My talk at Apache Kafka meetup, Dublin/Ireland, July 04, 2017.
https://www.meetup.com/Dublin-Apache-Kafka-Meetup-by-Confluent/events/240906790/
Abstract:
Modern businesses have data at their core, but this data is changing continuously. How can you harness this torrent of information in real time? The answer: stream processing.
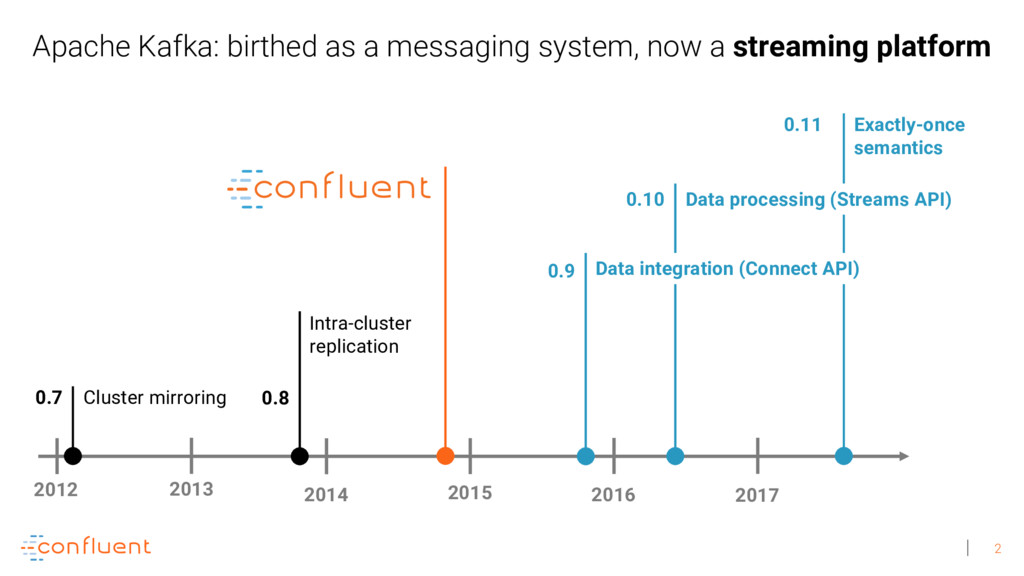
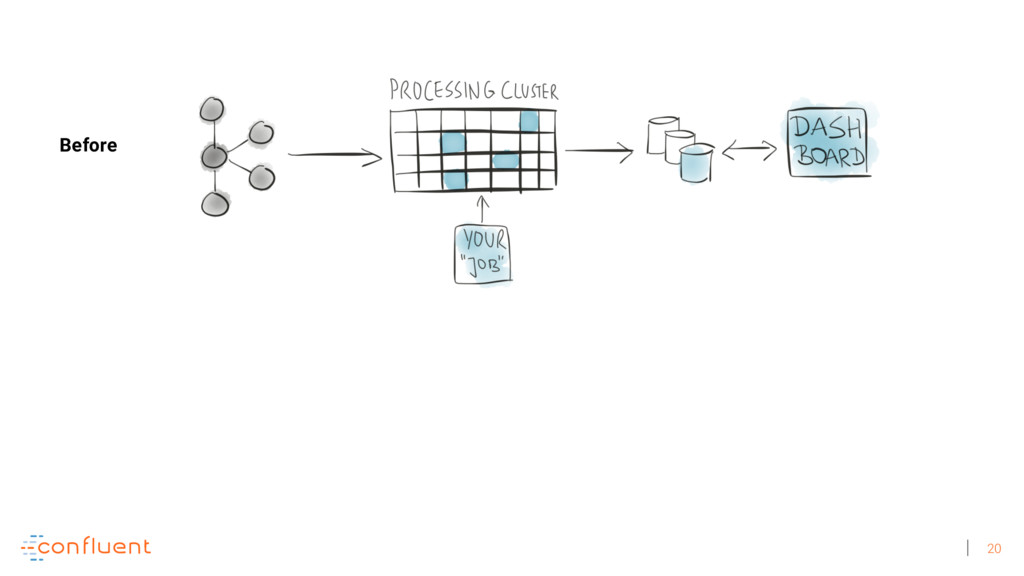
The core platform for streaming data is Apache Kafka, and thousands of companies are using Kafka to transform and reshape their industries, including Netflix, Uber, PayPal, Airbnb, Goldman Sachs, Cisco, and Oracle. Unfortunately, today’s common architectures for real-time data processing at scale suffer from complexity: to succeed, many technologies need to be stitched and operated together, and each individual technology is often complex by itself. This has led to a strong discrepancy between how we engineers would like to work and how we actually end up working in practice.
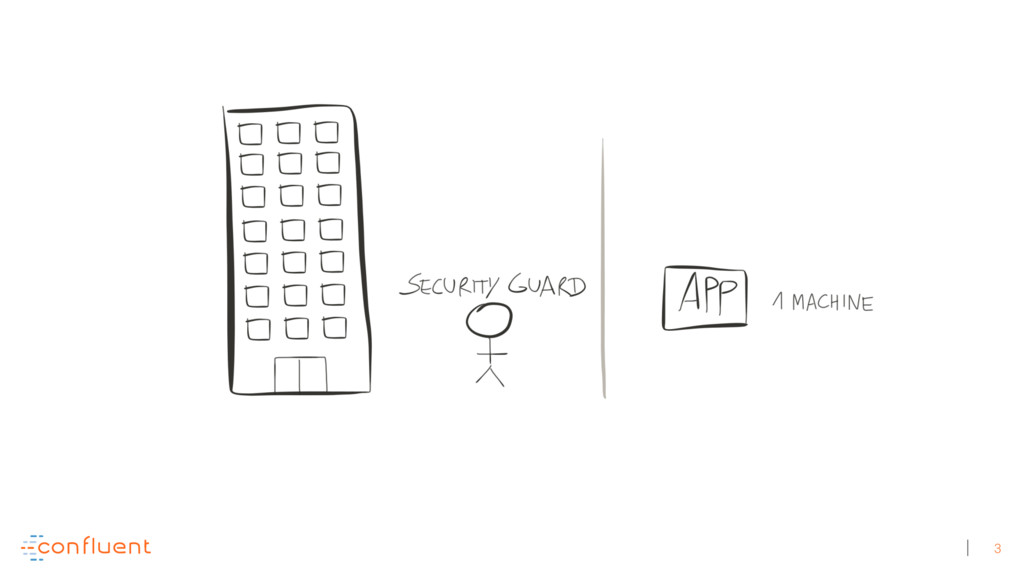
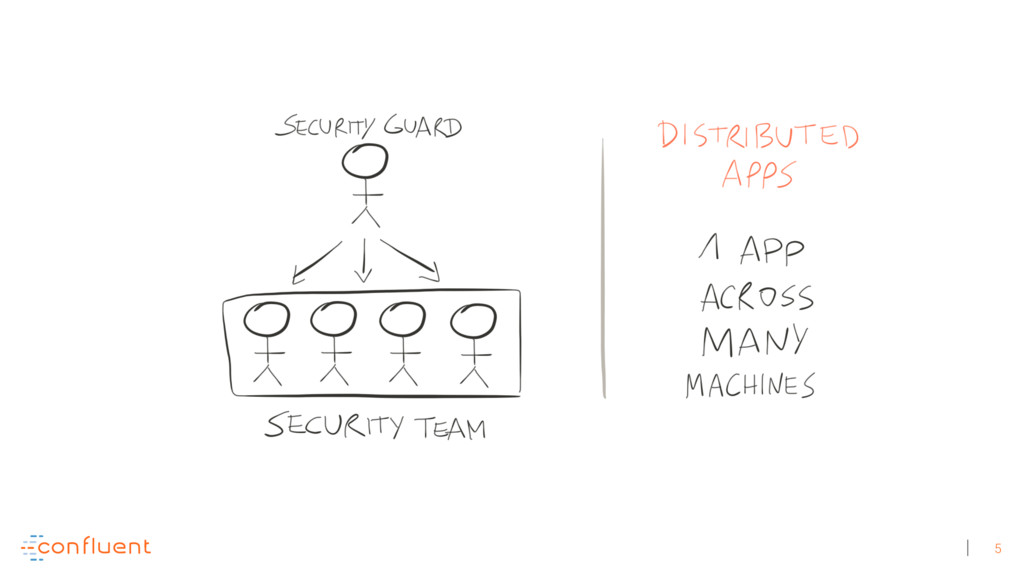
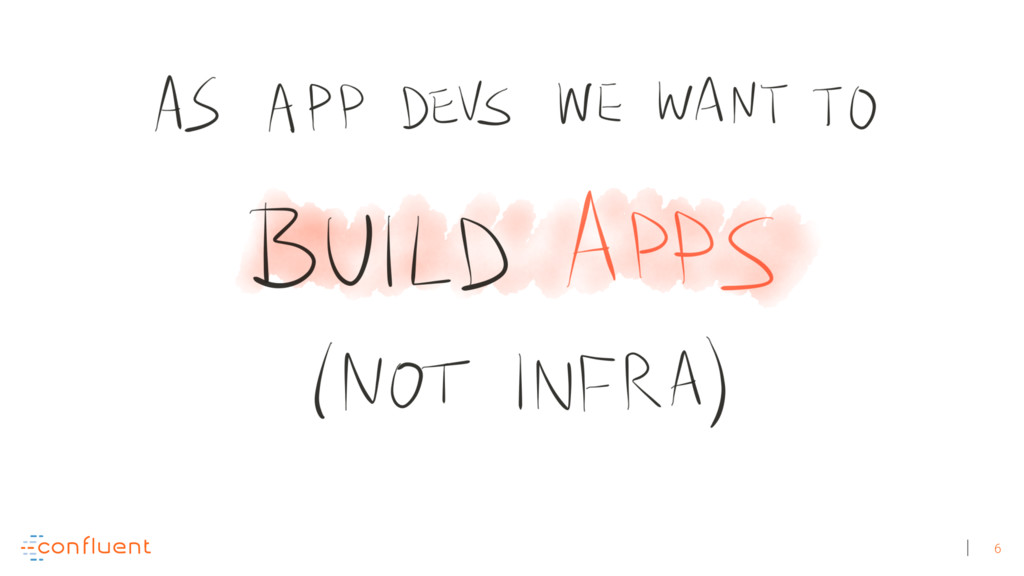
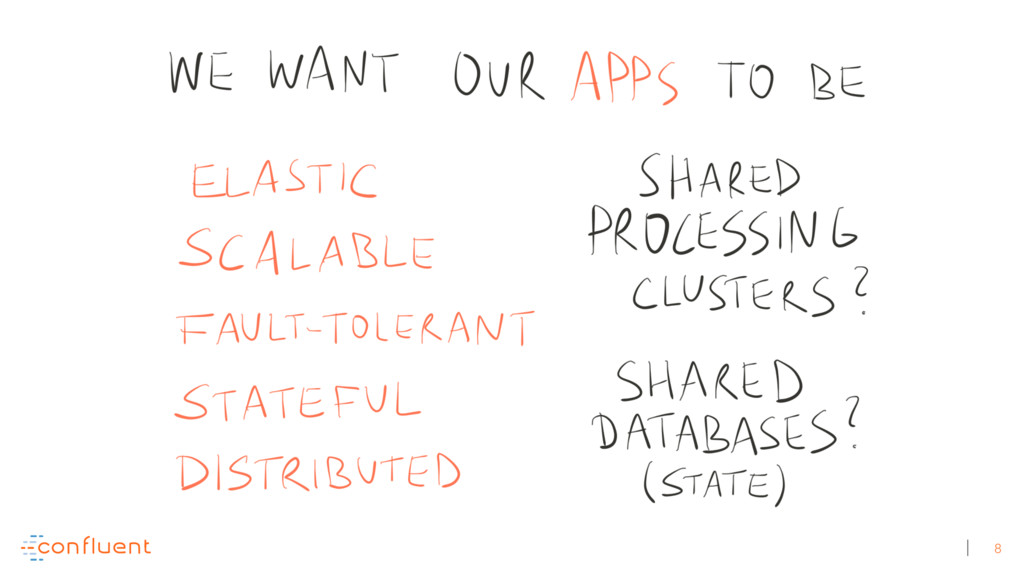
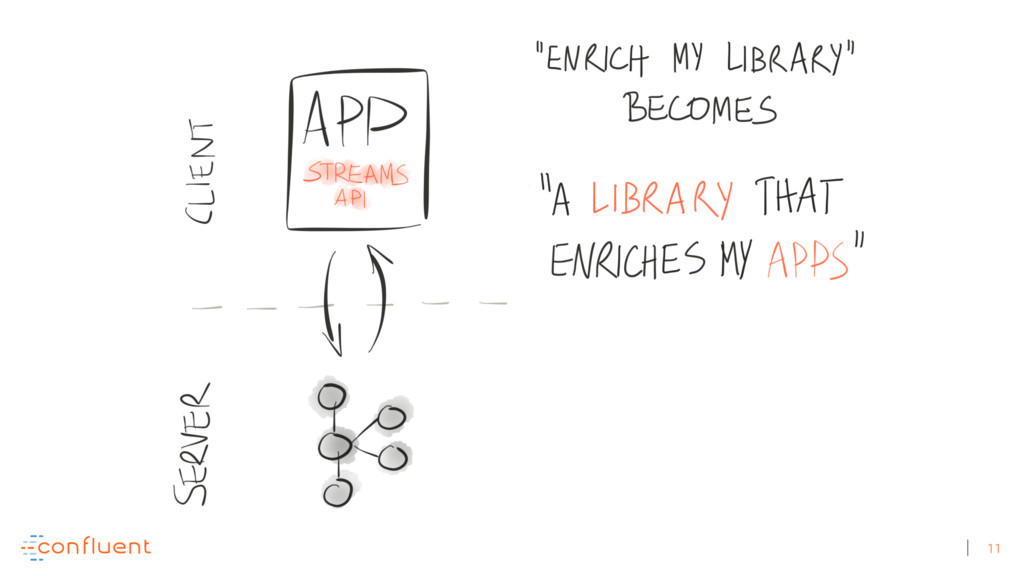
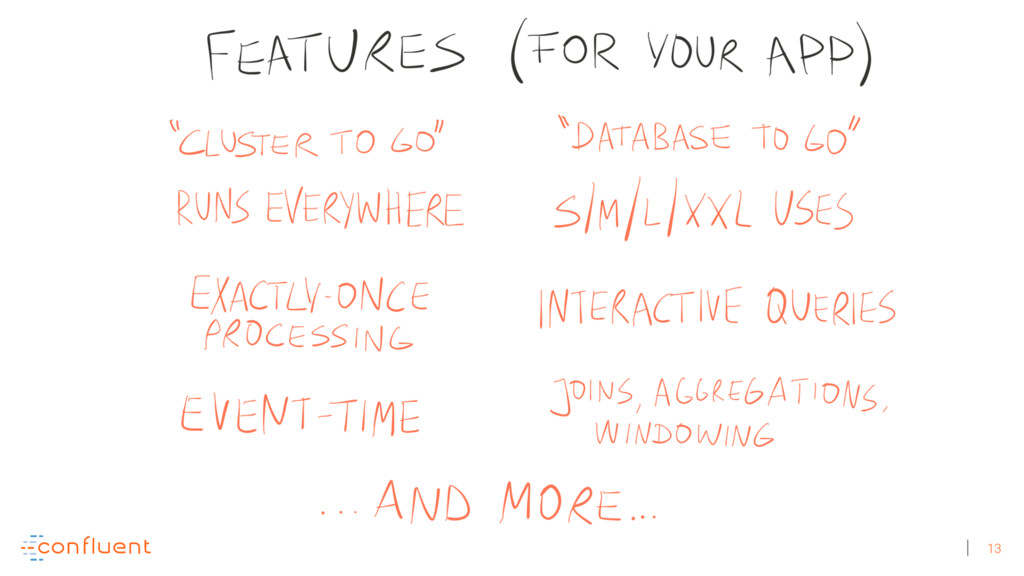
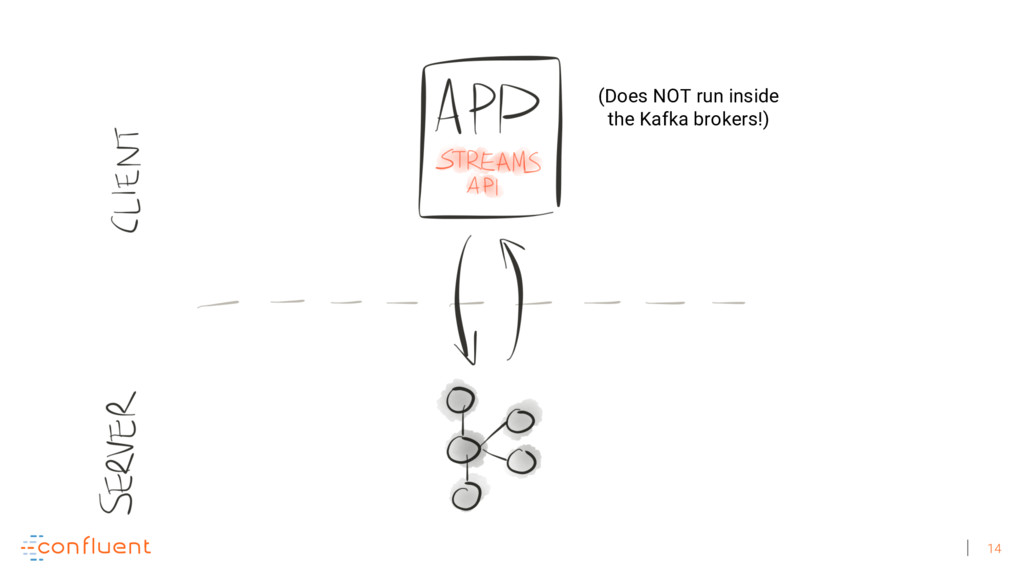
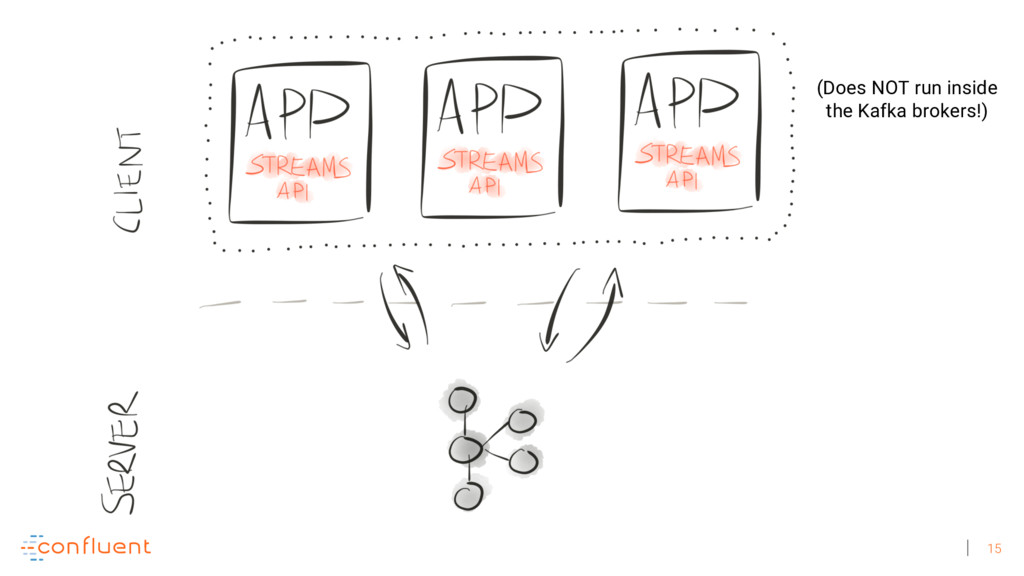
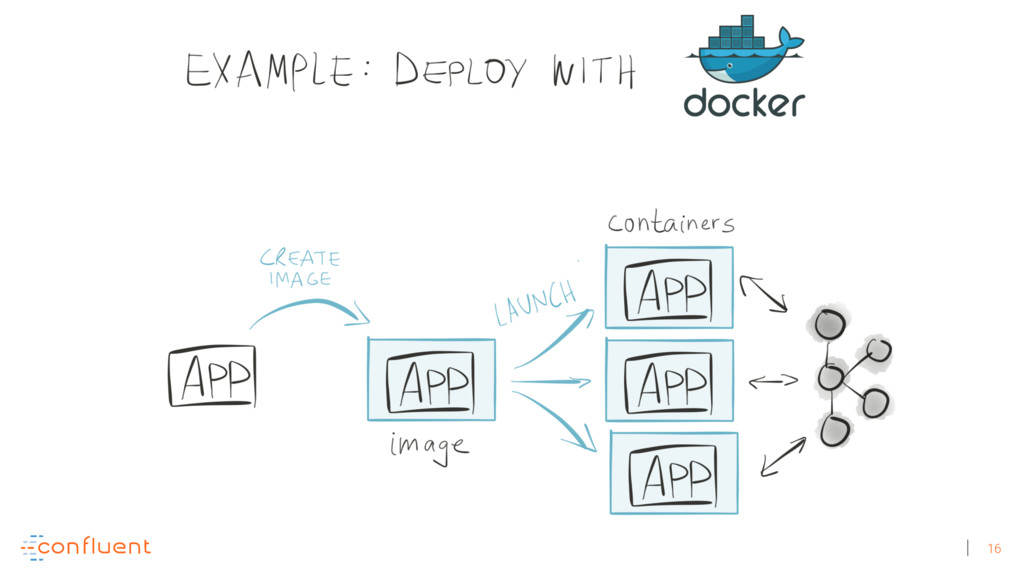
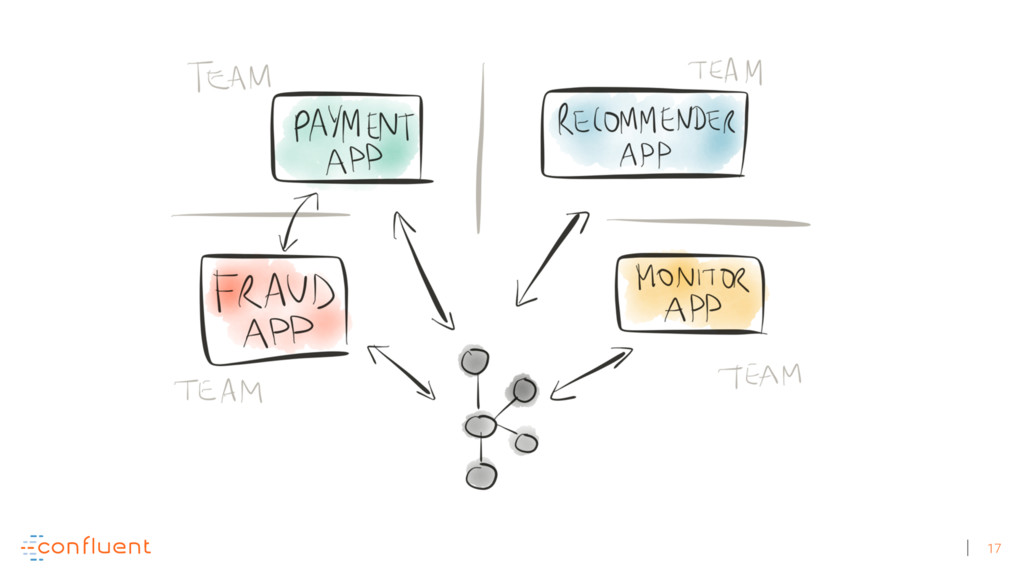
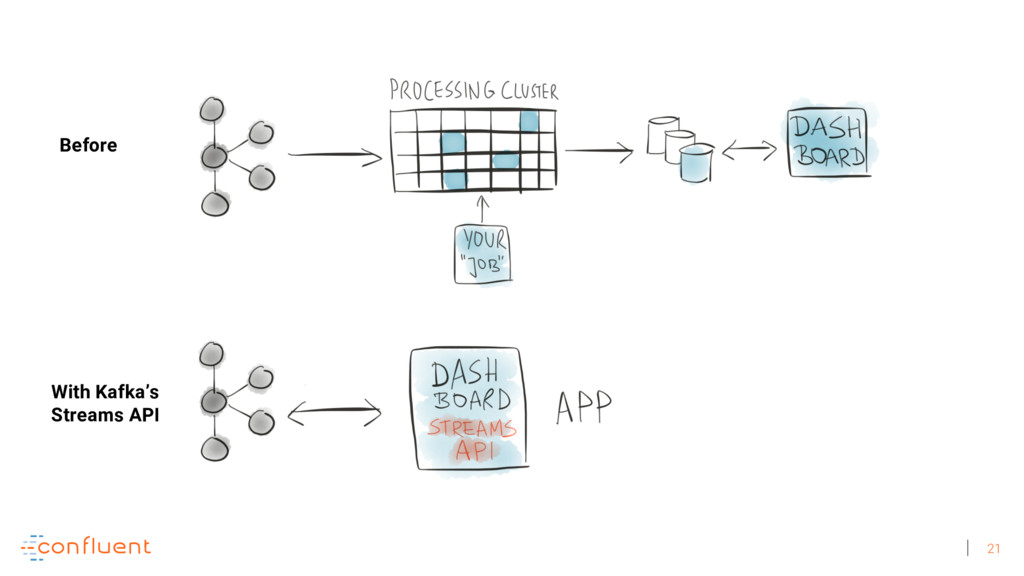
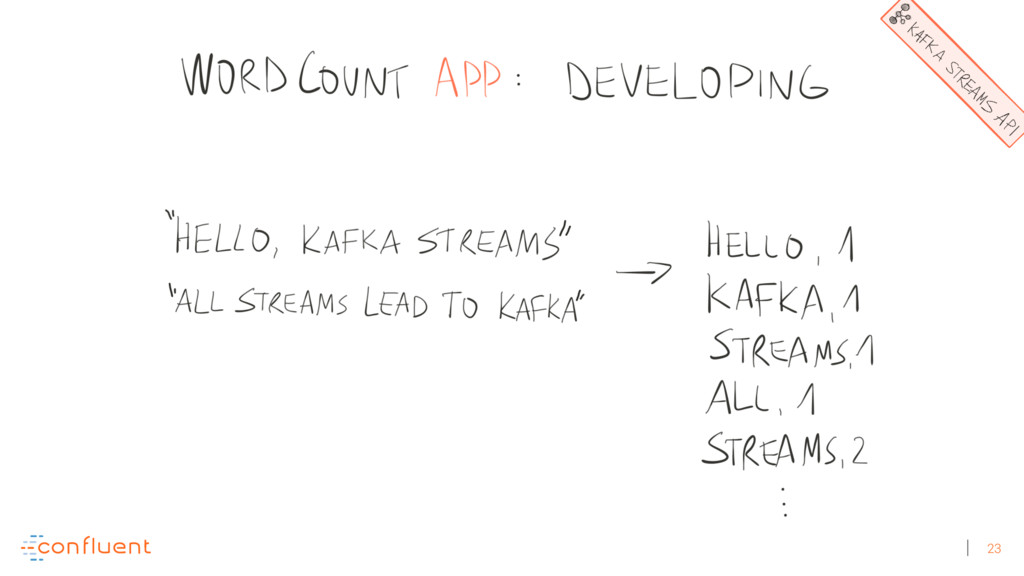
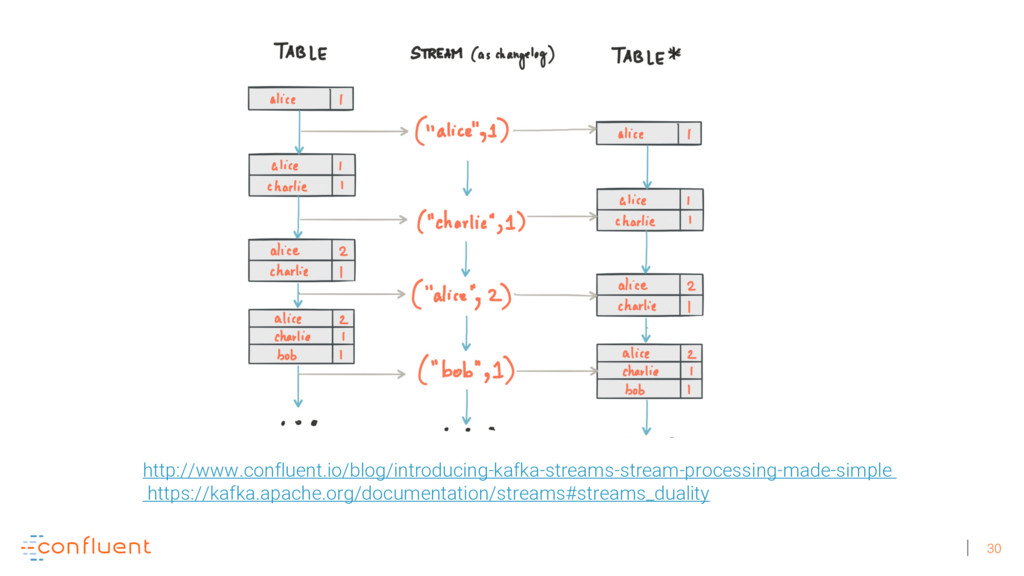
Michael Noll explains how Apache Kafka helps you radically simplify your data processing architectures by building normal applications to serve your real-time processing needs rather than building clusters or similar special-purpose infrastructure—while still benefiting from properties typically associated exclusively with cluster technologies, like high scalability, distributed computing, and fault tolerance. Michael also covers Kafka’s Streams API, its abstractions for streams and tables, and its recently introduced interactive queries functionality. Along the way, Michael shares common use cases that demonstrate that stream processing in practice often requires database-like functionality and how Kafka allows you to bridge the worlds of streams and databases when implementing your own core business applications (for example, in the form of event-driven, containerized microservices). As you’ll see, Kafka makes such architectures equally viable for small-, medium-, and large-scale use cases.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
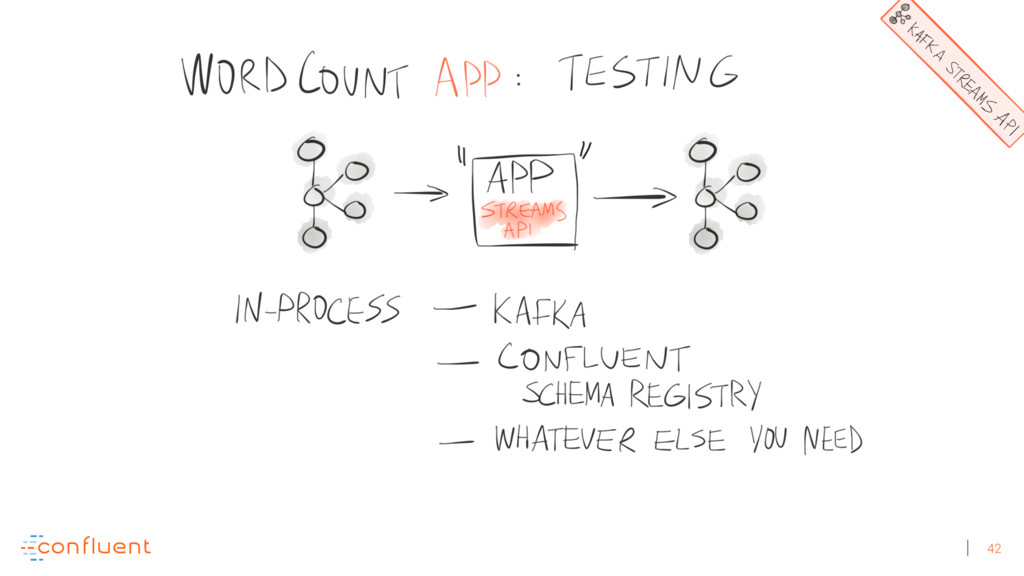{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
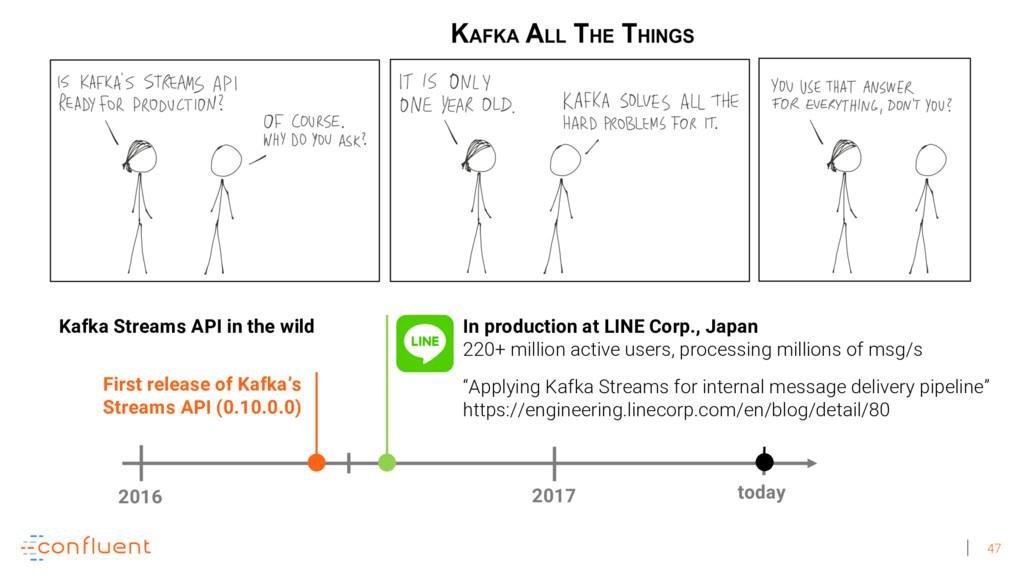{kind=link}
{kind=link}
{kind=link}
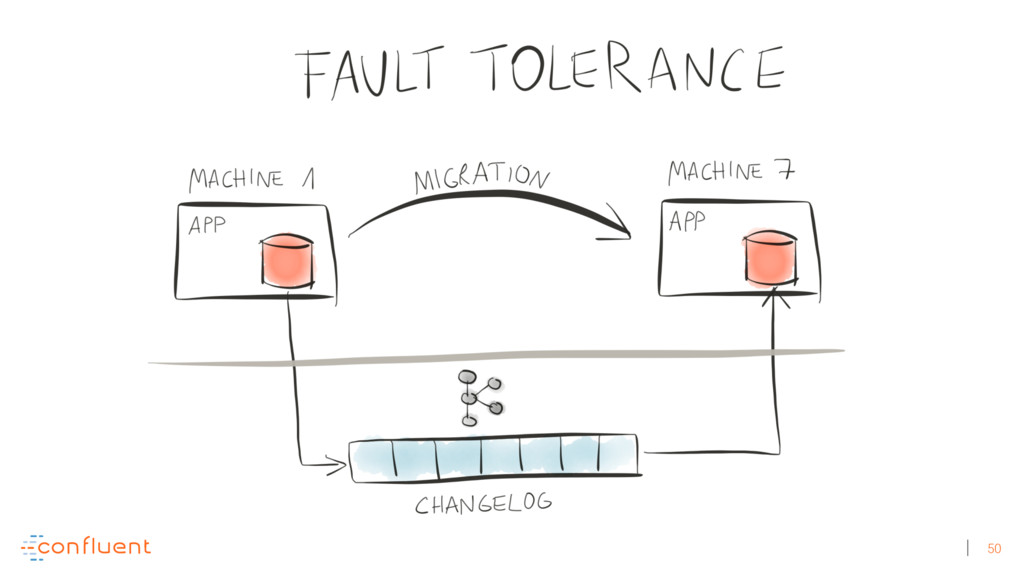{kind=link}
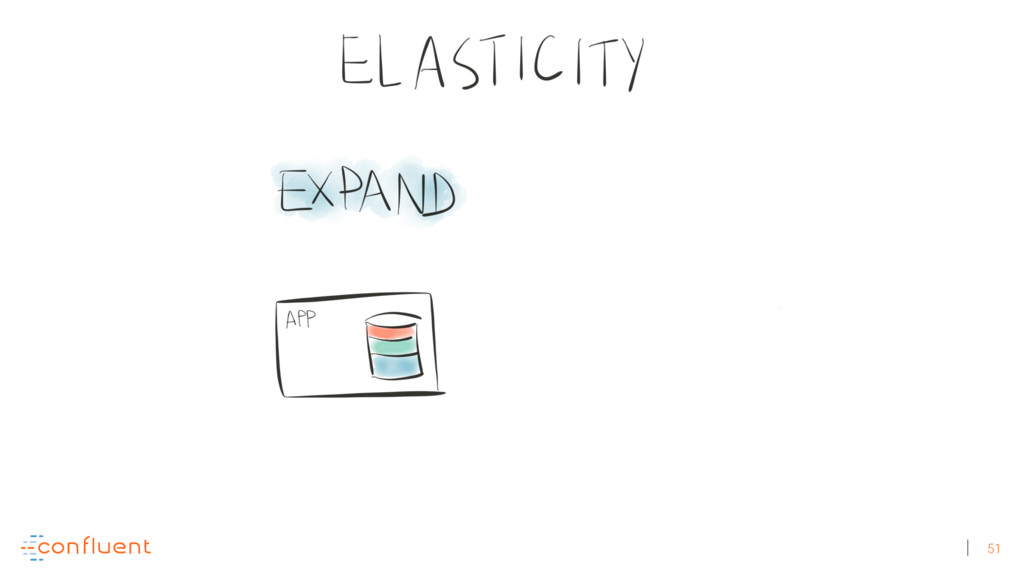{kind=link}
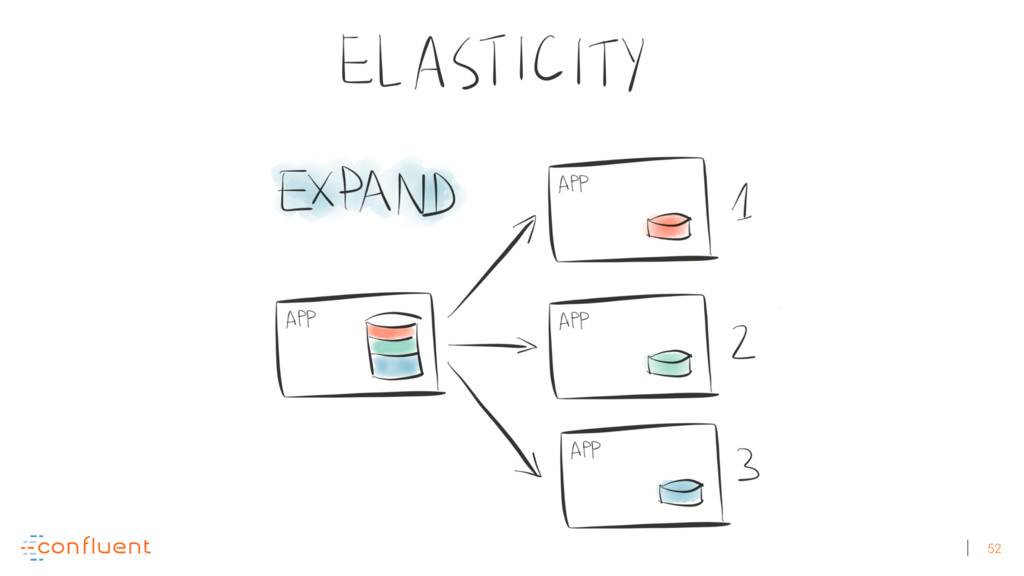{kind=link}
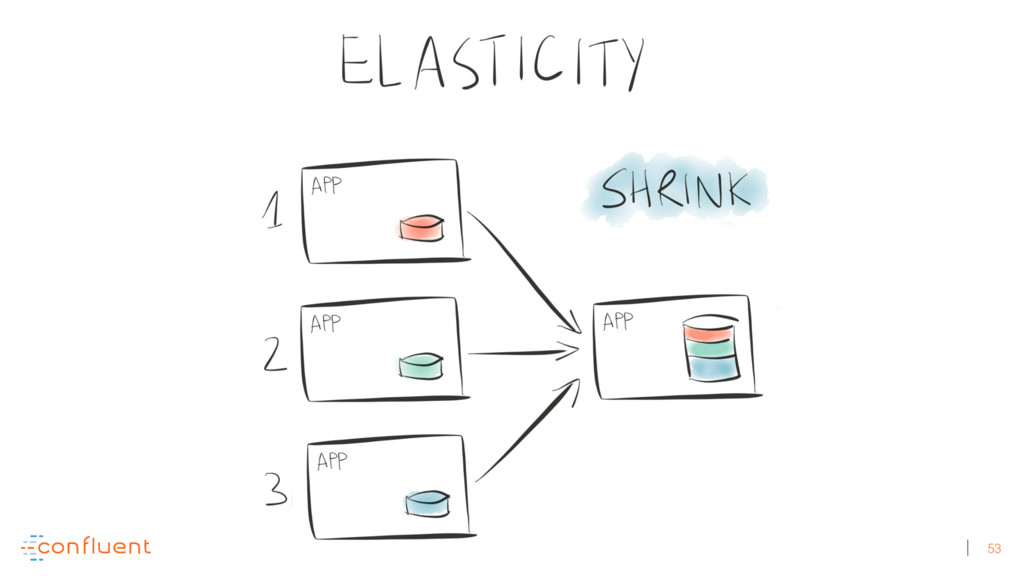{kind=link}
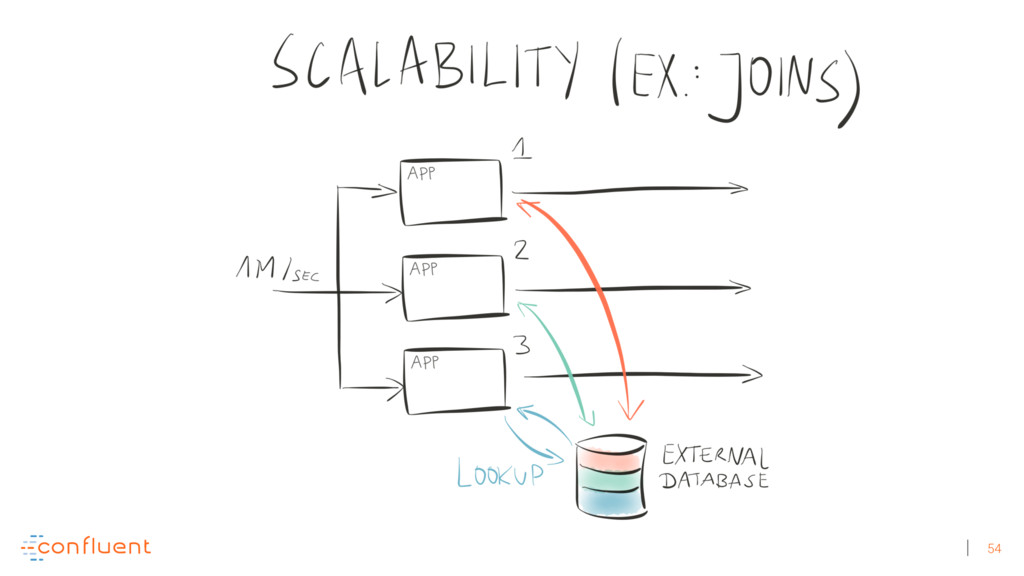{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}