busca para encontrar empresas locais, próximas de onde estão. Google 82% dos consumidores afirmam que reviews influenciam suas decisões de compra. Fonte: Local Customer Review Survey 2017 by Bright Local 93%
busca para encontrar empresas locais, próximas de onde estão. Google 82% dos consumidores acreditam em reviews tanto quanto em recomendações pessoais. 85% dos consumidores afirmam que reviews influenciam suas decisões de compra. Fonte: Local Customer Review Survey 2017 by Bright Local 93% Fonte: Local Customer Review Survey 2017 by Bright Local
A Distributed Storage System for Structured Data ▷ The Google File System ▷ The history of Hadoop ▷ Untangling Apache Hadoop YARN, Part 1: Cluster and YARN Basics ▷ How to calculate node and executors memory in Apache Spark Links
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
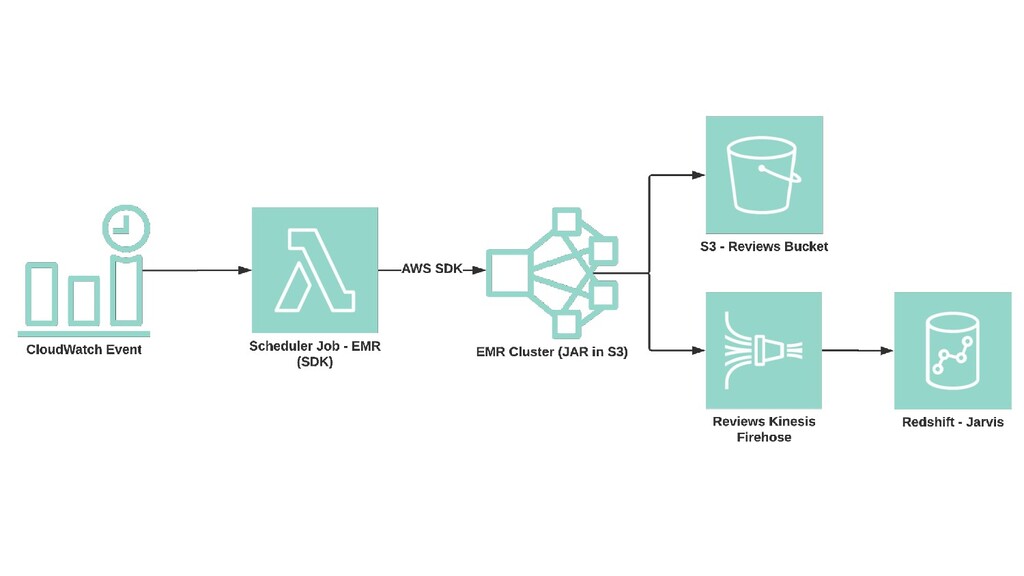{kind=link}
{kind=link}
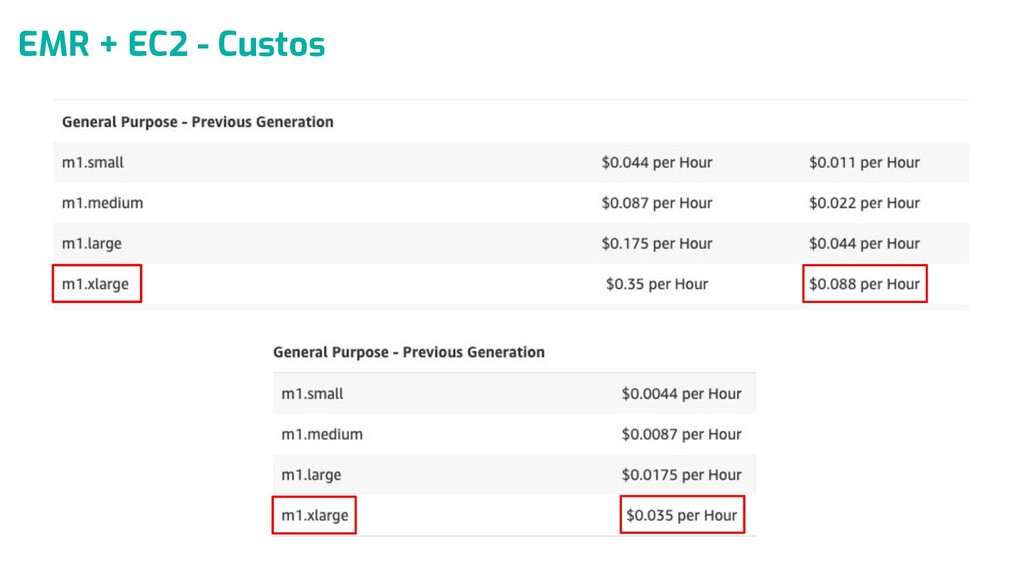{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
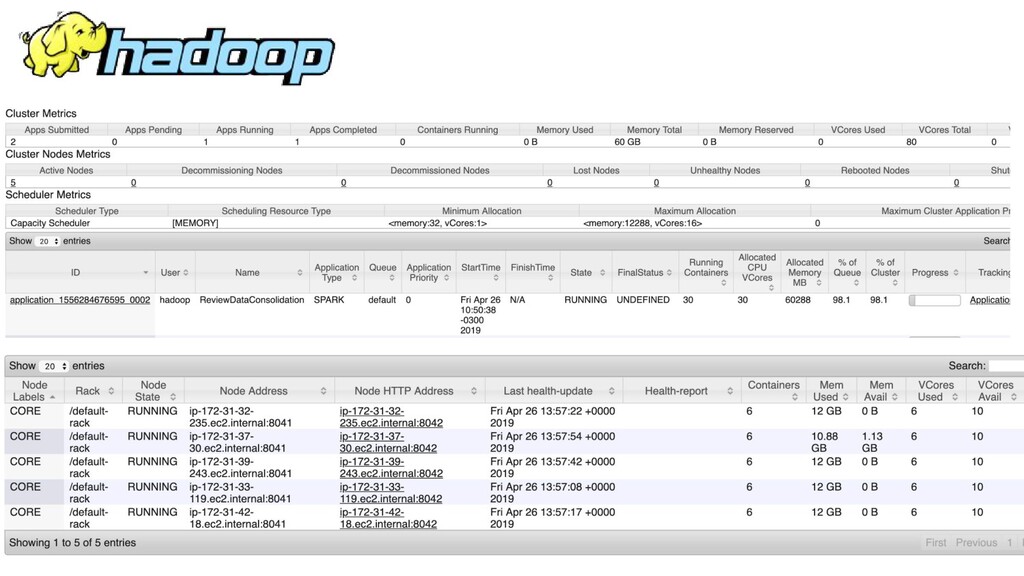{kind=link}
{kind=link}
{kind=link}
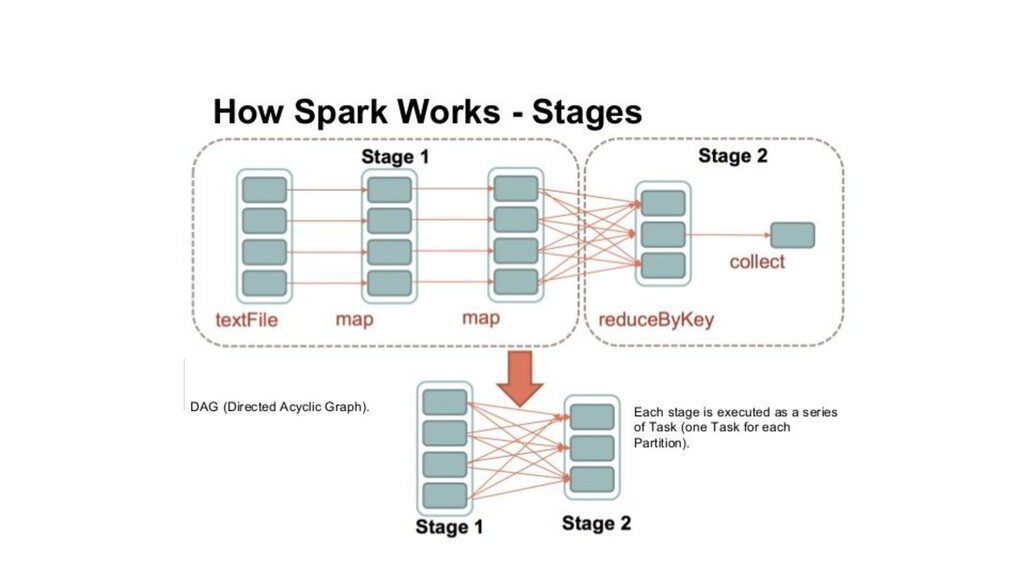{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
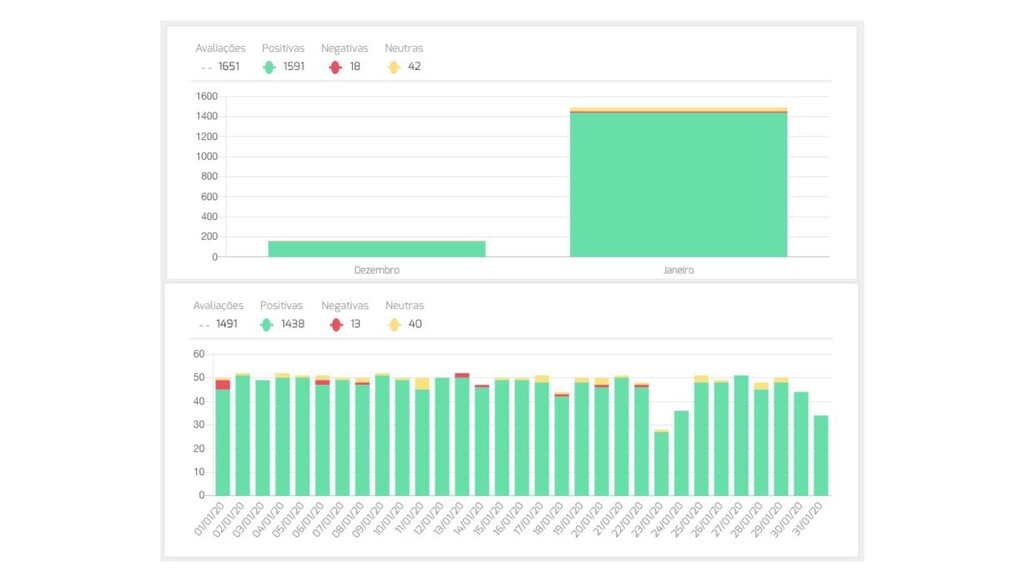{kind=link}
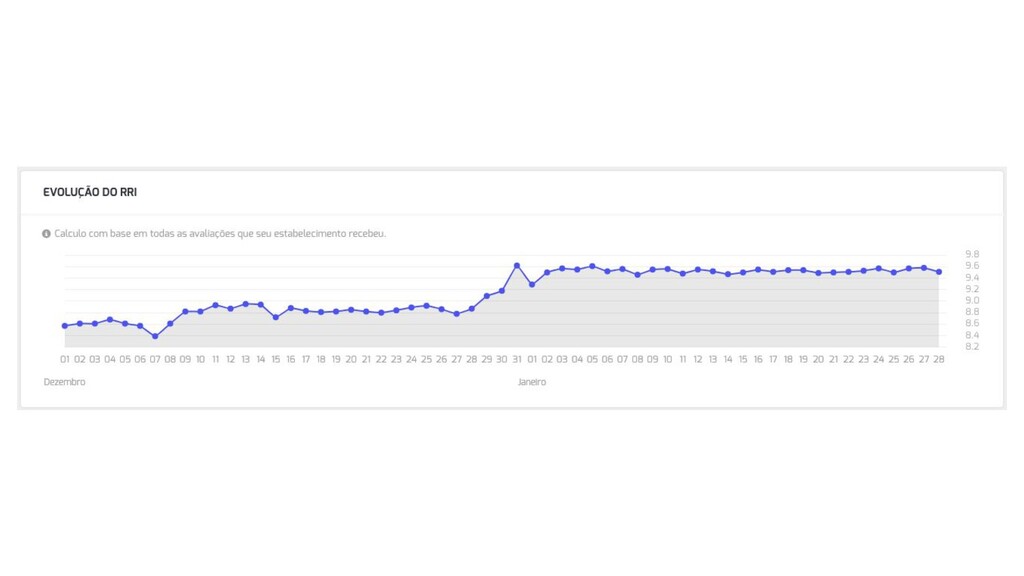{kind=link}
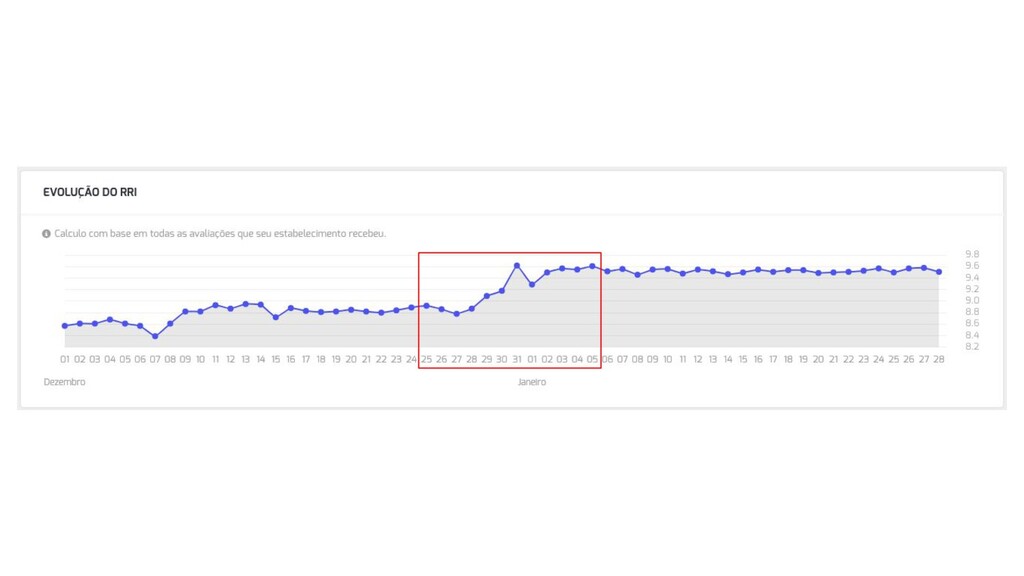{kind=link}
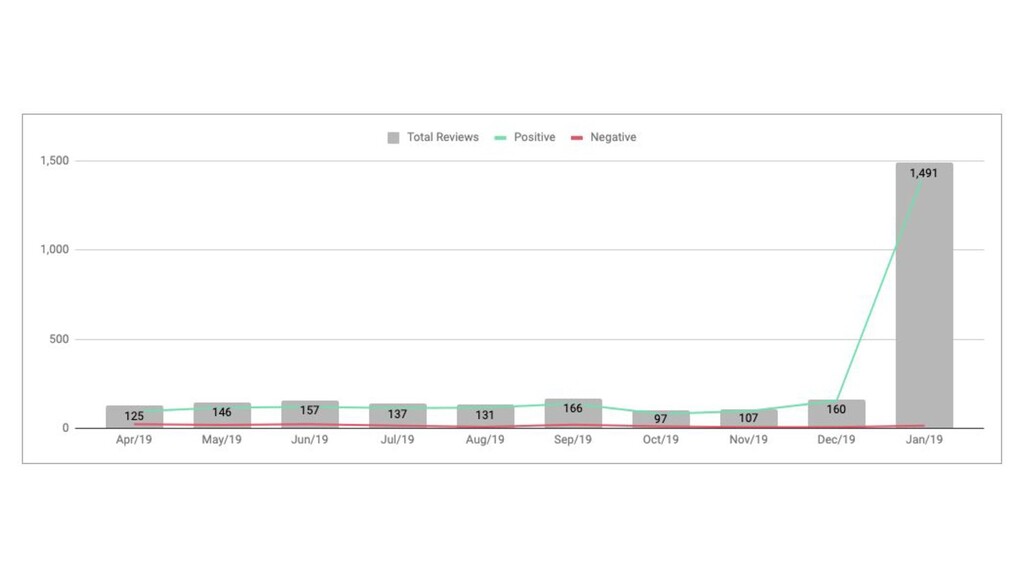{kind=link}
{kind=link}
{kind=link}
![Tks! Data is the new oil? rifeli.me reviewr.me [email protected]](https://files.speakerdeck.com/presentations/8dabba6ab1884109869f09de4997fd34/slide_103.jpg){kind=link}