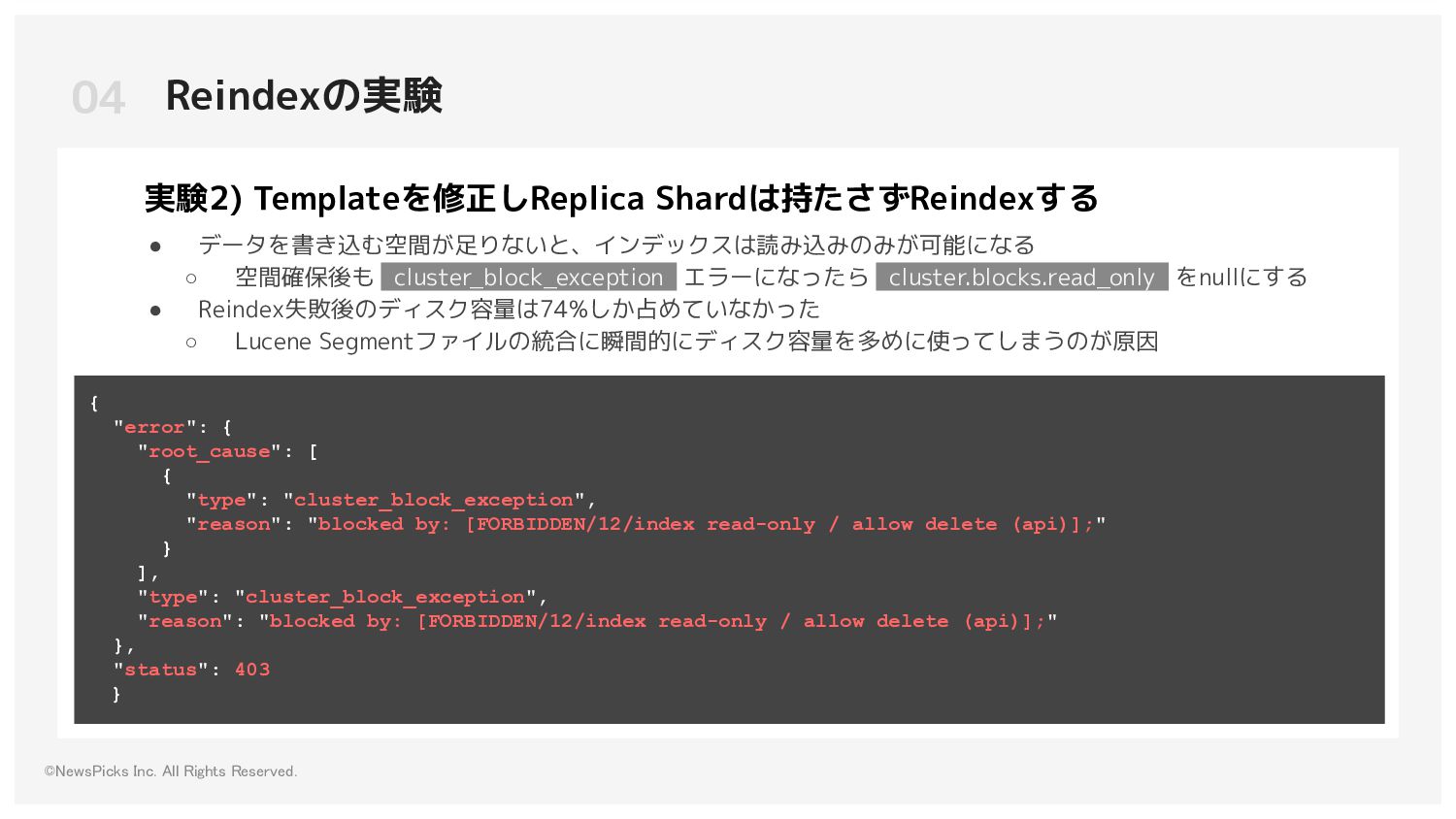
CPU 使用率がぐっと上がり、終わるまでその状態がつづく ◦ Node1台あたりのShard数が多くない場合は、Reindex中の CPU 使用率が60%程度に留まる • Reindex中に既存インデックスに対して検索を連続で行っても、レスポンスは問題なくスピーディー に返し、負荷もかからない • Templateを変更してのReindexは場合によっては、ディスクを多く占めるので、e既存 index サイズ * 3e のディスク容量を用意するのが安全である 05 実験でわかったこと 3つの実験からの気づき
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}