In this course we will go over the essentials for understanding experimentation at Mercari, and how to instrument and configure basic experiments and feature flags. We will also briefly review how this affects our development practices.
V2 API Preview • Experimentation Issues Feature Flags • Why use feature flags? • Common code-merging issues and how we can solve them. • Testing In Production Hands-On Session
experiments so that you can readily contribute back to your teams. Provide ideas and designs for implementing and executing experiments in the product code base. Feature Flags Increase development efficiency with faster and continuous integration practices.
discovered through this experiment that the objects fell with the same acceleration, proving his prediction true, while at the same time disproving Aristotle's theory of gravity (which states that objects fall at speed proportional to their mass).” Original image source: Theresa knott at English Wikibooks., Pisa experiment, modified with vector arrows, CC BY-SA 3.0
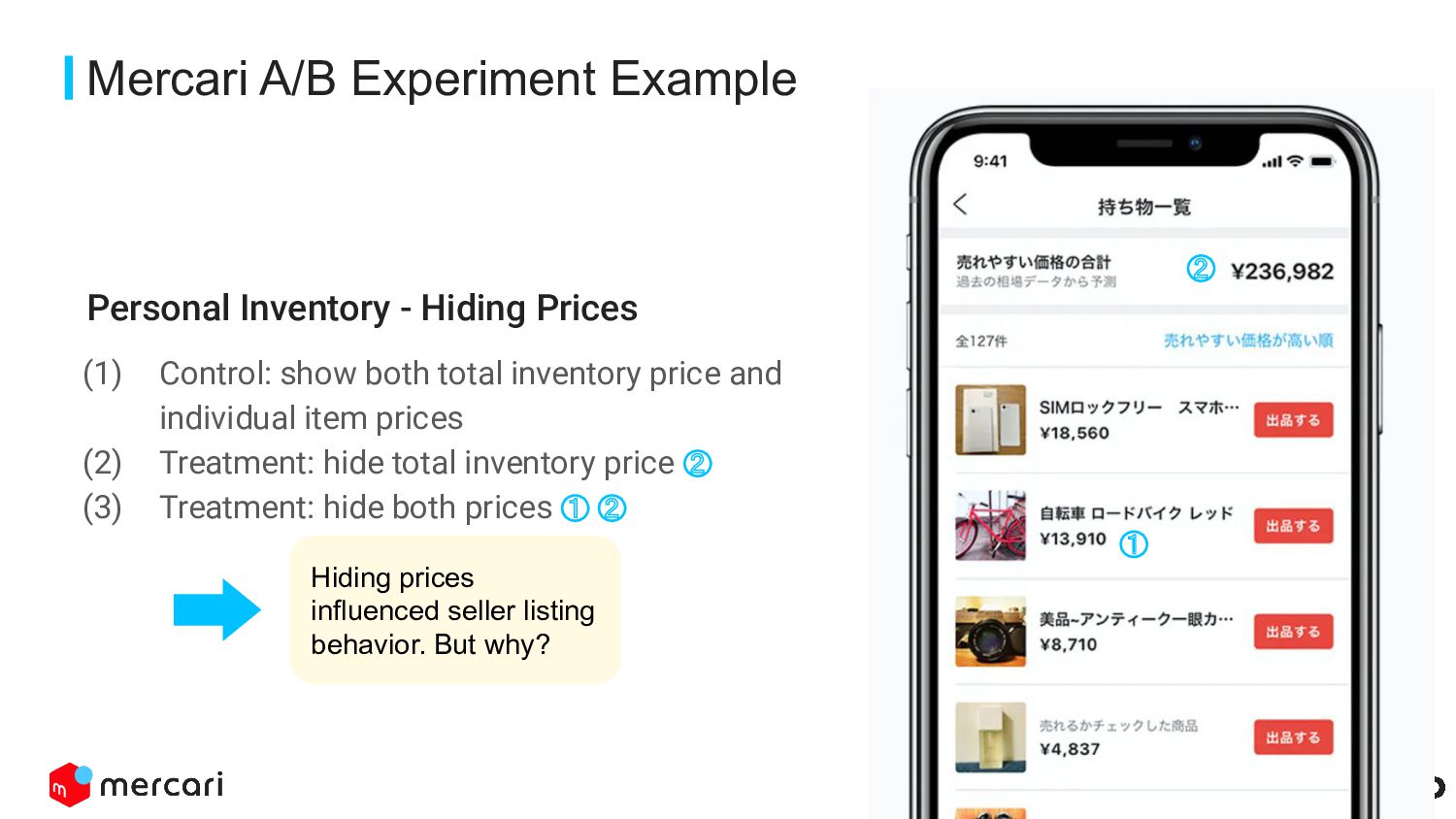
Control: show both total inventory price and individual item prices (2) Treatment: hide total inventory price ② (3) Treatment: hide both prices ① ② ① ② Hiding prices influenced seller listing behavior. But why?
“A way to increase GMV and therefore Mercari’s stock price.” 2: “An empirical method of acquiring knowledge.” 3: “Establish a data-driven culture that informs rather than relies on the HiPPO (Highest Paid Person’s Opinion)” 4: “Compare variations of the same web page to determine which will generate the best outcomes.” Why Run Experiments? GMV = Gross Merchandising Value
sources) 1: “A way to increase GMV and therefore Mercari’s stock price.” Your DevDojo presenter: @rhomel 2: “An empirical method of acquiring knowledge.” Wikipedia’s description of “Scientific Method” https://en.wikipedia.org/wiki/Scientific_method 3: “Establish a data-driven culture that informs rather than relies on the HiPPO (Highest Paid Person’s Opinion)” Published Book: “Trustworthy Online Controlled Experiments” Ron Kohavi (Amazon, Microsoft), Diane Tang (Google), Ya Xu (LinkedIn) 4: “Compare variations of the same web page to determine which will generate the best outcomes.” Nielsen Norman User Research Group on AB testing https://www.nngroup.com/articles/ab-testing-and-ux-research/ Why Run Experiments?
“A way to increase GMV and therefore Mercari’s stock price.” This is the end result that we hope to achieve for our company. 2: “An empirical method of acquiring knowledge.” This is the purpose of experimentation. It is the best answer because it creates an environment where the other answers become potential outcomes. 3: “Establish a data-driven culture that informs rather than relies on the HiPPO (Highest Paid Person’s Opinion)” This is one of the effects of understanding the importance of experimentation. 4: “Compare variations of the same web page to determine which will generate the best outcomes.” This is a tendency of how we conduct our experiments. Why Run Experiments?
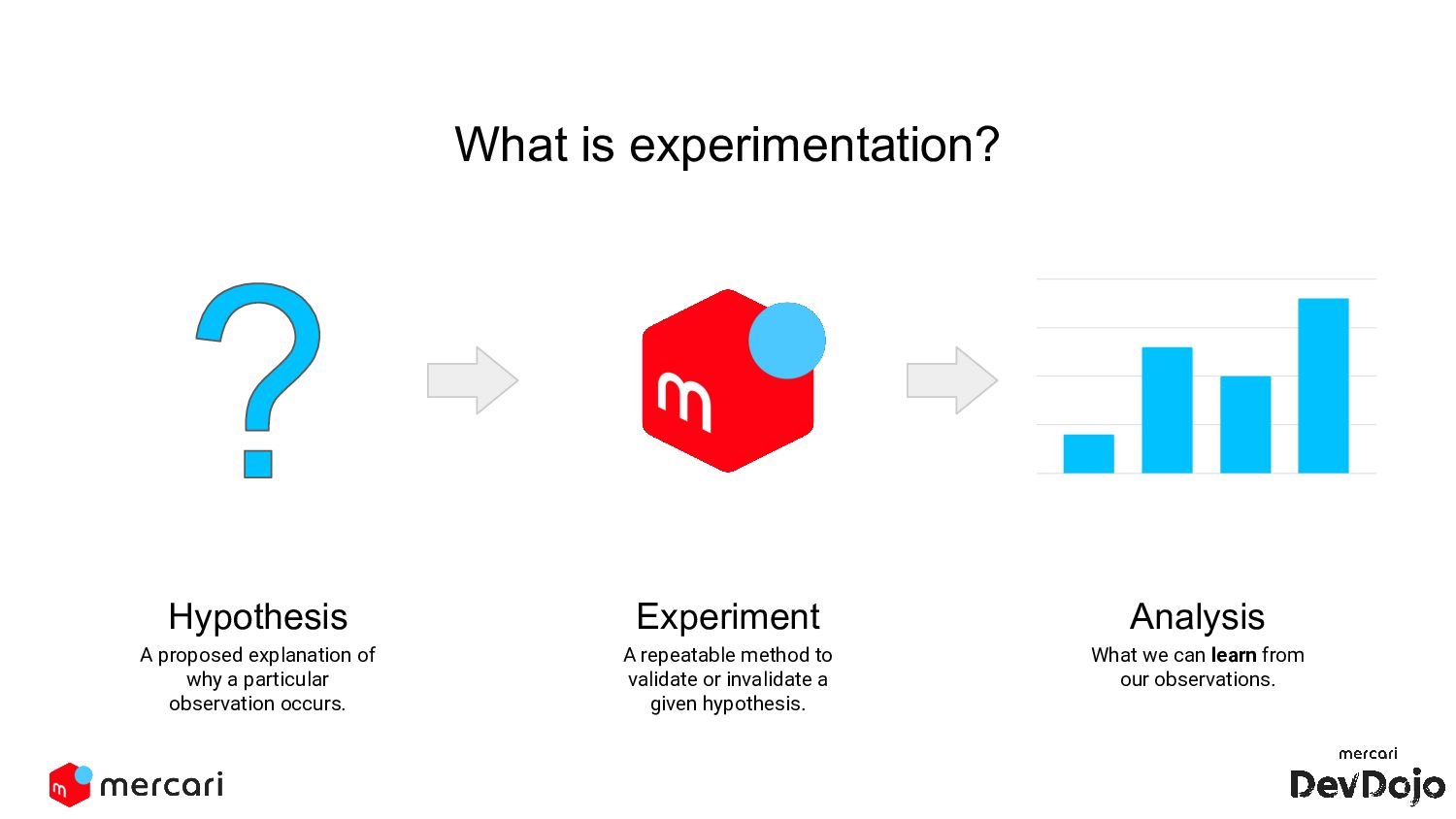
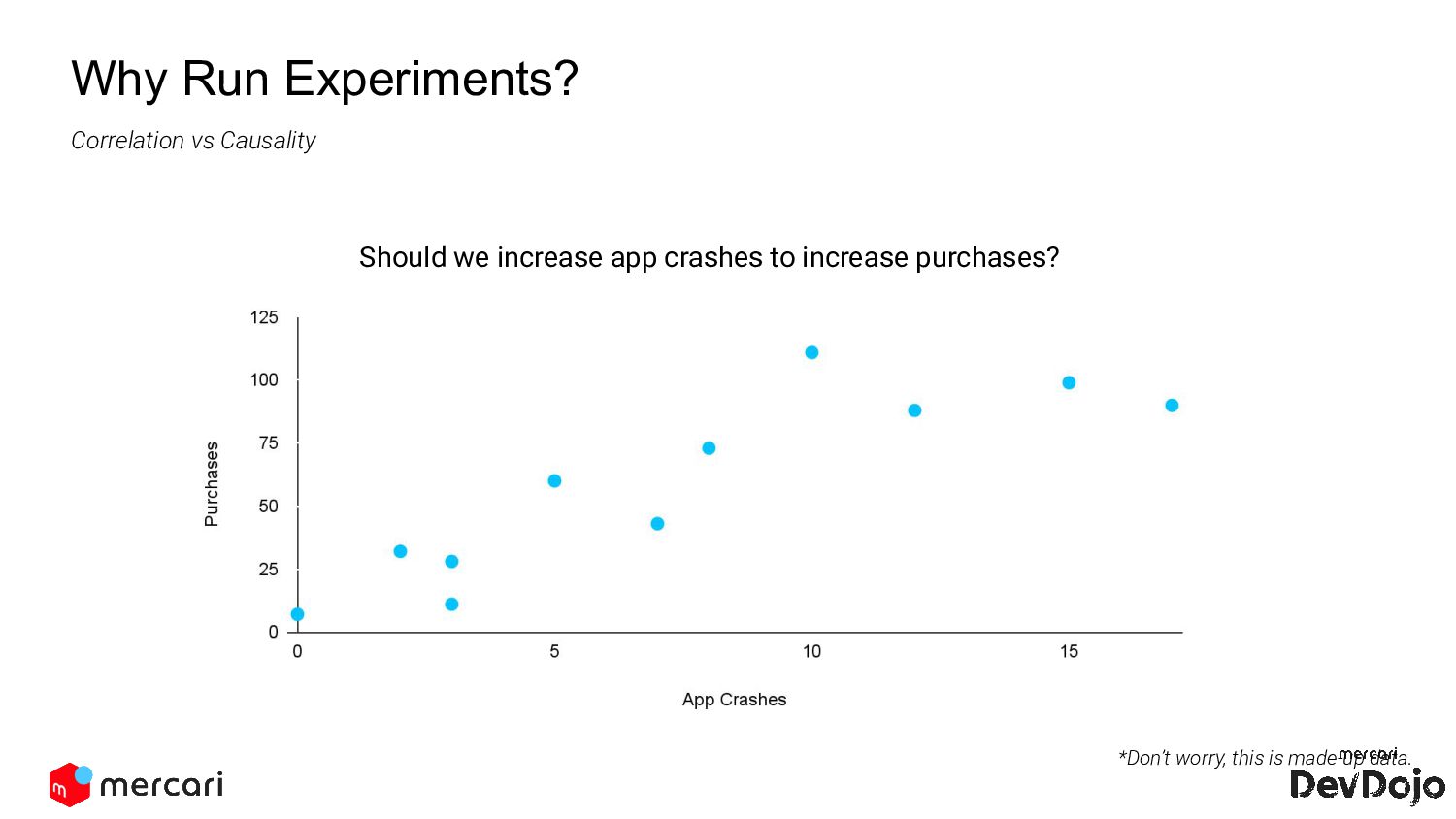
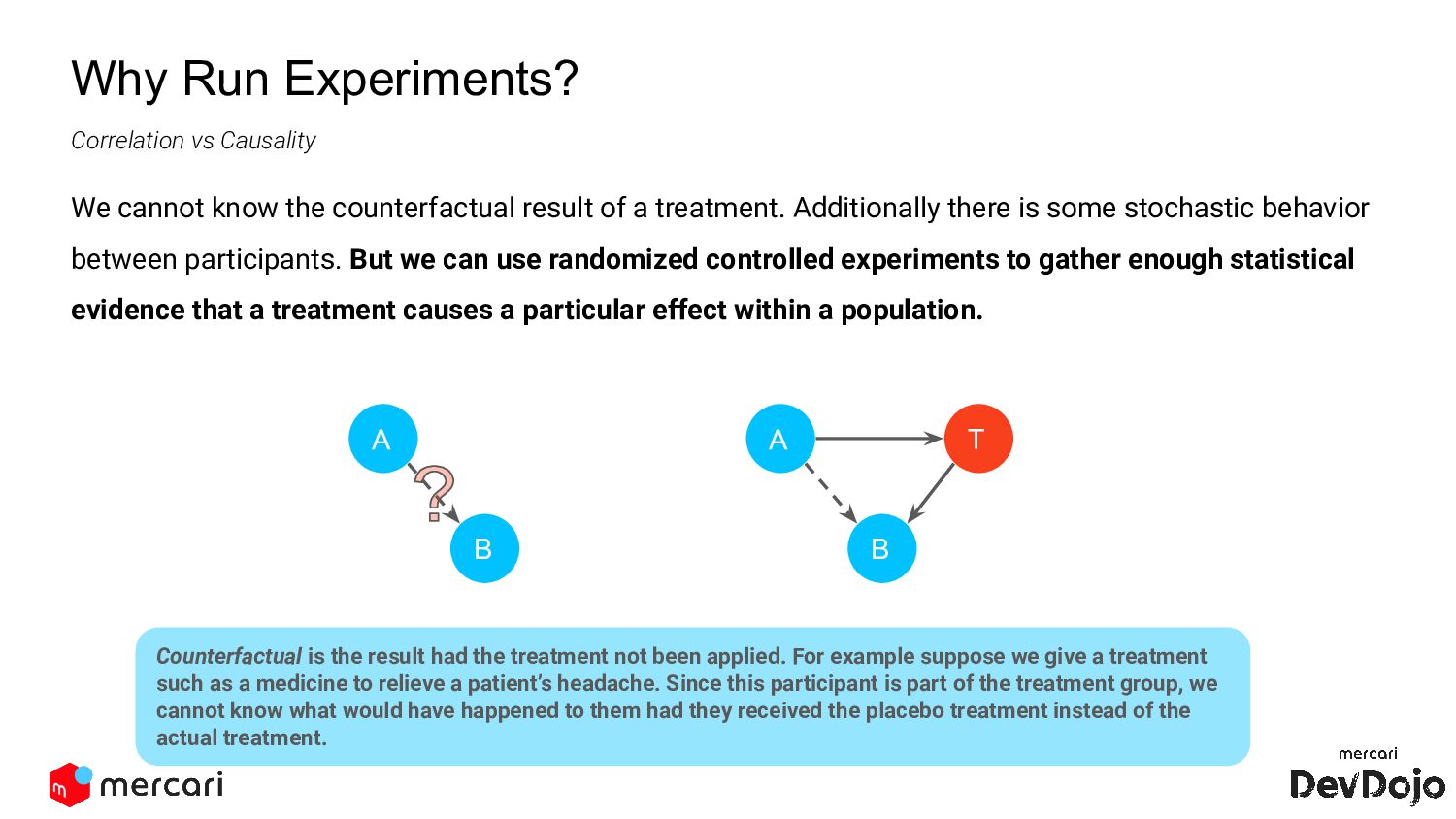
from our observations. Apply new knowledge about our service and marketplace. Why Run Experiments? But in order to learn anything, we need to establish causality. Simply finding correlations in data is not enough.
a treatment. Additionally there is some stochastic behavior between participants. But we can use randomized controlled experiments to gather enough statistical evidence that a treatment causes a particular effect within a population. A B A B T Correlation vs Causality Counterfactual is the result had the treatment not been applied. For example suppose we give a treatment such as a medicine to relieve a patient’s headache. Since this participant is part of the treatment group, we cannot know what would have happened to them had they received the placebo treatment instead of the actual treatment.
we’ve been leveraging experimentation and the scientific method for decades, and are fortunate to have a mature experimentation culture. There is broad buy-in across the company, including from the C-Suite, that, whenever possible, results from A/B tests or other causal inference approaches are near-requirements for decision making” “At Netflix, we do not view tests that do not produce winning experience as “failures.” When our members vote down new product experiences with their actions, we still learn a lot about their preferences, what works (and does not work!) for different member cohorts, and where there may, or may not be, opportunities for innovation.” Why Run Experiments? What Other Companies Are Doing
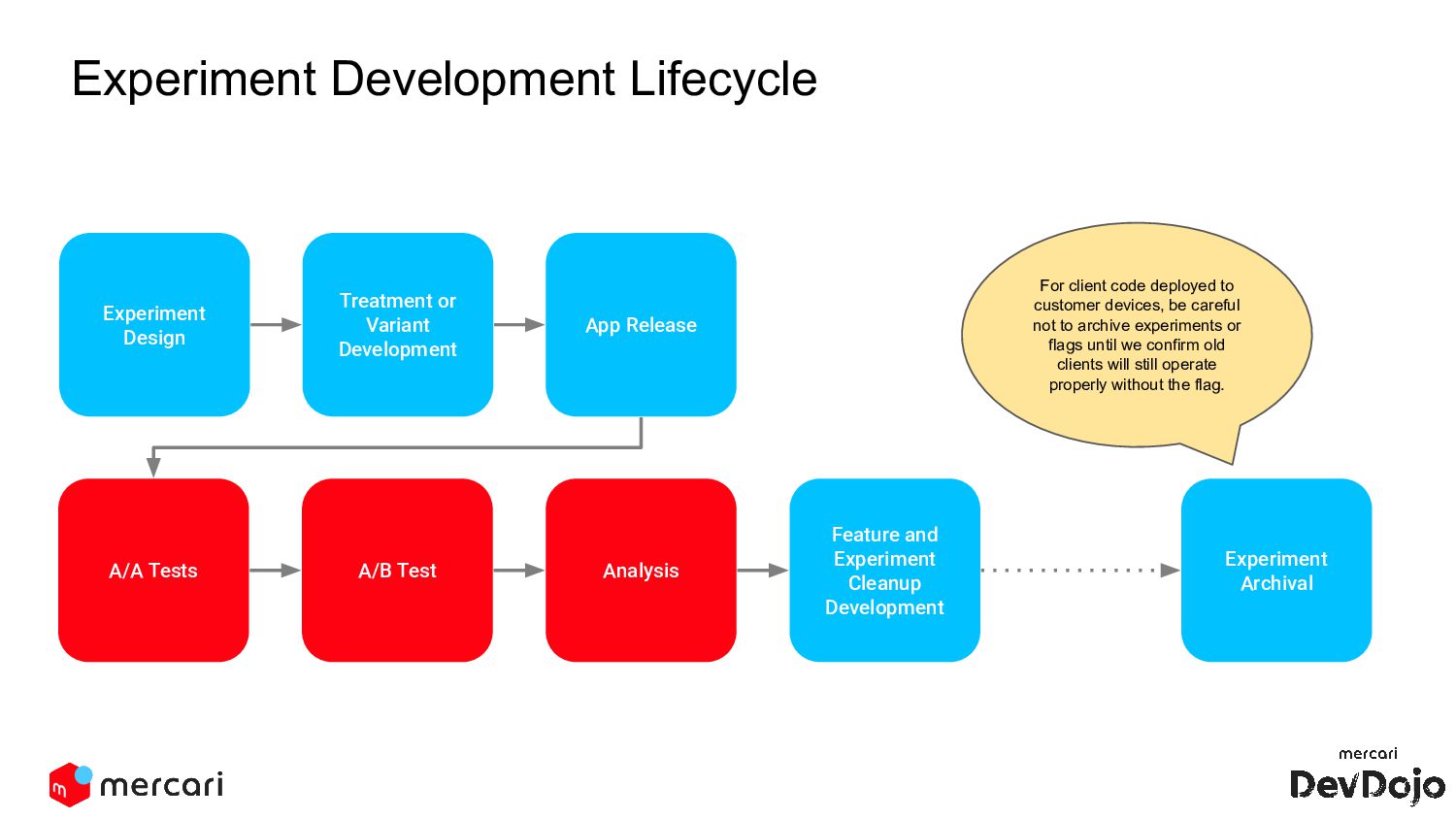
we plan on using our experiment to prove or disprove it. Common components of an Experiment Design Document at Mercari: • Hypothesis • Variables and their associated treatments • Metrics ◦ Goal Metrics ◦ Guardrail Metrics • Analysis • Conclusions and Future Actions Experiment Design In addition to reviewing the variants and treatments, also carefully look at the suggested guardrail metrics. For example certain feature interactions within the code base can lead to undesirable service incidents.
Release A/A Tests A/B Test Analysis Feature and Experiment Cleanup Development Experiment Archival For client code deployed to customer devices, be careful not to archive experiments or flags until we confirm old clients will still operate properly without the flag.
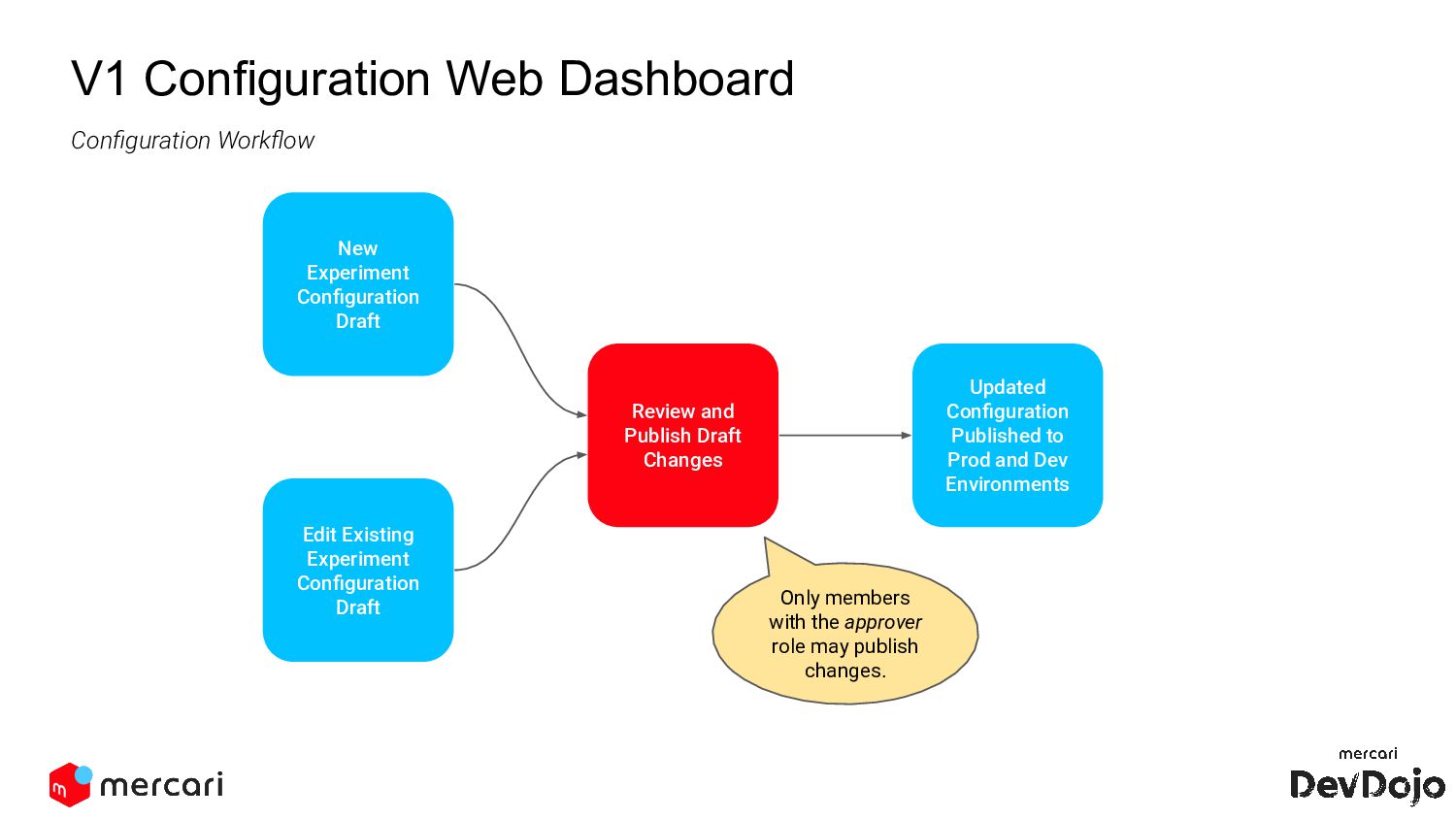
Review and Publish Draft Changes Edit Existing Experiment Configuration Draft Updated Configuration Published to Prod and Dev Environments Only members with the approver role may publish changes.
spaces. - platform: ios and android require the minimum version (integer). These versions should match Android version or iOS build numbers. - weights: percentage described as a decimal (0.5 = 50%) of threshold traffic to distribute to a particular variant. Changing weight ratios while an experiment is running will cause some users to be switch between variants. - threshold: percentage of all traffic to divert to the experiment. - start/end date: the time when the API will begin serving variant distributions for your experiment. If the API is accessed outside of the start/end dates, the experiment will not be included in the result set. So all client versions must always define an internal default value. V1 API Configuration Terminology
should be present: - X-Platform: the value here will be compared to the selected platform parameters - X-App-Version: the value here will be compared to the min-version parameter depending on the platform specified in the previous parameter If neither parameter matches the experiment configuration, variants will not be assigned. V1 API Server Headers
retrieving experiment variants. So usage will be implementation specific. In the following section we will go over a naive implementation so you can familiarize yourselves with general architecture nuances and gotchas.
func main() { tutorial := &Tutorial{ eventLogger: &EventLogger{}, } experiments := GetExperiments("Experiment_1", "Experiment_2", "Experiment_3") variant := experiments["Experiment_2"] // *** What is wrong here? tutorial.Show(variant) } // Tutorial decides which version of the tutorial to show if any. type Tutorial struct { eventLogger *EventLogger } V1 Sample Usage func (t *Tutorial) Show(variant uint) { t.eventLogger.LogEvent("Experiment_2", fmt.Sprintf("variant:%d", variant)) if variant == 0 || variant == 1 { // don't show anything for users not assigned to the experiment (0) and // the control group (1) return } if variant == 2 { t.Slideshow() return } if variant == 3 { t.Animation() return } if variant == 4 { t.DemoVideo() return } // *** On-hands session: How can we improve maintainability of this code? } func (t *Tutorial) Slideshow() { // omitted for brevity } func (t *Tutorial) Animation() { // omitted for brevity } func (t *Tutorial) DemoVideo() { // omitted for brevity } // Results maps experiment names to their assigned variants. type Results map[string]uint func GetExperiments(names ...string) Results { // *** What is wrong with this function implementation??? var response *http.Response var err error const maxRetries = 10 for c := 0; c < maxRetries; c++ { response, err = http.Get(generateURL(names)) if err != nil { log.Println("failed to fetch experiments") } if err == nil { break } } if err != nil { return Results{} } return parseExperiments(response) } func parseExperiments(response *http.Response) Results { // omitted for brevity return Results{} } func generateURL(names []string) string { param := url.QueryEscape(strings.Join(names, ",")) return fmt.Sprintf("https://localhost:55555/get_running_experiments_by_name?names=%s", param) } type EventLogger struct{} func (el *EventLogger) LogEvent(details ...string) { // Omitted for brevity. Assume all relevant details are properly logged. } This is a very obvious way to use the API. It is not a model of a good implementation.
:= GetExperiments("Experiment_1", "Experiment_2", "Experiment_3") variant := experiments["Experiment_2"] // *** What is wrong here? tutorial.Show(variant) } V1 Sample Usage: Key Concerns (1) A client predefined default variant value is not clearly specified. Because this is Go, the map access will result in the default value for uint which is 0. So the program will still execute normally. However other programming languages or constructs may not behave in a safe manner. So it is better to be explicit about the default behavior for the client if the experiments API becomes unavailable.
with this function implementation??? var response *http.Response var err error const maxRetries = 10 for c := 0; c < maxRetries; c++ { response, err = http.Get(generateURL(names)) if err != nil { log.Println("failed to fetch experiments") } if err == nil { break } } if err != nil { return Results{} } return parseExperiments(response) } V1 Sample Usage: Key Concerns (2)
with this function implementation??? var response *http.Response var err error const maxRetries = 10 for c := 0; c < maxRetries; c++ { response, err = http.Get(generateURL(names)) if err != nil { log.Println("failed to fetch experiments") } if err == nil { break } } if err != nil { return Results{} } return parseExperiments(response) } V1 Sample Usage: Key Concerns (2) The HTTP request has no timeout and no back off implementation. The lack of timeout means the request can block the program forever. Secondly the lack of request retry back off will result in multiple clients sending a request storm to the server. This can put too much pressure on the server infrastructure leading to further crashes and issues on the server if not handled well. Even when the server is able to properly deny requests in an overloaded state, in this case the client will be too fast with request retries and quickly fail for intermittent service downtime.
variant == 0 || variant == 1 { // don't show anything for users not assigned to the experiment (0) and // the control group (1) return } if variant == 2 { t.Slideshow() return } if variant == 3 { t.Animation() return } if variant == 4 { t.DemoVideo() return } // *** On-hands session: How can we improve maintainability of this code? } V1 Sample Usage: Key Concerns (3) Are we logging our events in the right place?
• Retry failed requests with back off intervals. • Ensure your client can react properly when the experiments API becomes unavailable. • React properly to defined HTTP response status codes. Ensure your event logging implementation logs events correctly: • Event logs should happen when it is clear the event has taken place: ◦ When a backend response completed transmission ◦ When a frontend client actually displays a component V1 Usage: Key Takeaways
is highly recommended to perform an A/A test. If the A/A test results in any imbalances, we must create a new experiment with a different name to get a new distribution. - Cannot isolate experiments from other running experiments. All clients querying the API will be considered for all experiments. - Cannot easily configure multiple client parameters from a single experiment. V1 API Key Limitations So my team is currently working on a new experimentation platform.
set of parameter values) - A newly designed bucketing algorithm based on layers (“overlapping experiments”) - Ability to re-randomize buckets without updating clients - And more! V2 Preview
}, { "parameter": "ListTutorialPage", "value": "video-animation", "experiment-id": "ListTutorials-6789" } ] V2 Preview This is still on-going work. It is just a sample for demonstrative purposes.
example we can observe either an extremely large increase or decrease in key metrics without observing any notable issues like app crashes or direct user feedback. Anytime we observe hard to believe statistic, it is known as Twyman’s Law. - Accurate event logging is another possible problem. For example if we naively believe we can just use server event logs for features that can affect client user metrics, then we may not get accurate interpretations because the communication between the client and server is lossy. We must be careful to consider accurately logging the state of client app in regards to actual displayed variant and experiment configurations. General Experimentation Issues Implementation and Logging Bugs
algorithm for randomization. Therefore randomization traits are limited by properties of md5 hashing. And we have observed imbalances because of this. - Even given pure random results, statistical hypothesis testing is still based on probabilities so there is always a small chance we observe some sort of unexpected results. General Experimentation Issues Observed Effects Due to Chance
that there are no confounding variables in the experiment design. A possible common confounding variable within our environment is the effects of latency on user behavior. For example it is possible that our user’s behavior is sensitive to the responsiveness of our application and APIs. Therefore if we test a new feature that is noticeably slower to respond than the feature it replaces, we may inadvertently be measuring the effects due to latency, not the actual feature itself. - Another time we inadvertently can run into confounding variables is the time period over which we run our experiment. For example user behavior is likely influenced by time of day, day of the week, and by seasonal aspects (holiday seasons vs non-holidays, winter vs summer, etc). So the chosen experimentation period may also introduce uncontrolled biases. General Experimentation Issues Confounding Variables
with each other. For example applying a treatment to a single user should not have any spillover effect to other users in the experiment. - Unfortunately our environment is a “two-sided marketplace” where buyers and sellers interact. So it is fairly easy to come up with experiment ideas that violate SUTVA. General Experimentation Issues Stable Unit Treatment Value Assumption (SUTVA)
• We want to have our main branch in a releasable state • We want to be able to activate and deactivate code that is already released Why Use Feature Flags?
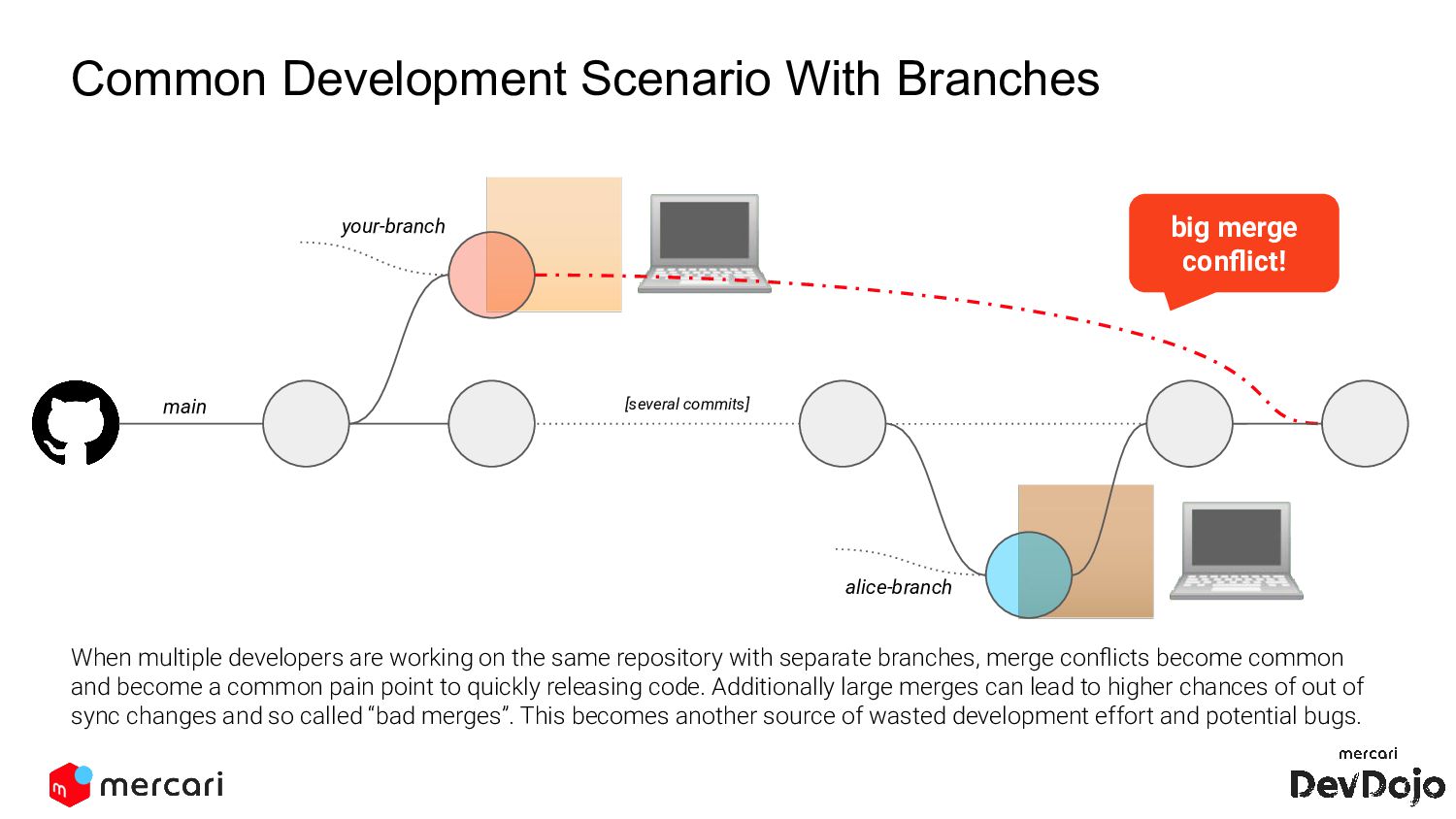
[several commits] big merge conflict! your-branch alice-branch When multiple developers are working on the same repository with separate branches, merge conflicts become common and become a common pain point to quickly releasing code. Additionally large merges can lead to higher chances of out of sync changes and so called “bad merges”. This becomes another source of wasted development effort and potential bugs.
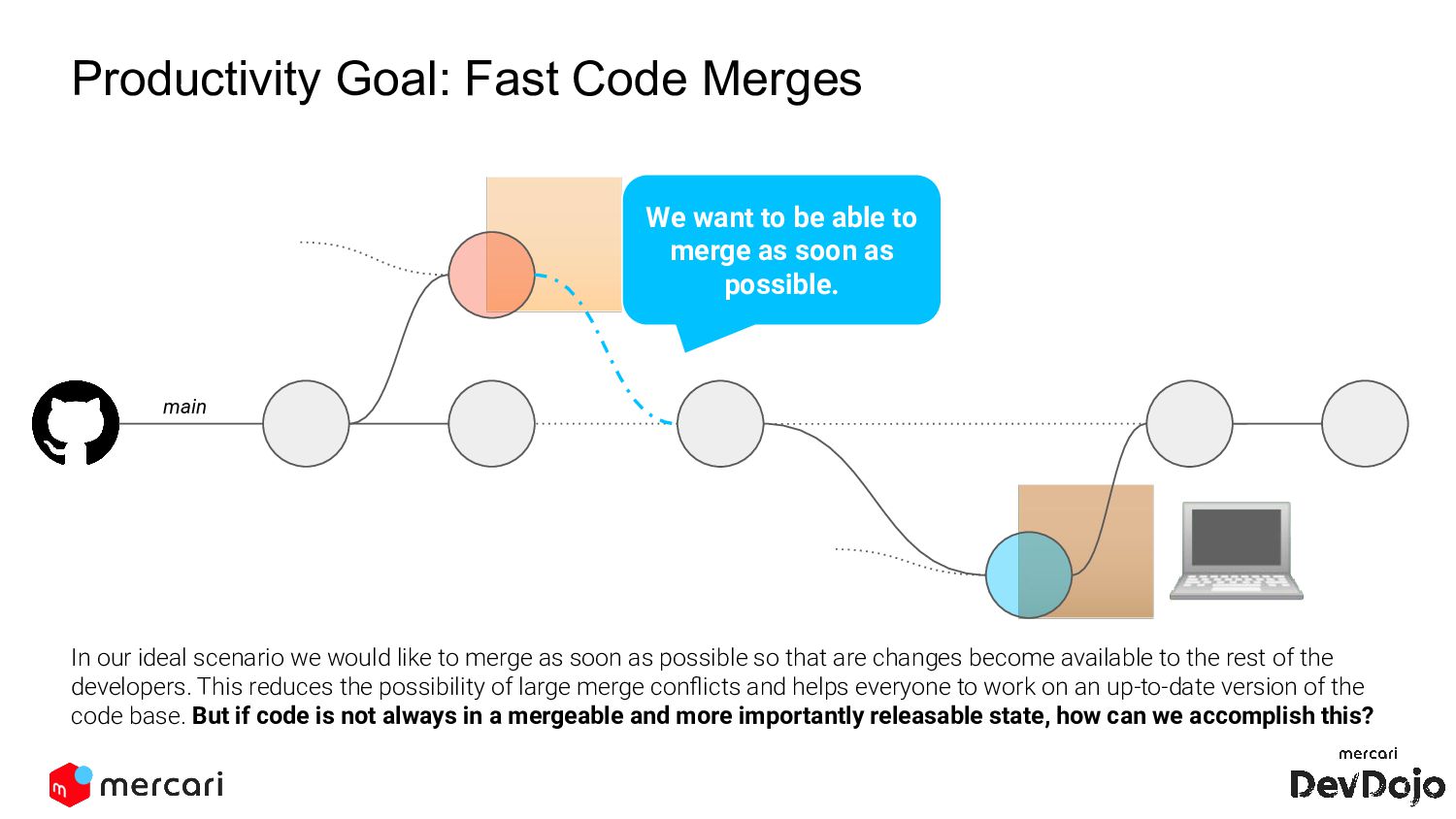
We want to be able to merge as soon as possible. In our ideal scenario we would like to merge as soon as possible so that are changes become available to the rest of the developers. This reduces the possibility of large merge conflicts and helps everyone to work on an up-to-date version of the code base. But if code is not always in a mergeable and more importantly releasable state, how can we accomplish this?
to pick up merged changes. Good: Everyone keeps their branches up to date reducing the possibility of a large merge conflict later. Bad: Individual developers spend time to keep their branches up to date. Additionally their local changes are not immediately visible to others.
merge changes into an unstable “development” branch. Good: Everyone synchronizes code into a single branch. Bad: Must introduce release branches to stabilize development. This leads to multiple branch management for each release.
problem as a source control problem. But what if we step away from source control and identify what code base traits we want to have: • We would like to have the code base in a releasable state at any time. • We would like developers to publish their changes as early as possible for shared visibility in the team.
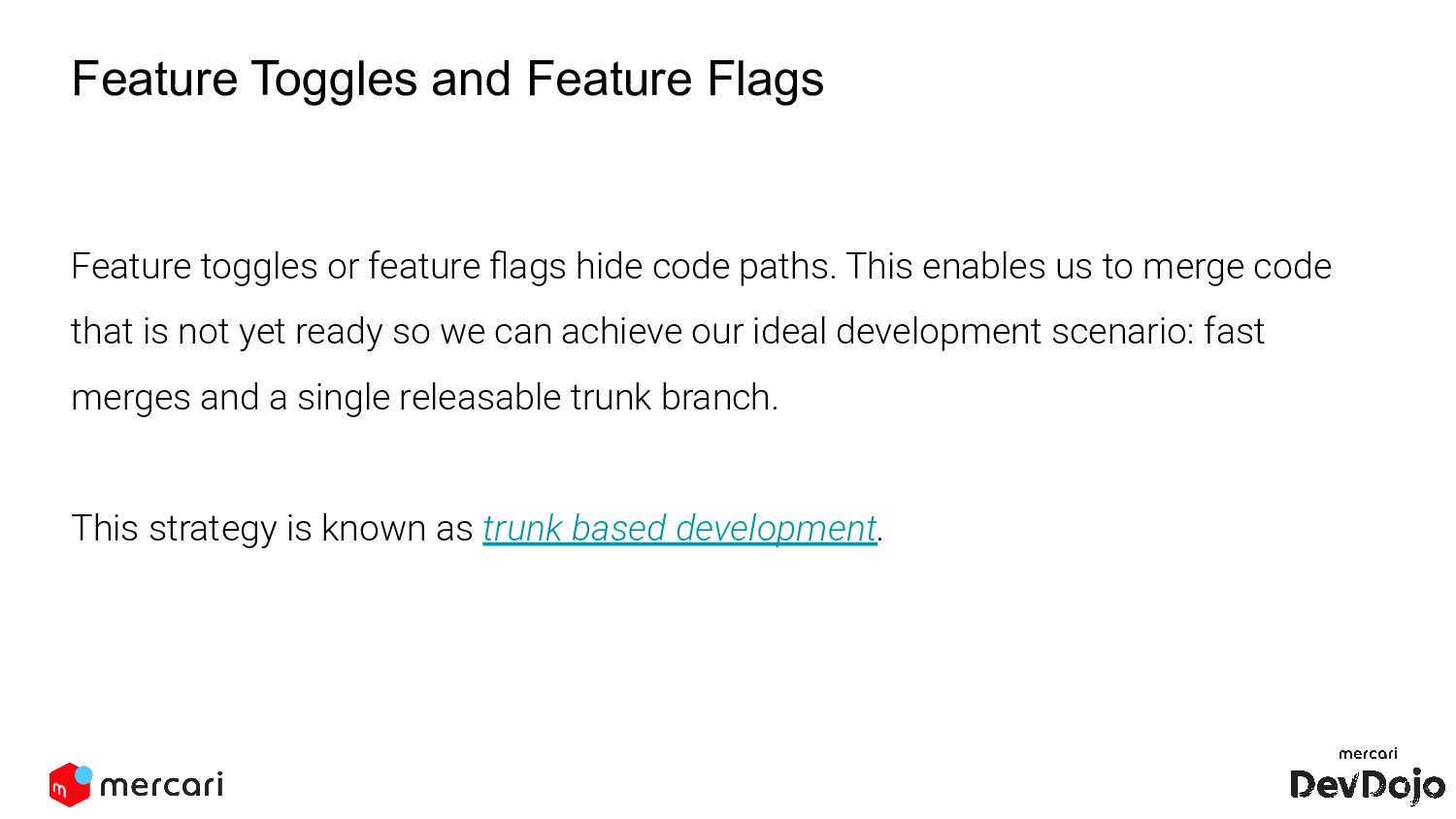
hide code paths. This enables us to merge code that is not yet ready so we can achieve our ideal development scenario: fast merges and a single releasable trunk branch. This strategy is known as trunk based development.
experiments API, we gain the ability to remotely activate and deactivate any code path and therefore feature. This gives a new capability: testing in production. But why would we want to test in production?
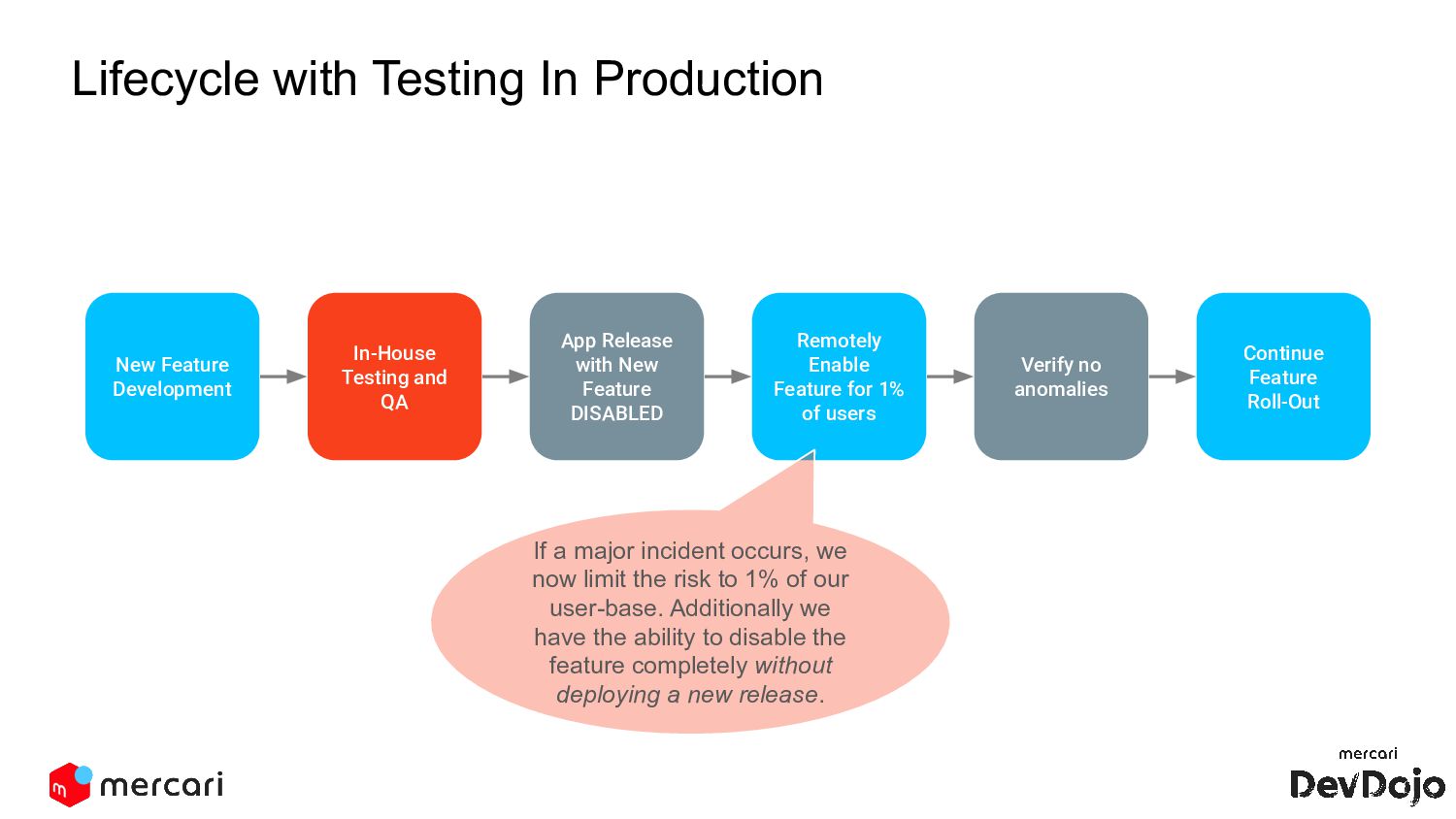
and QA App Release with New Feature DISABLED Remotely Enable Feature for 1% of users Verify no anomalies Continue Feature Roll-Out If a major incident occurs, we now limit the risk to 1% of our user-base. Additionally we have the ability to disable the feature completely without deploying a new release.
and release processes by allowing us to merge early and release early. • We reuse our existing Experiments API for feature flags and new feature rollouts. • We gain a new testing step called Testing In Production to reduce the risks associated with releasing new features.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}