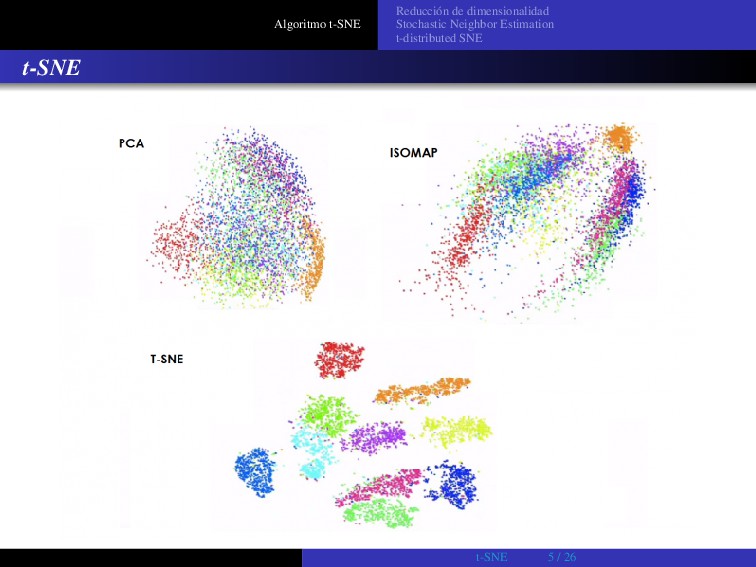
t-SNE t-SNE (t-Distributed Stochastic Neighbor Embedding) es un algoritmo no lineal de reducción de dimensionalidad, que funciona particularmente bien para visualización de conjuntos de datos de alta dimensionalidad. Se usa en procesamiento de imágenes, NLP, procesamiento de lenguaje y datos genómicos. ... y en astronomía t-SNE 4 / 26
Reducción de dimensionalidad Hay varias formas de reducir la dimensionalidad de un problema: Feature Elimination Reducir el espacio de features eliminando algunos. Feature Selection Asignar una metrica de importancia a los features, y quedarse con los más importantes. Feature Extraction Crear nuevos features que son funciones (lineales o no lineales) de los features originales. t-SNE 6 / 26
Reducción de dimensionalidad Los métodos de reducción de dimensionalidad convierten datos multidimensionales X = x1 , x2 , x3 , ..., xn (”datos”) en datos de baja dimensionalidad, Y = y1 , y2 , y3 , ..., yn (”puntos del mapa”). Lo que se busca es aprovechar la baja dimensionalidad para poder visualizar los datos. El objetivo de la reducción de dimensionalidad es preservar tanto como se pueda la estructura de datos en espacios multidimensionales en mapas de baja dimensionalidad. t-SNE 7 / 26
Stochastic Neighbor Embedding (SNE) SNE (Stochastic Neightbor Embedding, Hinton & Roweis 2002) convierte distancias euclideas en N dimensiones (N>> 2) en probabilidades condicionales que representan "similaridad". La similaridad entre un dato y otro es una medida de ”que tan parecidos son”, y se define como la probabilidad de que un dato xi elija a otro dato xj como vecino, sorteando todos los vecinos en base a una distribución Gaussiana de la distancia Euclídea. pi|j = exp(−||xi − xj ||2/2σ2 i ) k=i exp(−||xi − xk ||2/2σ2 i ) (1) donde los parámetros σi se deben optimizar. Notar que la similaridad no es simétrica. t-SNE 8 / 26
Similaridad La similaridad en el espacio de los datos, pi|j = exp(−||xi − xj ||2/2σ2 i ) k=i exp(−||xi − xk ||2/2σ2 i ) (2) tiene un equivalente en el espacio del mapa: qi|j = exp(−||yi − yj ||2/2σ2 i ) k=i exp(−||yi − yk ||2/2σ2 i ) (3) El mapa modela correctamente la similaridad entre los pares de datos en el espacio multidimensional, cuando las probabilidades condicionales sean iguales. Se define entonces una función de costo que cuantifica la diferencia entre las dos distribuciones. t-SNE 9 / 26
Kullback–Leibler divergence Es una medida de la diferencia entre dos distribuciones de probabilidad. Para dos distribuciones discretas de probabilidad, P y Q, la divergencia de Kullback–Leibler se define como el valor de expectación sobre P de la diferencia logarítmica entre P y Q: DKL = x∈X Pi|j log Pi|j Qi|j (4) Luego, DSNE = i DKL (Pi ||Qi ) (5) = i x∈X Pi|j log Pi|j Qi|j (6) donde X es la población. t-SNE 10 / 26
Similaridad similaridad en el espacio de los datos: pi|j = exp(−||xi − xj ||2/2σ2 i ) k=i exp(−||xi − xk ||2/2σ2 i ) (7) similaridad en el mapa: qi|j = exp(−||yi − yj ||2/2σ2 i ) k=i exp(−||yi − yk ||2/2σ2 i ) (8) El método SNE define una función de costo para minimizar la diferencia entre pi|j y qi|j , como la suma de las divergencias de Kullback–Leibler: C = i j pi|j log pi|j qi|j (9) t-SNE 11 / 26
Entropía de Shannon Una de las aplicaciones de la divergencia de Kullback-Leibler es la caraterización de la Entropía de Shannon. En su desarrollo de la teoría de la información (mediados del siglo XX), Claude E. Shannon introduce una función para medir el contenido de información de un evento A de una fuente discreta: I(A) = −log(P(A)) (10) La cantidad promedio de información de un sistema es el valor de expectación de la información I(A), es decir, HS (X) = i p(xi )log(p(xi )) (11) t-SNE 12 / 26
Perplexity Para el SNE, la perplexidad (?) es una medida del número efectivo de vecinos, y se define como Perp(Pi ) = 2HS(Pi) (12) donde HS (Pi ) = − j pi|j log2 (pi|j ) (13) t-SNE 13 / 26
Gradient descent La minimización de la función de costo: DSNE = i x∈X Pi|j log Pi|j Qi|j (14) mediante el descenso por gradiente asume una forma simple: ∂DSNE ∂yi = 2 j [pj|i − qj|i + pi|j − qi|j ](yi − yj ) (15) t-SNE 14 / 26
SNE: elección de la varianza σi El parámetro σi, que da la varianza de la Gaussiana para elegir vecinos centrada en cada punto dato i, es un parámetro libre. En general no hay un valor único que sea óptimo para todos los puntos, principalmente por los posibles cambios en la densidad de puntos: en las regiones densas es preferible usar varianzas más chicas que en las regiones escasas (sparse). El valor σi para el punto i induce una distribución de probabilidad Pi sobre todos los demás datos. La entropía de esta distribución aumenta con σ. El algoritmo SNE busca los valores de las varianzas fijando la perplexidad. t-SNE 15 / 26
Interpretación de la función de costo ∂DSNE ∂yi = 2 j pj|i − qj|i + pi|j − qi|j (yi − yj ) (16) se puede interpretar ("físicamente", Van der Maaten & Hinton 2008) comom la fuerza resultante de un conjunto de resortes entre el punto mapa yi y otros puntos mapa yj. Los resortes ejercen una fuerza en la dirección yi − yj. Estos resortes atraen o repelen pares de puntos mapa dependiendo si su distancia en el mapa es muy grande o muy chica para representar las similaridades entre los puntos multidimensionales. t-SNE 16 / 26
la ”t” en t-SNE SNE produce buenas visualizaciones, pero tiene algunos problemas: optimization problem: la función de costo es difícil de optimizar crowding problem: Se propone una variación del método, t-SNE, en donde: usa una versión simetrizada de la función de costo, con un gradiente más simple reemplaza la distribución Gaussiana por una t-Student para calcular la similaridad en el espacio de baja dimensión. t-SNE 19 / 26
t-SNE: simetrización de la función de costo En lugar de usar como función de costo la divergencia de KL entre las distribuciones condicionales pi|j y qi|j , se puede usar la divergencia de KL entre las distribuciones conjuntas: DSNE = i x∈X Pij log Pij Qij (17) que tienen las propiedades: pij = pji ∀i, j pero... que quiere decir esta probabilidad conjunta? t-SNE 20 / 26
t-SNE: simetrización de la función de costo La similaridad SNE en el mapa: qi|j = exp(−||yi − yj ||2/2σ2 i ) k=i exp(−||yi − yk ||2/2σ2 i ) (18) va a ser ahora: qi|j = exp(−||yi − yj ||2) k=i exp(−||yi − yk ||2) (19) t-SNE 21 / 26
t-SNE: simetrización de la función de costo y en el espacio de datos: pi|j = exp(−||yi − yj ||2/2σ2 i ) k=i exp(−||yi − yk ||2/2σ2 i ) (20) podría ser ahora: pi|j = exp(−||yi − yj ||2/2σ) k=i exp(−||yi − yk ||2/2σ) (21) pero causa problemas cuando hay datos que son outliers, ya que la función de costo casi no se ve afectada. Esto se soluciona redefiniendo una probabilidad conjunta simetrizada: pij = pi|j + pj|i 2n (22) t-SNE 22 / 26
t-SNE: simetrización de la función de costo pij = pi|j + pj|i 2n (23) En la versión simetrizada de la función de costo, se cumple que j pij es siempre no menor a 1/(2n), y por lo tanto cada dato hace una contribución no despreciable a la función de costo. Esta propuesta tiene la ventaja de que la función de costo, DSNE = i x∈X Pij log Pij Qij (24) tiene un gradiente más simple y fácil de calcular: (antes) ∂DSNE ∂yi = 2 j [pj|i − qj|i + pi|j − qi|j ](yi − yj ) (25) (ahora) ∂DSNE ∂yi = 4 j [pji − qij ](yi − yj ) (26) t-SNE 23 / 26
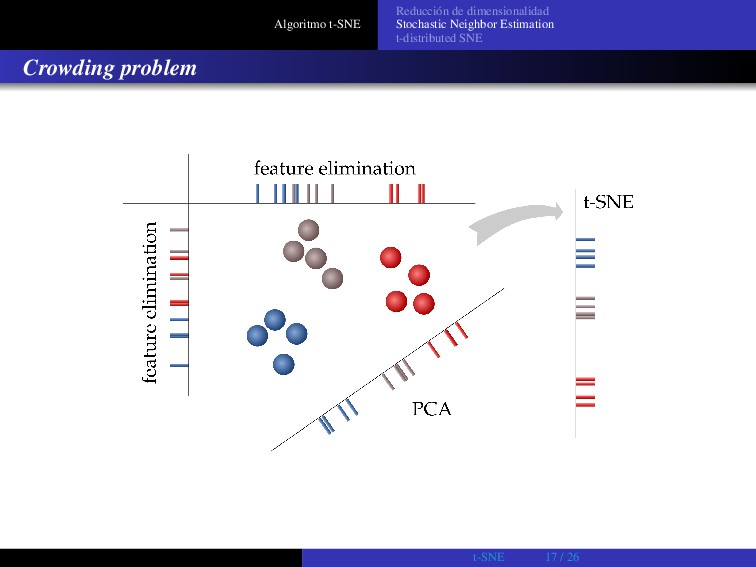
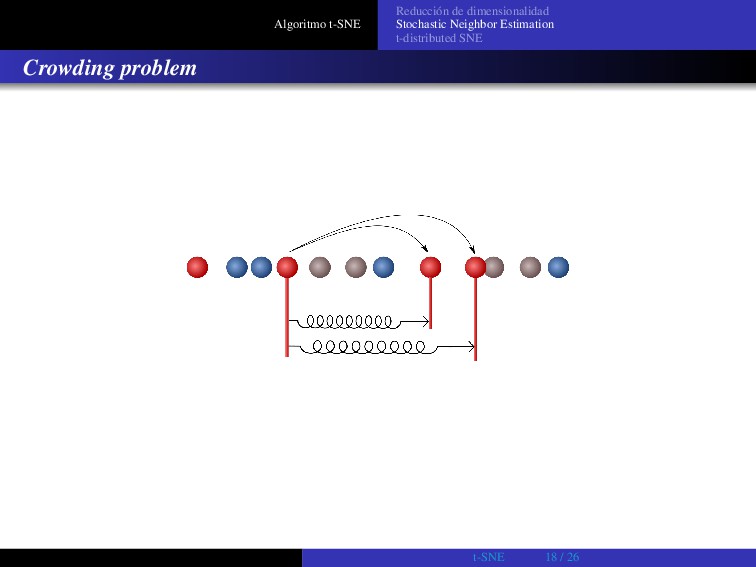
Crowding problem La alta dimensionalidad induce algunos problemas... No se puede modelar (perfectamente) con puntos en 2 dimensiones una distribución de puntos en N> 2 dimensiones. En N dimensiones podemos tener N+1 datos equidistantes. No hay manera de modelar esto en un mapa de 2 dimensiones. Sea un conjunto de datos en un subespacio bidimensional curvo que es aproximadamente lineal en escalas pequeñas, incluido en otro espacio de mayor dimensión: El volumen de una esfera de radio R en N dimensiones escala como RN. Por lo tanto si en N dimensiones tenemos una distribución de puntos uniforme, para modelarlos en 2 dimensiones hace falta mucho "más espacio". t-SNE 24 / 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}