Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介15年08月
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
miyanishi
July 24, 2015
240
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介15年08月
miyanishi
July 24, 2015
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
15年7月文献紹介
miyanishi
0
270
文献紹介15年06月
miyanishi
0
270
Featured
See All Featured
30 Presentation Tips
portentint
PRO
1
320
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
210
4 Signs Your Business is Dying
shpigford
187
22k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Between Models and Reality
mayunak
4
330
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Amusing Abliteration
ianozsvald
1
200
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
450
Making the Leap to Tech Lead
cromwellryan
135
9.9k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Transcript
文献紹介 山本研究室 修士2年 宮西 由貴
文献情報 • Orthographic and Morphological Processing for Persian-to-English Statistical Machine
Translation • Rasooli, Mohammad,et. al. • International Joint Conference on Natural Language Processing 2013 • P14-18 2
概要 • ペルシア語の複雑さを前処理でなくす – スペース – 活用 • SMTにどれだけ寄与するか? –
データスパースネスに効果あり? 3
ペルシア語の問題点 • 単語中のスペースについて – セミスペースと呼ばれるスペースを使用 – 大抵の人は普通のスペースと区別せず使用 →NLPツールはセミスペースで書くことを想定 →曖昧性も増加 •
pro-drop言語 4
ペルシア語の問題点 • ペルシア語の性や活用 – rich inflection な言語(接尾辞が多彩) – 形容詞 •
比較的シンプルな活用 • 比較級・最上級などが活用の対象 – 名詞 • 形容詞を伴う名詞句は形容詞によって接尾辞が付属 – 動詞 • 時制やムードなど様々な理由で接尾辞が変化 • 100種類以上の動詞+接尾辞の形が存在 5
スペースに関する解決策 • セミスペース辞書を作成 – セミスペースを持ちうる語を集めた辞書を作成 – コーパスの一部(トレーニングデータ)から セミスペースを含む語を取得 – 取得した語に対して活用を考慮し,拡張
• 言語モデルの作成 – バックオフを持つ3-gramを言語モデルとして使用 6
スペースに関する解決策 • N-gramモデルのチューニング – ツリーバンクをdevelopment setとして使用 – セミスペースを全て通常スペースに直し, セミスペースを予測 •
結果 – 精度→93% – 再現率→99% – F値→96% 7
既存の形態素解析について • PerStem – 正規表現+規則を用いて形態素解析 – 接尾辞なども除くことが可能 • 動詞の活用があまりに複雑 →動詞を正しく分割する方法を考案
8
提案する解析器 • VerbStem – 動詞の発見→コーパスから最尤推定 – 既存の動詞分析器を利用して 全ての付属(接辞など)を分割 – 動詞分析器の入力はセミスペースを使用
→セミスペースの推定を利用 9
機械翻訳への反映 • 5つのパターンを用意 – Raw :特になにもしない – Raw-RS : 全通常スペースをセミスペースに変換
– PerStem : PerStem解析器を使用 – Clean-SS : セミスペースの推定→校正 – VerbStem : 提案手法 10
実験設定 • ペルシア語-英語のパラレルコーパス – 160T文(3.7M語) – テストセットは268文 • アライメント:GIZA++ •
SMTシステム:moses 11
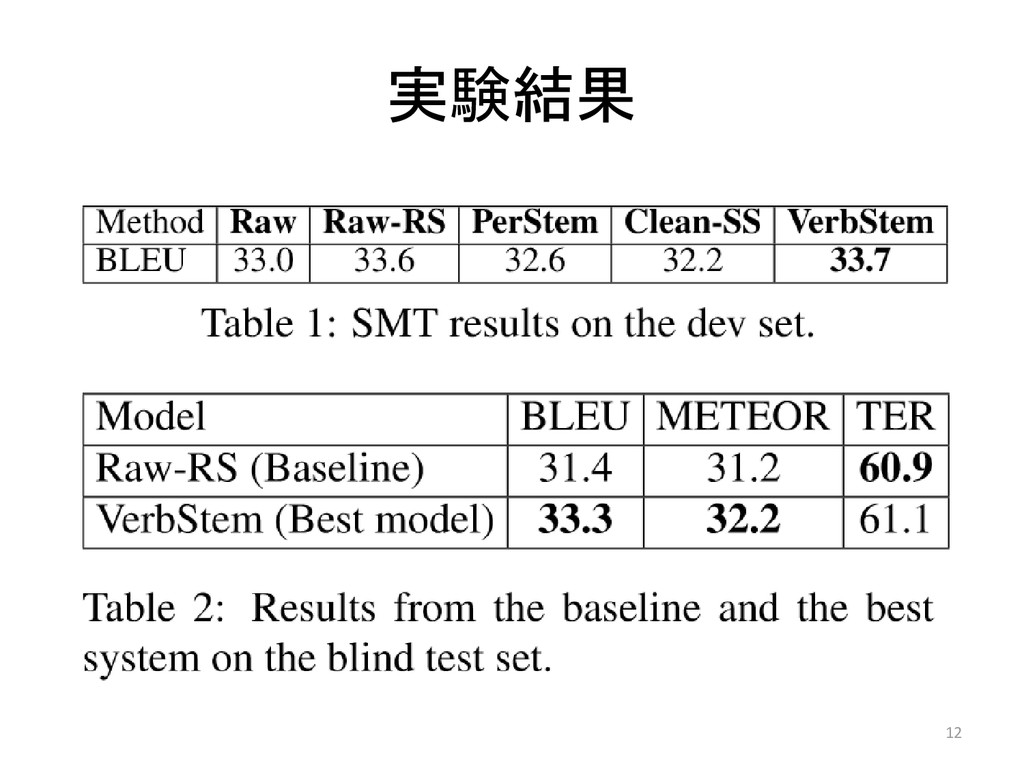
実験結果 12
概要 • ペルシア語の複雑さを前処理でなくす – スペースについて – 動詞の活用について • SMTにどれだけ寄与するか? –
データスパースネスに効果あり? – BLUE値で約1.5ポイントの上昇 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}