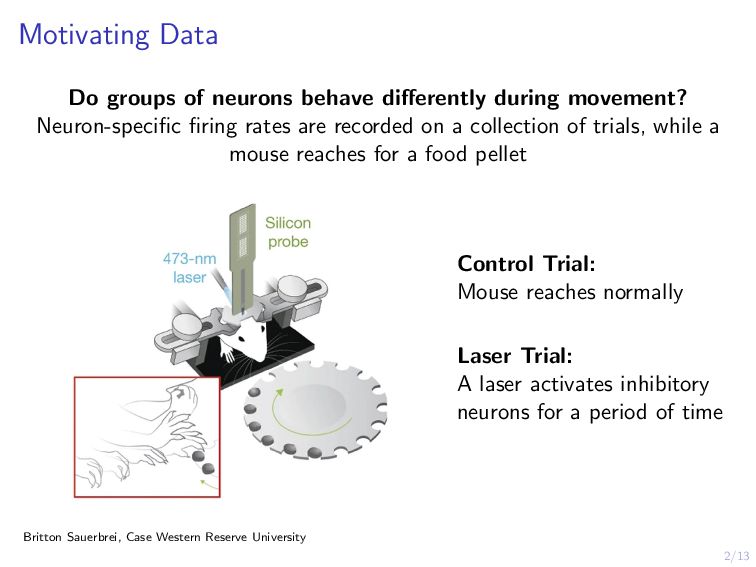
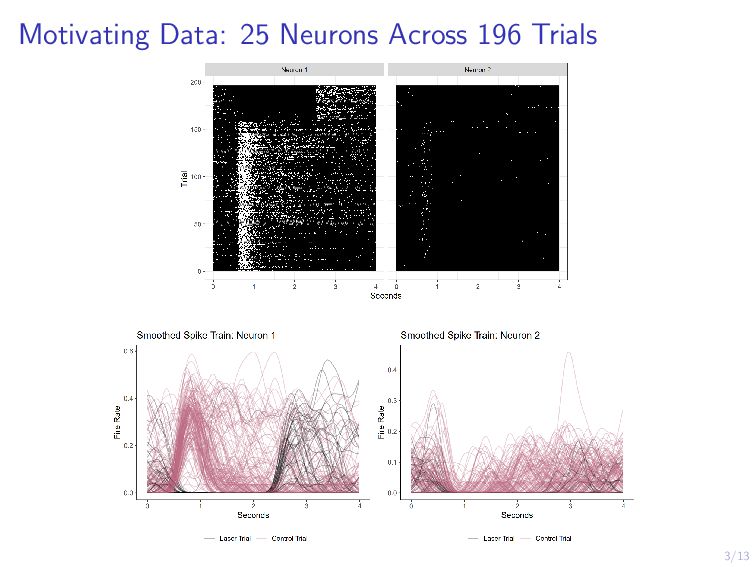
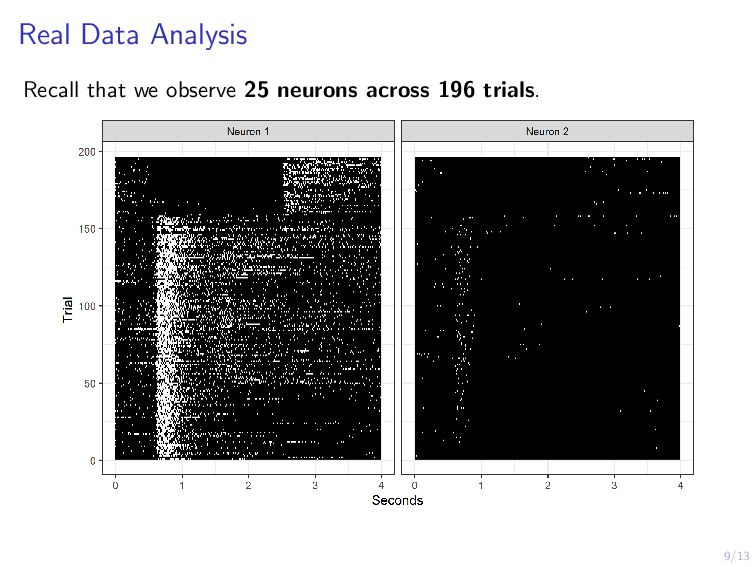
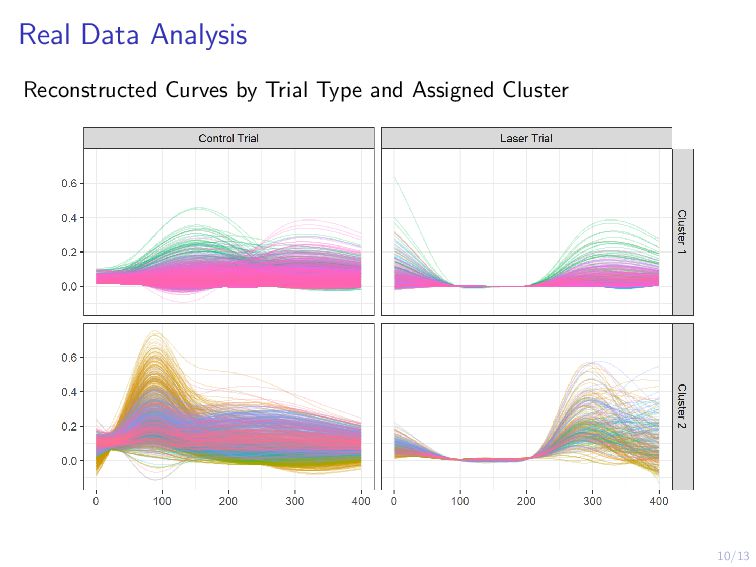
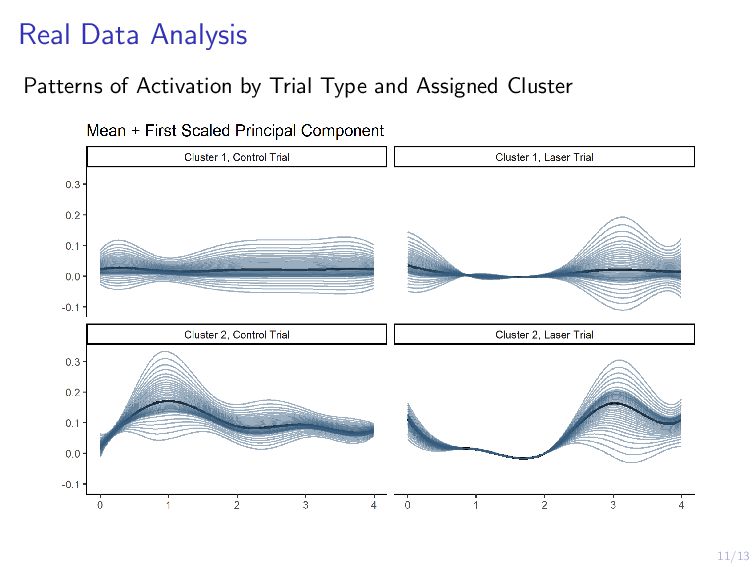
Scientists are interested in identifying neural activation patterns associated with skilled movement in the motor cortex. Neural firing rates are collected from trained mice as they reach for a food pellet on a number of trials under different scenarios. Functional data analysis is a collection of methods which treat data measured on a dense grid as a random function. Under this framework, we aim to cluster the neurons into interpretable clusters while preserving the inherent differences in activation between trial types. Additionally, we are interested in extracting low-dimension, cluster-specific activation patterns. We develop a method which simultaneously clusters and decomposes multilevel functional data across trials, resulting in distinguishable cluster-and-trial-type-specific representations of the data. We demonstrate this method on a collection of 25 neurons across 196 trials of two types.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![13/13 Thanks for listening! Madison Stoms [email protected]](https://files.speakerdeck.com/presentations/8148dce2afcf4725993cf53513d1c2da/slide_12.jpg){kind=link}