Big Data is a buzz-phrase that's been becoming more and more popular these days. Are you wondering whether you should care about all the hype? I did, not so long ago, and the answer for me is a Big Yes. In this talk, I'll show you what I found so appealing about this topic that it pushed me to make quite a radical shift in my career as a developer. At the beginning of my journey, my understanding of Big Data was, as I quickly realized, very limited. That's why I'd like to give you a birds-eye view of different sub-areas and specializations that Big Data entails. We'll touch on topics like infrastructure, engineering, data science and visualization. We'll see some real-world use-cases. We'll learn a bit about algorithmic aspects of dealing with large amounts of data. We'll take a look at recent proliferation of Big Data-related technologies, products and vendors, both open-source and commercial. And finally we'll get our hands dirty by doing some live coding demo.
![@MarekStoj [email protected]](https://files.speakerdeck.com/presentations/726d24bacb324190ae8727350a1f48d7/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
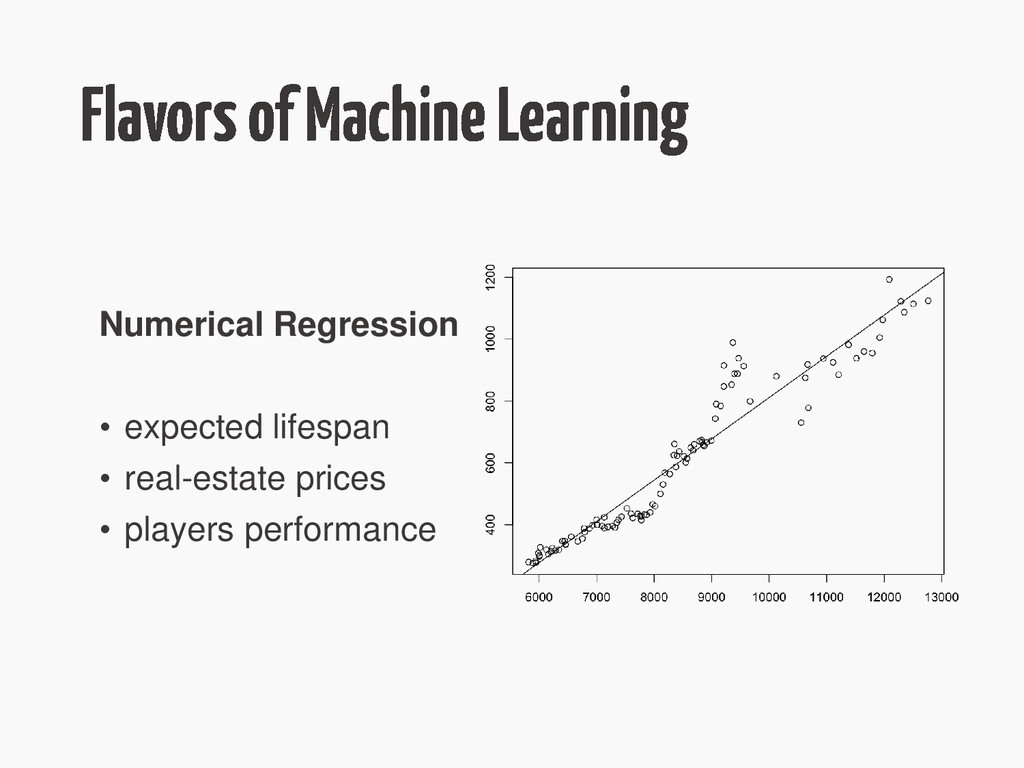{kind=link}
{kind=link}
{kind=link}
{kind=link}
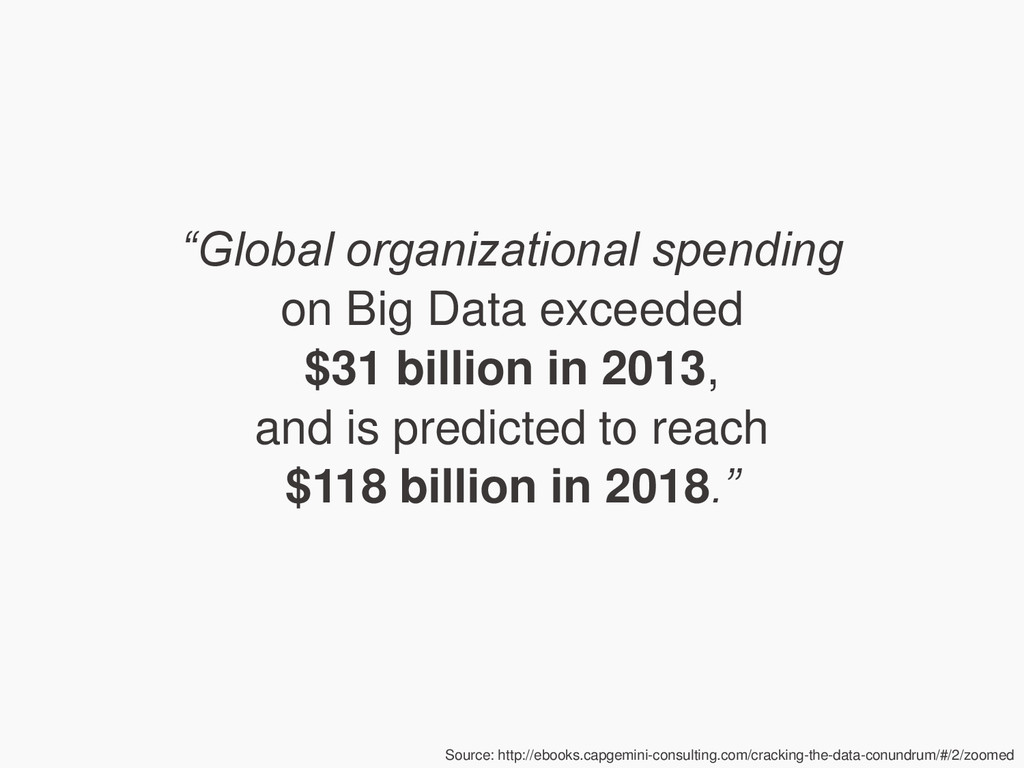{kind=link}
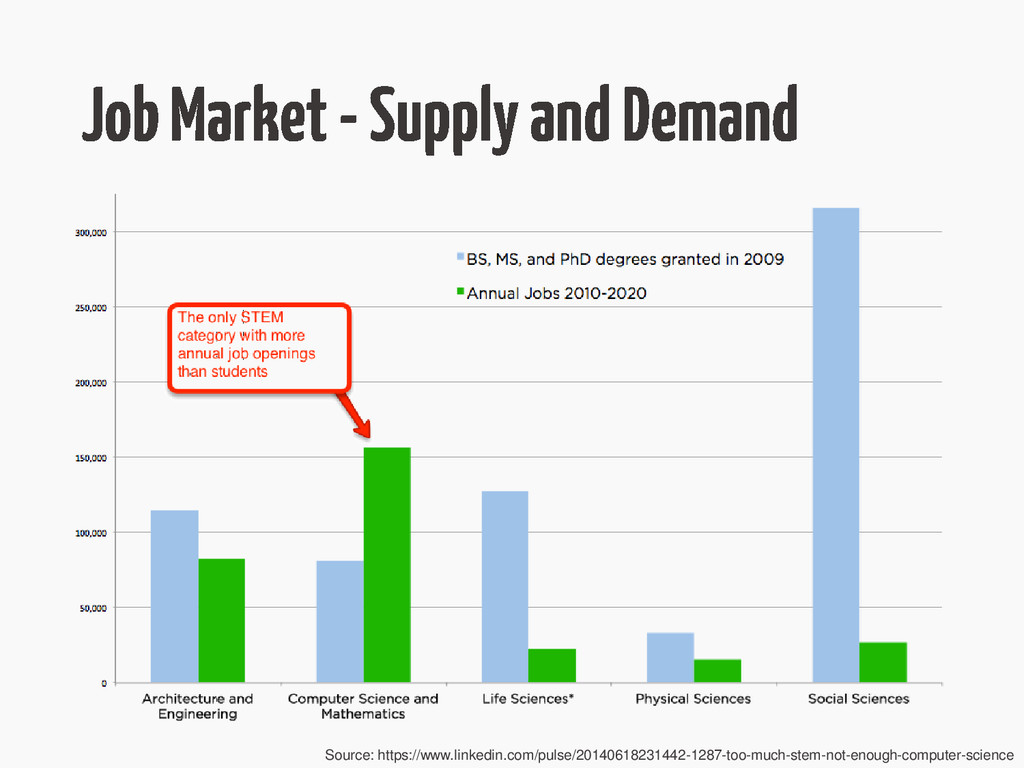{kind=link}
{kind=link}
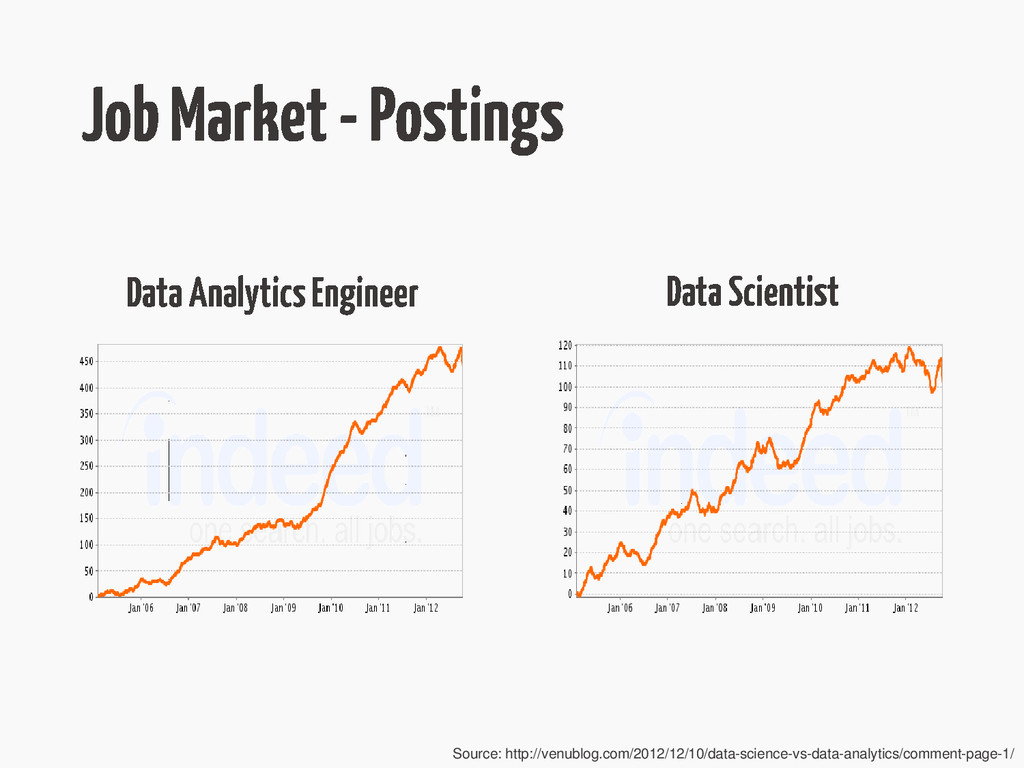{kind=link}
{kind=link}
![Slide deck available at http://goo.gl/C99kTO @MarekStoj [email protected] Homework ;) http://goo.gl/XrMiaG](https://files.speakerdeck.com/presentations/726d24bacb324190ae8727350a1f48d7/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}