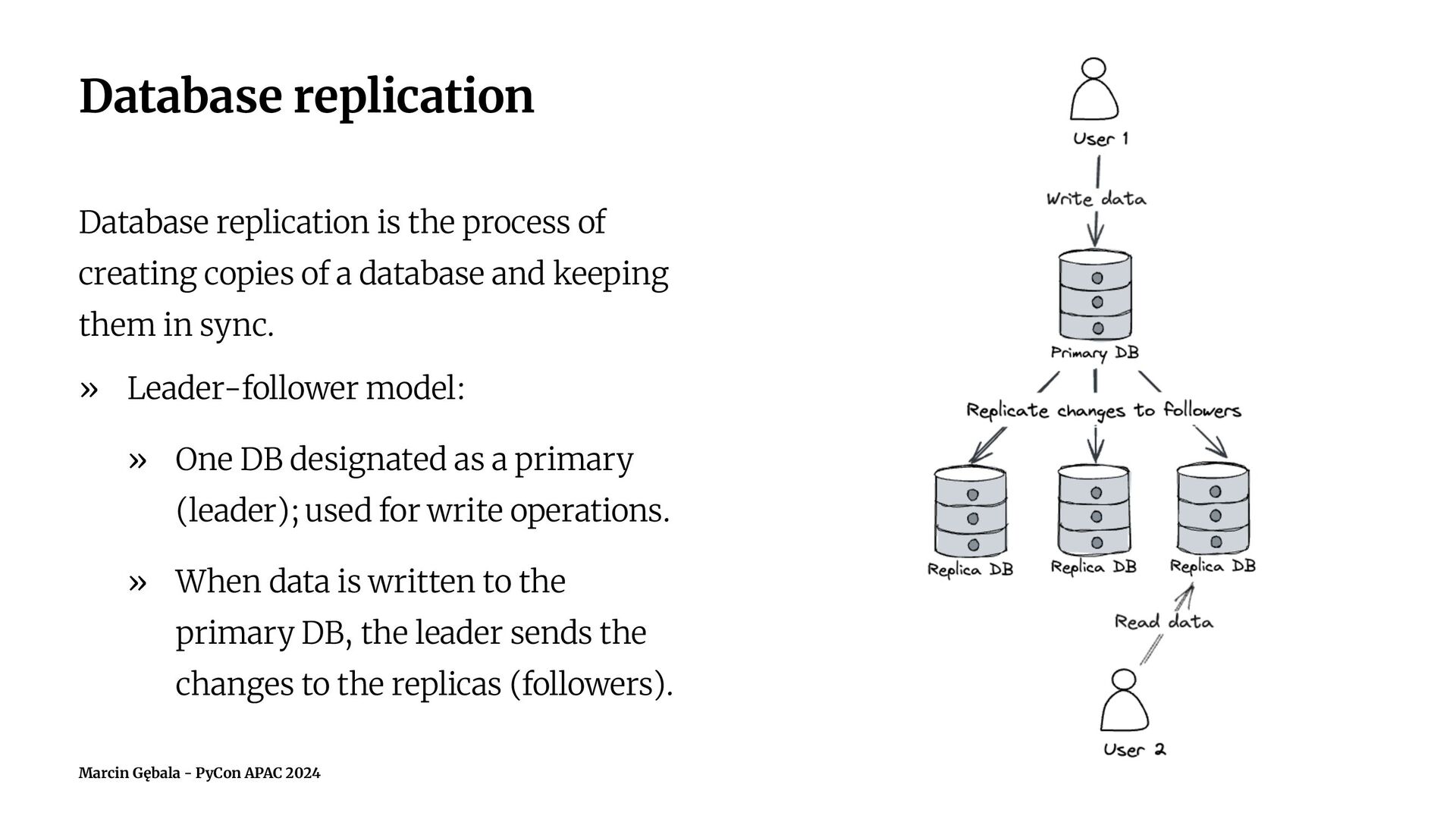
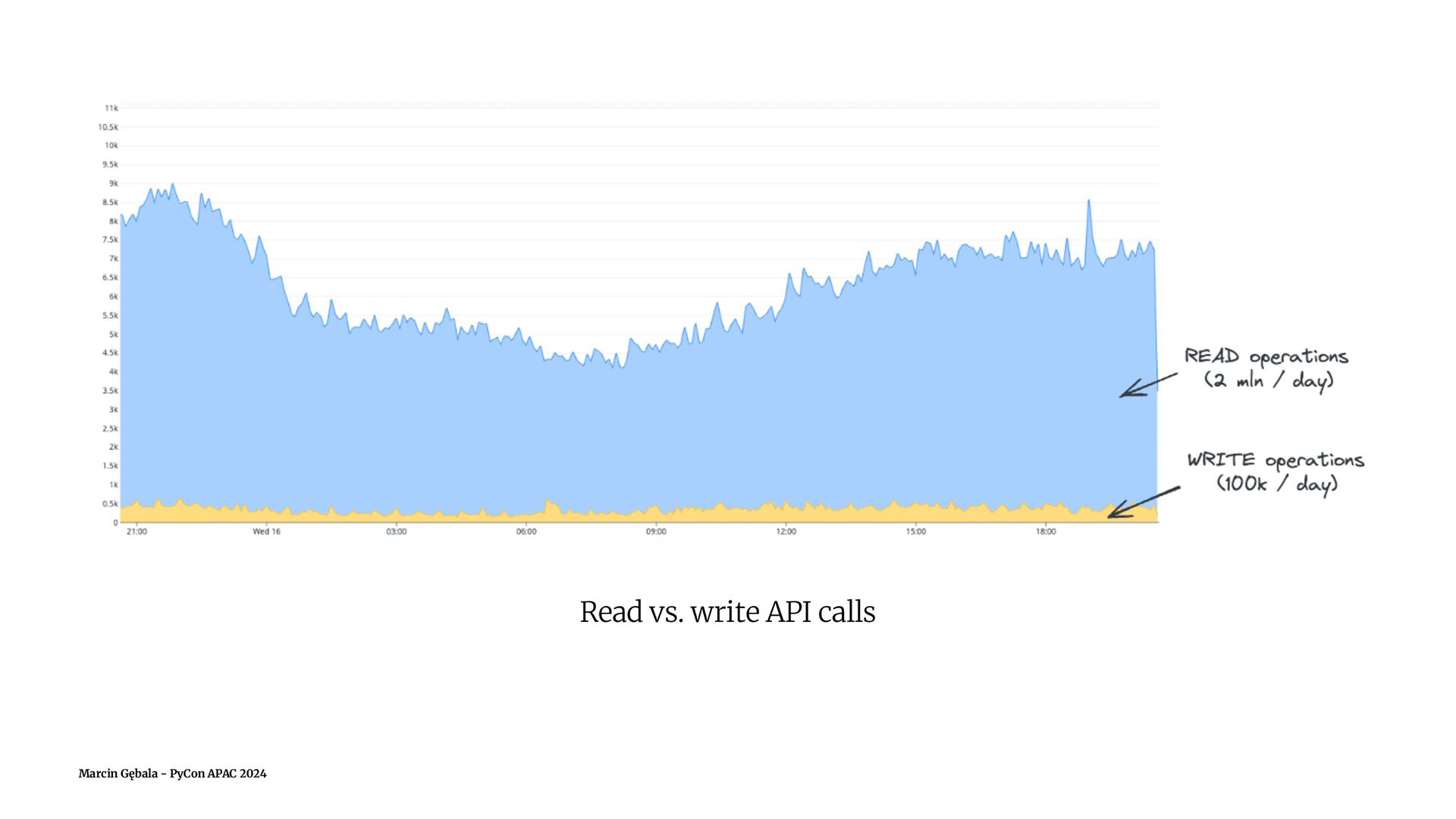
Database replication is a concept of storing the same data in multiple databases, which is useful in applications with high traffic, to maintain high availability and performance. Once the database becomes a bottleneck, a common solution is to create a setup with a separate database for write operations (a writer) and one or more databases for read operations (readers, replicas).
In this talk, we will look into a setup of a web application based on Django and Postgres, that is configured to use two databases - a writer and a reader. We will look at different aspects of this solution:
- theory of how replication works in different databases
- how to configure multiple databases with Django and Postgres
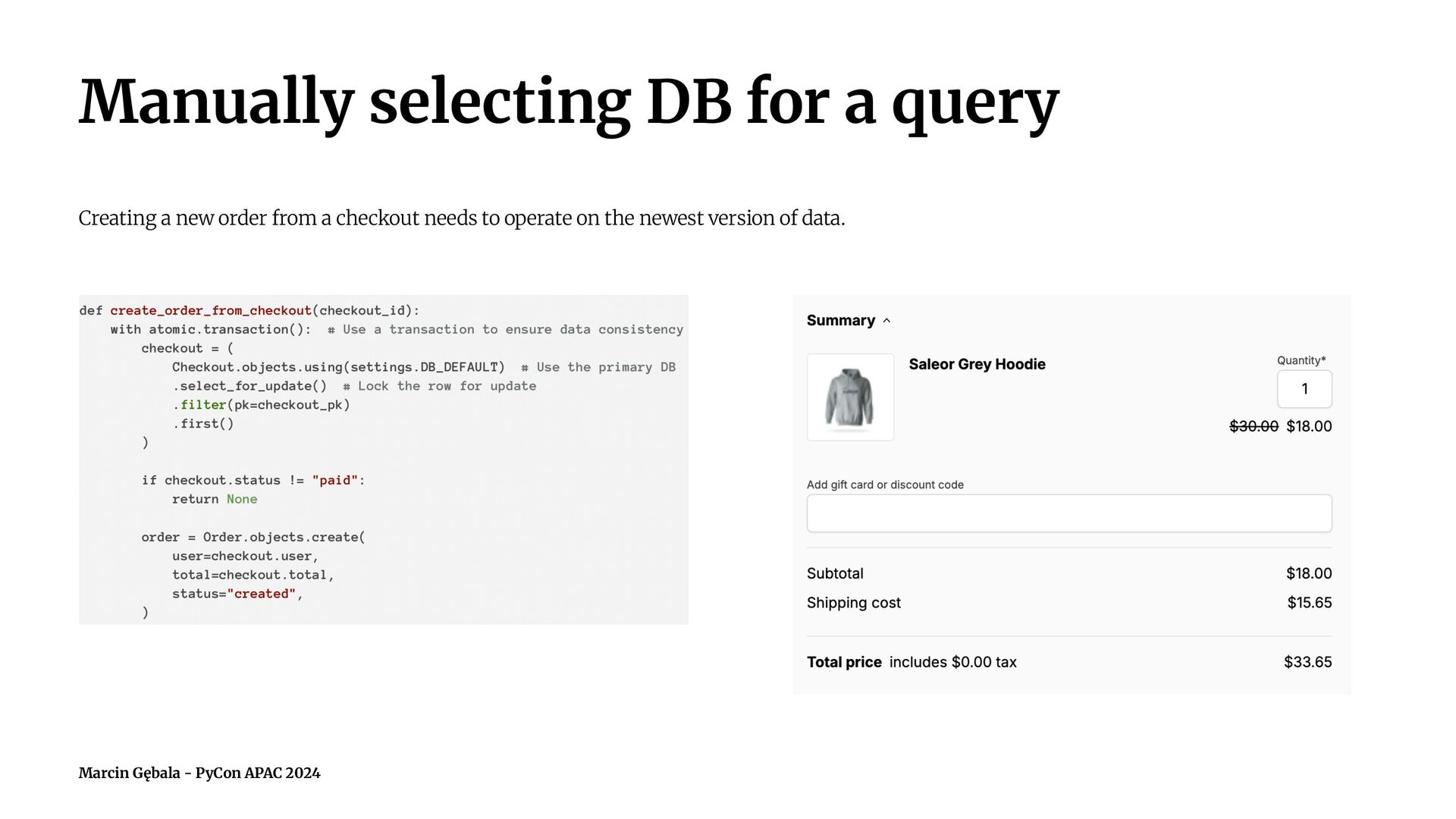
- practical examples of patterns to use in code to handle reading and writing using separate databases
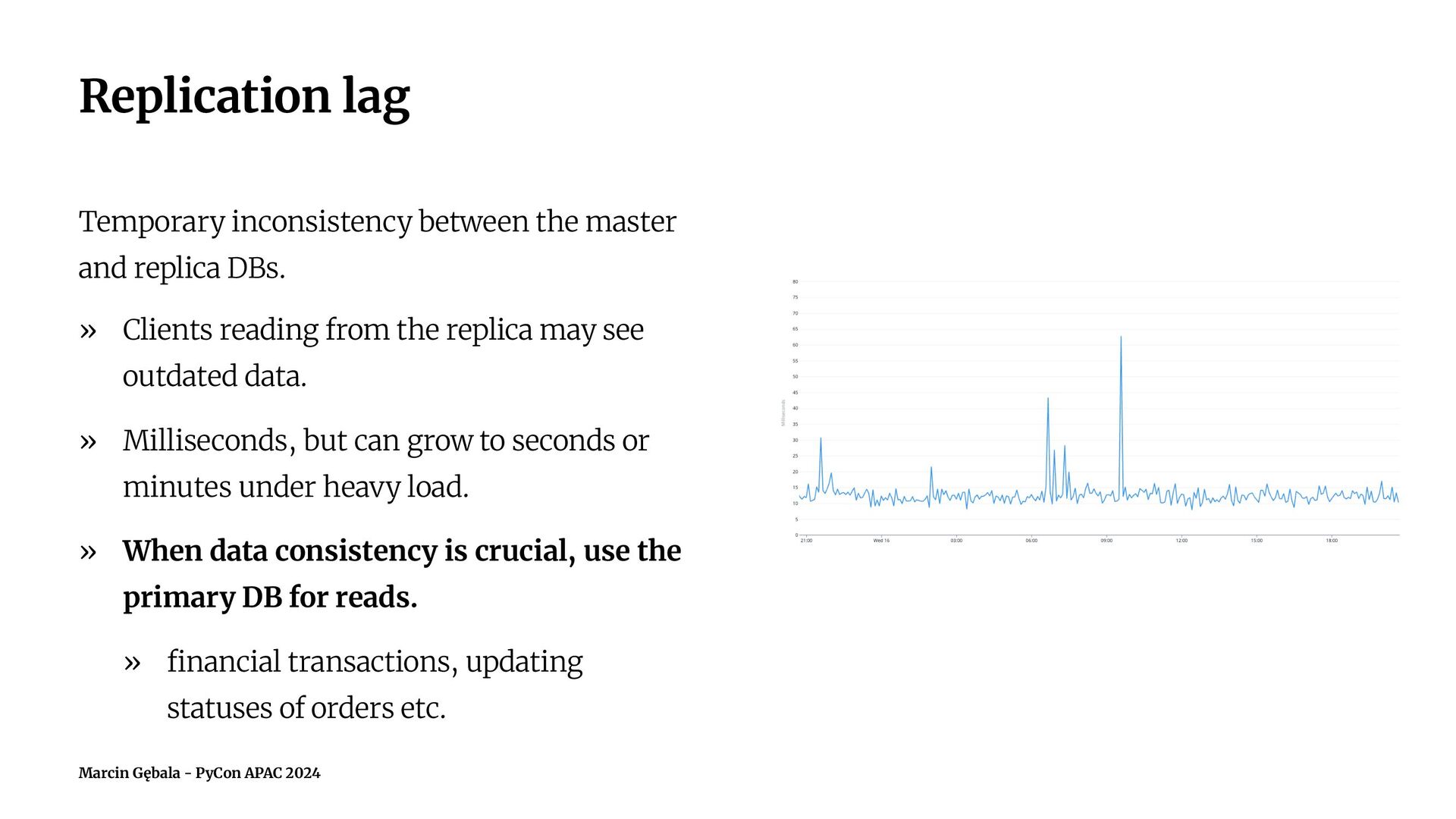
- challenges and edge cases that occur with this setup, such as handling the replication lag.
We will use an example web app to show all the concepts and look at real-life examples based on a large production app written in Django.
The structure of the talk is as follows:
1. Introduction to database replication - how it works, when and why it is useful.
2. Database replication in practice with Django and Postgres - configuration and best practices to use in code.
3. Challenges and edge cases and how to deal with them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}