applications like : - Text Summarization - Syntactic parsing - Word sense disambiguation - Ontology construction - Sentiment and subjectivity analysis - Text clustering • Associative or semantic networks are used to represent the language units and their relations where language units are the vertices (nodes) and the relations are the edges (links).
Node can represent text units can be : (words, collocations, word senses, sentences, documents) - Graph nodes do not have to be of the same category - Edges can represent relations: (co-occurrence, collocation, syntactic dependency, lexical similarity)
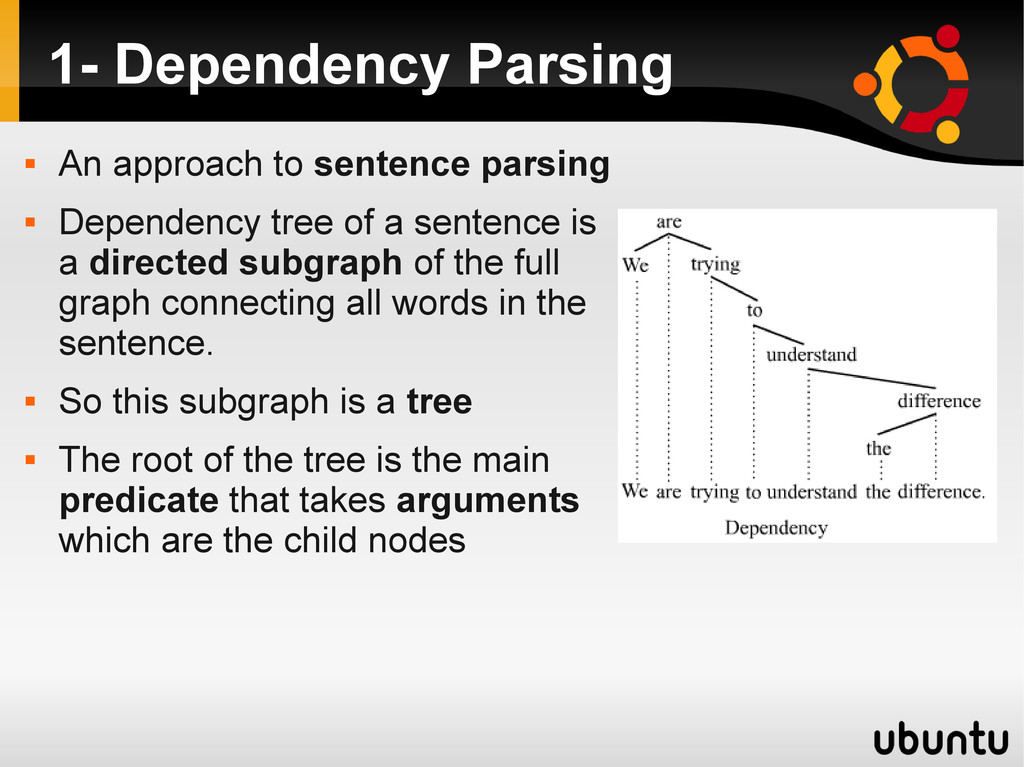
Dependency tree of a sentence is a directed subgraph of the full graph connecting all words in the sentence. So this subgraph is a tree The root of the tree is the main predicate that takes arguments which are the child nodes
the tree with the highest score using CLE (Chu Liu Edmonds) Algorithm of Maximum spanning tree (MST) in a directed graph. • Each node picks the neighbor with the highest score which will lead to a spanning tree or a cycle • CLE collapses each cycles into a single node • CLE runs in O(n^2)
then an MST is constructed by reversing the procedure and expanding all nodes. • McDonald achieved excellent results on a standard English data set and even better results on Czech (free word order language)
preposition like "with" is either attached to the main predicate (high verbal attachment) or the noun phrase before it (low nominal attachment). - “I ate pizza with olives.” - “I ate pizza with a knife.” • He proposed a semi-supervised learning process where a graph of nouns and verbs is constructed and if 2 words appear in the same context they are connected with an edge. • Random walk until convergence • Reached performance of 87.54% classification accuracy which is near the human performance which is 88.20%
a text • Can be nouns or pronouns • Approximate the correct assignment of references to entities in a text by using a graph- cut algorithm. Method: A graph is constructed for each entity • Every entity is linked to all the possible co- reference with weighted edges where weights are the confidence of each co-reference. • Min-cut partitioning separate each entity and its co-references.
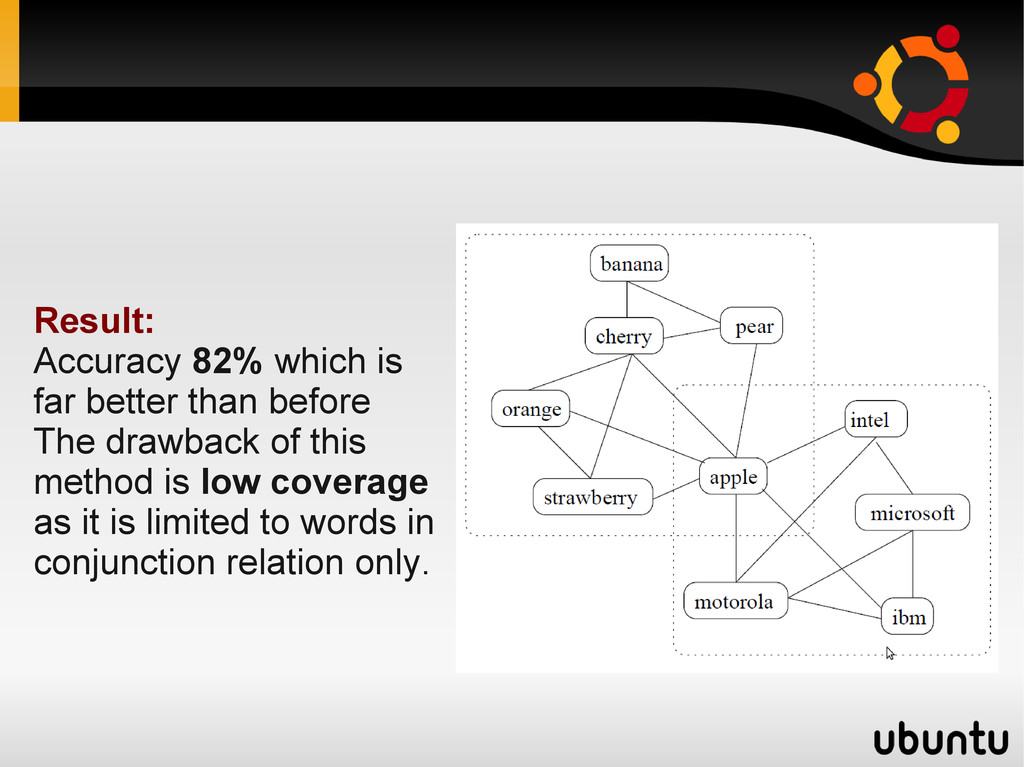
2002) Goal: build semantic classes automatically from raw corpora Method: • Build a co-occurrence graph from British National Corpus where nodes are words linked by conjunction (and/or) • Over 100,000 nodes and over half a million edges. • Representative nouns are manually selected and put in a seed set. • Largest number of links with the seed set is added to the seed
2001) Goal: • Observe Lexical Networks properties Method: • Build a co-occurrence network where words are nodes that are linked with edges if they appear in the same sentences with distance of 2 words at most. • Half million nodes with over 10 million edges Result: • Small-world effect: 2-3 jumps can connect any 2 words • Distribution of node degree is scale-free
on existing semantic networks like WordNet by applying shortest path algorithms to identify the closest semantic relation between 2 concepts (Leacock et al. 1998) • Random Walk algorithm (Hughes and Ramage, 2007) • PageRank gets the stationary distribution of nodes in WordNet biased on each word of an input word pair. • Divergence between these distributions is calculated to show the words relatedness.
al. 2005) Method: • Construct a graph of labeled and unlabeled examples for a given ambiguous word • Word sense examples are the nodes and weighted edges are drawn by pairwise metric of similarity. • Known labeled examples are the seed set are assigned with their correct labels (manually) • Labels are propagated through the graph through the weighted edges • Labels are assigned with certain probability • The propagation is repeated until the correct labels are assigned. Result: Performs better than SVM when there is a small number of examples provided.
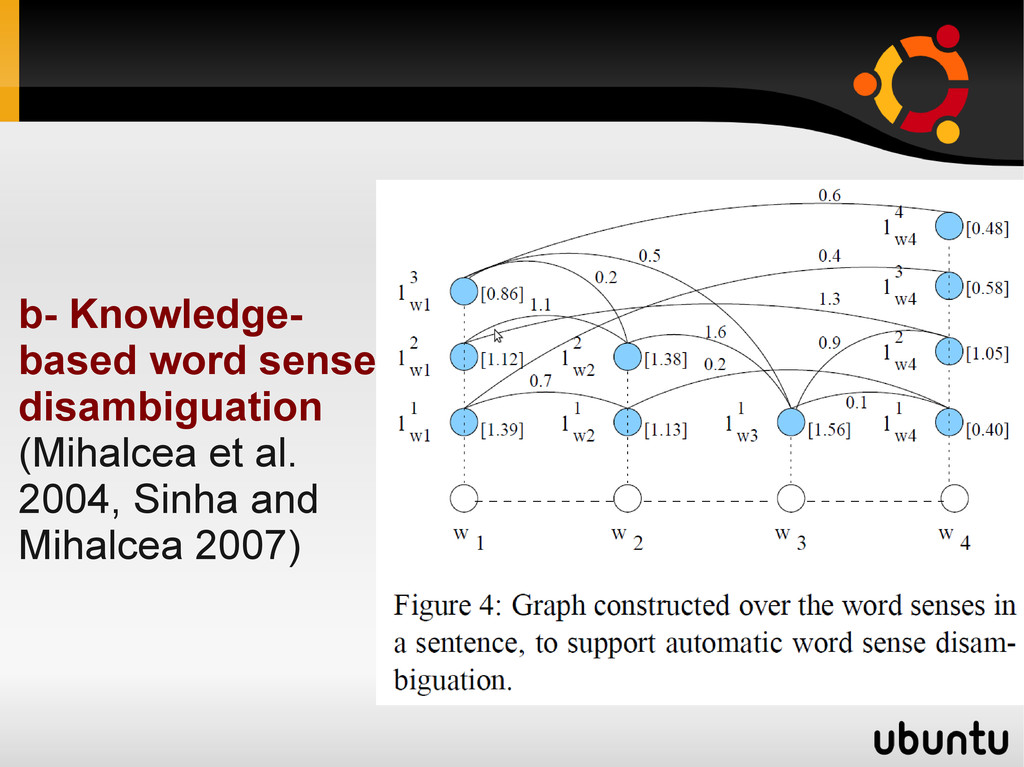
all the senses of its words as nodes • Senses are connected on the basis of their semantic relations (synonymy, antonymy ...) • A random walk results in a set of scores that reflects the importance of each word sense. Result: • Superior to other Knowledge-based word sense disambiguation that did not use graph based representations. Follow up work: • Mihalcea did not use semantic relations but she used weighted edges using a measure of lexical similarity • Brought generality as it can use any electronic dictionary not just a semantic network like WordNet
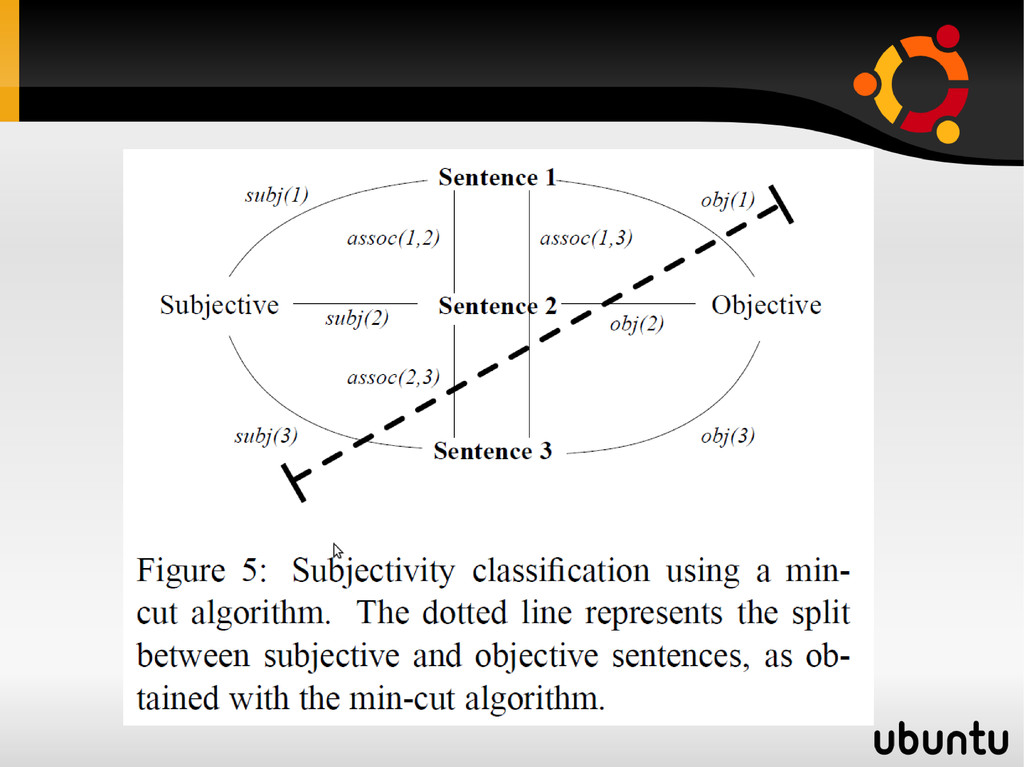
(Pang and Lea 2004) Method: • Drawing a graph where sentences are the nodes and the edges are drawn according to the sentences proximity • Each node is assigned a score showing the probability that its sentence is subjective using a supervised subjectivity classifier • Use min-cut algorithm to separate subjective from objective sentences. Results: • Better than the supervised subjectivity classifier b- By Assignment subjectivity and polarity labels (Esuli and Sebastiani 2007) Method: • Random walk on a graph seeded with nodes labeled for subjectivity and polarity.
a graph of the corpus where every node is a paragraph • Lexically similar paragraphs are linked with edges • A summary is retrieved by following paths defined by different algorithms to cover as much of the content of the graph as possible. b- Lexical Centrality (Erkan and Radev 2004) (Mihalcea and Tarau 2004) Method: • Sentences are nodes of the graph • Random walk to define the most visited nodes as central to the documents • Remove duplicates or near duplicates • Select sentences with maximal marginal relevance
et al., 2005) Answer a question from a group of documents Method: • Use biased random walk on a graph seeded with positive and negative examples • Each node is labeled according to the percentage a random walk ends at this node • The nodes with the highest score are central to the document set and similar to the seed nodes.
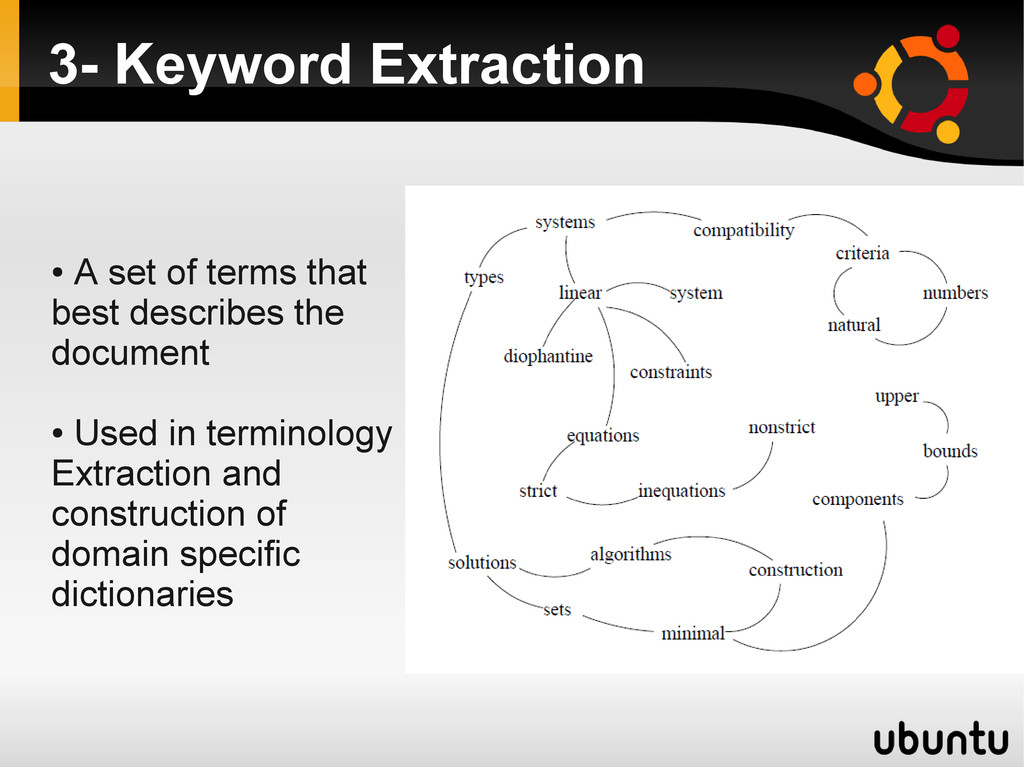
graph of for the input text where words are the the text words • Words are linked by co-occurrence relation limited by the distance between words. • Random walk on graph • Words ranked as important important and found next to each other are collapsed into one key phrase Result: • A lot better than tf.idf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1- Lexical Networks [continued] b- Lexical Network Properties(Ferrer-i-Cancho and Sole,](https://files.speakerdeck.com/presentations/4fc8de4b02ee4b0022013ab1/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}