Explicit 情報検索 Information Retrieval 関係データベース Relational Database 暗黙的 Implicit 推薦システム Recommender System 未知 Unknown データマイニング Data Mining Ricardo Baeza-Yates. 2020. Bias in Search and Recommender Systems. In Proceedings of the 14th ACM Conference on Recommender Systems (RecSys '20). Association for Computing Machinery, New York, NY, USA, 2. https://doi.org/10.1145/3383313.3418435
大谷 純, 加藤 遼, 鈴木翔吾, 河 野晋策 情報検索 :検索エンジンの実 装と評価 Stefan Büttcher, Charles L. A. Clarke, Gordon V. Cormack 梅澤 克之, Neil Rubens, 松田 健, 三川 健太, 水野 信也, 山本 健司 (翻訳) Introduction to Information Retrieval Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze 書籍
Explicit 情報検索 Information Retrieval 関係データベース Relational Database 暗黙的 Implicit 推薦システム Recommender System 未知 Unknown データマイニング Data Mining Ricardo Baeza-Yates. 2020. Bias in Search and Recommender Systems. In Proceedings of the 14th ACM Conference on Recommender Systems (RecSys '20). Association for Computing Machinery, New York, NY, USA, 2. https://doi.org/10.1145/3383313.3418435
Recommender Systems The Textbook Charu C. Aggarwal 情報推薦システム入門 -理論 と実践- Dietmar Jannach, Markus Zanker, Alexander Felfernig, Gerhard Friedrich 田中 克己, 角谷 和俊 (翻訳) 書籍
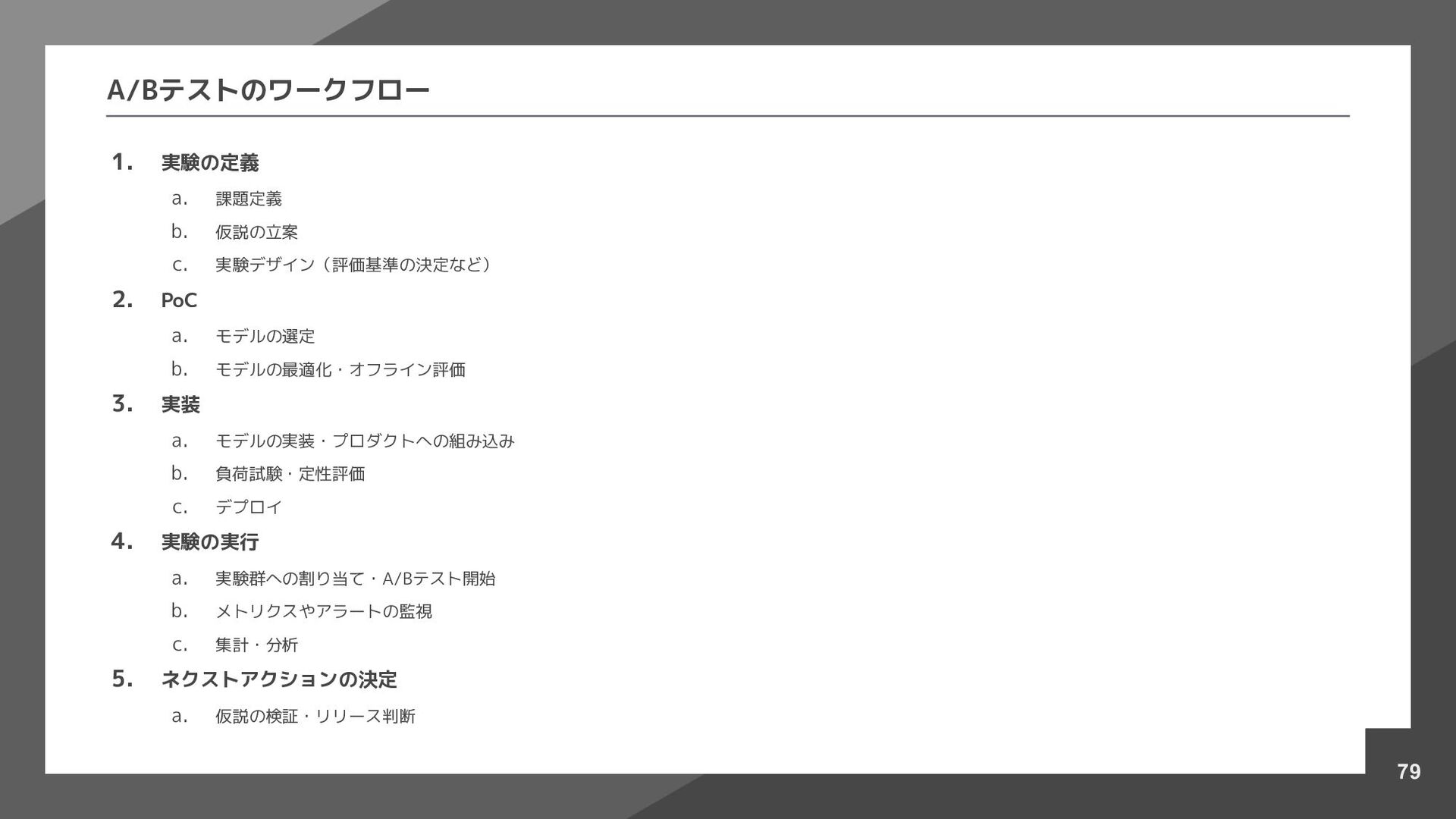
PoC a. モデルの選定 b. モデルの最適化・オフライン評価 3. 実装 a. モデルの実装・プロダクトへの組み込み b. 負荷試験・定性評価 c. デプロイ 4. 実験の実行 a. 実験群への割り当て・A/Bテスト開始 b. メトリクスやアラートの監視 c. 集計・分析 5. ネクストアクションの決定 a. 仮説の検証・リリース判断 A/Bテストのワークフロー
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
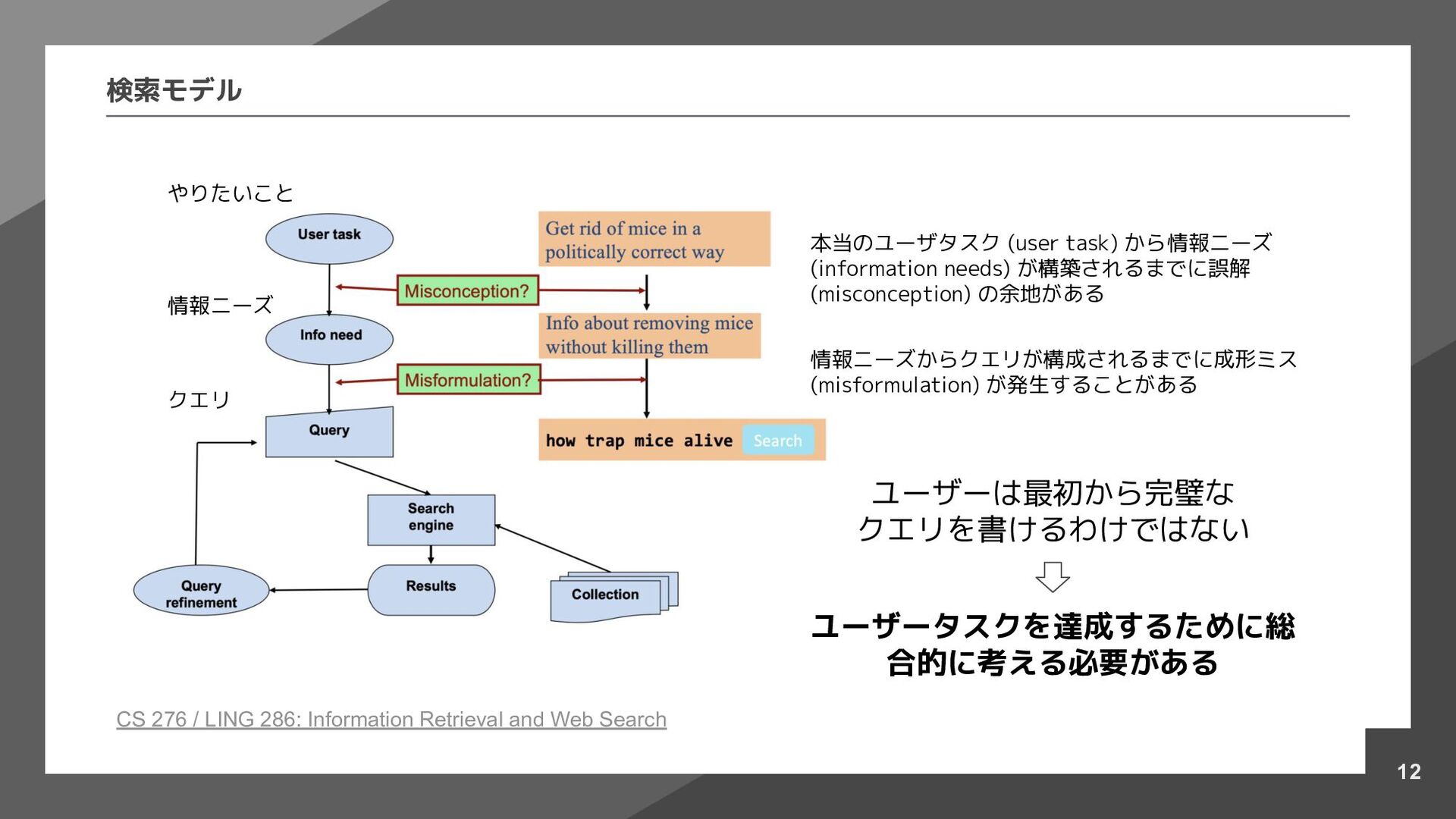{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}