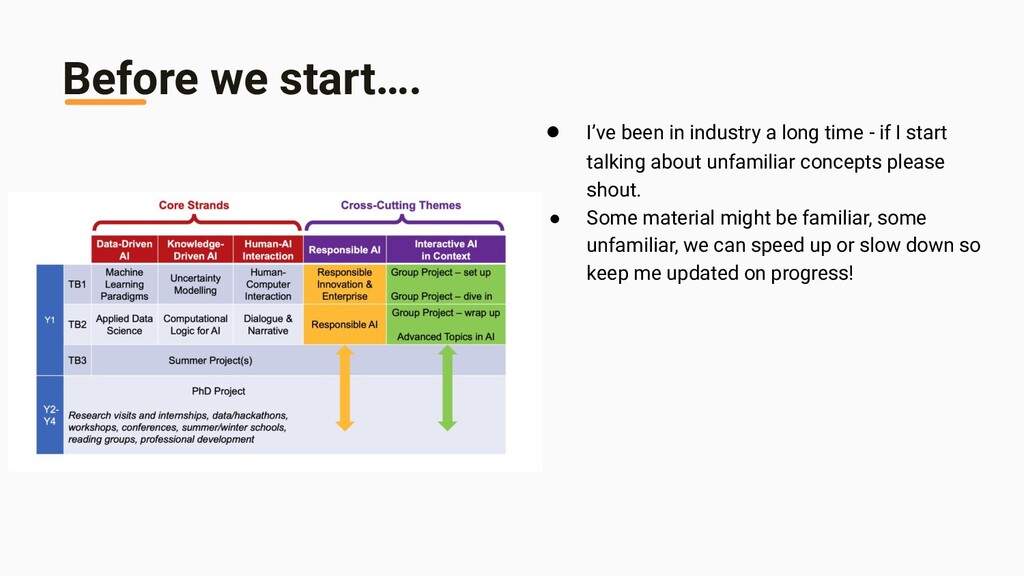
time - if I start talking about unfamiliar concepts please shout. • Some material might be familiar, some unfamiliar, we can speed up or slow down so keep me updated on progress!
• ML consultant at SecondSync 2011-2013 • Postdoc at QMUL 2013 in computational creativity • Data Scientist/data architect at Black Swan data 2013-2014 • Research Engineer at Gluru 2015-2016 • AI lead at Adarga 2016-2018 • Currently Machine Learning Infrastructure Lead at Cookpad • Co-organise Bristol Machine Learning meetup @ettieeyre
to share recipe ideas and cooking tips. • Started in Japan in 1997, listed company at Tokyo Stock Exchange. • We’re a global company with offices in 10 countries and a team of 700 • In 2017, we set our Global HQ up in Bristol. We currently have about 100 employees in Bristol.
believe that cooking is the key to a happier and healthier life for people, communities and the planet. The choices we make shape our world. And when we cook, the choices we make have an impact on ourselves, the people we cook for, the growers and producers we buy from and the wider environment. By building the platform that solves the issues related to everyday cooking and helps more people to cook, we believe we can help build a better world.
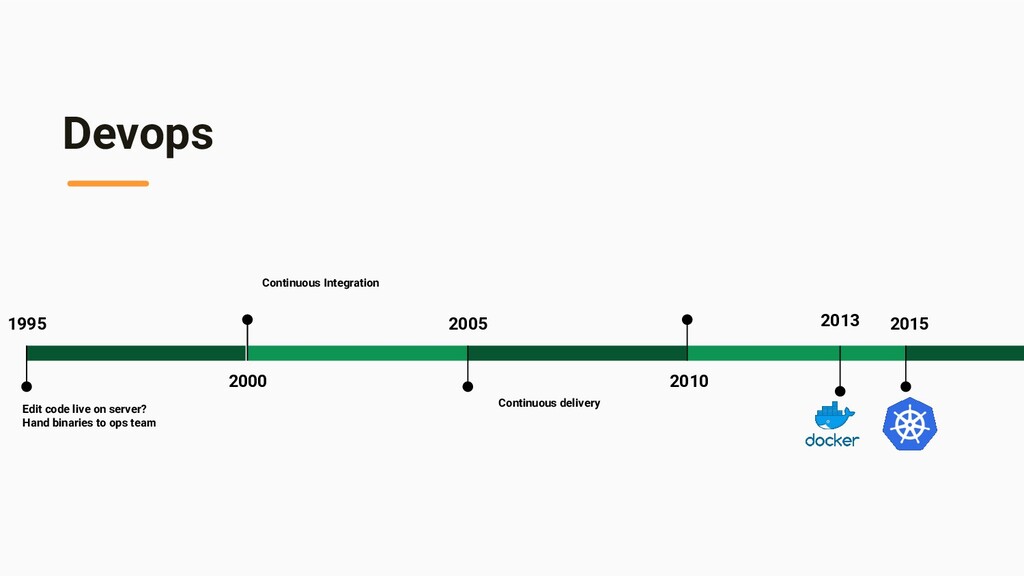
development and information-technology operations which aims to shorten the systems development life cycle and provide continuous delivery with high software quality.”
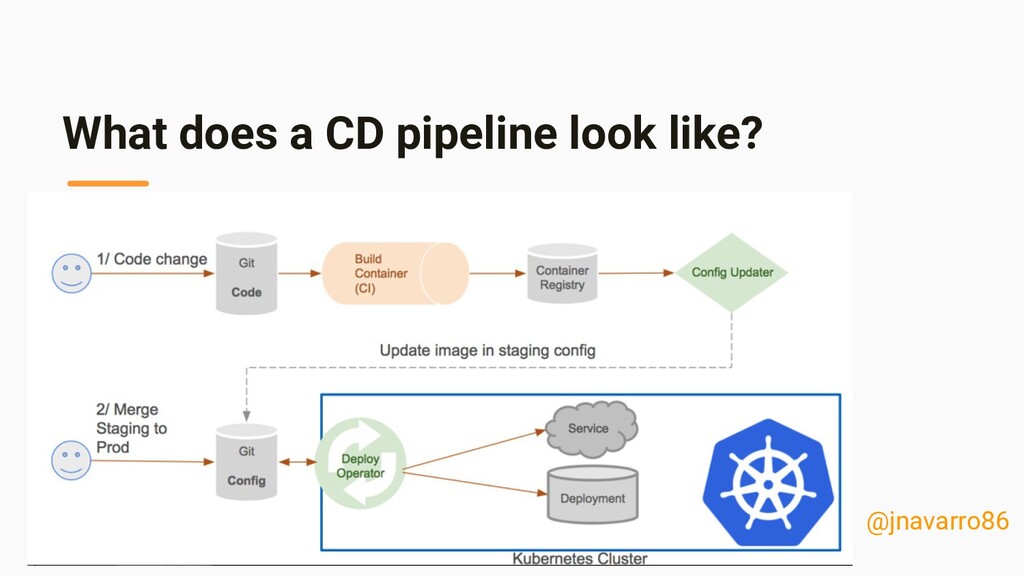
server • Ops team build your executables, and deploy onto a server • Cloud services (AWS, GCP, Azure, IBM, Oracle) • Immutable infrastructure, docker and kubernetes. • Continuous integration and continuous delivery • Gitops!
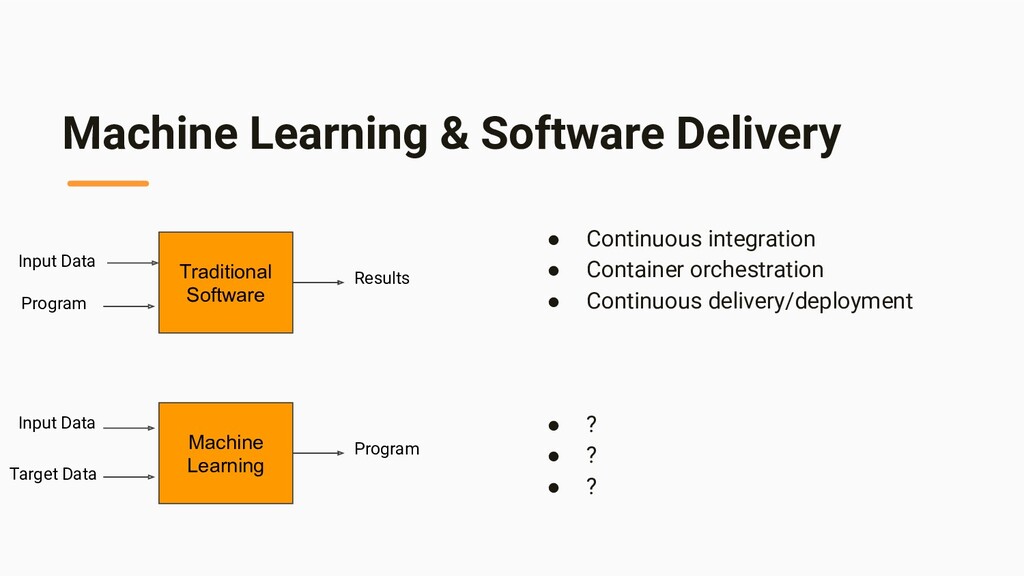
orchestration • Continuous delivery/deployment • ? • ? • ? Traditional Software Input Data Program Results Machine Learning Program Input Data Target Data
Monitoring for ML For each of these we want to achieve • Reliability • Test coverage • Reproducible behaviour • Joint ownership of development and operations
checked into a repository. • Online metrics vs. proxy metrics - do they . • Model staleness should be monitored (concept drift). • Simple models provide sensible baseline measures. • Model bias is tested/monitored.
the same distribution). • Unit tests for model code. • Integration tests on a full ML pipeline (data-features-training-model-serving). • Model quality is automatically assessed before serving. • Rollbacks in production if
can cause upstream problems. • Training and serving feature generation should compute the same values. • Monitor for model staleness. • NaNs in your data pipelines - what will the effect be? • Regressions in prediction quality - where will you generate and store the data to be able to do this?
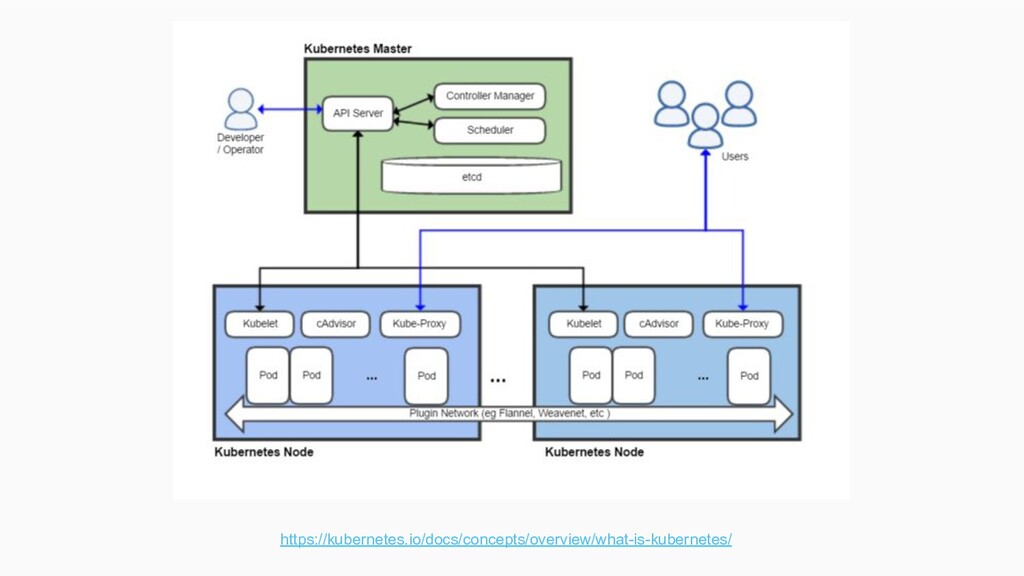
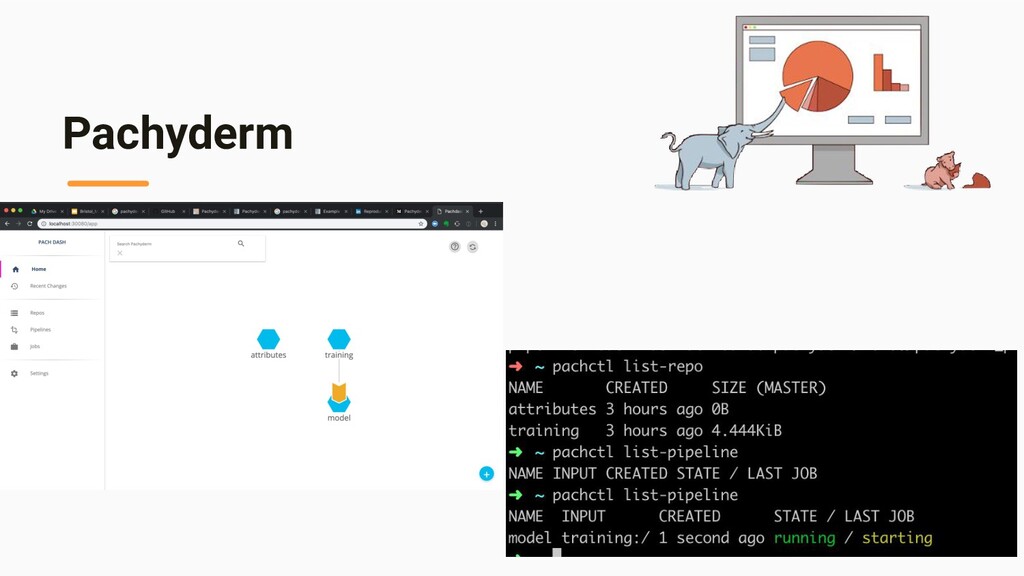
on kubernetes • Git for data, stored in custom distributed file system PFS (pachyderm file system). Tracks data commits and automates containerised processing between pfs buckets • Pachyderm pipelines automate data processing
features: ◦ pipelines ◦ katib ◦ Kube bench ◦ Notebooks ◦ Model store (versioned) ◦ Versioned data through metadata store • Pachyderm pipelines automate data processing
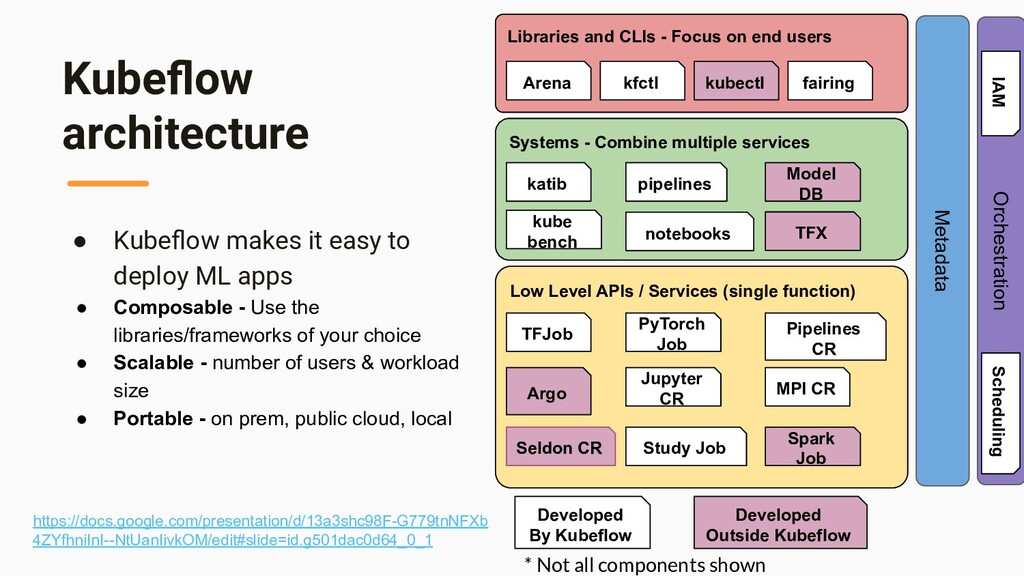
apps • Composable - Use the libraries/frameworks of your choice • Scalable - number of users & workload size • Portable - on prem, public cloud, local Libraries and CLIs - Focus on end users Systems - Combine multiple services Low Level APIs / Services (single function) Arena kfctl kubectl katib pipelines notebooks fairing TFJob PyTorch Job Jupyter CR Seldon CR kube bench Metadata Orchestration Pipelines CR Argo Study Job MPI CR Spark Job Model DB TFX Developed By Kubeflow Developed Outside Kubeflow * Not all components shown IAM Scheduling https://docs.google.com/presentation/d/13a3shc98F-G779tnNFXb 4ZYfhniInI--NtUanIivkOM/edit#slide=id.g501dac0d64_0_1
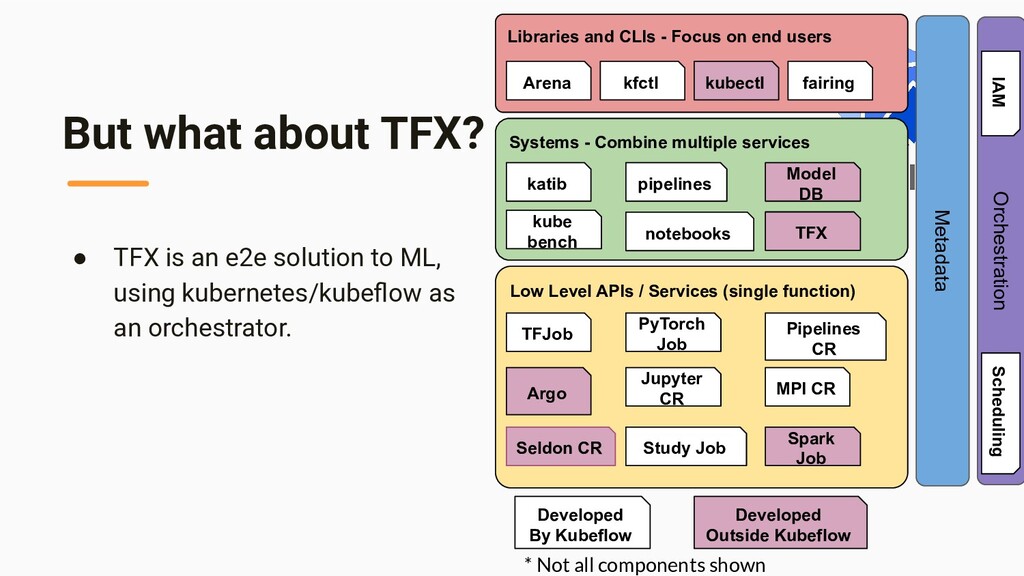
end users Systems - Combine multiple services Low Level APIs / Services (single function) Arena kfctl kubectl katib pipelines notebooks fairing TFJob PyTorch Job Jupyter CR Seldon CR kube bench Metadata Orchestration Pipelines CR Argo Study Job MPI CR Spark Job Model DB TFX Developed By Kubeflow Developed Outside Kubeflow * Not all components shown IAM Scheduling • TFX is an e2e solution to ML, using kubernetes/kubeflow as an orchestrator.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}