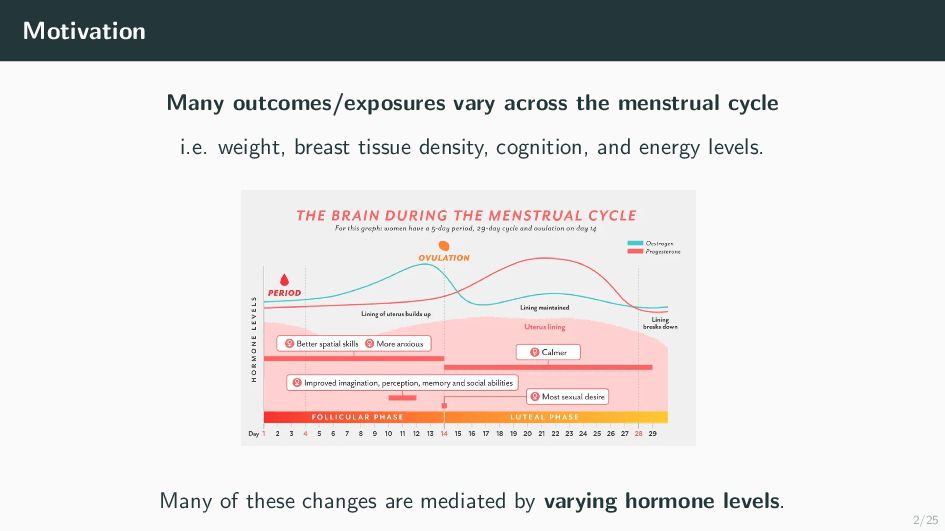
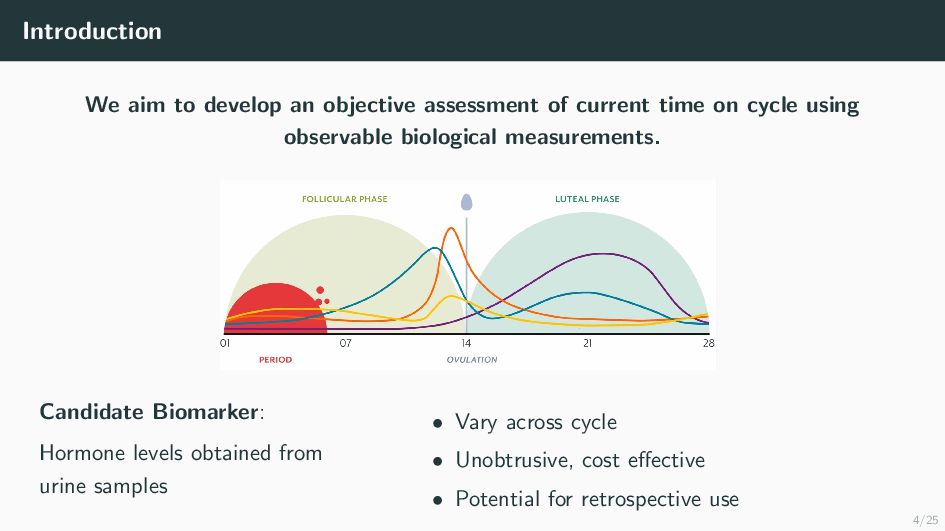
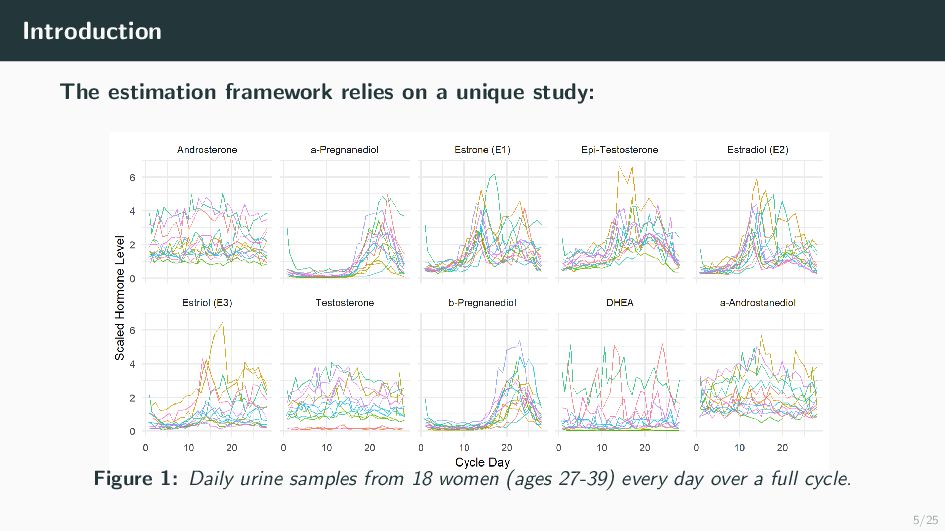
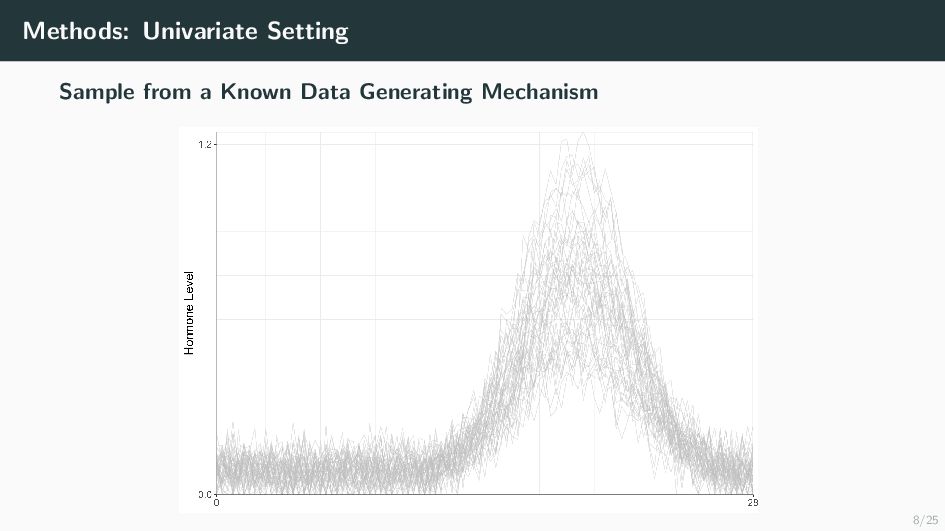
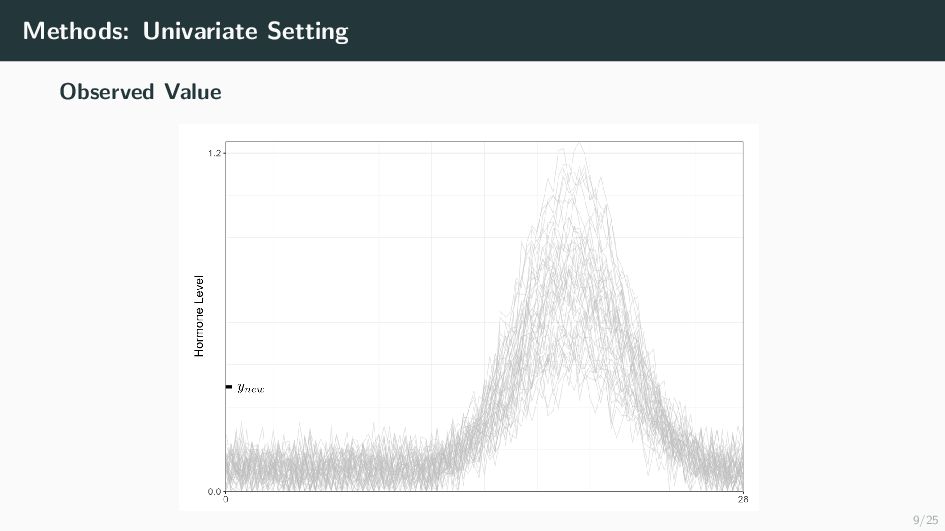
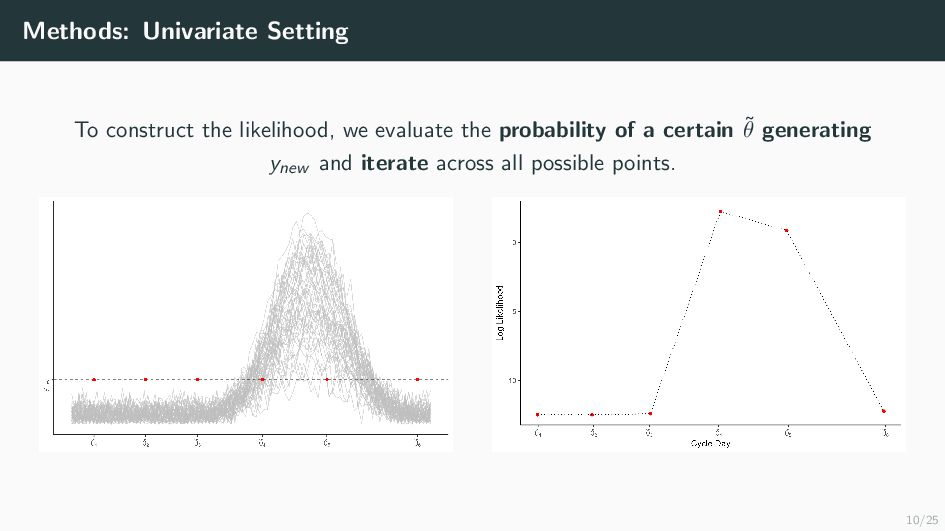
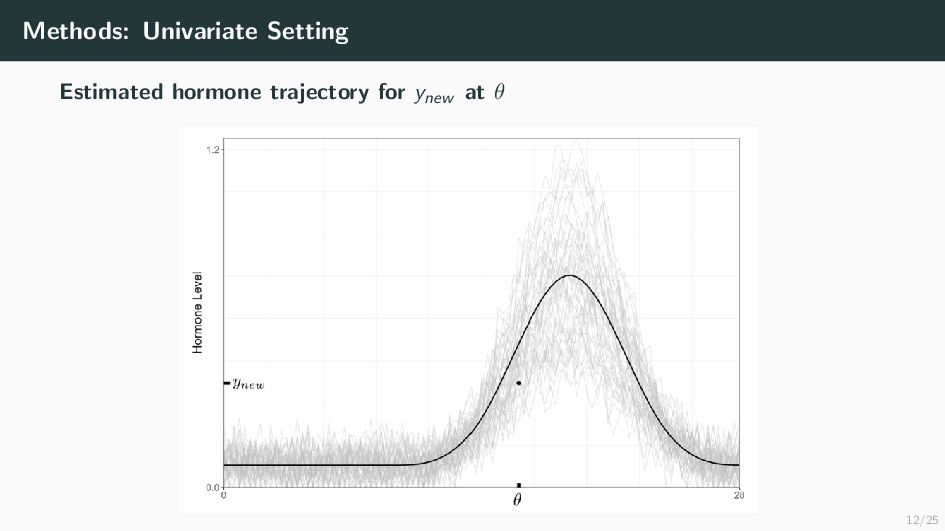
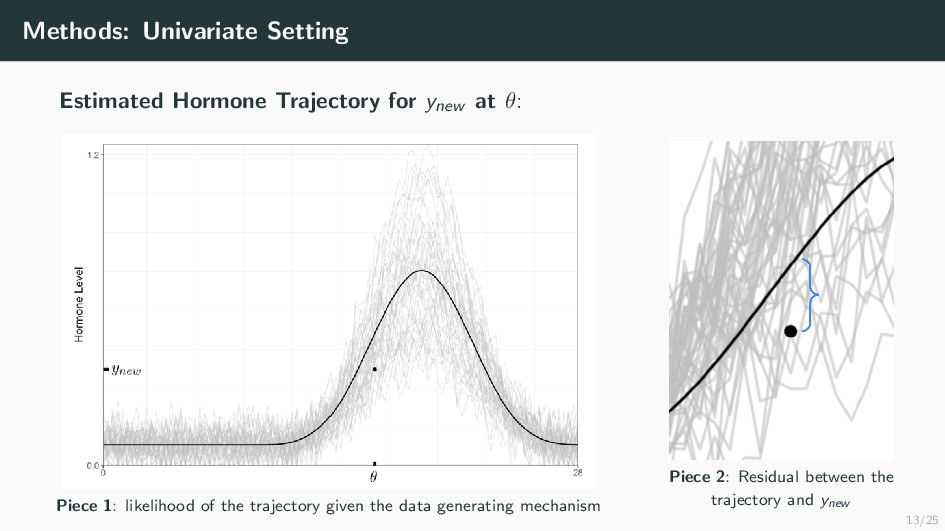
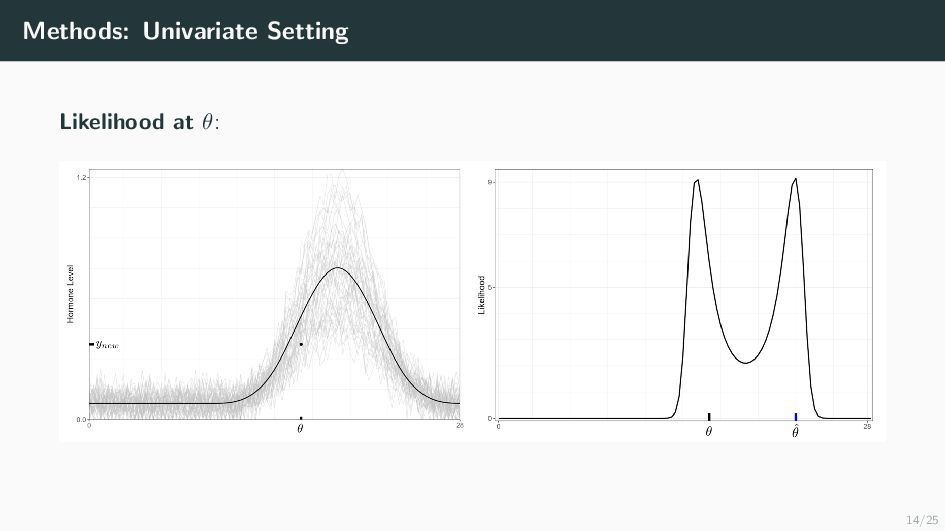
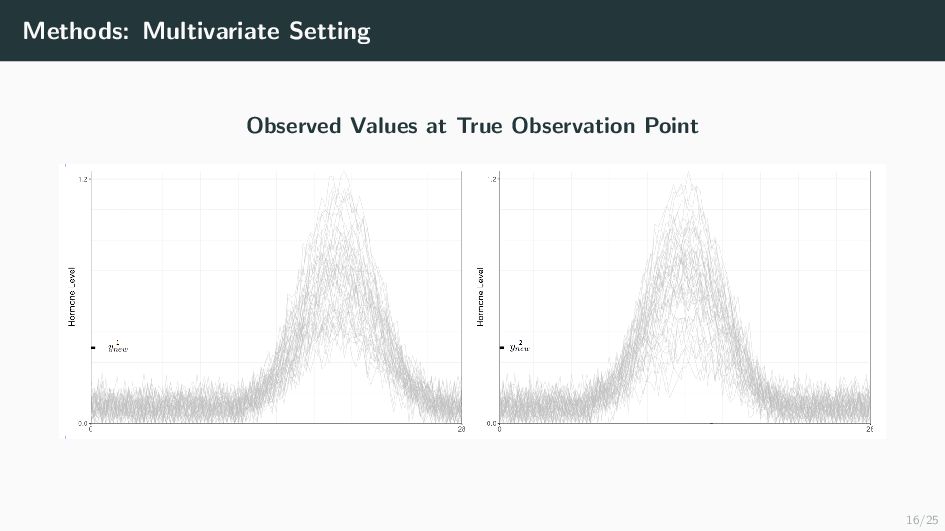
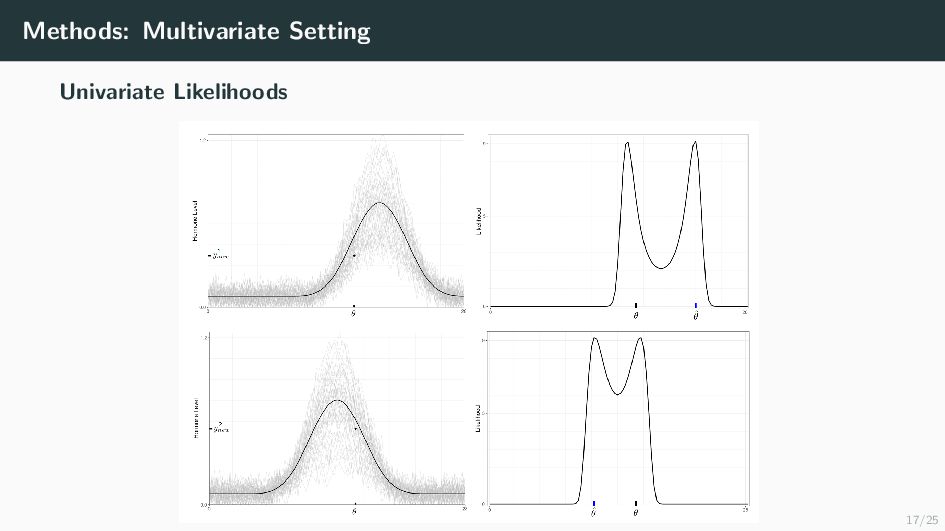
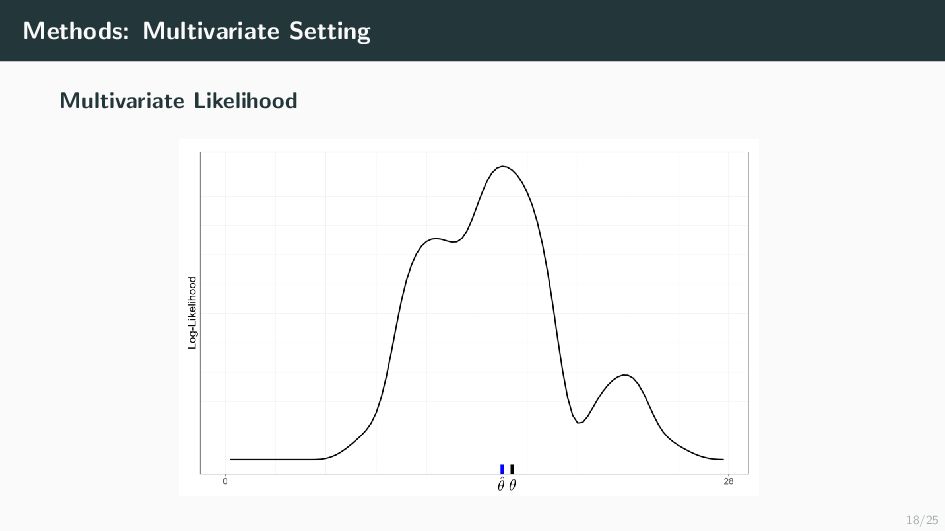
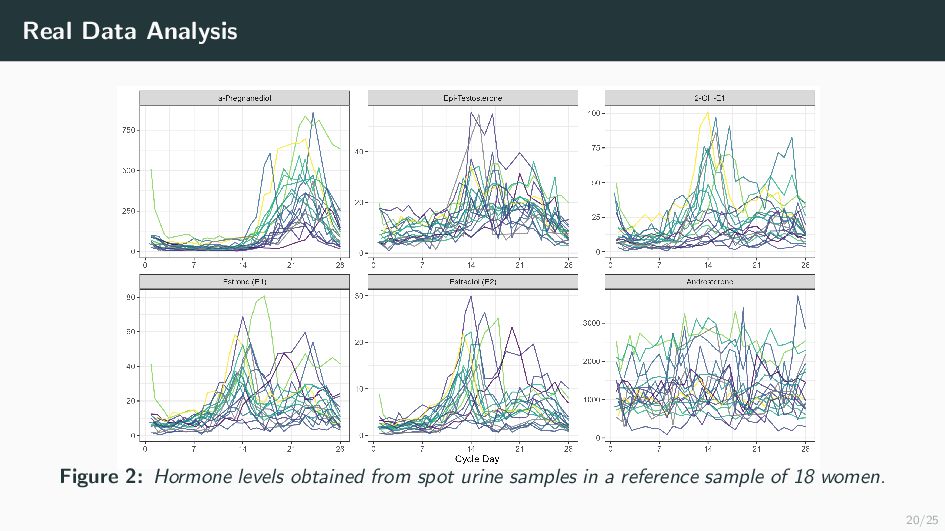
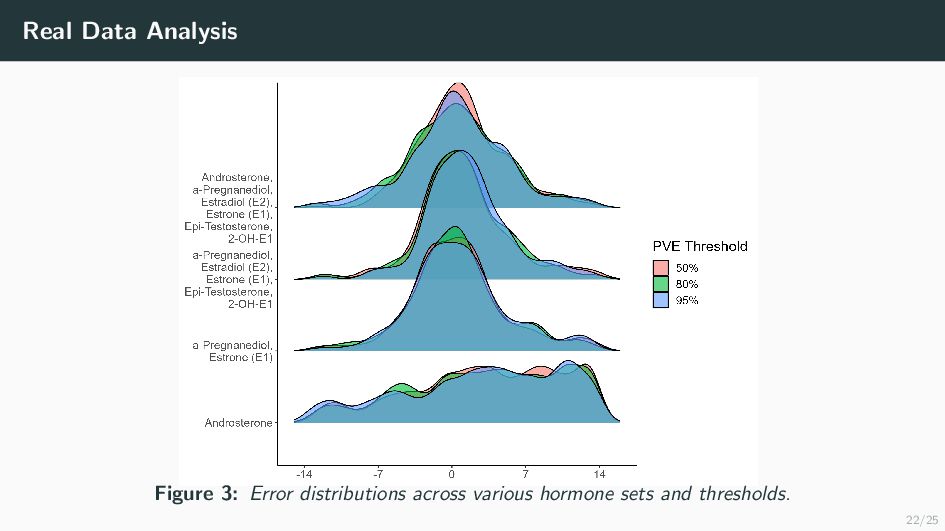
Many health-related outcomes and exposures vary over the menstrual cycle. Accounting for this source of variation could improve model accuracy and statistical power. However, cycle day is difficult to measure through self report or estimate using available methods, and is routinely overlooked in studies involving women's health. Our goal is to provide an accurate estimate of menstrual cycle day (i.e. number of days since the start of cycle) using hormone values derived from a single spot urine sample. We construct a likelihood for the latent cycle day based on observed hormone levels; this likelihood uses patterns of hormonal variation obtained from a unique study that followed a sample of women over a complete cycle as a reference. Our results suggest that we can estimate the cycle day within three days for the majority of observations based on single spot urine samples. This approach can be applied to ongoing and future studies in which menstrual cycle day is a potentially important variable, and may refine results based on extant datasets that obtained urine samples.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}