it should be reliable Software Reliability is the probability of a software system or component to perform its intended function under the specified operating conditions over the specified period of time [1] In other words the less faults there are in a software the more reliable it is.
is a problem in software that when run causes a failure. Fault Proneness is the likelihood of a piece of software to have faults. Fault prediction is identified as one major area to predict the probability that the software contains fault. We will survey 4 papers that use Machine learning to predict faults as early as possible.
of logic deals deals with reasoning that is approximate rather than fixed and exact. Its variables may have a truth value that ranges in degree between 0 and 1. It works by taking inputs in a range form then setting rules that define how these inputs will be used and then finding out the output and defuzzification by finding out a crisp value from a Fuzzy set.
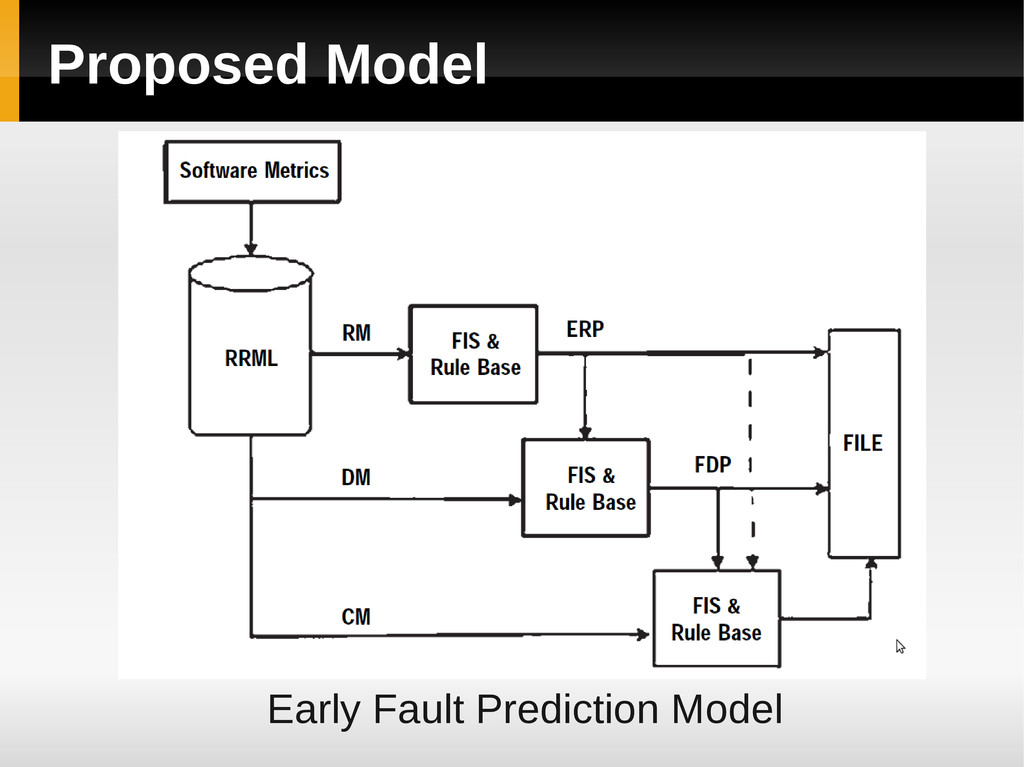
software metrics and process maturity together, for fault prediction. Input: Reliability Relevant Metric List (RRML) Output: Faults at the end of Requirements Phase (FRP) Faults at the end of Design Phase (FDP) Faults at the end of Coding Phase (FCP)
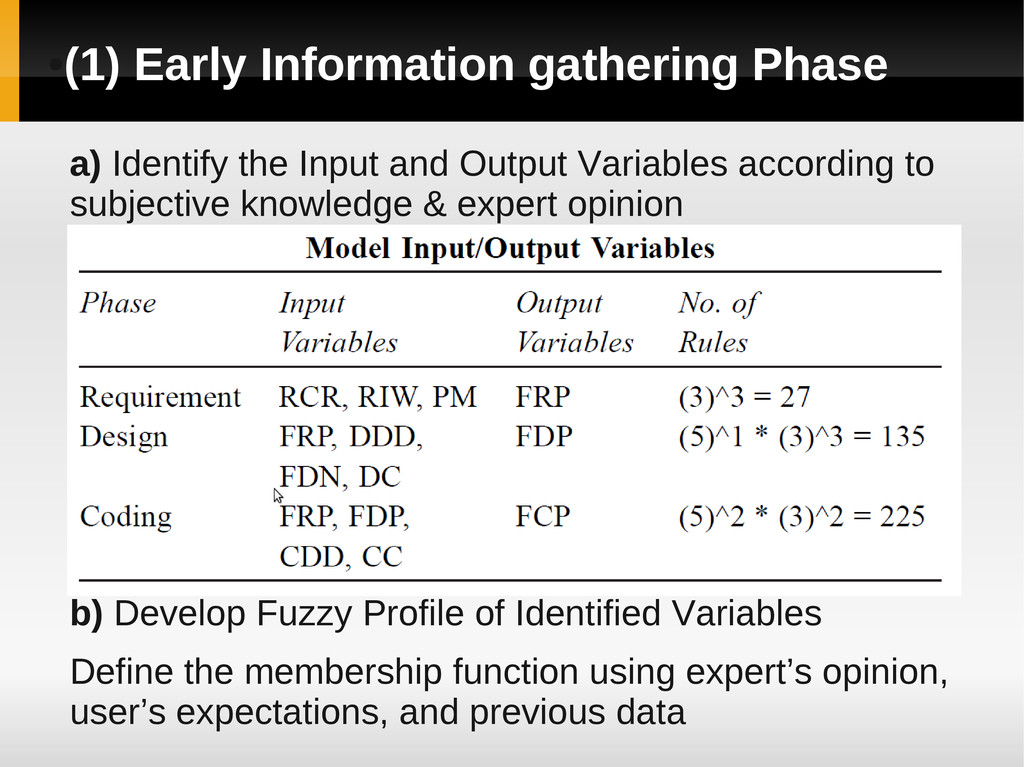
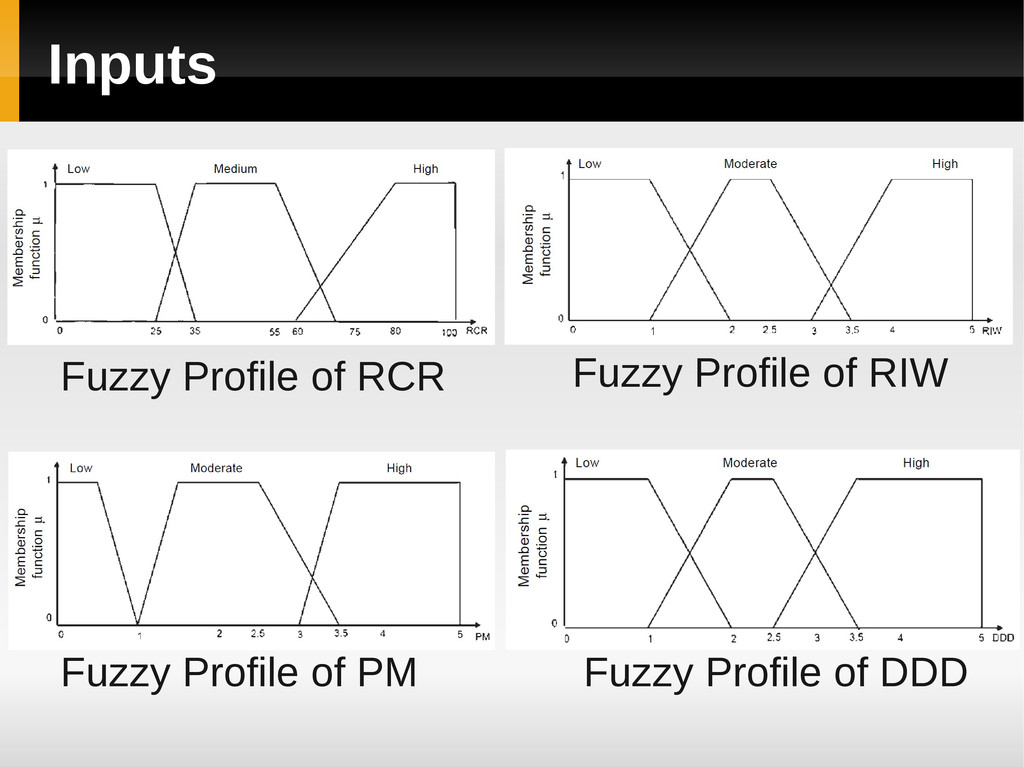
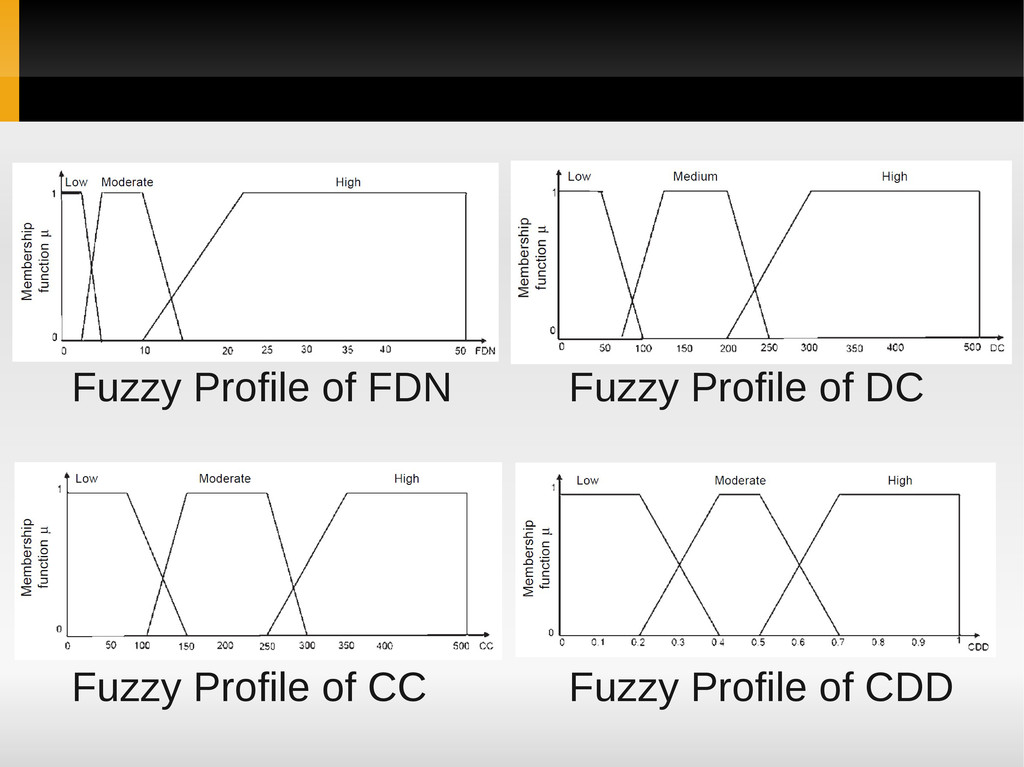
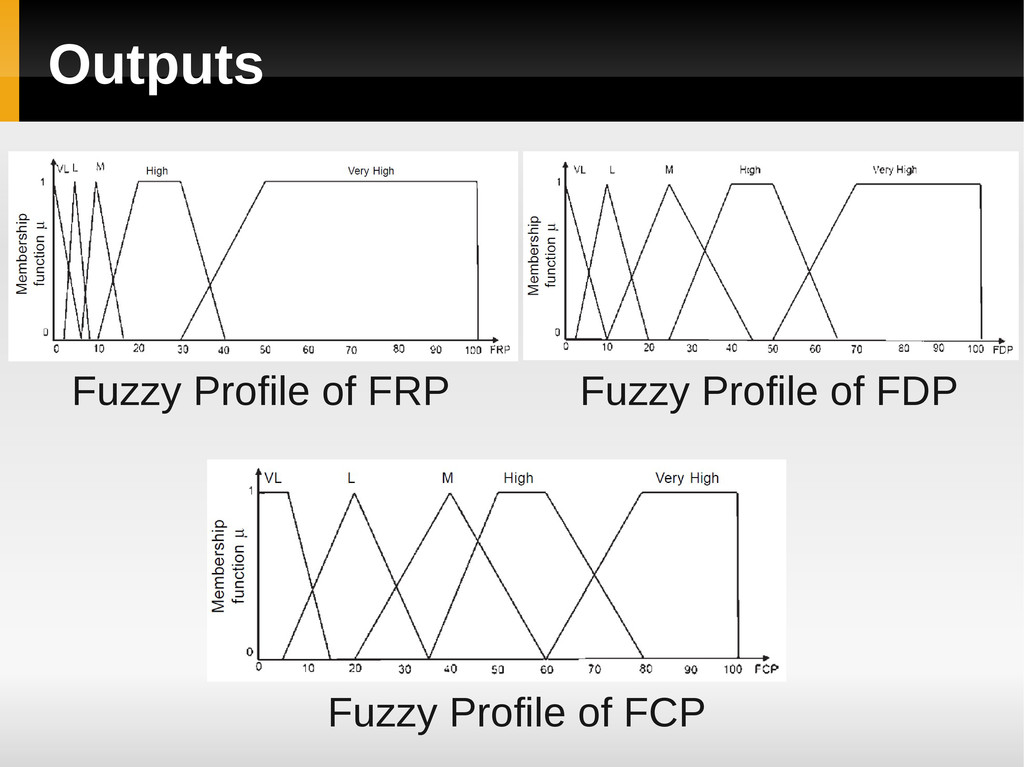
and Output Variables according to subjective knowledge & expert opinion b) Develop Fuzzy Profile of Identified Variables Define the membership function using expert’s opinion, user’s expectations, and previous data
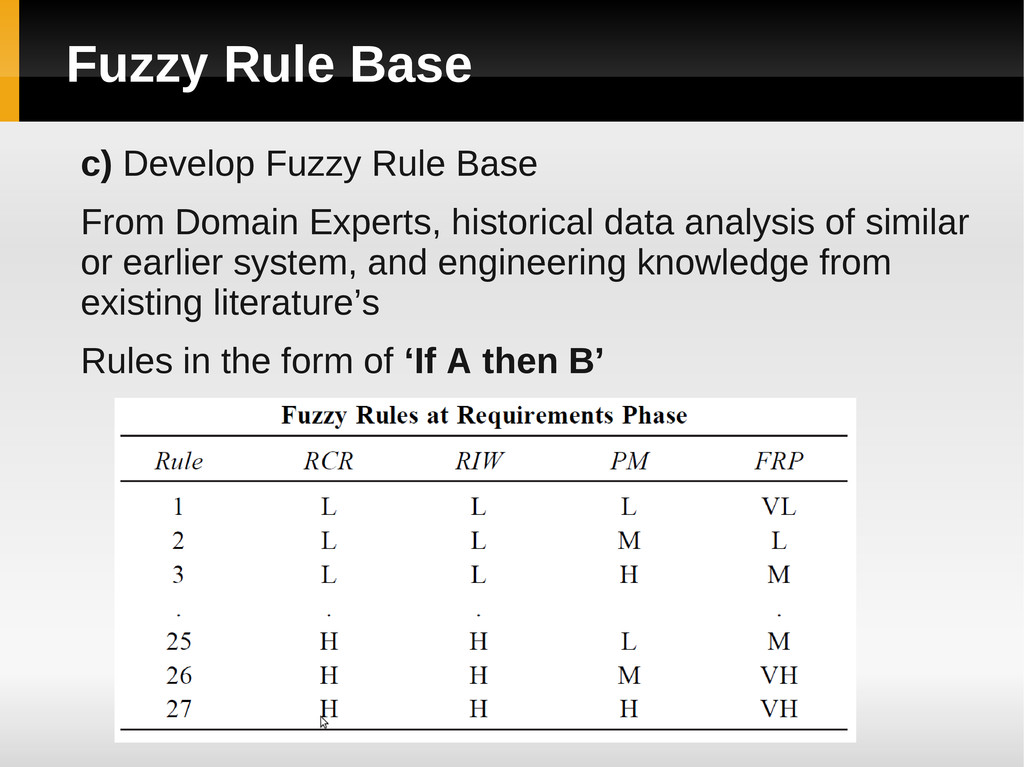
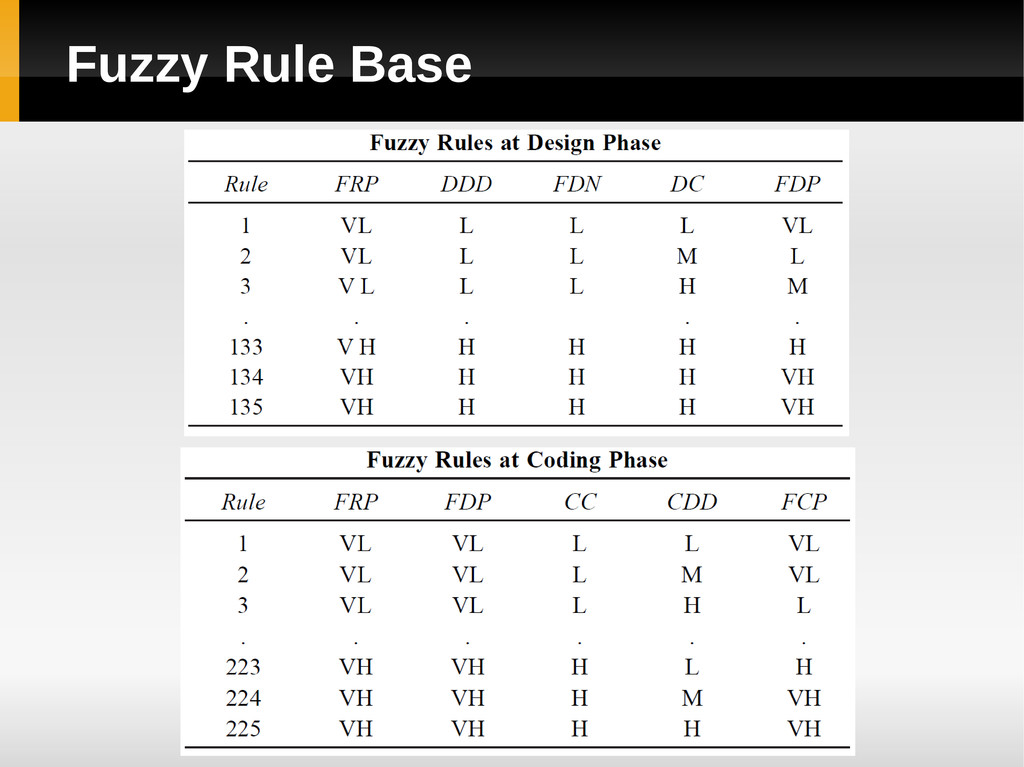
Experts, historical data analysis of similar or earlier system, and engineering knowledge from existing literature’s Rules in the form of ‘If A then B’
(fuzzy inference process or fuzzy reasoning) Defuzzification is the process of deriving a crisp value from a fuzzy set using a defuzzification method.
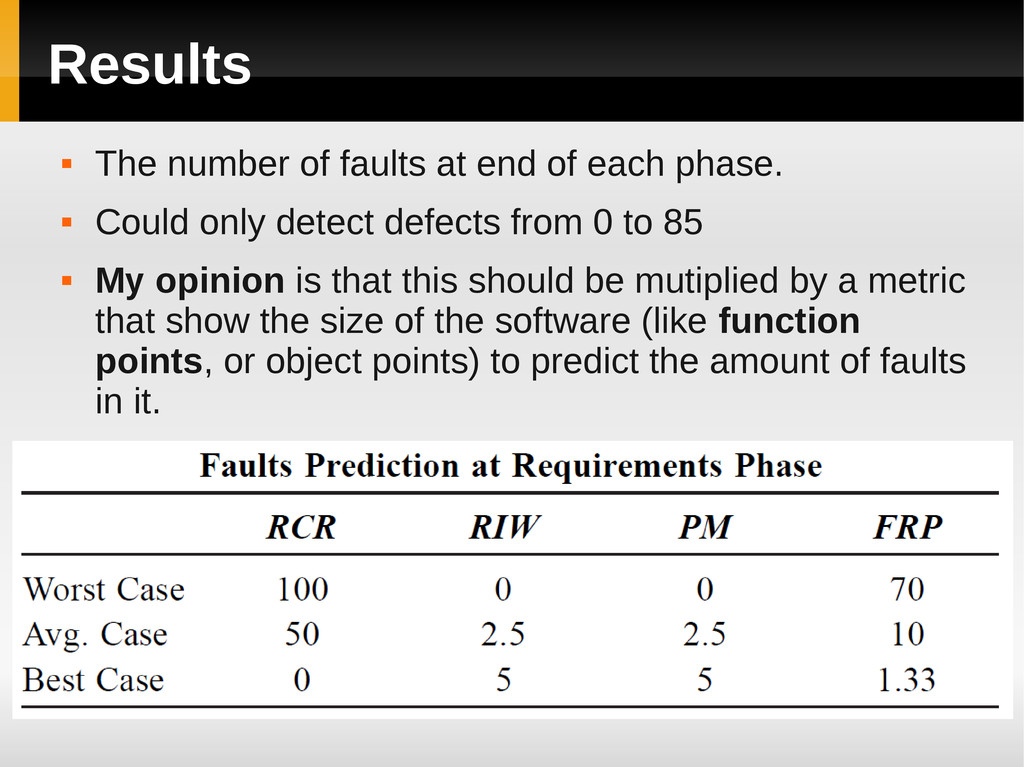
phase. Could only detect defects from 0 to 85 My opinion is that this should be mutiplied by a metric that show the size of the software (like function points, or object points) to predict the amount of faults in it.
a supervised learning method that analyzes data and recognizes patterns. The standard SVM takes a set of input data and predicts, for each given input, which of two possible classes comprises the input. The approach uses an SVM model to find the relationship between object-oriented metrics and fault proneness empirically evaluated using the KC1 NASA data set of a storage management system for ground data written in C++ with 145 classes and 2107 methods and 40 KLOC.
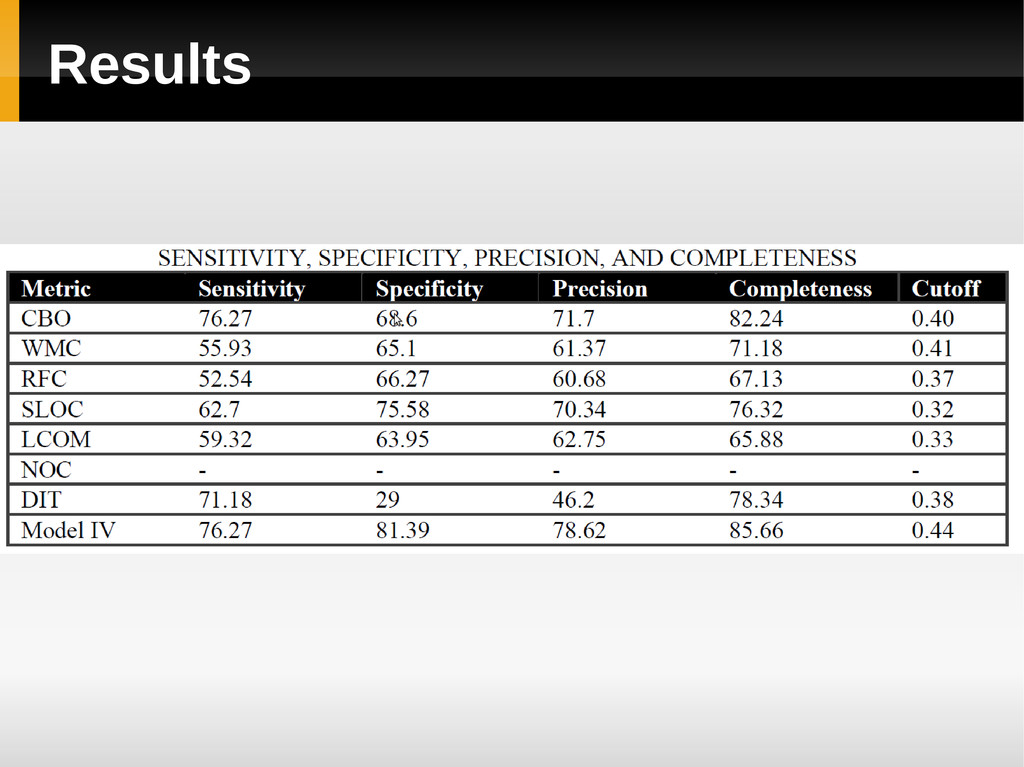
a module which contains a fault is correctly classified [7] Specificity is the proportion of correctly identified fault- free modules.[7] Probability of False alarm (PF) is the proportion of fault-free modules that are classified erroneously. PF=1-specificity [7] Precision is the probability of correctly predicting faulty modules among the modules classified as fault-prone. [7] Completeness value, which is defined as the number of faults in faulty predicted classes divided by the number of faults in all classes. [8]
search technique used in computing to find exact or approximate solutions to optimization and search problems. The accuracy of the developed system to find fault prone classes is measured as 80.14%
“population” of randomly generated “attempted solutions” to a problem then repeatedly do the following: • Evaluate each of the attempted solutions • Keep a subset of these solutions (the “best” ones) • Use these solutions to generate a new population • Quit when you have a satisfactory solution (or you run out of time) With help of Genetic algorithm classification of the software components into faulty/fault-free systems is performed
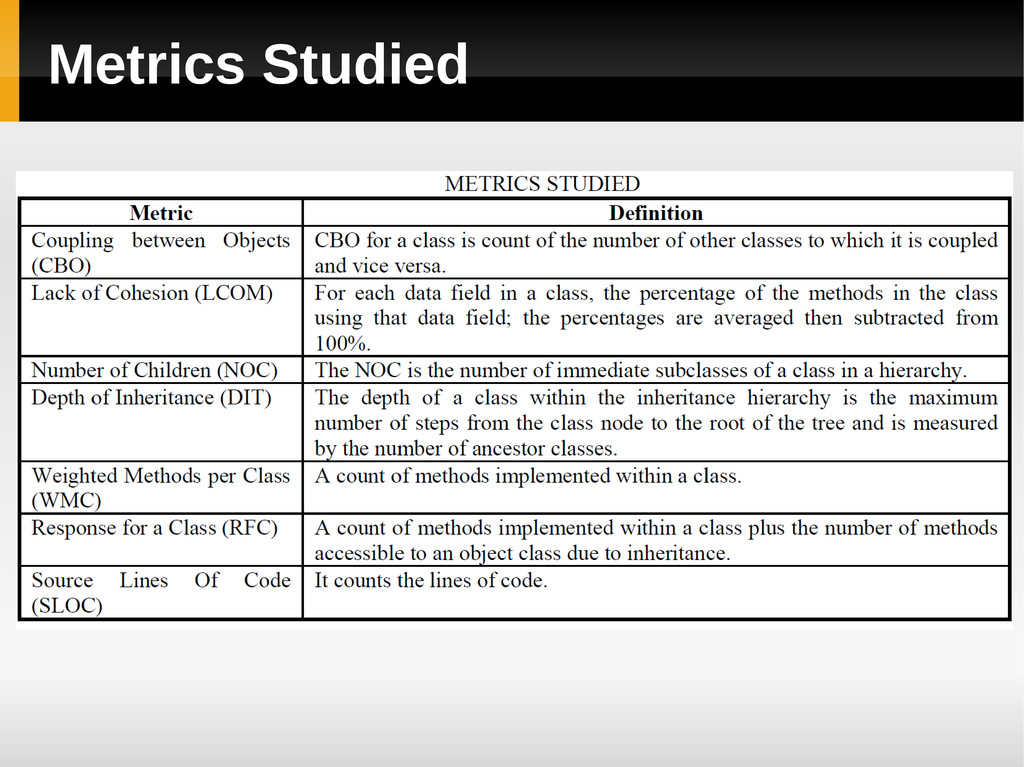
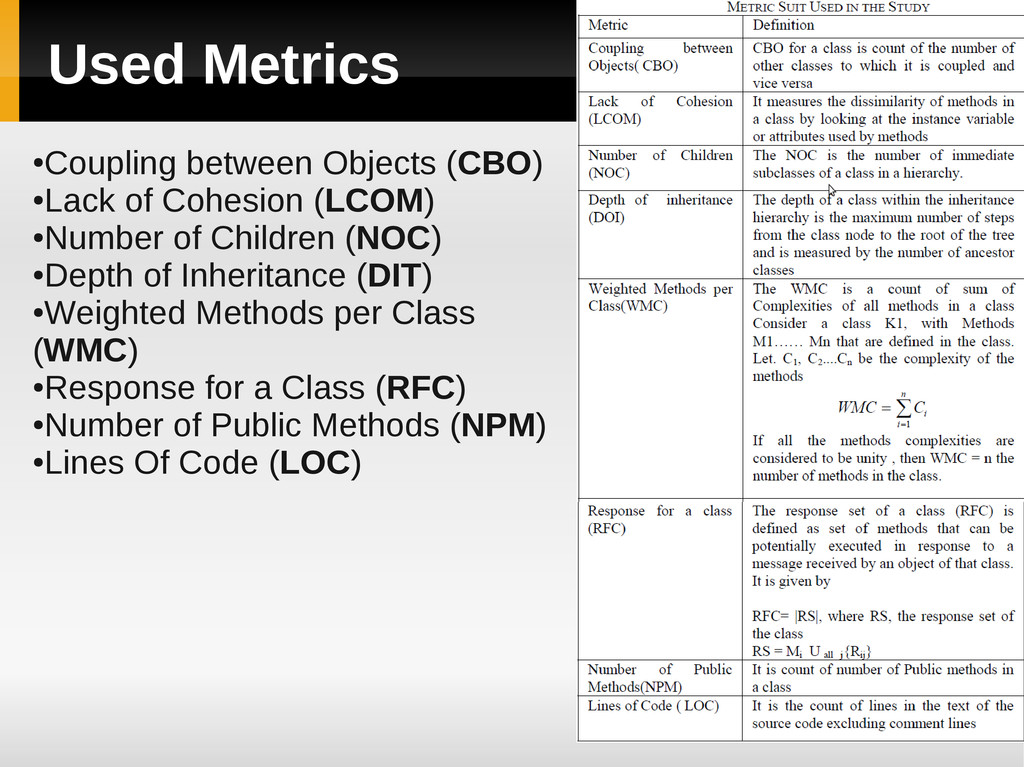
Cohesion (LCOM) • Number of Children (NOC) • Depth of Inheritance (DIT) • Weighted Methods per Class (WMC) • Response for a Class (RFC) • Number of Public Methods (NPM) • Lines Of Code (LOC)
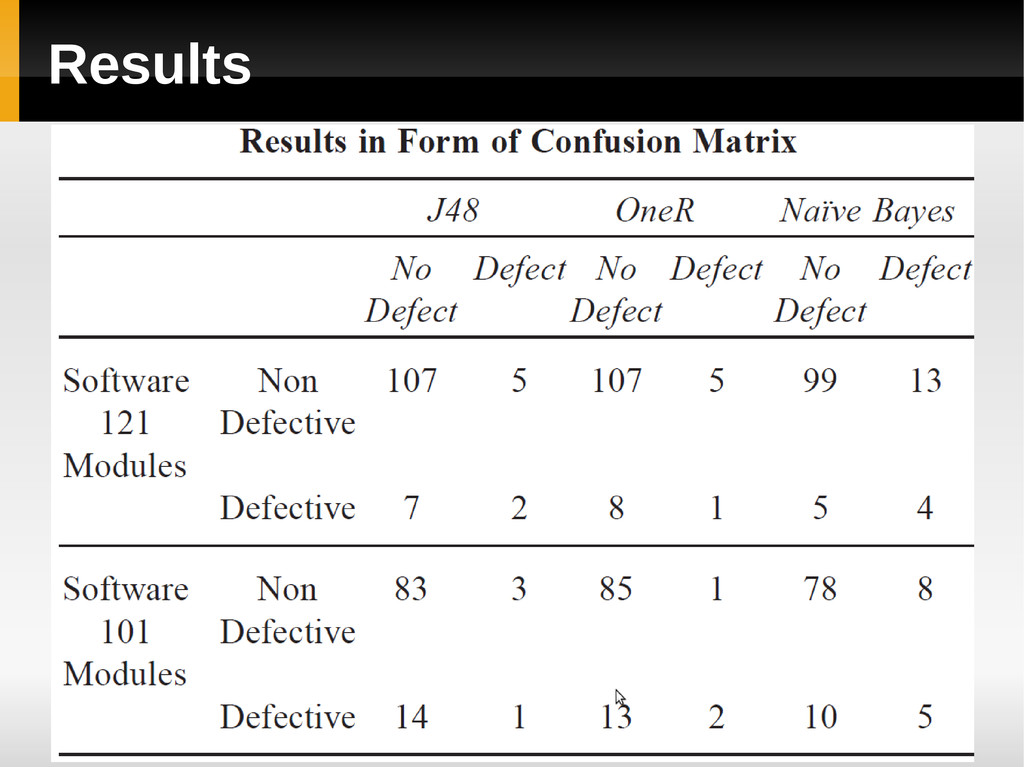
J48 OneR Naïve Bayes Used 29 Metrics Applied on 2 Small embedded pieces of software written in C 121 modules having 9 defective ones 101 modules having 15 defective ones
C4.5 recursively splits a data set according to checks on attribute values C4.5 uses greedy top-down construction technique to build classification decision trees using information theory
attribute OneR creates one rule for each attribute in the training data, then selects the rule with the smallest error rate to be the only one rule. Determines the class that appears most often for an attribute value A rule is simply a set of attribute values bound to their majority class. The error rate is the number of training data instances that the class of an attribute value does not agree with the binding for that attribute value in the rule.[4]
posterior probability Naïve Bayes assumes that all classes are conditionally independent i.e. there are no dependence relationship among the attributes. Naïve Bayes classifier estimates the probability of attribute values of each class from the training set by counting the frequency of each discrete attribute values. [4]
and risks. We discussed 4 approaches to fault prediction using machine learning algorithms on different reliability relevant software metrics and Capability Maturity Model (CMM) level. Results show that machine learning algorithms have good accuracy that can range from 80% to 90% Machine Learning approaches can also help software maintenance developers to classifying software modules into faulty and non-faulty modules.
Prediction Using Process Maturity and Software Metrics (Ajeet Kumar Pandey & N. K. Goyal, Reliability Engineering Centre, IIT Kharagpur, INDIA) [2] Software Fault Proneness Prediction Using Support Vector Machines (Yogesh Singh, Arvinder Kaur, Ruchika Malhotra) [3] A Genetic Algorithm Based Classification Approach for Finding Fault Prone Classes (Parvinder S. Sandhu, Satish Kumar Dhiman, Anmol Goyal) [4] Comparing The Effectiveness Of Machine Learning Algorithms For Defect Prediction by Pradeep Singh
(Nachiappan Nagappan, Thomas Ball, and Andreas Zeller) [6] Data Mining Static Code Attributes to Learn Defect Predictors (Tim Menzies, and Jeremy Greenwald) [7] Techniques for evaluating fault prediction models (Yue Jiang & Bojan Cukic & Yan Ma) [8] Empirical Validation of Object-Oriented Metrics on Open Source Software for Fault Prediction (Tibor Gyimothy, Rudolf Ferenc, and Istvan Siket)
{kind=link}
{kind=link}
{kind=link}
![[1] A Fuzzy Model for Early Software Fault Prediction Using](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Results [continued]](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_16.jpg){kind=link}
![[2] Software Fault Proneness Prediction Using Support Vector Machines](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Results [continued]](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_22.jpg){kind=link}
![Results [continued]](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_23.jpg){kind=link}
![Results [continued] Sensitivity and Completeness of the model](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_24.jpg){kind=link}
![[3] A Genetic Algorithm Based Classification Approach for Finding Fault](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[4] Comparing The Effectiveness Of Machine Learning Algorithms For Defect](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Results [continued] J48 and OneR performed better than Naïve](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_36.jpg){kind=link}
{kind=link}
![References [1] A Fuzzy Model for Early Software Fault](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_38.jpg){kind=link}
![References [continued] [5] Mining Metrics to Predict Component Failures](https://files.speakerdeck.com/presentations/4fc8dc48af6a0200220107d8/slide_39.jpg){kind=link}
{kind=link}