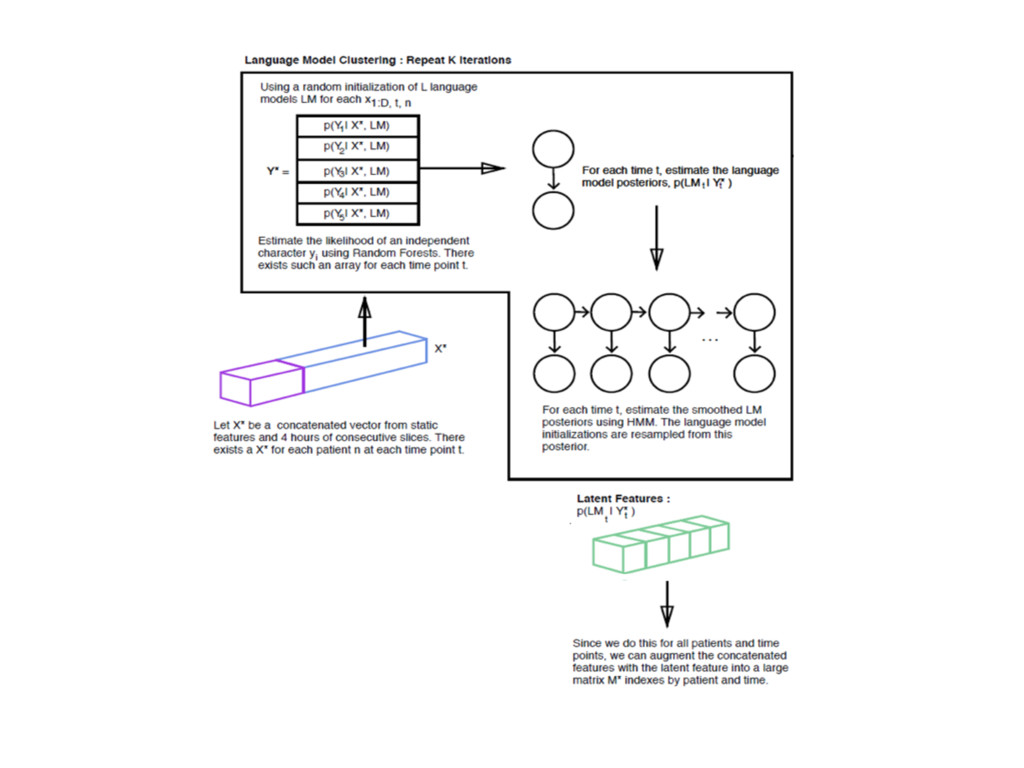
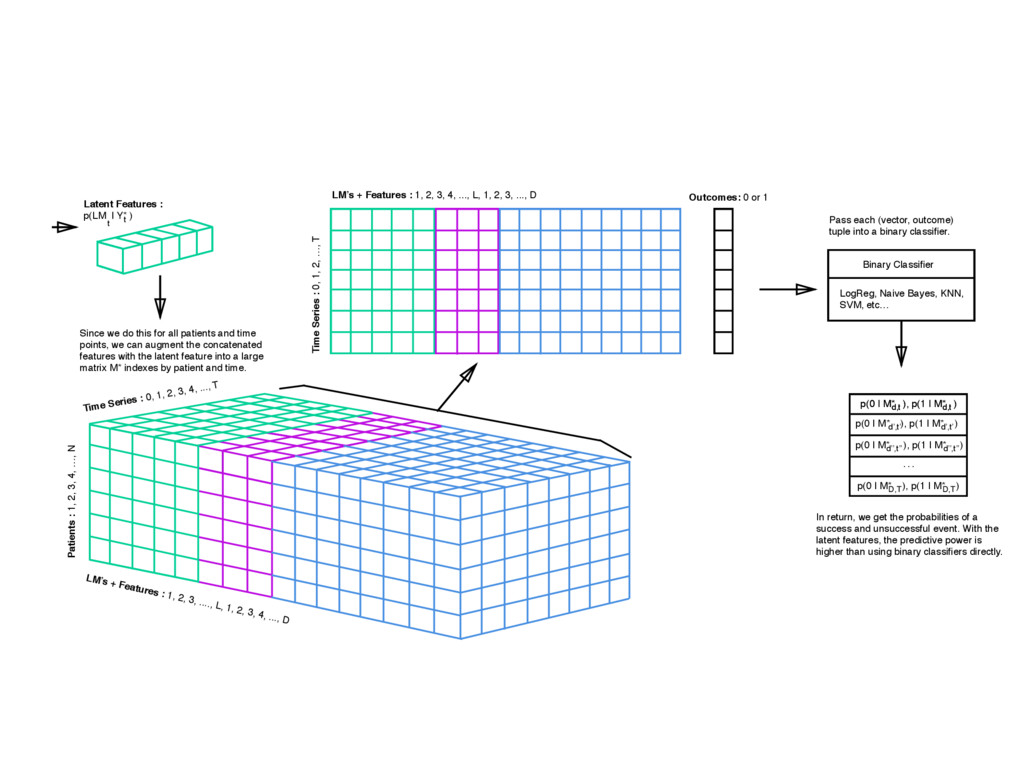
: 0, 1, 2, 3, 4, ..., T LM’s + Features : 1, 2, 3, ...., L, 1, 2, 3, 4, ..., D Latent Features : p(LM | Y* ) Since we do this for all patients and time points, we can augment the concatenated features with the latent feature into a large matrix M* indexes by patient and time. Pass each (vector, outcome) tuple into a binary classifier. In return, we get the probabilities of a success and unsuccessful event. With the latent features, the predictive power is higher than using binary classifiers directly. age age t t el Time Series : 0, 1, 2, …, T LM’s + Features : 1, 2, 3, 4, ..., L, 1, 2, 3, ..., D Outcomes: 0 or 1 Binary Classifier LogReg, Naive Bayes, KNN, SVM, etc… … p(0 | M* ), p(1 | M* ) d,t d,t p(0 | M* ), p(1 | M* ) d’,t’ d’,t’ p(0 | M* ), p(1 | M* ) d’’,t’’ d’’,t’’ p(0 | M* ), p(1 | M* ) D,T D,T p(0 | M* ), p(1 | M* ) d,t d,t
{kind=link}
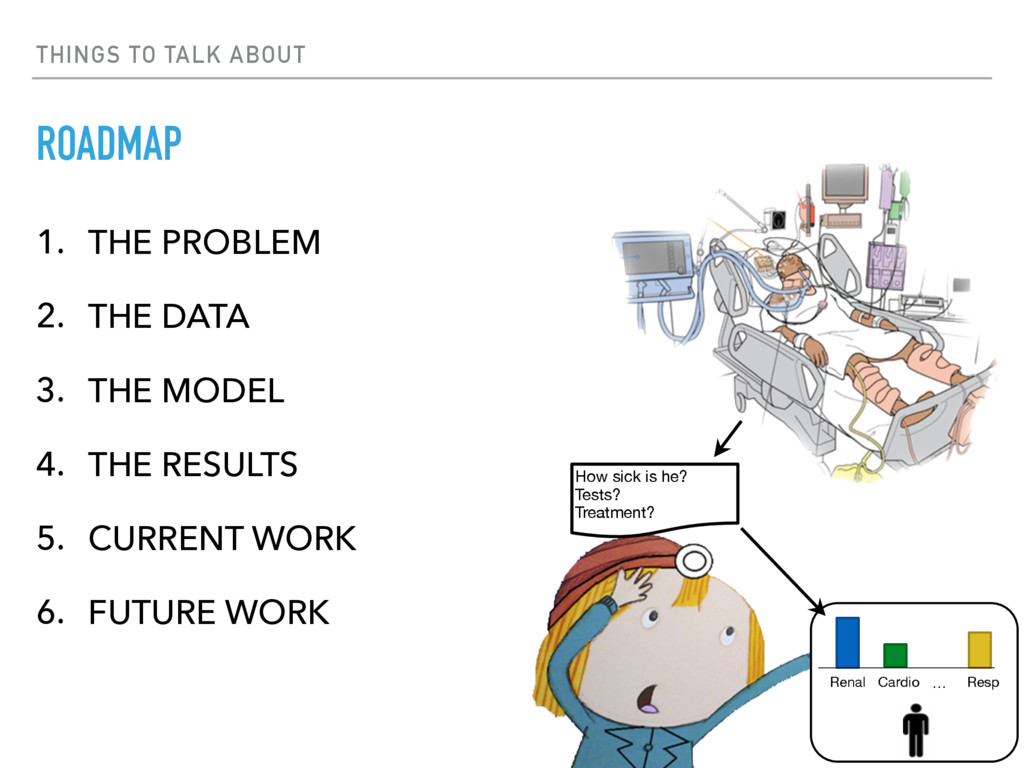{kind=link}
{kind=link}
{kind=link}
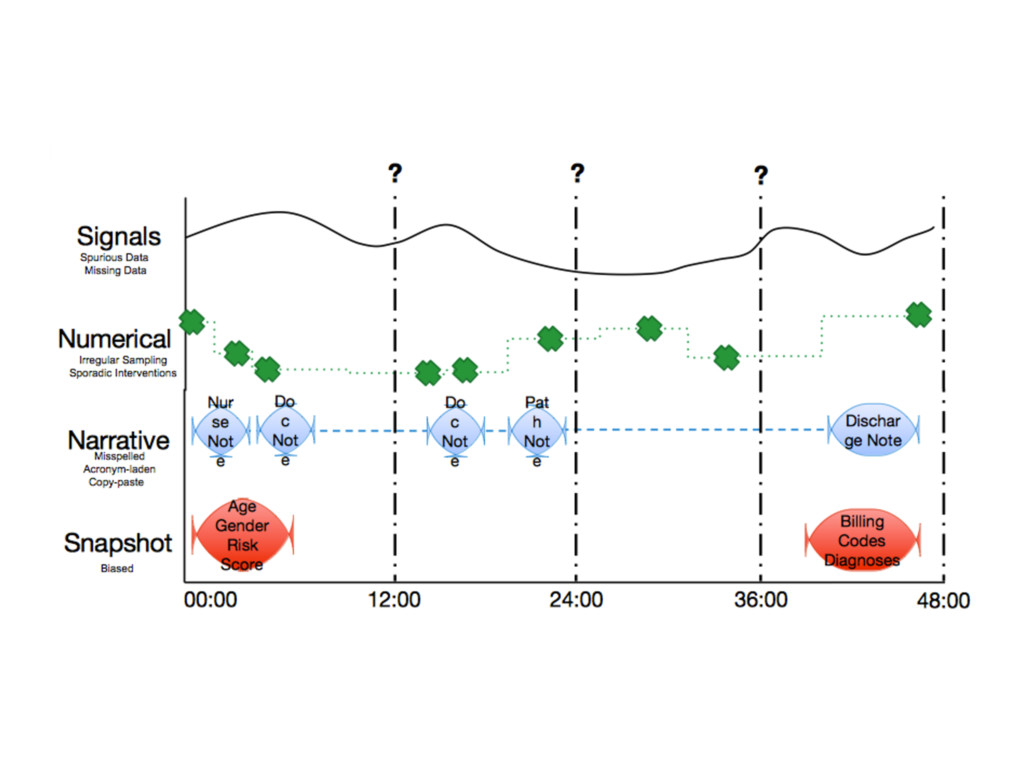{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
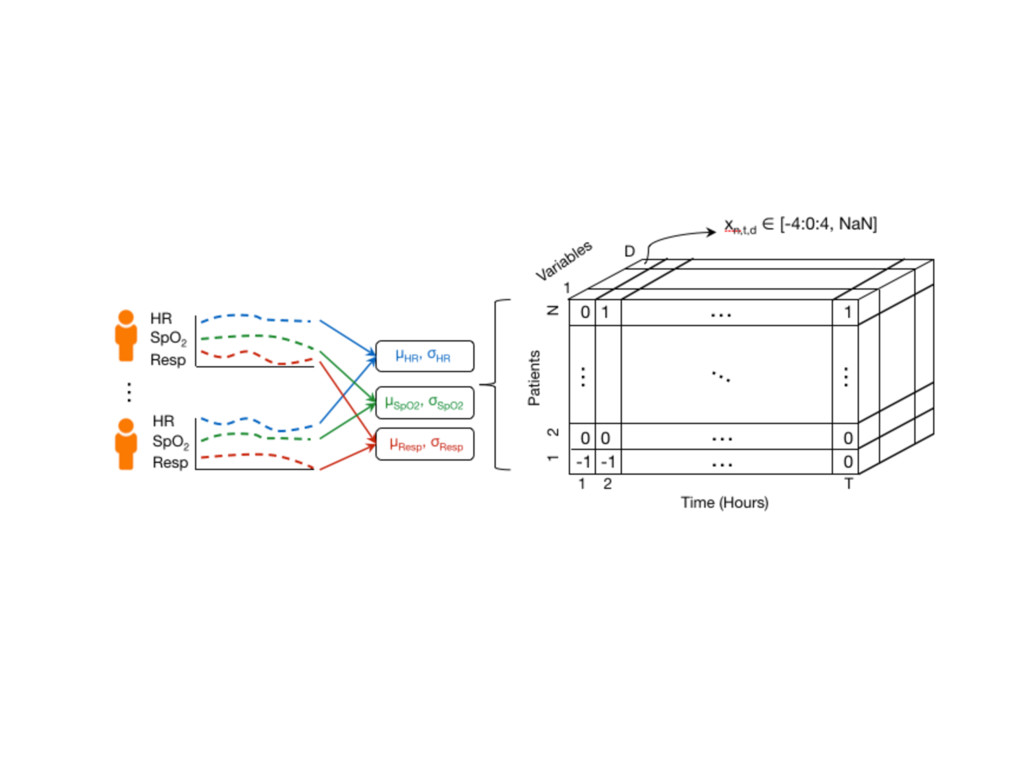{kind=link}
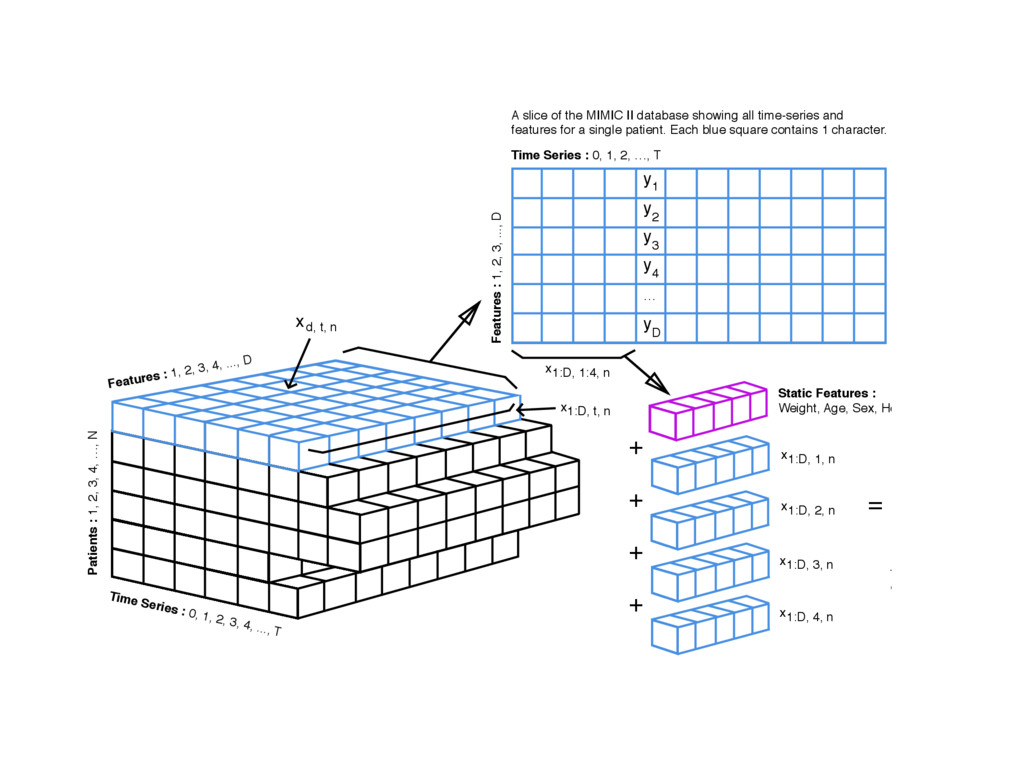{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
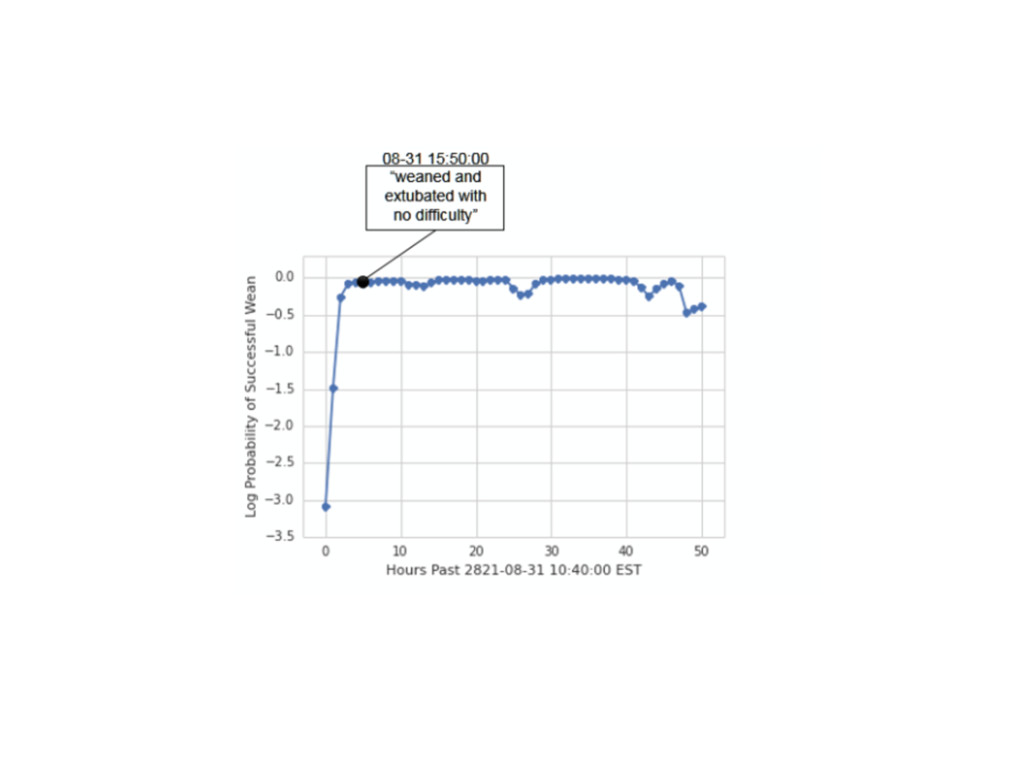{kind=link}
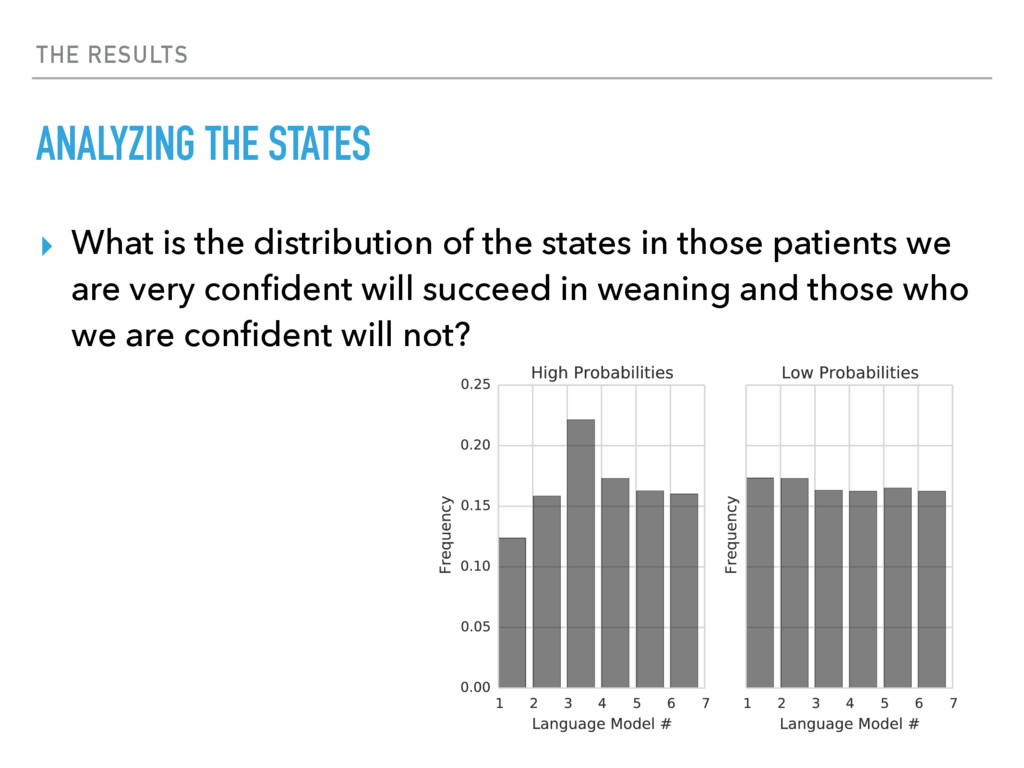{kind=link}
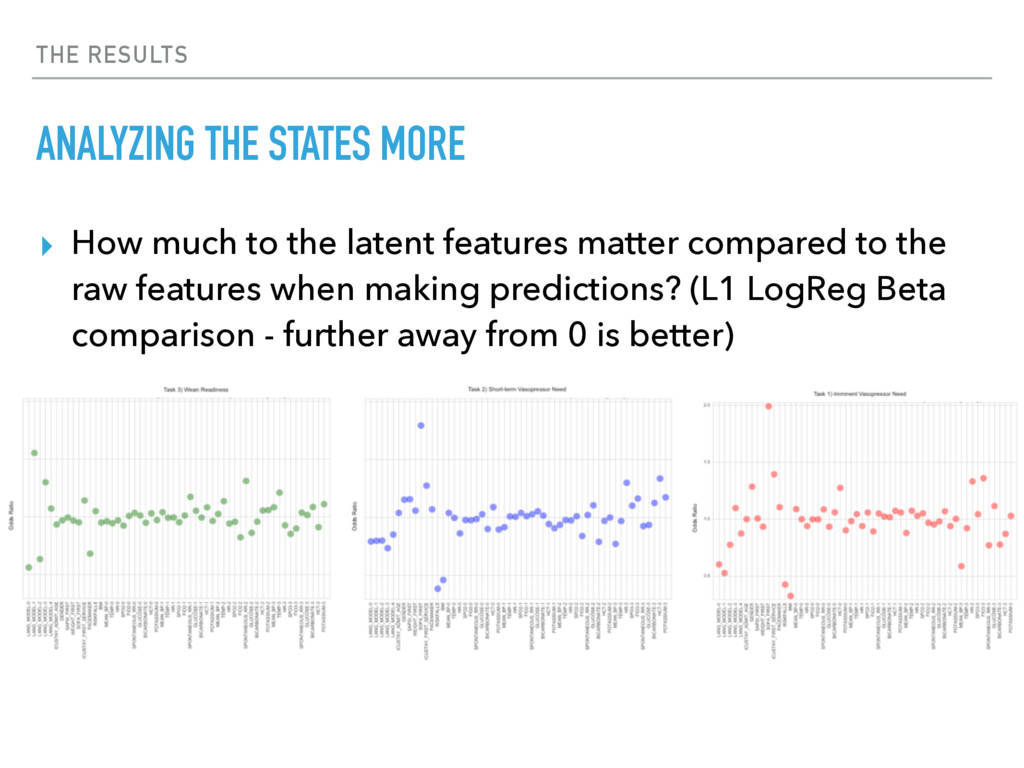{kind=link}
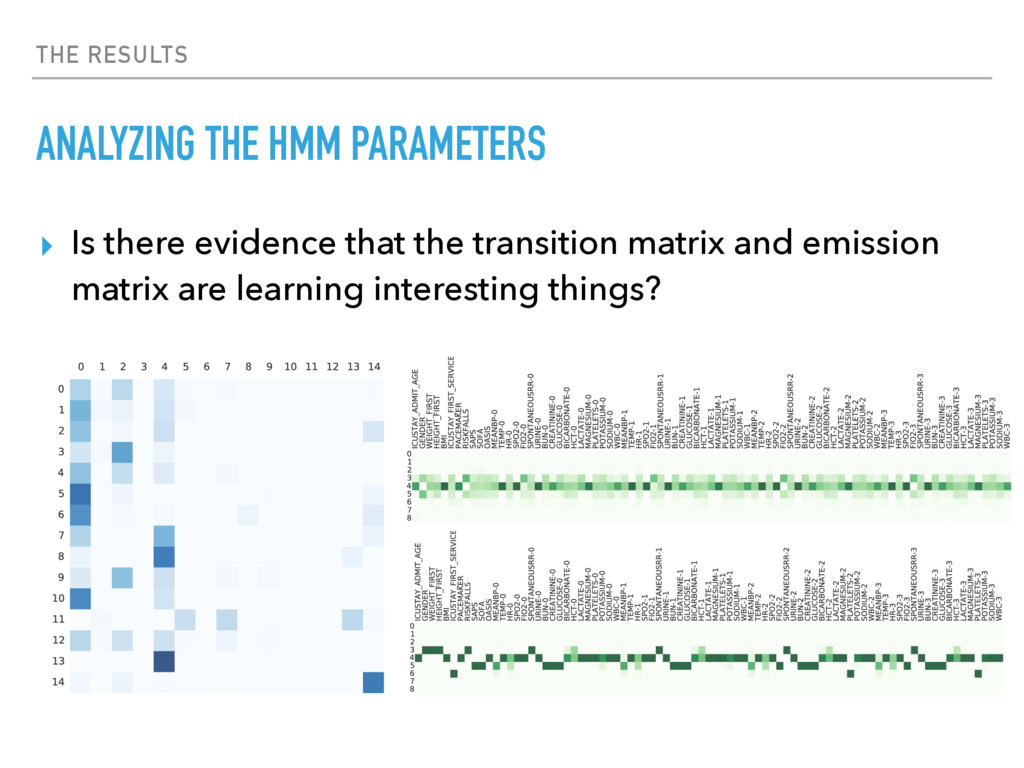{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}