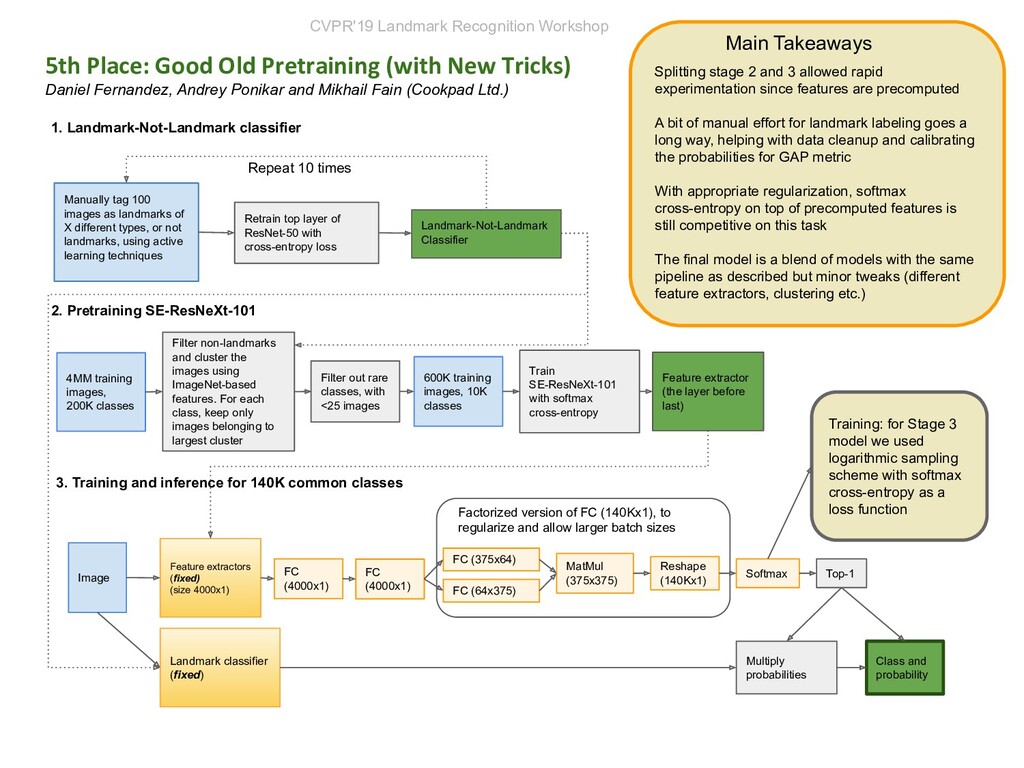
New Tricks) Daniel Fernandez, Andrey Ponikar and Mikhail Fain (Cookpad Ltd.) 1. Landmark-Not-Landmark classifier 2. Pretraining SE-ResNeXt-101 3. Training and inference for 140K common classes Manually tag 100 images as landmarks of X different types, or not landmarks, using active learning techniques Retrain top layer of ResNet-50 with cross-entropy loss Landmark-Not-Landmark Classifier Repeat 10 times 4MM training images, 200K classes Filter out rare classes, with <25 images Filter non-landmarks and cluster the images using ImageNet-based features. For each class, keep only images belonging to largest cluster 600K training images, 10K classes Train SE-ResNeXt-101 with softmax cross-entropy Feature extractor (the layer before last) Image Feature extractors (fixed) (size 4000x1) FC (4000x1) FC (375x64) MatMul (375x375) FC (64x375) Reshape (140Kx1) FC (4000x1) Factorized version of FC (140Kx1), to regularize and allow larger batch sizes Landmark classifier (fixed) Softmax Splitting stage 2 and 3 allowed rapid experimentation since features are precomputed A bit of manual effort for landmark labeling goes a long way, helping with data cleanup and calibrating the probabilities for GAP metric With appropriate regularization, softmax cross-entropy on top of precomputed features is still competitive on this task The final model is a blend of models with the same pipeline as described but minor tweaks (different feature extractors, clustering etc.) Top-1 Multiply probabilities Class and probability Main Takeaways Training: for Stage 3 model we used logarithmic sampling scheme with softmax cross-entropy as a loss function
{kind=link}