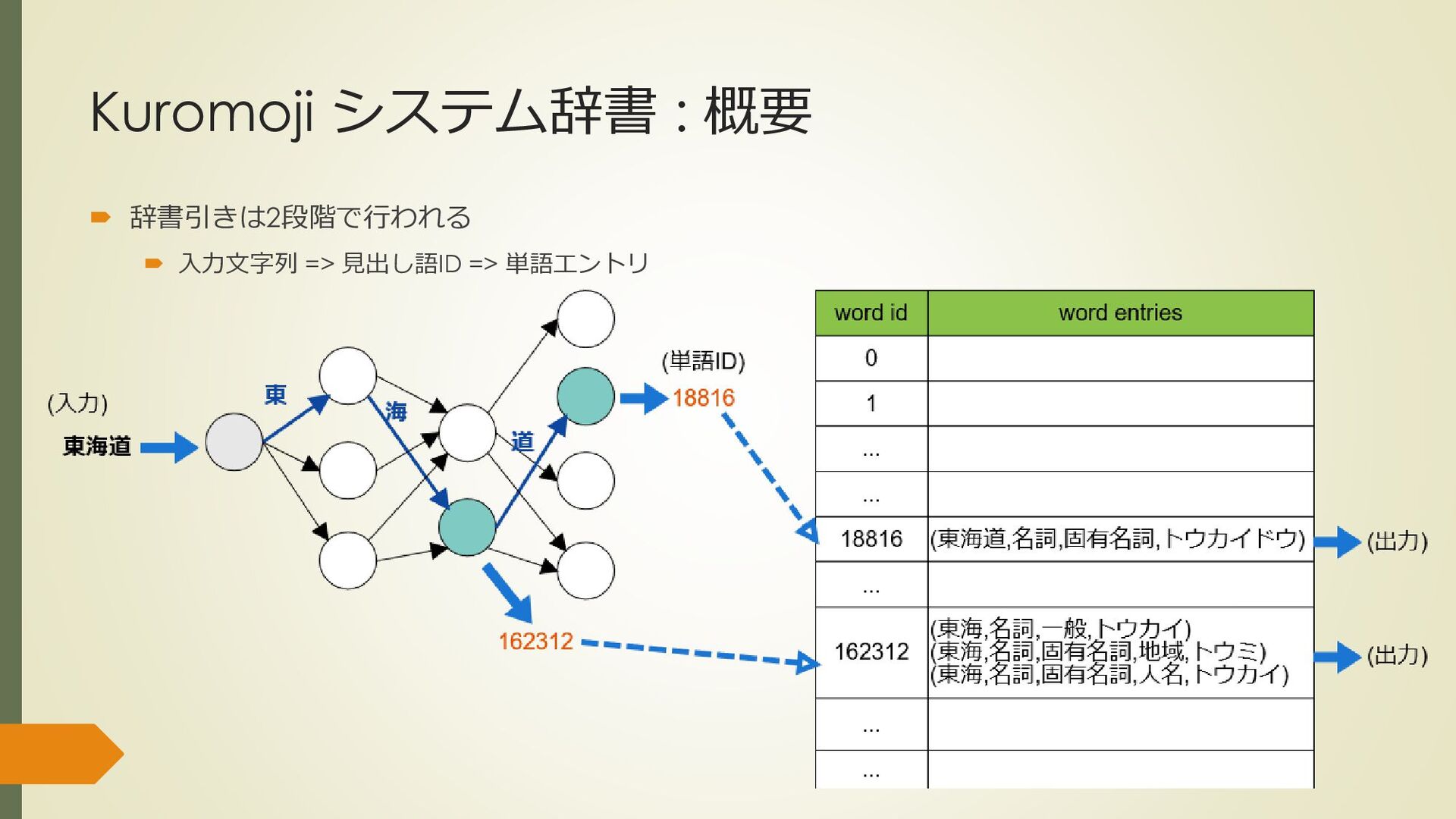
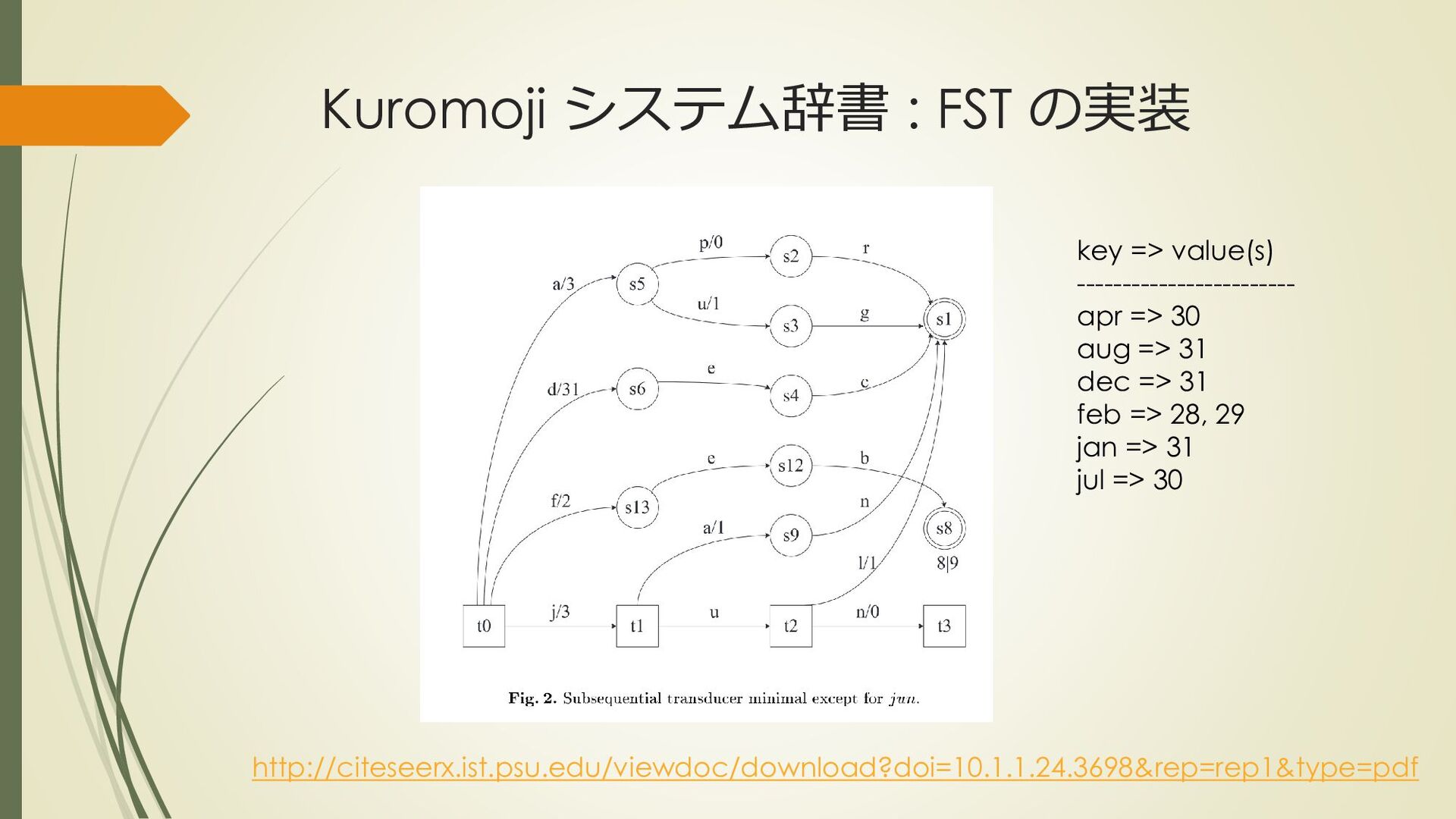
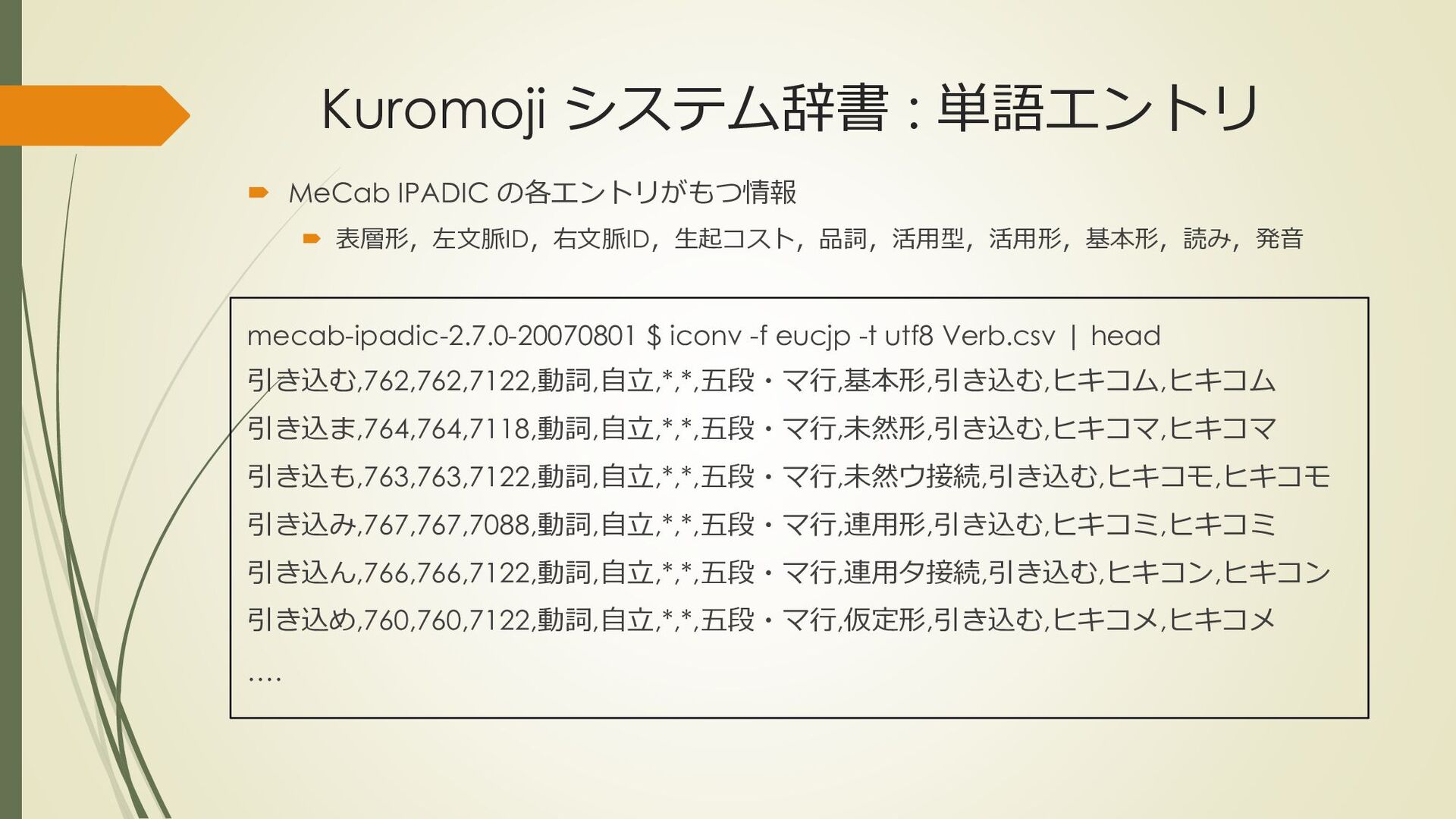
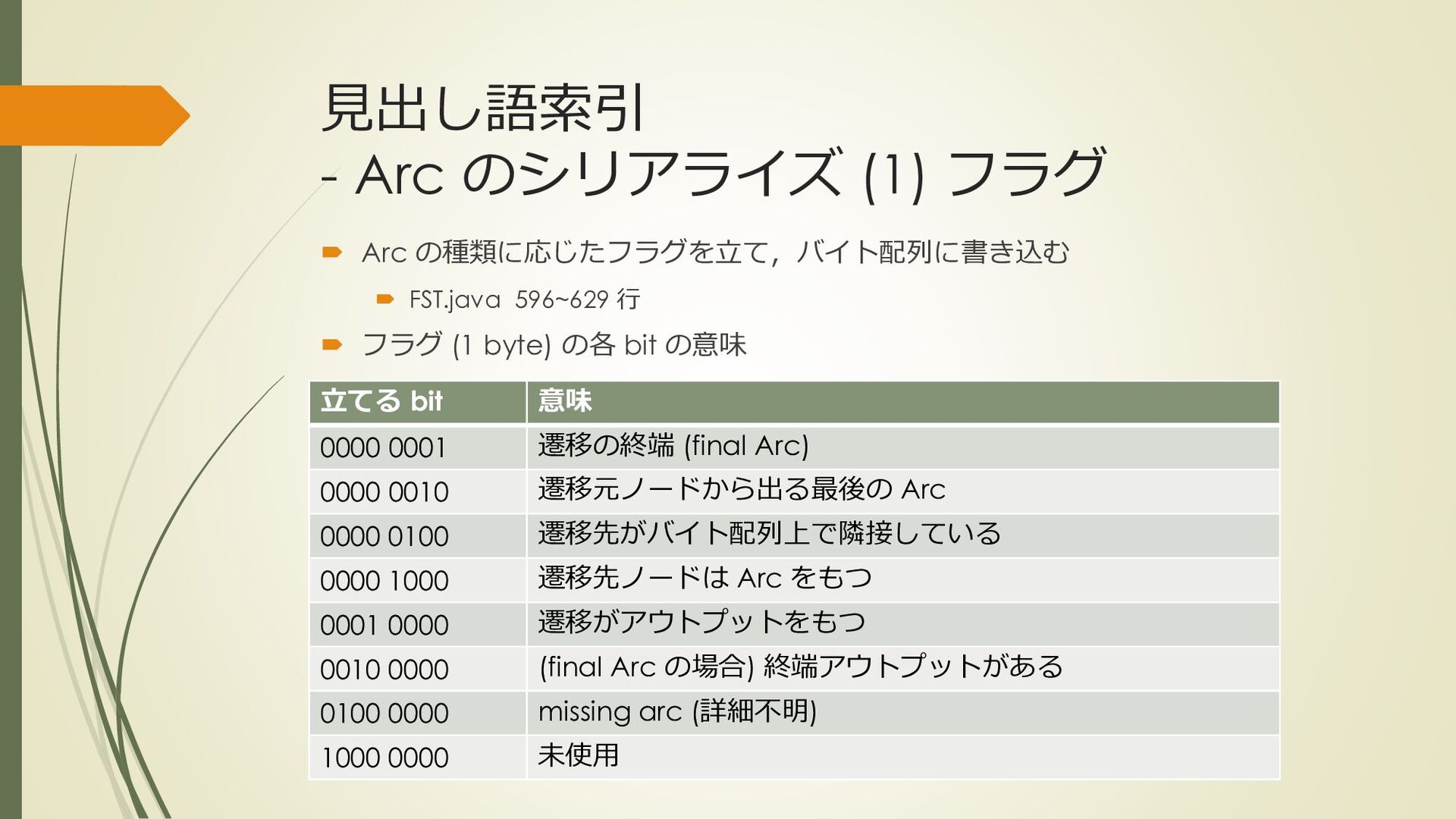
mecab-ipadic-2.7.0-20070801 $ iconv -f eucjp -t utf8 Verb.csv | head 引き込む,762,762,7122,動詞,自立,*,*,五段・マ行,基本形,引き込む,ヒキコム,ヒキコム 引き込ま,764,764,7118,動詞,自立,*,*,五段・マ行,未然形,引き込む,ヒキコマ,ヒキコマ 引き込も,763,763,7122,動詞,自立,*,*,五段・マ行,未然ウ接続,引き込む,ヒキコモ,ヒキコモ 引き込み,767,767,7088,動詞,自立,*,*,五段・マ行,連用形,引き込む,ヒキコミ,ヒキコミ 引き込ん,766,766,7122,動詞,自立,*,*,五段・マ行,連用タ接続,引き込む,ヒキコン,ヒキコン 引き込め,760,760,7122,動詞,自立,*,*,五段・マ行,仮定形,引き込む,ヒキコメ,ヒキコメ ….
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![単語エントリ - BinaryDictionaryWriter カラム 内容 entry[0] 表層形(見出し語) entry[1] 左文脈ID entry[2]](https://files.speakerdeck.com/presentations/d8618cf9e1de42bd95a0e040159a9fc5/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
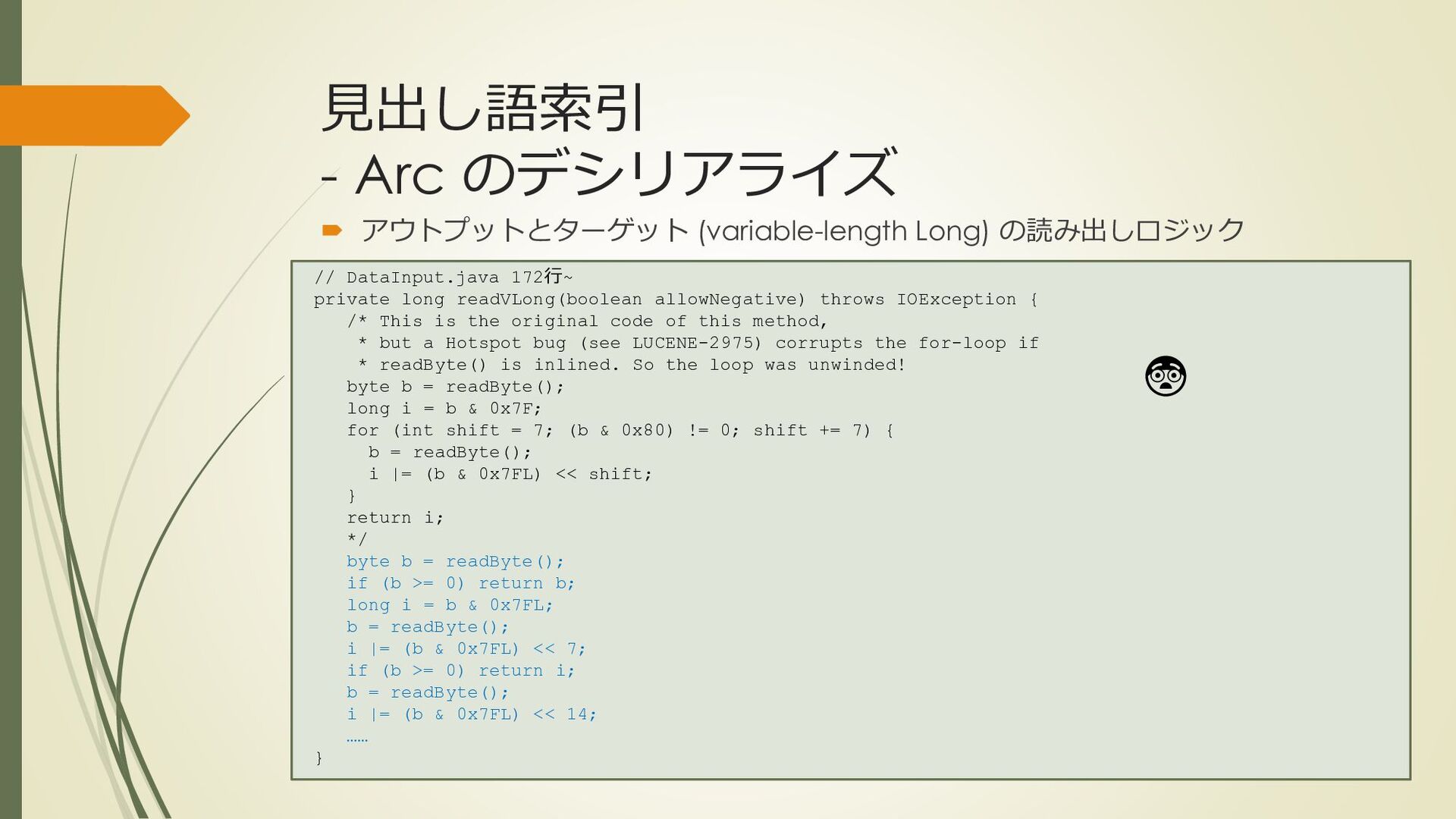{kind=link}
{kind=link}
{kind=link}
![おまけ:開発は続く システム辞書データと形態素解析器を切り離したいという案件 [LUCENE-8816] mecab ipadic もそろそろ古くなってきた. unidic](https://files.speakerdeck.com/presentations/d8618cf9e1de42bd95a0e040159a9fc5/slide_61.jpg){kind=link}
{kind=link}