– 프로그래밍을 하지 않고도 컴퓨터에게 내가 원하는 일 시키기 – 손을 사용하지 않고도 말로만 컴퓨터에게 내가 원하는 일 시키기 드디어 실현된 입코딩의 시대... • 인간의 지적 노동을 어디까지 대체할 수 있을까? – ChatGPT, GenSpark, ... – Claude Code, Gemini CLI, ... – Midjourney, Nano Banana, ... Generated using ChatGPT
더 잘 쓸 수 있게 되는 도구 vs. 아무것도 몰라도 쉽게 사용할 수 있는 도구 – CLI vs. GUI / Vim vs. IDE – UNIX shell 철학 : 특정 단위 작업을 전문적으로 잘 하는 작은 도구들을 조합하기 • AI: 전문가와 대중의 컴퓨팅 패러다임을 연결하는 새로운 고리 – 한 줄의 문장으로 end to end 앱 개발 – 자신의 전문 능력 강화 augmentation – 현실의 AI 사용 패턴은 그 중간 어디쯤... Generated using ChatGPT
언어가 제공하는 다양한 추상화 기법의 활용 – 다른 사람이 만든 코드와 모듈을 적재적소에 재사용하기 • AI 시대의 컴퓨터 사용자에게 composition이란? – 워크로드 유형 별로 가장 적합한 AI agent를 찾아서 조합 – AI agent가 AI agent를 지휘하게 함으로써 규모 키우기 Generated using ChatGPT
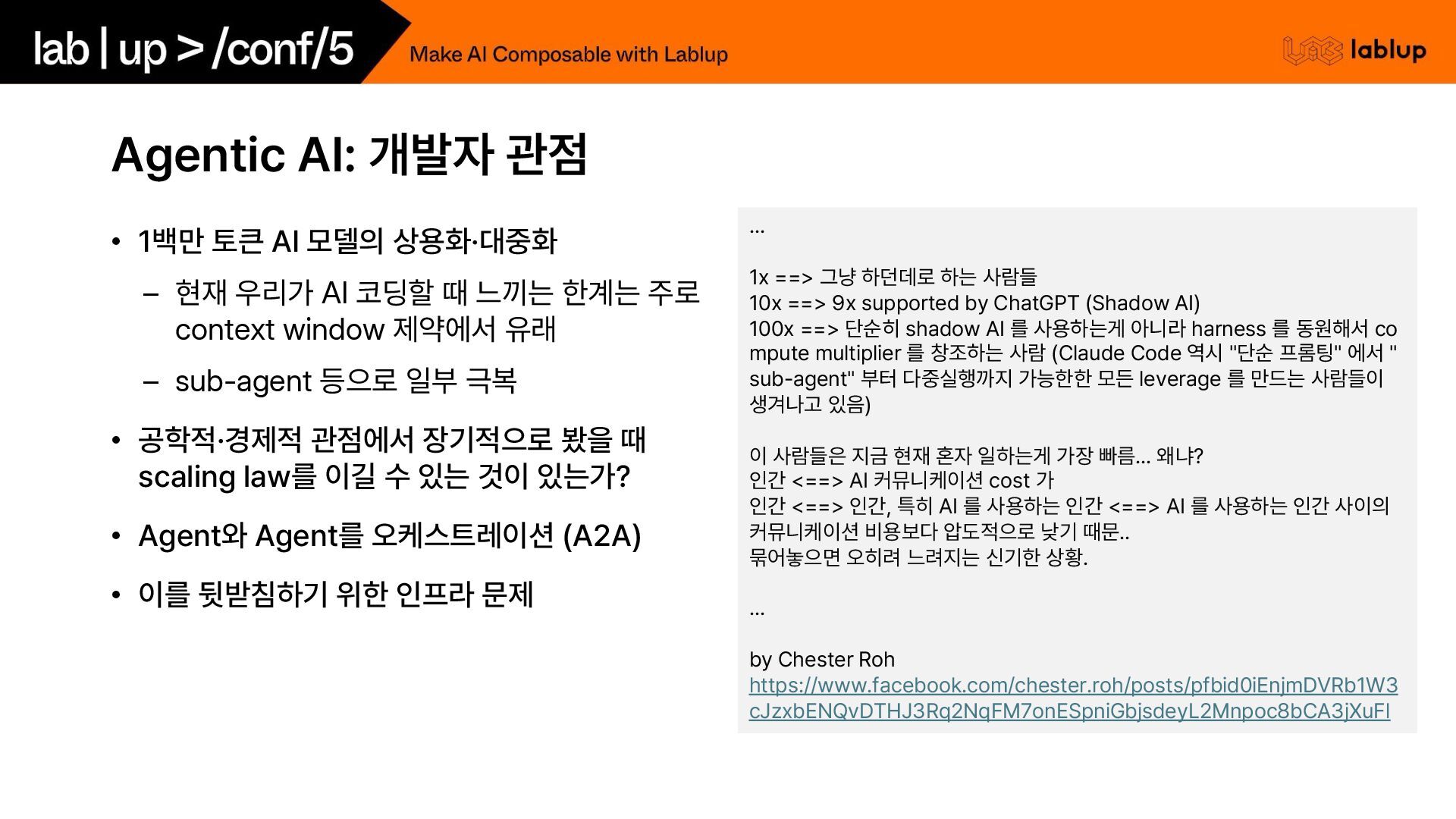
– 현재 우리가 AI 코딩할 때 느끼는 한계는 주로 context window 제약에서 유래 – sub-agent 등으로 일부 극복 • 공학적·경제적 관점에서 장기적으로 봤을 때 scaling law를 이길 수 있는 것이 있는가? • Agent와 Agent를 오케스트레이션 A2A • 이를 뒷받침하기 위한 인프라 문제 ... 1x 그냥 하던데로 하는 사람들 10x 9x supported by ChatGPT Shadow AI 100x 단순히 shadow AI 를 사용하는게 아니라 harness 를 동원해서 co mpute multiplier 를 창조하는 사람 Claude Code 역시 단순 프롬팅 에서 sub agent 부터 다중실행까지 가능한한 모든 leverage 를 만드는 사람들이 생겨나고 있음 이 사람들은 지금 현재 혼자 일하는게 가장 빠름... 왜냐? 인간 AI 커뮤니케이션 cost 가 인간 인간, 특히 AI 를 사용하는 인간 AI 를 사용하는 인간 사이의 커뮤니케이션 비용보다 압도적으로 낮기 때문.. 묶어놓으면 오히려 느려지는 신기한 상황. ... by Chester Roh https://www.facebook.com/chester.roh/posts/pfbid0iEnjmDVRb1W3 cJzxbENQvDTHJ3Rq2NqFM7onESpniGbjsdeyL2Mnpoc8bCA3jXuFl
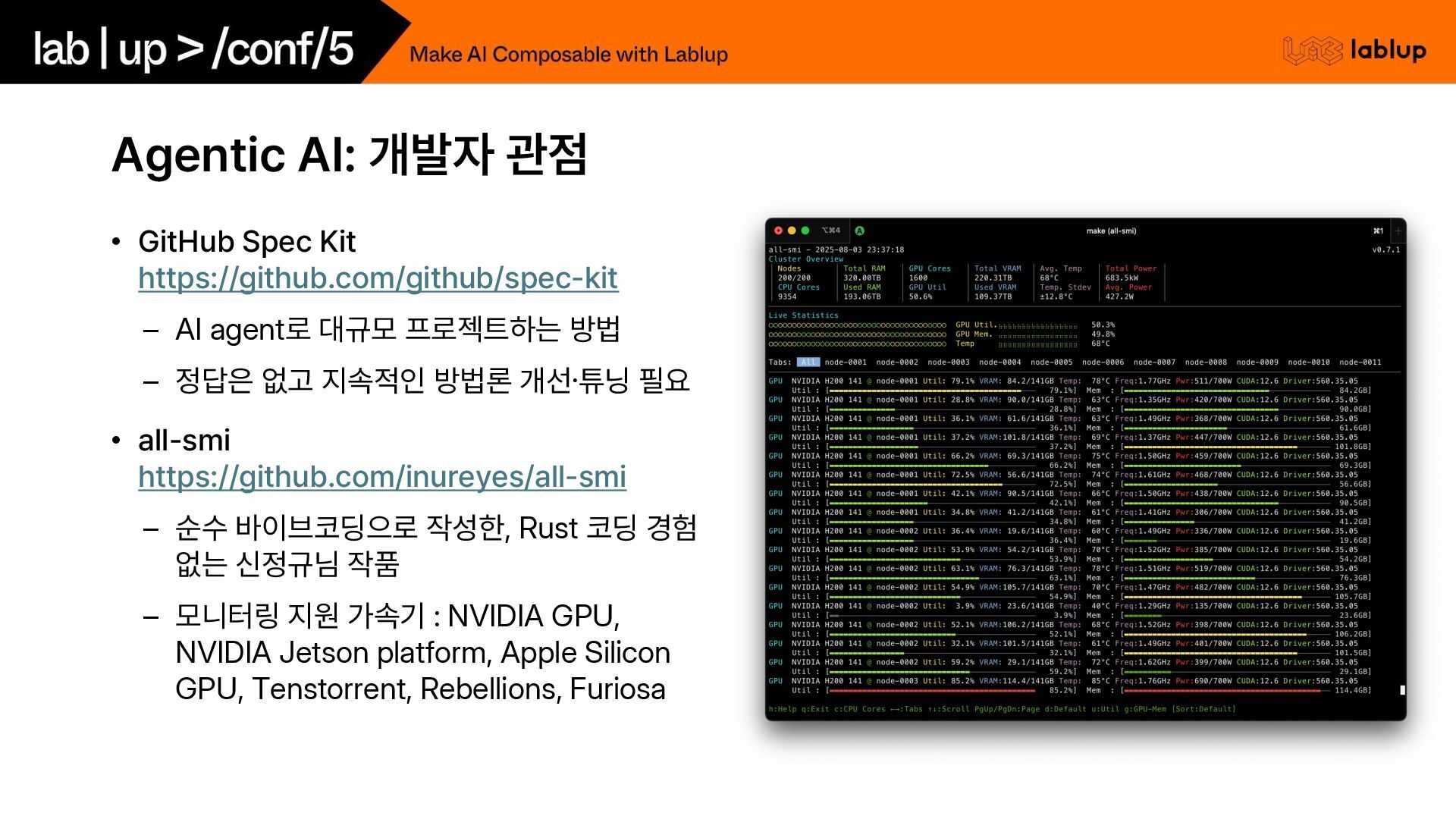
– AI agent로 대규모 프로젝트하는 방법 – 정답은 없고 지속적인 방법론 개선·튜닝 필요 • all smi https://github.com/inureyes/all smi – 순수 바이브코딩으로 작성한, Rust 코딩 경험 없는 신정규님 작품 – 모니터링 지원 가속기 : NVIDIA GPU, NVIDIA Jetson platform, Apple Silicon GPU, Tenstorrent, Rebellions, Furiosa
– (실제로는 입력/출력/사고 등으로 토큰 종류 구분) • 데이터센터는 곧 AI Token을 생성해내는 공장이다! – 제조업이 되는 순간 수요에 따라 수익이 증가 • AI Agent들을 돌려주는 지능 인프라 • 단위 면적, 단위 에너지 당 가장 많은 토큰을 뽑아내려면 뭘 해야 하는가?
물리적 인프라 : 에너지 밀도, 환경, 지속가능성 – Throughput-oriented computing ✓ 최대 성능은 하드웨어가 결정 ✓ 최대 효율은 소프트웨어가 결정 – 표준화된 단일 하드웨어 아키텍처 → 용도별로 특화된 이종 하드웨어 아키텍처 ✓ POSIX API 바깥에서 벌어지는 일들! – AI를 개발·배포·사용하는 과정의 모든 기술적 장애 요소 제거 ✓ 주로 소프트웨어 관점에서 AI Ready Datacenters Meetup @ Plug and Play Tech Center, Sunnyvale 2025-09-11
내부 지연으로 인한 전체 시스템 속도 저하 냉각 인프라 Cooling Infrastructure 냉각이 부족한 경우 성능 저하 발생 활용 효율성 Utilization Efficiency AI 리소스 이용에 따르는 활용 부족과 자원 불균형 가시성/텔레메트리 Observability / Telemetry 적절한 시스템 모니터링 및 진단의 중요성 스케줄러 확장성 Scheduler Scalability 복잡한 작업 부하에 필요한 확장 가능한 스케줄링 데이터/모델 보안 Data / Model Security 진화하는 보안 위협과 점점 복잡해지는 시스템
: "World-Best LLM" – 현금 과제비 지원 대신 LLM 훈련을 위한 GPU 자원 제공 – 공개시점 기준 세계 최고수준 LLM의 95 이상 성능 달성 목표 • 프로젝트 진행방식 – 5개 컨소시엄 선정하여 6개월마다 평가하여 하위 1개팀 탈락, 최종 2개팀 선발 후 1년 추가 지원 – 8월 중순 킥오프하여 현재 활발히 개발 진행 중 • 래블업 – 업스테이지 컨소시엄에 참여하여 분산 딥러닝 훈련 플랫폼으로 Backend.AI 제공 – 과제 진행에 따라 GPU 가상화 기술 고도화 및 LLM 평가·검증 과정에서 추가적인 R D 협력 예정
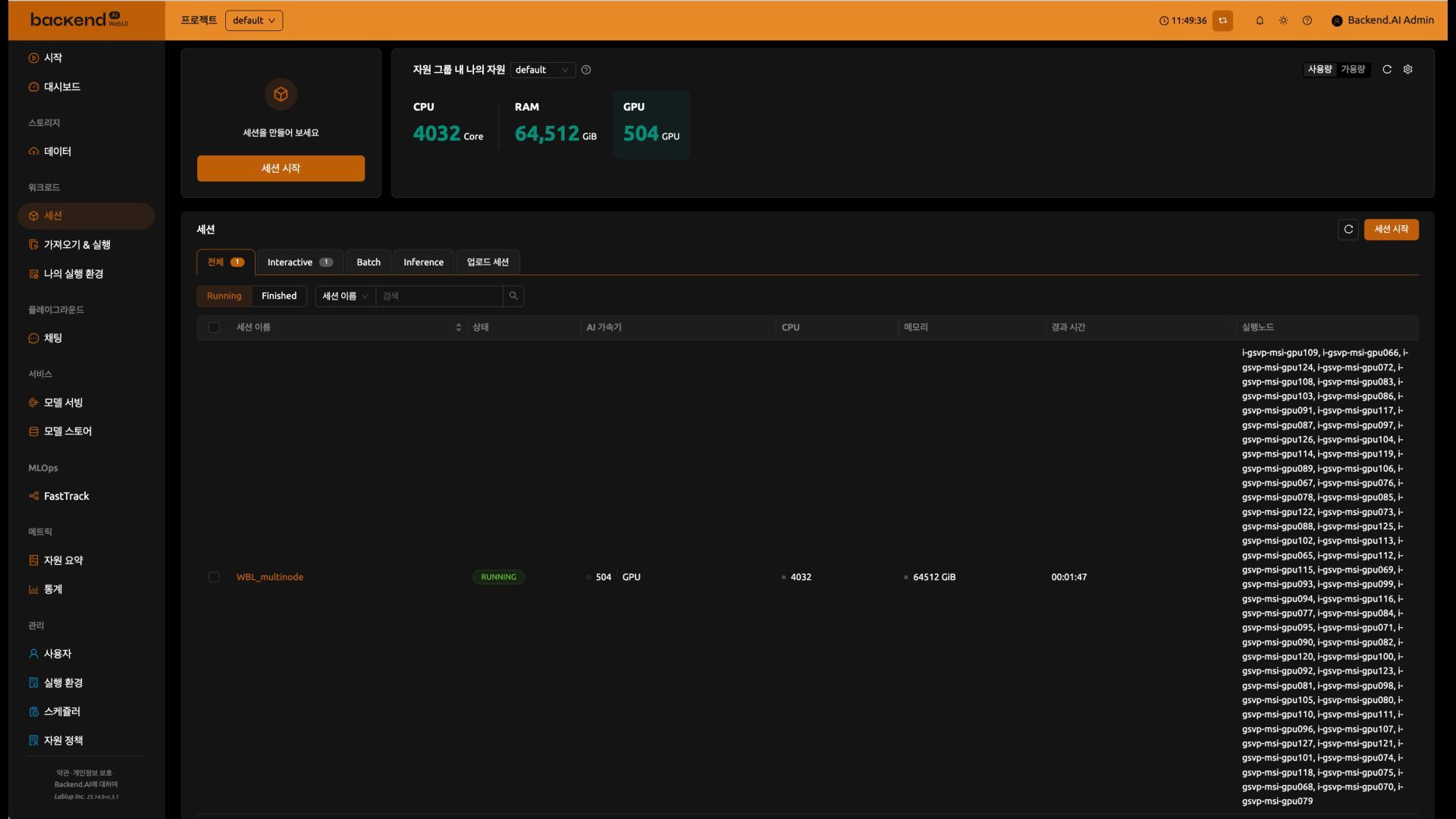
100B 크기 LLM • 자원 할당 : 60노드 (480 GPUs) + 3개의 예비·테스트용 노드 – 노드 별 사양 : 120코어 CPU, 2 TiB RAM, NVIDIA B200 8장, 400G IB 8포트, 스토리지용 200G RoCE • 주요 프레임워크 및 라이브러리 버전 – PyTorch 2.9 nightly TorchTitan 0.2.0 in dev – CUDA 13.0, NCCL 2.28.3 • 워크로드 특이사항 – 하나의 거대한 작업이 대부분의 시간 동안 대부분의 연산 자원 독차지 – 하드웨어·소프트웨어 장애가 발생하더라도 main training job은 계속 유지되어야 함 Workload & Infra Manager SKT GPU cluster Training Jobs Datacenter
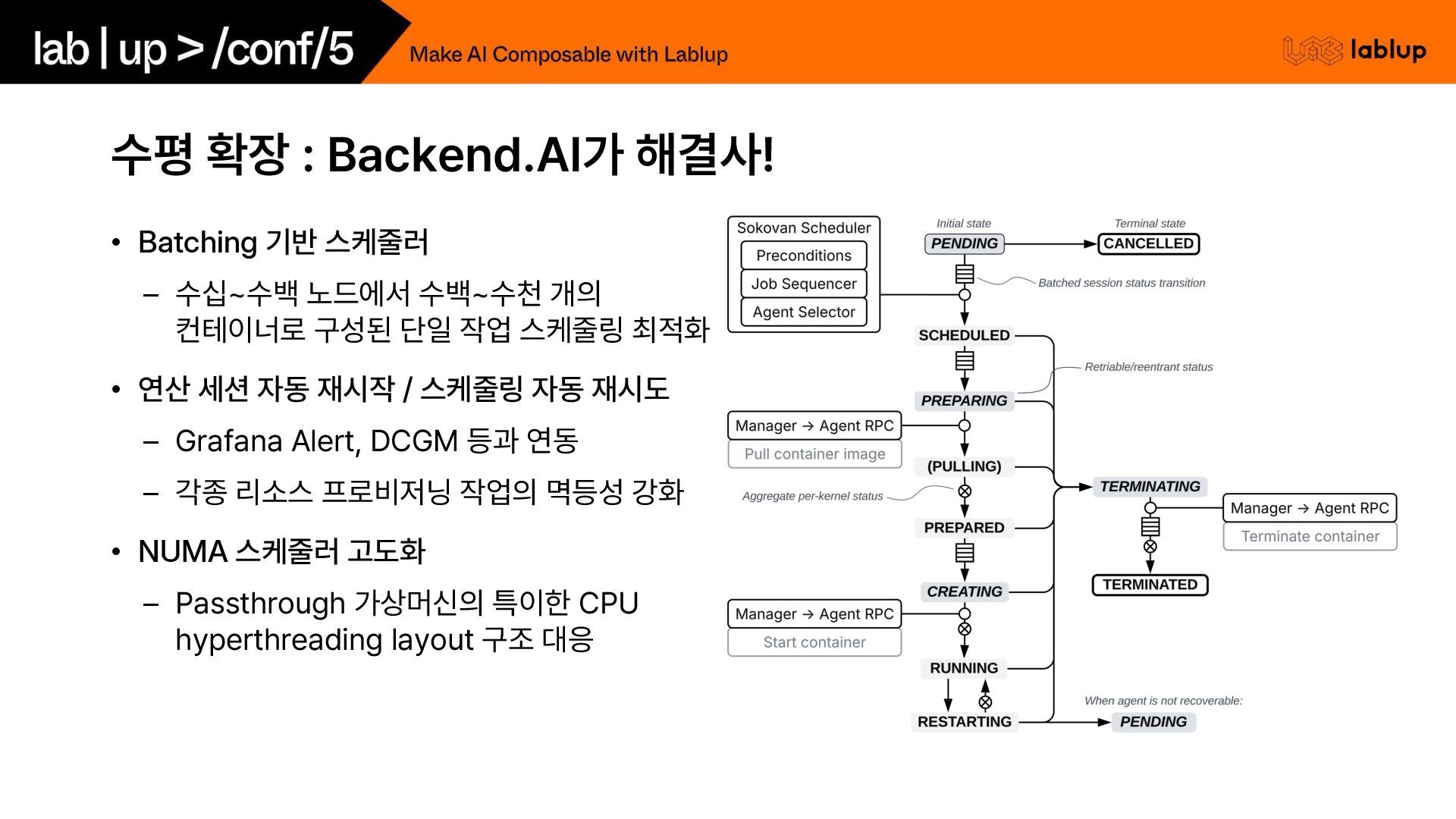
수십 수백 노드에서 수백 수천 개의 컨테이너로 구성된 단일 작업 스케줄링 최적화 • 연산 세션 자동 재시작 / 스케줄링 자동 재시도 – Grafana Alert, DCGM 등과 연동 – 각종 리소스 프로비저닝 작업의 멱등성 강화 • NUMA 스케줄러 고도화 – Passthrough 가상머신의 특이한 CPU hyperthreading layout 구조 대응
가속까지 스택 전반 작동에 대한 배경지식 필요 – 특정 이슈의 구체적인 원인 파악을 위해 전체 스택을 다 훑어야 하는 경우 비일비재 – 모델 코드 / 연산 라이브러리 및 딥러닝 프레임워크 / 오케스트레이션 플랫폼·스케줄러 / 호스트 운영체제, 하드웨어 및 드라이버 / 네트워크 및 스토리지 • Blackwell 환경에서의 MXFP8 처리 성능·안정성 이슈 – 오픈소스 라이브러리 및 드라이버 대응 시차 문제 – 훈련이 진행되는 동안에도 최신 버전의 드라이버와 라이브러리 적용 필요 • RoCE 및 Infiniband 최적화 – 네트워크 스위치의 MTU mismatch 이슈 – 수많은 NCCL 옵션 조합 켜거나 꺼야만 동작하는 경우부터 직간접적인 성능 차이까지...
– 슈퍼컴퓨팅, 빅데이터, GPU 가속, 클라우드 컴퓨팅 등 기존 모든 전산 분야 총망라 및 집대성 • 수평 확장을 위한 시스템 디자인 원리 : Batching, Parallelization, Pipelining – 실질적 문제 해결 : 모델 응용 영역부터 시스템 레벨까지 통합적·유기적 협업 필요 – PyTorch로 모델 개발도 잘 하면서 mmap 최적화 이슈도 볼 수 있는 사람? • 차세대 기술 이슈 – Disaggregated Serving: 비용절감을 위한 연산 단계별 성능 특성 레버리지 극대화 – Confidential Computing: MCP Agent VM을 위한 개인정보 보호 및 보안
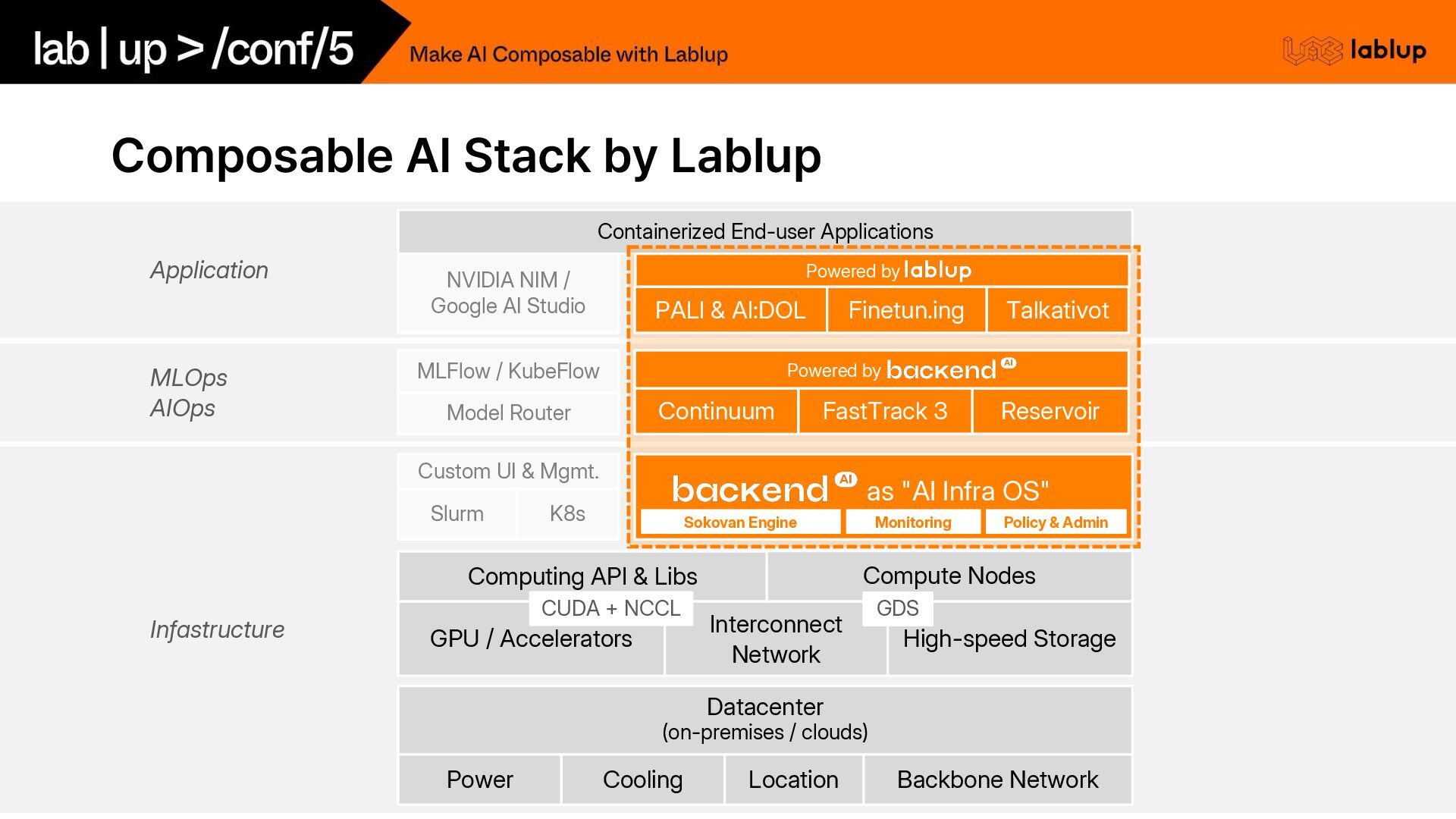
– 다양한 구조와 크기의 모델, 훈련과 추론의 조합 RL – 차세대 기술 이슈 disaggregated serving, confidential computing 통합 – 하드웨어와 강하게 결합 고객사에 배포하고 기술지원하려면? • Backend.AI로 뒷받침하는 Scale & Composability – 엔터프라이즈 배포 환경을 지원하는 Backend.AI 코어 플랫폼 기반 – 폐쇄망·클라우드 동시 지원 MLOps 개인화·도구화된 생성형 AI 서비스 – Backend.AI의 강점인 가속 기술 수직 통합 및 최적화 활용
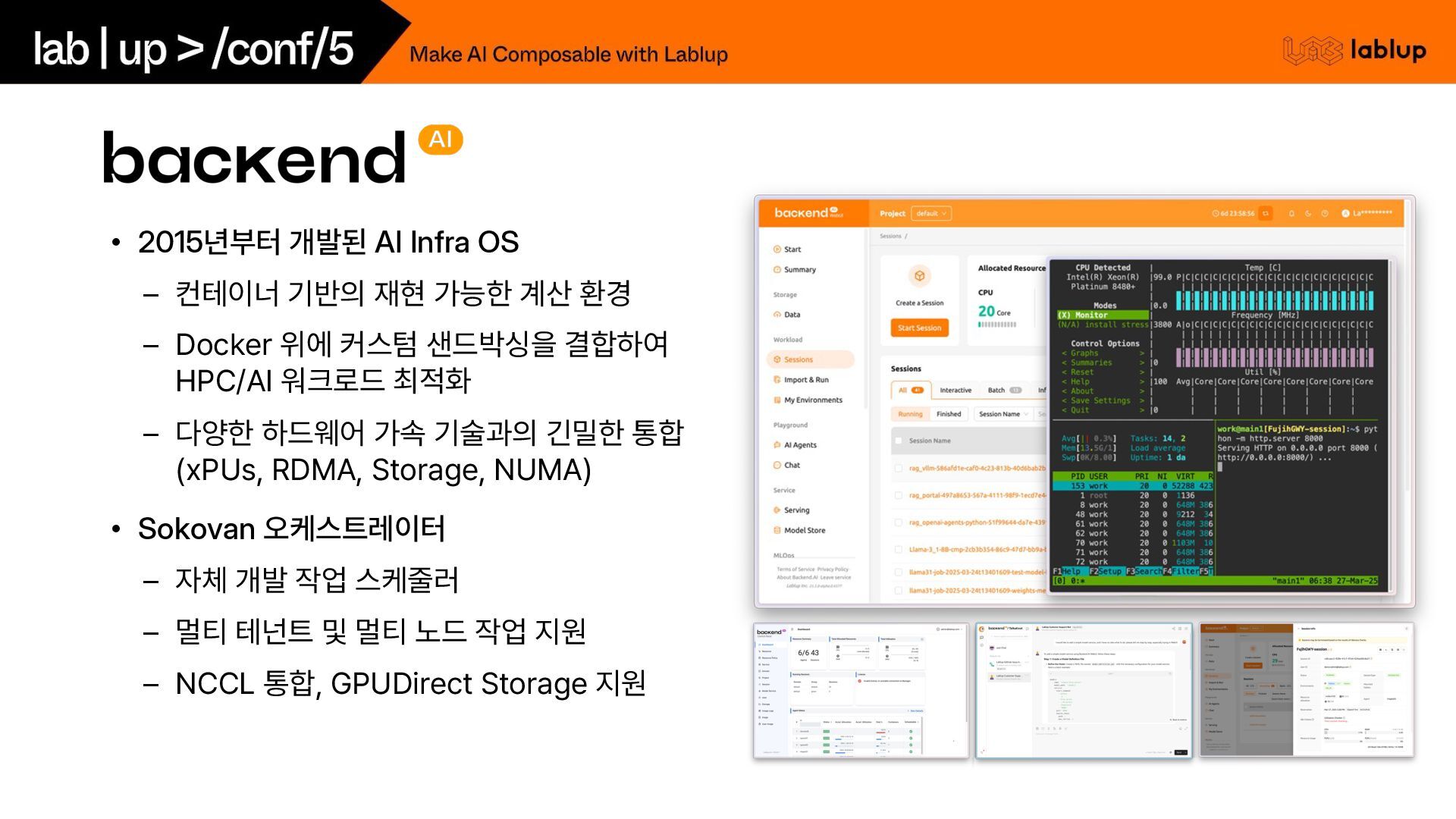
재현 가능한 계산 환경 – Docker 위에 커스텀 샌드박싱을 결합하여 HPC/AI 워크로드 최적화 – 다양한 하드웨어 가속 기술과의 긴밀한 통합 xPUs, RDMA, Storage, NUMA • Sokovan 오케스트레이터 – 자체 개발 작업 스케줄러 – 멀티 테넌트 및 멀티 노드 작업 지원 – NCCL 통합, GPUDirect Storage 지원
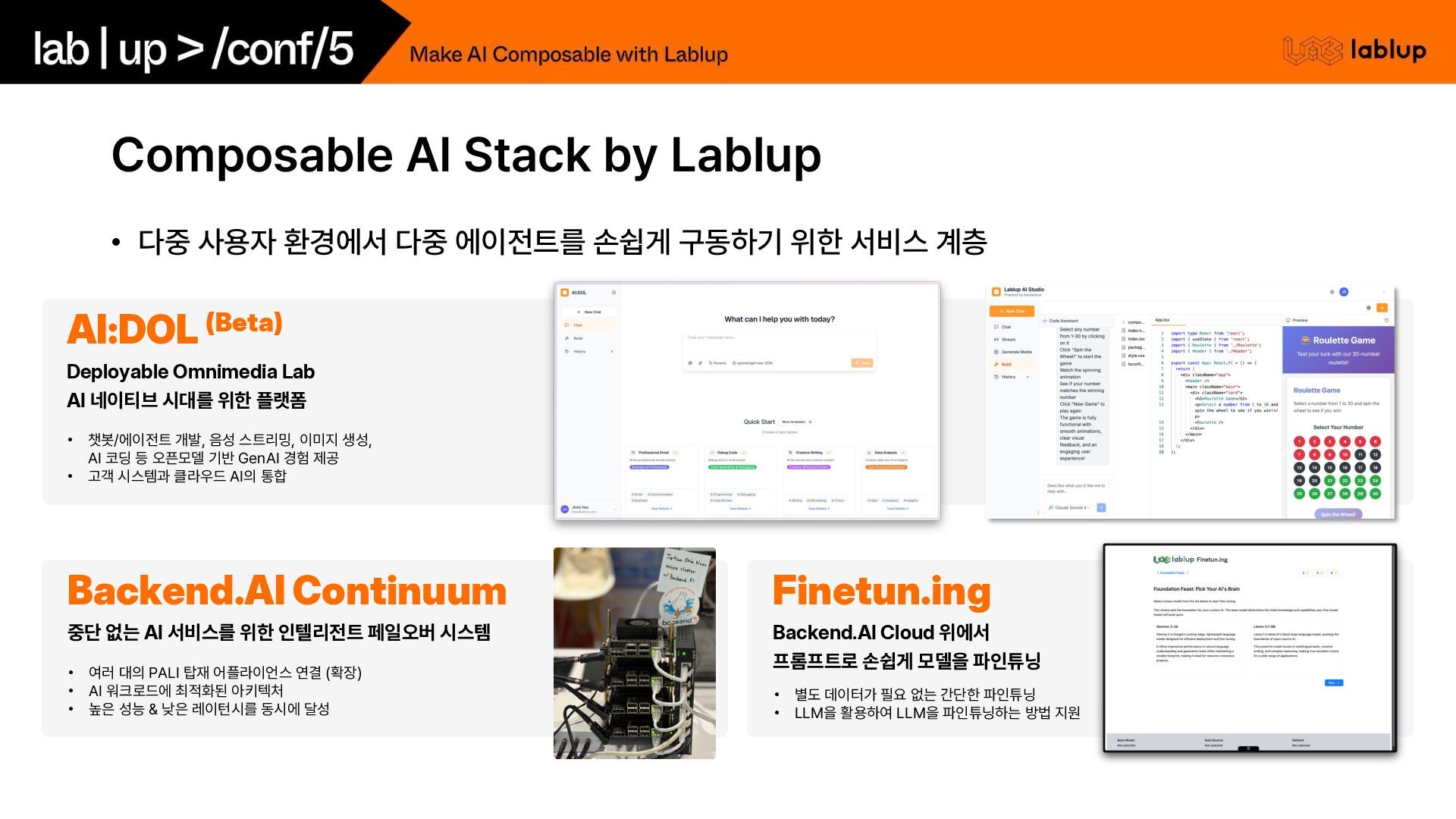
에이전트를 손쉽게 구동하기 위한 서비스 계층 AI:DOL (Beta) Deployable Omnimedia Lab AI 네이티브 시대를 위한 플랫폼 Backend.AI Continuum 중단 없는 AI 서비스를 위한 인텔리전트 페일오버 시스템 • 챗봇/에이전트 개발, 음성 스트리밍, 이미지 생성, AI 코딩 등 오픈모델 기반 GenAI 경험 제공 • 고객 시스템과 클라우드 AI의 통합 • 여러 대의 PALI 탑재 어플라이언스 연결 확장 • AI 워크로드에 최적화된 아키텍처 • 높은 성능 낮은 레이턴시를 동시에 달성 Finetun.ing Backend.AI Cloud 위에서 프롬프트로 손쉽게 모델을 파인튜닝 • 별도 데이터가 필요 없는 간단한 파인튜닝 • LLM을 활용하여 LLM을 파인튜닝하는 방법 지원
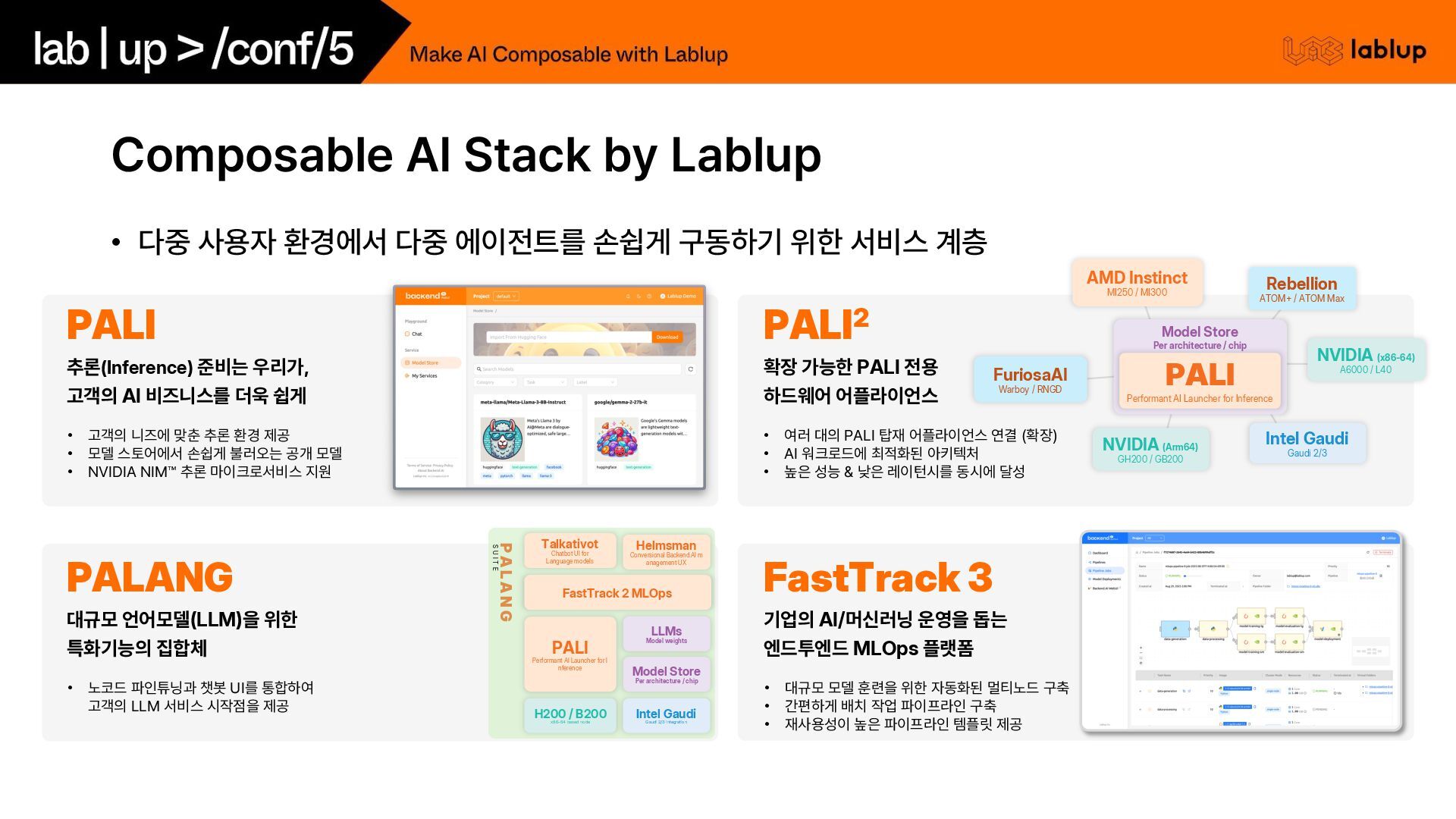
에이전트를 손쉽게 구동하기 위한 서비스 계층 PALI 추론(Inference) 준비는 우리가, 고객의 AI 비즈니스를 더욱 쉽게 PALI2 확장 가능한 PALI 전용 하드웨어 어플라이언스 • 고객의 니즈에 맞춘 추론 환경 제공 • 모델 스토어에서 손쉽게 불러오는 공개 모델 • NVIDIA NIM 추론 마이크로서비스 지원 • 여러 대의 PALI 탑재 어플라이언스 연결 확장 • AI 워크로드에 최적화된 아키텍처 • 높은 성능 낮은 레이턴시를 동시에 달성 PALANG 대규모 언어모델(LLM)을 위한 특화기능의 집합체 • 노코드 파인튜닝과 챗봇 UI를 통합하여 고객의 LLM 서비스 시작점을 제공 FastTrack 3 기업의 AI/머신러닝 운영을 돕는 엔드투엔드 MLOps 플랫폼 • 대규모 모델 훈련을 위한 자동화된 멀티노드 구축 • 간편하게 배치 작업 파이프라인 구축 • 재사용성이 높은 파이프라인 템플릿 제공 Rebellion ATOM+ / ATOM Max AMD Instinct MI250 / MI300 FuriosaAI Warboy / RNGD NVIDIA (Arm64) GH200 / GB200 Intel Gaudi Gaudi 2/3 NVIDIA (x86-64) A6000 / L40 Model Store Per architecture / chip PALI Performant AI Launcher for Inference PALI Performant AI Launcher for I nference Model Store Per architecture / chip FastTrack 2 MLOps Helmsman Conversional Backend.AI m anagement UX Talkativot Chatbot UI for Language models LLMs Model weights H200 / B200 x86-64 based node Intel Gaudi Gaudi 2/3 integration P A L A N G S U I T E
{kind=link}
{kind=link}
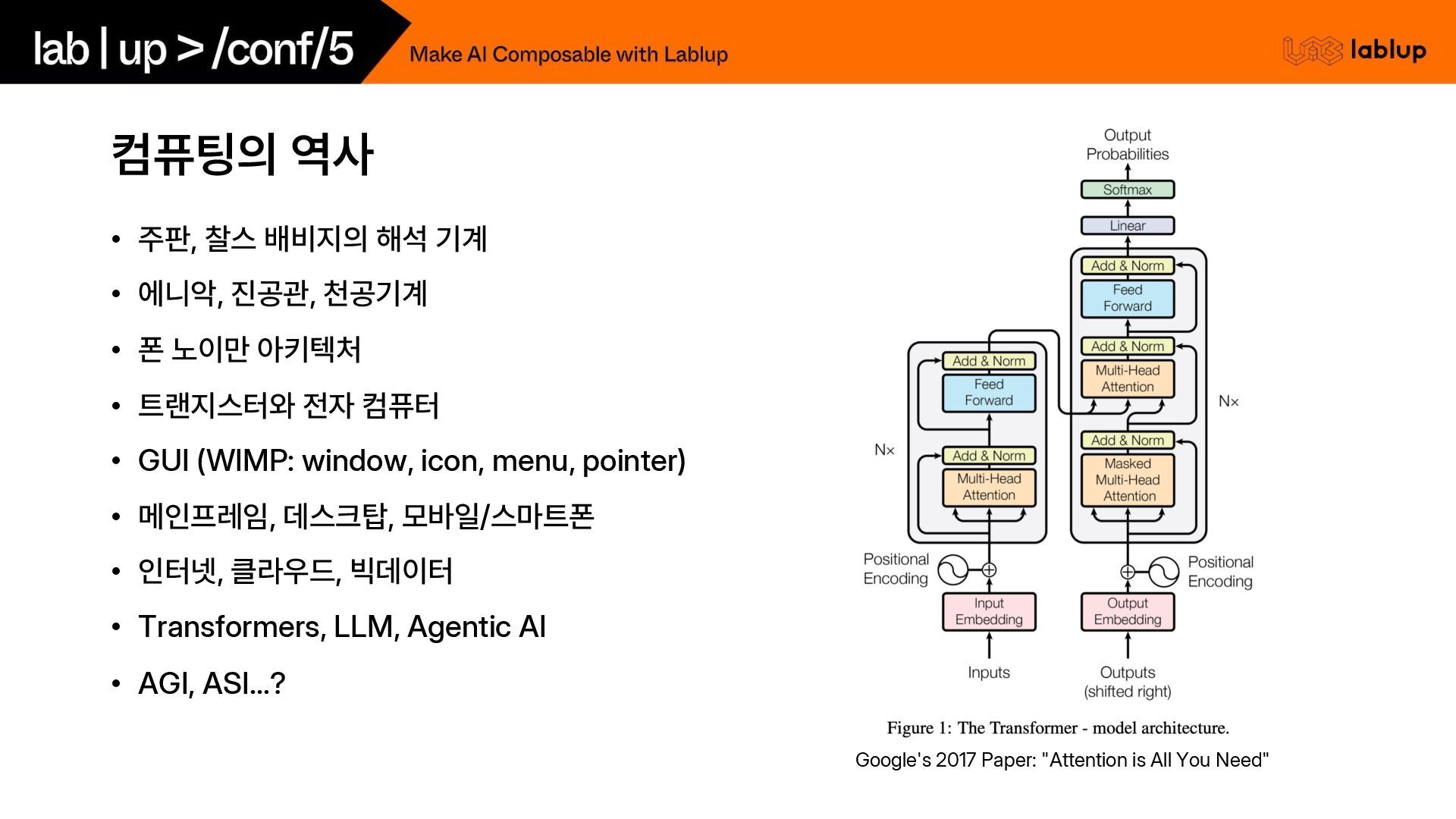{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
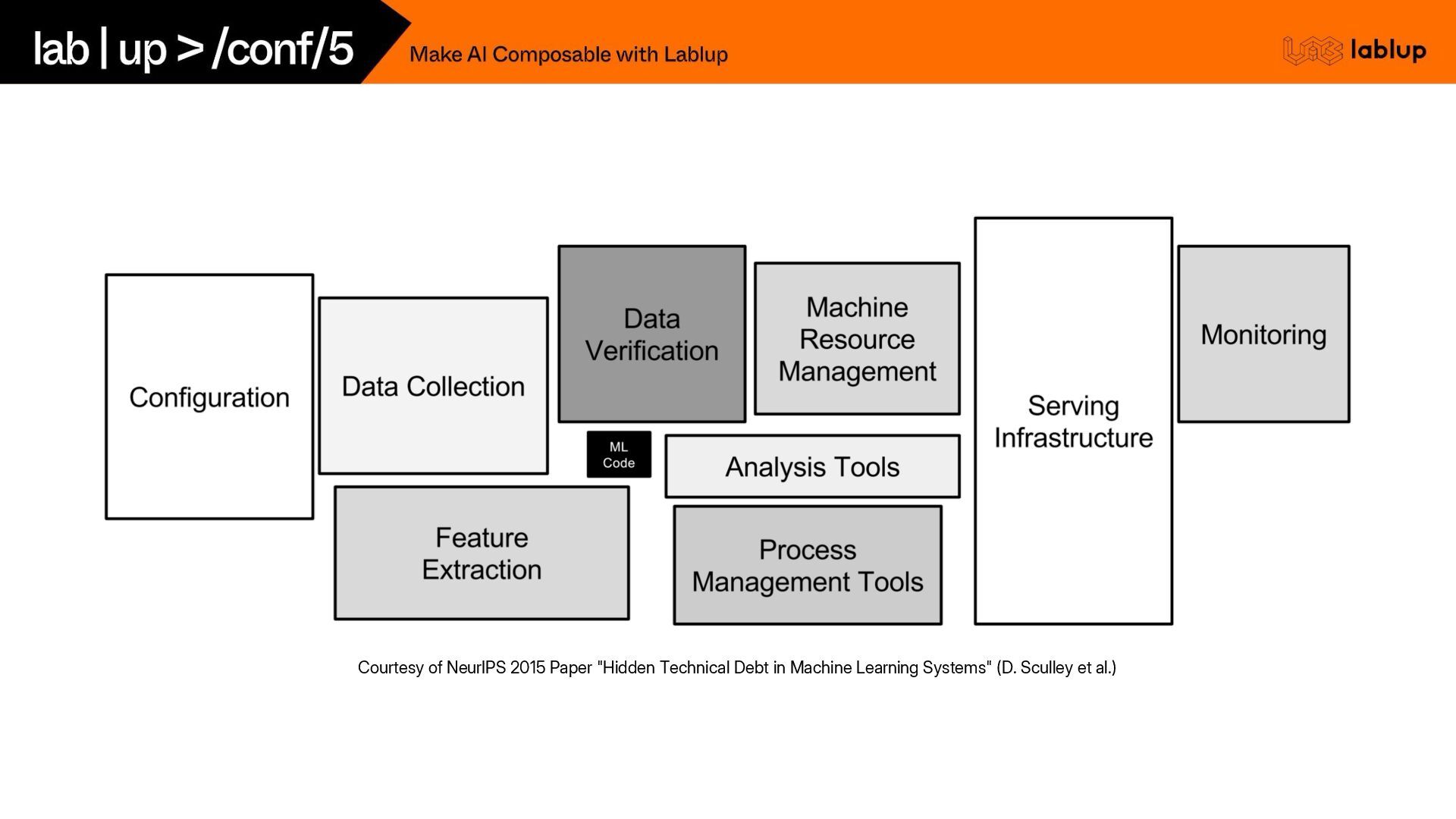{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}