Understanding how a database works allows you to use it more efficiently, and it's even more true when it comes to NOSQL databases. Let's see how Cassandra handle read and write requests on a ring and how compactions have an impact on requests.
Write requests concern ONE partition key ❖ Read requests mainly concern ONE partition key ❖ You (almost) can’t filter on other columns ❖ No joins, no constraints …
❖ A “table” is called a ColumnFamily (with cql3 we usually use the term table) ❖ Two primary keys : ❖ the Partition Key (let’s consider only this one for now) The only way to access your data ❖ the Cluster Key (we’ll talk about it later) ❖ A ColumnFamily contains a list of Rows ❖ A Row contains a list of Columns ❖ In other terms : Map<String,Map<String,?>>
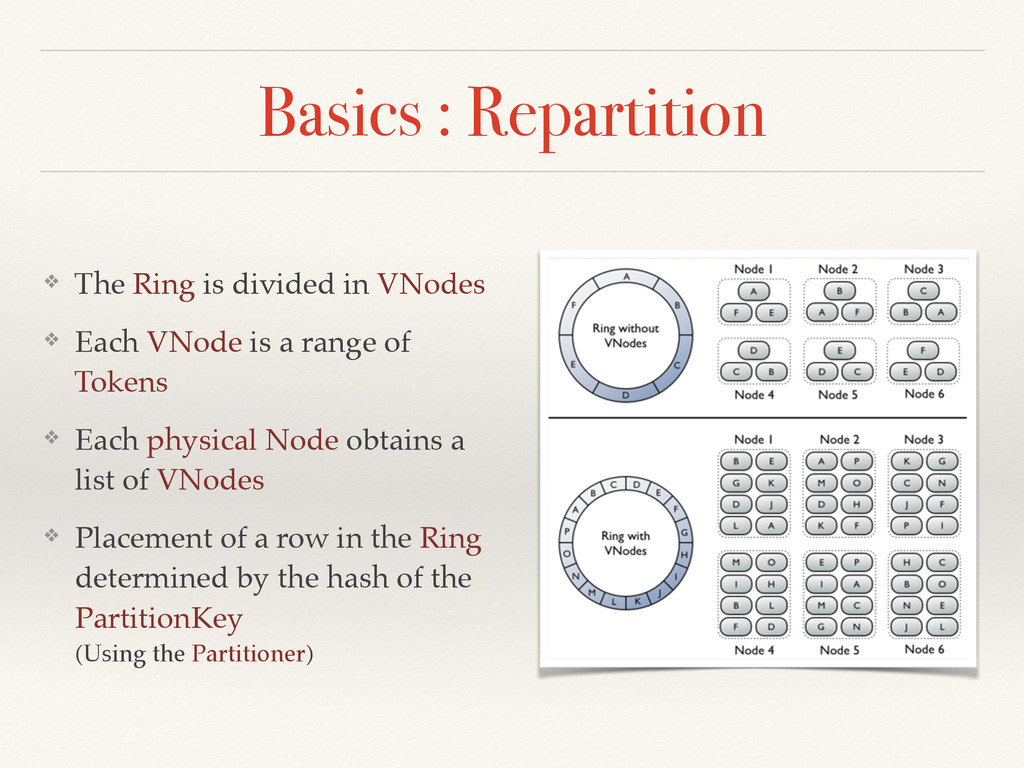
❖ Each VNode is a range of Tokens ❖ Each physical Node obtains a list of VNodes ❖ Placement of a row in the Ring determined by the hash of the PartitionKey (Using the Partitioner)
is defined per Keyspace ❖ 3 replication strategies : Local, Simple, NetworkTopology ❖ RF=3, the data are replicated on 3 nodes ❖ 4 nodes and RF=3, each node owns 75% CREATE KEYSPACE myKeyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor': ‘3'};
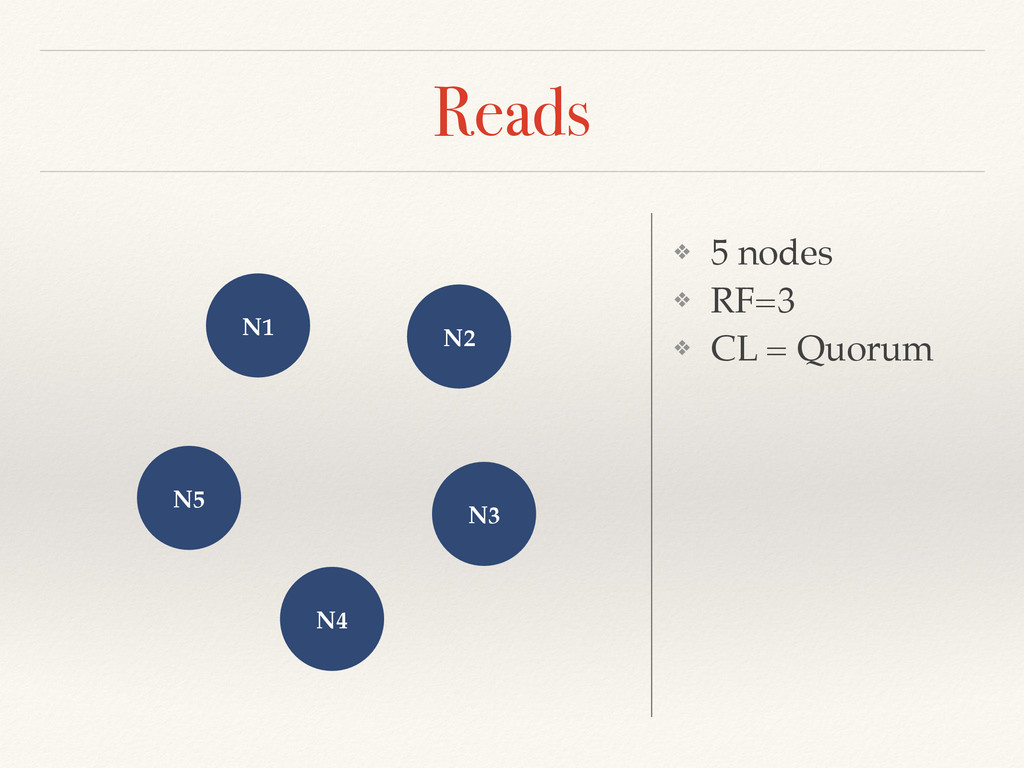
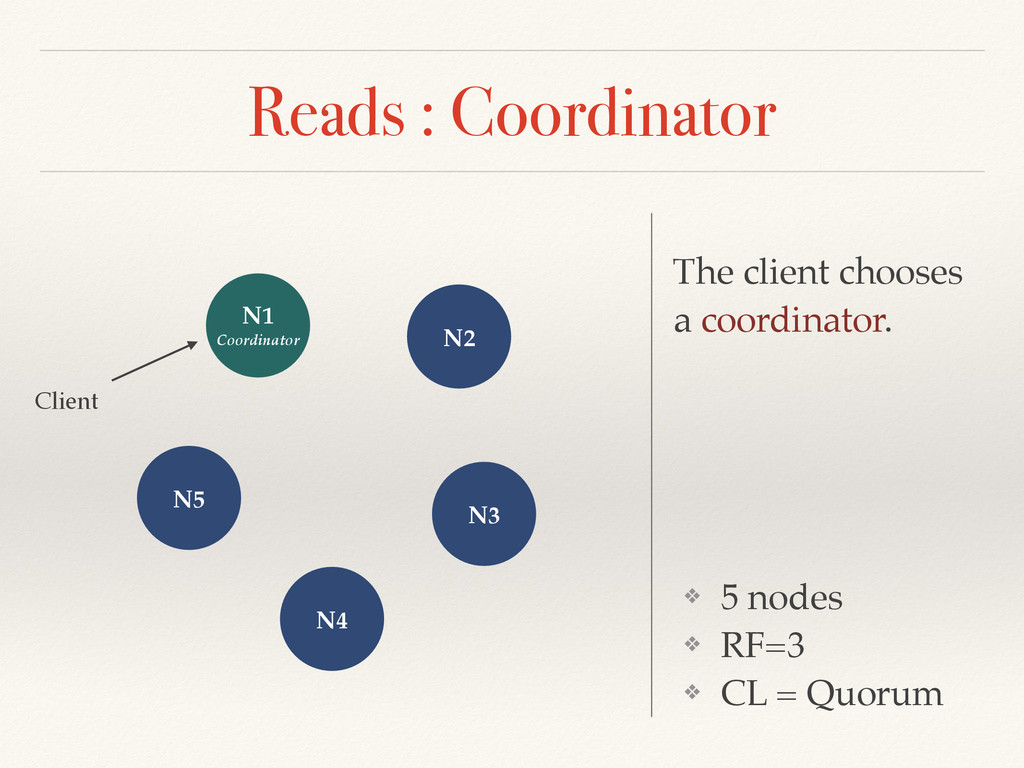
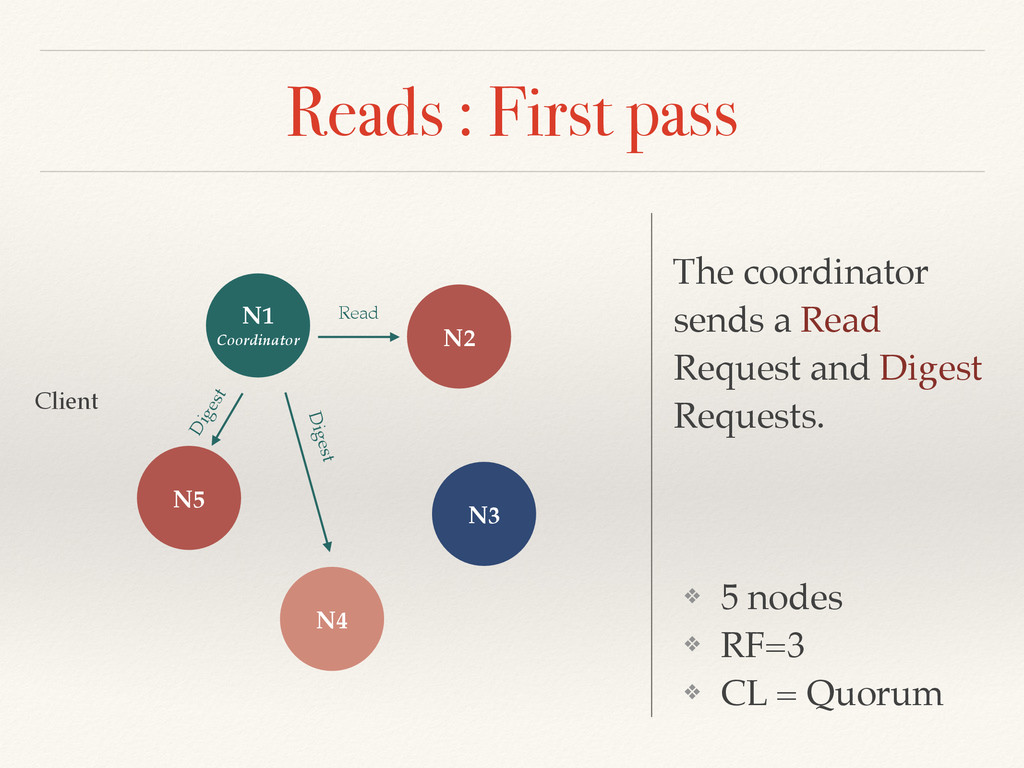
the CAP theorem) ❖ Cassandra offers a tunable Consistency (Tradeoff between consistency and latency) ❖ The Consistency Level is defined on each request ❖ Levels : Any (for writes only), One, Two, Three, All and Quorum = RF/2 + 1 ❖ RF=3 => 2 replicas involved in the query in Quorum
PartitionKey a set of records ❖ ClusterKey, part of the PrimaryKey ❖ CQL3 hides the wide row mechanism : you keep working on records. ❖ ClusterKey accepts Comparison operators (Unlike the PartitionKey that allows you only equality) ❖ ClusterKey accepts Ordering ❖ Huge number of rows (2 Billions)
in memory : Memtable ❖ In the mean time, the write is appended to the Commit log (durability) ❖ A timestamp is associated to each updated column ❖ The Memtable is flushed on the disk : SSTable ❖ Data is the Commit log is purged. During the Write Asynchronously When the contents exceed a threshold
by keys Sorted Strings Table ❖ Index File : ❖ (Key, offset) pairs ❖ Bloom Filter ❖ May contain only parts of the data of a CF or a key ❖ Concerns one ColumnFamily ❖ Multiple SSTables for one ColumnFamily ❖ Immutable
doesn’t check if the row already exists ❖ Inserts and updates are almost similar : upsert ❖ A delete creates a tombstone ❖ Cassandra supports Batches ❖ Batches can be atomic
❖ Hot spots ❖ Choose RF according to the consistency ❖ Prefer idempotent inserts/updates ❖ Use timestamps on queries ❖ Prefer concurrent writes to a batch ❖ Trust your cluster (low consistency is most of the time sufficient)
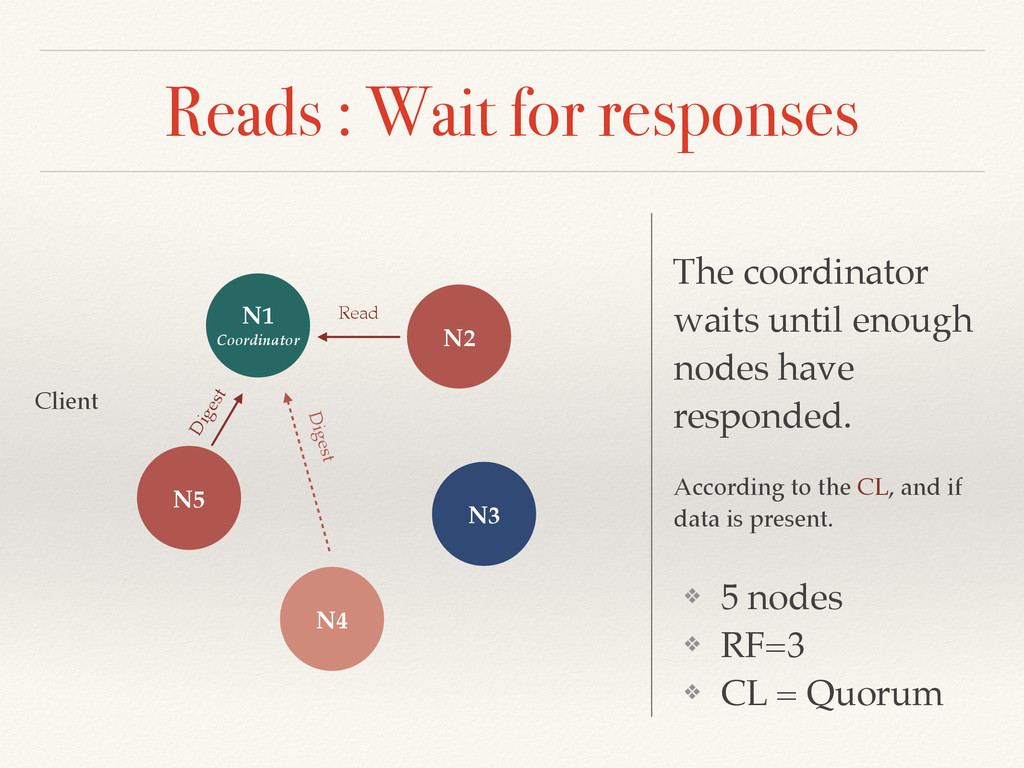
enough nodes have responded. According to the CL, and if data is present. N5 N1 Coordinator N2 N3 Client ❖ 5 nodes ❖ RF=3 ❖ CL = Quorum Read Digest Digest
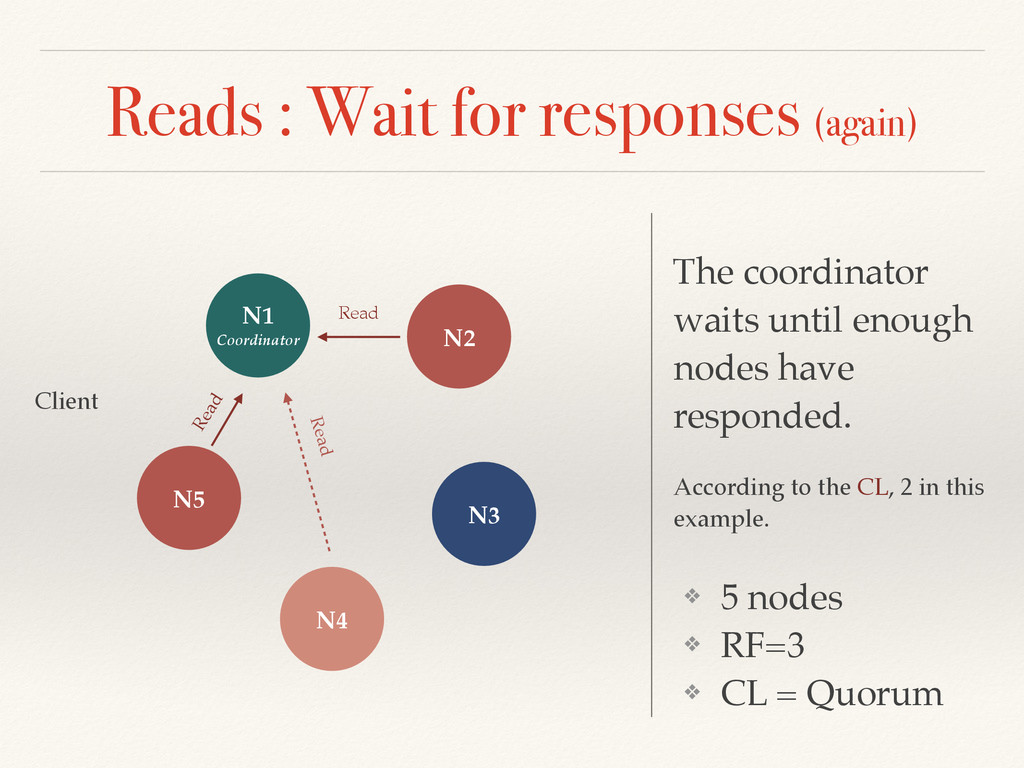
until enough nodes have responded. According to the CL, 2 in this example. N5 N1 Coordinator N2 N3 Client ❖ 5 nodes ❖ RF=3 ❖ CL = Quorum Read Read Read
Use the bloom filter to filter SSTables ❖ Use index to find row, and columns ❖ Read & Merge data ❖ Search in memory ❖ The Memtable contains the most recent data (updated lately) First Step Second Step Note ❖ A KeyCache is used to speed up column index seek ❖ A RowCache with frequently asked partitions can be used
similar-sized SSTables (when >4 by default) ❖ Would need 100% much free space during compaction ❖ No guarantees as to how many SSTables are read for one row ❖ Useful for : ❖ Write-heavy Workloads ❖ Rows Are Write-Once
team at Google ❖ Fixed small-sized SSTables (5MB by default) ❖ Non-overlapping within each level ❖ Read from a single SSTable 90% of the time ❖ Twice as much I/O as Size-Tiered ❖ Useful for : ❖ Rows Are Frequently Updated ❖ High Sensitivity to Read Latency ❖ Deletions or TTLed Columns in Wide Rows
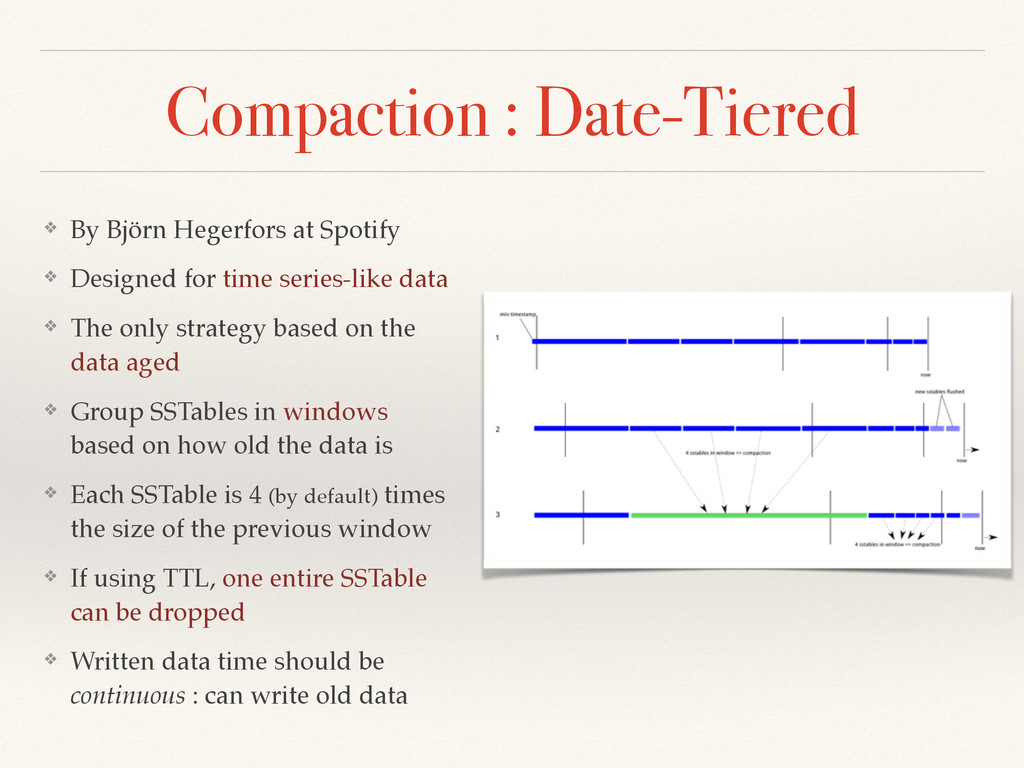
Designed for time series-like data ❖ The only strategy based on the data aged ❖ Group SSTables in windows based on how old the data is ❖ Each SSTable is 4 (by default) times the size of the previous window ❖ If using TTL, one entire SSTable can be dropped ❖ Written data time should be continuous : can write old data
concerned by writes) ❖ Use Denormalization ❖ Choose your primary keys ❖ Keep number of SSTables low (choose your compaction strategy) ❖ Use high consistency if really needed
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}