É cada vez mais difícil o processamento de grande quantidade de dados, alinhando o baixo custo, maior extração de inteligência e ganho na qualidade das informações extraídas.
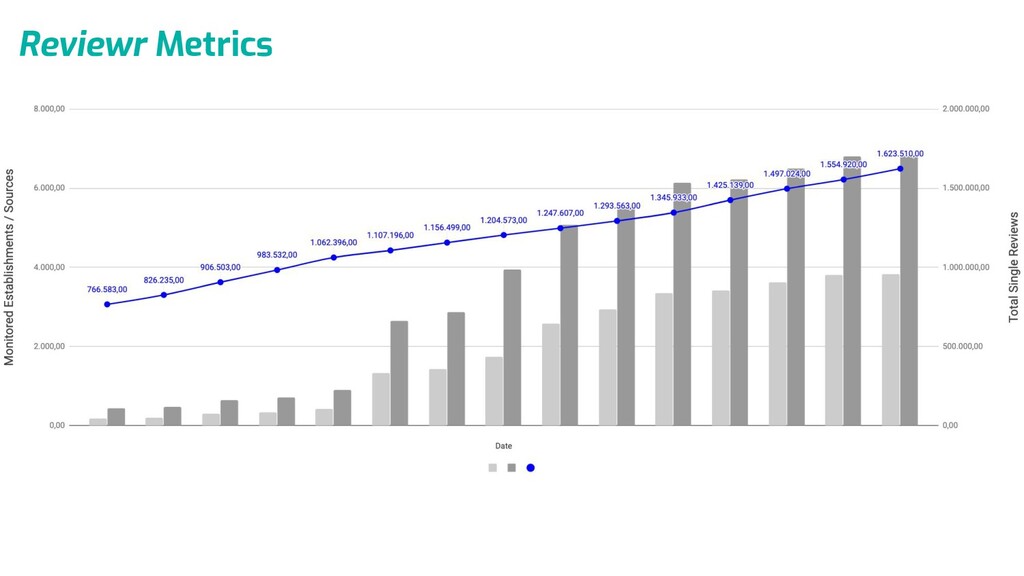
Nesta palestra, apresentarei os desafios e lições aprendidas com o projeto desenvolvido aqui na reviewr.me, onde consolidamos e processamos milhões de dados diariamente. Um case que mostra como atingimos baixíssimo custo, alta performance e qualidade.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
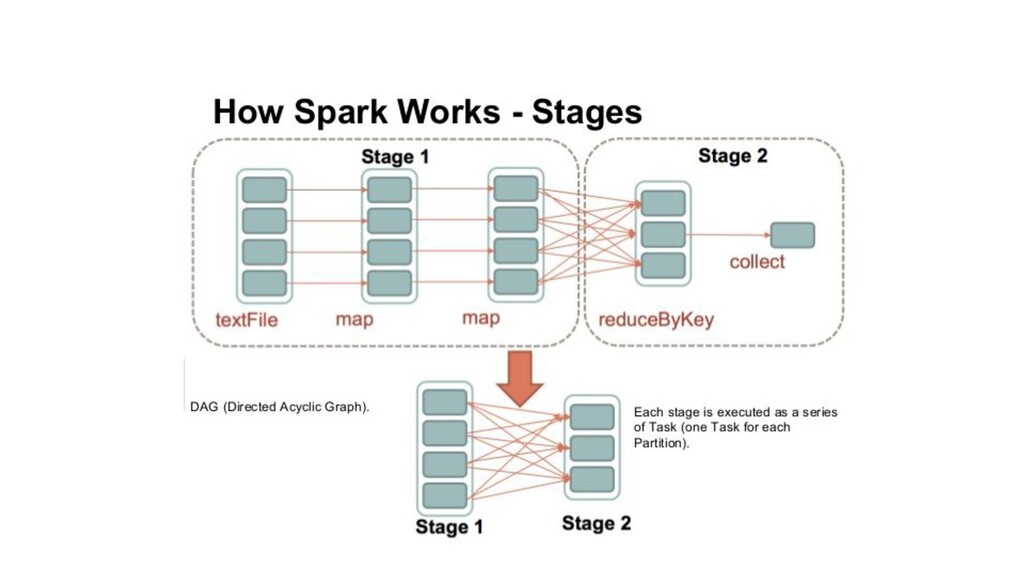{kind=link}
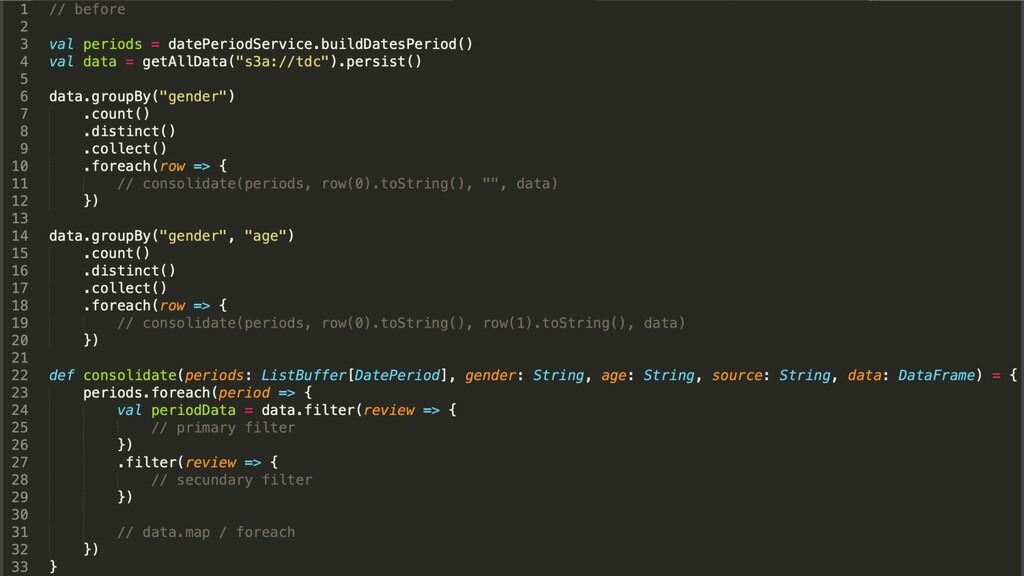{kind=link}
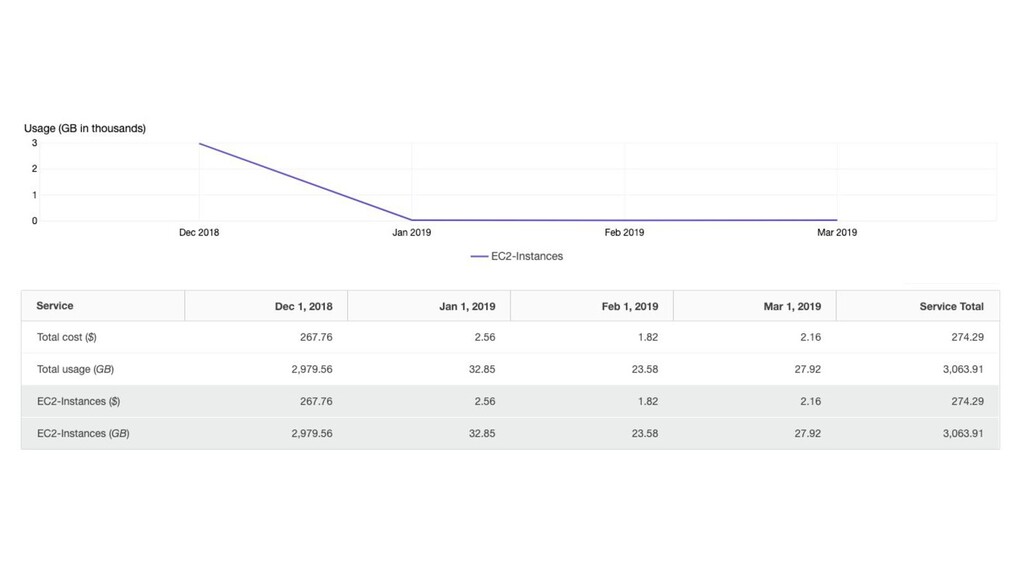{kind=link}
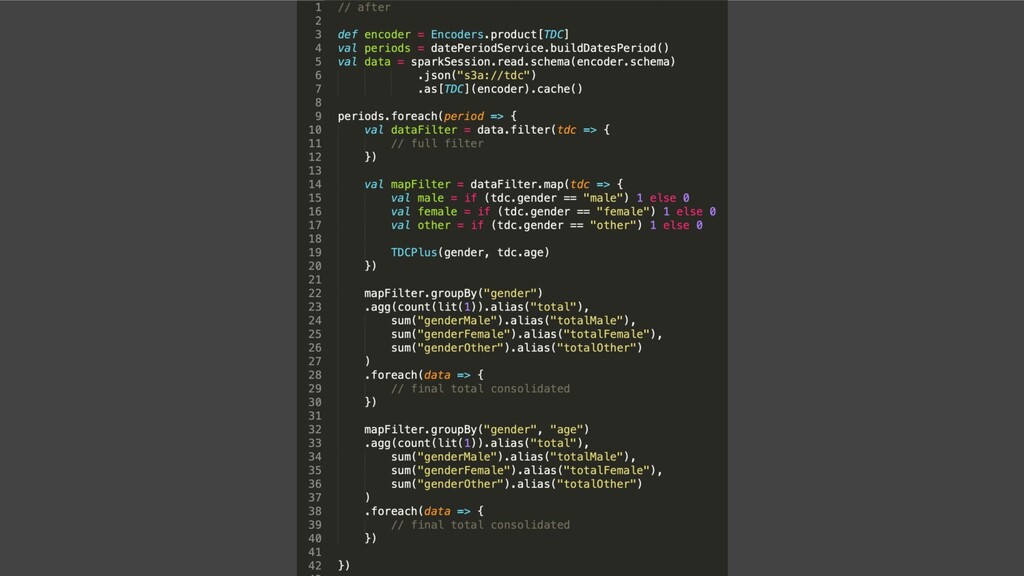{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigado! leonardorifeli.tech reviewr.me [email protected]](https://files.speakerdeck.com/presentations/0a9d8ca72c0d415698757dba5fc40561/slide_77.jpg){kind=link}