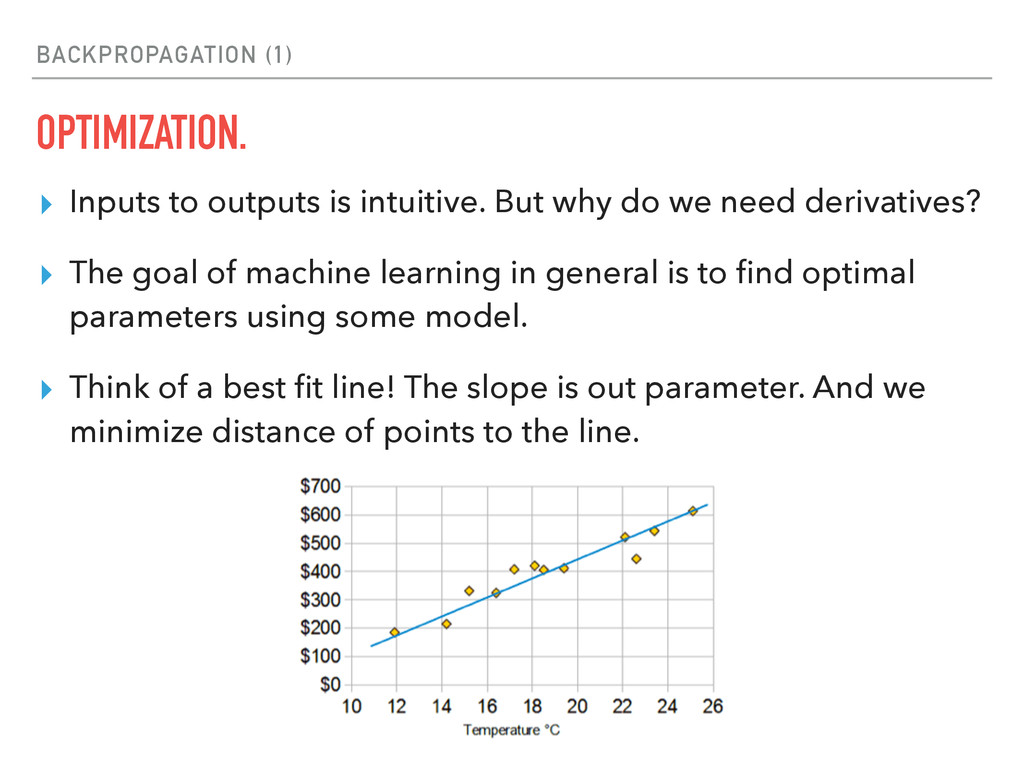
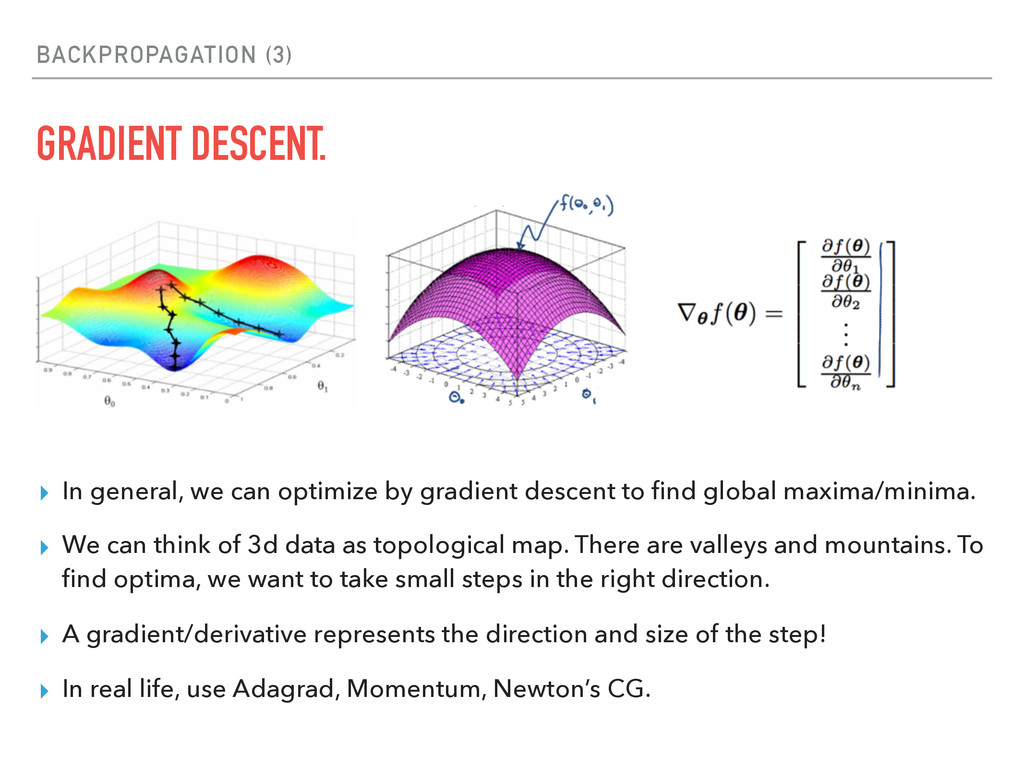
by gradient descent to find global maxima/minima. ▸ We can think of 3d data as topological map. There are valleys and mountains. To find optima, we want to take small steps in the right direction. ▸ A gradient/derivative represents the direction and size of the step! ▸ In real life, use Adagrad, Momentum, Newton’s CG.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ASK ME QUESTIONS! EMAIL? [email protected]](https://files.speakerdeck.com/presentations/5fbeddc0fcc448eb897ac721acc48d6e/slide_48.jpg){kind=link}