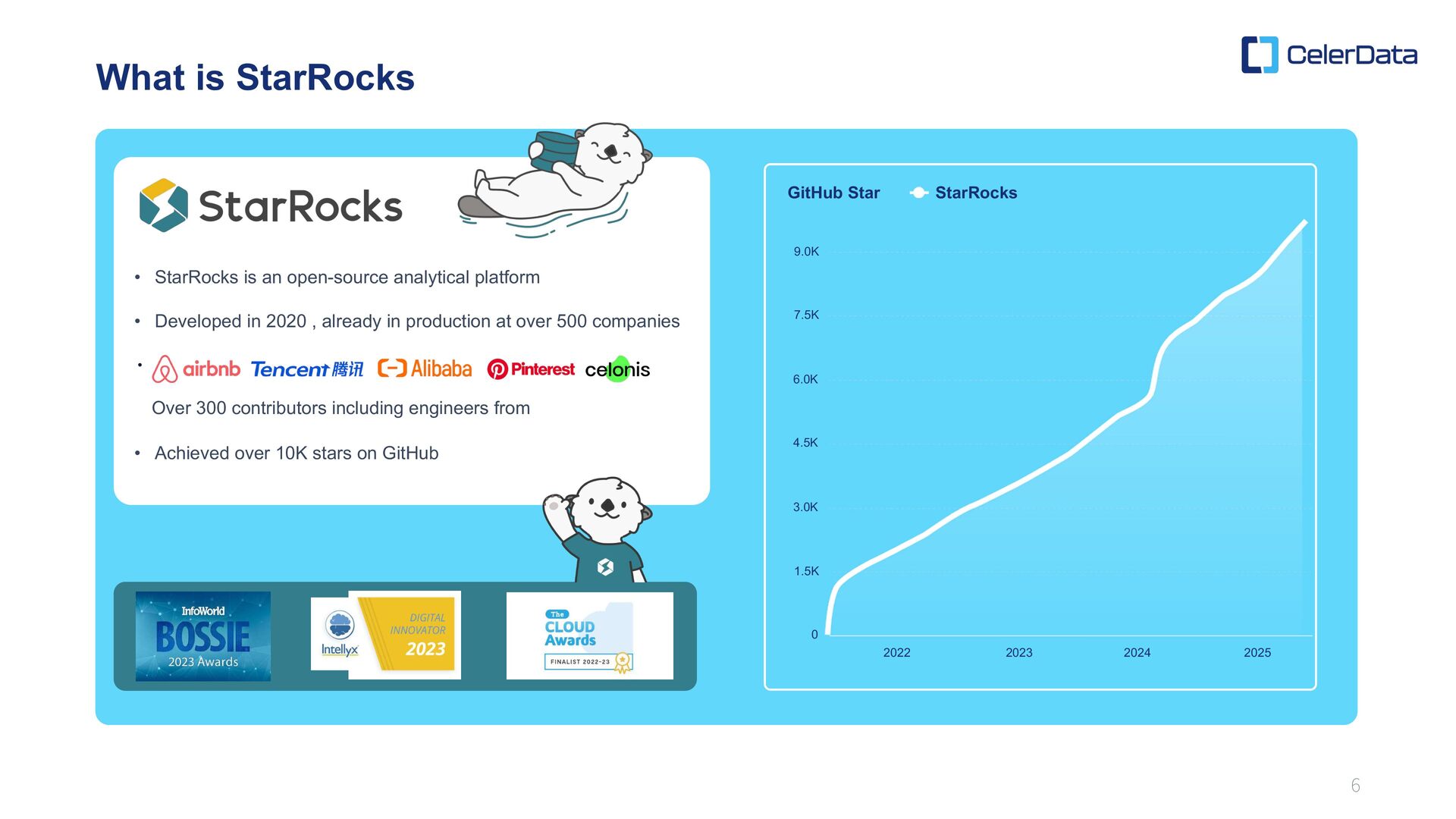
2022 2023 2025 2024 StarRocks What is StarRocks • StarRocks is an open-source analytical platform • Developed in 2020 , already in production at over 500 companies Over 300 contributors including engineers from • Achieved over 10K stars on GitHub
and GDPR certified • Security: SSO authentication, LDAP sync, row and column access Operations: Monitoring and alerts, cluster management GUI and API, query profiling • 24 hour 365 day SLA support Headquarters: Menlo Park, California Ecosystem Cloud Enter Enterprise Support Open Source OLAP • Founded in May 2020 • Donated to Linux Foundation in February 2023 • In production use at over 400 companies with market capitalization exceeding $10 billion
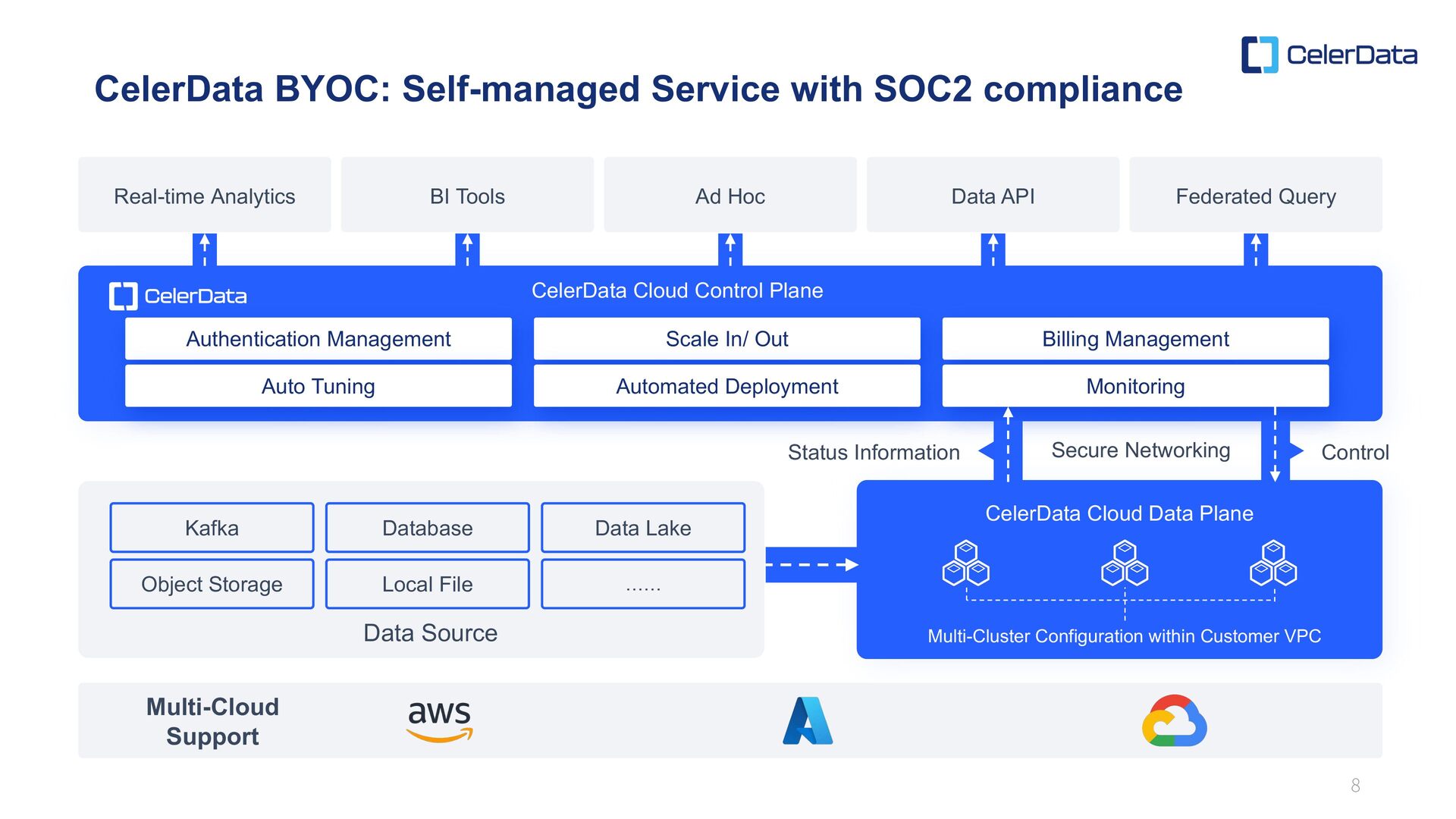
BI Tools Ad Hoc Data API Federated Query CelerData Cloud Control Plane Authentication Management Auto Tuning Scale In/ Out Automated Deployment Billing Management Monitoring Kafka Database Data Lake Object Storage Local File …… Data Source CelerData Cloud Data Plane Multi-Cluster Configuration within Customer VPC Multi-Cloud Support Status Information Control Secure Networking
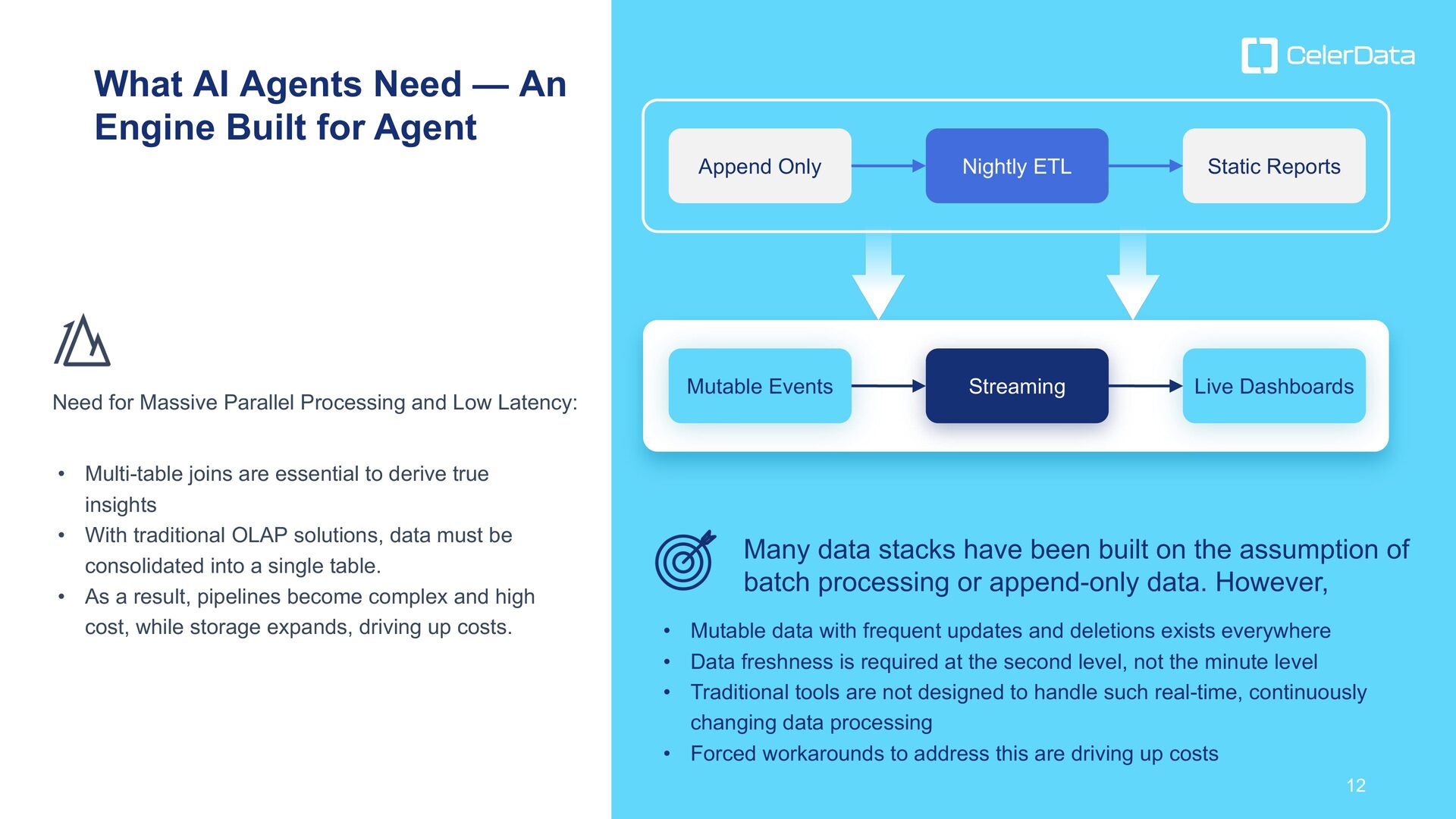
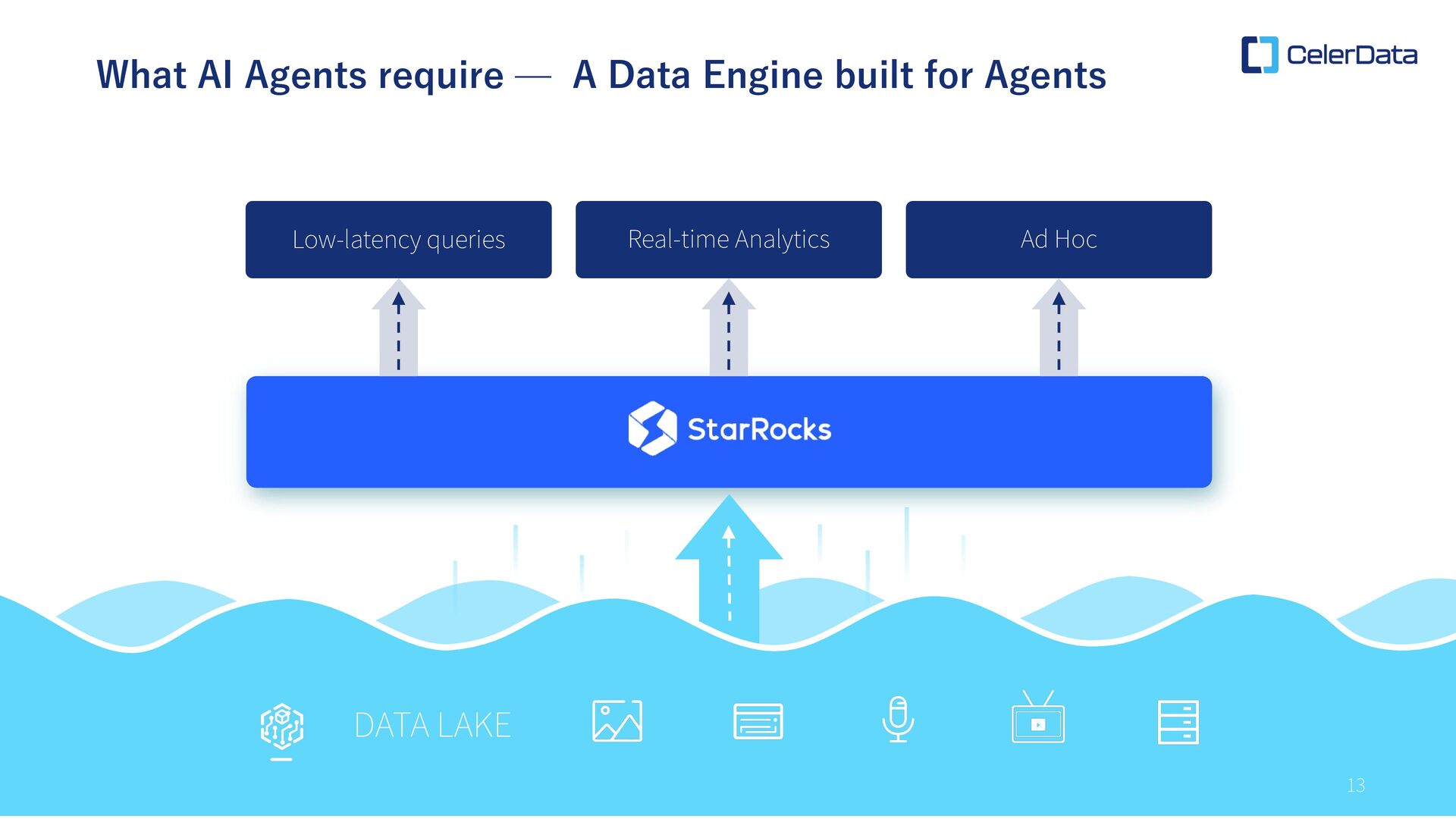
Agent Many data stacks have been built on the assumption of batch processing or append-only data. However, • Mutable data with frequent updates and deletions exists everywhere • Data freshness is required at the second level, not the minute level • Traditional tools are not designed to handle such real-time, continuously changing data processing • Forced workarounds to address this are driving up costs Need for Massive Parallel Processing and Low Latency: • Multi-table joins are essential to derive true insights • With traditional OLAP solutions, data must be consolidated into a single table. • As a result, pipelines become complex and high cost, while storage expands, driving up costs. Append Only Nightly ETL Static Reports Mutable Events Streaming Live Dashboards 12
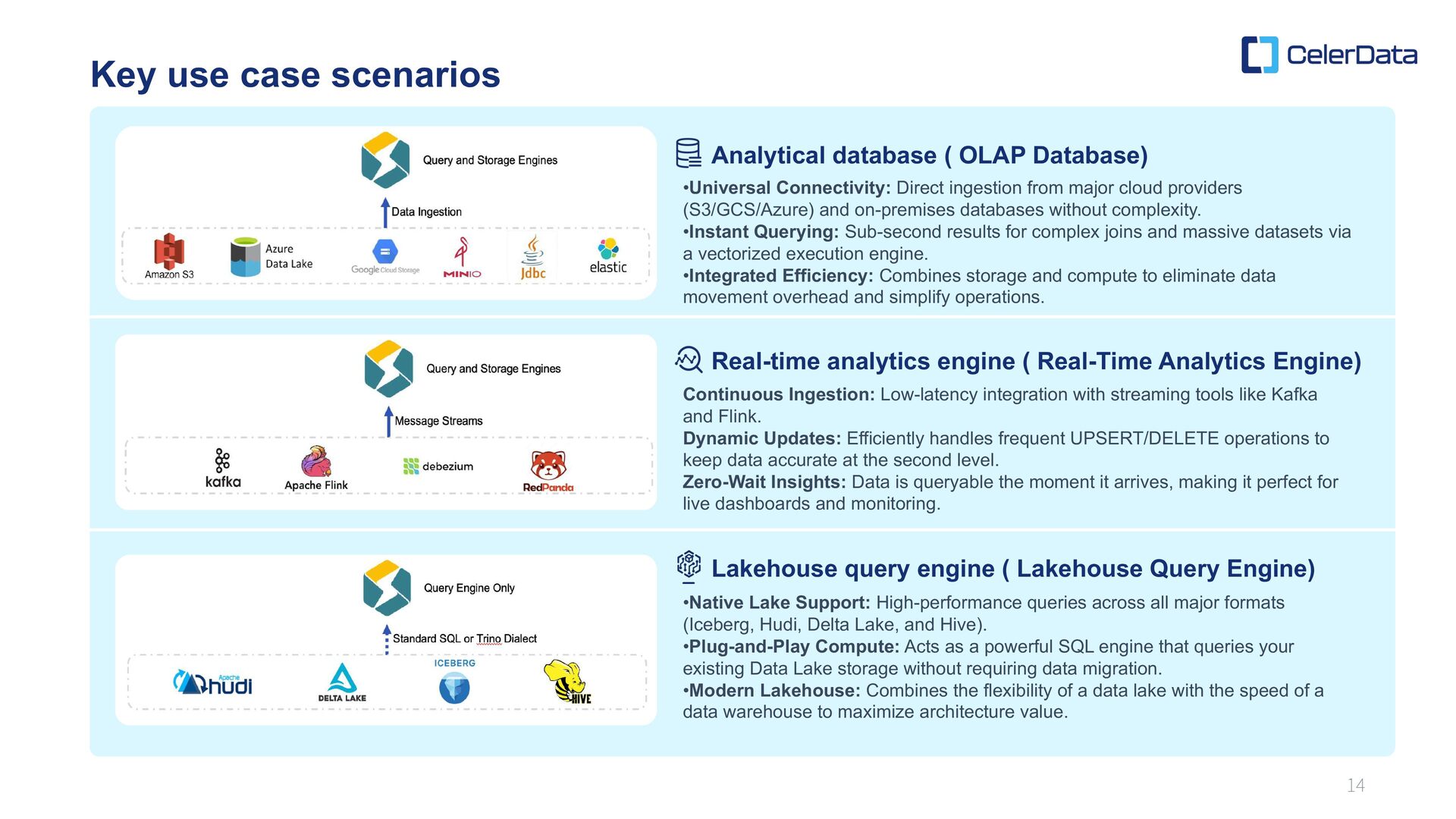
Real-time analytics engine ( Real-Time Analytics Engine) Lakehouse query engine ( Lakehouse Query Engine) Continuous Ingestion: Low-latency integration with streaming tools like Kafka and Flink. Dynamic Updates: Efficiently handles frequent UPSERT/DELETE operations to keep data accurate at the second level. Zero-Wait Insights: Data is queryable the moment it arrives, making it perfect for live dashboards and monitoring. •Native Lake Support: High-performance queries across all major formats (Iceberg, Hudi, Delta Lake, and Hive). •Plug-and-Play Compute: Acts as a powerful SQL engine that queries your existing Data Lake storage without requiring data migration. •Modern Lakehouse: Combines the flexibility of a data lake with the speed of a data warehouse to maximize architecture value. •Universal Connectivity: Direct ingestion from major cloud providers (S3/GCS/Azure) and on-premises databases without complexity. •Instant Querying: Sub-second results for complex joins and massive datasets via a vectorized execution engine. •Integrated Efficiency: Combines storage and compute to eliminate data movement overhead and simplify operations.
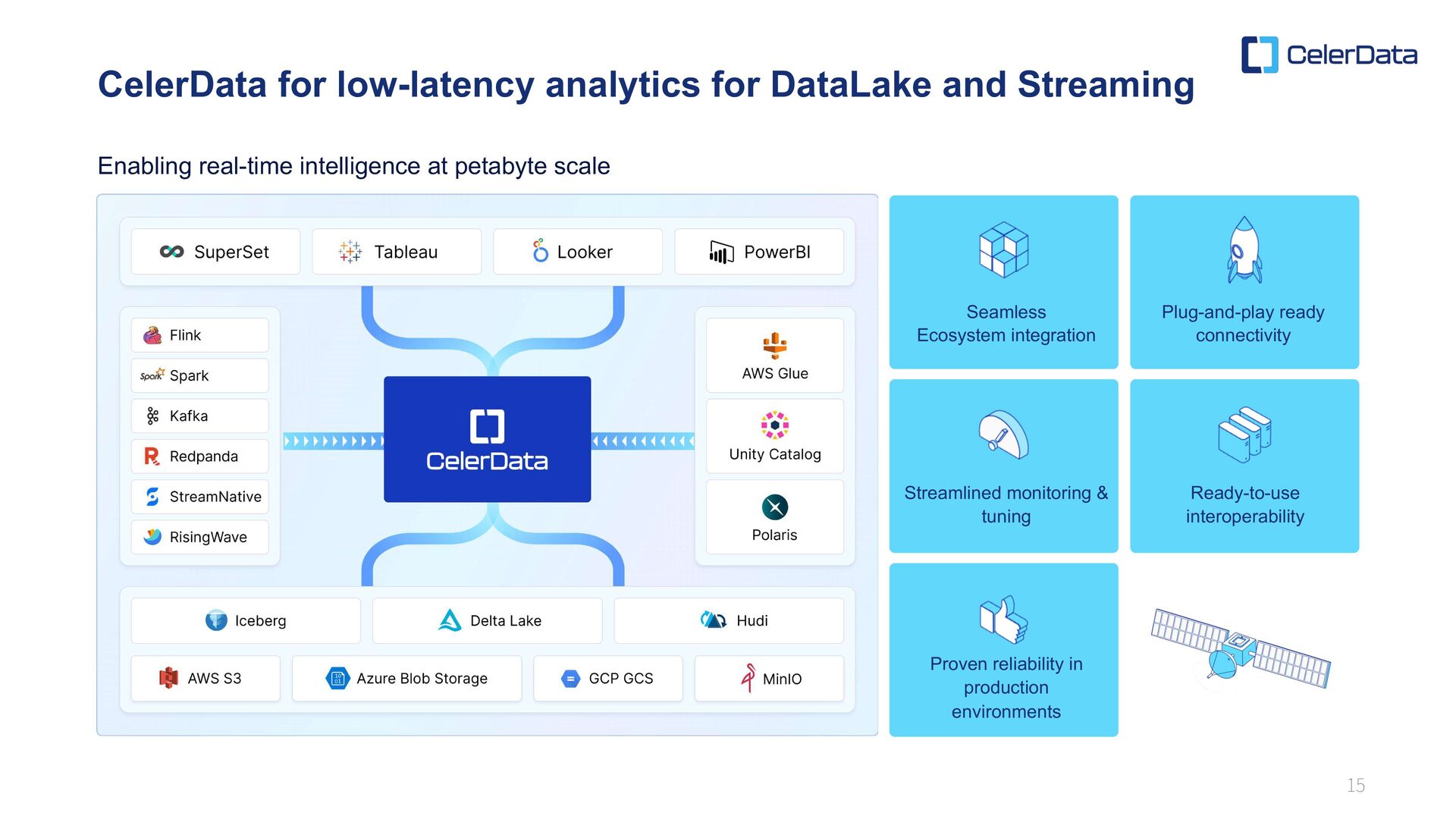
tuning Ready-to-use interoperability Proven reliability in production environments CelerData for low-latency analytics for DataLake and Streaming Enabling real-time intelligence at petabyte scale
Build a flexible and highly scalable Lakehouse infrastructure by utilizing Apache Iceberg as an open table format. • StarRocks provides high-speed, low-latency, and stable query performance for data residing on Iceberg. • Decouple storage and compute to simplify operations while integrally supporting batch, streaming, and BI. • ClickHouse (Real-time analytics for advertising): As concurrent execution increased, latency worsened; weak JOIN performance and poor scalability made maintenance and operations difficult. • Trino (Internal analytics): High costs and issues with stability. Value of Implementing StarRocks • High Load Resilience: Maintains stable low latency even under high loads of 800 QPS. • Data Model: Solved issues where massive wide tables and complex preprocessing pipelines were required in ClickHouse to avoid JOINs. • Performance vs. Trino: Achieved significantly higher speeds—3.6x faster for read performance and 1.8x faster for ETL performance compared to Trino. ≈ $ 2 B Advertise and IT
and acceleration of query results: Frequently used complex query results are pre-computed and stored, enabling immediate response to reference requests from Tableau. • Transparent query rewriting: Without modifying user (Tableau) side settings, queries are automatically routed to optimized views, significantly reducing wait time. • Balancing Data Freshness and Performance: Avoids the load of directly querying raw data in Delta Lake while efficiently caching and delivering the necessary data. • Data Fragmentation and Silos: Data is massive and distributed, and there is no unified platform to analyze all data sources in an integrated manner. • Tableau Cloud Performance Degradation: Query performance during visualization operations is low, with report display taking over 30 seconds or timeouts (calculation failure) occurring. • Lack of real-time data pipeline responsiveness: The synchronization pipeline to the DWH has become increasingly complex relative to the data update frequency on the Delta Lake side, resulting in inability to maintain the freshness of analytical data. • Dramatic improvement in composite analytics performance: Accelerates complex data analysis spanning Delta Lake, S3, and DWH. • Accelerated report display (enhanced UX): Achieves 5-6 seconds with Default Catalog and 8-10 seconds with direct reference (reduction to less than 1/3 of conventional time). • Simplifying Data Pipelines and Reducing TCO : Reduce complex ETL processing and simplify architecture. Minimize operational overhead and data infrastructure costs. • Improving Data Freshness ( Real-time ): Immediately reflect Data Lake updates in Visualization, providing an analysis environment with no time lag. ≈ $ 135 M Material View Online Game User Challenges The Solution Value of Implementing StarRocks
Migration to a Next-Generation Data Intelligence Platform: Consolidate data warehouse, data lake, and stream processing into a single platform to achieve a radical simplification of architecture. • Native and Powerful Support for Iceberg Clusters: Directly provide high-speed, scalable analytics and compute services for data on Iceberg. • High Costs of Snowflake: Annual costs reached several hundred million dollars. Operational costs grew faster than business growth, making radical improvement inevitable. • Computing Requirements for a World-Class Iceberg Cluster: Managing one of the world's largest Iceberg clusters required powerful data warehouse capabilities that balance high performance and high availability for company-wide business use. • Improved the overall query performance by 4x, dramatically accelerating analysis speed and decision-making for massive datasets. • Significant Cost Optimization: Successfully reduced data warehouse costs by 25%, data governance costs by 50% • Established a "Single Source of Truth," realizing a highly transparent and sustainable data utilization environment. Consumer Electronic ≈ $ 4 T User Challenges The Solution Value of Implementing StarRocks
Decouple multi-source Events as a unified real-time bus with horizontal scaling (target ≤ 100 K msg/s) • Autonomous subscription and workload isolation through partitions + consumer groups • Ensure consistency and traceability with at-least-once/exactly-once semantics + replay • Incremental processing and small Batch ingestion reduce Latency to data Visualization • Avoid heavy use of Stream Load with large numbers of REST calls; use more appropriate ingestion paths • Data distribution: multiple DWH ( Redshift/ Snowflake )+ S3 Data Lake. Joins across storage systems are difficult • Athena median Latency exceeds 30 seconds • Write amplification due to redundant copies/ data consistency challenges • Unable to meet real-time requirements: Fact↔Fact Join, PK update, Point Lookup, ultra-low latency • High DWH and data transfer costs ( Redshift/ Snowflake ) • High-speed OLAP: Efficient Join, AMV ( Aggregation Materialized Views), Query Rewrite • Glue Catalog integration. Can be used standalone as an analytical engine • Operate thousands of tables/views/ AMV, PB scale Iceberg data in a single cluster • Decommissioned Druid and achieved significant savings. Reduced Snowflake usage by 95%, total cost reduced by 90% • Dashboard creation reduced from hours/days to minutes. Achieved Real-time Analytics including Point Lookup/PK updates/Fact↔Fact Join • Aligns with the vision of data exploration, silo reduction, distributed governance, and autonomous data infrastructure ≈ $ 25 B The Solution Value of Implementing StarRocks
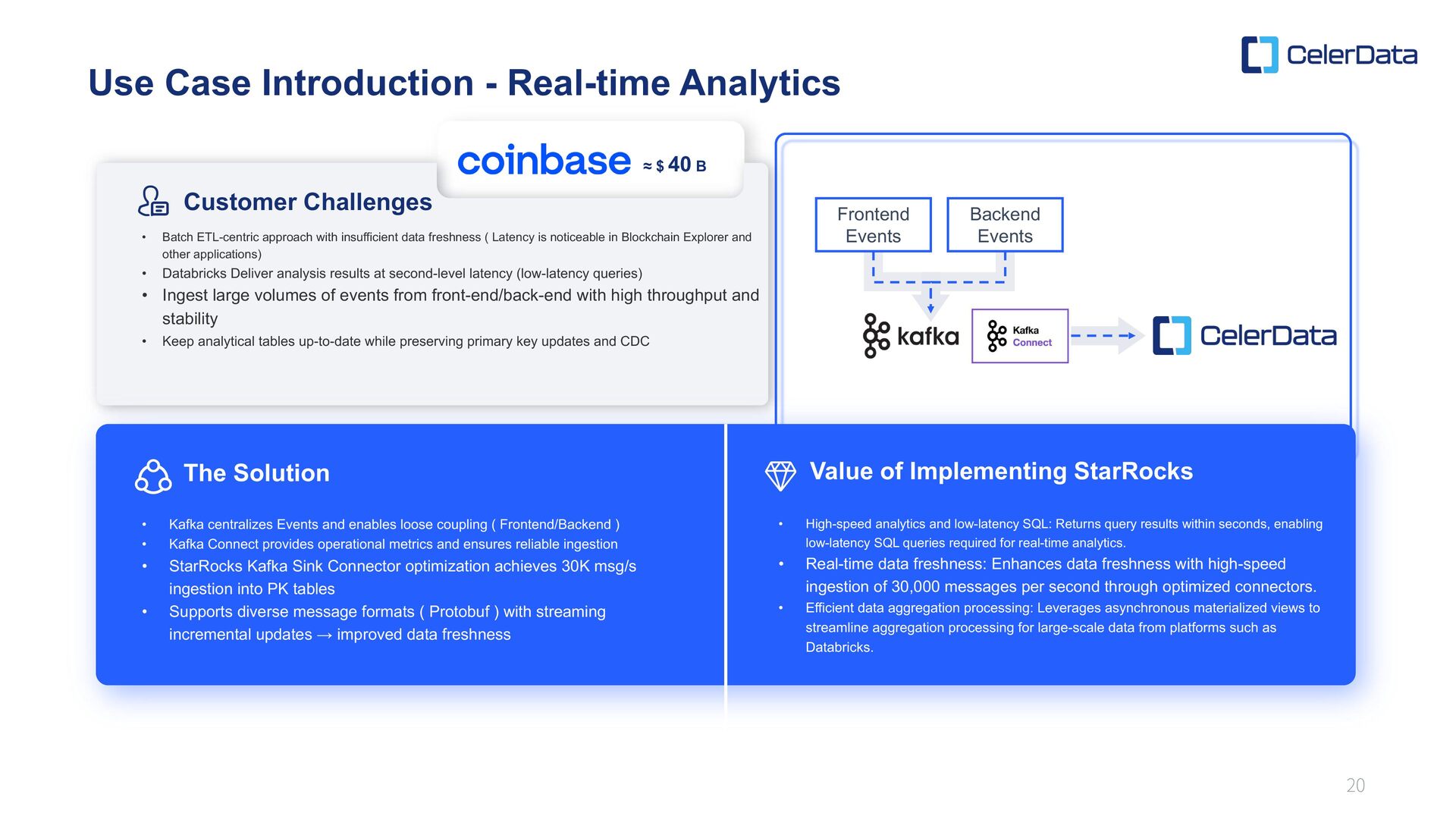
Kafka centralizes Events and enables loose coupling ( Frontend/Backend ) • Kafka Connect provides operational metrics and ensures reliable ingestion • StarRocks Kafka Sink Connector optimization achieves 30K msg/s ingestion into PK tables • Supports diverse message formats ( Protobuf ) with streaming incremental updates → improved data freshness • Batch ETL-centric approach with insufficient data freshness ( Latency is noticeable in Blockchain Explorer and other applications) • Databricks Deliver analysis results at second-level latency (low-latency queries) • Ingest large volumes of events from front-end/back-end with high throughput and stability • Keep analytical tables up-to-date while preserving primary key updates and CDC • High-speed analytics and low-latency SQL: Returns query results within seconds, enabling low-latency SQL queries required for real-time analytics. • Real-time data freshness: Enhances data freshness with high-speed ingestion of 30,000 messages per second through optimized connectors. • Efficient data aggregation processing: Leverages asynchronous materialized views to streamline aggregation processing for large-scale data from platforms such as Databricks. Frontend Events Backend Events ≈ $ 40 B The Solution Value of Implementing StarRocks
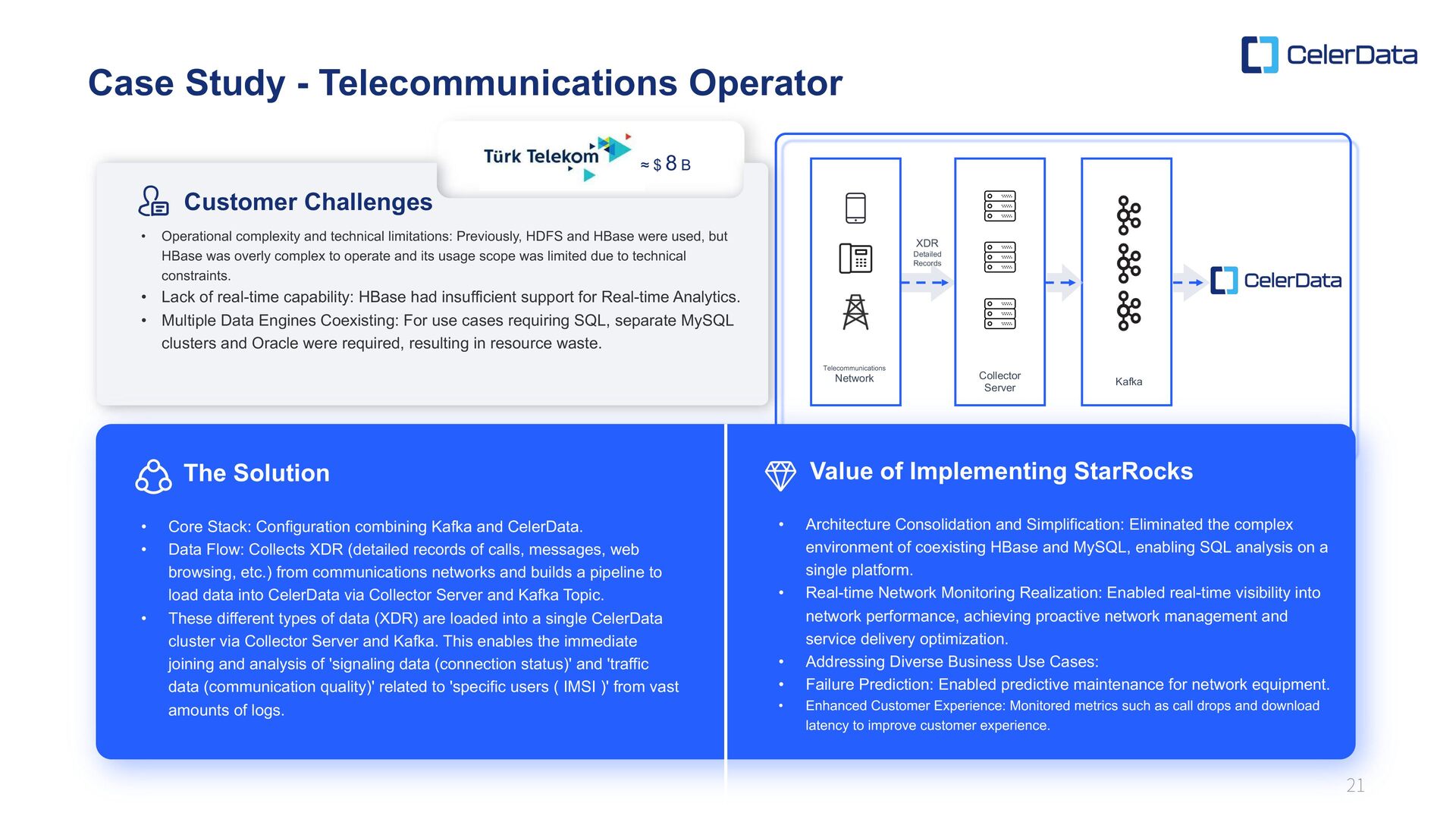
Stack: Configuration combining Kafka and CelerData. • Data Flow: Collects XDR (detailed records of calls, messages, web browsing, etc.) from communications networks and builds a pipeline to load data into CelerData via Collector Server and Kafka Topic. • These different types of data (XDR) are loaded into a single CelerData cluster via Collector Server and Kafka. This enables the immediate joining and analysis of 'signaling data (connection status)' and 'traffic data (communication quality)' related to 'specific users ( IMSI )' from vast amounts of logs. • Operational complexity and technical limitations: Previously, HDFS and HBase were used, but HBase was overly complex to operate and its usage scope was limited due to technical constraints. • Lack of real-time capability: HBase had insufficient support for Real-time Analytics. • Multiple Data Engines Coexisting: For use cases requiring SQL, separate MySQL clusters and Oracle were required, resulting in resource waste. • Architecture Consolidation and Simplification: Eliminated the complex environment of coexisting HBase and MySQL, enabling SQL analysis on a single platform. • Real-time Network Monitoring Realization: Enabled real-time visibility into network performance, achieving proactive network management and service delivery optimization. • Addressing Diverse Business Use Cases: • Failure Prediction: Enabled predictive maintenance for network equipment. • Enhanced Customer Experience: Monitored metrics such as call drops and download latency to improve customer experience. ≈ $ 8 B Telecommunications Network Collector Server Kafka XDR Detailed Records The Solution Value of Implementing StarRocks
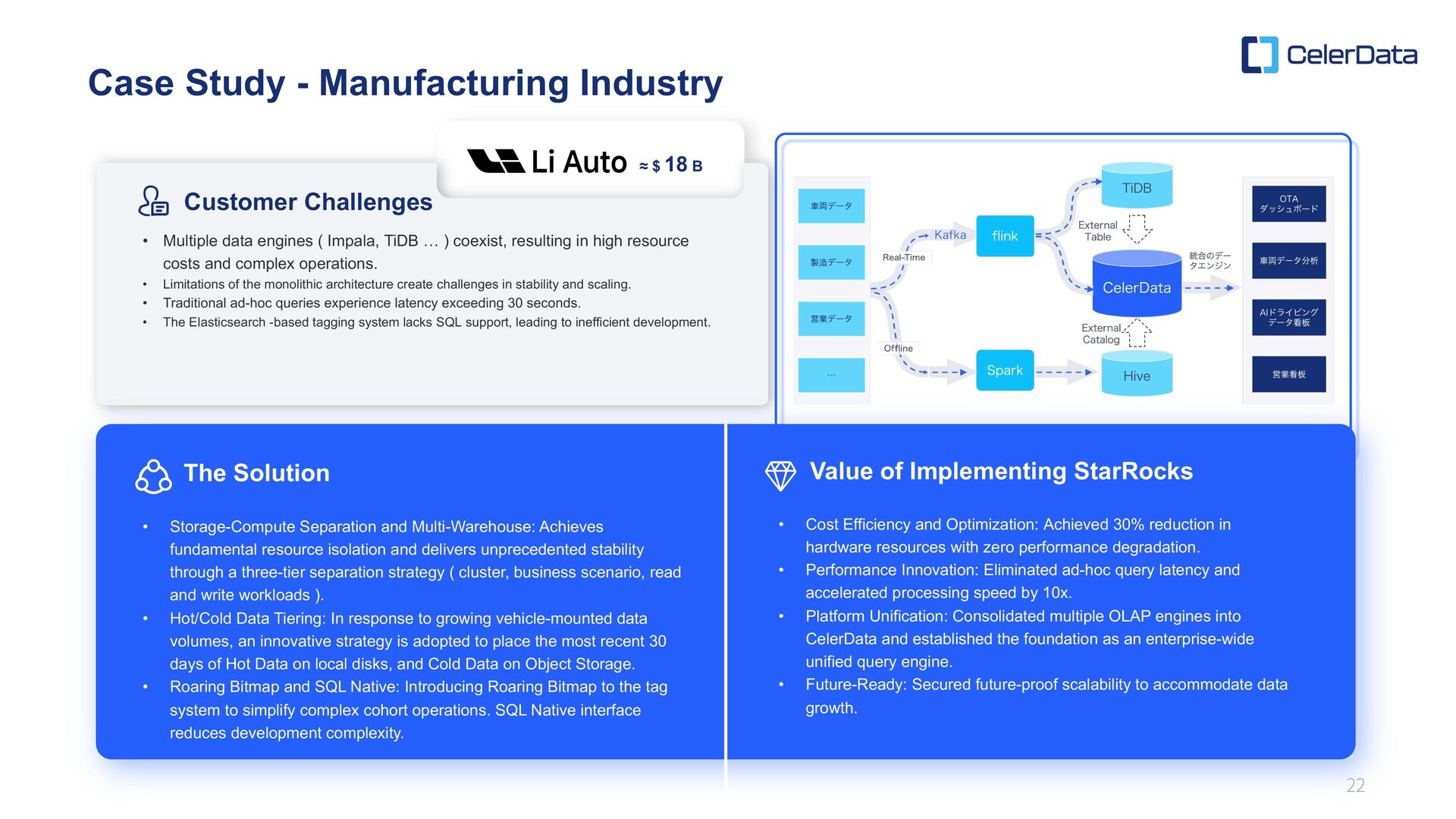
Separation and Multi-Warehouse: Achieves fundamental resource isolation and delivers unprecedented stability through a three-tier separation strategy ( cluster, business scenario, read and write workloads ). • Hot/Cold Data Tiering: In response to growing vehicle-mounted data volumes, an innovative strategy is adopted to place the most recent 30 days of Hot Data on local disks, and Cold Data on Object Storage. • Roaring Bitmap and SQL Native: Introducing Roaring Bitmap to the tag system to simplify complex cohort operations. SQL Native interface reduces development complexity. • Multiple data engines ( Impala, TiDB … ) coexist, resulting in high resource costs and complex operations. • Limitations of the monolithic architecture create challenges in stability and scaling. • Traditional ad-hoc queries experience latency exceeding 30 seconds. • The Elasticsearch -based tagging system lacks SQL support, leading to inefficient development. • Cost Efficiency and Optimization: Achieved 30% reduction in hardware resources with zero performance degradation. • Performance Innovation: Eliminated ad-hoc query latency and accelerated processing speed by 10x. • Platform Unification: Consolidated multiple OLAP engines into CelerData and established the foundation as an enterprise-wide unified query engine. • Future-Ready: Secured future-proof scalability to accommodate data growth. ≈ $ 18 B The Solution Value of Implementing StarRocks
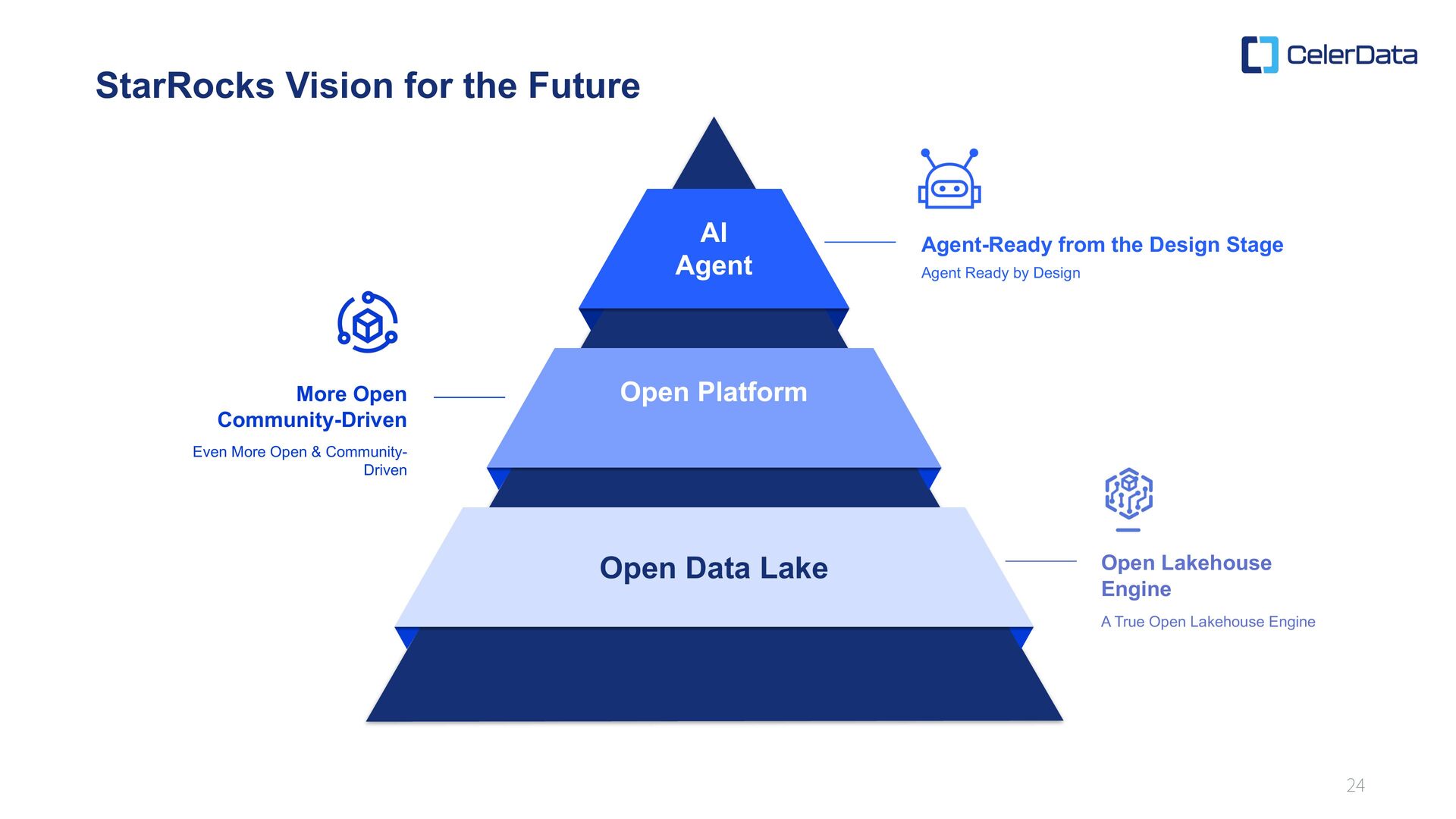
Lakehouse Engine AI Agent Agent-Ready from the Design Stage Open Platform Open Data Lake Even More Open & Community- Driven Agent Ready by Design A True Open Lakehouse Engine
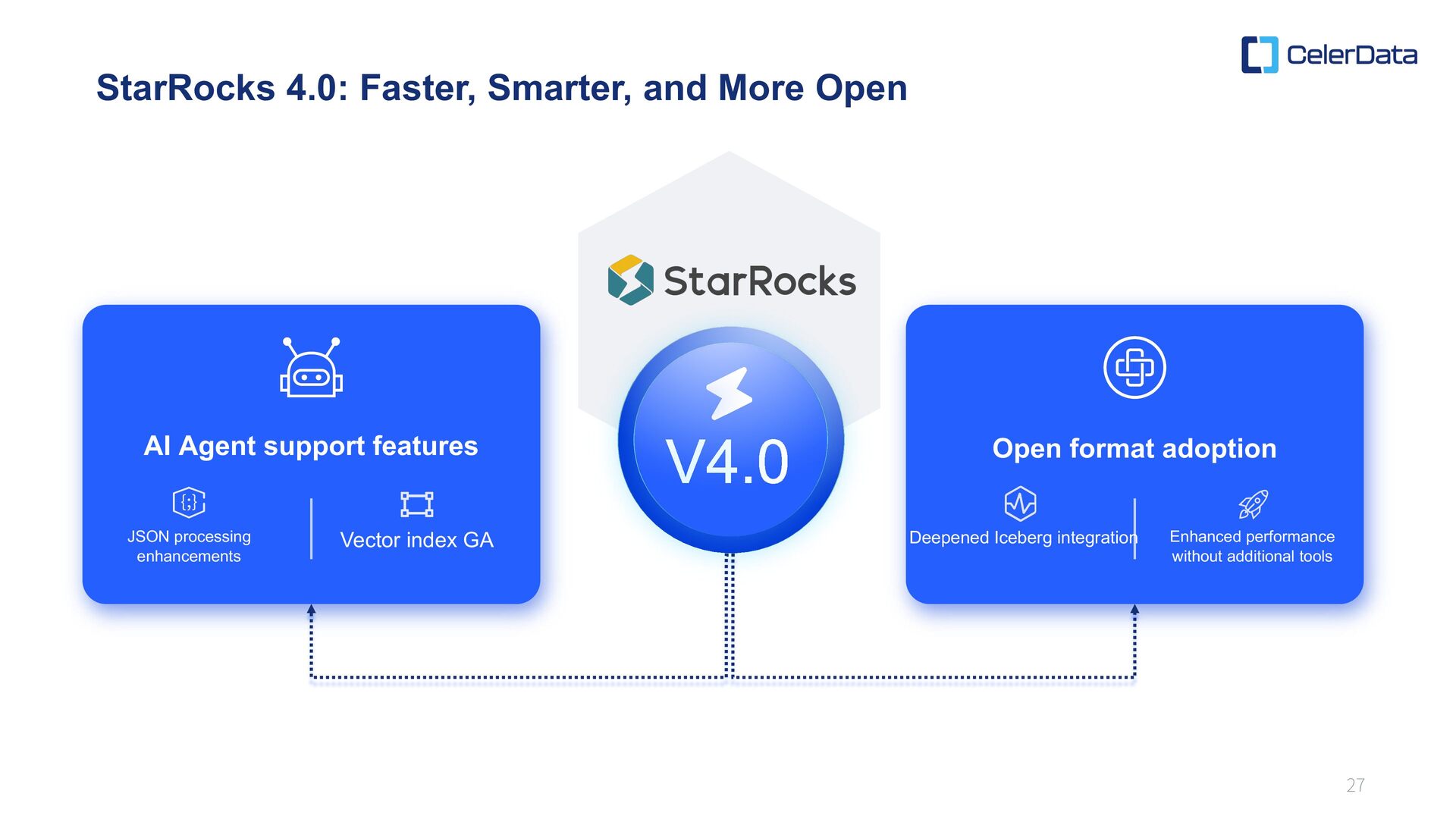
support features Open format adoption JSON processing enhancements Deepened Iceberg integration Vector index GA Enhanced performance without additional tools
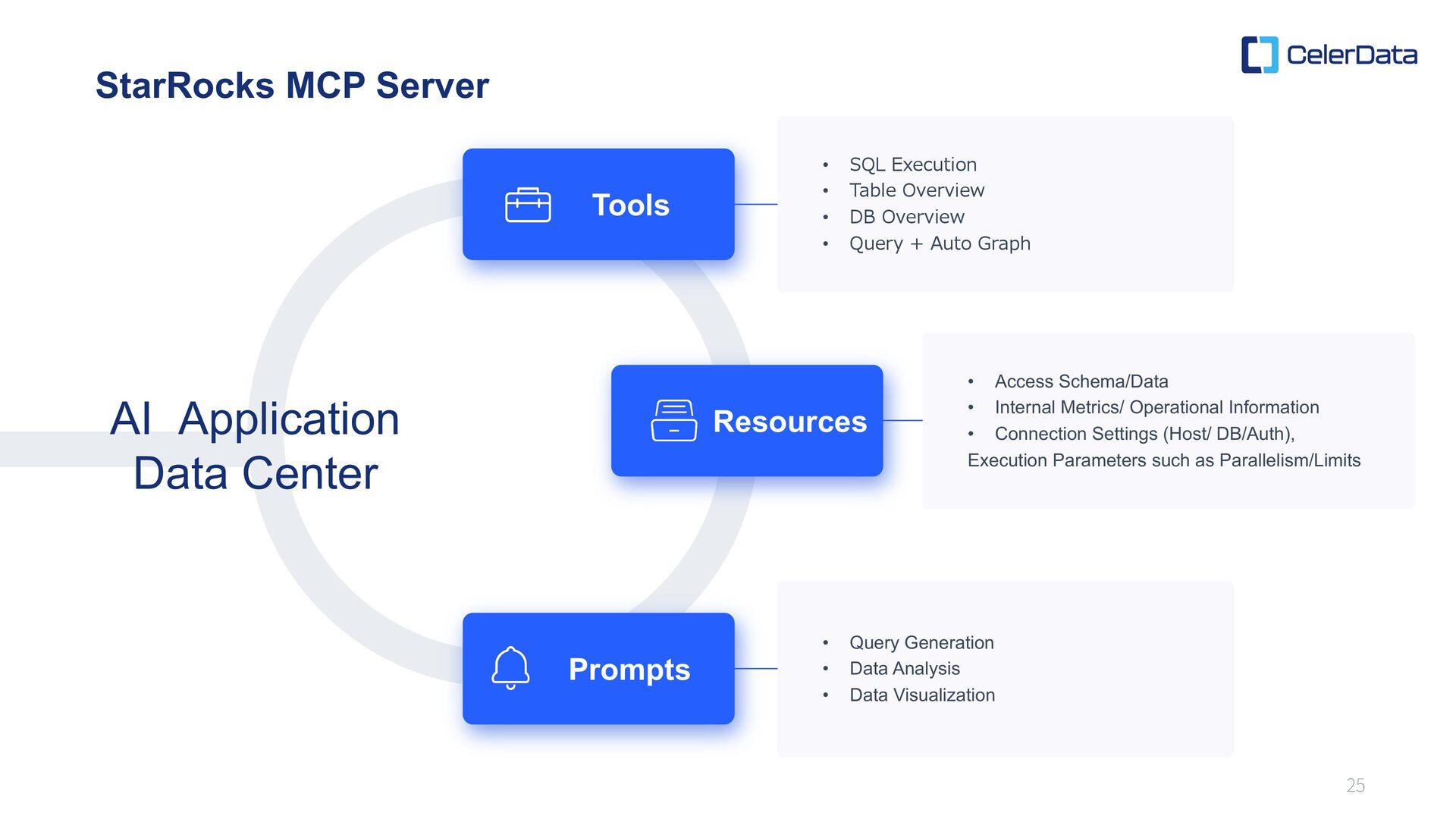
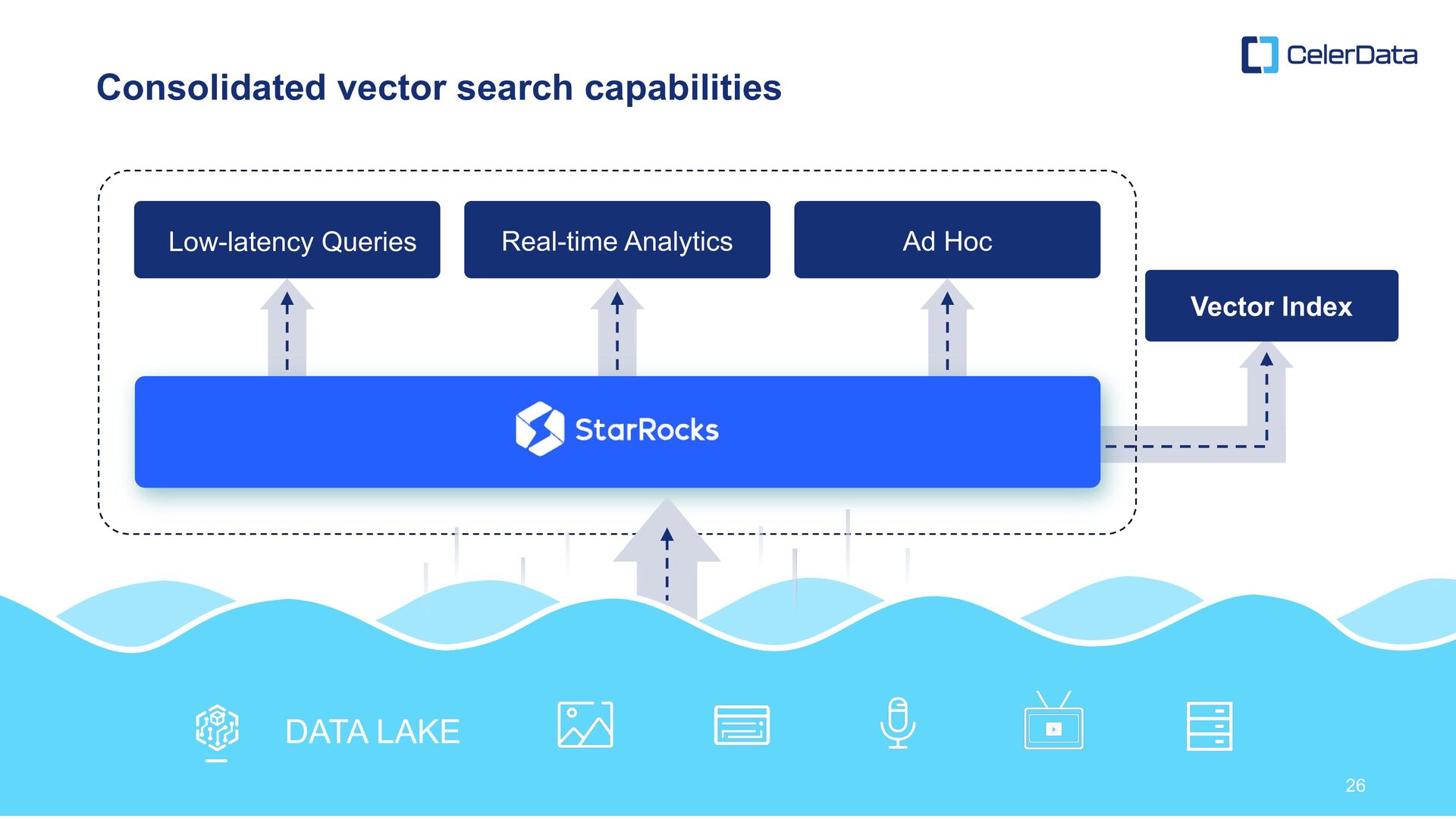
expected in the era amplified … High-performance query engine Real-Time and High- Concurrency Analytics Vector Search + Unified Analytics Platform AI Capabilities StarRocks MCP Server
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}