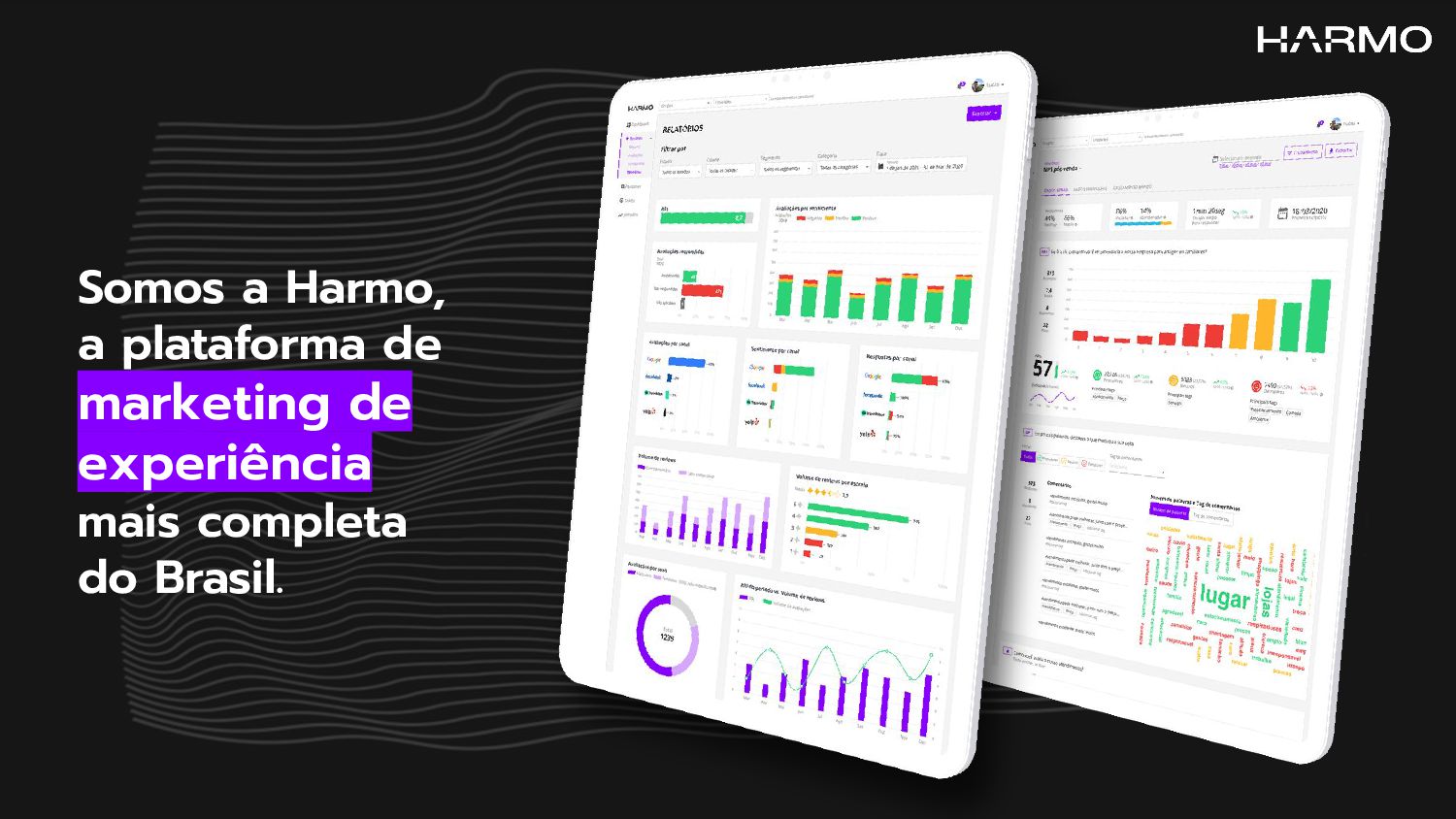
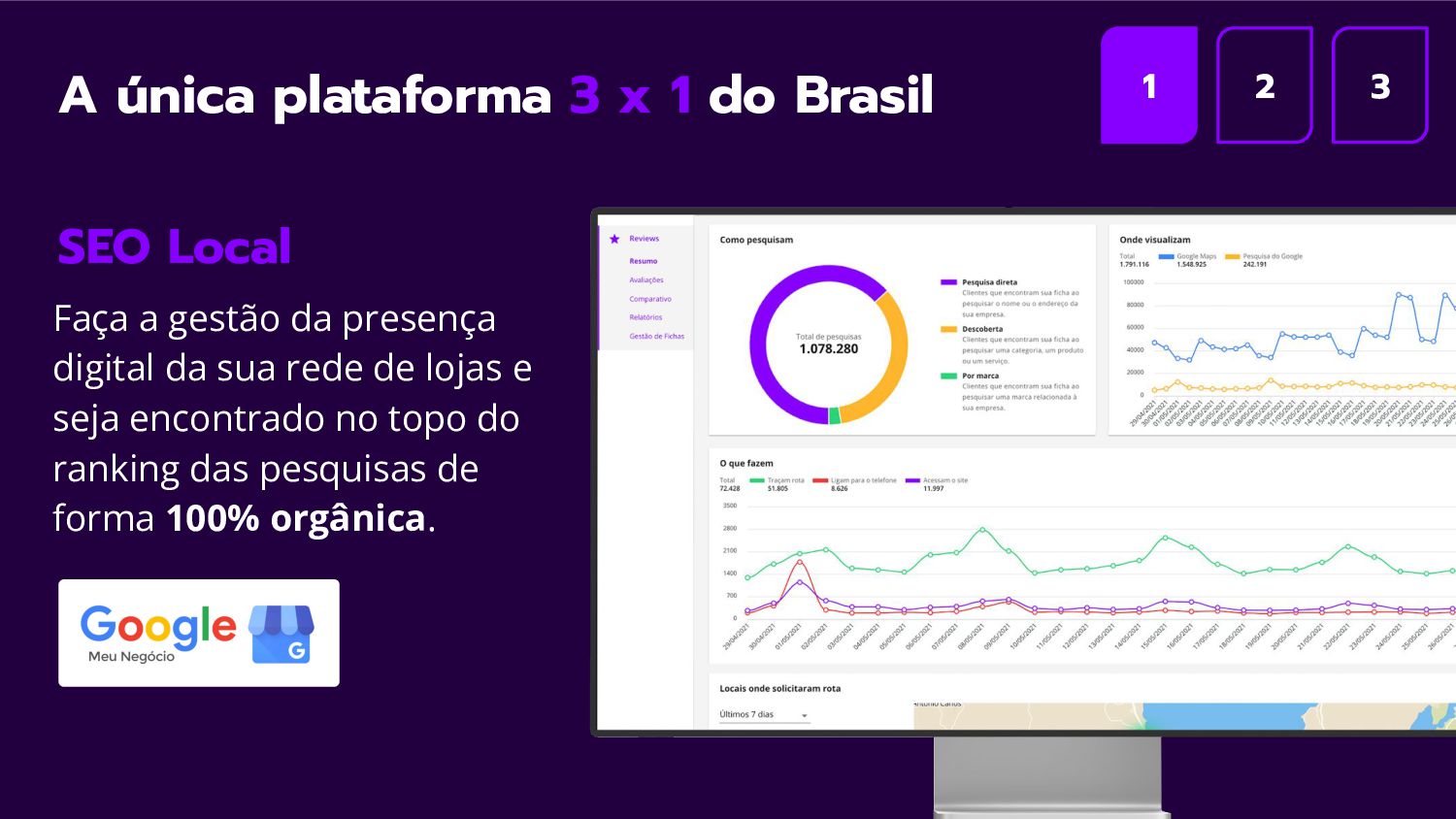
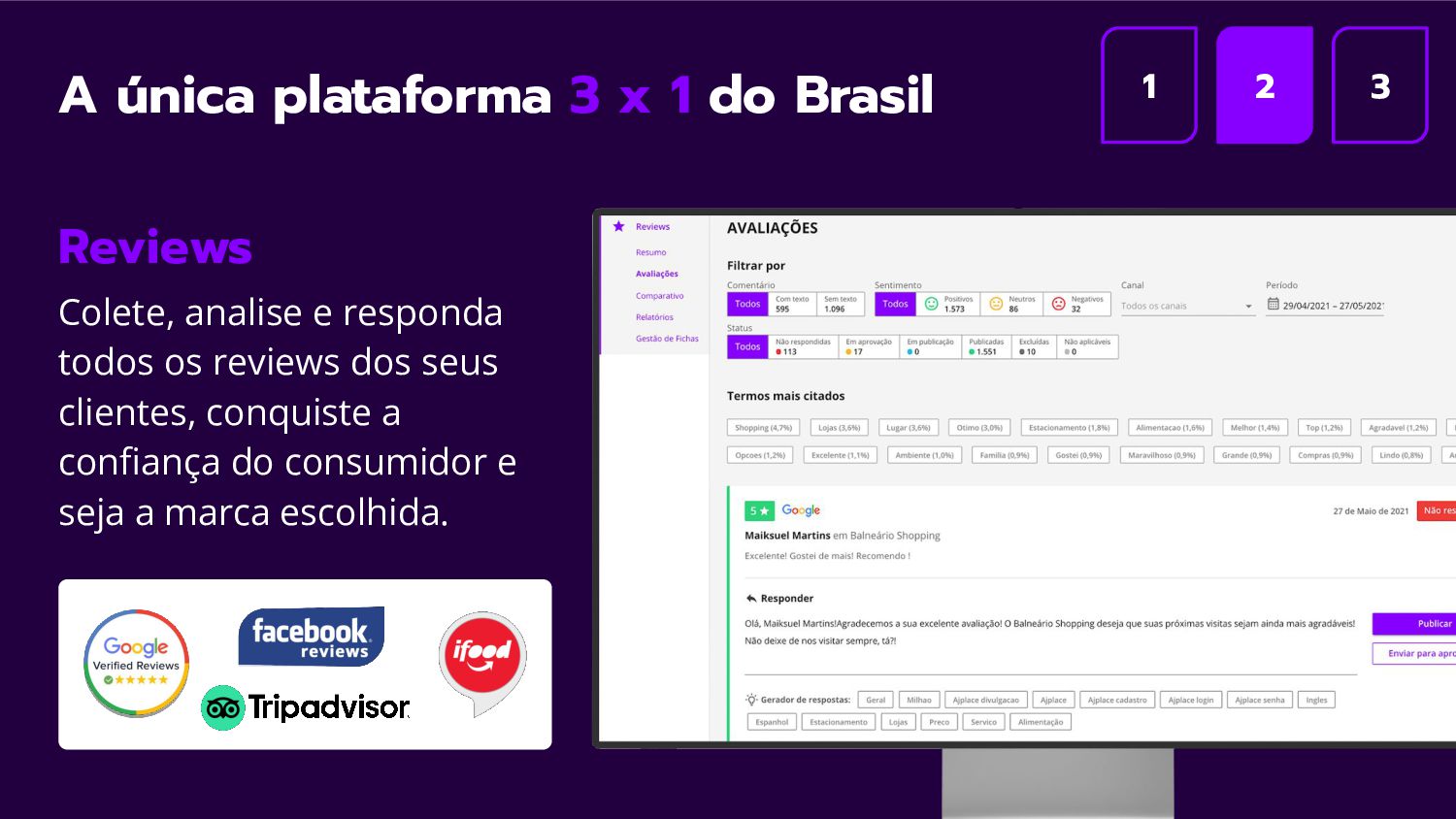
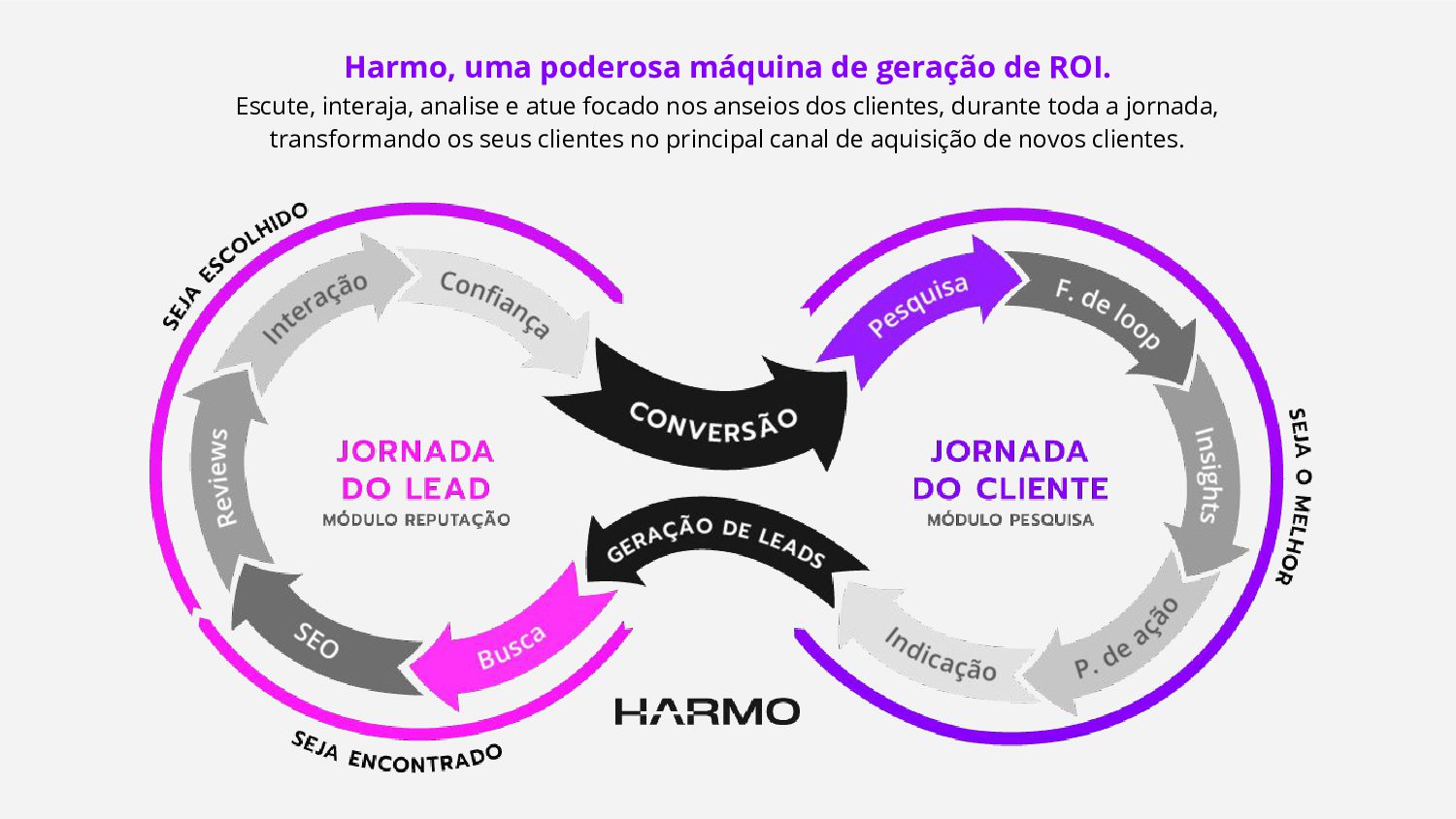
É cada vez mais difícil o processamento de grande quantidade de dados, alinhando o baixo custo, maior extração de inteligência e ganho na qualidade das informações extraídas.
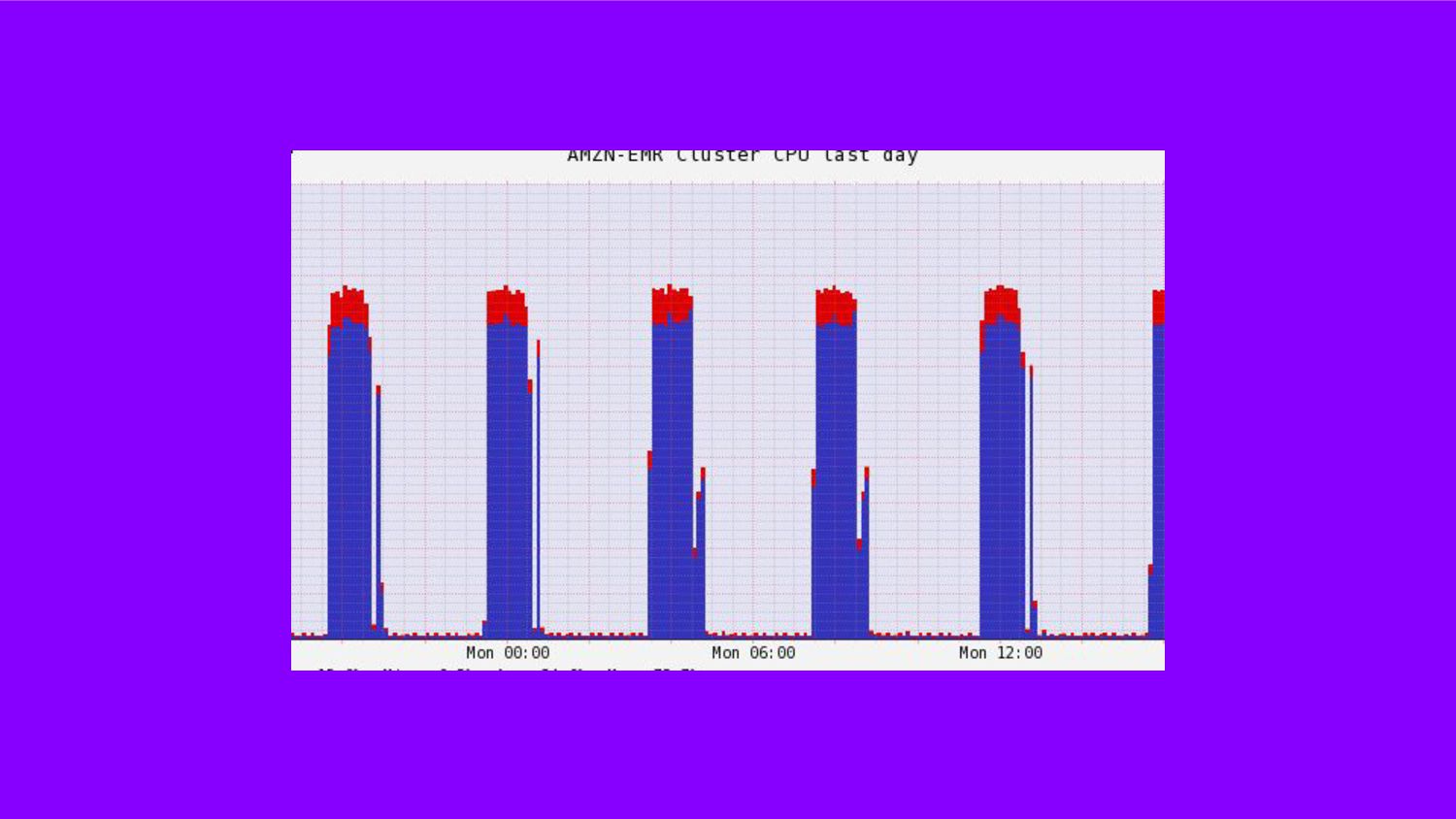
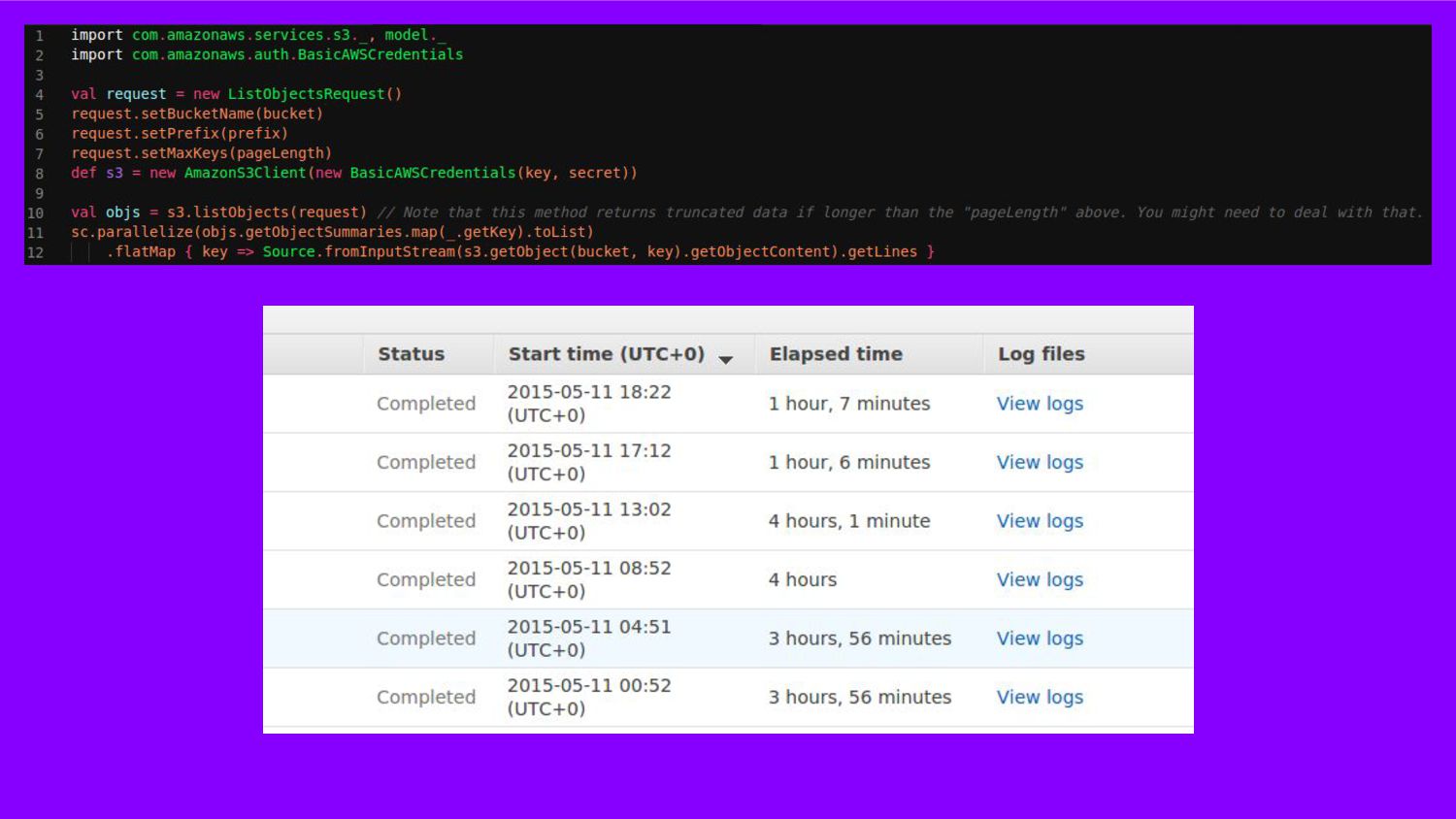
Nesta palestra, apresentarei os desafios e lições aprendidas com o projeto desenvolvido aqui na harmo.me, onde coletamos, consolidamos e processamos milhões de dados diariamente. Um case que mostra como atingimos baixíssimo custo, alta performance e qualidade nos dados. Também as lições aprendidas ao longo dos anos.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Leonardo Rifeli | CTO [email protected] harmo.me seo local | reviews](https://files.speakerdeck.com/presentations/c92c7e3ad9ee4660a5022b0d7a108b82/slide_73.jpg){kind=link}