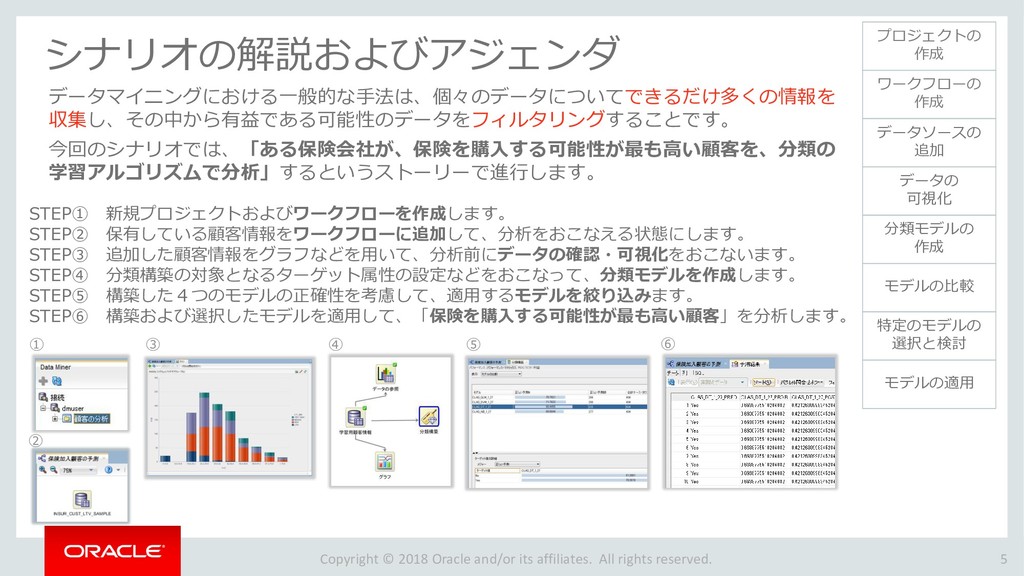
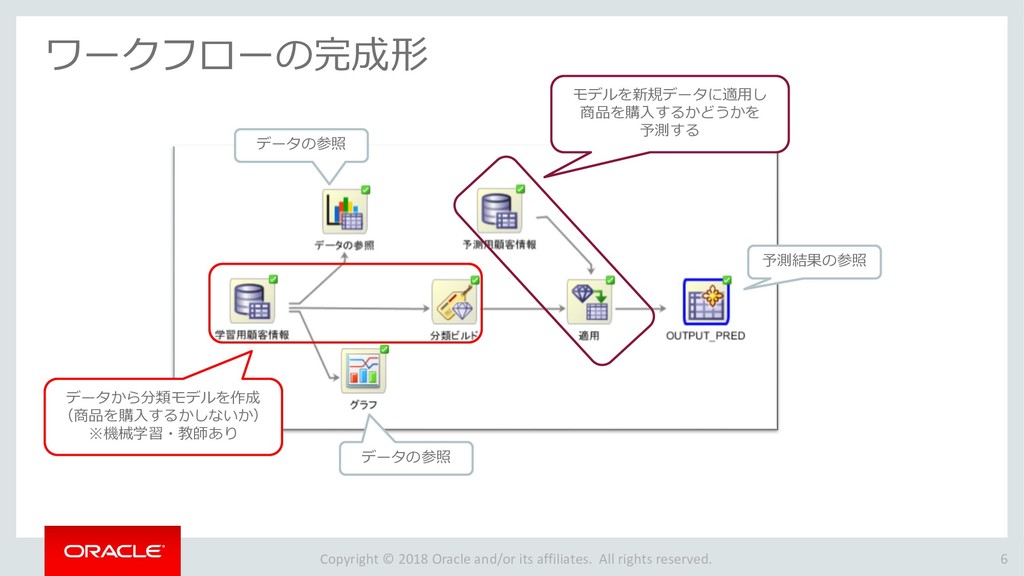
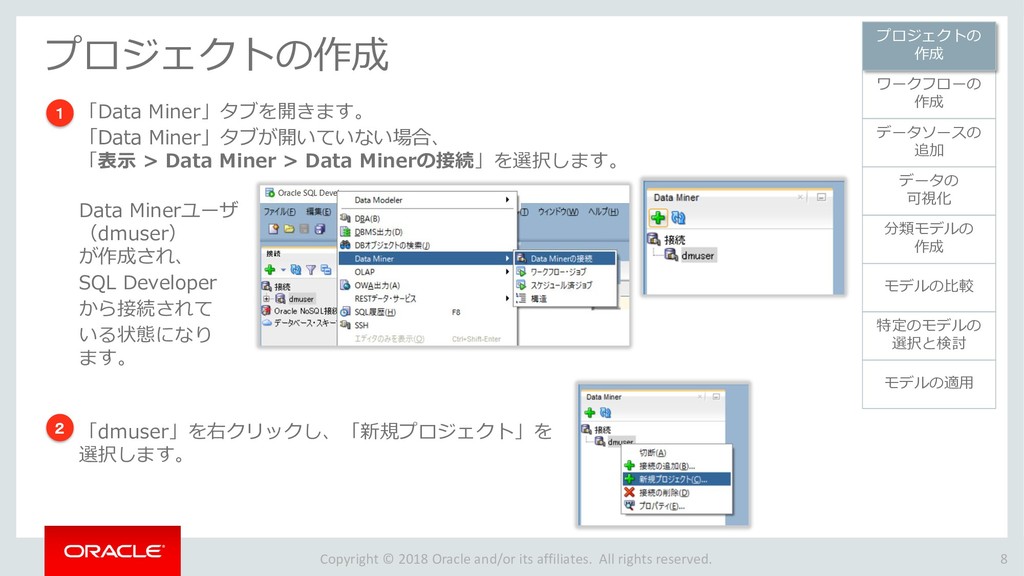
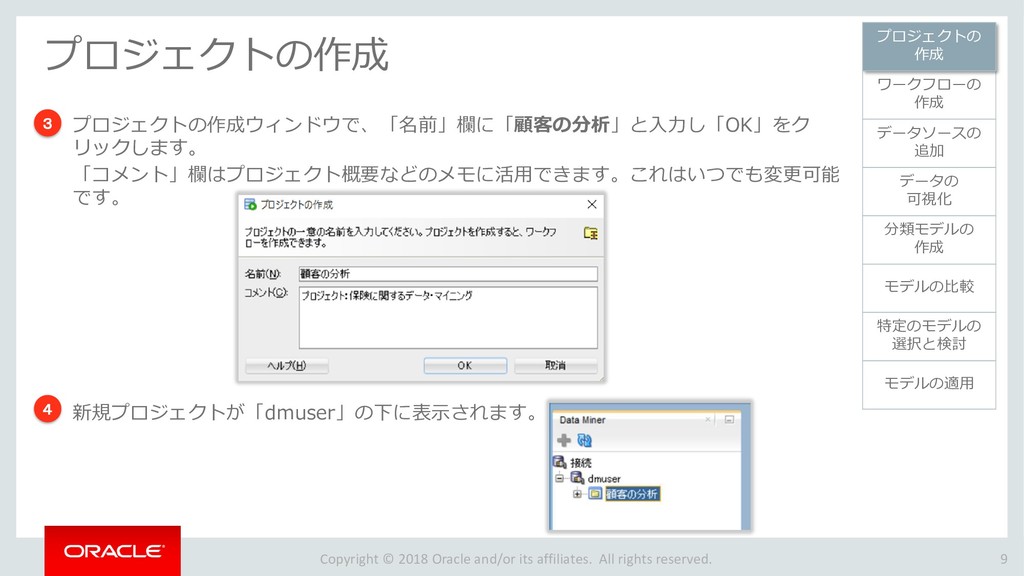
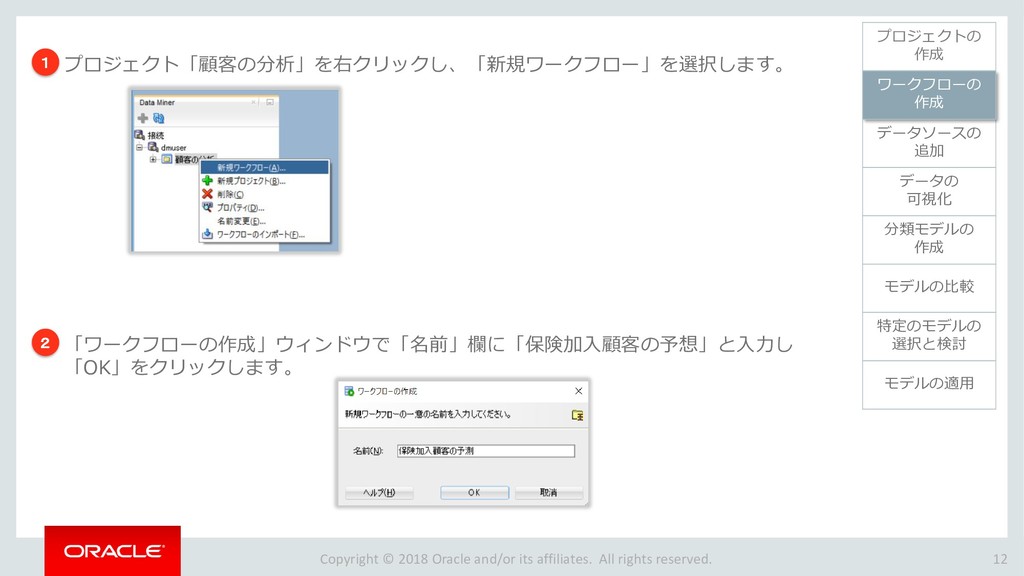
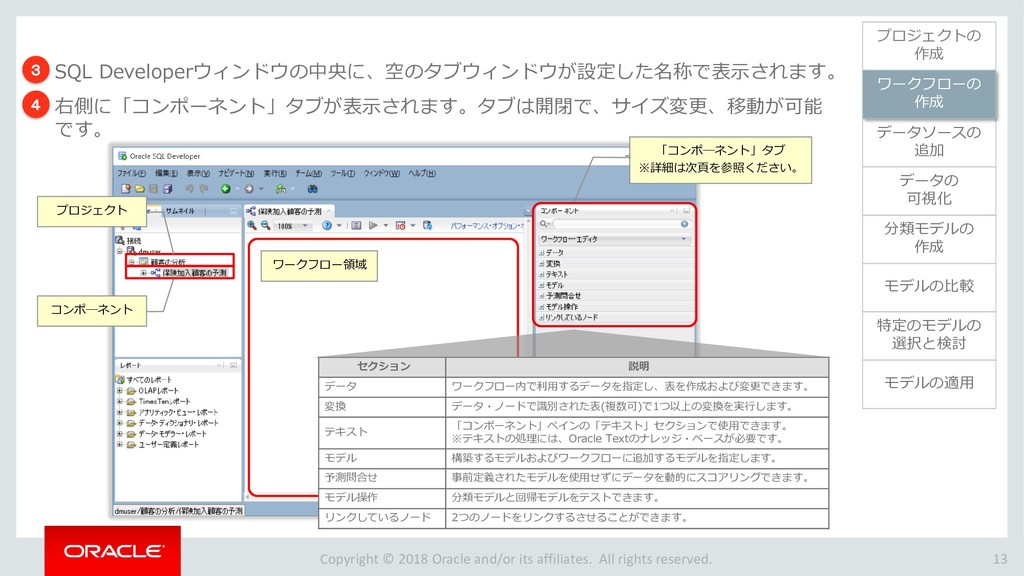
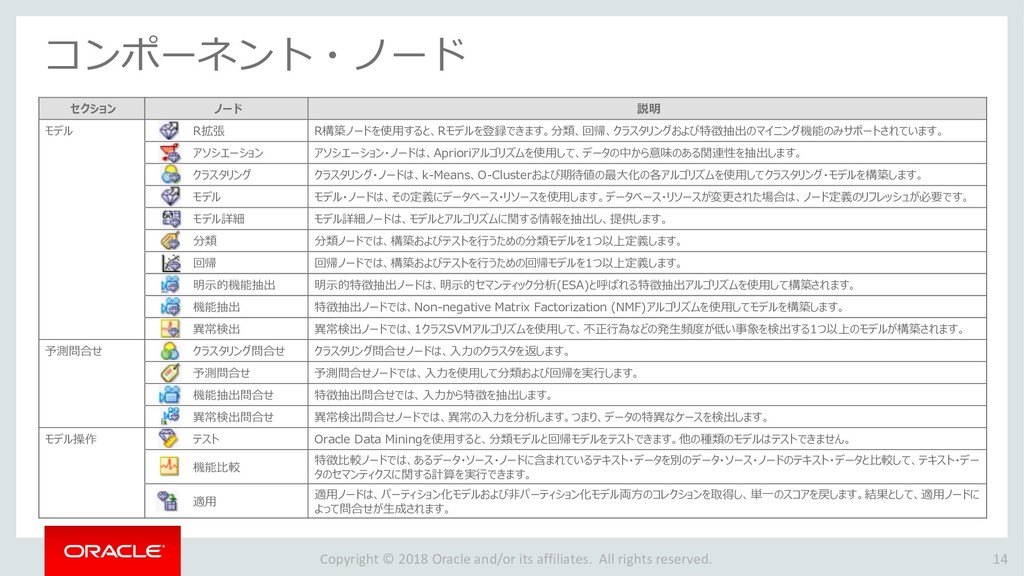
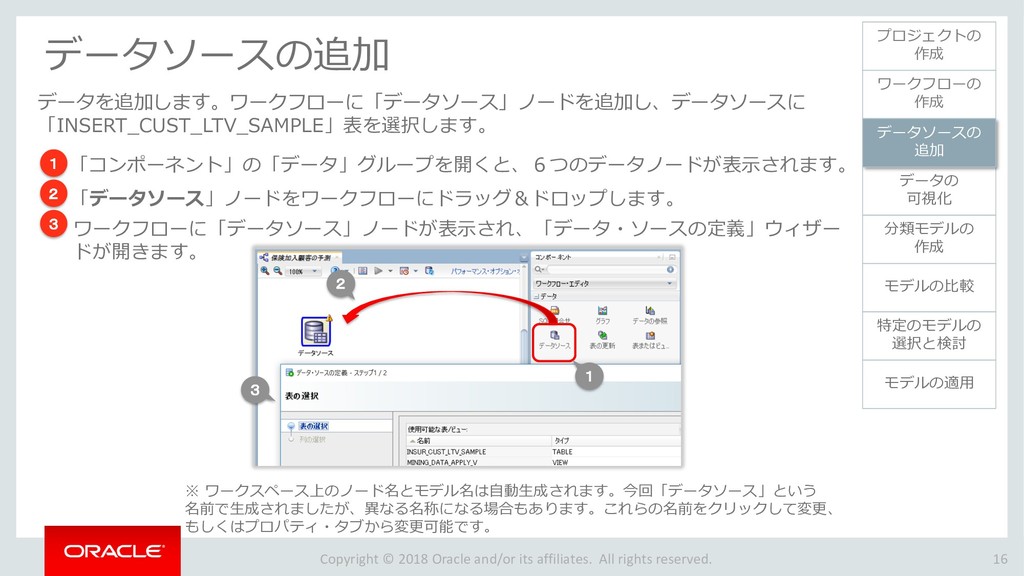
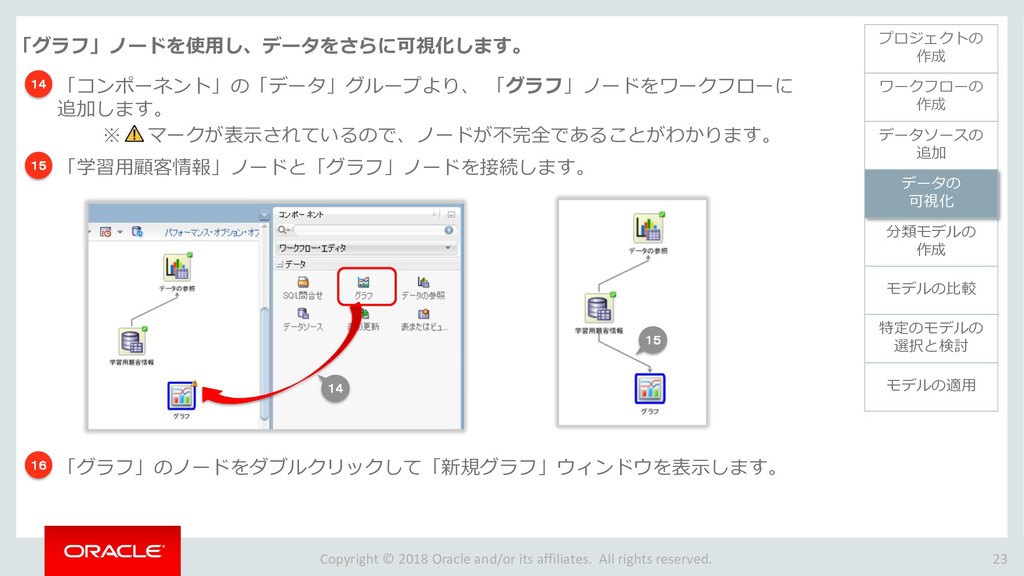
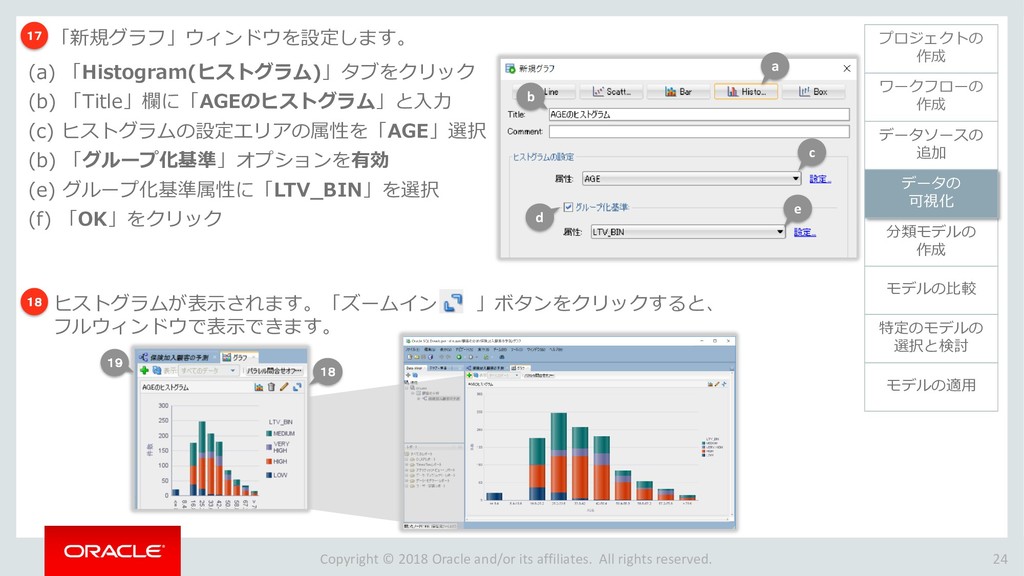
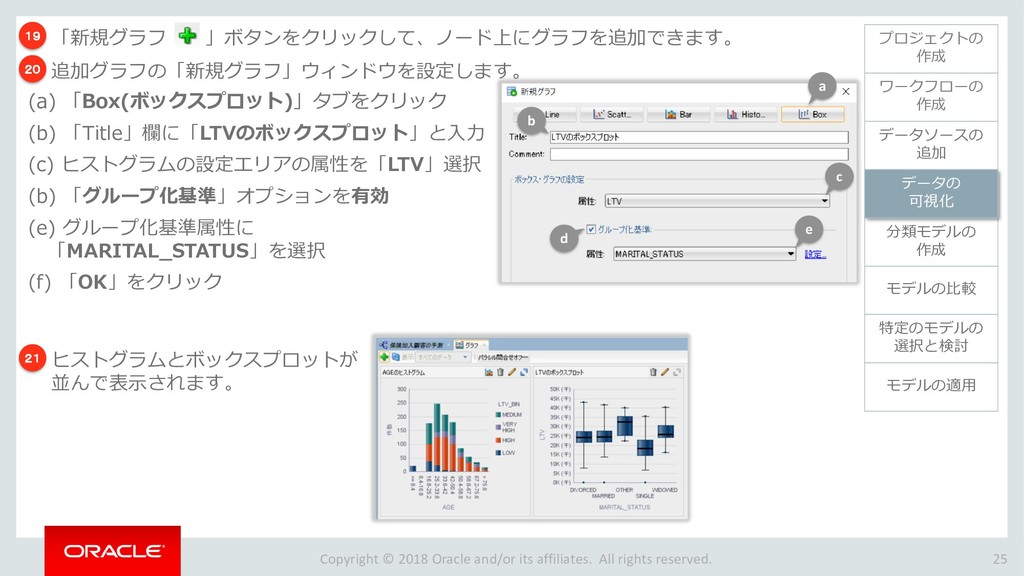
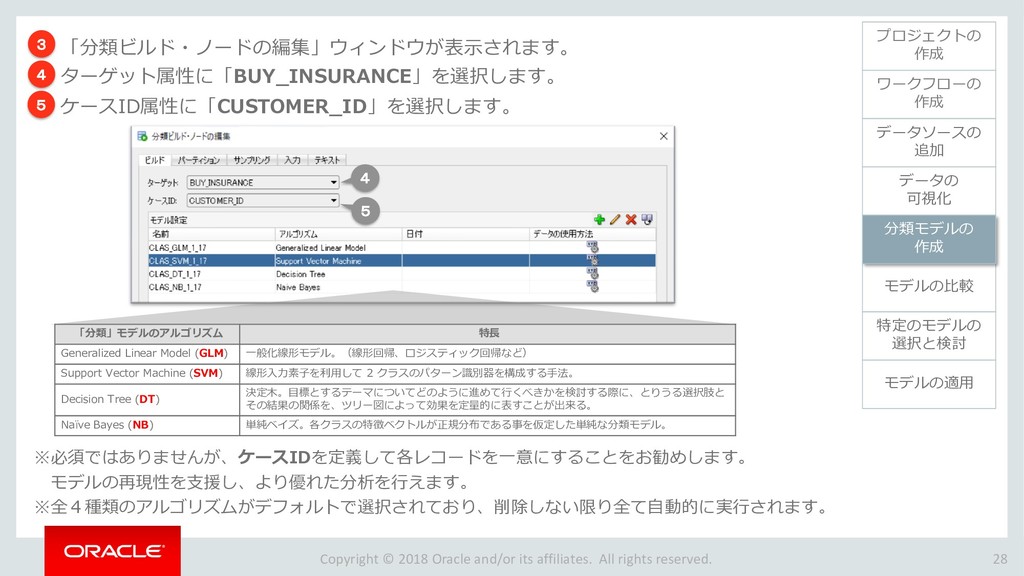
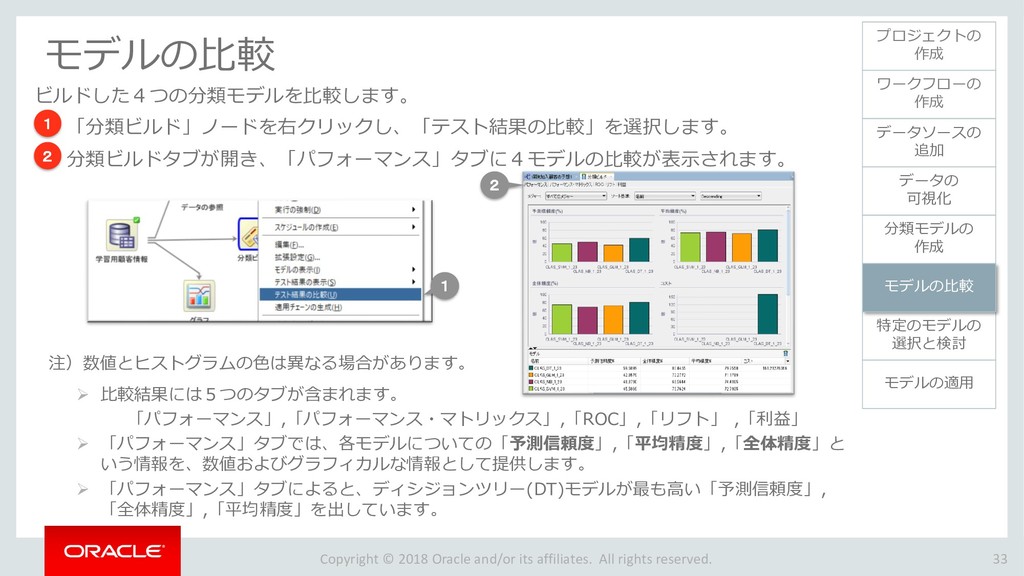
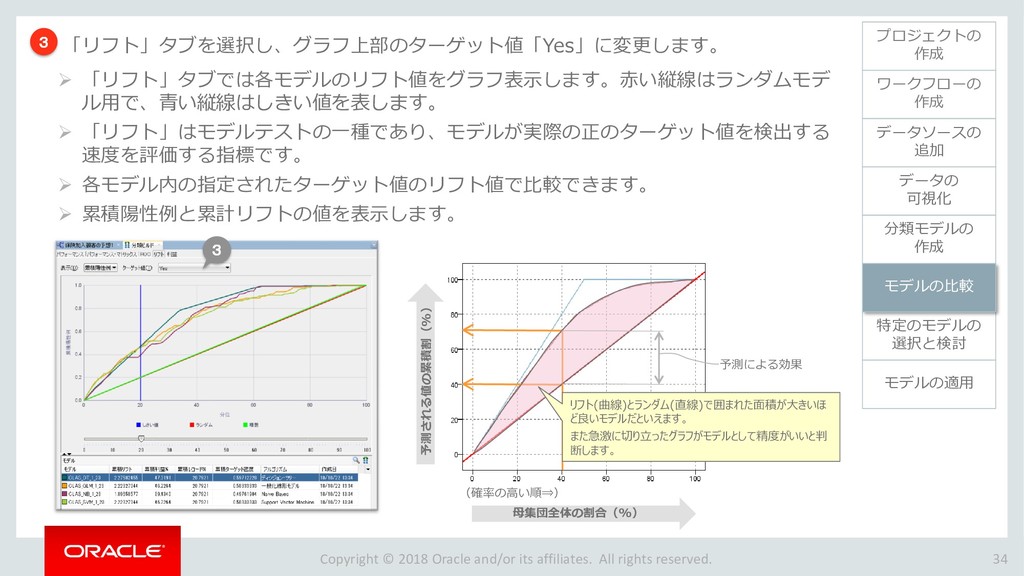
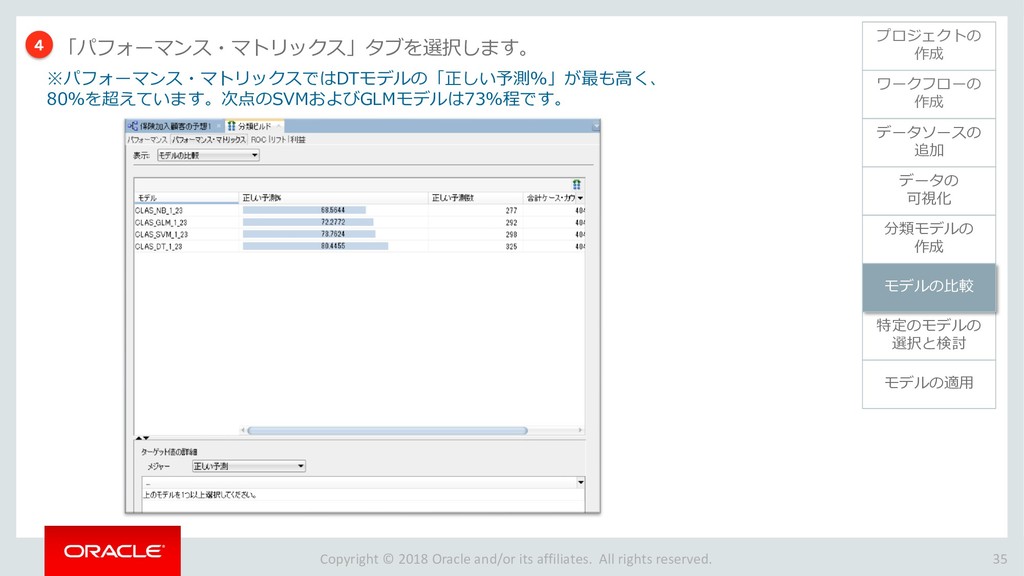
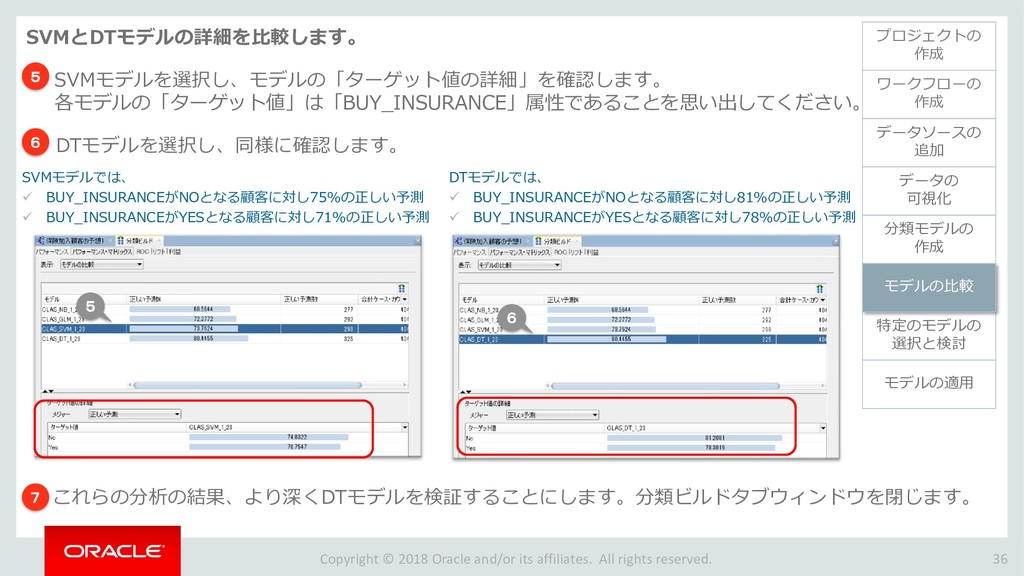
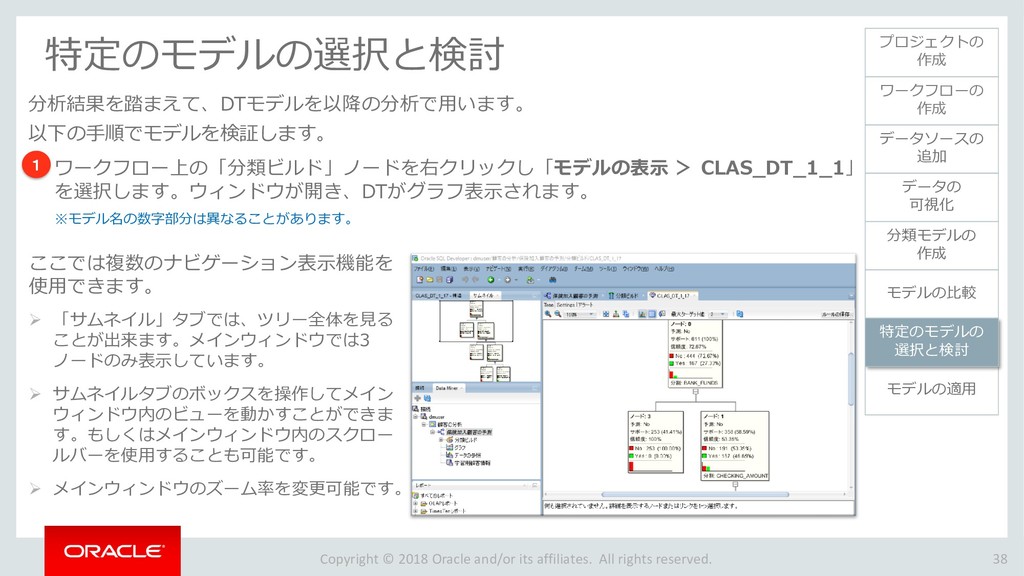
モデルの比較 33 ワークフローの 作成 データソースの 追加 データの 可視化 分類モデルの 作成 特定のモデルの 選択と検討 モデルの適用 プロジェクトの 作成 モデルの比較 ビルドした4つの分類モデルを比較します。 「分類ビルド」ノードを右クリックし、「テスト結果の比較」を選択します。 1 分類ビルドタブが開き、「パフォーマンス」タブに4モデルの比較が表示されます。 2 注)数値とヒストグラムの色は異なる場合があります。 ➢ 比較結果には5つのタブが含まれます。 「パフォーマンス」,「パフォーマンス・マトリックス」,「ROC」,「リフト」 ,「利益」 ➢ 「パフォーマンス」タブでは、各モデルについての「予測信頼度」,「平均精度」,「全体精度」と いう情報を、数値およびグラフィカルな情報として提供します。 ➢ 「パフォーマンス」タブによると、ディシジョンツリー(DT)モデルが最も高い「予測信頼度」, 「全体精度」,「平均精度」を出しています。 1 2
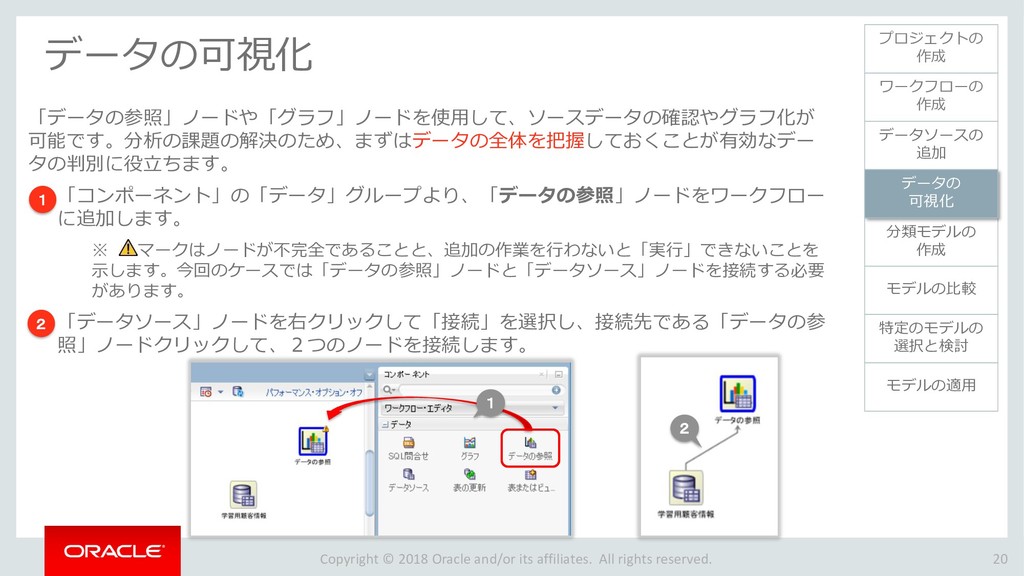
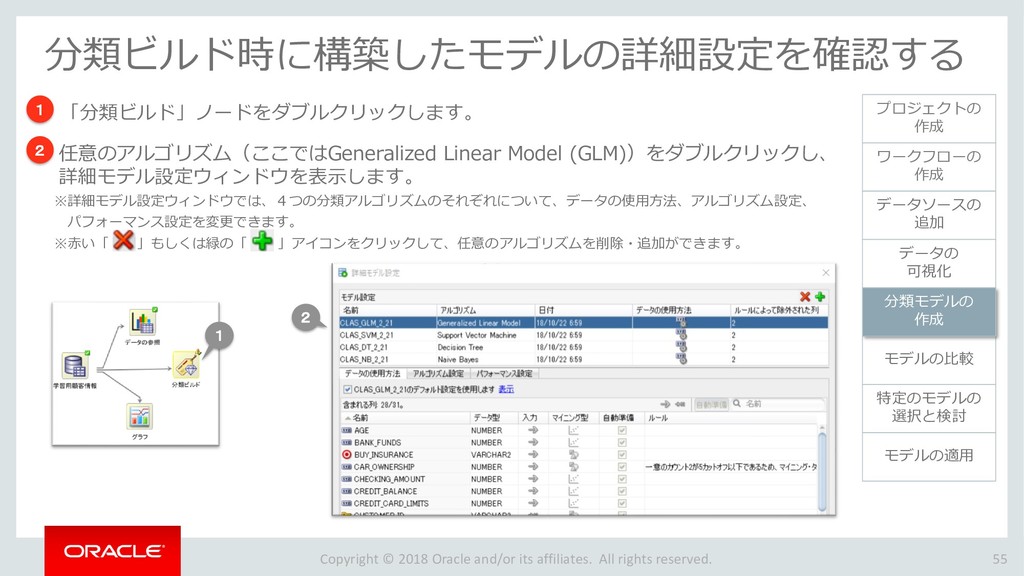
{kind=link}
{kind=link}
{kind=link}
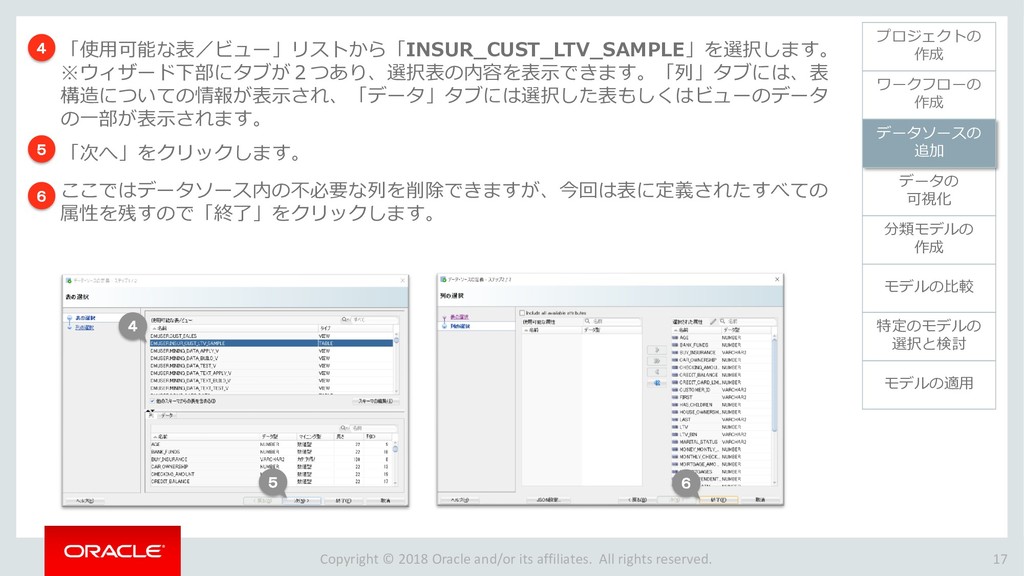
{kind=link}
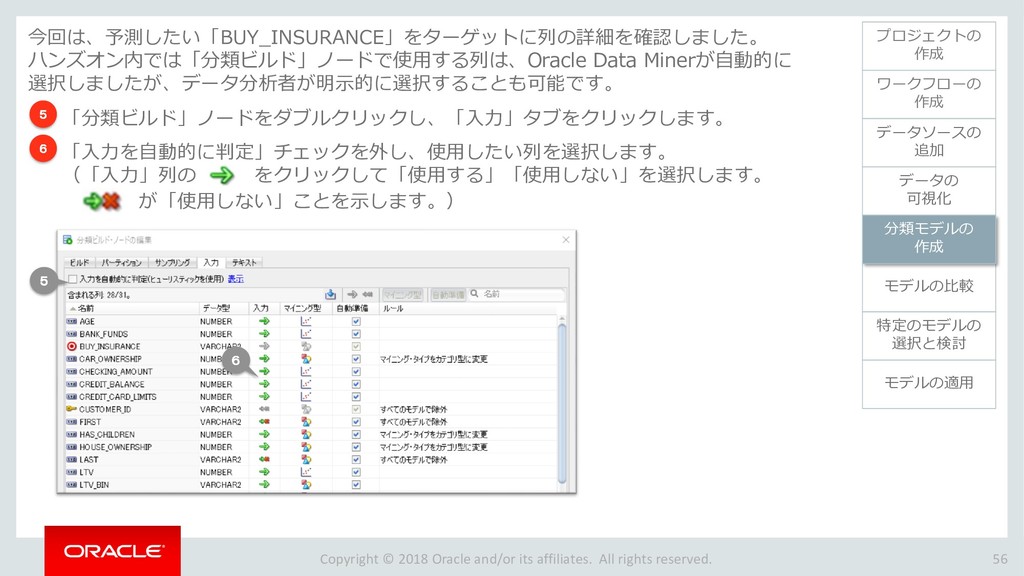
{kind=link}
{kind=link}
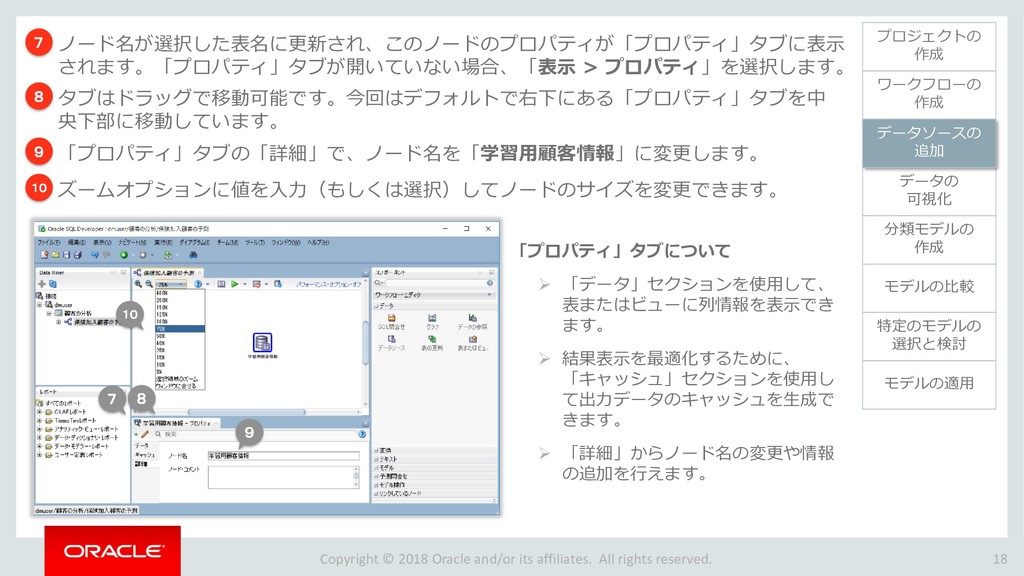
{kind=link}
{kind=link}
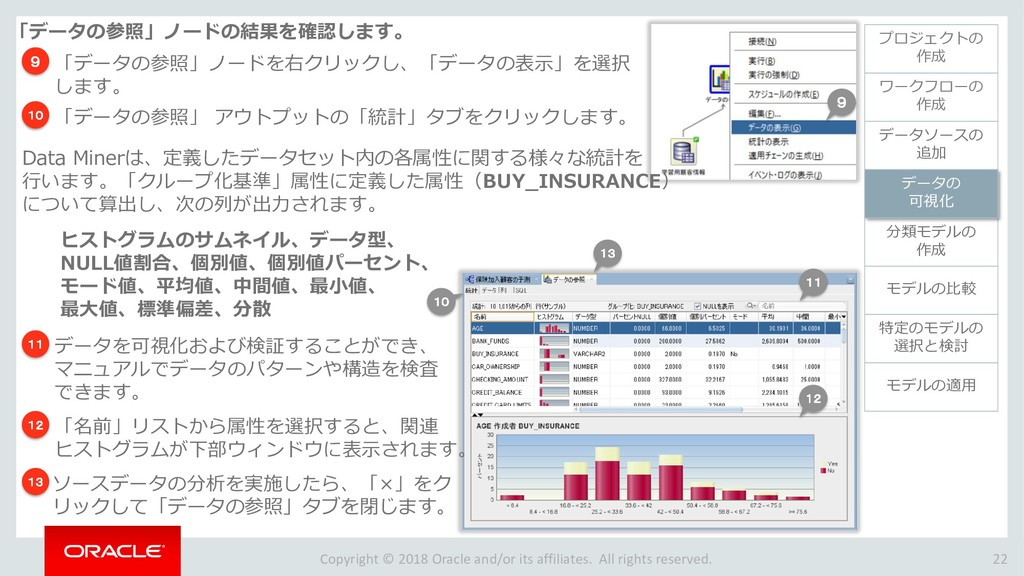
{kind=link}
{kind=link}
{kind=link}
{kind=link}
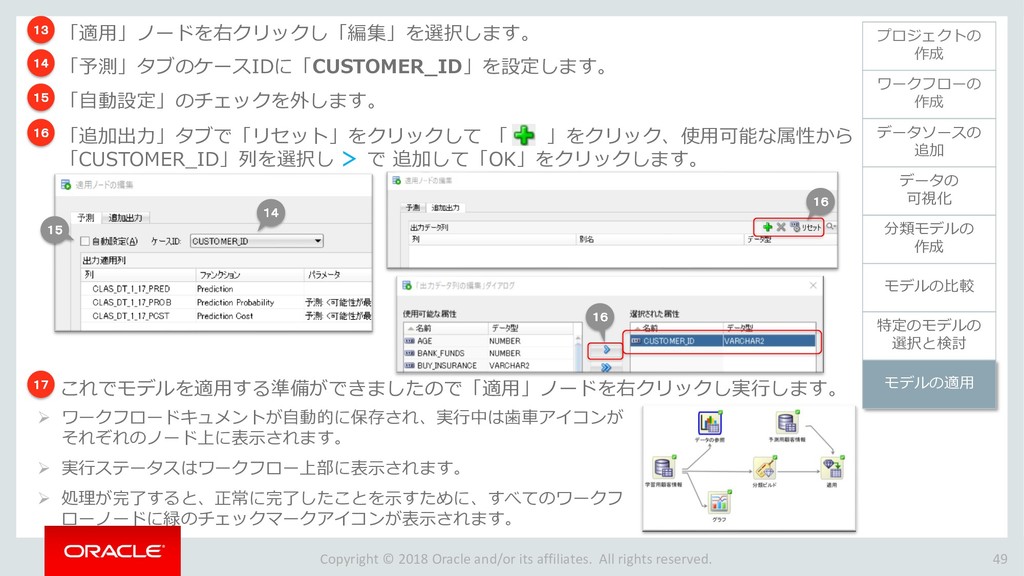
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
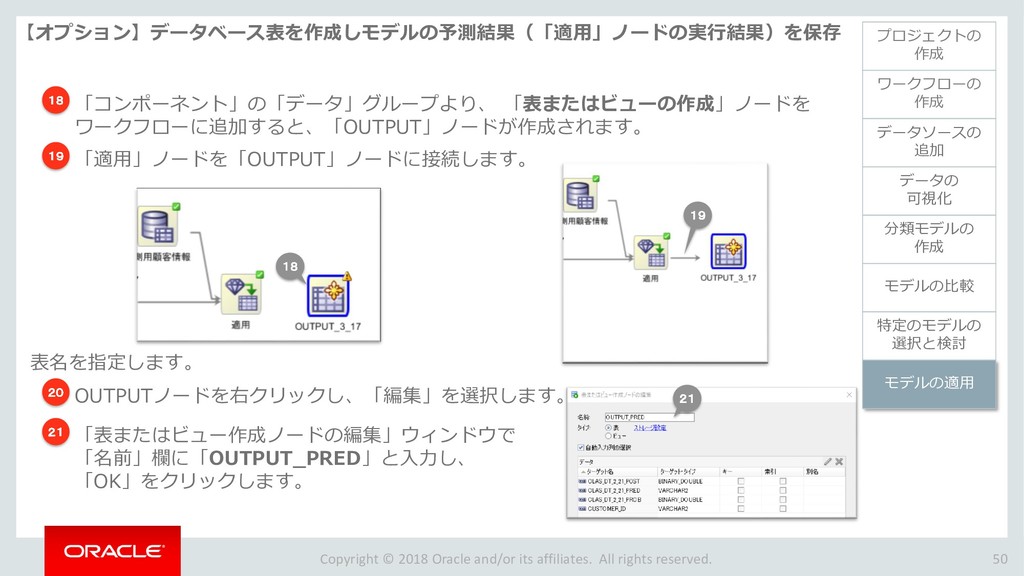
{kind=link}
{kind=link}
{kind=link}
{kind=link}
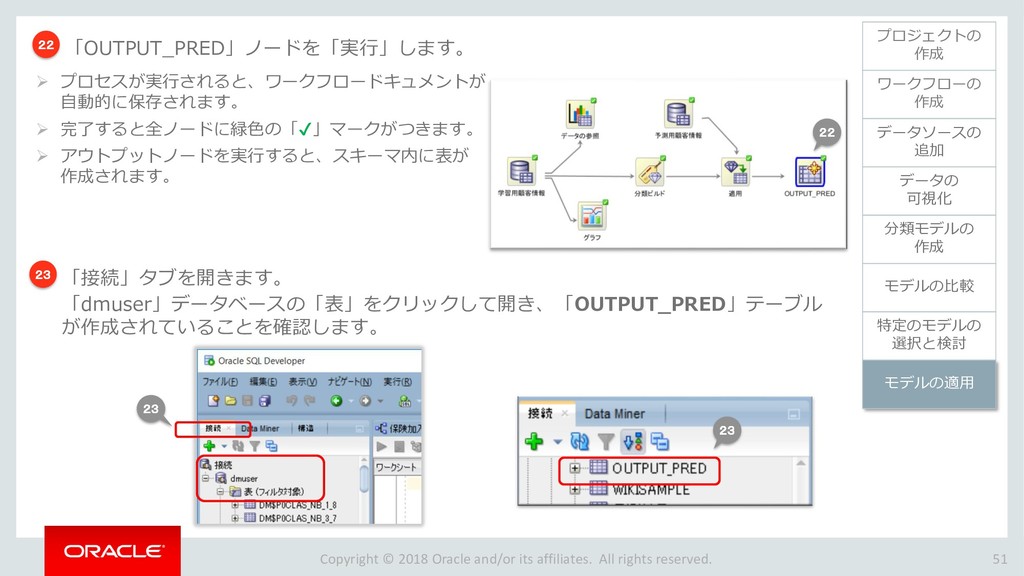
{kind=link}
{kind=link}
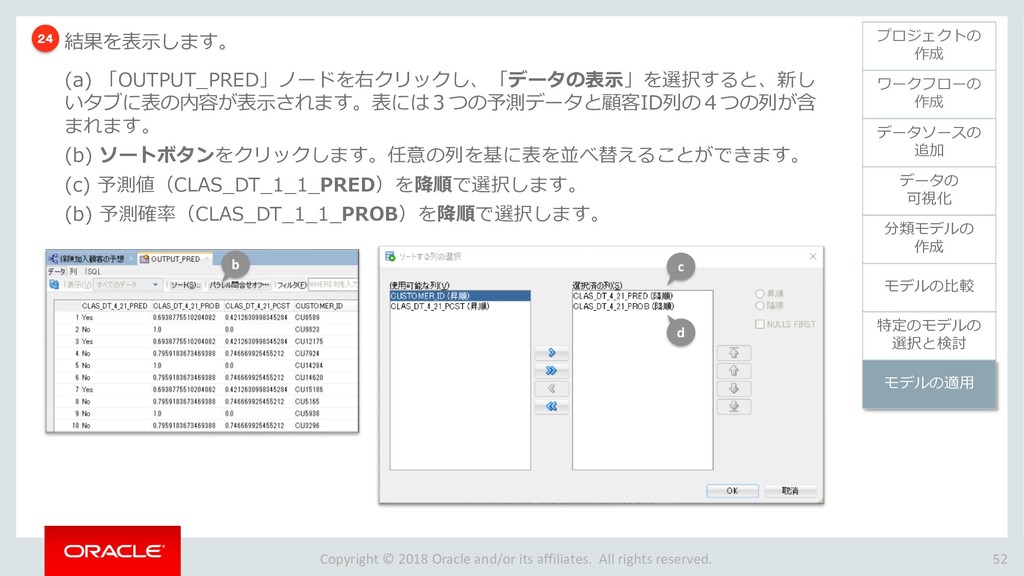
{kind=link}
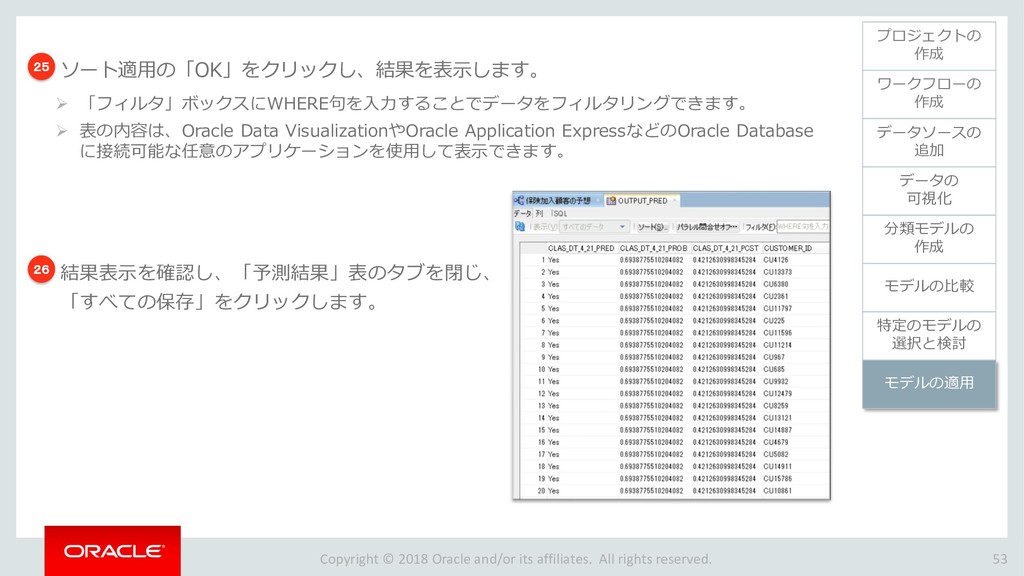
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
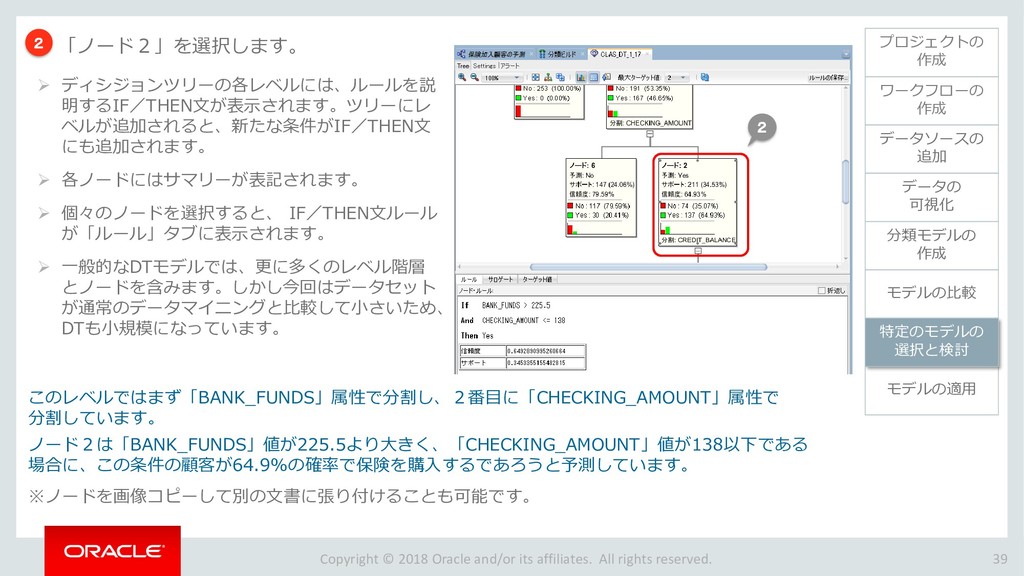{kind=link}
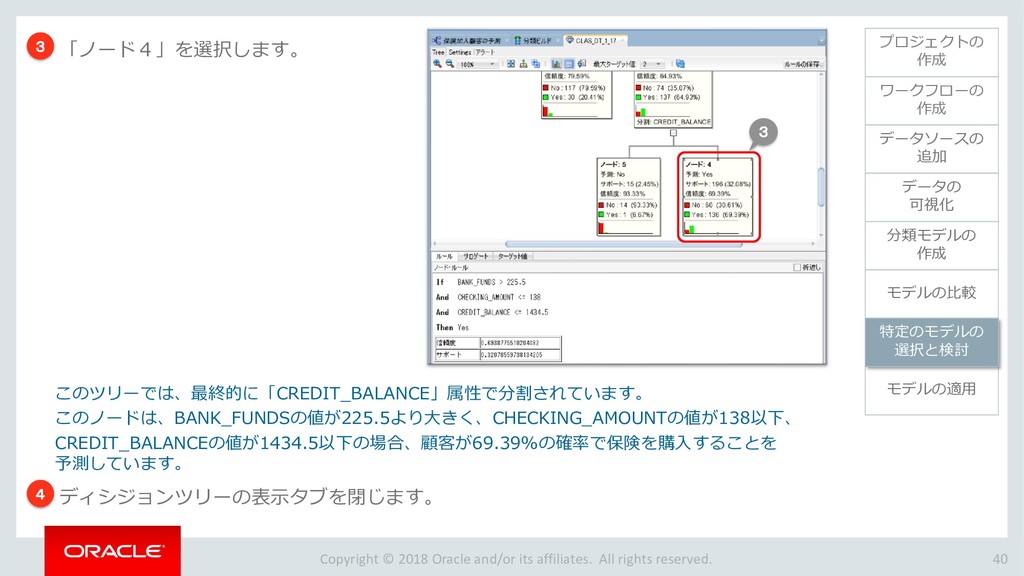{kind=link}
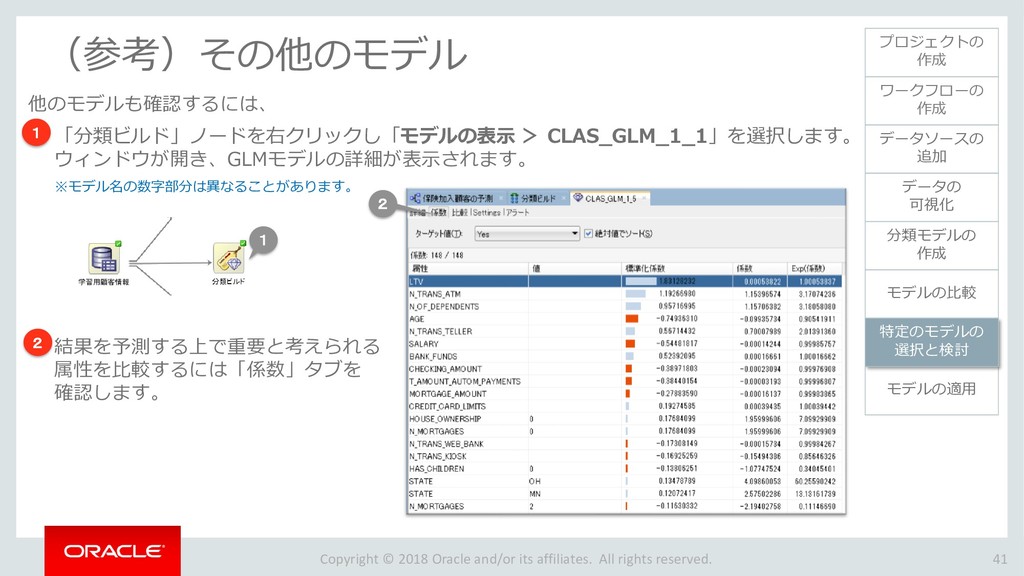{kind=link}
{kind=link}
{kind=link}
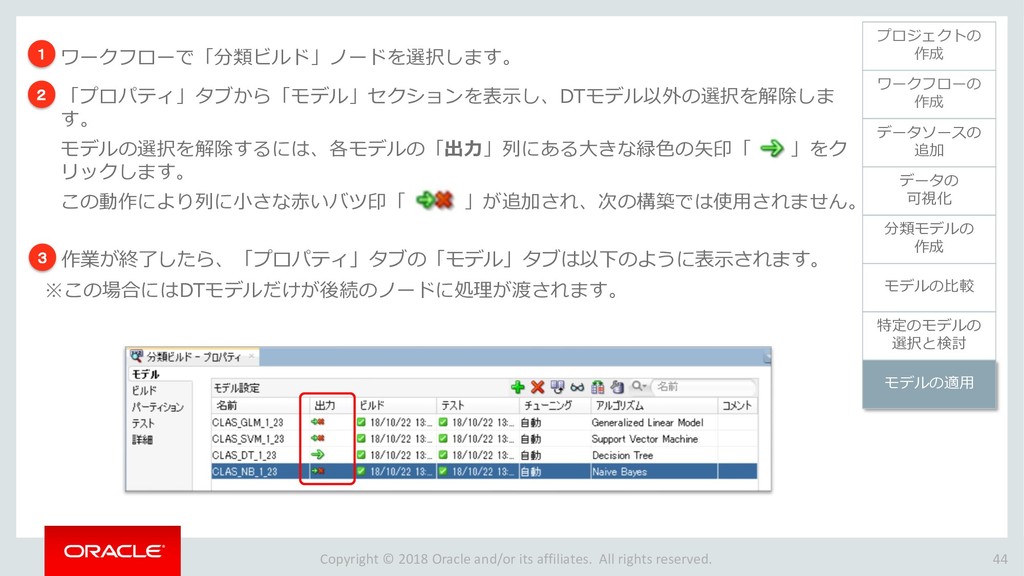{kind=link}
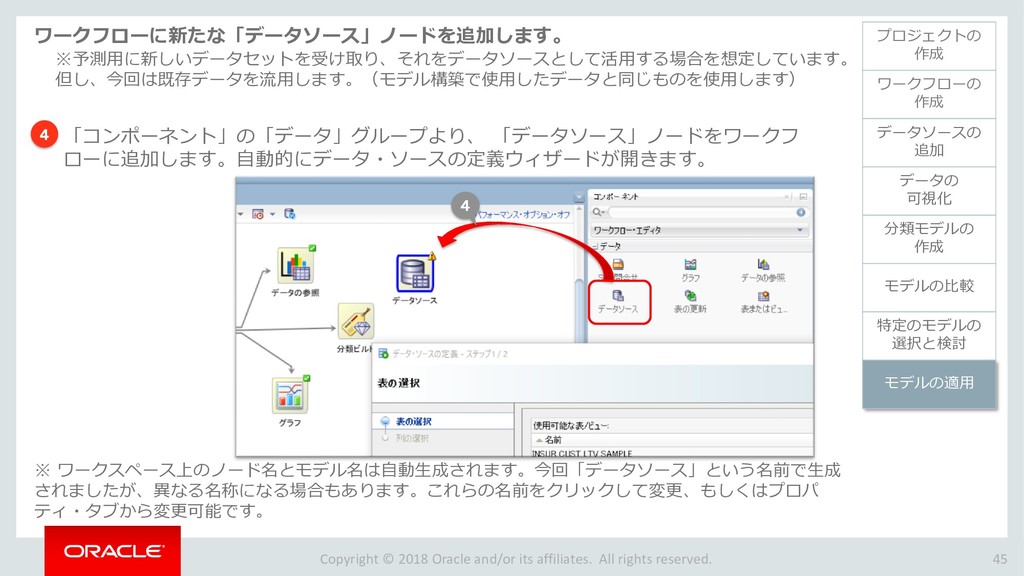{kind=link}
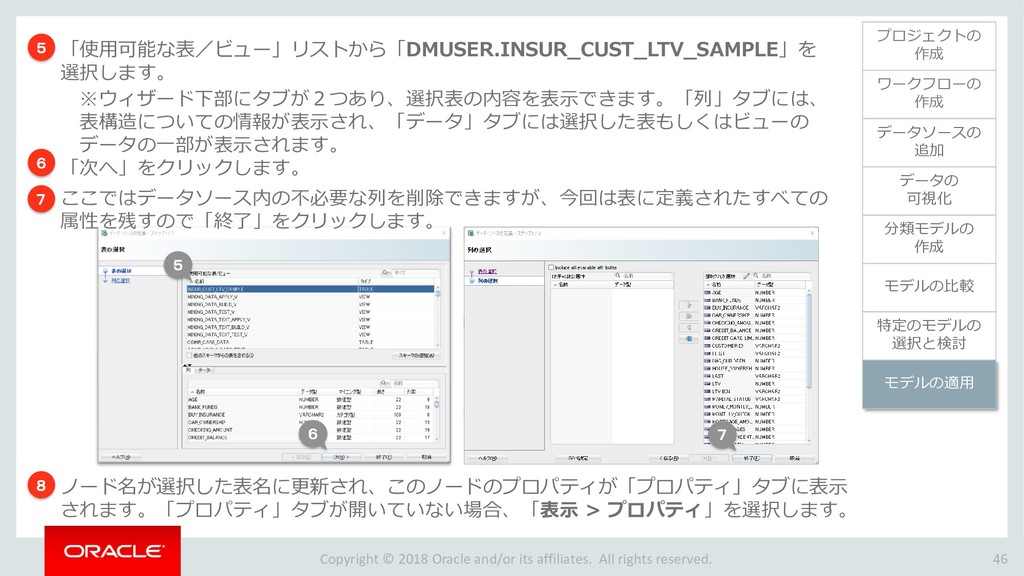{kind=link}
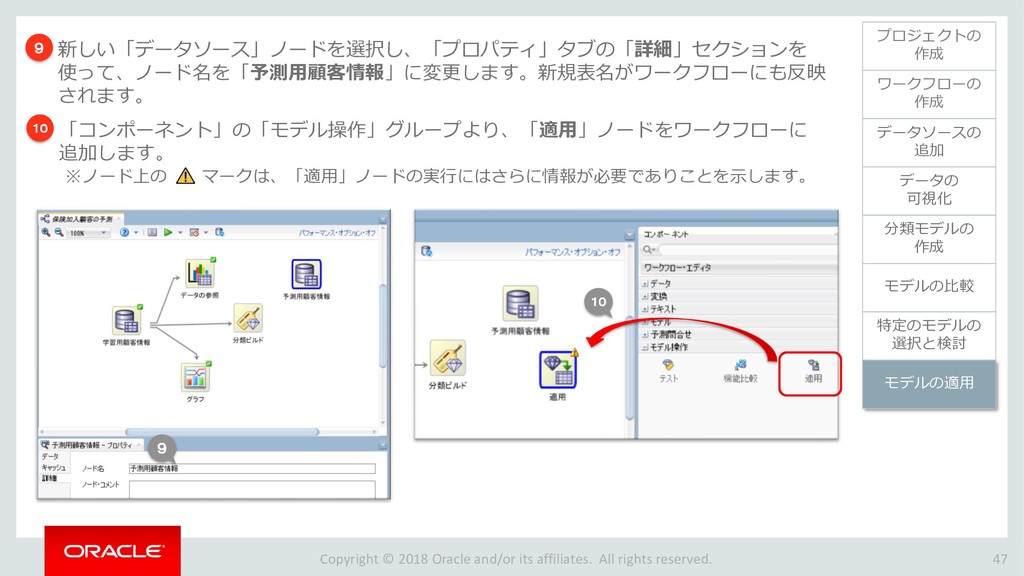{kind=link}
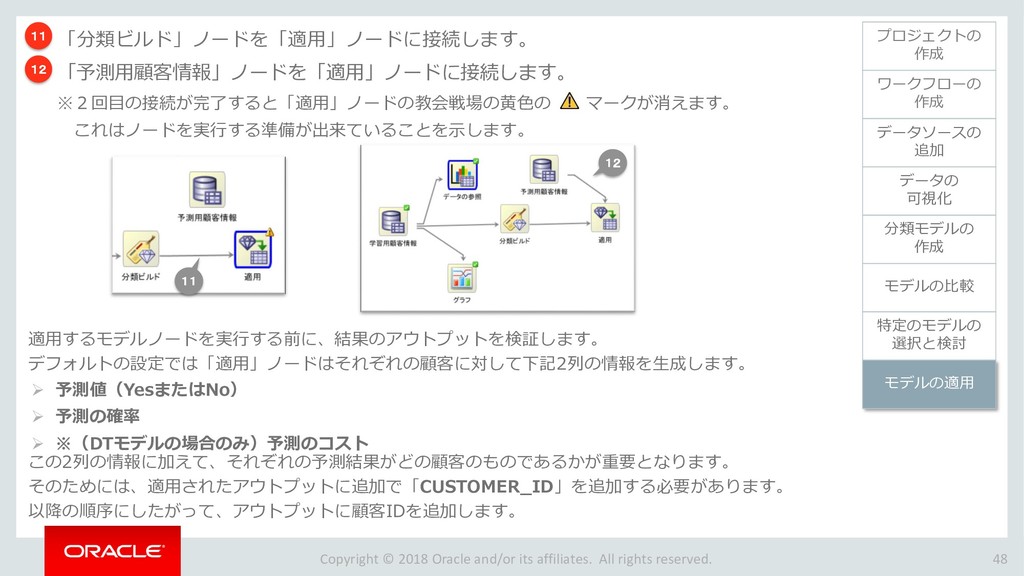{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}