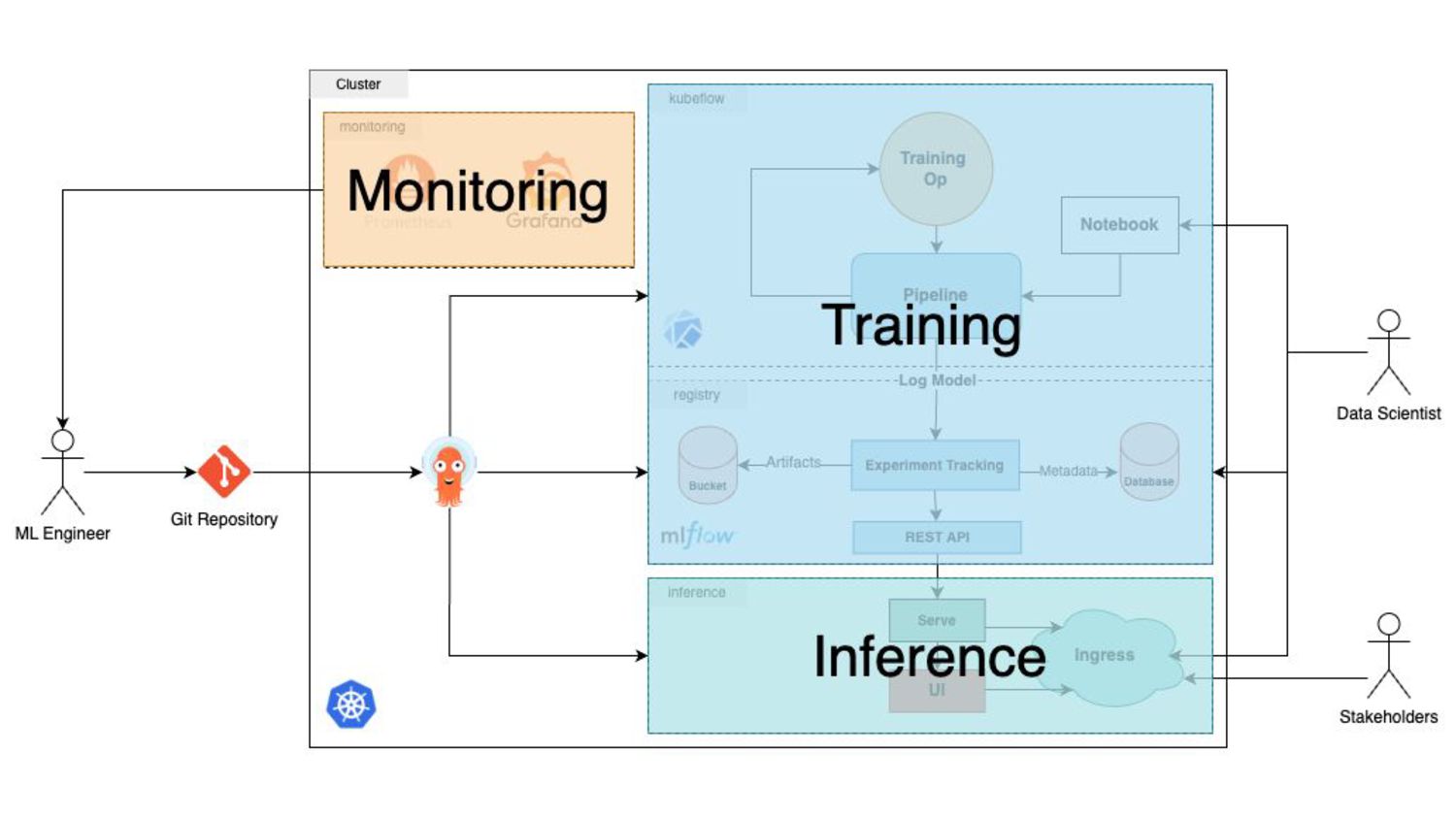
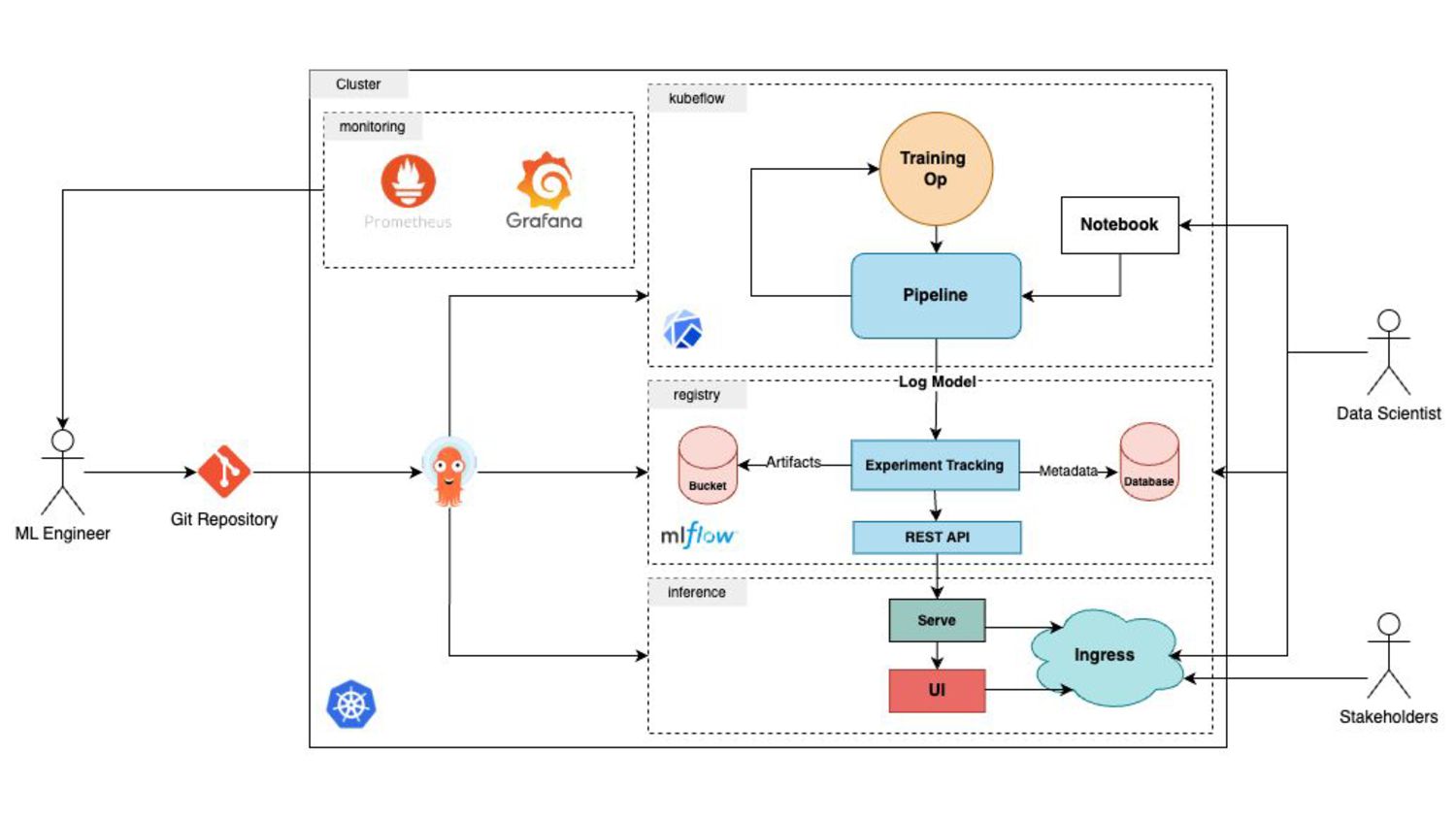
experimenting ideas - In a worksetup, a team works on AI model design-development - Training models usually involve long running tasks - Model training consists of different steps (preprocessing, training …) - Provisioning hardware for a couple of hours are way more affordable than owning it - We need to monitor the process, dig into each step and be able to debug 2
(Digital Ocean) 2. Track experiments (MLFlow) 3. Separate steps (Kubeflow Pipeline Components) 4. Register Models (MLFlow Model Registry) 5. Use Notebooks with predefined images (Jupyter Notebook) 6. Serve Models from model registry (MLFlow/PyTorch) 7. Evaluate Models with a UI (Streamlit)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}