Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
(n=1の)テーブルデータコンペの取り組み方
Search
Makoto Hyodo
September 20, 2023
Technology
5.1k
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
(n=1の)テーブルデータコンペの取り組み方
2023/9/23の関東Kaggler会でお話する予定の資料です!
Makoto Hyodo
September 20, 2023
Other Decks in Technology
See All in Technology
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
320
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
180
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
140
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
31
26k
Retriever と Reranker、結局どうする?
kazuaki
1
510
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
800
QAと開発の両側から進める AI活用 -QAプロセスAI支援ツールキットと Inner Loop / Outer Loopの取り組み-
legalontechnologies
PRO
2
380
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
200
害獣害虫を自動判別! ペストコントロール支援ビジネス成功のヒント【SORACOM Discovery 2026】
soracom
PRO
0
130
NetBoxを利用した作業効率化の試み_NetDevNight4
tnoha
0
390
PLaMoを毎日の開発で使い育てていく
pfn
PRO
0
140
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
710
Featured
See All Featured
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
440
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
230
For a Future-Friendly Web
brad_frost
183
10k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
4k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
How to train your dragon (web standard)
notwaldorf
97
6.7k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
360
Transcript
(n=1の)テーブルデータコンペの 取り組み方 2023/09/23 関東Kaggler会
自己紹介 兵藤 誠(Makotu) ※kaggleのアイコンはその時々の推しのアニメやVtuberのキャラにしており 安定してなかったんですが今は上のアイコン(有馬かな)に落ち着いています。 • 普段は受託分析会社でクライアントワーク • 仕事では基本的にテーブルデータを触ることが多い •
データ分析よりクライアントコミュニケーション 関連の方がたぶん得意 1~2年前くらいに使ってたやつ
Kaggleではテーブルデータが主戦場 テーブル テーブル テーブル テーブル NLP BAN
ここ1年程度はやけに調子が良かったです テーブル テーブル テーブル テーブル NLP BAN 1年以上前
色々学びはありましたが…(主に精神面で) • チームは知ってる人 or コードやSolutionを ちゃんと公開している人と組むのが良い、という学び。 (某Oがつくレコメンドコンペ) • 運営の方にはイラついても 常に感謝の気持ちを忘れずに
平常心をキープするメンタル。 (某Pがつく子供向けゲームコンペ。瞑想を日課にしてた。)
今日は自分の取り組み姿勢について話します テーブルデータコンペの取り組み方全般 • 各コンペのSolutionはDiscussionを見れば良いので割愛 • 「銀・銅メダルは毎回取れるんだけど」くらいの方のご参考になれば
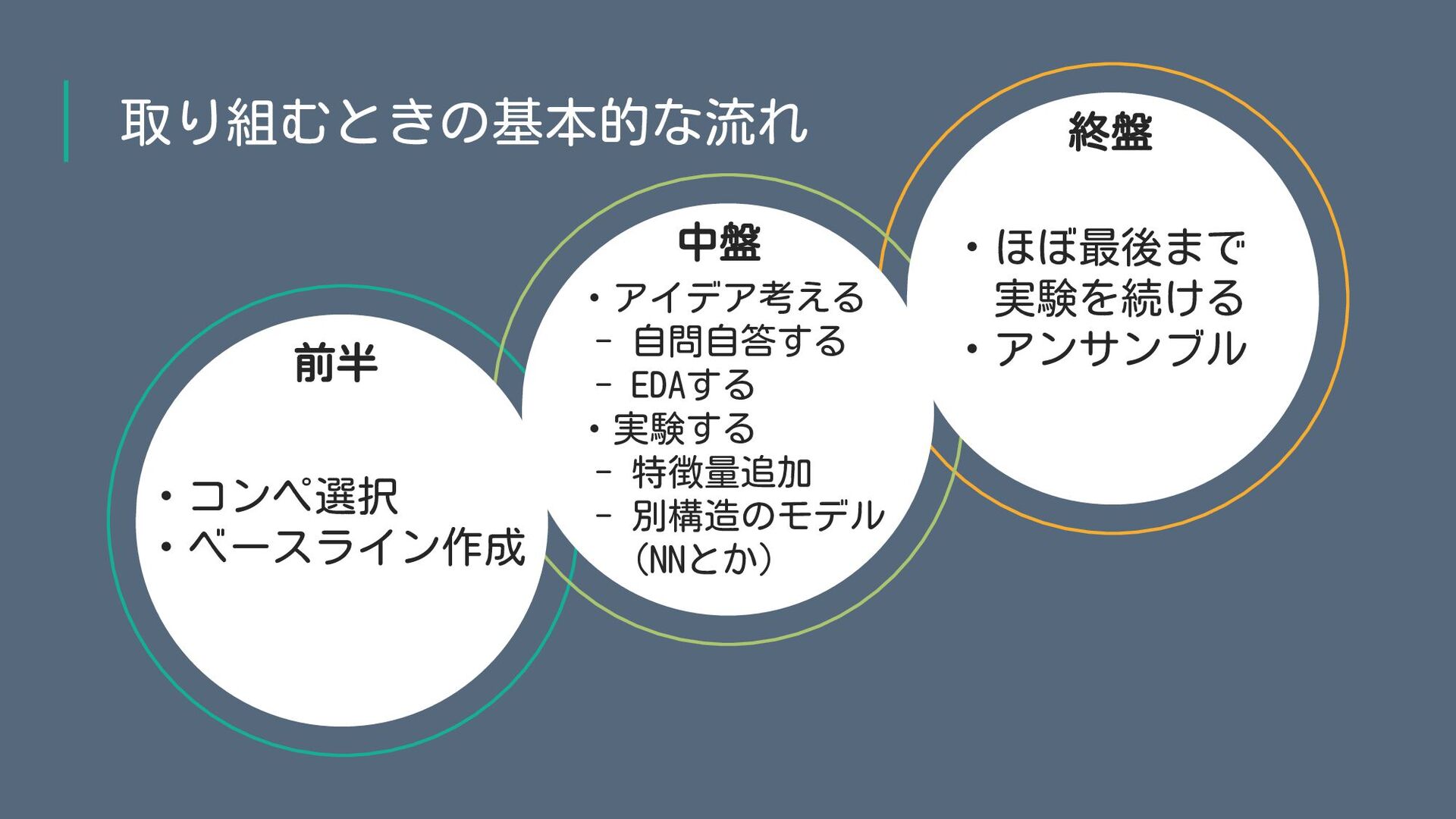
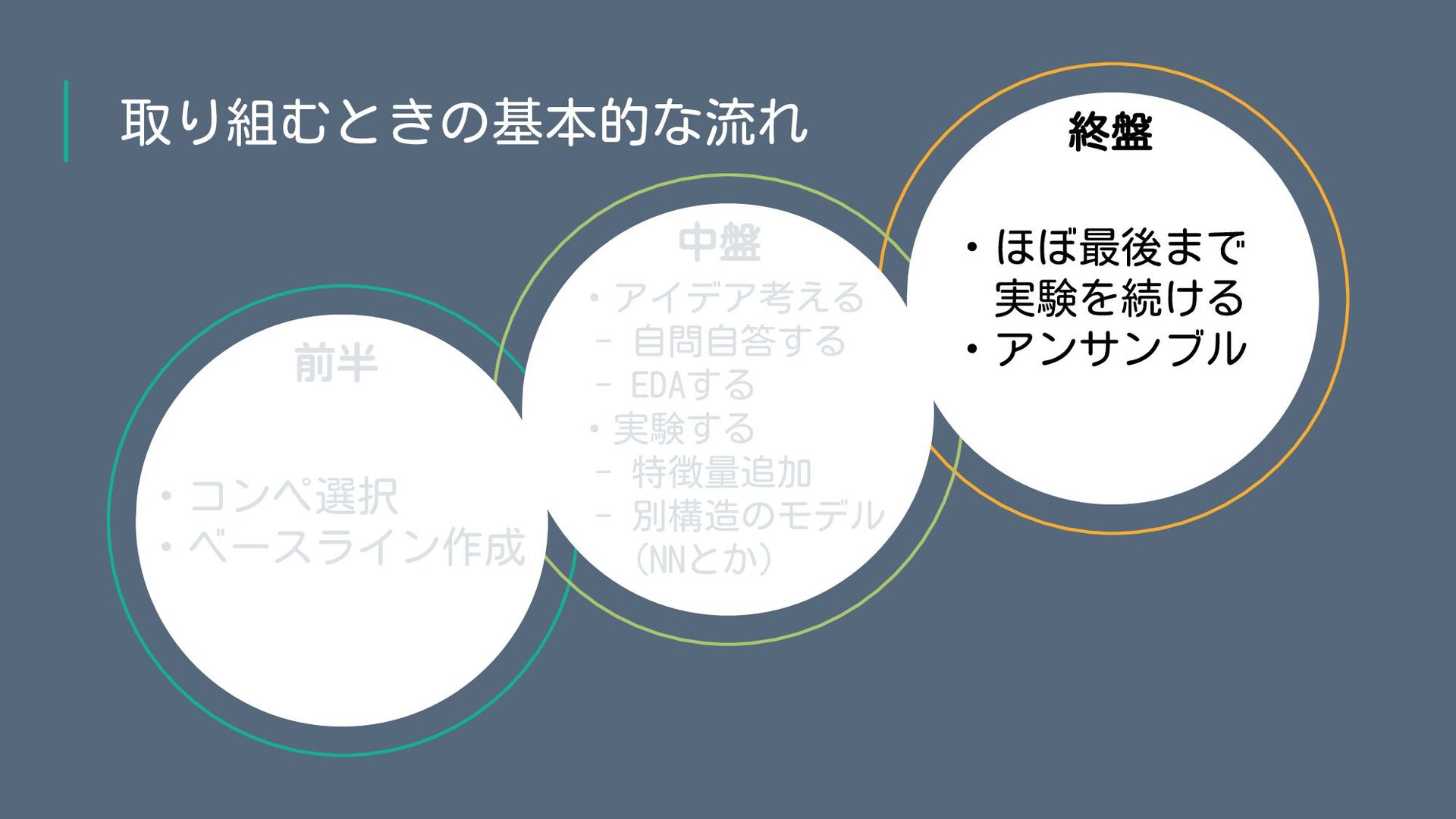
取り組むときの基本的な流れ ・コンペ選択 ・ベースライン作成 ・アイデア考える - 自問自答する - EDAする ・実験する -
特徴量追加 - 別構造のモデル (NNとか) ・ほぼ最後まで 実験を続ける ・アンサンブル 前半 中盤 終盤
取り組むときの基本的な流れ ・コンペ選択 ・ベースライン作成 ・アイデア考える - 自問自答する - EDAする ・実験する -
特徴量追加 - 別構造のモデル (NNとか) ・ほぼ最後まで 実験を続ける ・アンサンブル 前半 中盤 終盤
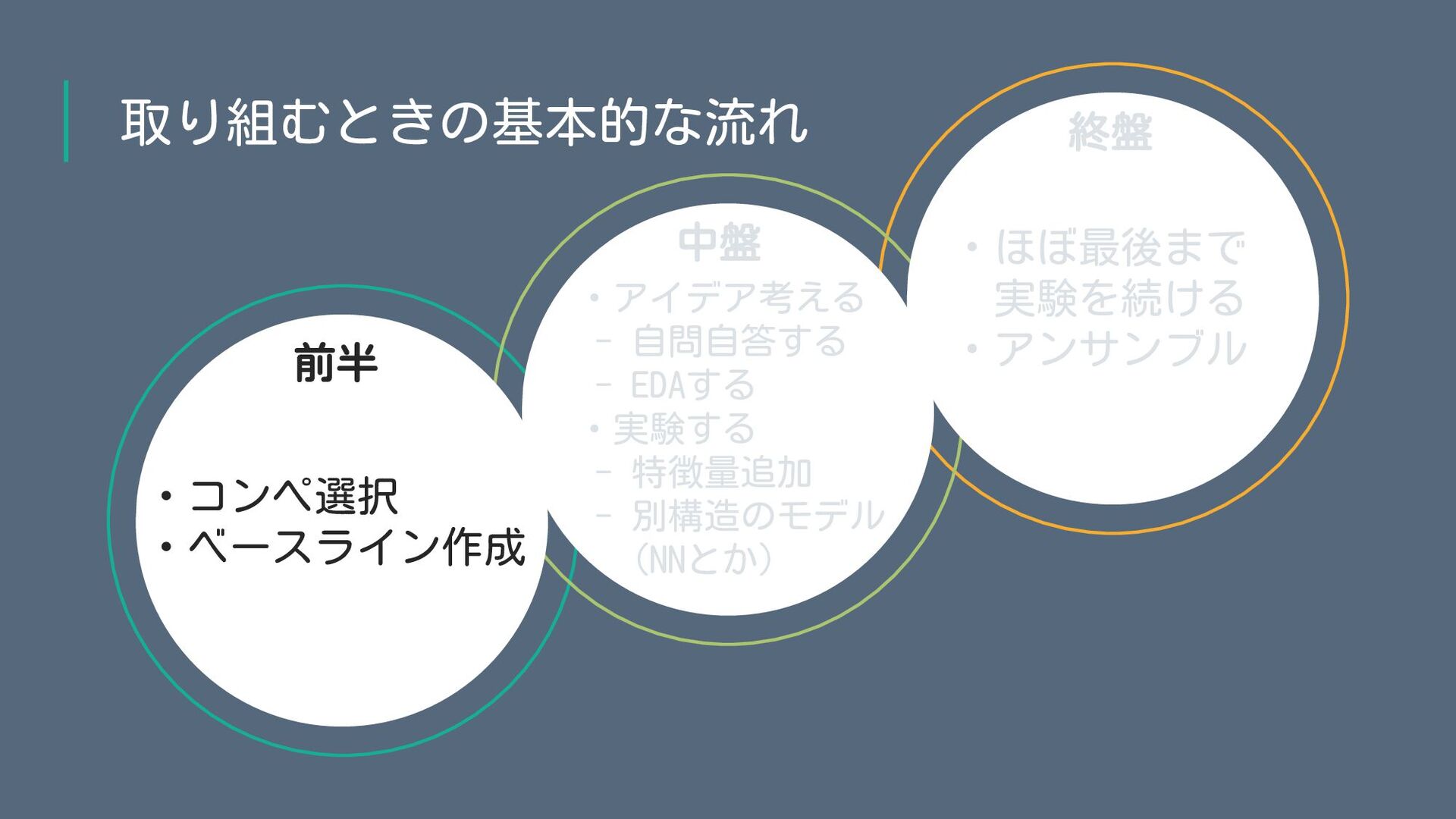
参加前:コンペ選択 1. 新しい学びがありそう(学び重視) • 今まで触れていなかったデータ・ジャンル • 自分の場合、テーブルが得意なので画像やNLPとかのコンペは「学び重視」の範疇 • タスク設定が斬新 2.
高順位が取れそう(成果重視) • CV-LBが相関してそう / 上位メンツ的に安心そう • 自分が経験してきたデータ・タスクに似ている • 自分の場合は「人の行動」を題材に扱うコンペが得意で、そういうコンペを選びがち • リソース勝負にならなそう 「新しい学びがありそう」 「高順位を取れそう」の2軸が存在し、 その時の状況やモチベーションによって重み付けが変化。
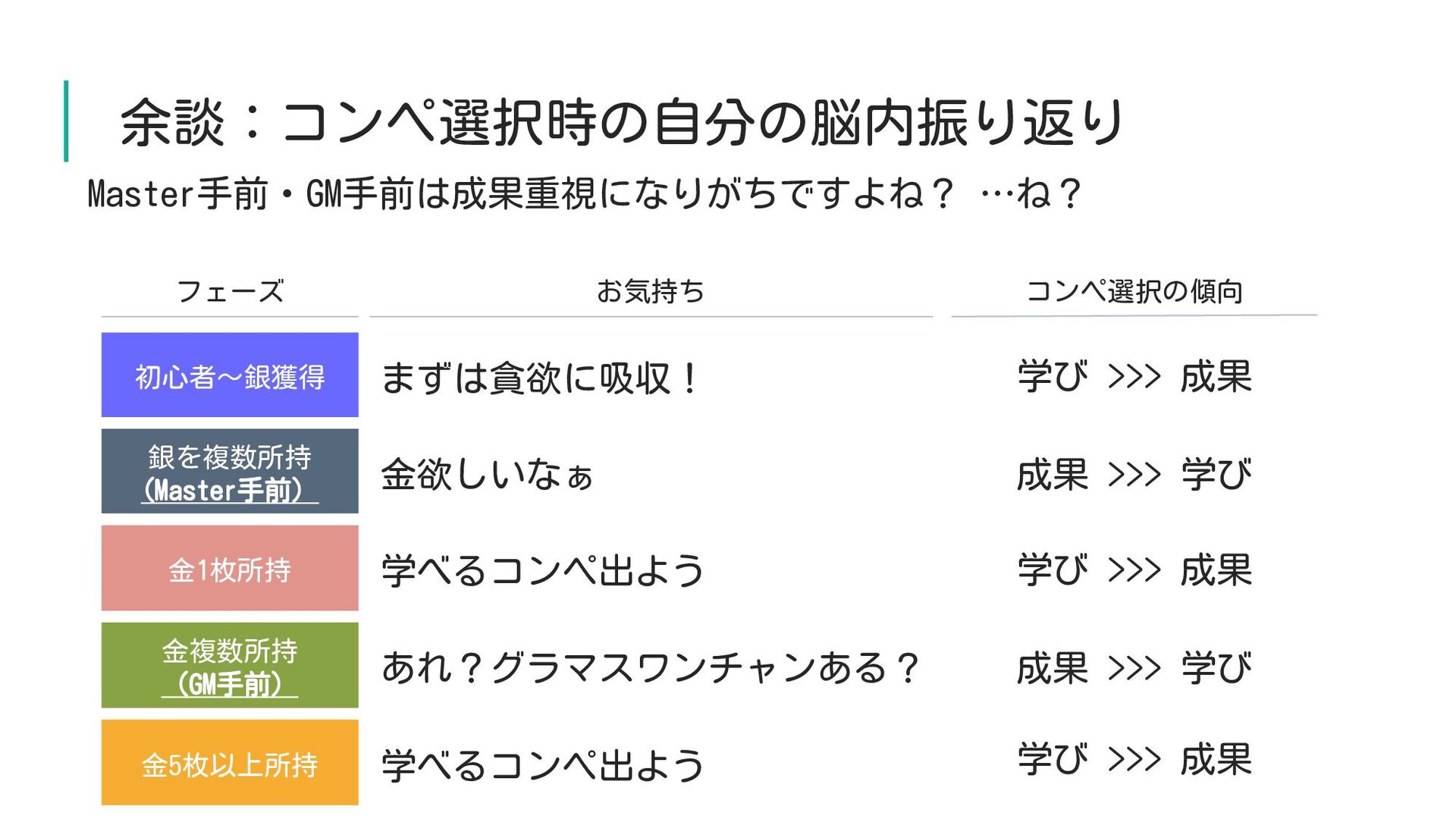
余談:コンペ選択時の自分の脳内振り返り Master手前・GM手前は成果重視になりがちですよね? …ね? 初心者~銀獲得 まずは貪欲に吸収! 金欲しいなぁ 学べるコンペ出よう 銀を複数所持 (Master手前) 金1枚所持
金複数所持 (GM手前) あれ?グラマスワンチャンある? 学べるコンペ出よう 金5枚以上所持 フェーズ お気持ち コンペ選択の傾向 学び >>> 成果 学び >>> 成果 成果 >>> 学び 学び >>> 成果 成果 >>> 学び
前半:ベースライン作成 • Public Notebookはチラッとだけ確認 • どういう手法が使われているかのみを確認 • クオリティが高いことがほぼ約束されている場合はある程度見る (ChrisさんとかRadekさんとか) •
Folkはしない。基本は自前で実装する • 自前で実装しないと(=完全に不明点が無い状態にしないと) その後の実験や試行錯誤の幅が狭まる • ただ、銀圏下位・銅圏を狙うならFolkして自分の工夫を少し足すのが 時間効率が良いと思う • とりあえずある程度CV-LBがある程度相関していればOK • 変に時間を使わず、スピード感重視
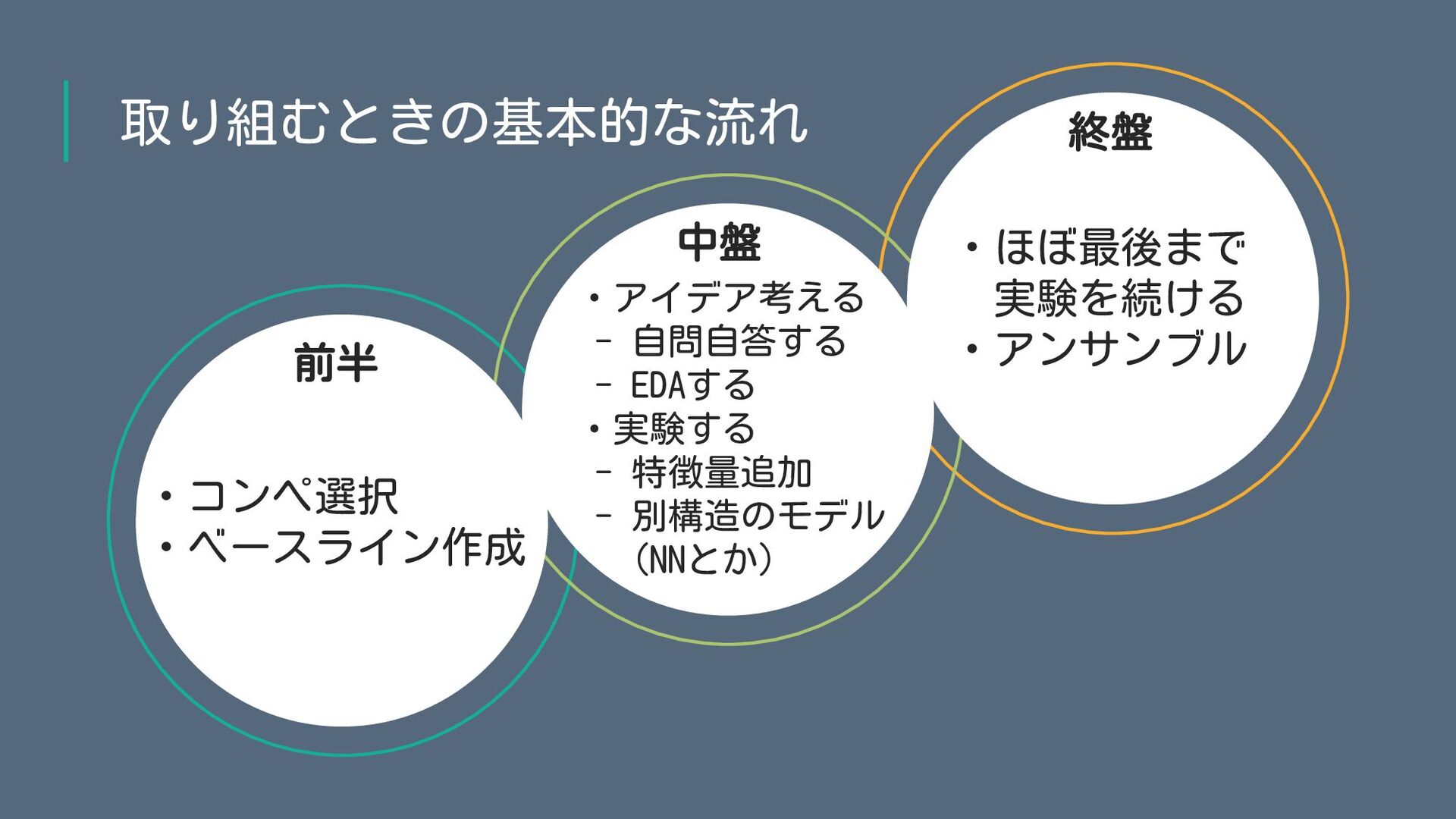
取り組むときの基本的な流れ ・コンペ選択 ・ベースライン作成 ・アイデア出し - 自問自答する - EDAする ・実験する -
特徴量追加 - 別構造のモデル (NNとか) ・ほぼ最後まで 実験を続ける ・アンサンブル 前半 中盤 終盤
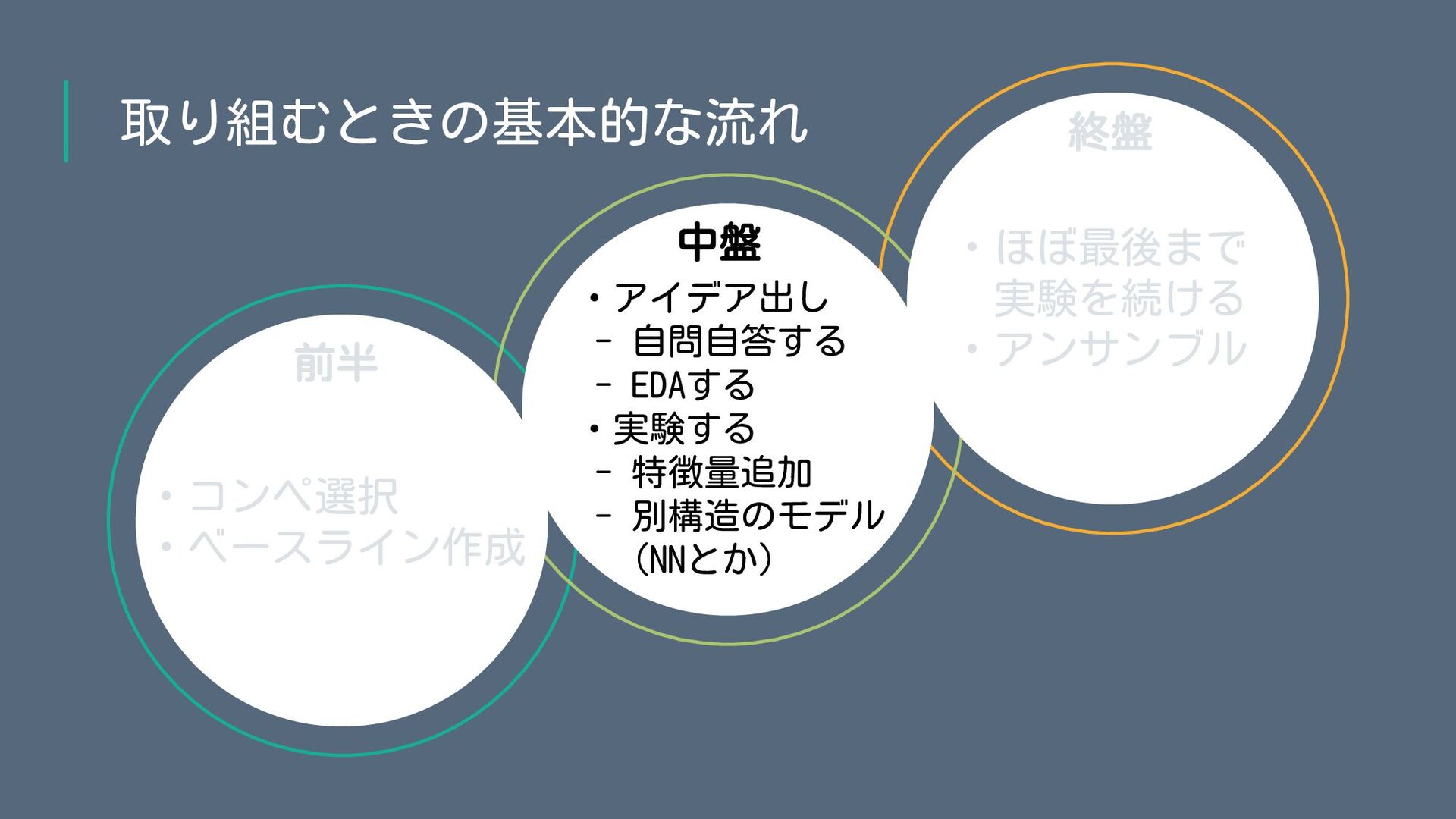
中盤:アイデア出し(自問自答する) • データの背景や、ユーザーの行動や気持ちを想像して もっと良い特徴量や見落としている要素が無いかを自問自答する。 • 試行錯誤がうまくいかなった際、なんでうまくいかなかったのか?を 自分に問いかける。 散歩したりお風呂入ったりなど自分がリラックスできる時間帯に行い、 思いついたらslackの自分の個人チャンネルに投下する。
• このコンペってどんなコンペだっけ?登場人物誰だっけ? 登場人物の行動の特徴は? • 任意のUser_idの人になったと仮定して、どういう行動を取りそう? たまーにやりそうな行動は?明らか変な行動は? • 今の知識のままコンペ初期にタイムスリップしたとして、 どういうアプローチや何に気をつける? •
今までの実験で「あれ?」って思ったことは何?それはなぜ? • 今の実験、なんでうまくいかなかったと思う、ねえなんで? • いきなり強い人から「そのアプローチ全然間違ってるよ」と 言われたと仮定して、何が間違っていそう? 自分に問いかける質問例
実験B: CV/LB 下がった! 自問自答してもアイデアが出ない時って? (メタい発言だが)単純に自分に 「アイデアを出すために必要な学習データ」が溜まっていない説。 • 色々なコンペで自分でアイデアを考えて良かった・悪かった経験 • 特に悪い結果が出たときに「悔しい、なぜ!?」と思い自分なりの仮説を
立てる経験の繰り返し(なぜ悪かったのか?を言語化できると良いと思う) • 色々なコンペで他人のソリューションを確認した経験 • 画像や自然言語は、おそらくここに最新手法の論文の考え方なども加わると思われる 実験A: CV/LB 上がった! 自分の中の学習データとして蓄積
• パーキンソン病患者の、今までの病状進行度と タンパク質のデータからn年先の病状の進行度を予測するコンペ。 • データ数が少なかったので、データを見ながらじっと妄想。 • 患者側だけでなく、病院側のお気持ちになった時に、健康な人からは 毎回データ取得するのってめんどいんじゃね?という発想から 健康な人と不健康な人で来院頻度や時期に差があることに気づけた。 •
発想が先に来て、後からEDAして「やっぱりそうか」と確信を持った。 自問自答の例 AMP-Parkinson's Disease Progression Prediction
• アメリカの子供向けゲームで、各ユーザーがゲーム内で出題される 18問の質問に1回目の回答で正解できるかを予測する。 • 実際にプレイしながらユーザーのお気持ちになって特徴量を考えた。 • 必ず通るイベントと通らないイベントがある、などの気づきを得たり、 ゲーム内のお助けヒント(Notebook)をどのイベントの前で 何秒開いたかの特徴量、など良く効いてる特徴量を作りこめた。 自問自答の例
Predict Student Performance from Game Play
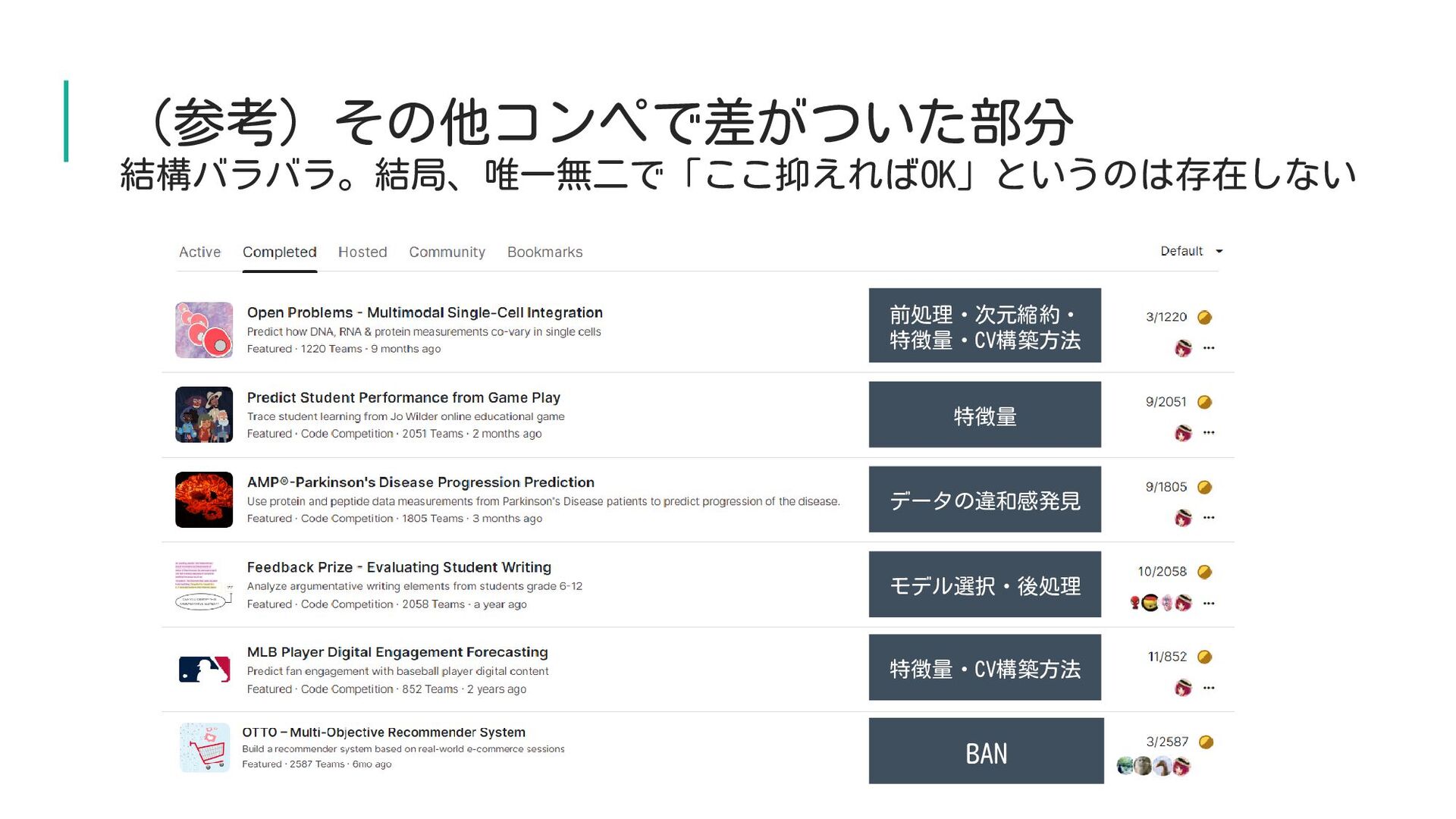
(参考)その他コンペで差がついた部分 結構バラバラ。結局、唯一無二で「ここ抑えればOK」というのは存在しない 前処理・次元縮約・ 特徴量・CV構築方法 特徴量 モデル選択・後処理 特徴量・CV構築方法 データの違和感発見 BAN
中盤:EDA • EDAは中盤以降に実施。(publicのEDAだけは初期にサラッと見る) 試行錯誤がうまくいかない理由を確認したり、考えたアイデアや 仮説がうまくいきそうかを確認するときに初めてEDAして確認する。 「探索的」データ分析は探索する明確な目的が無いと時間の無駄。 • 上記のように主に目的を持って探索することが多いが、あまりに 行き詰ったら、目的無くデータ見たりグラフ作ったりして じーっと違和感を探すことも。
画像コンペで、画像を見て人の目で違和感を見つけるのに似ているかも。
中盤:実験 1実験 1Notebook派閥 • ファイル名を「exp_xxx_(実験内容)_(cv)」ってする。 基本一人で見返す(自分がわかれば良い)ので管理は適当。 • パラメータセンシティブではないテーブルデータコンペは正直これで十分。
取り組むときの基本的な流れ ・コンペ選択 ・ベースライン作成 ・アイデア考える - 自問自答する - EDAする ・実験する -
特徴量追加 - 別構造のモデル (NNとか) ・ほぼ最後まで 実験を続ける ・アンサンブル 前半 中盤 終盤
終盤:アンサンブル • アンサンブルにはそこまで時間かけない派 • CV見ながらアンサンブルして、後は最後まで 実験に時間を費やすことが多い (アイデア出ない時にアンサンブルに時間かけるイメージ)
その他(1) • (少なくとも勾配ブースティング系がメインのコンペについては) パラメータチューニングにほぼ時間をかけない (同じ時間で別のアイデアを試す方が投資対効果が大きい印象) • テーブルデータであっても、勾配ブースティングだけでは金圏に 辿り着ける可能性は低くなっている(特に時系列が絡むケース)。 NN系(MLP・LSTM・Transformer)はある程度自由に組めると良さげ。
その他(2) • シンプルな法則として、試行錯誤の量・質と最終成績は (変なコンペじゃない限り)ある程度は関連してるはず。 • 試行錯誤の量も質も、投資する時間と関連してるはず。 • 「色々なコンペに出て、色々な解法を考えて試して、 ある程度の時間をちゃんと投資する」ことを繰り返せば 結果はついてくるのでは。
取り組むときの基本的な流れ ・コンペ選択 ・ベースライン作成 ・アイデア考える - 自問自答する - EDAする ・実験する -
特徴量追加 - 別構造のモデル (NNとか) ・ほぼ最後まで 実験を続ける ・アンサンブル 前半 中盤 終盤
今後の目標 ・テーブル以外でソロ金取って、 ソロ金5枚のGMになることをゆるく目指してみる。 (参加コンペは「学び重視」に重きを置く)
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}