made up of around 20,500 human genes, high resolution maps of Chromosomes including billions of base pairs of DNA-sequence information. Laboratory information & Database management systems and Graphical User Interfaces were the computing tools required to help researchers decipher this pool of data. These computing challenges were overcome by this latest field of research ,Bioinformatics. Researchers have developed Public Databases connected to the internet to make genome data available worldwide along with analytical software to facilitate research on this data. Scientists now have a more detailed blueprint of the Human Genetic code.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
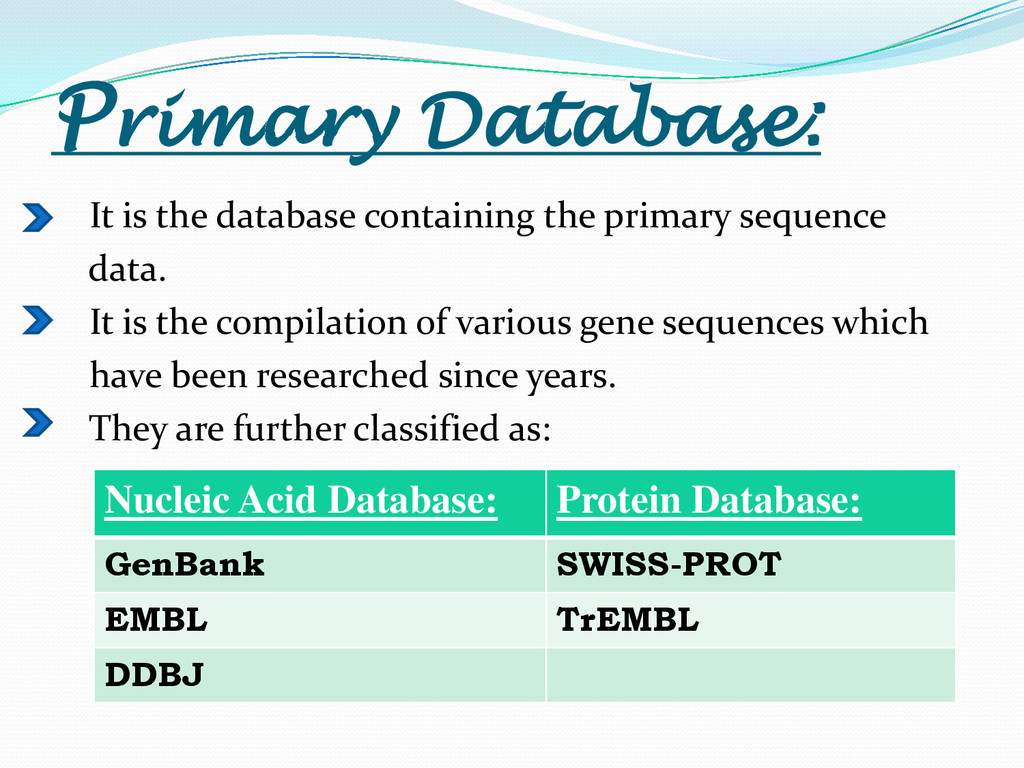{kind=link}
{kind=link}
{kind=link}
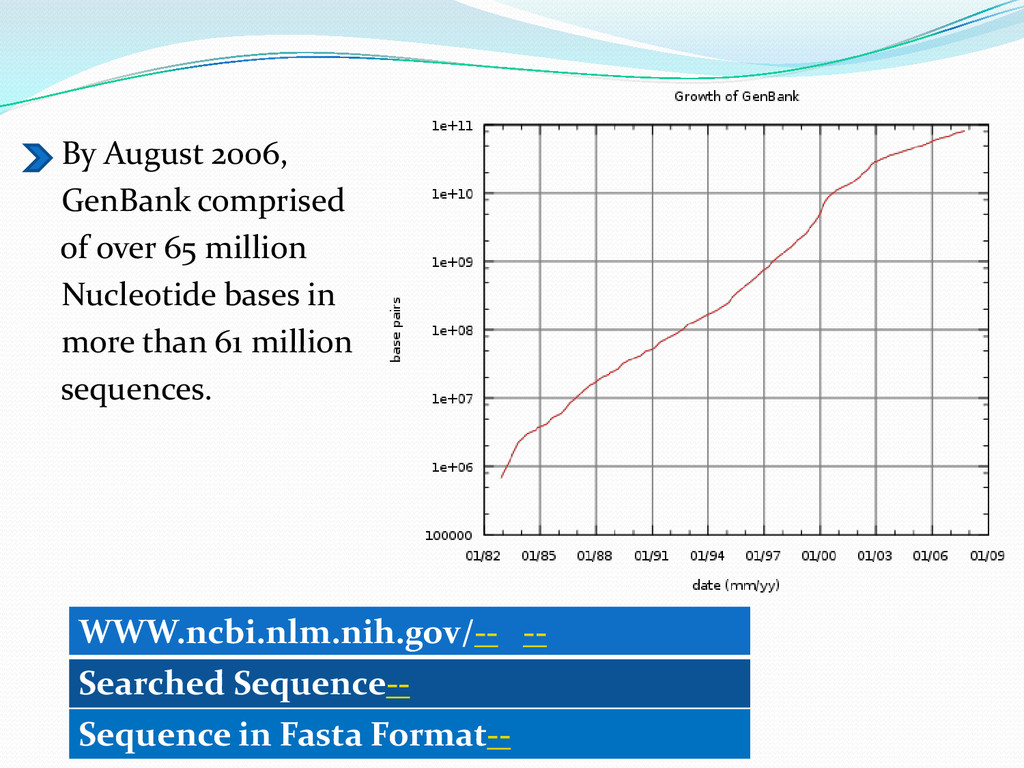{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
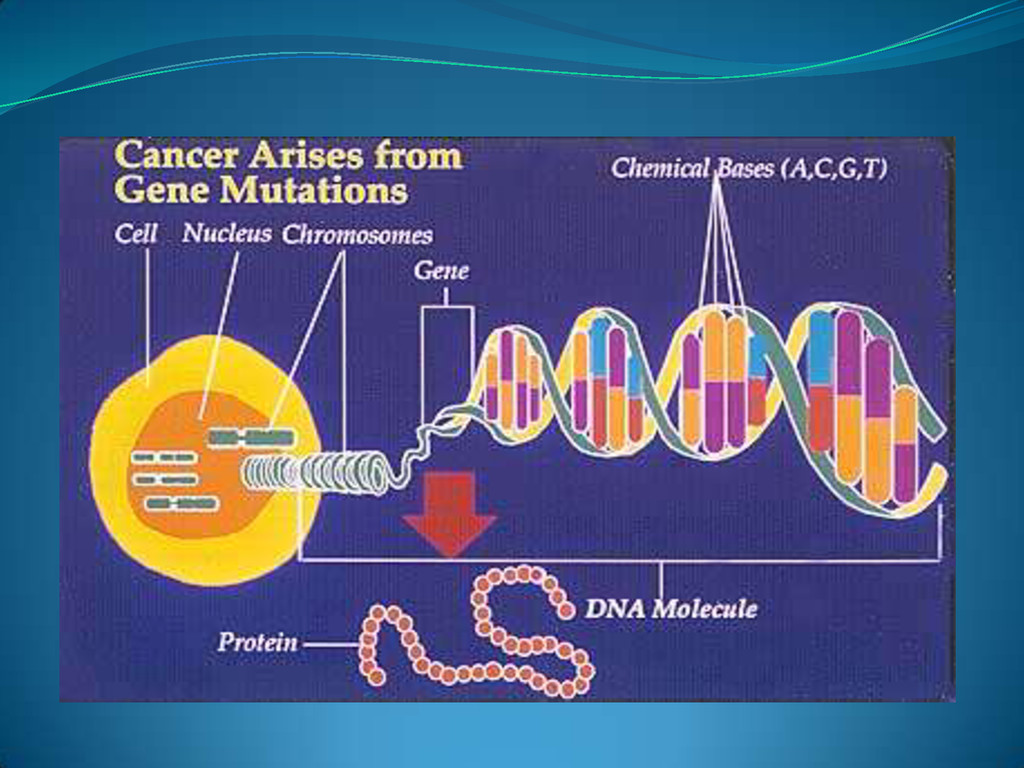{kind=link}
{kind=link}
{kind=link}
{kind=link}
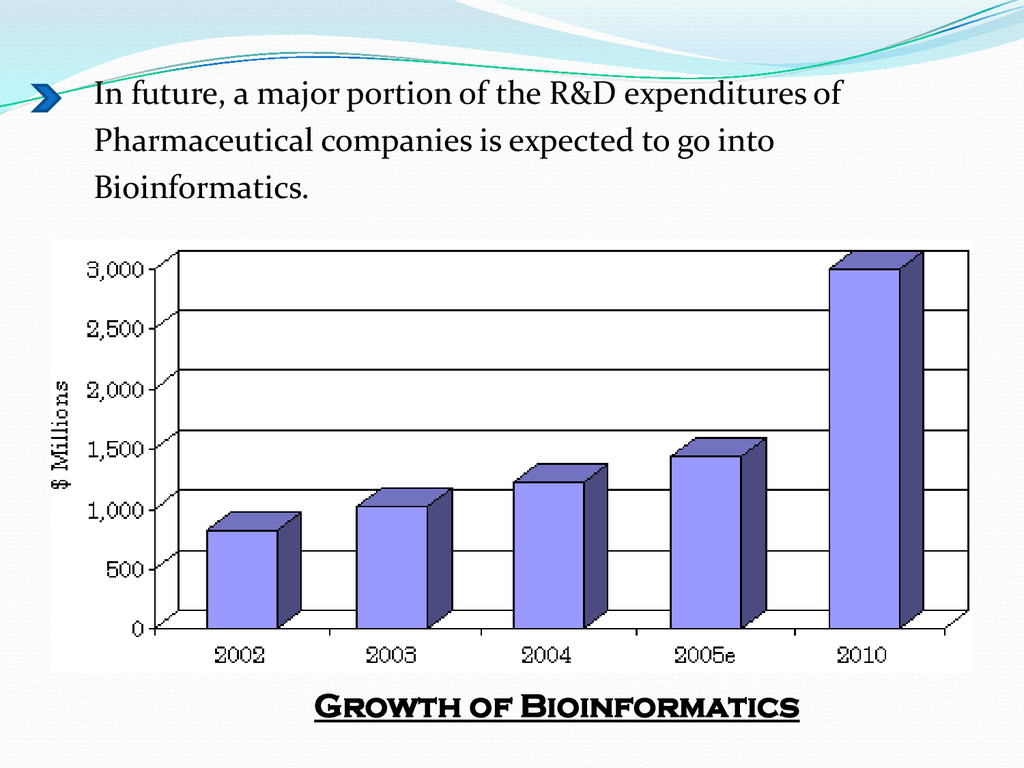{kind=link}
{kind=link}
{kind=link}
{kind=link}