Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介7月分
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
miyanishi
July 24, 2014
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介7月分
miyanishi
July 24, 2014
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
文献紹介15年08月
miyanishi
0
240
15年7月文献紹介
miyanishi
0
270
Featured
See All Featured
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
How to Ace a Technical Interview
jacobian
281
24k
A Tale of Four Properties
chriscoyier
163
24k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
410
Faster Mobile Websites
deanohume
310
31k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
140
A Modern Web Designer's Workflow
chriscoyier
698
190k
Raft: Consensus for Rubyists
vanstee
141
7.5k
Paper Plane
katiecoart
PRO
1
51k
Music & Morning Musume
bryan
47
7.2k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Navigating Team Friction
lara
192
16k
Transcript
自然言語処理研究室 修士1年 宮西 由貴
タイトル: Word Sense Disambiguation Improves Information Retrieval 著者:
Zhi Zhong Hwee Tou Ng Proceedings of Annual Meeting of ACL:Long papers,2012,p273-282 01
IRタスクにWSDは有効か? 有効・効果なし どちらの意見も存在 筆者の提案 語義情報を考慮した言語モデル 精度UP↑
同義関係を用いたクエリ拡張 再現率UP↑ IRタスクにおけるWSDの有効性を示した! 結果 02
語義曖昧性解消(WSD)の現状 他タスクへの有効性が期待 機械翻訳(MT)×WSD ⇒ 精度が向上! 情報検索(IR)×WSD
⇒ ??? IR×WSDの研究者の意見 WSDと組み合わせる効果あり WSDと組み合わせる効果なし どちらも 存在している 03
クエリのタームが多義の場合 WSDによって曖昧性解消 正しいクエリで検索が可能 ⇒精度がUP! クエリ拡張への応用を考えた場合
WSDによって語義が決定 同じ語義を持つ単語をクエリに使用可能 ⇒再現率がUP! クエリ:検索する語全体 ターム:クエリの要素 (例) 長岡 花火 04
精度UPのために・・・ 語義情報を考慮した言語モデル ▪ ベースはユニグラムモデル ▪ 語義を考慮するように拡張 再現率UPのために・・・
同義関係を用いたクエリ拡張 ▪ クエリ拡張のベースはPRF ▪ 同義語をクエリとして追加 05
None
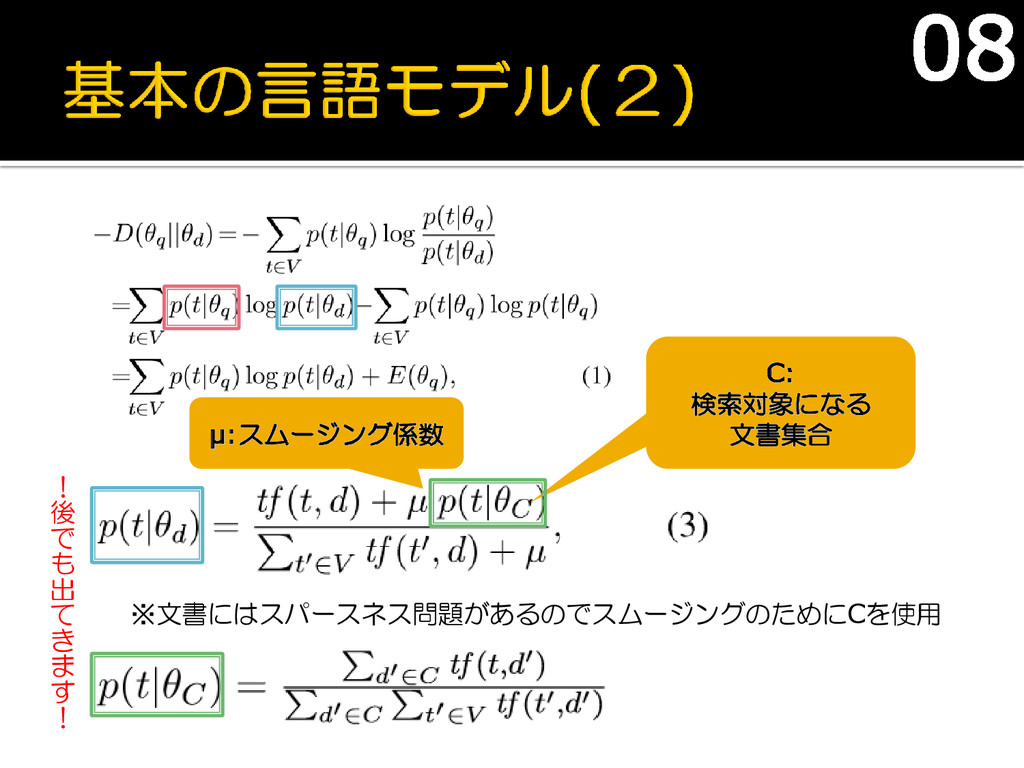
ユニグラムモデルをベースに使用 クエリと検索対象文書の類似度は ネガティブKL divergenceを使用 モデル :クエリ :文書 t:ターム
E():エントロピー 06
tf(t,q): q内での、tの出現頻度 07
※文書にはスパースネス問題があるのでスムージングのためにCを使用 C: 検索対象になる 文書集合 μ:スムージング係数 08 ! 後 で も
出 て き ま す !
再現率を上げるために行う PRFは2ステップ 文書集合Cをクエリによってランク付け 上位kランクの文書を使ってクエリ拡張 クエリ拡張メソッドは複数ある
説明略 09
対訳コーパス 7つ を使用 全て中国語-英語のペア 対訳コーパスの使い方 英・中の文をトークン化
GIZA++でアライメントを取得 ある単語e(英語)に着目して対訳対を取得 eの出現頻度が高い対訳文対のみを取得 ↑をトレーニングデータとして機械学習 10
IRにおけるWSDの難しさ:短い クエリに含まれるタームは2~3つほど 充分な情報を得られない PRFの考え方を用いる クエリと関係性の高い上位k件の文書を使用
文書中の単語を用いて曖昧性解消 11
S(t,q): t∈q に付与される 語義sの集合 stf(s,d): 文書dの中の 語義sの頻度 12
13 stf(s,d): 文書dの中の 語義sの頻度 R(s,q)=R(s)-S(q): 語義sと同義な語義の集合 - クエリqの中の全ターム に付与された語義集合
None
各クエリは50個ほど TREC TREC6-8を使用 TREC6のみパラメータ学習に使用 ROBUST
2003と2004のテストセットを使用 RB03,RB04と表記 14
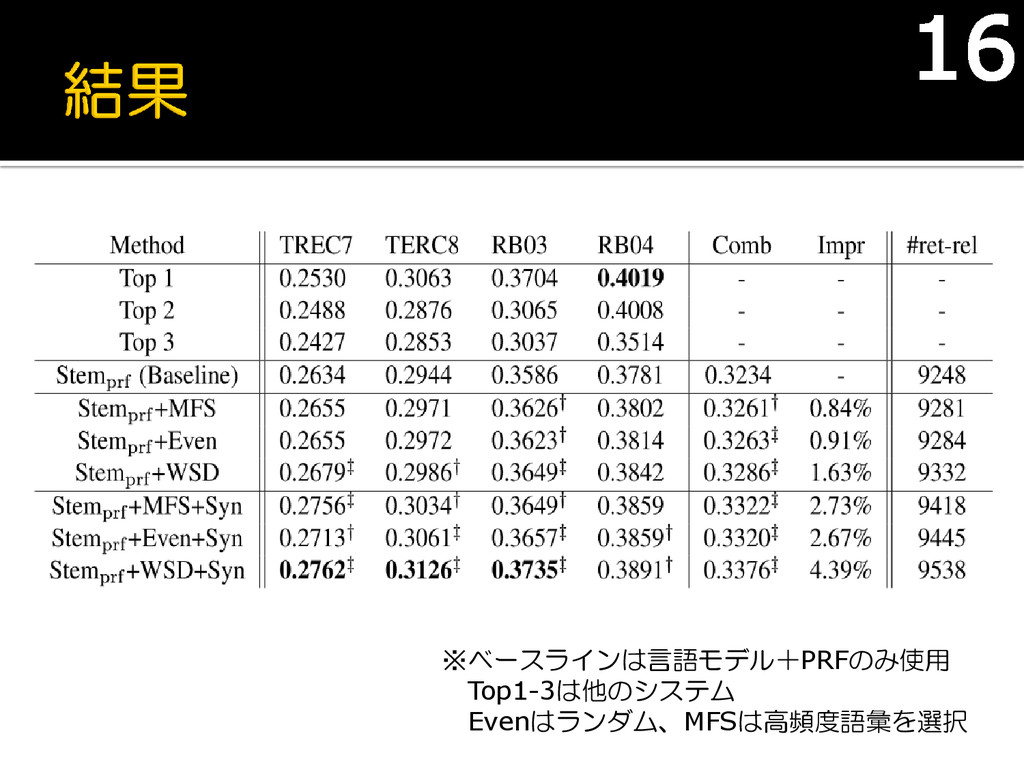
qと関連のある文書数 (正解文書数) r番目の文書が関係あり⇒1 その他⇒0 取得した文書数 Q:クエリqの集合 15
※ベースラインは言語モデル+PRFのみ使用 Top1-3は他のシステム Evenはランダム、MFSは高頻度語彙を選択 16
語義を考慮した方がスコアが高い 同義関係を用いたクエリ拡張も効果あり ちゃんとWSDを行うのが良い 筆者の仮説は当たっていた! 17
目的: WSDでIRは改良するのかを確かめる 提案: 語義を考慮した情報検索手法 RPFに代わる同義語を用いたクエリ拡張
結果: WSDによってIRが改良することを確認! 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}