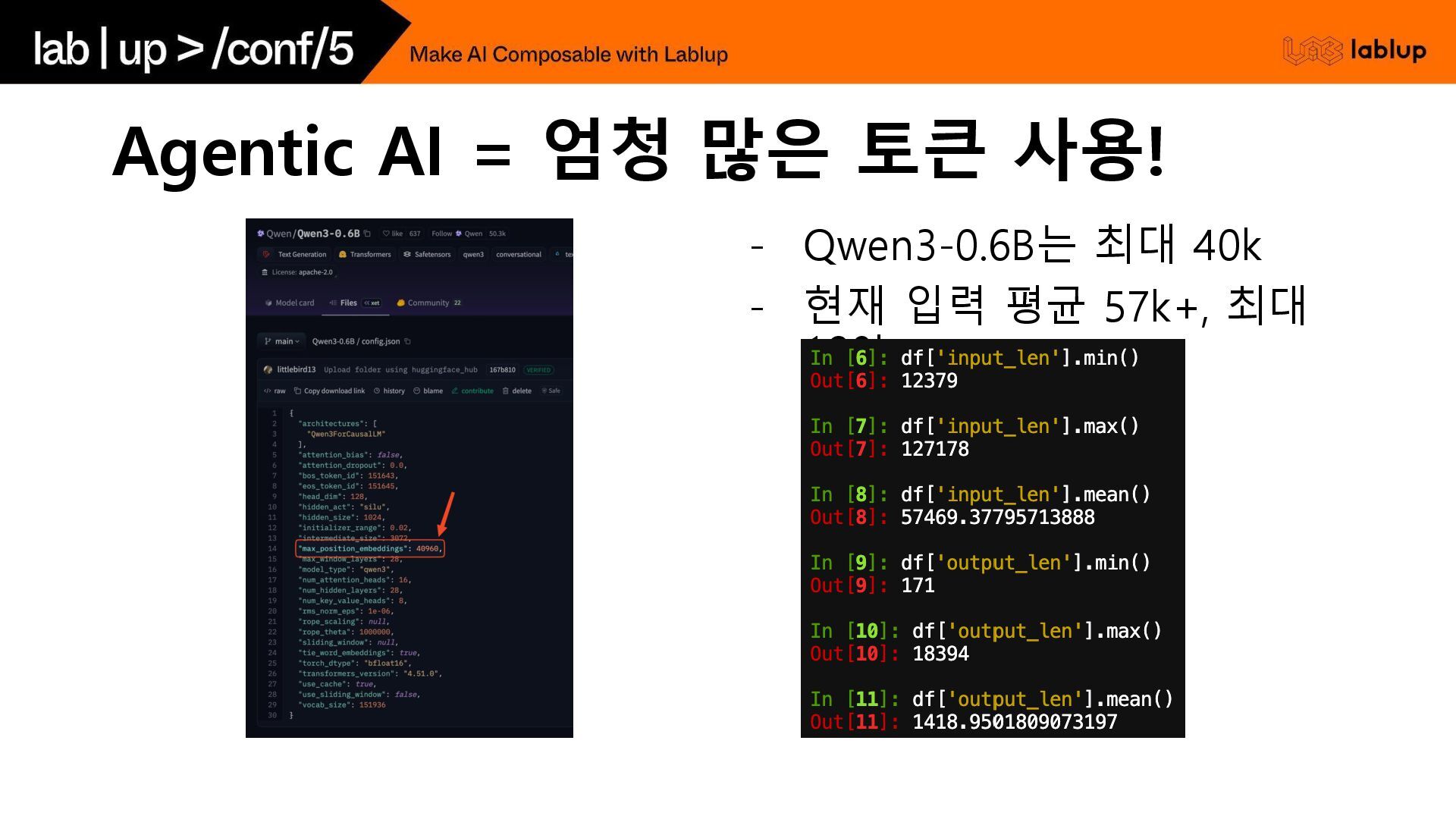
Agentic AI = 엄청 많은 토큰 사용! - Qwen3-0.6B는 최대
40k - 현재 입력 평균 57k+, 최대 128k
Agentic AI = 엄청 많은 토큰 사용! RoPE Scaling으로 확장
- Qwen3-14B는 지원 - 작은 모델들은 비지원 - 성능이 확 감소…
Agentic AI = 엄청 많은 토큰 사용! Qwen3 4B Instruct
모델 --> Native context 256K
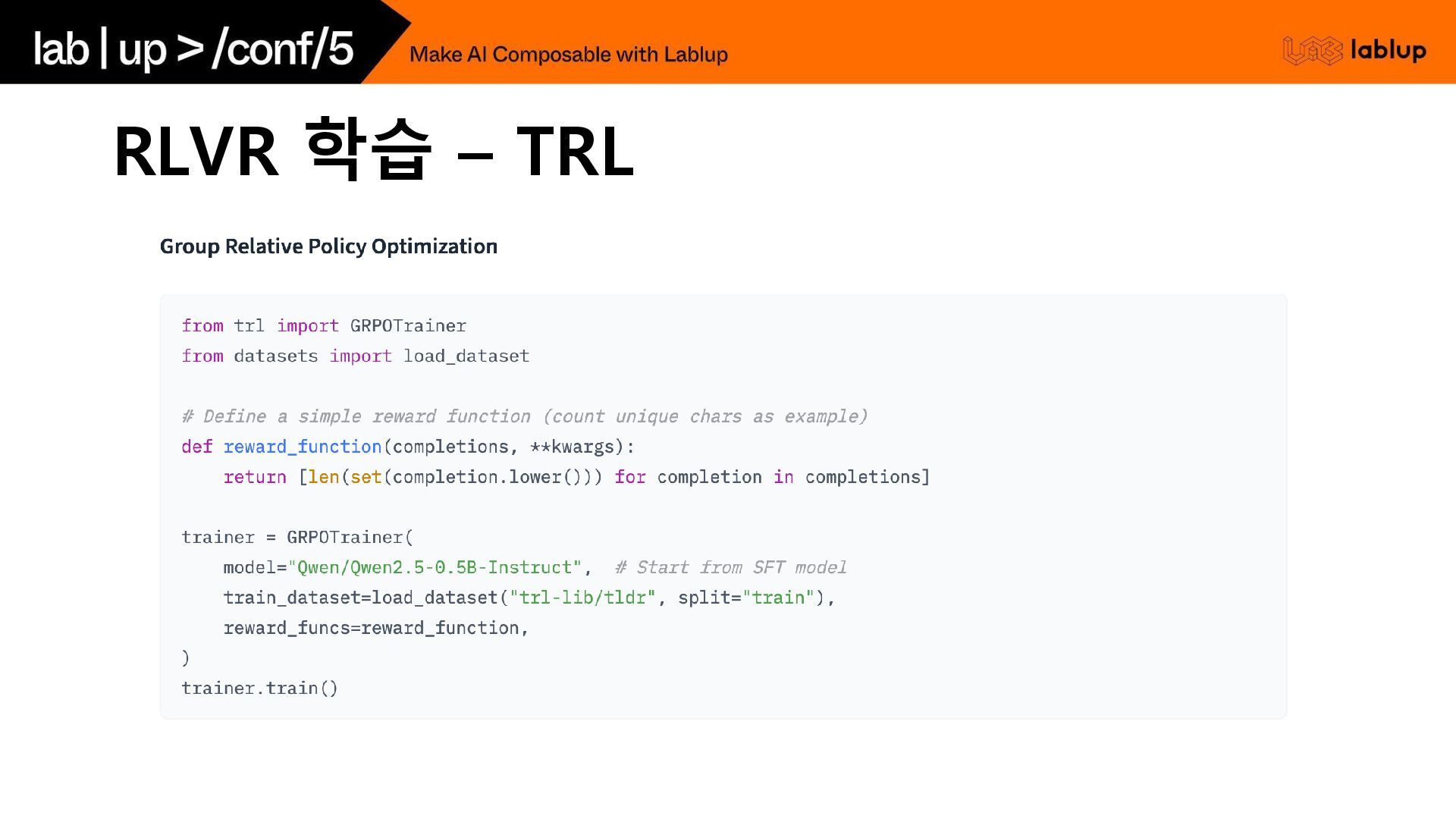
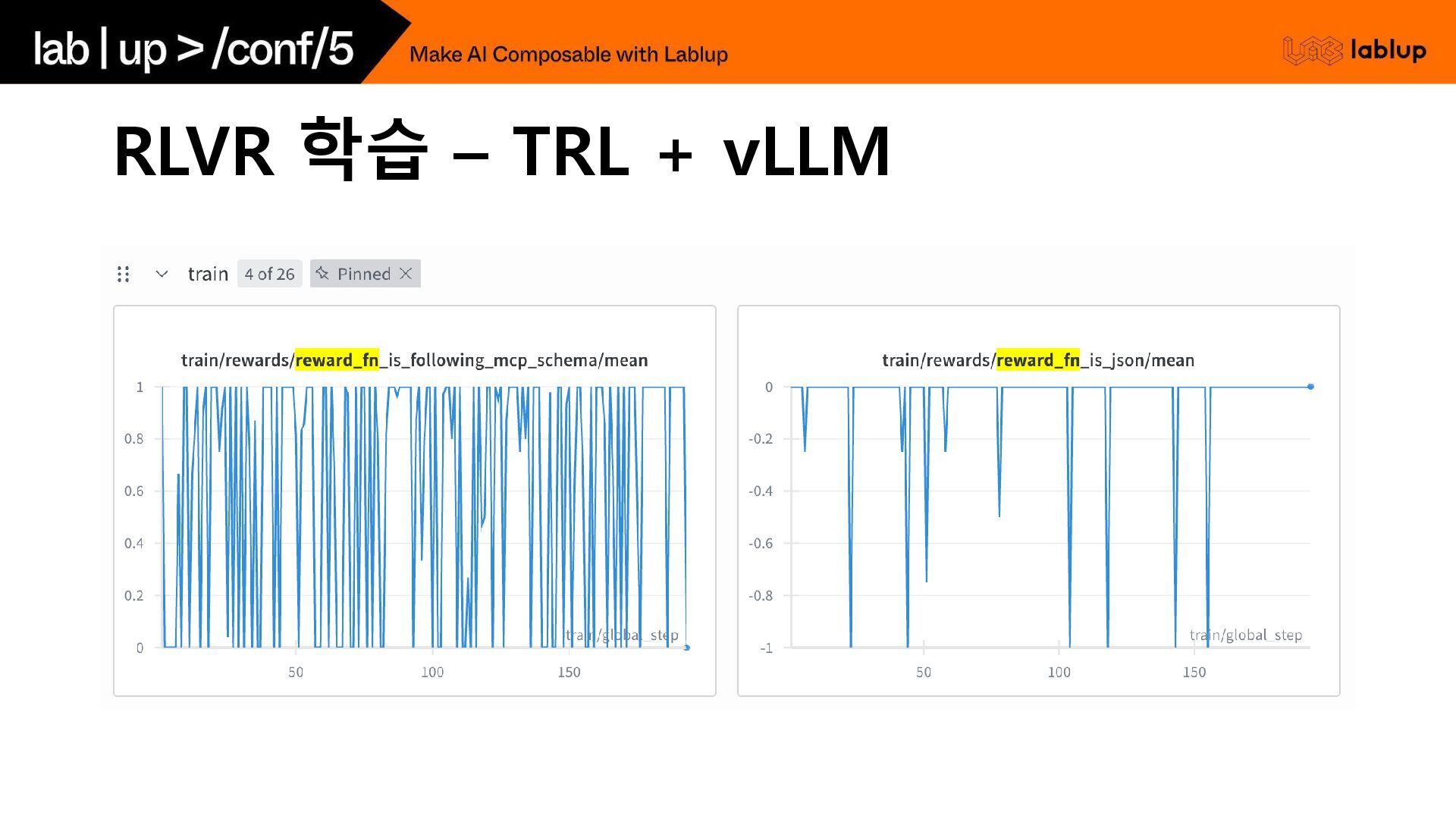
RLVR 학습 – TRL
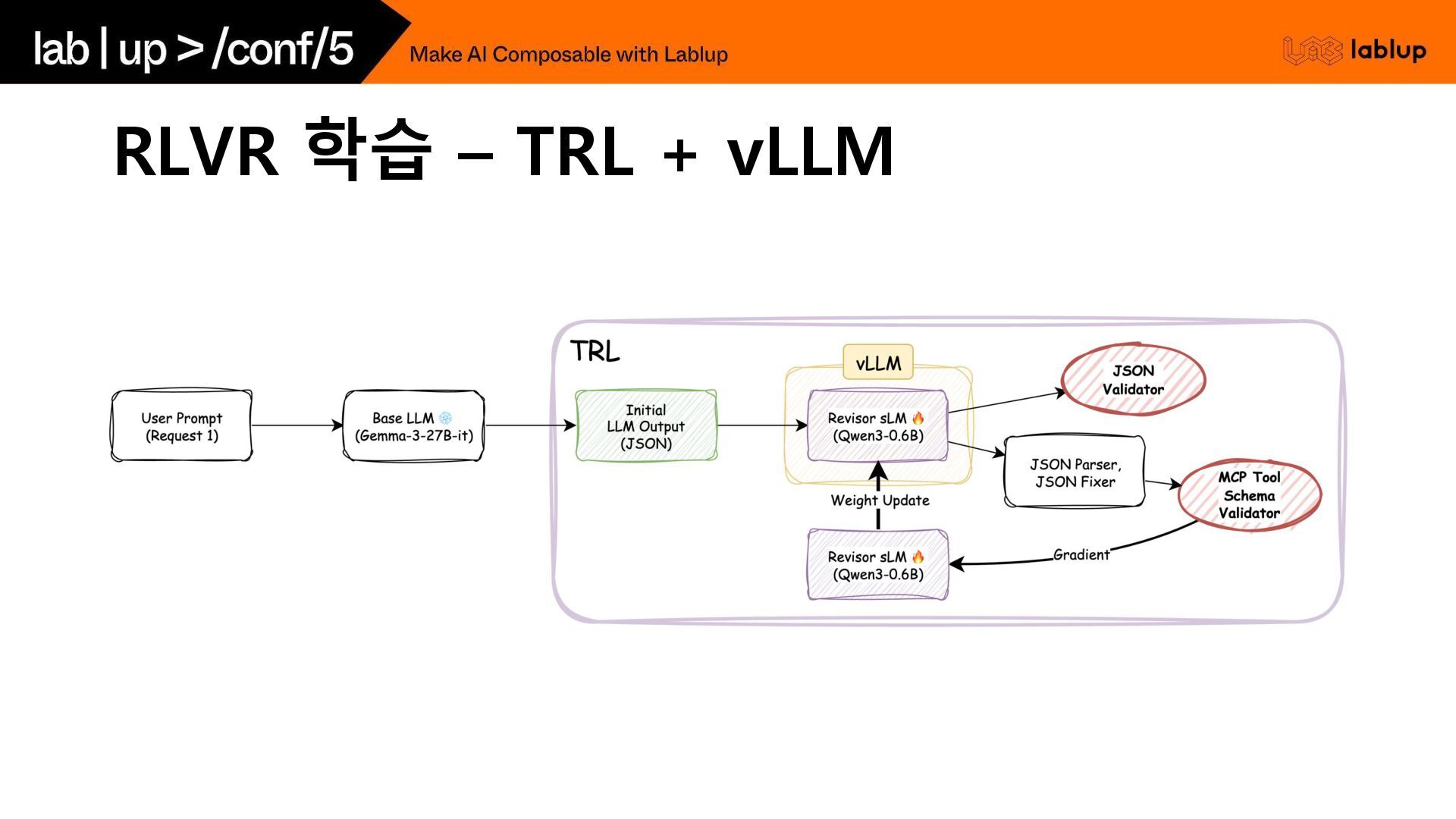
RLVR 학습 – TRL + vLLM
RLVR 학습 – TRL + vLLM
RLVR 학습 – TRL + vLLM
모델 성능 측정은 동일하게
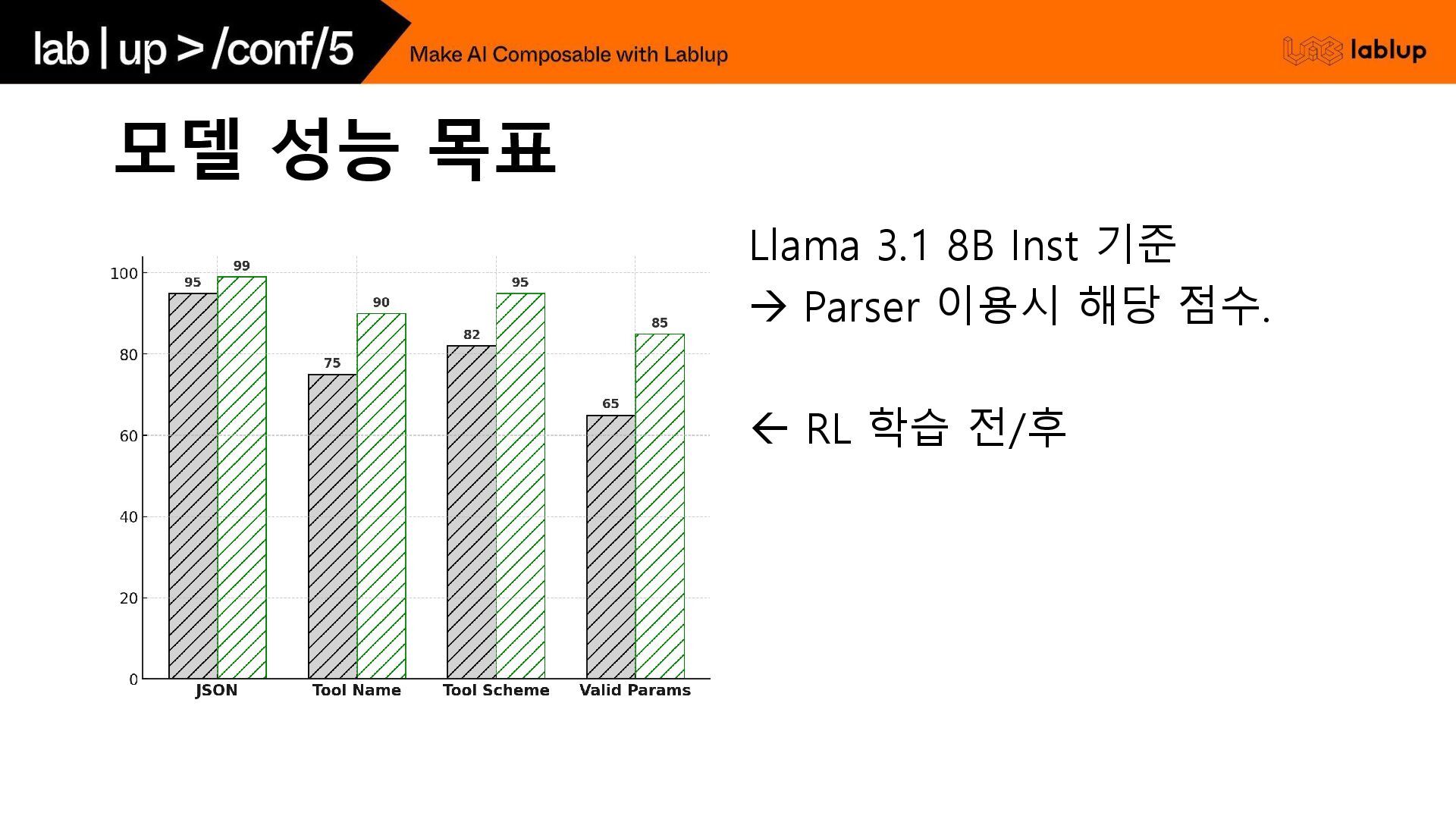
모델 성능 목표 Llama 3.1 8B Inst 기준 → Parser
이용시 해당 점수. RL 학습 전/후
Todo - ing
LLM as Judge, LLM이 주는 Reward
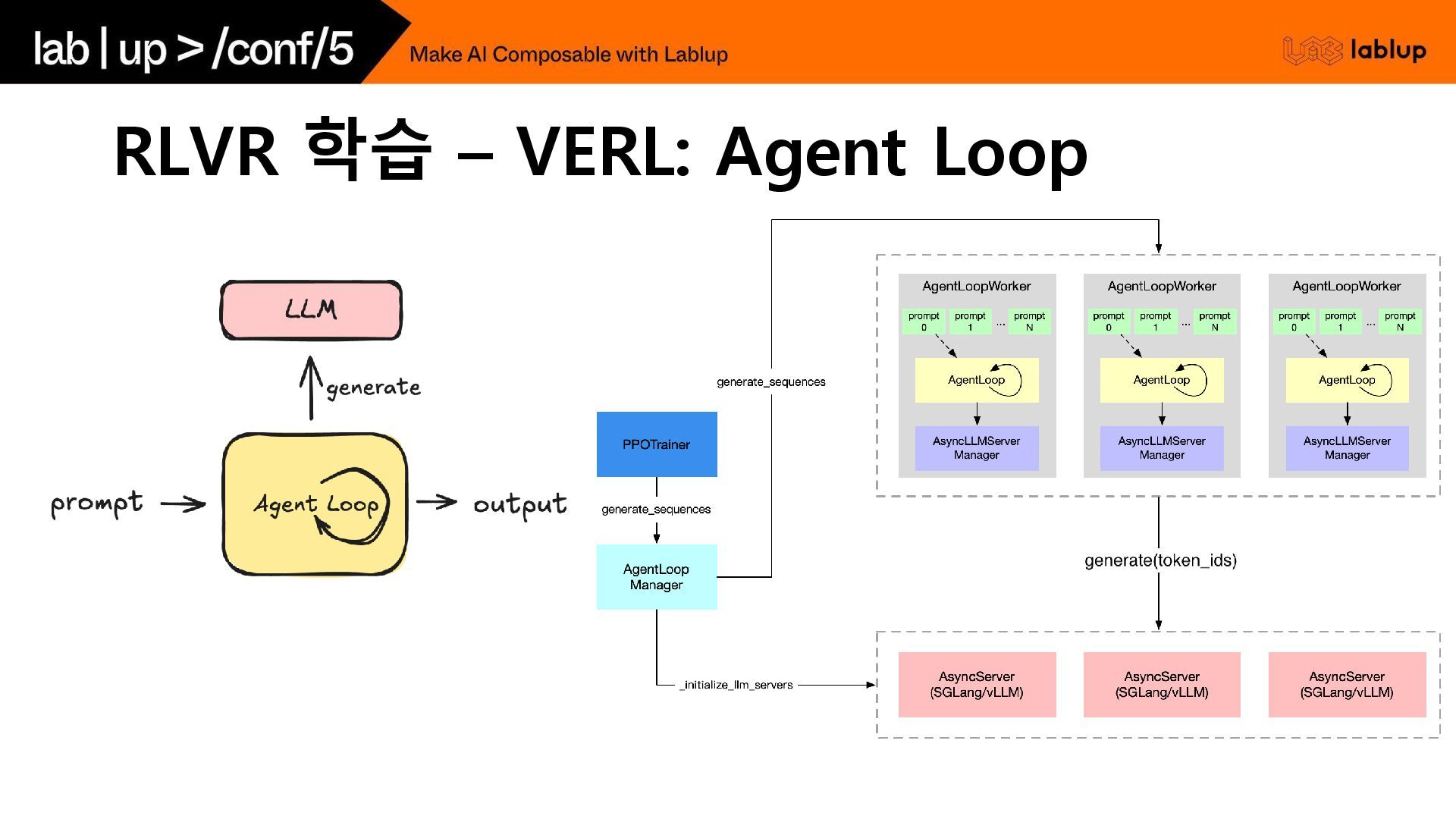
RLVR 학습 – VERL
RLVR 학습 – VERL: Agent Loop
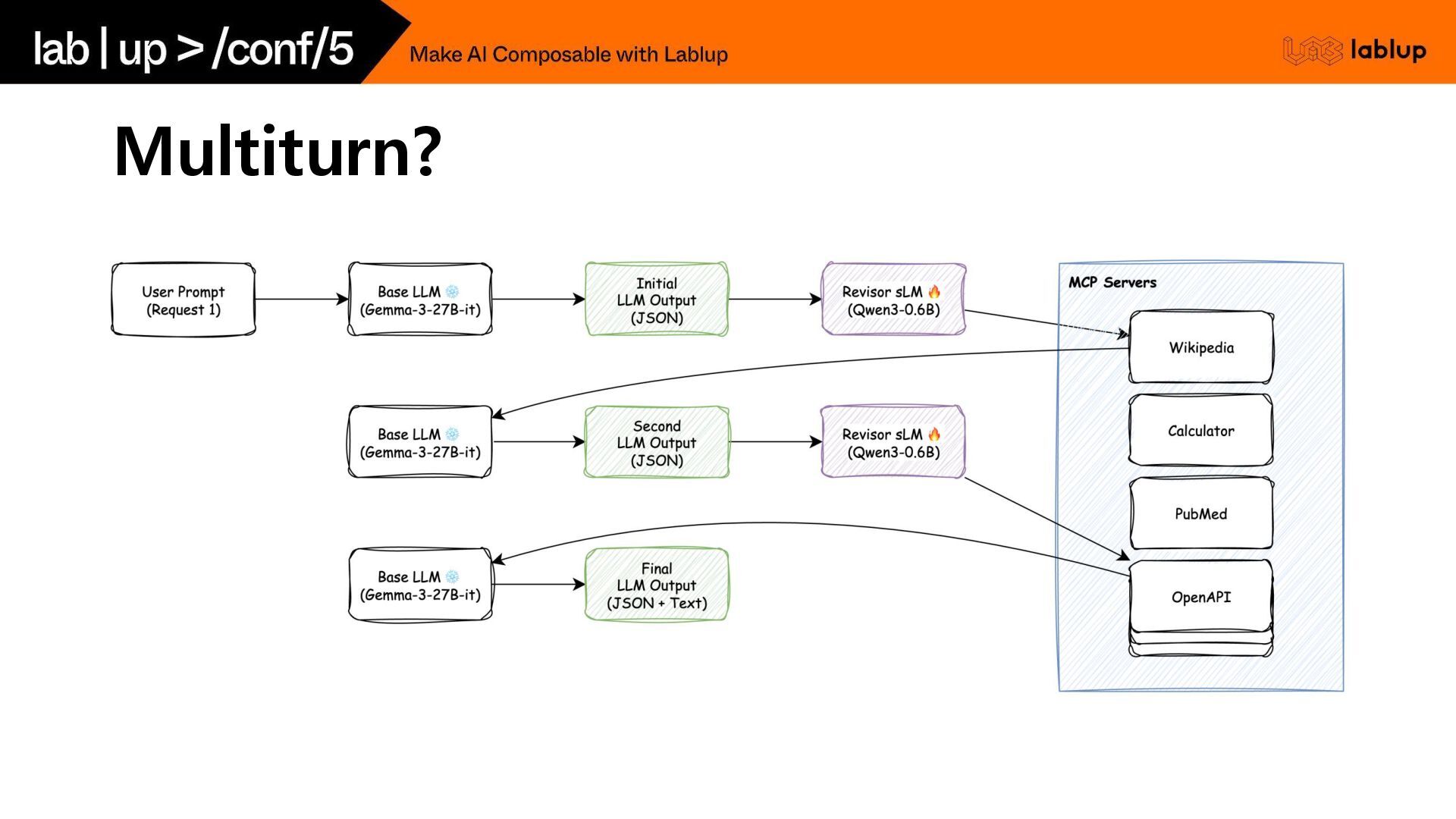
Multiturn?
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}