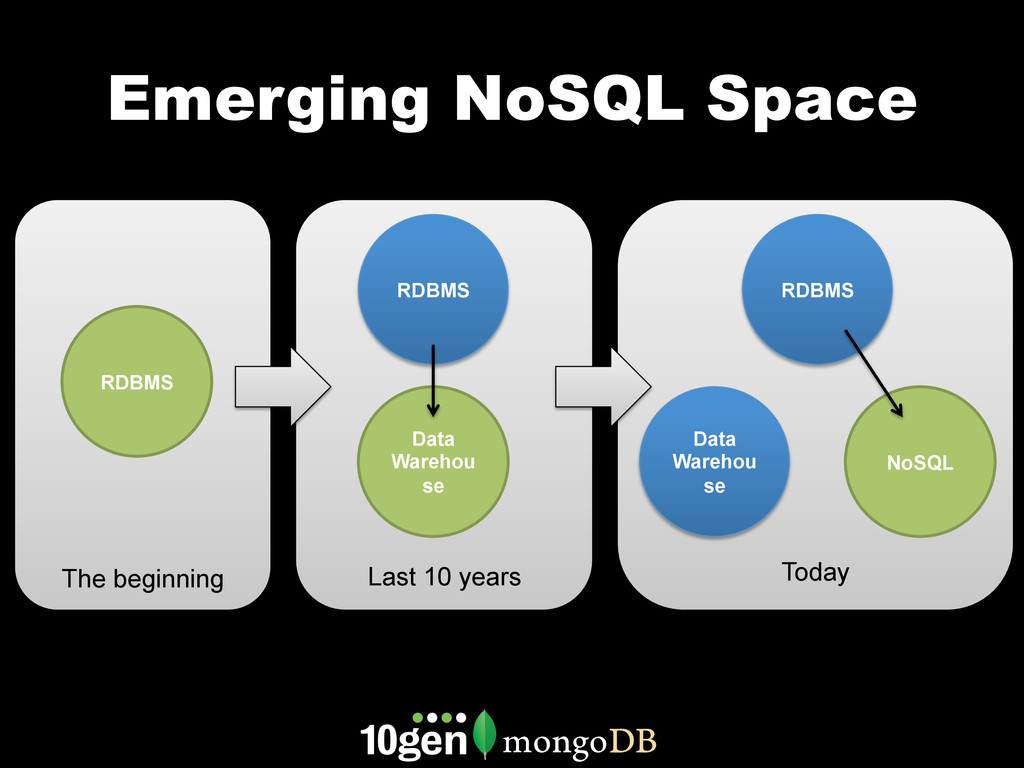
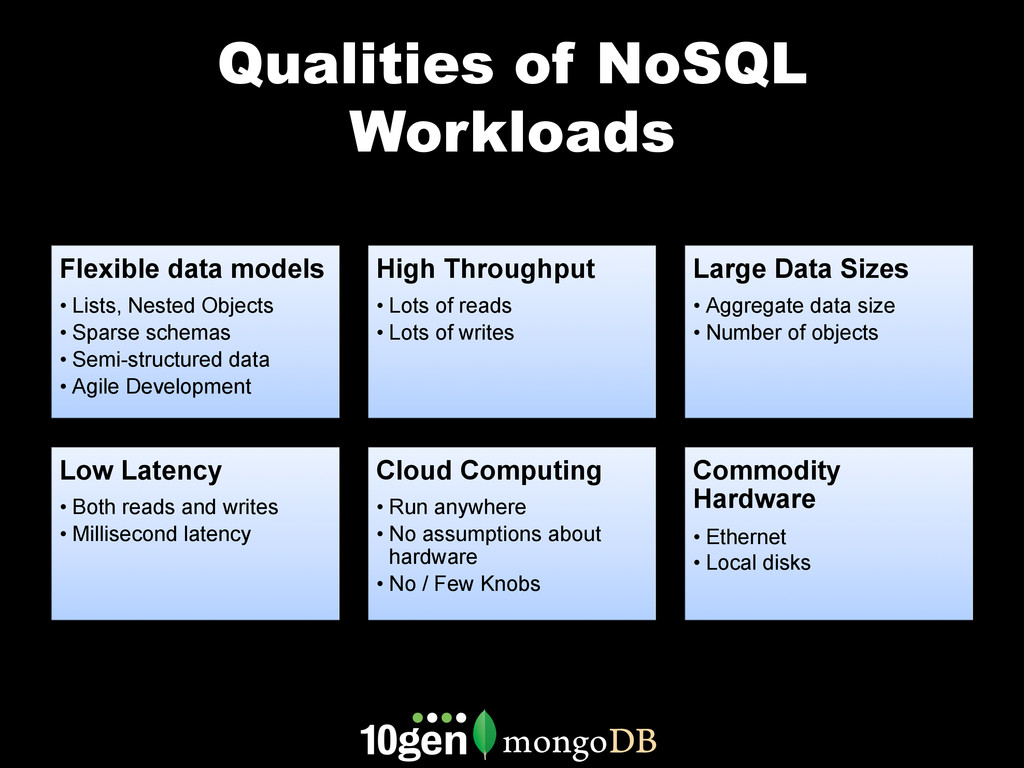
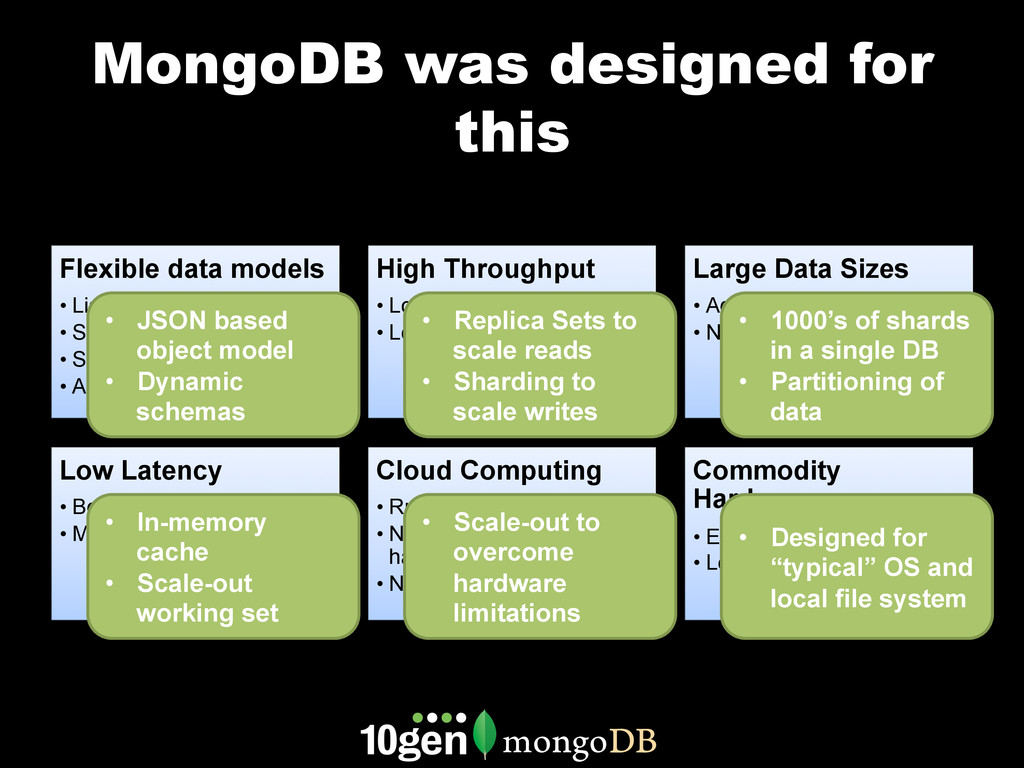
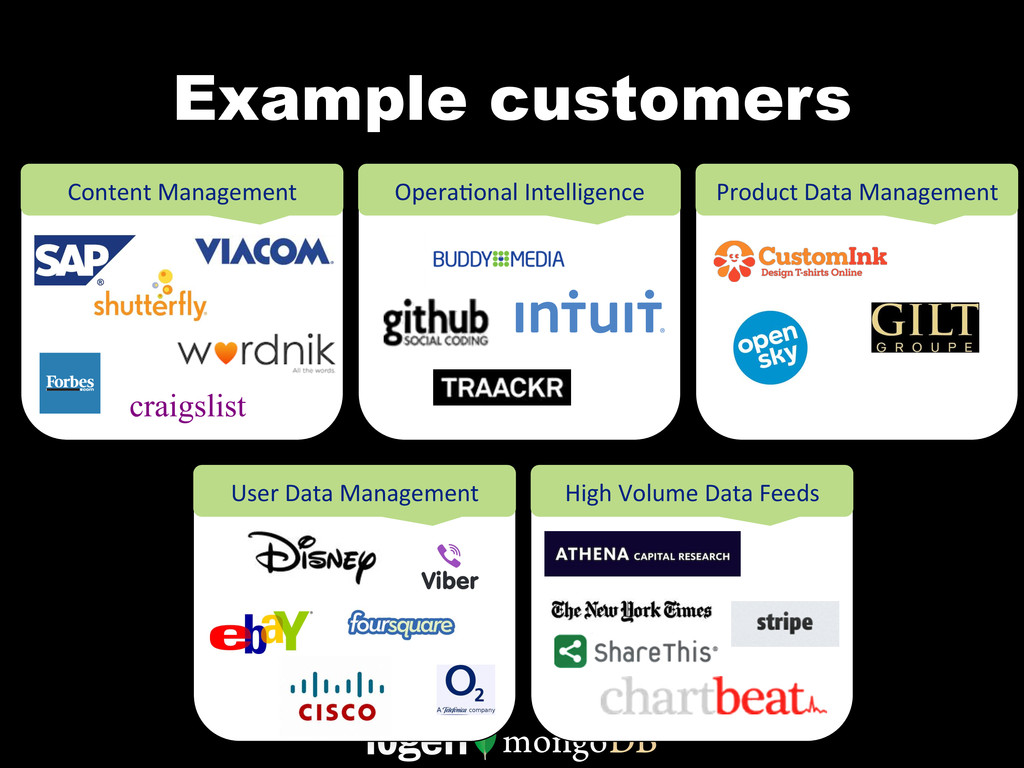
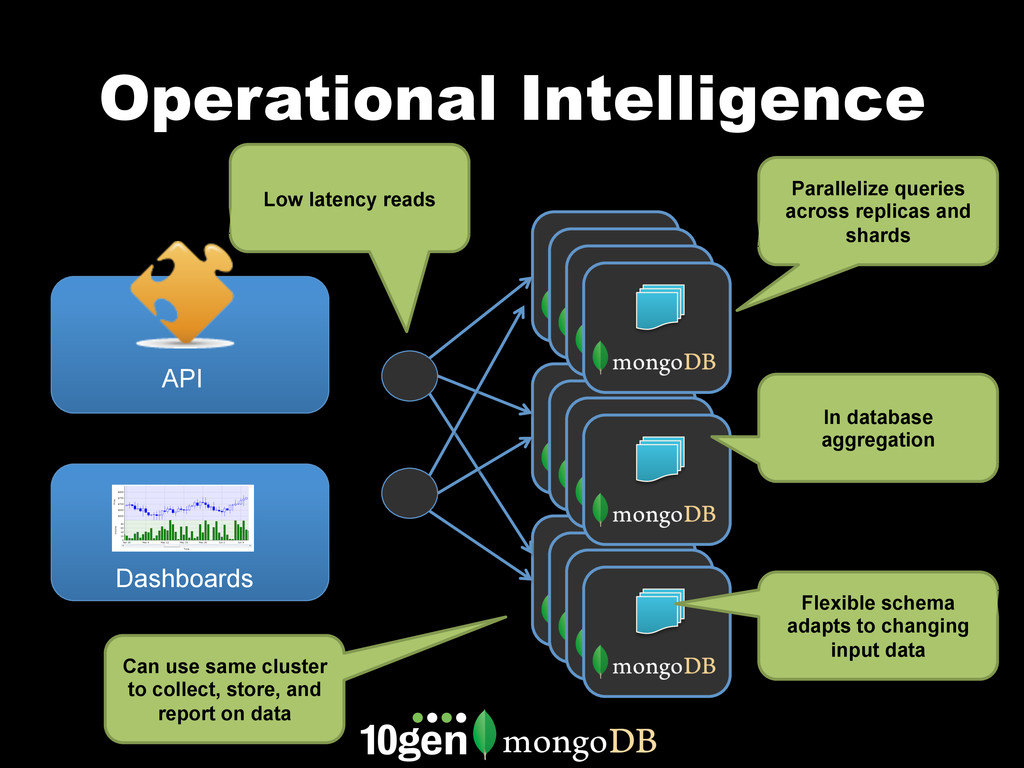
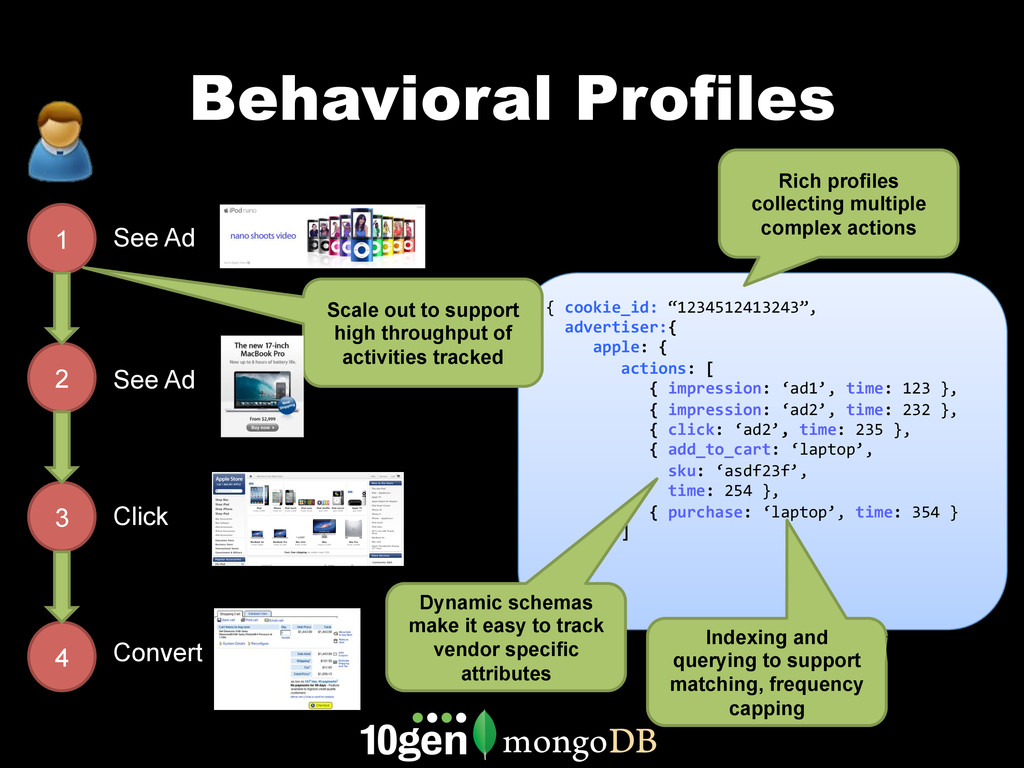
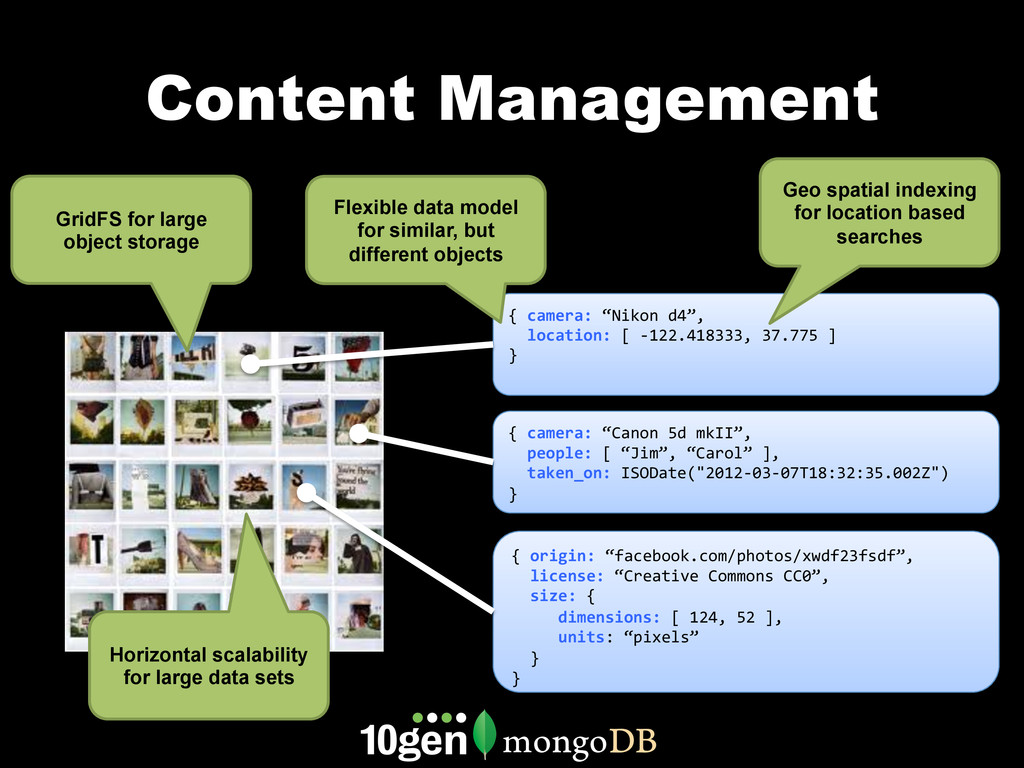
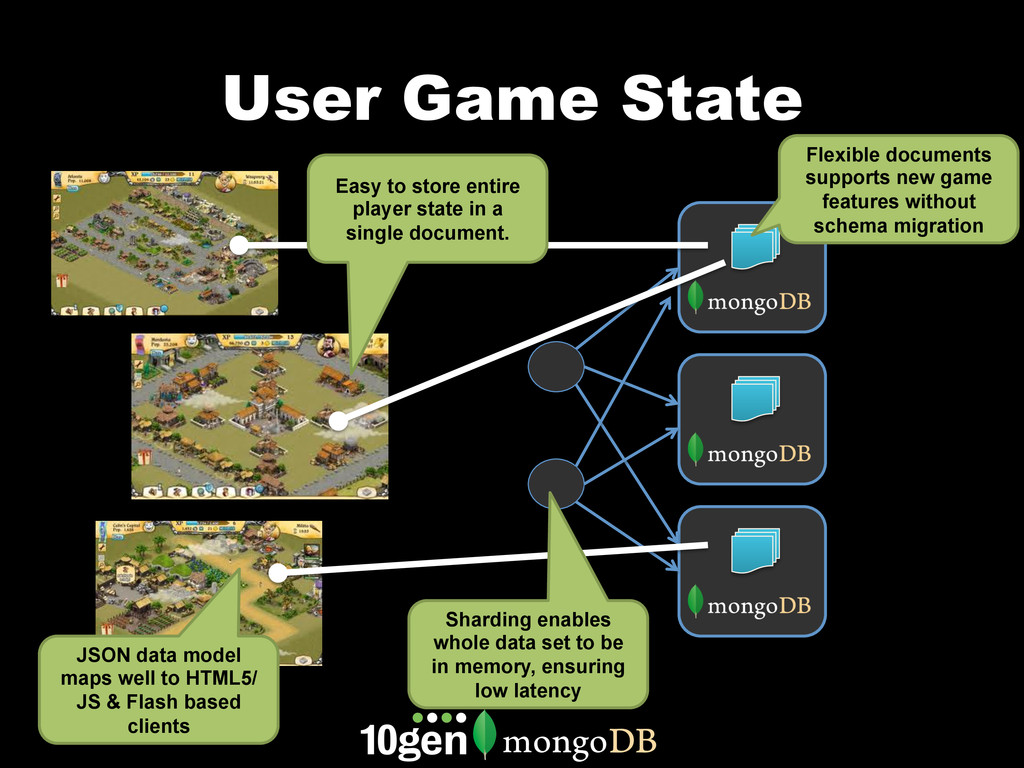
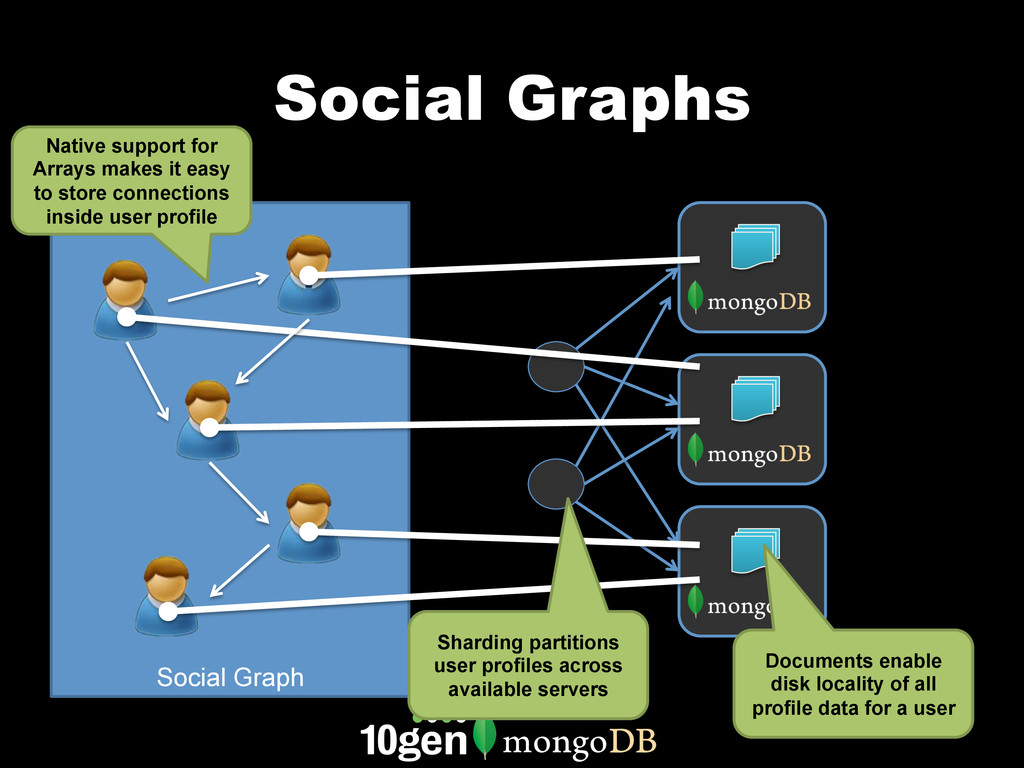
MongoDB works differently than other databases. It's document oriented data model, range based partitioning, and strong consistency model are well suited to some problems, and less well suited to others. In this webinar, we'll go through real world use cases of MongoDB that take advantage of these unique features. We'll cover specific customers using MongoDB, how they implemented their solution and how you can build similar solutions for your own organization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}